别再硬抗K8s多云管理的痛了,我带你从零手撸Kurator,这套实操方案真能让运维早下班
别再硬抗K8s多云管理的痛了,我带你从零手撸Kurator,这套实操方案真能让运维早下班
哈喽大家好,我是你们的Kurator老司机。咱们搞云原生的,不管是做DevOps还是SRE,最近这两年肯定被“多云”、“混合云”甚至“边缘计算”这些概念轰炸得头皮发麻。说实话,单搞一个K8s集群都已经够让人掉头发了,现在还得管一堆散落在各地的集群,这不是要命吗?Kurator这玩意儿说白了,就是个能帮你把多云、边缘、调度一把抓的“瑞士军刀”。我都替大家试过了,它整合了Karmada、Volcano、KubeEdge这些开源神器,就像是个大管家,专门治各种集群管理的疑难杂症。咱们今天就来个实操局,顺便把它的底裤……哦不,底层逻辑给扒一扒。
一、 先把家伙事儿备齐:Kurator环境搭建实录
咱们搞技术的,光说不练假把式。要玩转Kurator,第一步肯定得先把环境搭起来。很多人觉得开源项目部署难,其实Kurator这点做得还挺人性化。咱们直接上Linux环境,不管是虚拟机还是云主机,跟着我这几步走,基本不会翻车。
1. 基础依赖与源码获取
首先你机器上得有Go环境和Docker,这个我就不啰嗦了。重点来了,咱们得把源码拉下来。别去瞎搜索了,直接用这个官方镜像库,速度稳得一比。
我们可以从github上面下载源码,我把源码标注出来啦
点击后拉到最下面就可以看到源码压缩包啦,不同需求的朋友可以下载不同平台的源码
下载下来解压就可以看到源码文件啦
2. 编译与初始配置
拉下来之后,咱们得编译出CLI工具。这里有个坑要注意,就是网络问题导致依赖包拉不下来,建议配个GOPROXY。编译完之后,咱们就可以初始化一个控制面了。这步其实就是在你本地或者管理集群上安装Kurator的Operator和CRD。
3. 验证环境
装完之后,你得确认所有的Pod都Run起来了。一般来说,你会看到kurator-controller-manager在跑,这就说明咱们的地基打好了,后面才能盖楼。
二、 揭秘核心引擎:从调度到底层架构的“上帝视角”
环境弄好了,咱们得懂它的原理,不然出了Bug你都不知道去哪看日志。Kurator之所以强,是因为它把好几个大佬(Karmada, Volcano等)的能力揉在一起了。
1. Karmada多集群管理平台的总体架构
这是Karmada多集群管理平台的总体架构图,展示了其控制平面如何通过各类控制器实现策略分发与跨集群资源协同: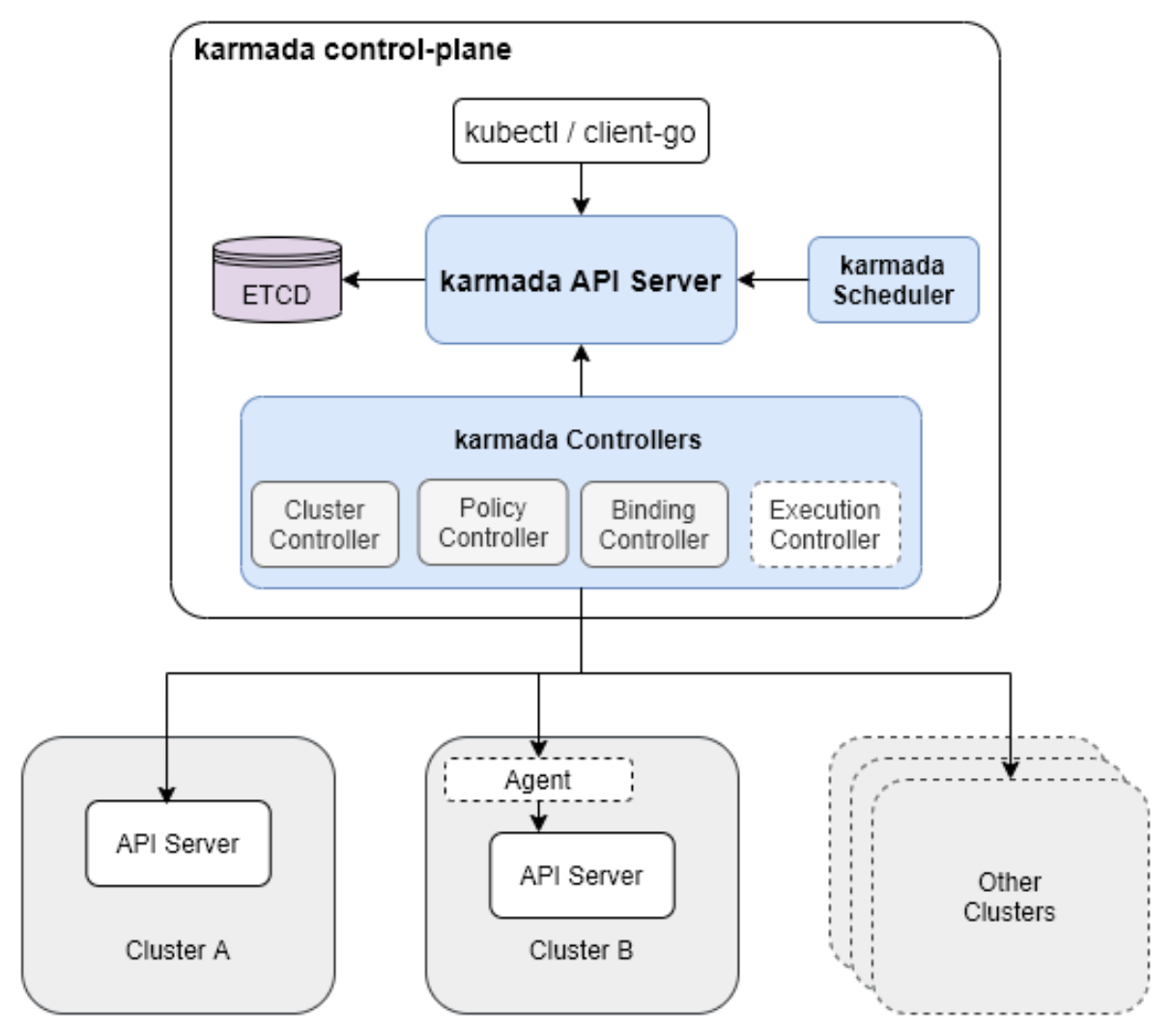
Kurator的多集群能力其实是Karmada给的。你可以把Karmada想象成一个“集群的集群管理器”。它的架构很有意思,分为控制面和数据面。控制面里有API Server、Scheduler、Controller Manager,这跟K8s很像,但它管的是“Member Cluster”(成员集群)。
它的核心逻辑是:用户只跟Karmada控制面交互,提交资源清单。Karmada会把这些资源“翻译”并分发到下属的几十上百个集群里。这中间有个关键组件叫Cluster Controller,它负责盯着每个成员集群的状态,一旦哪个集群断连了或者资源不够了,它立马就能感知到。
2. Karmada调度引擎与Volcano调度器工作流
这是Karmada调度引擎的官方参考图,展示了其如何将资源模板绑定到不同集群,并应用差异化策略实现工作负载分发: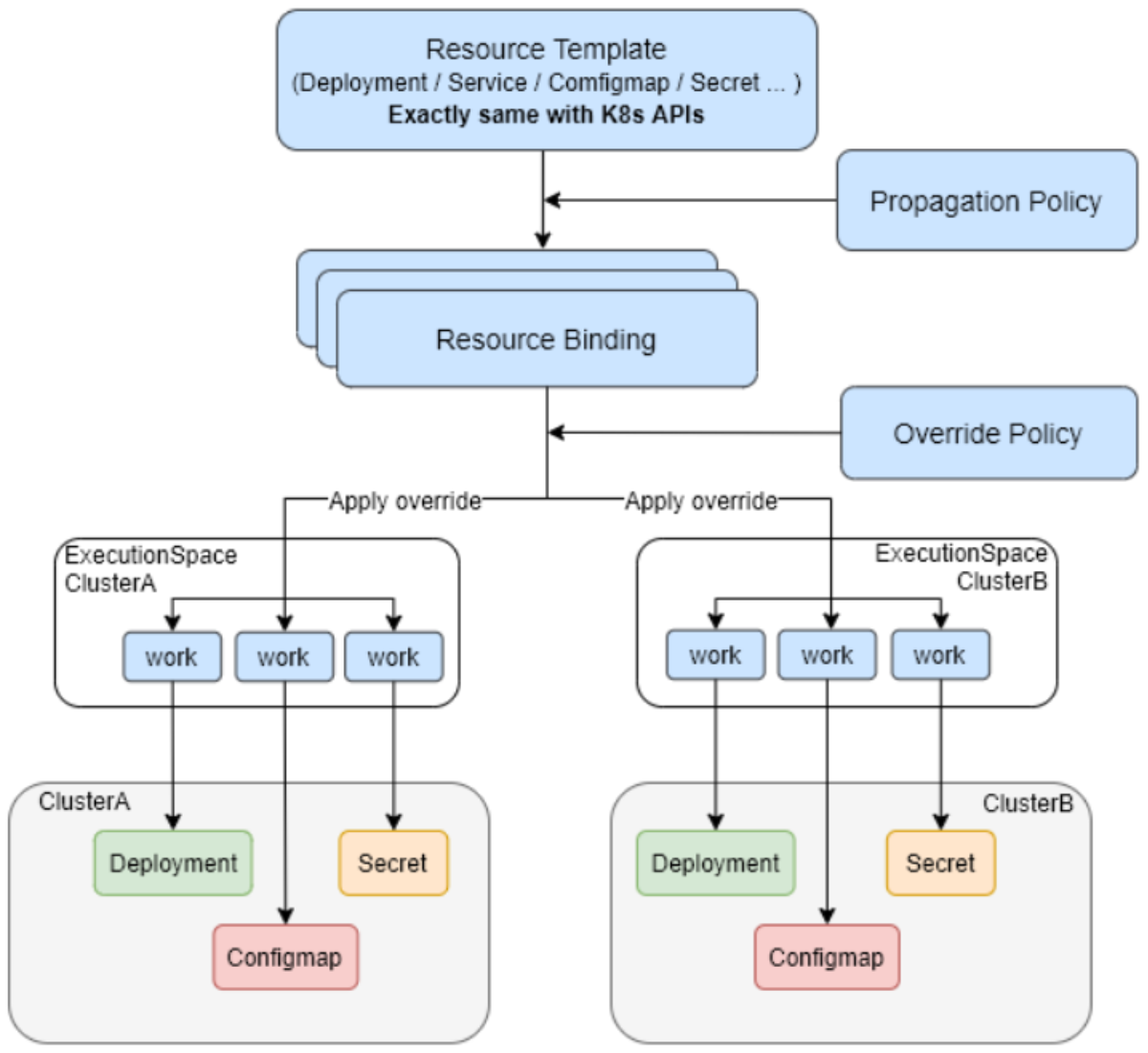
这俩得放在一起说,因为它们是Kurator的“大脑”。
先说Karmada调度引擎。它解决的是“应用该去哪个集群”的问题。比如你有北京、上海、广州三个集群,当你发一个Deployment时,Karmada调度器会根据你定义的策略(比如地域亲和性、剩余资源量),通过一系列的Filter(过滤)和Score(打分)插件,算出哪个集群最适合,然后把应用派发过去。
再看Volcano调度器工作流。如果说Karmada是宏观调控,Volcano就是微观操作,特别是针对AI训练这种批处理任务。Volcano的工作流非常细腻:它有一个Job Admission环节,然后进入队列。调度器会通过Action(比如Enqueue, Allocate, Preempt)来决定Pod的生死。特别是在资源紧张时,Volcano能玩出花来,比如Gang Scheduling(帮派调度),要么大家都别跑,要跑就得所有Pod资源都齐了一起跑,避免死锁。
3. 集群资源的拓扑结构与分级优化
这张图展示了集群资源的拓扑结构,清晰地呈现了从控制平面到机器部署的各个组件如何关联,比如Cluster、Control Plane和MachineDeployment之间的引用关系,帮助理解Kubernetes集群的构建逻辑: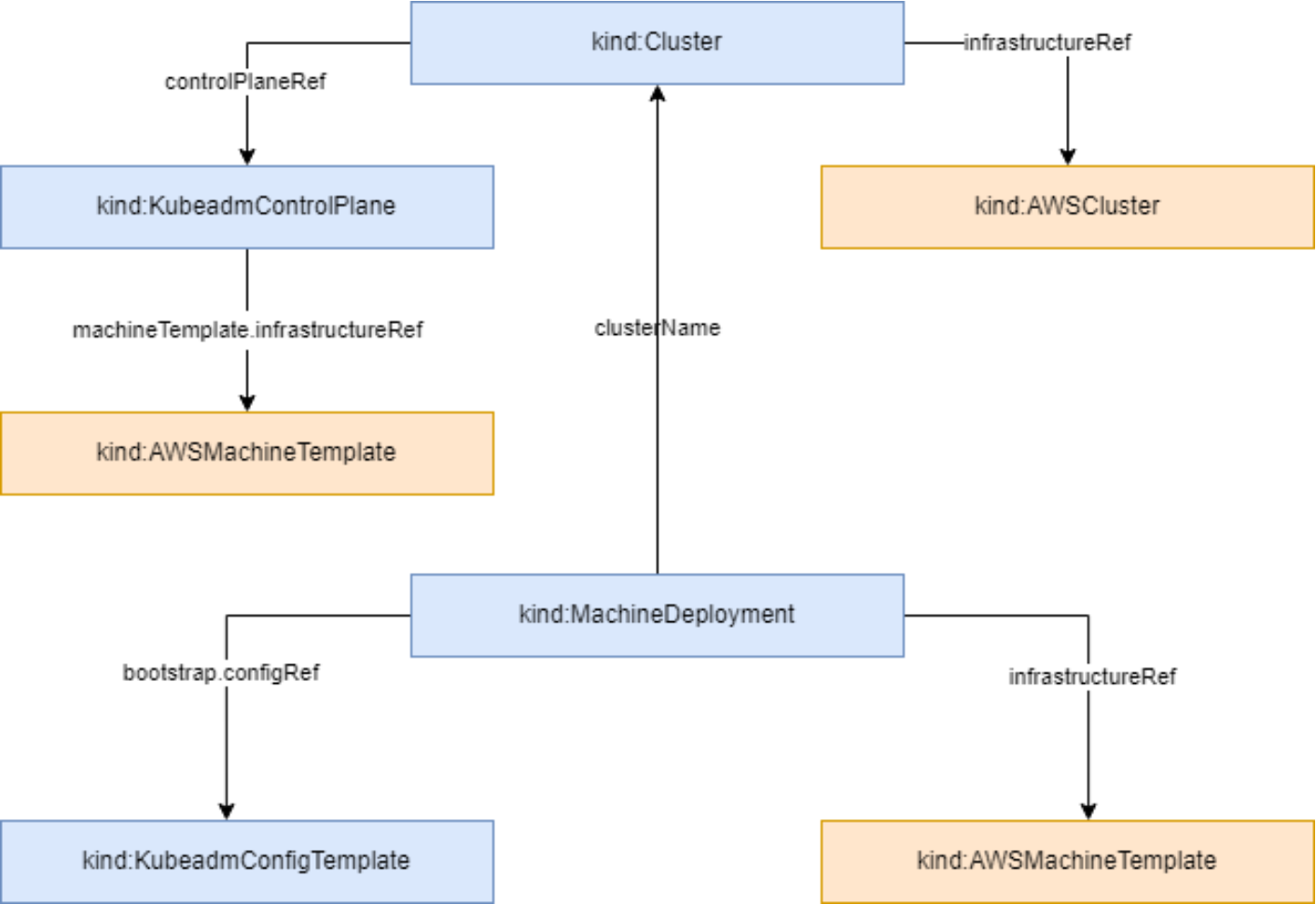
Kurator在处理资源时,不是乱放的,它有一个清晰的集群资源拓扑结构。它把基础设施抽象成了层级关系:Region(大区) -> Zone(可用区) -> Cluster(集群) -> Node(节点)。这就好比画了一张作战地图,哪里兵力(资源)多,哪里空虚,一目了然。
针对不同集群规模的分级优化策略,Kurator也有一手。对于小规模集群(比如边缘端),它会精简控制面的组件,减少内存占用;而对于超大规模(上千节点)的中心集群,它会开启并行调度和异步处理机制,甚至对ETCD进行拆分调优,保证指令下发不堵车。
三、 玩转全生命周期:从创建、纳管到无缝迁移
了解了大脑,咱们来看看Kurator的手脚。它是怎么把一个集群从无到有变出来,又是怎么把别人的孩子领回家的。
1. Kurator集群生命周期管理与Cluster Operator架构
这张图展示了Kurator Cluster Operator的整体架构,它通过监听API Server的资源变化,自动管理不同环境下的集群和机器: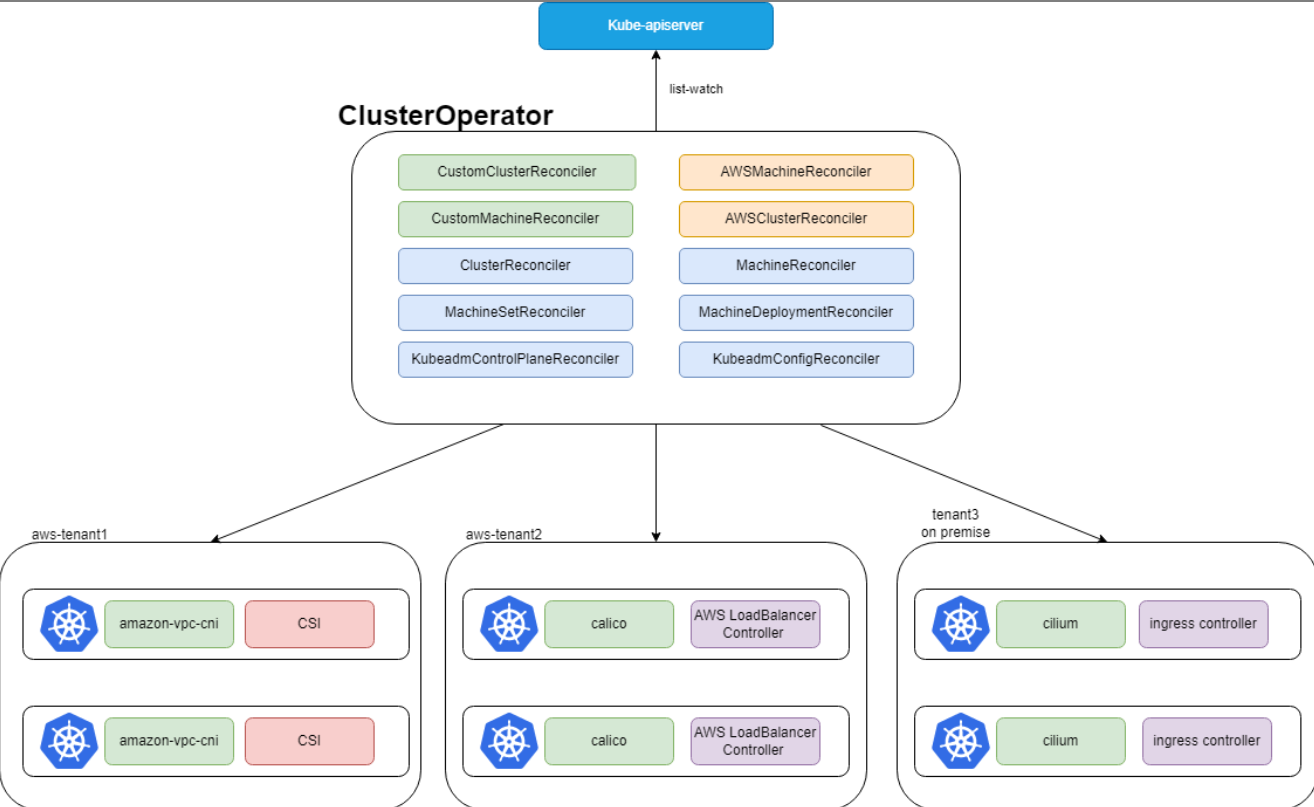
这里有个核心组件叫Kurator Cluster Operator。这兄弟就是个勤劳的搬砖工。它的整体架构是基于声明式API设计的。你写一个YAML告诉它:“我要一个AWS上的集群,3个Master,5个Worker”,Cluster Operator就会去调用底层的驱动(比如Cluster API)去申请虚拟机、配置网络、安装K8s组件。
整个Kurator集群生命周期管理覆盖了Provisioning(创建)、Upgrading(升级)、Scaling(扩缩容)和Deleting(销毁)。最爽的是升级,以前手动升级K8s简直是噩梦,现在通过Kurator,改个Version字段,它就会通过Rolling Update的方式,一台台给你换镜像,业务都不带感知的。
2. Fleet集群注册机制
这是Fleet集群注册机制的官方示意图,展示了中央控制器如何通过令牌统一纳管边缘及多区域集群: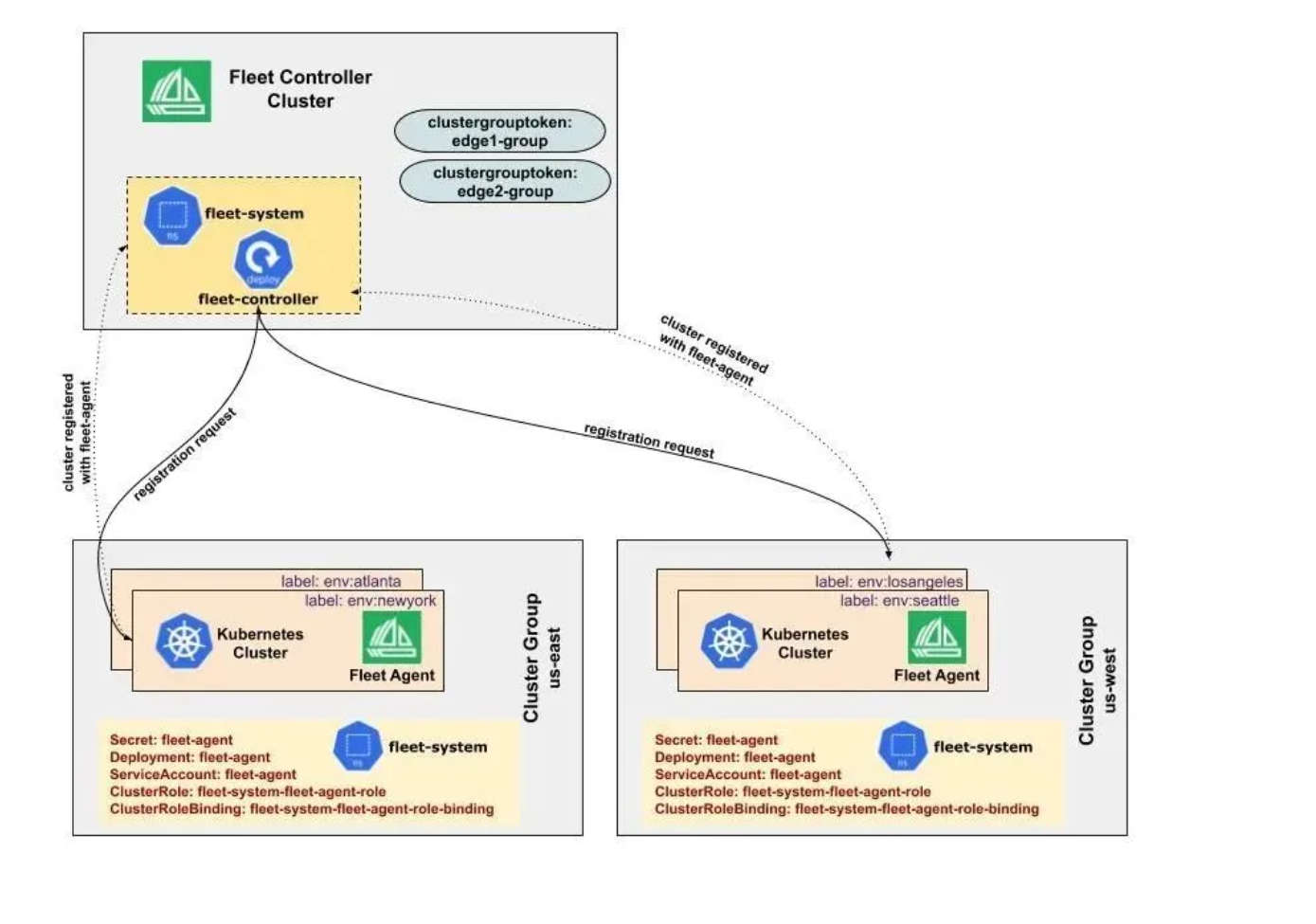
那如果是现成的集群怎么纳管进来呢?这就得靠Fleet集群注册机制了。这就像是给每个集群发个身份证。
操作流程大概是这样:你在成员集群里装一个Agent,这个Agent会主动向Kurator的控制面发起“注册请求”(Join Request)。控制面收到请求后,会生成一个Token和证书,发回给Agent。一旦握手成功,这台集群就正式编入Fleet(舰队)了,你可以像操作本地集群一样操作它。
3. Kurator的统一迁移流程
很多老哥问:“我以前用的原生K8s或者其他平台,能转到Kurator吗?” 必须能。Kurator设计了一套统一迁移流程。
这不像搬家那么累,它更像是“过户”。首先,Kurator会扫描你现有集群的资源清单(Backup);然后,通过Velero或者自定义的Migration Tool,将元数据同步到Kurator的控制面;最后,接管控制权。整个过程中,Pod是不需要重启的,流量也不会断,真正做到了平滑过渡。
下面是一段模拟配置Fleet注册的YAML,看着是不是很亲切?
apiVersion: cluster.kurator.dev/v1alpha1
kind: MemberCluster
metadata:
name: edge-cluster-shanghai-01
namespace: kurator-system
spec:
# 这里咱们定义连接方式,一般是用KubeConfig
apiEndpoint: "https://192.168.100.10:6443"
secretRef:
name: edge-cluster-sh-secret
namespace: kurator-system
# 咱们给这集群打个标签,方便后面Karmada调度
labels:
region: china-east
env: production
purpose: ai-inference
# 同步模式,咱们设为Push,让控制面推配置下去
syncMode: Push
status:
# 这里不用手写,注册成功后系统会自动回填状态
conditions: []
四、 打通云边端与DevOps:实操GitOps与边缘计算
现在的业务早就不仅限在机房了,还得往边缘跑,发布的频率也越来越高。这块Kurator整合了KubeEdge和GitOps,简直是提效神器。
1. KubeEdge架构的工作流程
这是KubeEdge架构的工作流程参考图,展示了云端控制器如何通过CloudHub与边缘节点通信,实现应用下发和设备管理的完整协同链路: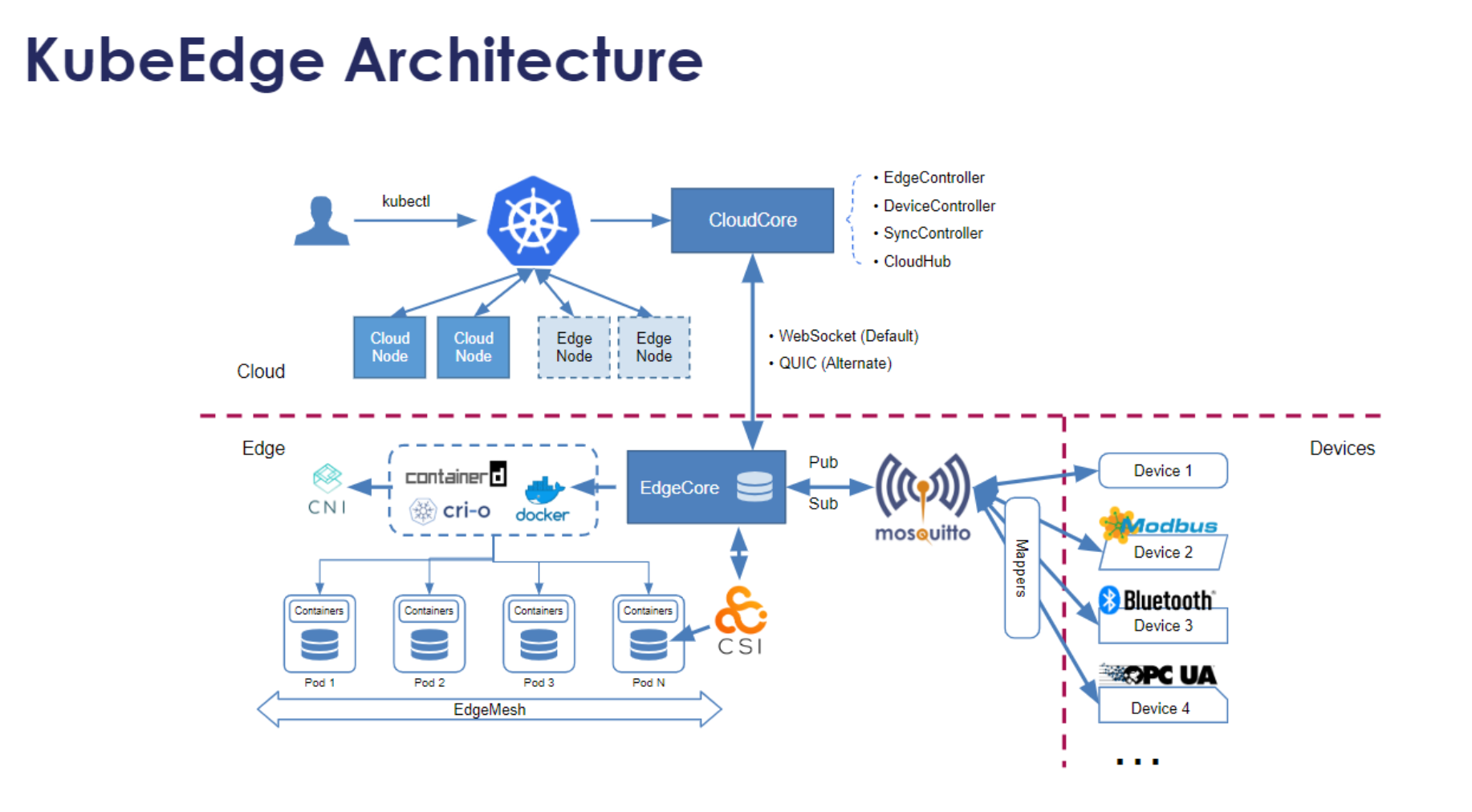
如果你的业务涉及IoT或者边缘计算,KubeEdge必不可少。它的工作流程非常经典,解决了“云边网络不稳定”的痛点。
在云端,有一个CloudCore组件,它通过WebSocket监听K8s API Server的变化。当你在云端创建一个Pod并指定调度到边缘节点时,CloudCore会拦截这个请求,把它打包成消息,通过WebSocket通道发给边缘端的EdgeCore。
EdgeCore收到消息后,不会直接把Pod拉起来,而是先存在本地的SQLite数据库里(这就叫离线自治)。就算这时候网断了,EdgeCore也能根据本地记录维持业务运行。等网好了,它再把边缘设备的状态(比如温度、湿度数据)同步回云端。
2. GitOps流水线的操作流程
这是GitOps流水线的操作流程图,展示了从代码变更、镜像构建到配置更新与生产环境自动部署的完整工作流。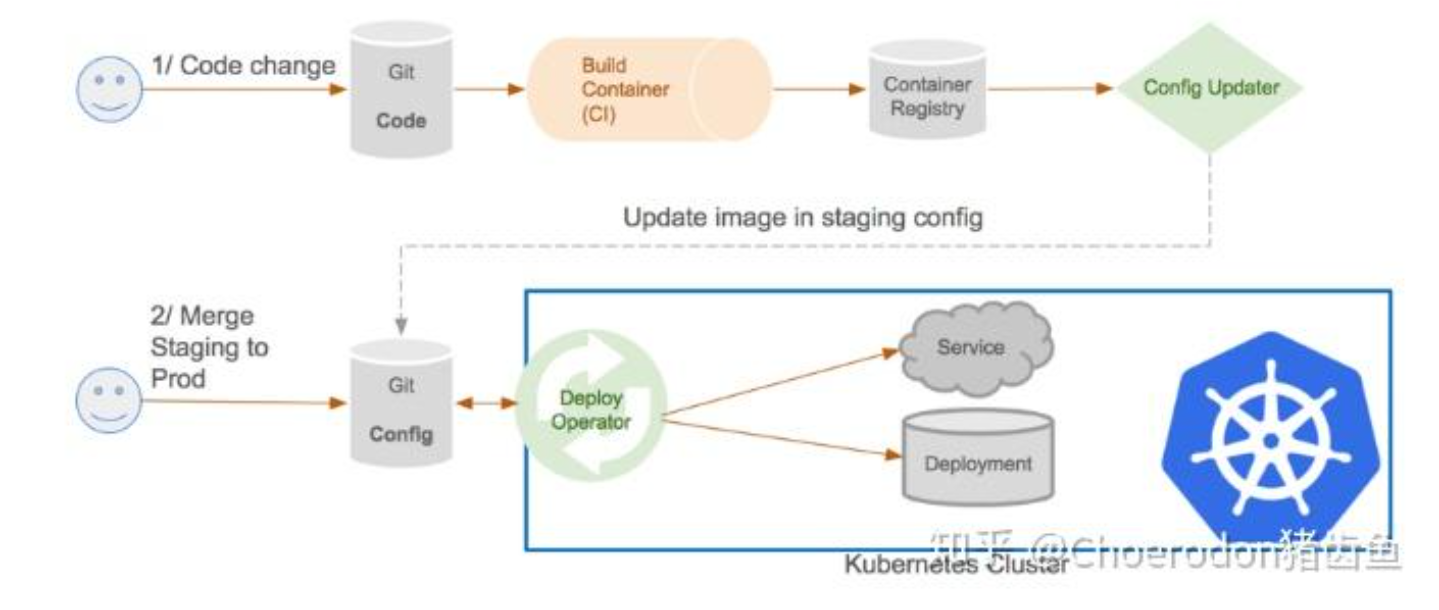
在这个环节,Kurator推崇的是“一切皆代码”。GitOps流水线的操作流程是这样的:
开发人员写完代码,同时也更新了K8s的部署文件(Manifests),然后提交到Git仓库(比如GitCode)。这时候,Kurator里集成的ArgoCD或者Flux组件检测到了Git仓库的变化。
它会对比集群里的实际状态和Git里的期望状态。如果不一致(比如镜像版本变了),它就自动拉取新配置,应用到集群里。这中间不需要人工SSH上去敲kubectl apply,全程审计可追溯。
3. 配置蓝绿发布实战
为了让发布更稳,咱们通常会配置蓝绿发布。在Kurator里,这可以通过集成的Flagger或Istio能力来实现。
简单说,就是新版本(绿)上来后,不急着切所有流量。先切5%,看看有没有报错;没问题切20%,再没问题切50%,最后全切过去(变成蓝)。一旦中间出现500错误率飙升,立马回滚。
这有个手搓的流量切分配置,大伙儿感受一下:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: my-app-route
spec:
hosts:
- my-app.prod.svc.cluster.local
http:
- route:
# 这是旧版本(蓝),暂时还是主力
- destination:
host: my-app.prod.svc.cluster.local
subset: v1
weight: 90
# 这是新版本(绿),咱们先放点血(流量)进去测测
- destination:
host: my-app.prod.svc.cluster.local
subset: v2
weight: 10
timeout: 2s
retries:
attempts: 3
perTryTimeout: 2s
五、 价值与未来:Kurator到底想下一盘什么棋?
说了这么多技术细节,最后咱们把视角拉高点,看看Kurator这盘大棋。
1. Kurator核心价值的全景路线
Kurator的野心不小,它的核心价值全景路线分三步走。第一阶段是“统一纳管”,就是现在做的,把各种云、边缘都连起来;第二阶段是“应用治理”,提供Service Mesh、Serverless等高阶能力,让应用跑得更爽;第三阶段是“智能运维”,利用AI技术做故障自愈、成本优化。
现在的Kurator正处在二三阶段的过渡期。它不仅仅是一个工具,更像是一个标准化的云原生操作系统。
2. 实战中的小技巧代码
最后,给大家来个彩蛋。在实际运维中,我们经常需要快速查看所有集群的健康状态,手敲命令太累。这是我自己常用的一个小脚本,虽然土了点,但实用性满分。
#!/bin/bash
# 一个简单的巡检脚本,手搓的,将就看
# 获取所有成员集群的列表
CLUSTERS=$(kubectl get memberclusters -n kurator-system -o jsonpath='{.items[*].metadata.name}')
echo "====== Kurator 集群健康巡检开始 ======"
echo "检查时间: $(date)"
for cluster in $CLUSTERS; do
echo "----------------------------------------"
echo "正在检查集群: $cluster ..."
# 检查连接状态
STATUS=$(kubectl get membercluster $cluster -n kurator-system -o jsonpath='{.status.conditions[?(@.type=="Ready")].status}')
if [ "$STATUS" == "True" ]; then
echo "✅ 状态: 在线 (Ready)"
# 顺便看看节点数,假装在做深度分析
NODE_COUNT=$(kubectl --kubeconfig=$cluster-config get nodes --no-headers 2>/dev/null | wc -l)
echo "📊 节点数量: $NODE_COUNT"
else
echo "❌ 状态: 异常! 请立即排查!"
fi
done
echo "========================================"
echo "巡检结束,该干饭了兄弟们!"
总结
Kurator这东西,确实是帮我们把复杂的云原生组件给“Kurated”(策展/整理)了一遍。从GitOps的一键发布,到KubeEdge的云边协同,再到Volcano的精细调度,它给咱们提供了一套开箱即用的最佳实践。
希望大家看完这篇文章,能去亲自跑一下,哪怕炸了也没事,重装呗,谁还不是从炸集群过来的呢?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 30
30 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)