【前瞻创想】Kurator云原生平台实战:构建分布式多云基础设施,实现统一资源编排、调度、流量管理与监控的完整指南
【前瞻创想】Kurator云原生平台实战:构建分布式多云基础设施,实现统一资源编排、调度、流量管理与监控的完整指南
【前瞻创想】Kurator云原生平台实战:构建分布式多云基础设施,实现统一资源编排、调度、流量管理与监控的完整指南
摘要
本文深入探讨Kurator这一开源分布式云原生平台,从理论到实践全面解析其核心架构与功能模块。Kurator站在Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada等流行云原生技术的肩膀上,为企业提供统一的多云、边缘云管理解决方案。文章将系统介绍Kurator框架设计,详细演示环境搭建过程,并深度剖析Fleet多集群管理、Karmada跨集群调度、KubeEdge边缘集成、Volcano批量计算等关键功能的实践应用。通过真实场景的代码示例和架构分析,帮助读者掌握构建企业级分布式云原生基础设施的核心技能,为数字化转型提供技术支撑。
一、Kurator云原生平台架构解析
分布式云原生架构参考图: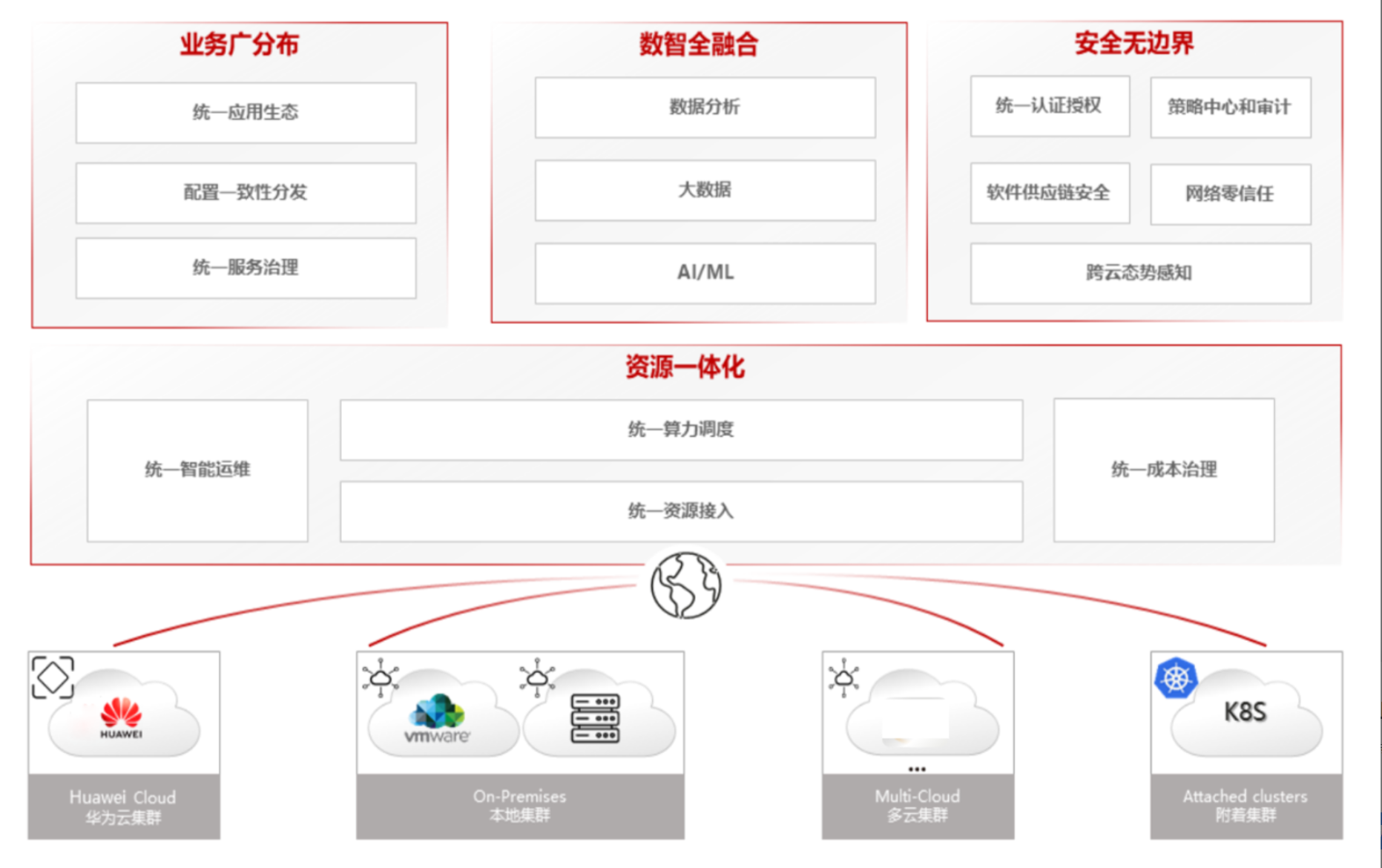
1.1 Kurator的核心定位与价值
Kurator是一个开源的分布式云原生平台,其核心定位是帮助企业构建自己的分布式云原生基础设施,加速企业数字化转型进程。在当今多云、混合云、边缘计算快速发展的背景下,企业面临着资源分散、管理复杂、应用交付效率低下等诸多挑战。Kurator通过整合多个优秀的云原生开源项目,提供了一站式的解决方案,实现了从基础设施到应用层的统一管理。
Kurator的独特价值在于它不仅仅是一个简单的工具集合,而是一个经过深度整合的平台。它解决了企业在多云环境下面临的统一资源编排、统一调度、统一流量管理、统一监控等关键问题,降低了技术复杂度,提升了运维效率。特别是在边缘计算场景下,Kurator能够实现云-边-端的协同工作,为物联网、智能制造、智慧城市等场景提供强大的技术支撑。
1.2 Kurator的技术生态整合
Kurator的技术生态参考图:
Kurator站在众多优秀云原生开源项目的肩膀上,构建了一个完整的技术生态。其核心组件包括:
- Kubernetes:作为容器编排的基础,提供容器化应用的部署、扩展和管理能力
- Istio:提供服务网格能力,实现微服务间的流量管理、安全策略和可观测性
- Prometheus:提供全面的监控和告警能力,覆盖基础设施、应用和服务层面
- FluxCD:实现GitOps工作流,将应用部署与配置管理通过Git仓库进行版本控制
- KubeEdge:将Kubernetes原生能力延伸到边缘,支持边缘节点管理和边缘应用部署
- Volcano:提供批处理和高性能计算场景的高级调度能力
- Karmada:实现多集群应用管理,支持跨集群的资源调度和故障转移
- Kyverno:提供策略引擎,确保多集群环境中策略的一致性
这些组件并非简单拼凑,而是通过Kurator的统一架构进行了深度整合,实现了1+1>2的效果。例如,Karmada与Kubernetes的结合,使得跨集群调度成为可能;KubeEdge与Kubernetes的集成,让边缘节点可以像普通节点一样被管理;Volcano的调度能力与Kubernetes原生调度器的配合,能够满足不同场景的调度需求。
1.3 Kurator平台架构设计
kurator架构参考图: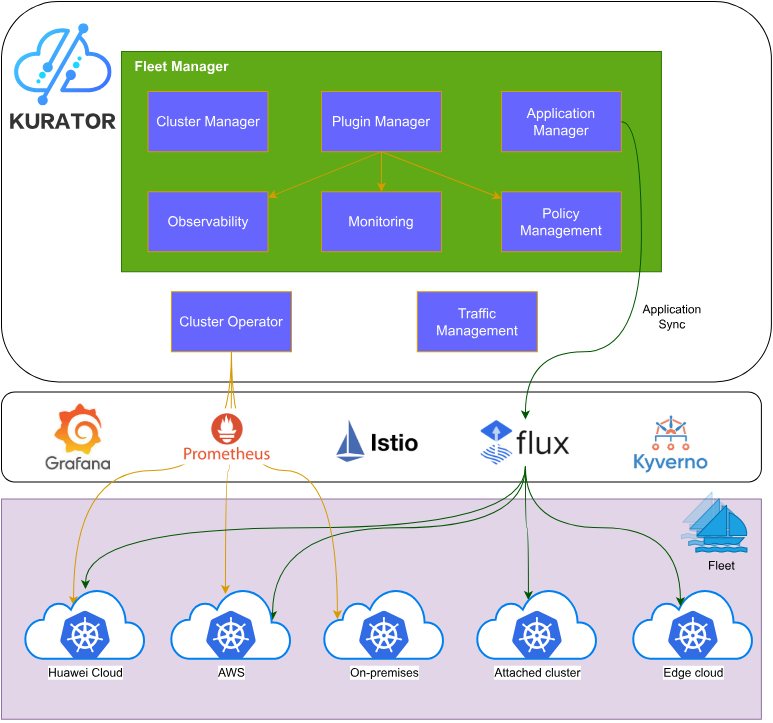
Kurator的架构设计遵循了模块化、可扩展的原则,整体架构可分为以下几个层次:
- 基础设施层:支持公有云、私有云、边缘节点等多种基础设施,通过Infrastructure-as-Code的方式进行声明式管理
- 集群管理层:提供集群的生命周期管理,包括集群创建、配置、升级、销毁等操作
- 资源管理层:实现多集群资源的统一管理,包括计算、存储、网络等资源的抽象和调度
- 应用管理层:提供应用的跨集群部署、流量管理、策略管理等功能
- 可观测性层:聚合多集群的监控、日志、追踪数据,提供统一的可观测性视图
- API与集成层:提供统一的API接口,支持与CI/CD工具、DevOps平台等外部系统的集成
这种分层架构设计使得Kurator具有很好的灵活性和可扩展性,可以根据实际需求选择性地启用或扩展特定功能模块。同时,Kurator采用了声明式API设计,用户可以通过YAML文件定义期望状态,系统会自动将实际状态收敛到期望状态,大大简化了运维复杂度。
二、Kurator环境搭建与安装实践
2.1 环境准备与依赖安装
在开始安装Kurator之前,需要准备合适的环境和依赖。Kurator支持在Linux系统上运行,推荐使用Ubuntu 20.04或CentOS 7/8作为基础操作系统。以下是环境准备的详细步骤:
# 1. 更新系统包
sudo apt-get update && sudo apt-get upgrade -y
# 2. 安装基础依赖
sudo apt-get install -y curl wget git jq make
# 3. 安装Docker
curl -fsSL https://get.docker.com | sh
sudo usermod -aG docker $USER
newgrp docker
# 4. 安装kubectl
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
chmod +x kubectl
sudo mv kubectl /usr/local/bin/
# 5. 安装kind (Kubernetes in Docker)
curl -Lo ./kind https://github.com/kubernetes-sigs/kind/releases/latest/download/kind-linux-amd64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/
# 6. 验证安装
docker --version
kubectl version --client
kind version
环境准备完成后,需要确保系统有足够的资源。对于开发测试环境,建议至少4核CPU、8GB内存;对于生产环境,根据实际工作负载需求进行规划。
2.2 Kurator源码获取与构建
Kurator的源码托管在GitHub上,可以通过git clone命令获取最新代码。以下是详细步骤:
# 克隆Kurator源码仓库
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 或者使用wget下载zip包
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
unzip main.zip
mv kurator-main kurator
cd kurator
# 查看目录结构
ls -la
如果显示下面的问题
表示没用设置git代理,我们可以先设置git代理;先看一下电脑上的代理端口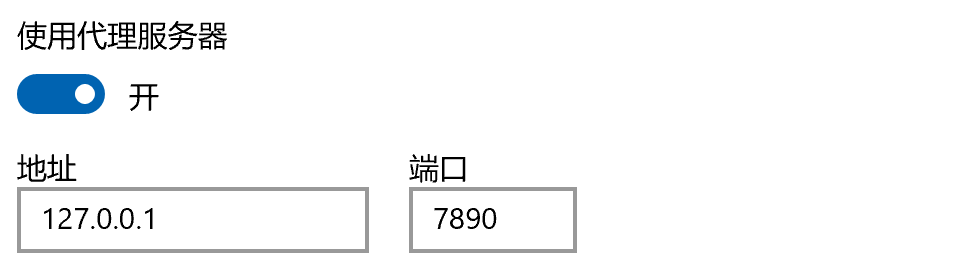
再设置git的代理端口,设置成本地代理
git config --global http.proxy http://127.0.0.1:7890
然后再拉取
git clone https://github.com/kurator-dev/kurator.git

就可以拉取资源了,当然也可以换源,你们可以试试
克隆完成后,目录结构大致如下:
cmd/:包含Kurator各组件的命令行入口pkg/:核心功能包,包含各组件的实现manifests/:Kubernetes部署清单文件hack/:构建和开发辅助脚本examples/:示例配置和用例docs/:文档
接下来,构建Kurator二进制文件:
# 安装Go依赖 (需要Go 1.18+)
go mod download
# 构建Kurator
make build
# 验证构建结果
ls -la bin/
./bin/kurator --version
构建成功后,会在bin目录下生成kurator二进制文件,这个文件是Kurator的核心命令行工具,用于集群管理、应用部署等操作。
2.3 Kurator集群部署与验证
Kurator支持多种部署方式,包括单集群部署、多集群部署、边缘集群部署等。这里以单集群部署为例,演示如何快速启动一个Kurator集群:
# 1. 创建kind集群作为管理集群
cat <<EOF | kind create cluster --name kurator-management --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
EOF
# 2. 配置kubectl上下文
kubectl cluster-info --context kind-kurator-management
# 3. 初始化Kurator
./bin/kurator init --components all
# 4. 验证Kurator组件状态
kubectl get pods -n kurator-system
kubectl get crds | grep kurator
部署完成后,应该能够看到kurator-system命名空间下的所有Pod都处于Running状态。这表明Kurator的核心组件已经成功启动。接下来,可以创建一个Fleet来管理多个集群:
# 创建Fleet
cat <<EOF | kubectl apply -f -
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: demo-fleet
spec:
clusters:
- name: member1
kubeconfigSecret: member1-kubeconfig
- name: member2
kubeconfigSecret: member2-kubeconfig
EOF
# 验证Fleet状态
kubectl get fleet demo-fleet -o yaml
通过以上步骤,我们成功搭建了一个Kurator环境,并初始化了一个Fleet。这个环境可以作为后续实践的基础,用于测试多集群管理、边缘计算、批处理调度等功能。
三、多集群管理与Fleet实践
3.1 Fleet多集群架构设计
Fleet架构官方参考图: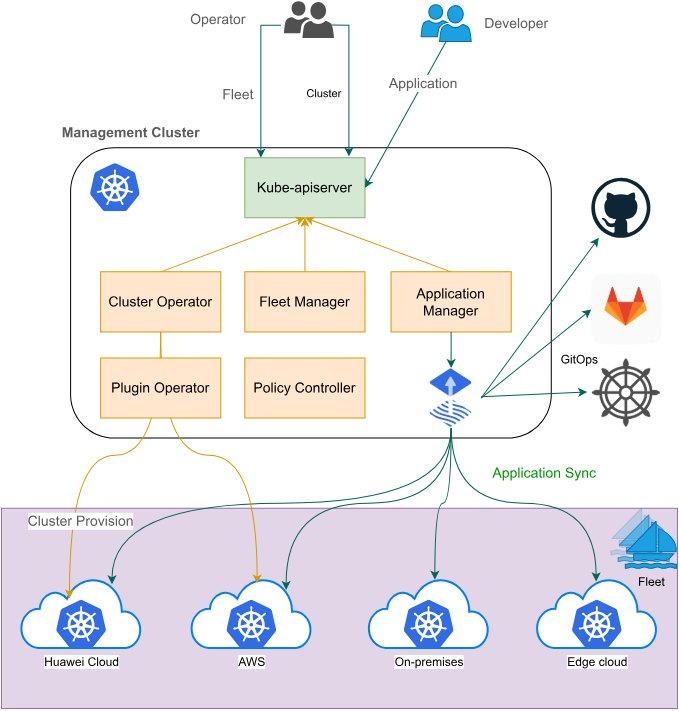
Fleet是Kurator中用于多集群管理的核心概念。在分布式云原生环境中,企业往往拥有多个Kubernetes集群,这些集群可能分布在不同的云提供商、不同的地域,甚至是边缘位置。Fleet提供了一种统一的方式来管理这些异构集群,实现资源、应用、策略的统一管控。
Fleet架构的核心思想是"逻辑集群"的概念。一个Fleet由多个物理集群组成,但在逻辑上被视为一个单一的集群。这种设计带来了以下优势:
- 统一视角:管理员可以通过Fleet的统一接口查看和管理所有集群的资源
- 应用分发:应用可以定义一次,自动分发到Fleet中的多个集群
- 策略同步:安全策略、网络策略等可以在Fleet层面定义,自动同步到各集群
- 服务发现:跨集群的服务发现和服务调用变得更加简单
- 资源聚合:Fleet可以聚合各集群的资源状态,提供全局视图
Fleet架构包含以下几个关键组件:
- Fleet Controller:负责Fleet资源的生命周期管理
- Cluster Registration:处理集群的注册和注销流程
- Policy Engine:确保各集群策略的一致性
- Service Discovery:提供跨集群的服务发现能力
- Metrics Aggregation:聚合各集群的监控指标
3.2 集群注册与身份管理
Fleet 的集群注册官方参考图: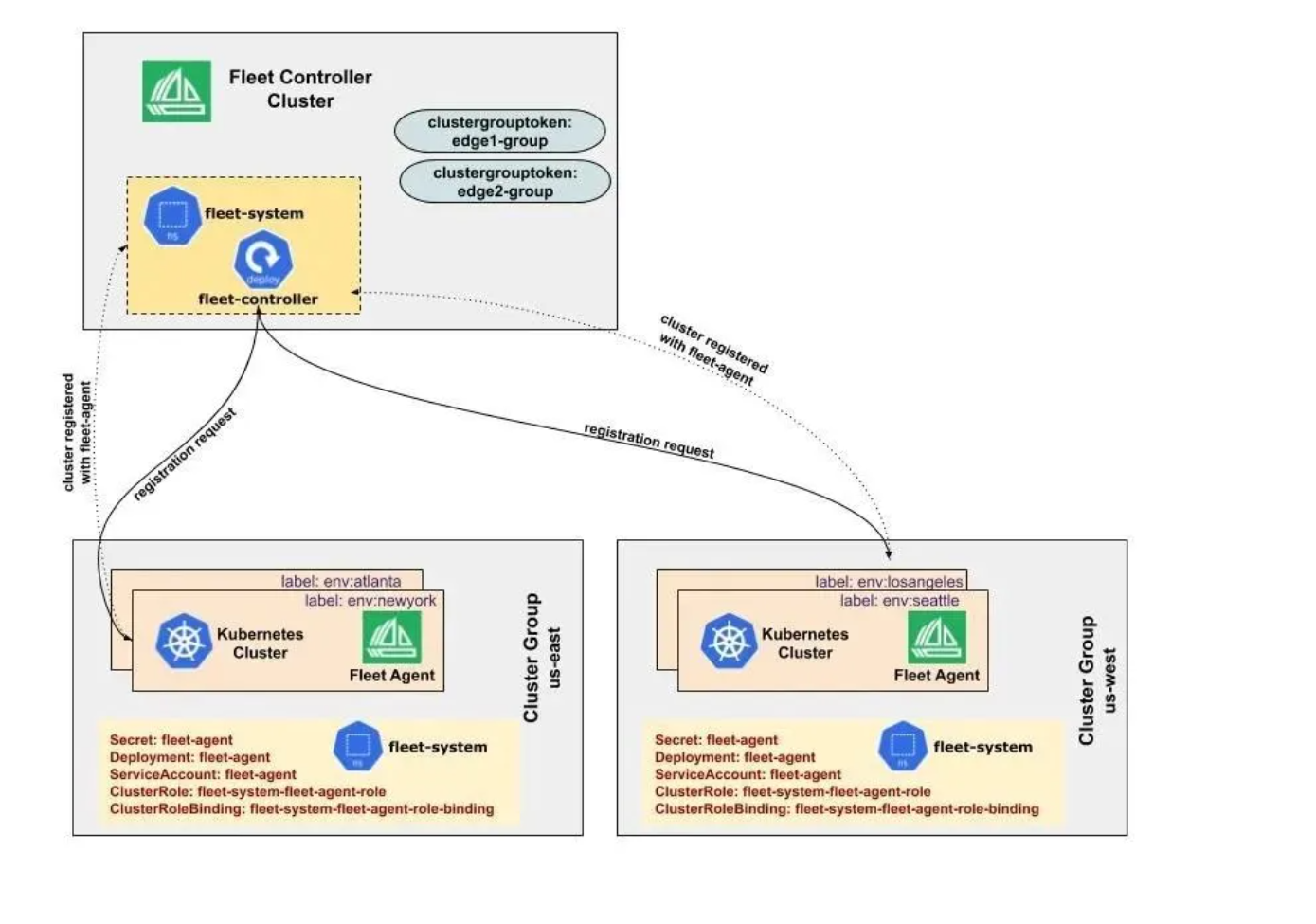
在Kurator中,将集群加入Fleet是一个标准化的流程。这个流程不仅涉及技术层面的连接,还包括身份和权限的管理。以下是集群注册的详细步骤:
# 1. 创建集群注册资源
apiVersion: fleet.kurator.dev/v1alpha1
kind: ClusterRegistration
meta
name: edge-cluster-01
spec:
# 集群访问凭证
kubeconfigSecret:
name: edge-cluster-01-kubeconfig
namespace: kurator-system
# 集群标签,用于后续的调度和选择
labels:
location: edge
region: beijing
environment: production
# 集群属性
attributes:
kubernetesVersion: "1.24.0"
nodeCount: 10
provider: "baremetal"
集群注册成功后,Kurator会自动创建相应的Cluster资源,并将其加入Fleet。这个过程中,关键的是身份相同性(Identity Sameness)的处理。Kurator通过以下机制确保跨集群身份的一致性:
- ServiceAccount同步:Fleet中定义的ServiceAccount会自动同步到所有成员集群,确保相同的服务账户在不同集群中有相同的权限
- RBAC策略统一:Role和ClusterRole资源可以在Fleet层面定义,自动分发到各集群
- 证书管理:使用统一的CA签发证书,确保跨集群通信的安全性
- Token同步:ServiceAccount的Token会自动同步,支持跨集群的API调用
# 查看Fleet中的集群列表
kubectl get clusters -l fleet.kurator.dev/name=demo-fleet
# 验证ServiceAccount同步
kubectl get serviceaccount -n default --context=fleet-demo-fleet
kubectl get serviceaccount -n default --context=member-cluster-1
这种身份管理机制不仅简化了多集群环境下的权限管理,还为跨集群的服务调用和资源访问提供了基础。
3.3 跨集群资源同步与服务发现
Fleet的一个重要功能是实现跨集群的资源同步和服务发现。在传统多集群架构中,不同集群之间的服务发现是一个复杂的问题。Kurator通过Fleet提供了统一的服务发现机制。
**命名空间相同性(Namespace Sameness)**是Kurator实现跨集群服务发现的基础。在Fleet中,相同名称的命名空间会被视为同一个逻辑命名空间,无论它们物理上位于哪个集群。这使得服务发现变得简单:
# 1. 在Fleet中定义命名空间
apiVersion: fleet.kurator.dev/v1alpha1
kind: NamespacePlacement
meta
name: demo-namespace
spec:
fleet: demo-fleet
namespaceName: demo-app
placement:
clusterSelector:
matchLabels:
location: cloud
Fleet 队列中的服务相同性官方参考图: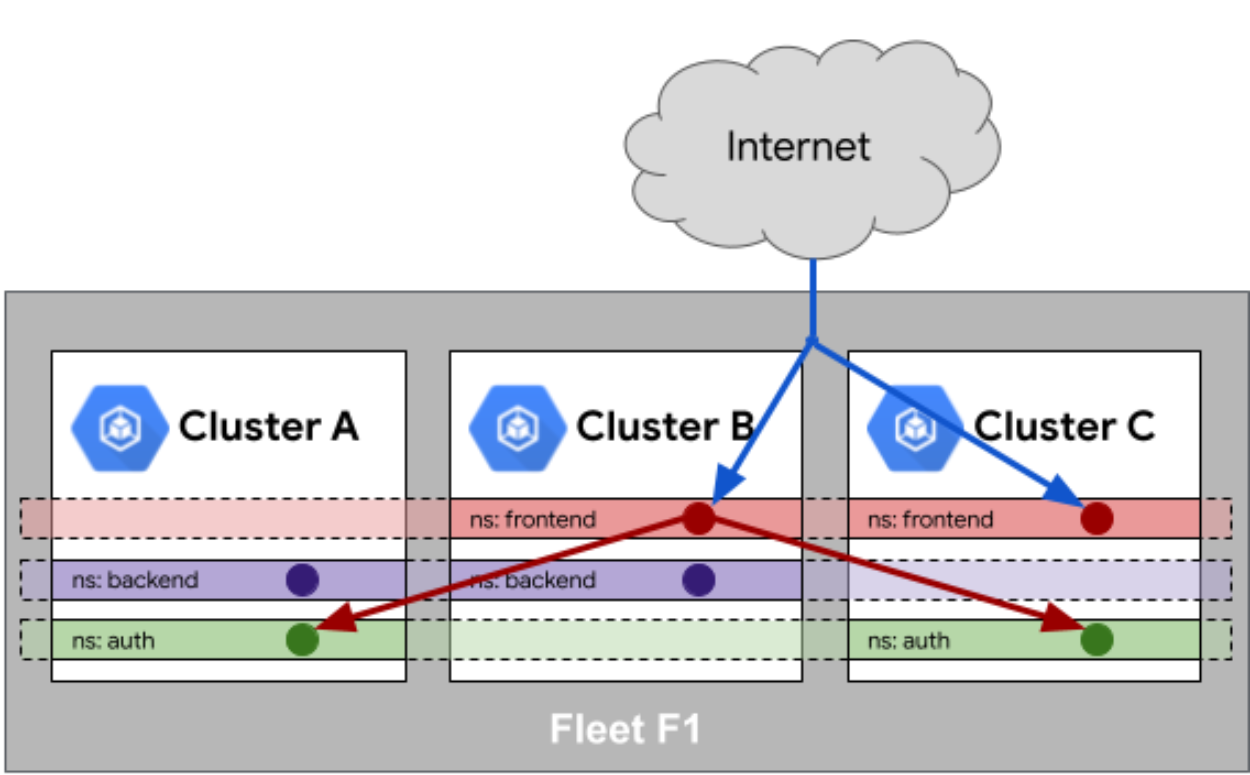
**服务相同性(Service Sameness)**则进一步确保了相同名称的服务在不同集群中被视为同一个服务。Kurator会自动为跨集群服务创建全局DNS记录,格式为<service-name>.<namespace>.svc.clusterset.local:
# 2. 创建跨集群服务
apiVersion: v1
kind: Service
meta
name: frontend-service
namespace: demo-app
annotations:
fleet.kurator.dev/service-sameness: "true"
spec:
selector:
app: frontend
ports:
- port: 80
targetPort: 8080
通过这些机制,应用可以透明地访问跨集群的服务,无需关心服务实际部署在哪个集群中。例如,一个部署在云集群中的服务可以无缝调用部署在边缘集群中的数据库服务:
// 应用代码中访问跨集群服务
func getDataFromEdgeDB() {
// 通过全局DNS访问边缘集群中的数据库服务
resp, err := http.Get("http://edge-db.demo-app.svc.clusterset.local:5432/data")
if err != nil {
log.Fatal(err)
}
// 处理响应
}
这种服务发现机制大大简化了分布式应用的开发和部署,开发者可以像在单集群环境中一样编写代码,而无需考虑底层的多集群复杂性。
四、Karmada跨集群调度与弹性伸缩
4.1 Karmada在Kurator中的集成架构
Karmada 的总体架构官方参考图: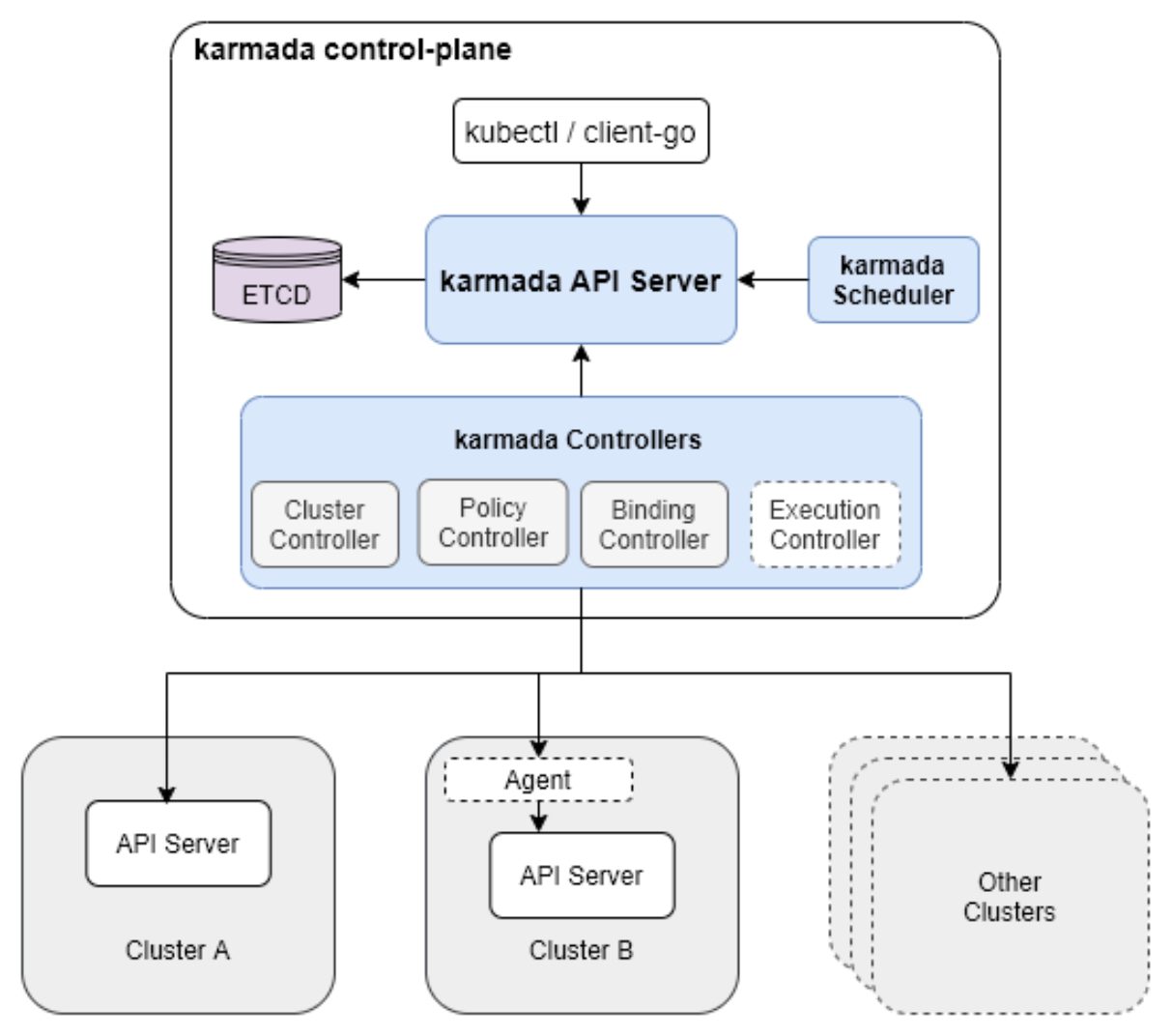
Karmada是Kurator集成的核心组件之一,专注于多集群应用管理。Karmada(Kubernetes Armada)是一个开源的多集群Kubernetes编排系统,它允许用户将工作负载分发到多个Kubernetes集群中,实现高可用、容灾、地理分布等需求。
在Kurator架构中,Karmada被深度集成,作为Fleet的底层调度引擎。Kurator对Karmada进行了封装和扩展,提供了更易用的API和更丰富的功能。Karmada的核心概念包括:
- PropagationPolicy:定义资源如何分发到目标集群
- Cluster:注册到Karmada的成员集群
- ResourceBinding:资源与集群的绑定关系
- Work:在成员集群中实际创建的资源
Kurator在此基础上增加了:
- 与Fleet的无缝集成
- 统一的身份和权限管理
- 增强的监控和可观测性
- 与GitOps工作流的集成
# 查看Karmada组件状态
kubectl get pods -n karmada-system
# 查看注册的集群
kubectl get clusters -n karmada-system
4.2 跨集群应用部署策略
Karmada提供了丰富的工作负载分发策略,Kurator将其封装为更易用的API。以下是几种常见的部署策略:
1. 副本分片策略(Replica Slicing)
将工作负载的副本分发到多个集群,每个集群运行部分副本。这种策略适合需要高可用的应用:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: nginx-pp
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
replicaScheduling:
replicaSchedulingType: Duplicated # 或 Split
replicaDivisionPreference: Weighted
weightPreference:
cluster-east: 70
cluster-west: 30
2. 集群故障转移策略(Failover)
定义主集群和备用集群,当主集群不可用时,自动将工作负载迁移到备用集群:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: failover-pp
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: critical-app
placement:
clusterAffinity:
clusterNames:
- cluster-primary
- cluster-backup
clusterTolerations:
- key: cluster.karmada.io/not-ready
operator: Exists
effect: Failover
3. 地理位置感知策略(Location-aware)
根据用户地理位置,将应用部署到最近的集群,优化访问延迟:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: geo-aware-pp
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: frontend
placement:
clusterAffinity:
matchLabels:
region: asia
matchExpressions:
- key: latency
operator: LessThan
values: ["50ms"]
在Kurator中,这些策略可以通过更简洁的API进行配置:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Application
meta
name: demo-app
spec:
fleet: demo-fleet
placement:
strategy: weighted
weights:
cluster-east: 70
cluster-west: 30
template:
apiVersion: apps/v1
kind: Deployment
meta
name: nginx
spec:
replicas: 10
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
4.3 跨集群弹性伸缩实践
Karmada跨集群弹性伸缩策略参考图: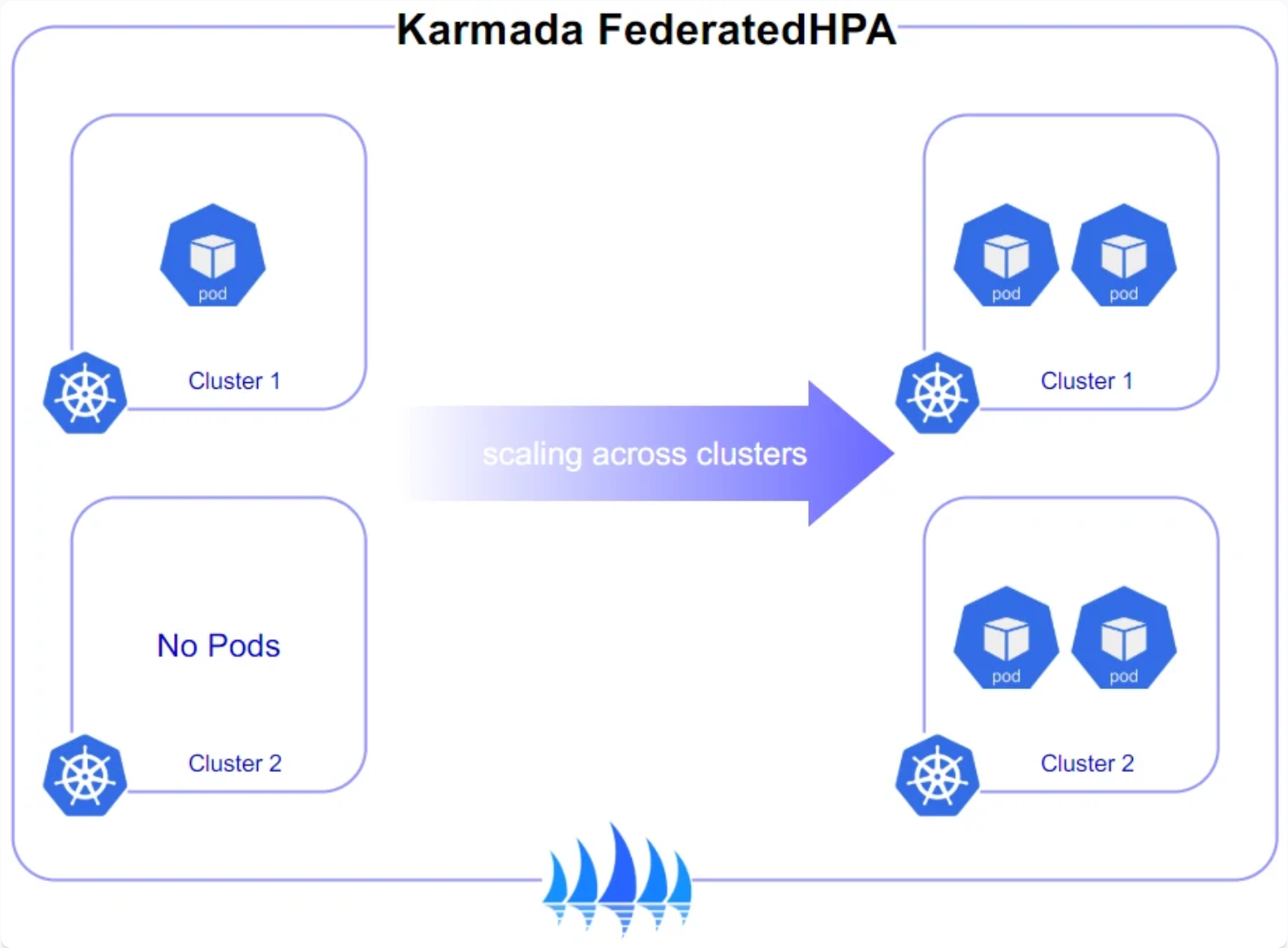
Karmada与Kubernetes HPA(Horizontal Pod Autoscaler)的结合,实现了跨集群的弹性伸缩能力。Kurator在此基础上提供了更智能的伸缩策略,考虑集群资源利用率、成本、性能等因素。
1. 集群级弹性伸缩
根据集群整体负载情况,动态调整工作负载在各集群中的副本分布:
apiVersion: autoscaling.karmada.io/v1alpha1
kind: ClusterScaledObject
meta
name: frontend-cso
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
minReplicas: 5
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
clusterMetrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
2. 基于预测的弹性伸缩
Kurator集成了预测算法,可以根据历史负载数据预测未来需求,提前进行伸缩:
// 预测算法示例
func predictScaling(currentLoad float64, history []float64) int32 {
// 使用简单移动平均算法
var sum float64
window := 5
if len(history) < window {
window = len(history)
}
for i := 0; i < window; i++ {
sum += history[len(history)-1-i]
}
avg := sum / float64(window)
// 预测未来负载(简单线性预测)
trend := (currentLoad - avg) / avg
predictedLoad := currentLoad * (1 + trend*0.5)
// 计算所需副本数
targetReplicas := int32(math.Ceil(predictedLoad / 0.7)) // 70% CPU利用率目标
return max(1, min(targetReplicas, 100)) // 限制在1-100之间
}
3. 成本感知伸缩策略
在多云环境中,不同云提供商的成本差异很大。Kurator支持成本感知的伸缩策略,将工作负载优先调度到成本更低的集群:
apiVersion: policy.kurator.dev/v1alpha1
kind: CostAwarePolicy
meta
name: cost-optimization
spec:
fleet: demo-fleet
costMetrics:
- provider: aws
region: us-east-1
instanceType: m5.large
hourlyCost: 0.096
- provider: gcp
region: us-central1
instanceType: e2-standard-2
hourlyCost: 0.078
scalingStrategy:
preferredClusters:
- cluster-name: gcp-cluster
weight: 80
- cluster-name: aws-cluster
weight: 20
fallbackOnInsufficientResources: true
这些弹性伸缩策略不仅提高了应用的可用性和性能,还优化了资源利用率,降低了总体拥有成本(TCO)。在实际生产环境中,可以根据业务需求组合使用这些策略,实现最佳的资源利用效果。
五、KubeEdge边缘计算集成实践
5.1 KubeEdge架构与核心组件
KubeEdge架构参考图: 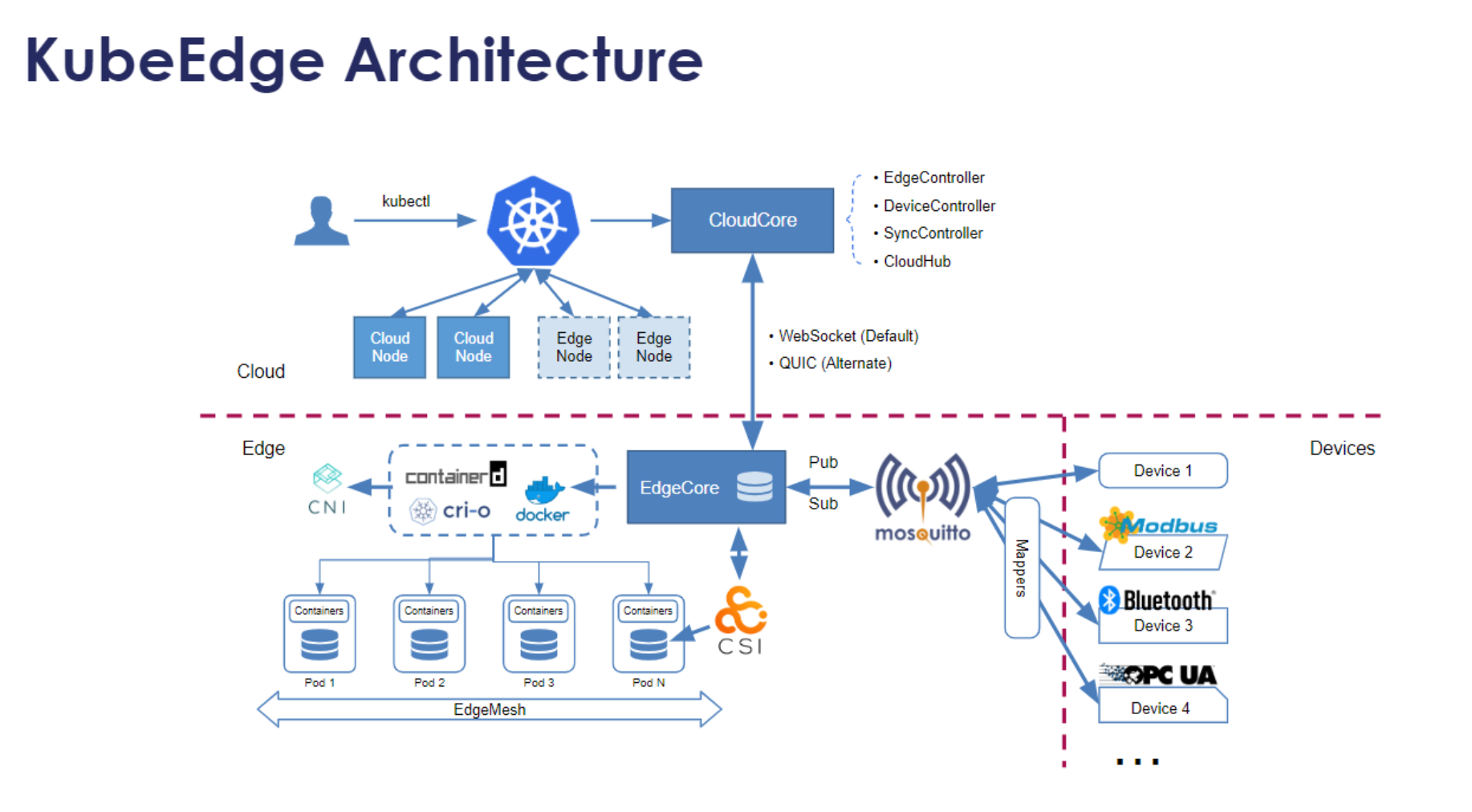
KubeEdge是Kurator集成的重要边缘计算框架,它将Kubernetes原生能力扩展到边缘节点。KubeEdge的核心价值在于它解决了边缘计算场景下的特殊挑战:网络不稳定、设备资源受限、安全要求高等问题。
KubeEdge的核心组件参考图: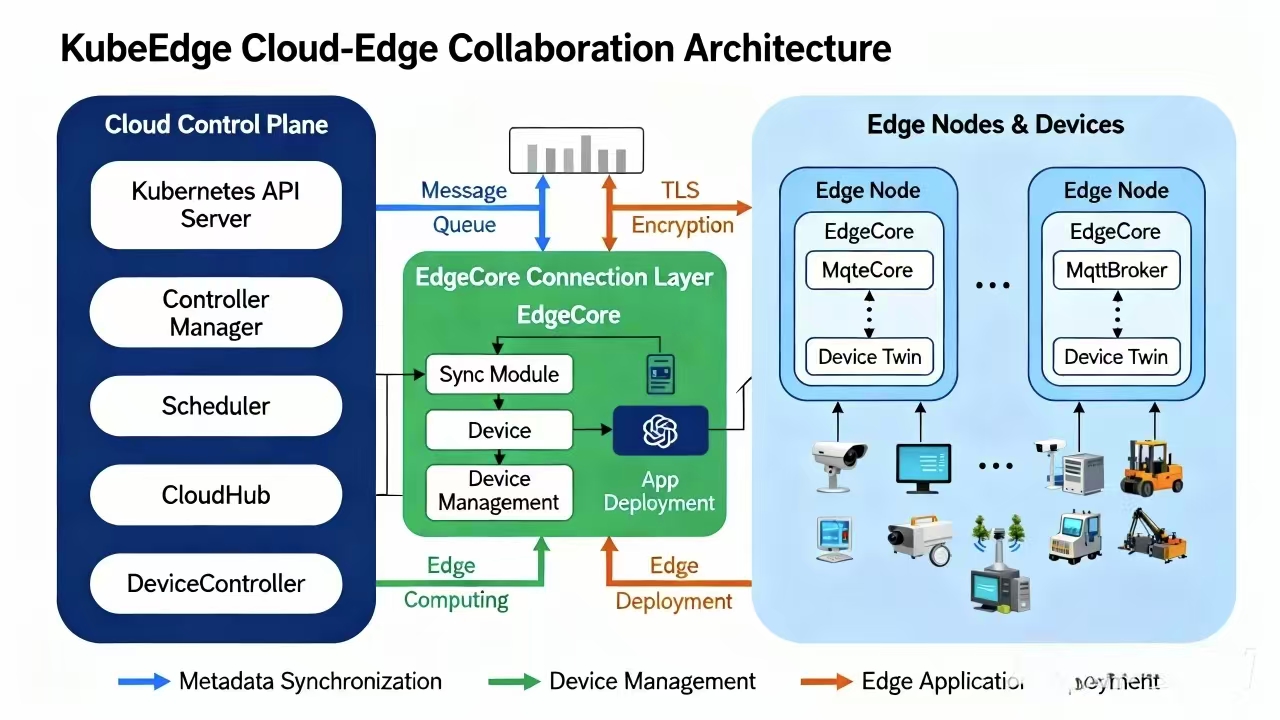
KubeEdge架构分为云边两部分:
云端组件(Cloud Side):
- CloudCore:云端核心组件,负责与Kubernetes API Server通信,管理边缘节点和应用
- ControllerManager:包含多个控制器,如NodeController、PodController等,实现Kubernetes资源的同步
- DeviceController:管理边缘设备,同步设备状态到云端
边缘组件(Edge Side):
- EdgeCore:边缘核心组件,运行在边缘节点上
- EdgeMesh:边缘服务网格,提供本地服务发现和通信
- DeviceTwin:设备孪生,缓存设备状态,支持离线操作
- MetaManager:元数据管理,存储边缘节点的配置和状态
- EdgeHub:与云端通信的组件,支持WebSocket和QUIC协议,在网络不稳定时自动重连
KubeEdge的关键特性包括:
- 云边协同:边缘节点作为Kubernetes节点无缝集成
- 离线自治:在网络中断时,边缘节点可以继续运行已有应用
- 设备管理:支持MQTT、Bluetooth、Modbus等多种协议的设备接入
- 边缘存储:支持本地持久化存储,适应边缘场景
- 边缘AI:集成TensorFlow、PyTorch等AI框架,支持边缘推理
# 查看KubeEdge组件状态
kubectl get pods -n kubeedge-system
kubectl get nodes -l node-role.kubernetes.io/edge=
5.2 Kurator中KubeEdge的集成实践
Kurator对KubeEdge进行了深度集成,简化了边缘集群的管理。通过Kurator,用户可以:
- 统一节点管理:边缘节点和云端节点在同一个界面中管理
- 应用分发:将应用无缝部署到边缘节点
- 策略同步:安全策略、网络策略自动同步到边缘
- 监控聚合:边缘节点的监控数据聚合到中心平台
边缘节点注册流程:
# 1. 生成边缘节点注册命令
./bin/kurator edge-node register edge-node-01 \
--labels location=beijing,floor=1,type=raspberry-pi \
--taints node-role.kubernetes.io/edge=:NoSchedule
# 2. 在边缘设备上执行注册命令
# (在边缘设备上执行生成的命令)
curl -O https://kurator-edge-install.example.com/install.sh
chmod +x install.sh
./install.sh --token=xxxx --server=https://kurator-api.example.com
边缘应用部署:
apiVersion: apps/v1
kind: Deployment
meta
name: edge-camera-app
spec:
replicas: 1
selector:
matchLabels:
app: camera-processor
template:
meta
labels:
app: camera-processor
spec:
nodeSelector:
node-role.kubernetes.io/edge: ""
containers:
- name: camera-processor
image: kurator/camera-ai:latest
resources:
limits:
cpu: "1"
memory: 512Mi
nvidia.com/gpu: 1 # 边缘AI推理
volumeMounts:
- name: camera-data
mountPath: /data/camera
volumes:
- name: camera-data
hostPath:
path: /mnt/camera
设备管理配置:
apiVersion: devices.kubeedge.io/v1alpha2
kind: DeviceModel
meta
name: camera-sensor
spec:
properties:
- name: resolution
description: Camera resolution
type: string
- name: fps
description: Frames per second
type: integer
- name: status
description: Camera status
type: string
---
apiVersion: devices.kubeedge.io/v1alpha2
kind: Device
meta
name: camera-001
spec:
deviceModelRef:
name: camera-sensor
nodeSelector:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values: [edge-node-01]
properties:
propertyVisitors:
- propertyName: resolution
protocol:
modbus:
register: 1
quantity: 1
5.3 边缘-云协同计算场景
云边协同计算场景参考图:
Kurator结合KubeEdge和Karmada,实现了真正的边缘-云协同计算。以下是一个典型的协同计算场景:智能工厂的视觉质检系统。
场景描述:
- 边缘侧:工厂车间部署多个摄像头,进行实时视频采集
- 边缘计算:在边缘节点运行AI模型,进行初步的缺陷检测
- 云端协同:将可疑样本上传到云端,进行更精确的分析和模型训练
- 模型更新:训练好的新模型自动分发到边缘节点
系统架构:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Application
meta
name: smart-factory-vision
spec:
fleet: factory-fleet
components:
- name: edge-camera-collector
type: deployment
properties:
replicas: 10
location: edge
nodeSelector:
node-role.kubernetes.io/edge: ""
containers:
- name: camera-collector
image: kurator/camera-collector:1.0
resources:
limits:
cpu: "0.5"
memory: 256Mi
- name: edge-defect-detector
type: deployment
properties:
replicas: 10
location: edge
containers:
- name: defect-detector
image: kurator/defect-detector:1.2
resources:
limits:
nvidia.com/gpu: 1
env:
- name: MODEL_VERSION
value: "1.2"
- name: cloud-analysis-service
type: deployment
properties:
replicas: 3
location: cloud
containers:
- name: analysis-service
image: kurator/cloud-analysis:1.0
resources:
limits:
cpu: "4"
memory: 8Gi
协同工作流程:
- 边缘摄像头采集视频流,进行预处理
- 边缘AI模型进行实时缺陷检测,准确率约85%
- 将置信度低于90%的样本上传到云端
- 云端使用更复杂的模型进行二次分析,准确率98%
- 云端定期聚合边缘数据,重新训练模型
- 新模型通过GitOps工作流自动分发到边缘节点
代码实现示例:
# 边缘侧推理代码
import cv2
import numpy as np
import requests
import json
from edge_model import load_model, predict
# 加载边缘模型
model = load_model("/models/defect-detector-v1.2.onnx")
def process_frame(frame):
# 预处理
processed = preprocess(frame)
# 边缘推理
result, confidence = predict(model, processed)
# 如果置信度低,上传到云端
if confidence < 0.9:
upload_to_cloud(frame, result, confidence)
return result, confidence
def upload_to_cloud(frame, result, confidence):
# 将可疑样本上传到云端进行二次分析
_, buffer = cv2.imencode('.jpg', frame)
data = {
"frame": buffer.tobytes().decode('latin1'),
"edge_result": result,
"confidence": confidence,
"device_id": os.environ.get("DEVICE_ID", "unknown")
}
try:
response = requests.post(
"https://cloud-analysis.factory.svc.clusterset.local/analyze",
json=data,
timeout=5.0
)
if response.status_code == 200:
cloud_result = response.json()
print(f"Cloud analysis: {cloud_result}")
except Exception as e:
print(f"Cloud analysis failed: {e}")
# 保存到本地,稍后重试
save_for_retry(frame, result, confidence)
这个协同计算场景展示了Kurator如何通过整合KubeEdge和Karmada,实现边缘和云端的无缝协作,充分发挥各自优势:边缘的低延迟、高带宽特性,以及云端的强大计算和存储能力。
六、Volcano批处理调度架构与实践
6.1 Volcano架构与核心概念
Volcano调度架构参考图: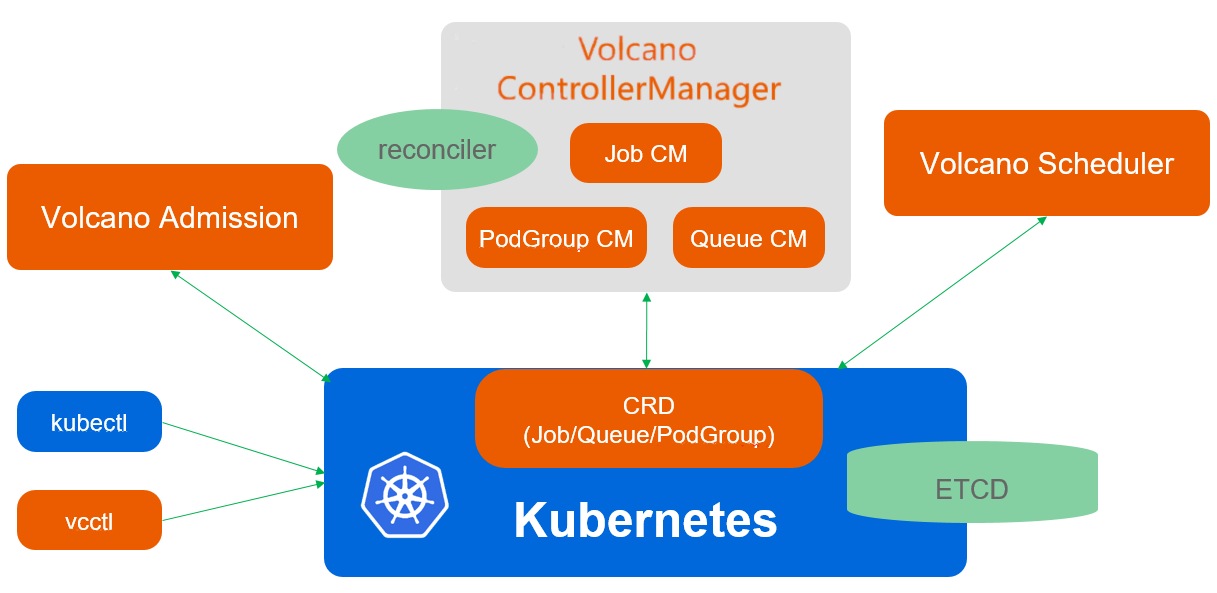
Volcano是Kurator集成的批处理和高性能计算调度框架,专门针对AI/ML、大数据、HPC等计算密集型工作负载优化。Volcano的核心价值在于它解决了Kubernetes原生调度器在批处理场景下的局限性,如缺乏任务依赖、缺乏队列管理、缺乏拓扑感知等。
Volcano架构包含以下几个核心组件:
Volcano Scheduler工作流参考图: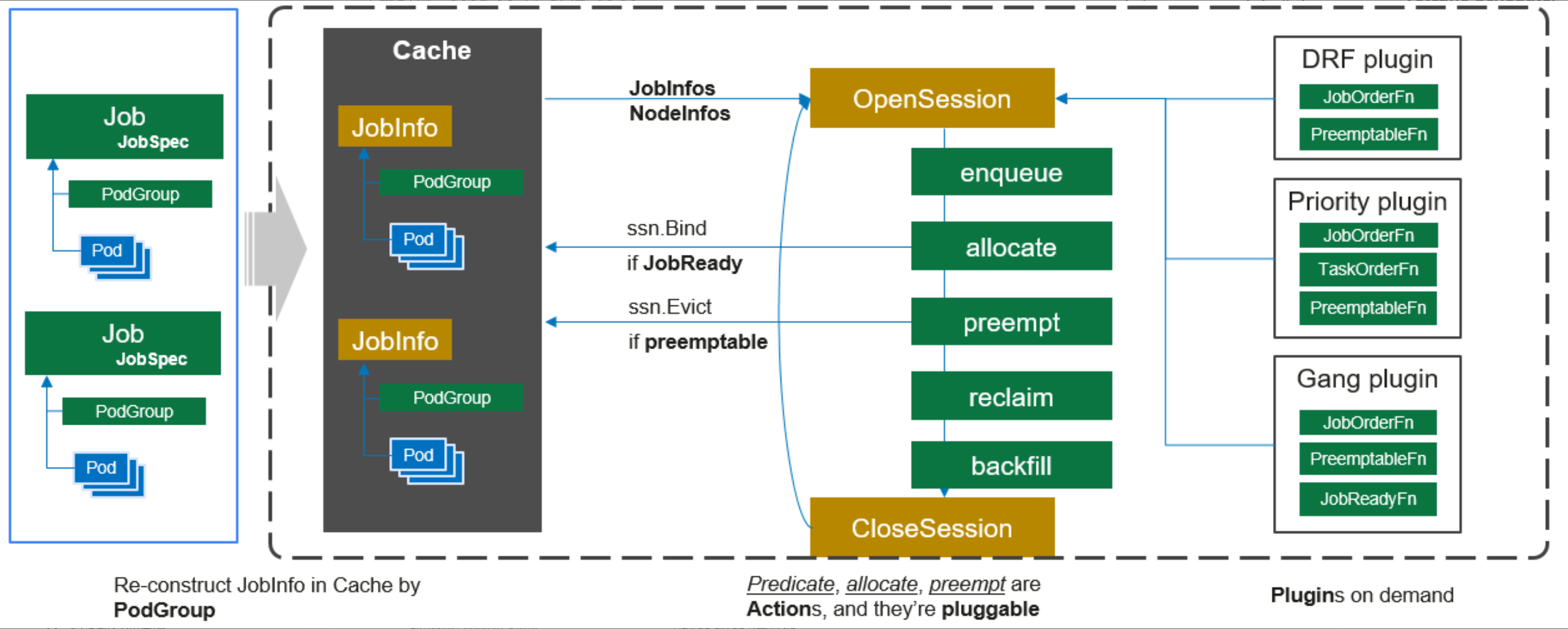
Volcano Scheduler:
- Actions:调度动作,如Allocate、Backfill、Preempt等
- Plugins:调度插件,实现具体调度策略
- Cache:集群状态缓存,提高调度性能
Volcano Controller:
- Job Controller:管理VolcanoJob生命周期
- Queue Controller:管理队列资源分配
- PodGroup Controller:管理Pod分组
VolcanoJob和Queue、PodGroup 参考图: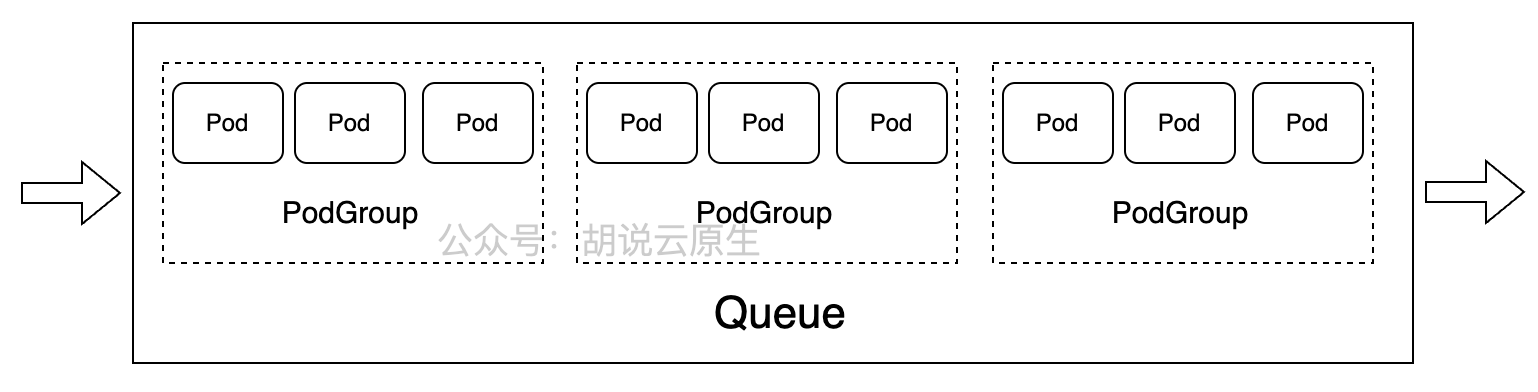
Volcano的核心概念包括:
- Queue:资源队列,用于组织和隔离不同团队或项目的资源
- PodGroup:Pod分组,表示具有相同调度需求的Pod集合
- Job:工作负载抽象,支持多种任务模式(MPI、TensorFlow、Spark等)
- Task:任务定义,指定容器镜像、资源需求等
# 查看Volcano组件
kubectl get pods -n volcano-system
kubectl get queues
kubectl get podgroups
6.2 Kurator中Volcano的集成应用
Kurator将Volcano深度集成到其多集群架构中,通过Karmada实现跨集群的批处理调度。这种集成带来了以下优势:
1. 跨集群资源池化:
不同集群的计算资源(特别是GPU资源)可以组成统一的资源池,提高资源利用率。
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: ai-training-queue
spec:
weight: 1
capability:
cpu: "100"
memory: 500Gi
nvidia.com/gpu: "20"
reclaimable: true
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
meta
name: distributed-training
spec:
minMember: 8
minTaskMember:
- name: worker
minMember: 6
- name: ps
minMember: 2
queue: ai-training-queue
2. 拓扑感知调度:
Volcano支持NUMA拓扑、GPU拓扑、网络拓扑等感知调度,Kurator将其扩展到跨集群场景。
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: distributed-tensorflow
spec:
minAvailable: 8
schedulerName: volcano
plugins:
ssh: []
svc: []
tasks:
- replicas: 2
name: ps
template:
spec:
containers:
- image: tensorflow/tensorflow:2.5.0-gpu
name: tensorflow
resources:
limits:
nvidia.com/gpu: 1
env:
- name: TF_CONFIG
valueFrom:
configMapKeyRef:
name: tf-config
key: ps
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values: [zone-a] # 参数服务器需要在同一区域
- replicas: 6
name: worker
template:
spec:
containers:
- image: tensorflow/tensorflow:2.5.0-gpu
name: tensorflow
resources:
limits:
nvidia.com/gpu: 4
env:
- name: TF_CONFIG
valueFrom:
configMapKeyRef:
name: tf-config
key: worker
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: volcano.sh/job-name
operator: In
values: [distributed-tensorflow]
topologyKey: kubernetes.io/hostname # 工作节点需要在同一主机
3. 队列优先级与抢占:
Kurator支持跨集群的队列优先级管理,高优先级任务可以抢占低优先级任务的资源。
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: high-priority
spec:
weight: 100 # 高权重
reclaimable: true
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: low-priority
spec:
weight: 10 # 低权重
reclaimable: true
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: urgent-analysis
spec:
queue: high-priority
tasks:
- replicas: 4
name: analysis
policies:
- event: PodEvicted # 当被驱逐时重新调度
action: RestartJob
template:
spec:
containers:
- image: data-analysis:latest
name: analysis
resources:
limits:
cpu: "8"
memory: 32Gi
6.3 AI训练工作负载调度实践
在实际的AI训练场景中,Volcano的高级调度能力可以显著提升训练效率。以下是一个分布式PyTorch训练的完整示例:
场景需求:
- 训练一个大型计算机视觉模型
- 需要8个GPU节点,每个节点4个GPU
- 节点之间需要高速网络互联
- 训练任务具有严格的启动同步要求
资源规划:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: cv-training-queue
spec:
weight: 50
capability:
cpu: "320" # 8 nodes * 40 cores
memory: 2000Gi # 8 nodes * 250Gi
nvidia.com/gpu: "32" # 8 nodes * 4 GPUs
reclaimable: true
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
meta
name: imagenet-training
spec:
minMember: 8
minTaskMember:
- name: worker
minMember: 8
queue: cv-training-queue
scheduleTimeoutSeconds: 300 # 5分钟超时
训练任务定义:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: imagenet-resnet50
spec:
minAvailable: 8 # 必须8个Pod都就绪才能启动
schedulerName: volcano
plugins:
ssh: [] # 启用SSH插件,方便调试
env: [] # 环境变量插件
svc: [] # 服务发现插件
ttlSecondsAfterFinished: 3600 # 完成后1小时清理
tasks:
- replicas: 8
name: worker
policies:
- event: TaskCompleted
action: CompleteJob
template:
meta
annotations:
volcano.sh/task-spec: "worker" # 任务规格标识
spec:
schedulerName: volcano
containers:
- image: pytorch/pytorch:1.10.0-cuda11.3-cudnn8-runtime
name: pytorch
command: ["python", "/workspace/train.py"]
args:
- "--model=resnet50"
- "--dataset=imagenet"
- "--batch-size=128"
- "--epochs=100"
- "--lr=0.1"
- "--distributed"
env:
- name: MASTER_ADDR
value: "imagenet-resnet50-worker-0.imagenet-resnet50"
- name: MASTER_PORT
value: "23456"
- name: WORLD_SIZE
value: "8"
- name: NCCL_IB_DISABLE
value: "0" # 启用InfiniBand
- name: NCCL_SOCKET_IFNAME
value: "ib0" # InfiniBand网络接口
resources:
limits:
cpu: "36"
memory: 180Gi
nvidia.com/gpu: 4 # 4 GPUs per node
requests:
cpu: "32"
memory: 160Gi
nvidia.com/gpu: 4
volumeMounts:
- name: dataset
mountPath: /data/imagenet
- name: checkpoint
mountPath: /checkpoints
- name: workspace
mountPath: /workspace
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values: [p4d.24xlarge] # AWS GPU实例
- key: topology.kubernetes.io/zone
operator: In
values: [us-west-2a] # 同一可用区
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: volcano.sh/job-name
operator: In
values: [imagenet-resnet50]
topologyKey: kubernetes.io/hostname # 避免同一主机
volumes:
- name: dataset
persistentVolumeClaim:
claimName: imagenet-pvc
- name: checkpoint
persistentVolumeClaim:
claimName: checkpoint-pvc
- name: workspace
configMap:
name: training-code
训练代码关键部分:
# train.py
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DistributedSampler
import torchvision
import os
import time
def setup_ddp():
"""初始化分布式训练"""
rank = int(os.environ['RANK'])
world_size = int(os.environ['WORLD_SIZE'])
dist.init_process_group(
backend='nccl',
init_method='env://',
rank=rank,
world_size=world_size
)
torch.cuda.set_device(rank % torch.cuda.device_count())
return rank, world_size
def create_model():
"""创建ResNet50模型"""
model = torchvision.models.resnet50(pretrained=False)
model = model.cuda()
model = DDP(model, device_ids=[torch.cuda.current_device()])
return model
def train_epoch(model, dataloader, optimizer, criterion, epoch, rank):
"""训练一个epoch"""
model.train()
total_loss = 0
start_time = time.time()
for batch_idx, (data, target) in enumerate(dataloader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
if batch_idx % 10 == 0 and rank == 0:
print(f'Epoch {epoch} Batch {batch_idx}/{len(dataloader)} '
f'Loss: {loss.item():.6f} '
f'Time: {time.time()-start_time:.2f}s')
avg_loss = total_loss / len(dataloader)
if rank == 0:
print(f'Epoch {epoch} Average Loss: {avg_loss:.6f}')
return avg_loss
def main():
# 初始化分布式环境
rank, world_size = setup_ddp()
# 创建模型、优化器、损失函数
model = create_model()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss()
# 创建数据集
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
dataset = torchvision.datasets.ImageFolder(
'/data/imagenet/train',
transform=transform
)
# 分布式数据采样器
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=128,
sampler=sampler,
num_workers=8,
pin_memory=True
)
# 训练循环
for epoch in range(100):
sampler.set_epoch(epoch) # 确保每个epoch数据打乱
train_epoch(model, dataloader, optimizer, criterion, epoch, rank)
# 定期保存检查点
if rank == 0 and epoch % 10 == 0:
torch.save({
'epoch': epoch,
'model_state_dict': model.module.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}, f'/checkpoints/resnet50_epoch_{epoch}.pt')
# 清理分布式环境
dist.destroy_process_group()
if __name__ == '__main__':
main()
这个示例展示了Kurator如何通过Volcano实现复杂的AI训练工作负载调度。通过拓扑感知、资源预留、任务同步等机制,确保了分布式训练的高效性和稳定性。在实际生产环境中,这种调度能力可以显著缩短训练时间,提高GPU资源利用率,降低AI训练成本。
七、GitOps与CI/CD实践
7.1 GitOps工作流架构设计
GitOps是Kurator内置的核心工作流模式,它将Git仓库作为系统状态的唯一真实来源,通过声明式配置实现基础设施和应用的自动化管理。Kurator基于FluxCD实现了完整的GitOps工作流,具有以下特点:
声明式配置:所有基础设施和应用配置都通过YAML文件定义,存储在Git仓库中
自动化同步:系统自动检测Git仓库变更,并将集群状态同步到期望状态
版本控制:所有变更都有完整的版本历史,支持回滚和审计
多环境支持:通过分支、标签或目录结构管理不同环境(dev/staging/prod)
安全合规:变更需要通过Pull Request和Code Review,确保合规性
Kurator的GitOps架构包含以下核心组件:
FluxCD Controller:监控Git仓库变更,同步资源到集群
Kustomize Controller:处理Kustomize配置,支持环境特定的覆盖
Helm Controller:管理Helm Release,支持Chart版本管理
Notification Controller:发送事件通知,集成Slack、Email等
Image Automation:自动更新容器镜像版本,支持语义化版本控制
# 查看FluxCD组件
kubectl get pods -n flux-system
kubectl get gitrepositories -A
kubectl get kustomizations -A
kubectl get helmreleases -A
7.2 Kurator GitOps实践示例
以下是一个完整的GitOps工作流示例,展示如何在Kurator中管理多环境应用部署。
仓库结构设计:
gitops-repo/
├── clusters/
│ ├── production/
│ │ ├── fleet.yaml
│ │ ├── namespaces.yaml
│ │ └── kustomization.yaml
│ └── staging/
│ ├── fleet.yaml
│ ├── namespaces.yaml
│ └── kustomization.yaml
├── apps/
│ ├── frontend/
│ │ ├── base/
│ │ │ ├── deployment.yaml
│ │ │ ├── service.yaml
│ │ │ └── kustomization.yaml
│ │ ├── production/
│ │ │ ├── deployment-patch.yaml
│ │ │ └── kustomization.yaml
│ │ └── staging/
│ │ ├── deployment-patch.yaml
│ │ └── kustomization.yaml
│ └── backend/
│ ├── base/
│ │ ├── deployment.yaml
│ │ ├── service.yaml
│ │ └── kustomization.yaml
│ ├── production/
│ │ ├── deployment-patch.yaml
│ │ └── kustomization.yaml
│ └── staging/
│ ├── deployment-patch.yaml
│ └── kustomization.yaml
└── infrastructure/
├── cert-manager/
│ ├── release.yaml
│ └── kustomization.yaml
├── istio/
│ ├── control-plane.yaml
│ └── kustomization.yaml
└── monitoring/
├── prometheus.yaml
└── kustomization.yaml
GitRepository配置:
# clusters/production/fleet.yaml
apiVersion: source.toolkit.fluxcd.io/v1
kind: GitRepository
meta
name: gitops-repo
namespace: flux-system
spec:
url: https://github.com/company/gitops-repo
ref:
branch: main
interval: 1m
secretRef:
name: gitops-repo-credentials
---
# clusters/production/kustomization.yaml
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
meta
name: cluster-production
namespace: flux-system
spec:
path: ./clusters/production
prune: true
sourceRef:
kind: GitRepository
name: gitops-repo
interval: 5m
timeout: 2m
healthChecks:
- apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
name: production-fleet
namespace: kurator-system
应用部署配置:
# apps/frontend/production/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- ../../base
patchesStrategicMerge:
- deployment-patch.yaml
namespace: frontend-prod
---
# apps/frontend/production/deployment-patch.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 10
template:
spec:
containers:
- name: frontend
resources:
limits:
cpu: "1"
memory: 1Gi
env:
- name: ENVIRONMENT
value: production
- name: API_URL
value: https://api.production.example.com
Helm Release配置:
# apps/backend/production/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- release.yaml
---
# apps/backend/production/release.yaml
apiVersion: helm.toolkit.fluxcd.io/v2
kind: HelmRelease
meta
name: backend
namespace: backend-prod
spec:
chart:
spec:
chart: backend
version: "1.2.3"
sourceRef:
kind: HelmRepository
name: company-charts
namespace: flux-system
interval: 1m
interval: 5m
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
values:
replicaCount: 8
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: "1"
memory: 1Gi
env:
environment: production
databaseUrl: postgresql://backend-prod-db.example.com
service:
type: ClusterIP
port: 8080
autoscaling:
enabled: true
minReplicas: 4
maxReplicas: 20
targetCPUUtilizationPercentage: 70
7.3 CI/CD流水线集成
Kurator的GitOps工作流可以与现有的CI/CD工具集成,形成完整的软件交付流水线。以下是一个基于GitHub Actions的CI/CD流水线示例:
CI阶段(代码构建与测试):
# .github/workflows/ci.yaml
name: CI Pipeline
on:
push:
branches: [ main ]
paths:
- 'apps/frontend/**'
pull_request:
branches: [ main ]
paths:
- 'apps/frontend/**'
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Node.js
uses: actions/setup-node@v3
with:
node-version: '16'
- name: Install dependencies
working-directory: apps/frontend
run: npm ci
- name: Run tests
working-directory: apps/frontend
run: npm test
- name: Build application
working-directory: apps/frontend
run: npm run build
- name: Build and push Docker image
uses: docker/build-push-action@v3
with:
context: apps/frontend
push: true
tags: ghcr.io/company/frontend:${{ github.sha }}
cache-from: type=gha
cache-to: type=gha,mode=max
CD阶段(GitOps同步):
# .github/workflows/cd.yaml
name: CD Pipeline
on:
workflow_run:
workflows: ["CI Pipeline"]
types:
- completed
push:
branches: [ main ]
paths:
- 'apps/**/kustomization.yaml'
- 'apps/**/deployment.yaml'
- 'infrastructure/**'
jobs:
deploy-staging:
if: ${{ github.event.workflow_run.conclusion == 'success' && github.ref == 'refs/heads/main' }}
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Update image version in staging
working-directory: apps/frontend/staging
run: |
yq eval '.images[0].newTag = "${{ github.sha }}"' -i kustomization.yaml
- name: Create Pull Request to staging
uses: peter-evans/create-pull-request@v4
with:
token: ${{ secrets.GITHUB_TOKEN }}
branch: update-frontend-staging-${{ github.sha }}
base: main
title: "Update frontend to ${{ github.sha }} in staging"
body: |
This PR updates the frontend application to the latest build.
Build SHA: ${{ github.sha }}
CI status: ${{ github.event.workflow_run.conclusion }}
commit-message: "chore: update frontend to ${{ github.sha }} in staging"
deploy-production:
needs: deploy-staging
if: ${{ github.event.workflow_run.conclusion == 'success' && github.ref == 'refs/heads/main' }}
runs-on: ubuntu-latest
environment: production
steps:
- uses: actions/checkout@v3
- name: Update image version in production
working-directory: apps/frontend/production
run: |
yq eval '.images[0].newTag = "${{ github.sha }}"' -i kustomization.yaml
- name: Create Pull Request to production
uses: peter-evans/create-pull-request@v4
with:
token: ${{ secrets.GITHUB_TOKEN }}
branch: update-frontend-production-${{ github.sha }}
base: main
title: "Update frontend to ${{ github.sha }} in production"
body: |
This PR updates the frontend application to the latest build.
Build SHA: ${{ github.sha }}
CI status: ${{ github.event.workflow_run.conclusion }}
Staging deployment: ${{ needs.deploy-staging.result }}
commit-message: "chore: update frontend to ${{ github.sha }} in production"
自动化镜像更新:
# apps/frontend/image-update.yaml
apiVersion: image.toolkit.fluxcd.io/v1beta1
kind: ImageUpdateAutomation
meta
name: frontend-auto-update
namespace: flux-system
spec:
git:
checkout:
ref: main
branch: auto-update-frontend
commit:
author:
name: fluxcdbot
email: fluxcdbot@example.com
messageTemplate: |
Automated image update for frontend
- Image: ghcr.io/company/frontend:${BRANCH}
- Time: ${DATE}
push:
branch: main
interval: 1h0m0s
update:
path: ./apps/frontend
strategy: Setters
sourceRef:
kind: GitRepository
name: gitops-repo
这个CI/CD流水线实现了完整的GitOps工作流:
- CI阶段:代码变更触发构建、测试和镜像构建
- Staging部署:自动创建PR更新staging环境配置
- 人工审批:团队成员Review PR,确认staging环境正常
- Production部署:审批通过后,自动创建PR更新production环境
- 自动化监控:系统自动同步Git仓库变更,部署应用
- 镜像自动化:新镜像构建成功后,自动更新Kubernetes配置
通过这种工作流,Kurator实现了安全、可靠、可审计的软件交付过程,大大提高了交付效率和质量。
八、【前瞻创想】Kurator云原生技术发展与企业数字化转型战略
8.1 云原生技术融合创新方向
随着云原生技术的快速发展,Kurator为代表的分布式云原生平台正在引领新一轮的技术融合创新。基于多年的云原生社区参与经验,我认为以下几个方向将成为未来3-5年的关键创新点:
1. 智能调度与自愈系统:
当前的调度系统主要基于静态规则和简单算法,未来的调度器将深度融合AI/ML技术,实现:
- 工作负载预测:基于历史数据预测资源需求,提前进行资源分配
- 故障预测:通过分析系统指标,预测潜在故障,主动迁移工作负载
- 能耗优化:考虑数据中心PUE、碳排放等因素,实现绿色调度
- 成本动态优化:根据实时市场价格、预留实例使用率等,动态调整资源分配
# 伪代码:AI增强的调度决策
def ai_scheduling_decision(pod, clusters):
# 特征工程
features = extract_features(pod, clusters)
# 预测各集群的执行时间、成本、成功率
predictions = prediction_model.predict(features)
# 多目标优化:时间 + 成本 + 可靠性
scores = []
for i, cluster in enumerate(clusters):
time_score = 1.0 / (predictions[i]['execution_time'] + 1)
cost_score = 1.0 / (predictions[i]['cost'] + 1)
reliability_score = predictions[i]['success_rate']
# 权重可配置
total_score = (0.5 * time_score +
0.3 * cost_score +
0.2 * reliability_score)
scores.append((cluster.name, total_score))
# 选择最优集群
best_cluster = max(scores, key=lambda x: x[1])[0]
return best_cluster
2. 云边端一体化架构:
边缘计算和终端设备的快速发展,要求云原生平台支持真正的云-边-端一体化:
- 层次化调度:工作负载可以在云、边缘、终端之间动态迁移
- 数据亲和性:计算任务优先调度到数据所在位置,减少数据传输
- 异构硬件抽象:统一抽象GPU、TPU、FPGA、NPU等异构硬件
- 轻量级运行时:为资源受限的终端设备提供轻量级容器运行时
3. 安全内生设计:
安全将成为云原生平台的核心设计原则,而非附加功能:
- 零信任架构:默认不信任任何组件,基于身份和上下文进行访问控制
- 机密计算:在可信执行环境(TEE)中运行敏感工作负载
- 自动合规:自动生成合规报告,实时监控策略违反
- 供应链安全:从代码到运行时的完整供应链安全验证
8.2 企业数字化转型战略建议
基于Kurator的技术能力,我为企业数字化转型提出以下战略建议:
1. 架构现代化演进路径:
企业不应一次性重构所有系统,而应采用渐进式演进策略:
- 评估与规划:识别核心业务系统,评估云原生就绪度
- 试点项目:选择非关键但有代表性的业务系统进行试点
- 平台建设:构建企业级云原生平台,统一技术栈和标准
- 规模化推广:逐步将更多系统迁移到云原生平台
- 持续优化:基于运行数据持续优化架构和成本
2. 组织与文化变革:
技术变革必须伴随组织和文化变革:
- 平台工程团队:建立专门的平台工程团队,负责云原生平台建设
- DevOps文化:打破开发和运维的壁垒,建立共享责任的文化
- 技能提升:投资员工技能提升,特别是云原生、自动化、可观测性等领域
- 度量与激励:建立正确的度量体系,激励团队关注业务价值而非技术指标
3. 成本优化策略:
云原生技术虽然带来灵活性,但也可能增加成本,需要精细化管理:
- FinOps实践:建立云财务管理团队,实施持续的成本优化
- 混合部署:核心系统在私有云,弹性部分在公有云,实现成本和性能平衡
- 自动化伸缩:基于实际负载自动调整资源,避免资源浪费
- 预留实例优化:结合预测分析,优化预留实例购买策略
8.3 Kurator生态发展与社区建设
Kurator作为开源项目,其成功不仅依赖技术,更依赖活跃的社区和健康的生态。我建议从以下几个方面推动Kurator生态发展:
1. 供应商中立战略:
- 多云支持:确保对主流云提供商(AWS/Azure/GCP/阿里云/腾讯云)的平等支持
- 开源优先:核心功能保持开源,避免供应商锁定
- 标准遵循:积极参与CNCF等标准组织,推动行业标准
2. 开发者体验优化:
- 简化入门:提供一键部署、交互式教程、沙盒环境
- 文档质量:投资高质量文档,包括概念解释、实践指南、故障排除
- 工具链集成:与主流IDE(VSCode/IntelliJ)、CI/CD工具(Jenkins/GitHub Actions)、监控工具(Prometheus/Grafana)深度集成
3. 企业支持体系:
- 认证培训:建立Kurator认证体系,培养专业人才
- 商业支持:与合作伙伴共建商业支持网络,为企业用户提供SLA保障
- 成功案例:积累和分享各行业成功案例,证明技术价值
4. 创新孵化机制:
- 研究合作:与高校、研究机构合作,探索前沿技术
- 创新基金:设立创新基金,资助有潜力的子项目
- 黑客松活动:定期组织黑客松,激发社区创造力
# 伪代码:Kurator社区贡献者成长路径
def contributor_journey():
# 阶段1:用户
start_as_user()
report_bugs()
ask_questions_in_community()
# 阶段2:贡献者
fix_documentation_typos()
write_tutorials()
contribute_small_bug_fixes()
# 阶段3:核心贡献者
design_new_features()
review_pull_requests()
mentor_new_contributors()
# 阶段4:维护者
make_architectural_decisions()
manage_release_process()
represent_project_in_community()
# 持续学习
attend_conferences()
participate_in_cnfc_events()
collaborate_with_other_projects()
Kurator的未来发展不应仅仅关注技术实现,更要关注如何为企业创造实际价值,如何培养健康的开源生态,如何推动整个云原生技术向前发展。通过技术、社区、商业的三轮驱动,Kurator有望成为分布式云原生领域的标杆项目,为中国乃至全球的数字化转型贡献力量。
作为云原生技术从业者,我们有幸站在技术变革的前沿。Kurator不仅是一个技术平台,更是一个连接开发者、企业、社区的桥梁。让我们携手共建,推动云原生技术在更广泛的场景中落地生根,为数字经济的发展注入新的活力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)