Kurator 搞定多集群跟云边协同的那些野路子,这一套打法咱们必须拿下!
Kurator 搞定多集群跟云边协同的那些野路子,这一套打法咱们必须拿下!
嘿,兄弟们,今儿咱们不开那种照本宣科的会,把门关严实了,咱就纯粹聊聊技术,聊聊那些在机房里熬夜熬出来的真东西。
说实话,Kurator 这玩意儿,刚出来那会儿我也稍微持点怀疑态度,寻思着“这不又是个造轮子的货么”。但后来上手一摸,嘿,真香!它不像咱以前东拼西凑那一堆散件儿,又是 KubeEdge 又是 Volcano 又是 Karmada 的,整得人头大。Kurator 给我的感觉就像是个经验老道的“大管家”,它不是简单的把这些组件捆一块儿,而是把多集群编排、云边协同、AI 任务调度这些硬骨头给你炖烂了,喂到嘴边。它解决的是咱运维兄弟最头疼的“碎片化”问题,让你在管十几个集群、几百个边缘节点的时候,不仅不慌,还能腾出手来喝口茶。今儿我就把这几年摸爬滚打总结出来的“野路子”毫无保留地掏给大伙儿。
一、 别整虚的,先把家伙事儿抄起来:环境搭建与云边基石
咱干技术的,不动手那都是耍流氓。要玩转 Kurator,第一步得先把环境支棱起来。我知道大伙儿平时忙,没空看那些又臭又长的官方文档,咱直接来干货。
1.1 极速起步:把源码撸下来
咱现在的环境大多是 Linux,不管是 Centos 还是 Ubuntu,套路都差不多。这第一步,咱得把 Kurator 的源码搞到手,这可是咱的“军火库”。别去瞎找那些过期的包,直接去 GitCode 拉最新的,热乎的。
当然,感兴趣的同学,可以将项目下载下来体验一下:
然后我们找到Kurator的https地址,通过git将其拉取到本地: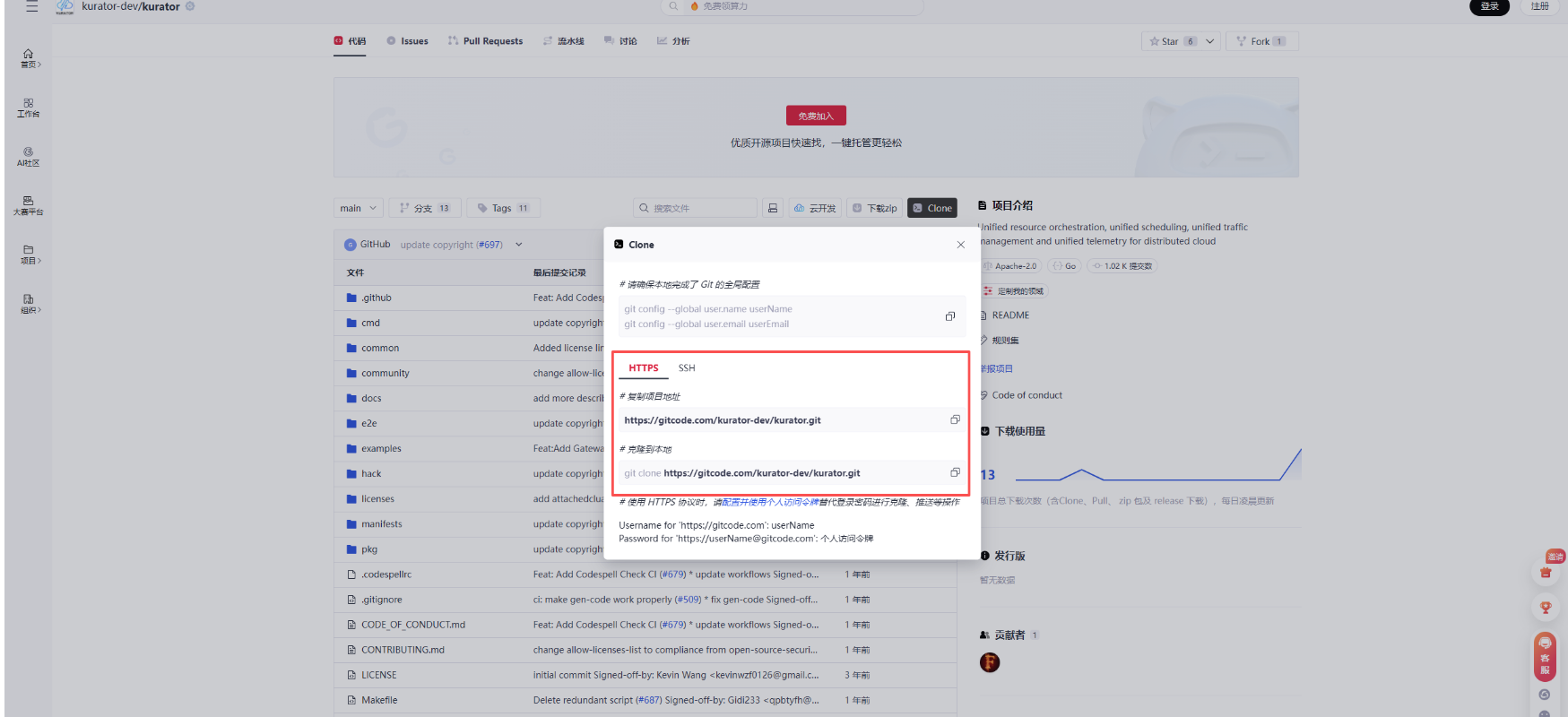
分别执行下面两条命令:
# 复制项目地址
https://gitcode.com/kurator-dev/kurator.git
# 克隆到本地
git clone https://gitcode.com/kurator-dev/kurator.git
实际克隆项目演示效果可以看到如下图: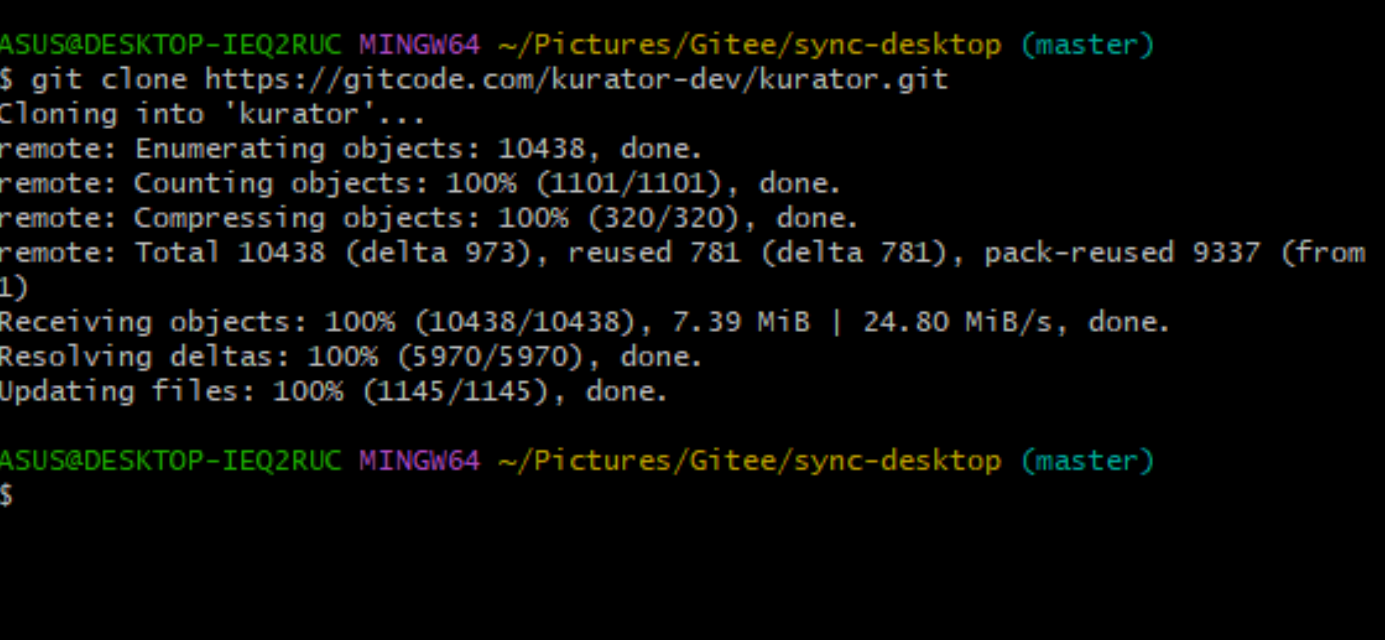
如下展示的便是完整的项目源码啦:
下载完成后,我们便可以进行项目部署及实战演练了。
这一步看似简单,但很多兄弟死在网络上,或者拉错了分支。记住了,源码在手,心里才有底,后面遇到啥诡异配置,直接 grep 源码有时候比 Google 都好使。
1.2 云边协同那点事儿:KubeEdge 核心组件与隧道机制剖析
这是KubeEdge云边协同架构的核心组件图,展示了云端控制平面、消息通道与边缘节点的全链路组件及交互方式: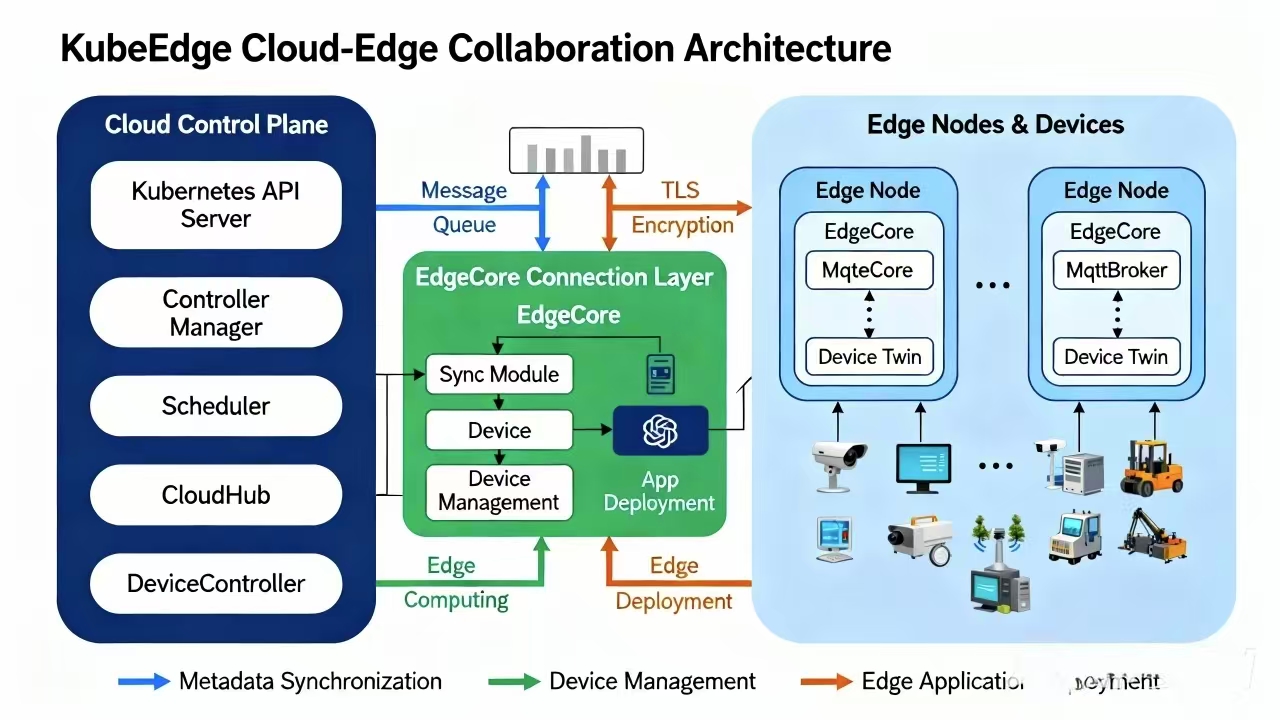
环境弄好了,咱先聊聊云边协同这块硬骨头。咱都知道 KubeEdge 是好东西,但为啥总有人掉坑里?关键就在这 CloudCore 和 EdgeCore 的爱恨情仇上。
CloudCore 就像是咱的大脑,蹲在云端(K8s Master 节点附近),负责发号施令;EdgeCore 就是咱的手脚,散落在工厂、车间、路灯杆子上。这中间隔着十万八千里,网络环境那是相当恶劣。这时候,Tunnel(隧道机制) 就显得贼关键了。
我之前做过一个智慧园区的项目,边缘节点都在内网后面,也就是大伙儿常说的 NAT 环境下。CloudCore 想主动找 EdgeCore?门儿都没有!KubeEdge 的 Tunnel 机制就是为了干穿这层 NAT。它利用 WebSocket 或者 QUIC 建立长连接,一旦这路通了,云端下发的指令(比如 Pod 创建)和边缘上报的状态(比如设备温度),就能在这条隧道里双向狂奔。
在 Kurator 里配置这个,你不需要手动去搞证书、搞配置文件的 copy,它帮你封装了一层。你只需要关心你的业务逻辑。
1.3 实战场景:当 AI 算力下沉到边缘
聊个具体的业务场景,方便大家理解。现在都在搞 AI,但那模型推理要是每次都回传到云端,光那个延迟就能让客户骂娘,更别提视频流那昂贵的带宽费了。
这时候,云边协同的价值就出来了。我们在云端用 GPU 集群(这就涉及到后面要说的 Volcano 了)把模型训练好,然后通过 Kurator 的分发机制,把轻量化的模型推送到边缘的 EdgeCore 节点上。
边缘节点接个摄像头,直接本地跑推理,识别出有人没戴安全帽,立马报警。这中间,云端只负责模型迭代和宏观管控,边缘负责实时计算。这才是云边协同的正确打开方式,省钱、快、稳!
二、 舰队管理(Fleet)里的那些“暗坑”与“神技”
集群多了,就成了“舰队”。Fleet 这东西,用好了是航母编队,用不好就是连环撞船。
2.1 这里的黎明静悄悄:命名空间相同性(Namespace Sameness)
这是Fleet舰队中命名空间相同性的示意图,展示了多集群间命名空间的对齐逻辑与统一编排映射关系: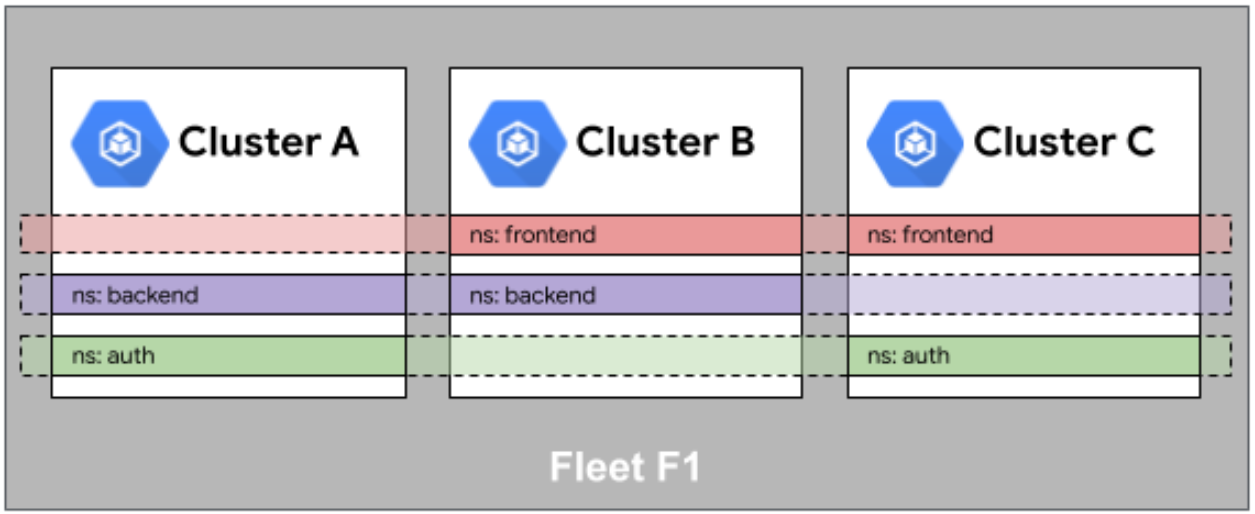
兄弟们,听我一句劝,多集群管理里,Namespace Sameness 这个概念一定要刻在脑子里。啥意思呢?就是你在集群 A 里的 prod 命名空间,和集群 B 里的 prod 命名空间,在逻辑上必须被视为同一个“管理域”。
实战中这意味着什么?意味着你的 Service、Secret、ConfigMap 在不同集群的同名 Namespace 下,应该有一致的语义。Kurator 在整合 Fleet 时,强依赖这个逻辑。
比如说,我有一套微服务,分片部署在三个集群里。如果我没遵循这个原则,A 集群叫 production,B 集群叫 prod-v1,那做跨集群服务发现的时候,你就哭吧,路由规则能写到你手断。Kurator 利用这一点,能帮你自动打通跨集群的服务网格,前提是你得守规矩,把名字起得整齐划一。
2.2 身份映射(Identity Mapping):外面的世界很精彩,也很危险
这是Fleet访问队列外部资源的身份映射示意图,展示了跨集群服务与云平台服务账户的统一身份关联机制: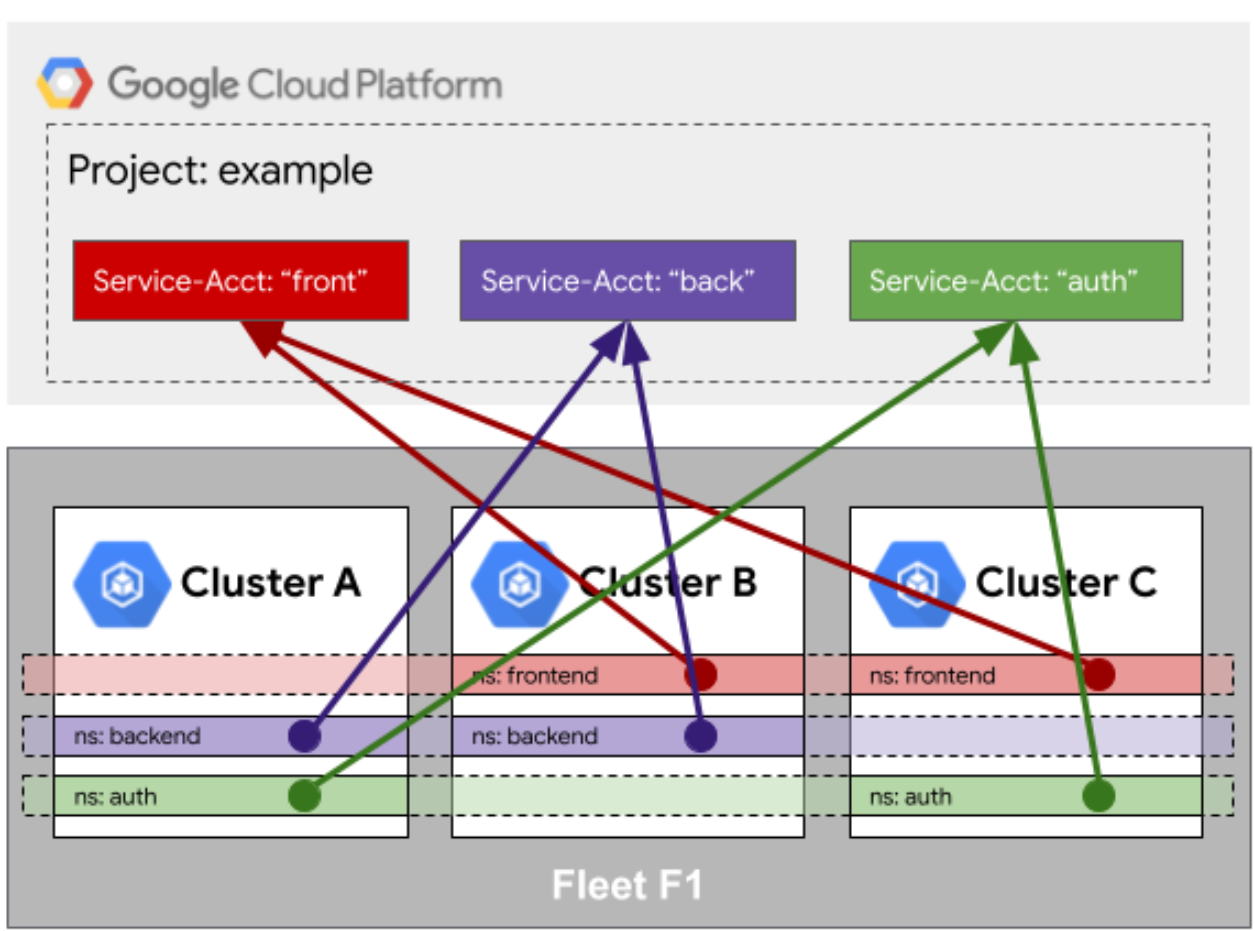
Fleet 有个很骚的功能,就是让集群里的 Pod 去访问集群外部的资源(比如云厂商的 S3、RDS),但又不想把 AccessKey 写死在代码里。这时候就要用到 Identity Mapping。
简单说,就是把 K8s 里的 ServiceAccount 映射成云厂商 IAM 的角色。在 Kurator 的配置体系里,这块被简化了不少。
场景是这样的:你的应用在 Fleet 管理的 10 个集群里跑,都要去读同一个 S3 桶。你不用去给每个集群发密钥。你只需要配置好映射规则,当 Pod 启动时,它拿着自己的 ServiceAccount Token 去找云厂商换临时的访问凭证。
这招儿“空手套白狼”既安全又方便,特别是在轮转密钥的时候,应用层完全无感。
2.3 Kurator 这一套 CI/CD 流水线,真香
这张图讲的是怎么用Kurator来搭建CI/CD流水线,从配置Pipeline、设置网关、绑定GitHub Webhook,再到创建各种密钥,一步步教你把自动化构建和部署跑起来,整个流程清晰又实用: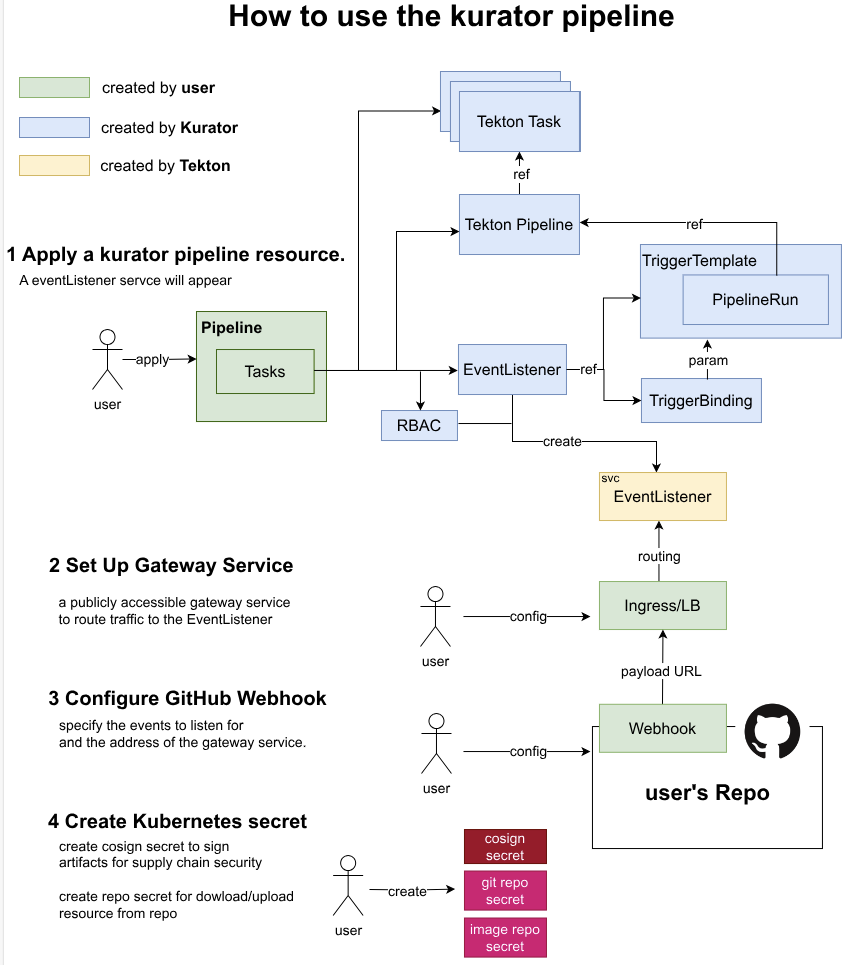
咱们把 Fleet 和 GitOps 结合起来,那 CI/CD 就能玩出花来。以前我们部署,是 Jenkins 脚本满天飞,现在用了 Kurator,思路变了。
我们在 Git 仓库里定义好了一切:应用的代码、Helm Chart 的配置、以及 Kurator 的 ApplicationCR。
当开发老弟提交代码合并到 main 分支,CI 跑完测试构建镜像。这时候,CD 环节不是去连集群执行 kubectl apply,而是去修改 Git 仓库里的 Image Tag。
Kurator 里的组件监测到 Git 变了,立马触发同步。这中间还能插入审批流、甚至结合 Tekton 做更复杂的流水线编排。咱们手撸一套这玩意儿,最大的感受就是:睡得踏实。因为所有变更都有版本记录,回滚就是一秒钟的事儿——git revert 完事。
三、 流量为王:路由、金丝雀与 GitOps 的落地姿势
业务跑起来了,流量怎么切?版本怎么发?这一块 Kurator 整合了 Istio 和 Flagger 等生态,给咱们提供了不少便利。
3.1 流量路由与金丝雀发布:稳字当头
这是Kurator的流量路由参考图,展示了其如何通过入口网关和服务网格技术,在金丝雀发布中实现精确的流量分割与路由控制: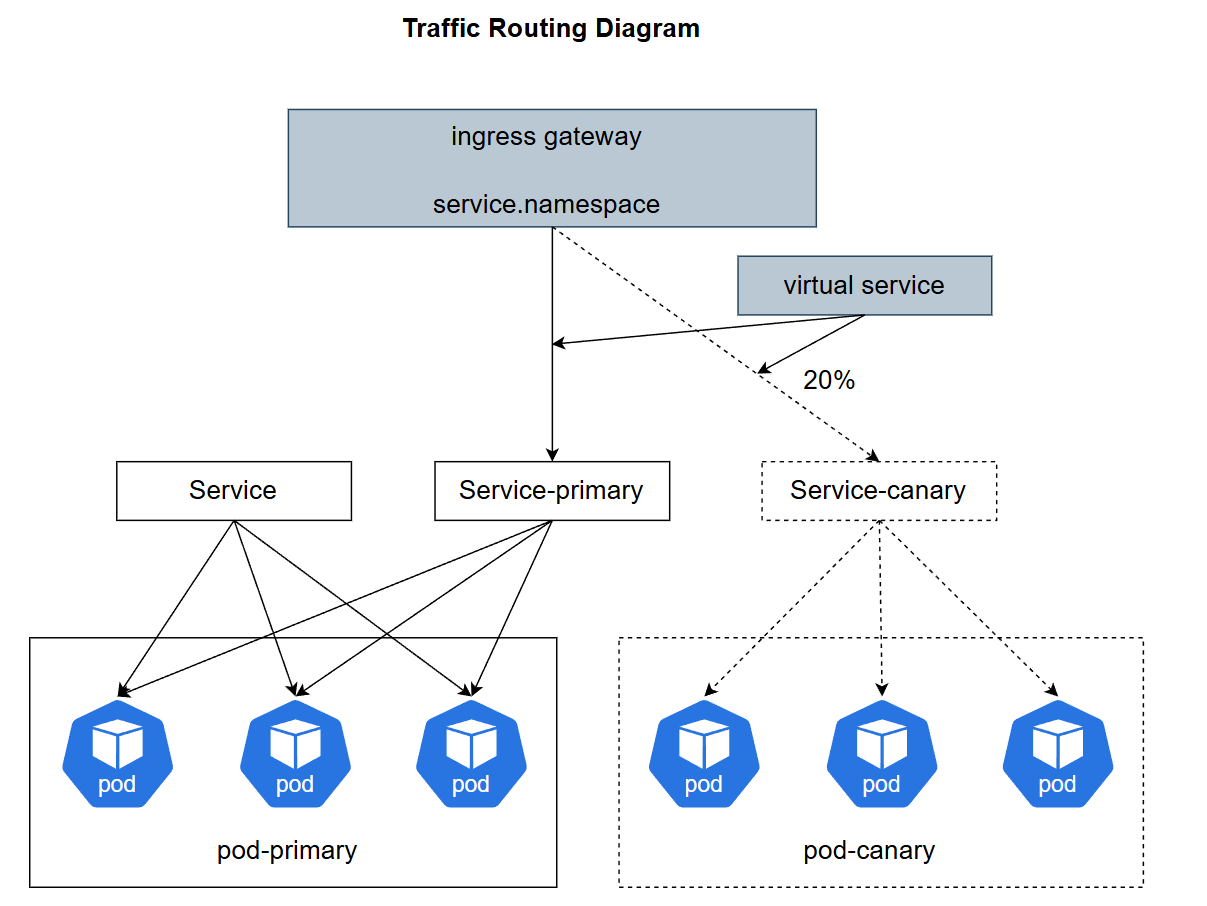
别上来就全量发布,那是赌博。咱们要的是“润物细无声”。
实战中,我们利用 Kurator 配置金丝雀发布(Canary)。新版本 V2 上线,先不给流量,或者只给内部测试账号的流量(基于 Header 路由)。
确认没崩,日志正常,开始切 5% 的真实流量。Kurator 会自动监控 Prometheus 里的指标(比如 HTTP 500 错误率、延迟 P99)。如果指标健康,它自动加码到 10%、20%…直到 100%。
要是中间出了岔子,比如延迟飙升,Kurator 直接切断 V2 流量,回退到 V1。这一套自动化操作,比咱们半夜盯着屏幕手动改 Nginx 配置靠谱多了。
这里给大伙儿看一段我常用的金丝雀发布配置片段,注意看注释,全是血泪经验:
apiVersion: flagger.app/v1beta1
kind: Canary
metadata:
name: backend-service
namespace: prod
spec:
# 目标引用,指向咱们的 Deployment
targetRef:
apiVersion: apps/v1
kind: Deployment
name: backend-v2
# 进度条配置,别搞太快,步子大了容易扯着蛋
analysis:
interval: 1m # 每分钟检查一次
threshold: 5 # 错 5 次就回滚,别犹豫
maxWeight: 50 # 金丝雀最大吃到 50% 流量,咱就稳一手
stepWeight: 5 # 每次加 5%,慢慢来
# 这里的指标是关键,没这些监控数据,这就是瞎搞
metrics:
- name: request-success-rate
thresholdRange:
min: 99 # 成功率低于 99% 咱们就得报警了
- name: request-duration
thresholdRange:
max: 500 # 延迟超过 500ms 就算慢
# 这里还能配 webhooks,跑个负载测试啥的
3.2 GitOps 的落地:FluxCD 与 Helm 的双人舞
咱们聊聊 GitOps 的具体落地。Kurator 主要是集成了 FluxCD。在多集群环境下,FluxCD 的 Helm Controller 简直是神器。
以前用 Helm,得自己敲 helm install。现在呢,我们在 Git 仓库里放一个 HelmRelease 的 CRD 文件。
这个文件告诉 Flux:“嘿,去那个 Chart 仓库拉最新的 nginx Chart,用这一套 values.yaml 配置,给我部署到 web 这个 Namespace 去。”
更绝的是,配合 Kurator 的多集群分发能力,我可以在一个管理集群上定义这个 HelmRelease,然后通过 Label Selector 把它分发到几十个边缘集群。这就叫“运筹帷幄之中,决胜千里之外”。所有的配置漂移(Configuration Drift),Flux 都会帮你自动修正,强制集群状态和 Git 保持一致。
四、 算力调度与排查心经:Volcano 与网络诊断
最后这部分,咱们聊点硬核的:资源怎么分,网络不通怎么查。
4.1 Volcano 深度解剖:Job、Queue 与 PodGroup 的三角恋
这是Volcano中Job、Queue与PodGroup关系的参考图,直观展示了任务队列如何管理多个PodGroup及其Pod的调度分组: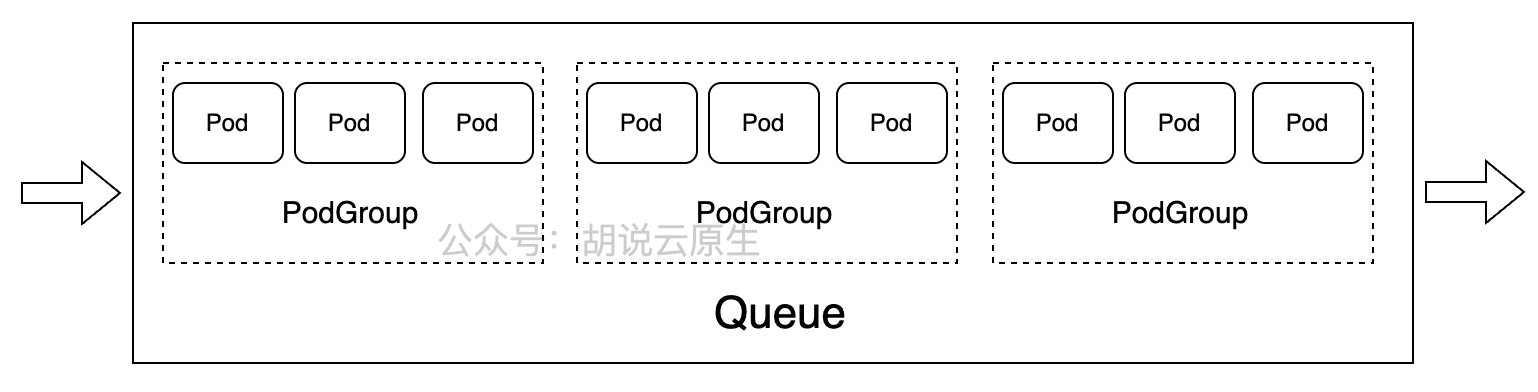
做大数据和 AI 的兄弟对 Volcano 肯定不陌生。K8s 原生的调度器对于批处理任务来说,有点太“单纯”了,它只管一个个 Pod 塞进去,不管它们是不是一伙的。
Volcano 引入了 Queue(队列)、Job(作业) 和 PodGroup 的概念。
- Queue:这是分蛋糕的刀。你可以给不同的部门(研发部、测试部)分不同的 Queue,设定好权重(Weight)和配额(Capability)。研发部的任务多了,可以借用测试部的空闲资源,这叫资源借用(DRF 算法)。
- Job:这是具体的活儿。
- PodGroup:这是 Job 的灵魂。一个 TensorFlow 的训练任务,往往需要 10 个 Worker 节点同时跑起来才能干活(Gang Scheduling)。如果资源只够启动 5 个,原生调度器可能就把这 5 个起起来傻等,占着茅坑不拉屎。Volcano 看到了 PodGroup 里的
minMember是 10,资源不够?那这 5 个也别起了,排队去!等资源够了 10 个一起上。
这就是为了避免死锁和资源浪费。
下面这段 Volcano 的 Job 配置,是我为了跑一个 MPI 任务特意调优过的:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: mpi-job-demo
spec:
minAvailable: 3 # 兄弟,没有 3 个 Pod 咱就不开工,省得浪费感情
schedulerName: volcano
queue: research-queue # 挂在研发部的账上
plugins:
ssh: [] # MPI 需要 SSH 免密,Volcano 帮你搞定,贴心吧
svc: []
tasks:
- replicas: 1
name: master
template:
spec:
containers:
- command:
- /bin/bash
- -c
- "MPI_ARGS... 跑起来!"
image: mpi-benchmark:latest
name: mpi-master
resources:
requests:
cpu: "2" # 给主节点多点 CPU,它得指挥
- replicas: 2
name: worker
template:
spec:
containers:
- command:
- /bin/bash
- -c
- "等待召唤..."
image: mpi-benchmark:latest
name: mpi-worker
resources:
requests:
cpu: "1"
4.2 万能网络连通性排查思路:老中医把脉
最后,送大家一套我珍藏多年的网络排查心法。多集群、云边协同,网络是最容易出幺蛾子的。
当有人喊“服务调不通了”,别慌,按这个顺序来:
- 链路拆解:先画图,流量是从哪到哪?是 Pod 到 Pod,还是 Ingress 到 Pod,还是跨集群?
- DNS 查验:进到 Pod 里(
kubectl exec),nslookup一下目标 Service 的名字。80% 的问题都是 DNS 解析失败。 - Service IP 通不通:Ping 是没用的(ClusterIP 很多时候禁 Ping),直接
telnet或者nc -v <ClusterIP> <Port>。如果不通,查 kube-proxy,查 IPVS 规则。 - Pod IP 通不通:如果 Service IP 都不通,直接测目标 Pod IP。通了,说明 Service 转发有问题;不通,说明 CNI 网络插件炸了(比如 Flannel/Calico 的 BGP 没建好)。
- 跨集群/云边特例:
- 如果是云边,去 EdgeCore 节点查
edge-tunnel的日志,看 WebSocket 连没连上。 - 如果是跨集群,查网关(Gateway)的路由表,查 Submariner 或其他隧道组件的状态。
- 如果是云边,去 EdgeCore 节点查
这一套下来,基本病灶就能定位得七七八八了。
结语
兄弟们,Kurator 这套组合拳,打好了是真能提升战斗力。它把 Fleet 的统筹、KubeEdge 的延伸、Volcano 的算力调度、FluxCD 的自动化全串起来了。技术这东西,没有什么高大上的秘密,无非就是多踩坑、多总结、多交流。希望今儿这些实战经验,能帮大家在生产环境里少掉几根头发。回头有机会,咱们再细聊聊 Service Mesh 在这架构里的玩法,那又是另一番天地了!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)