咱们聊聊怎么用Kurator终结多云痛苦:从环境搭建到搞定分布式架构的保姆级实操指南
咱们聊聊怎么用Kurator终结多云痛苦:从环境搭建到搞定分布式架构的保姆级实操指南
好久不见,我是你们的云原生老司机。你需要一个能统管全局的“带头大哥”,这就是Kurator。简单说,它就是给你的K8s集群们找了个“管家”,把那些复杂的分布式管理、流量治理、策略下发全给你包圆了。今天我就带大家扒开Kurator的底裤,看看它是怎么把分布式云原生架构玩出花的。
第一章:扒一扒Kurator的“骨架”与分布式云原生的野心
咱们先别急着敲键盘,得先搞清楚Kurator这货到底长啥样。很多兄弟觉得分布式云原生听着高大上,其实说白了就是把以前单集群解决不了的事儿,放到多集群甚至多云环境里去解决。
1.1 分布式云原生架构与Kurator的定位
现在的业务场景太复杂了,你不可能把所有鸡蛋放在一个篮子里。分布式云原生架构的核心痛点在于“割裂”——网络割裂、配置割裂、监控割裂。Kurator作为开源的分布式云原生平台,它的架构设计初衷就是为了缝合这些裂痕。
这就引出了Kurator架构和Kurator平台的总体架构。你可以把它想象成一个三层汉堡:
- 最底层是基础设施层,也就是大家熟悉的Kubernetes集群的标准架构,不管是你要接阿里云的ACK,还是自建的Kubeadm集群,Kurator都认。
- 中间层是Kurator的核心控制平面,这里包含了舰队管理(Fleet)、策略中心、应用分发中心。
- 最上层是统一的API网关和操作入口。
这种架构最骚的地方在于,它不是为了取代K8s,而是为了增强K8s。它通过自定义CRD(Custom Resource Definition)把多云管理的逻辑“寄生”在K8s之上,让你用管理一个Pod的方式去管理一堆集群。
这是分布式云原生架构的参考图,展示了如何通过统一应用治理、数据融合、安全及资源调度,实现对多云、本地及边缘异构集群的一体化管理: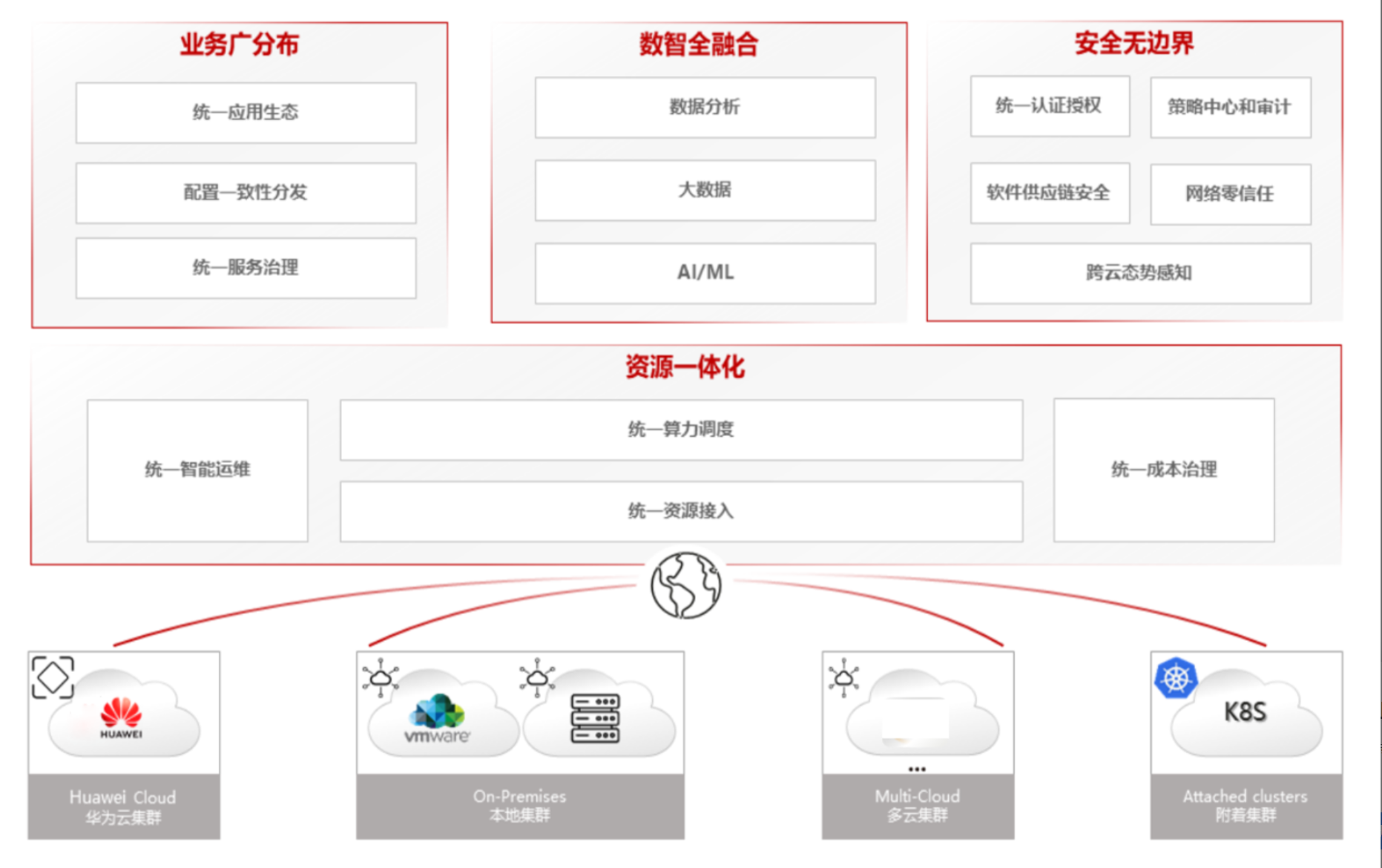
1.2 深入Cluster Operator的实现逻辑
那它是怎么控制下游集群的呢?这就得聊聊Cluster Operator的实现了。这是我个人觉得Kurator里最迷人的部分。
传统的做法是写脚本,SSH上去一顿操作,容易出错还不好回滚。Kurator搞了个Operator模式。它在主控集群里跑了一个Controller,这玩意儿盯着一种叫Cluster的资源对象。当你在YAML里写“我要一个AWS集群”,这个Operator就会监听到这个变化,然后调用底层的API(比如Cluster API或者通过KubeConfig直连)去驱动目标状态。
这个Operator内部其实维护了一个Kurator分发流程的状态机。这个状态机非常严谨,通常包含 Pending(等待中)、Provisioning(创建中)、Syncing(同步中)、Ready(就绪)和 Failed(失败)这几种状态。每一个状态的流转都有严格的条件检查,比如网络通不通、认证过没过。这就保证了我们在分发应用或者配置集群时,不会出现“发了一半卡住了但显示成功”这种坑爹情况。
这张图展示了Cluster Operator的实现细节,其实就是用户通过声明一个CRD,触发API Server事件,然后由Operator监听并调度多个管理worker去自动对接和管理不同的本地集群,整个过程用无密码认证打通,既安全又高效: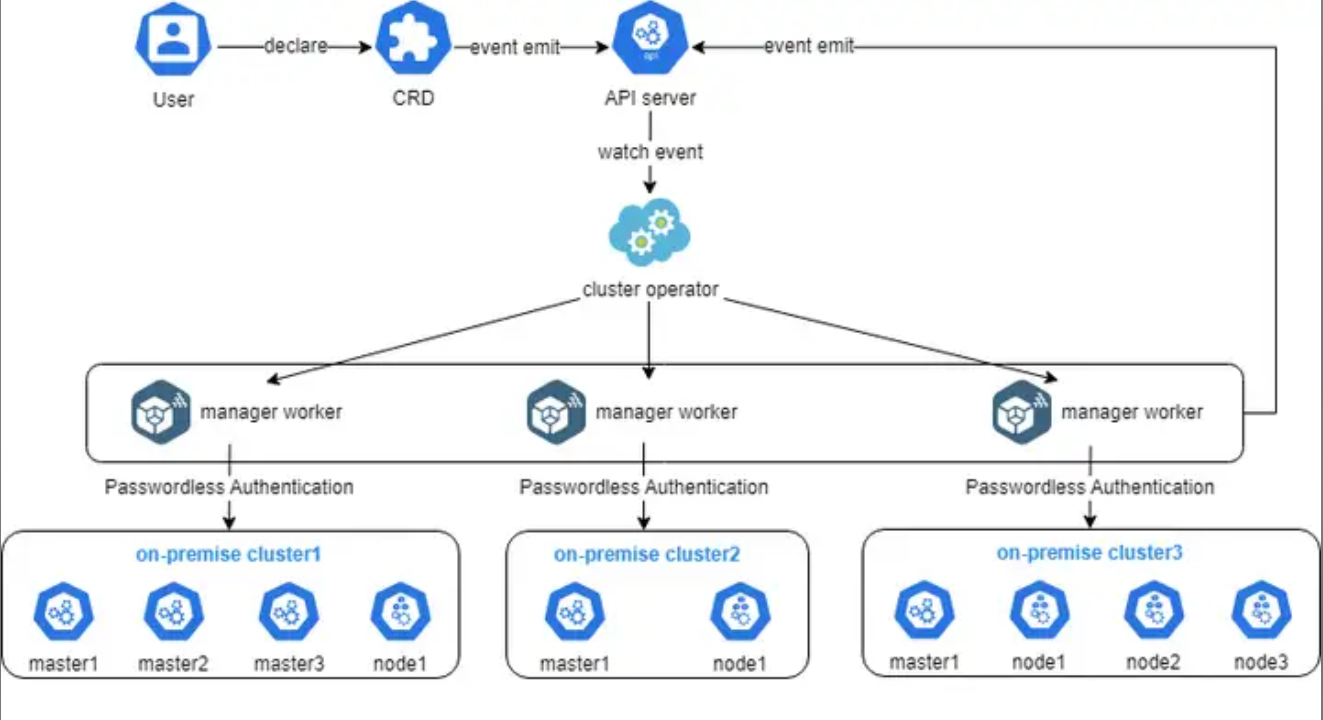
第二章:别废话,先把环境跑起来(实操搭建)
光说不练假把式。咱们现在就动手,在本地或者你的测试机上把Kurator这一套环境给支棱起来。这一步非常关键,环境搭不好,后面讲的流量路由全是白搭。
2.1 准备工作与代码拉取
首先,你得有个Linux环境或者Mac,Docker得装好吧?Go环境也得有,毕竟咱们是搞云原生的。
接下来,最重要的一步,把源码拉下来。咱们用国内的源,速度快点:
# 兄弟们,这个命令一定要敲对,别去下那些老掉牙的包了
# 直接从gitcode拉最新的源码,保证咱们讲的功能都在
git clone https://gitcode.com/kurator-dev/kurator.git
cd kurator
# 看看这一堆文件,这就是咱们的军火库
ls -F
可以看到这是项目的gitCode源码
我们可以拉取下来
源码文件如下,接下来就可以使用了
可以注意到,这个命令kurator version可以看到版本号
2.2 初始化控制平面
这里我们不需要真的去买十台云服务器,我们可以用Kind或者Minikube模拟多集群。但核心的Kurator控制平面,我们需要先把它安装到我们的“管理集群”里。
通常我们会跑一个安装脚本,或者直接用Helm。但我建议大家手搓一下Makefile里的命令,这样能看到它到底装了啥。
Kurator集群生命周期管理在这里就体现出来了。当你执行安装命令时,Kurator会自动安装Cluster API的组件,还会把Cert Manager这些依赖都装好。它实际上是在你的管理集群里构建了一套“生产线”。
这是一个手搓的简单Cluster配置示例,咱们假装要纳管一个本地集群:
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
metadata:
name: my-test-cluster
namespace: default
spec:
# 这里是关键,告诉Kurator这玩意儿在哪
# 咱们实操的时候,通常直接把kubeconfig塞进去
kubeConfigSecretRef:
name: my-cluster-kubeconfig
# 标记一下,这是个测试环境,以后策略管理要用
labels:
env: staging
region: beijing
把这个YAML apply进去,如果你的Operator工作正常,状态机就会开始转动,从Unknown变成Ready,这时候你就完成了纳管的第一步。
第三章:云原生舰队与统一策略管理(像指挥官一样操作)
环境通了,现在你手头可能有几十个集群了,总不能一个个去apply YAML吧?这时候就要用到“舰队”的概念了。
3.1 玩转云原生舰队管理
这张图讲的是云原生舰队管理,就是通过一个管理中心集群来统一管理多个下属集群,不管是创建、注册还是部署应用,都可以集中控制: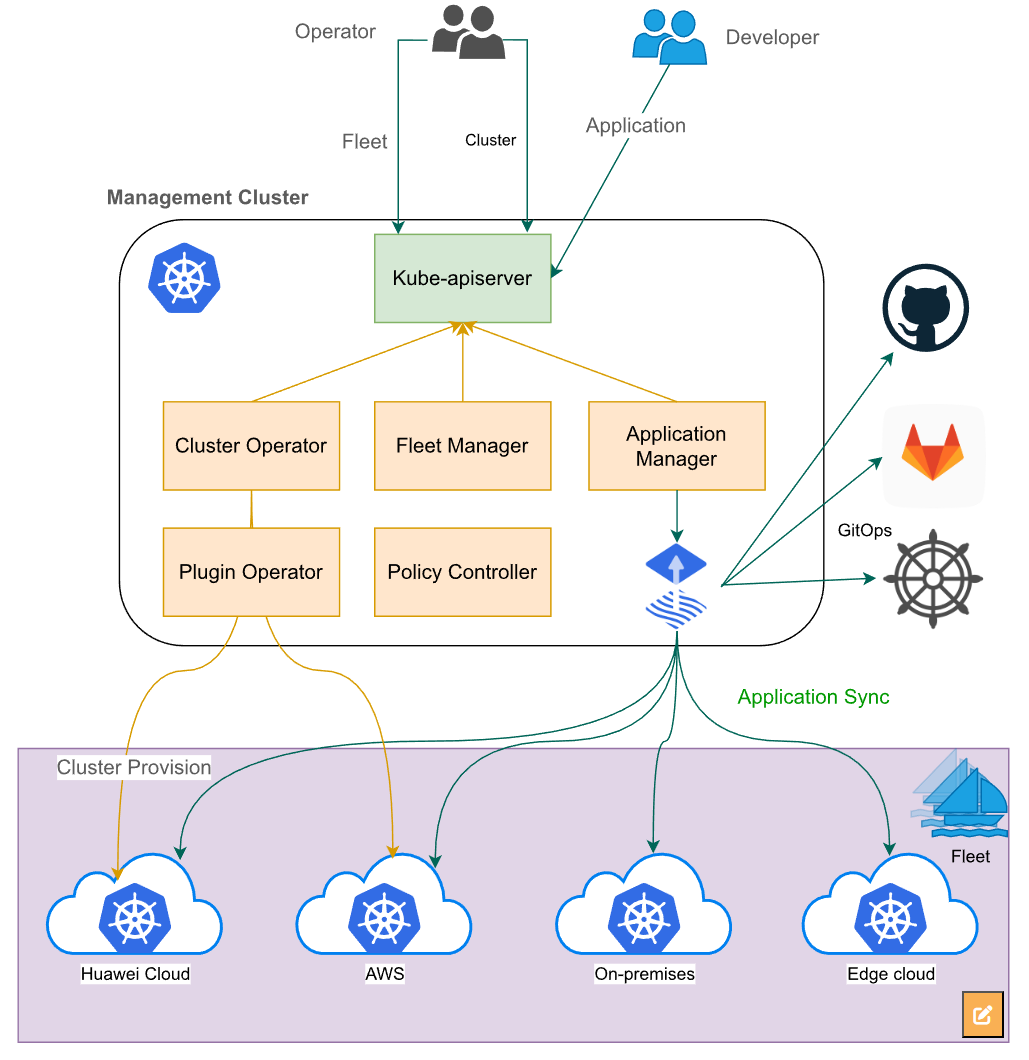
云原生舰队管理(Fleet Management)是Kurator用来解决“批量操作”的神器。你可以把所有的开发环境集群打上 tag: dev,把生产环境打上 tag: prod。
Kurator允许你定义一个Fleet对象。比如,“所有北京区域的集群”就是一个舰队。当你需要发布一个应用时,你不需要指定具体的集群名字,你只需要说“把这个应用发给北京舰队”。Kurator会自动去解析这个舰队里包含哪些集群,并且动态监控。如果你明天新加了一个北京的集群,应用会自动同步过去,这就是自动化的魅力。
3.2 统一策略管理架构的实战
这张图展示了Kurator的统一策略管理架构,用户只需要在一处定义策略,就能通过Fleet和FluxCD自动同步到多个集群,配合Kyverno实现跨集群的一致性治理,真正做到“一次配置,全栈生效”: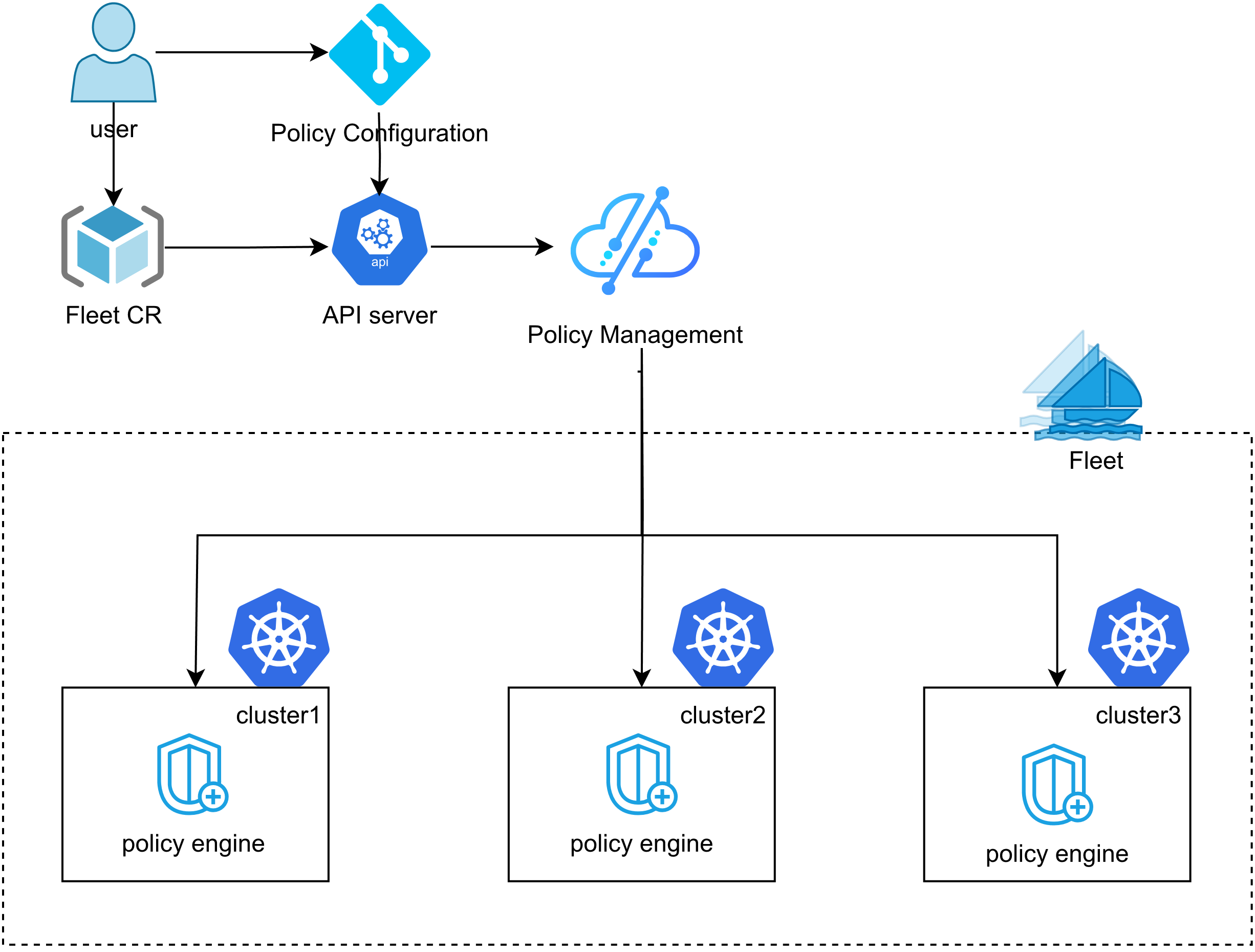
管好人不容易,管好集群更难。Kurator的统一策略管理架构基于OPA(Open Policy Agent)或者Kyverno,但Kurator做了一层更高级的抽象。
想象一下,你作为平台管理员,要强制要求所有生产环境的Pod都必须限制CPU和内存配额,或者禁止使用 latest 标签的镜像。在Kurator里,你只需要写一条策略。
这条策略会通过Kurator的分发机制,下发到所有属于“生产舰队”的集群里。如果有人试图在一个边缘集群里违规部署,Kurator立马就会拦截,并报警。这就是Unified Policy Management。它把零散的规则集中化了,不管你下面是阿里云还是腾讯云,规矩是我定的。
3.3 状态机在分发中的作用
刚才提到了Kurator分发流程的状态机,在策略下发时也起作用。它会确保策略在所有目标集群都生效。如果某个集群网络断了,状态机会标记为 SyncFailed,并不断重试,直到网络恢复。这比那种“发出去就不管”的脚本强一万倍。
第四章:流量治理与AB测试(精细化运营的杀手锏)
基础设施搞定了,接下来就是业务层面的事儿了。这年头,谁还没个灰度发布、蓝绿部署的需求?
4.1 Kurator的流量路由黑科技
这是Kurator的流量路由参考图,展示了其如何通过入口网关和服务网格技术,在金丝雀发布中实现精确的流量分割与路由控制: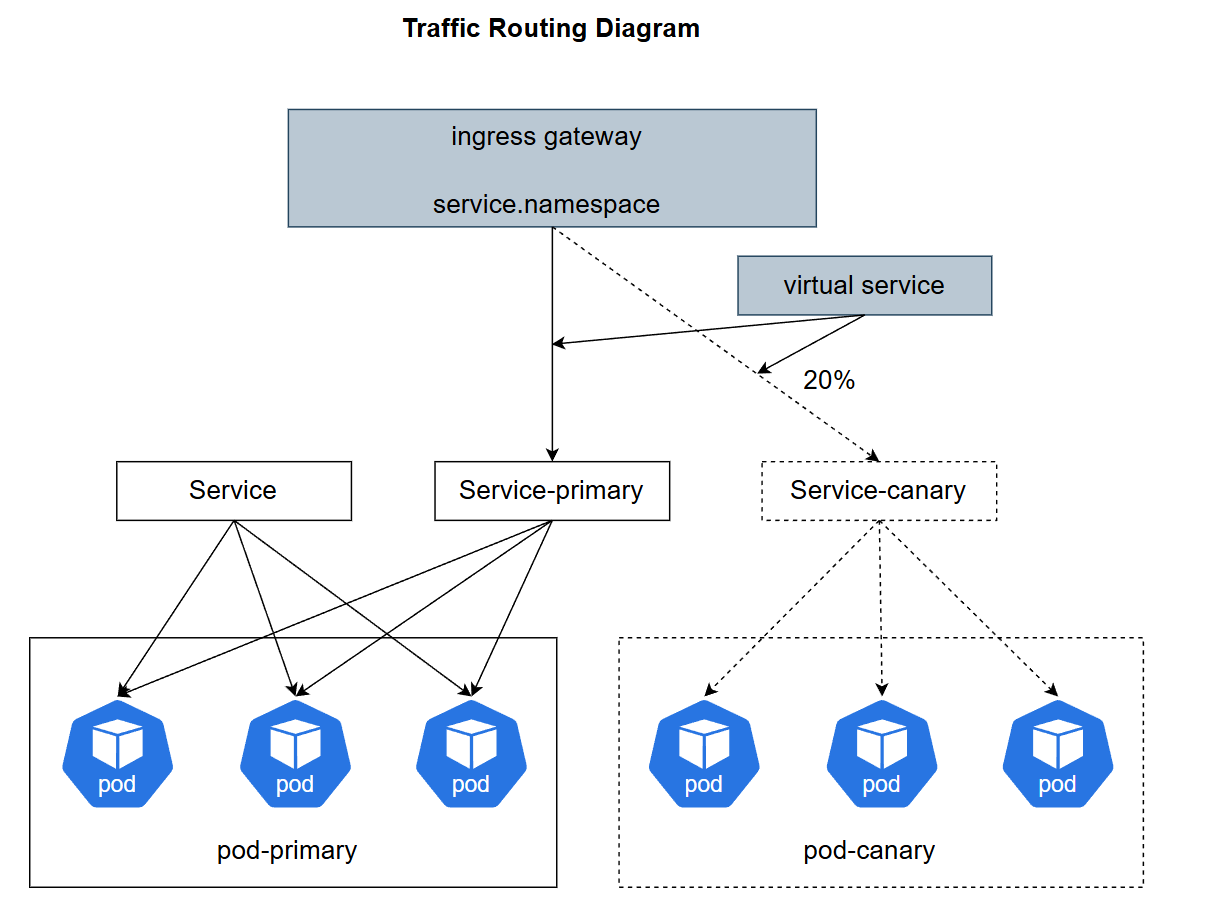
Kurator的流量路由机制是基于Istio或者Gateway API封装的。但在多集群场景下,这就很复杂了。Kurator提供了一种全局流量策略。
比如,你有两个集群,一个在上海,一个在深圳。你想让上海的用户访问上海的集群,深圳的访问深圳的。或者,当上海集群爆满时,自动把20%流量切到深圳。Kurator通过DNS策略和全局负载均衡(GSLB)的配置集成,让你在CRD里就能配好这些规则,不用去改底层的Nginx配置。
4.2 手把手教你配置A/B测试
Kurator中配置A/B测试是我觉得最实用的功能之一。以前做AB测试,开发得改代码,运维得改网关,累得半死。在Kurator里,这被抽象成了一个 Rollout 对象。
我们要实操一下,假设我们有一个Web服务,要上个新版本,只想让10%带有 header: ios 的用户看到。
看看这代码,是不是很亲切,这就是咱们日常要写的配置:
apiVersion: apps.kurator.dev/v1alpha1
kind: ApplicationPolicy
metadata:
name: web-ab-test
spec:
targetRef:
name: my-web-app
trafficRouting:
# 这里定义我们要用的网关类型,Kurator支持多种
provider: istio
analysis:
# 这里配置AB测试的各种指标,比如错误率不能超过1%
metrics:
- name: request-success-rate
threshold: 99
strategy:
canary:
steps:
# 第一步,切5%流量,如果有特定的header匹配
- setWeight: 5
match:
- headers:
user-agent:
regex: ".*iPhone.*"
# 暂停一下,人工确认没问题再继续
- pause: {}
- setWeight: 50
这段配置一旦生效,Kurator底层的Controller就会去调整VirtualService和DestinationRule,你根本不用操心Istio那些复杂的CRD。
这是在Kurator中配置A/B测试的YAML示例,展示了如何基于用户代理和Cookie的头部匹配规则进行精细化流量分割与多维度指标分析: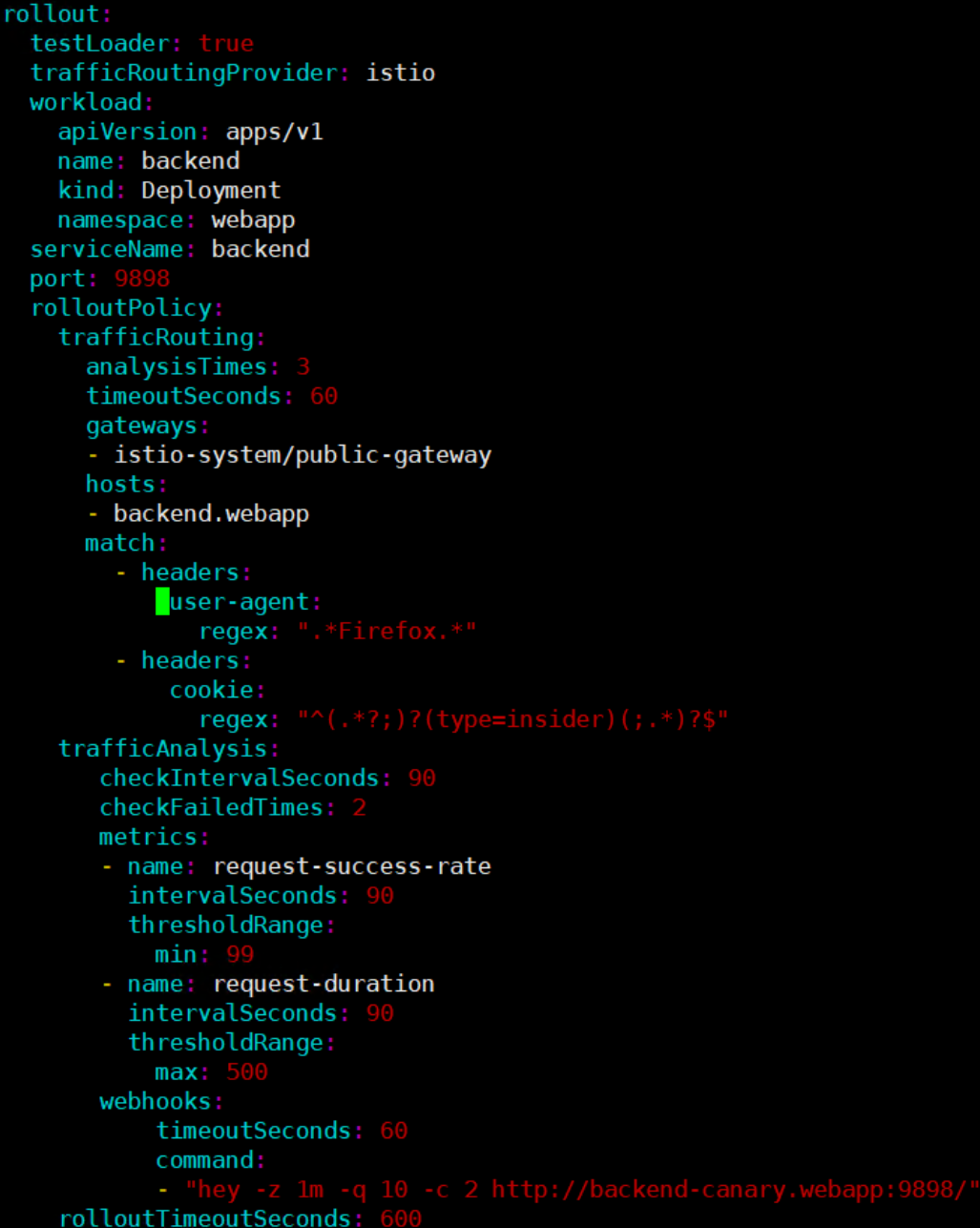
第五章:搞定算力调度与Volcano集成(给AI任务加个塞)
最后,咱们得聊聊算力。现在的业务,不仅仅是跑个Web服务那么简单,还有大量的AI训练、大数据处理任务。这就涉及到了Volcano分组调度。
5.1 为什么需要Volcano?
Kubernetes原生的调度器是针对Service这种长期运行服务的,对于批处理任务(Batch Jobs)其实挺笨的。比如我要跑一个分布式的TensorFlow训练,需要10个Pod同时启动才能跑,如果资源只够启动5个,K8s原生调度器就会把这5个先起起来占着坑,结果大家都跑不起来,这就叫“死锁”。
Kurator集成了Volcano,就是为了解决这个问题。
5.2 Volcano分组调度实战
这是Volcano分组调度参考图,展示了其如何通过整体资源检查与阈值判断,实现批处理作业的成组调度与资源保障: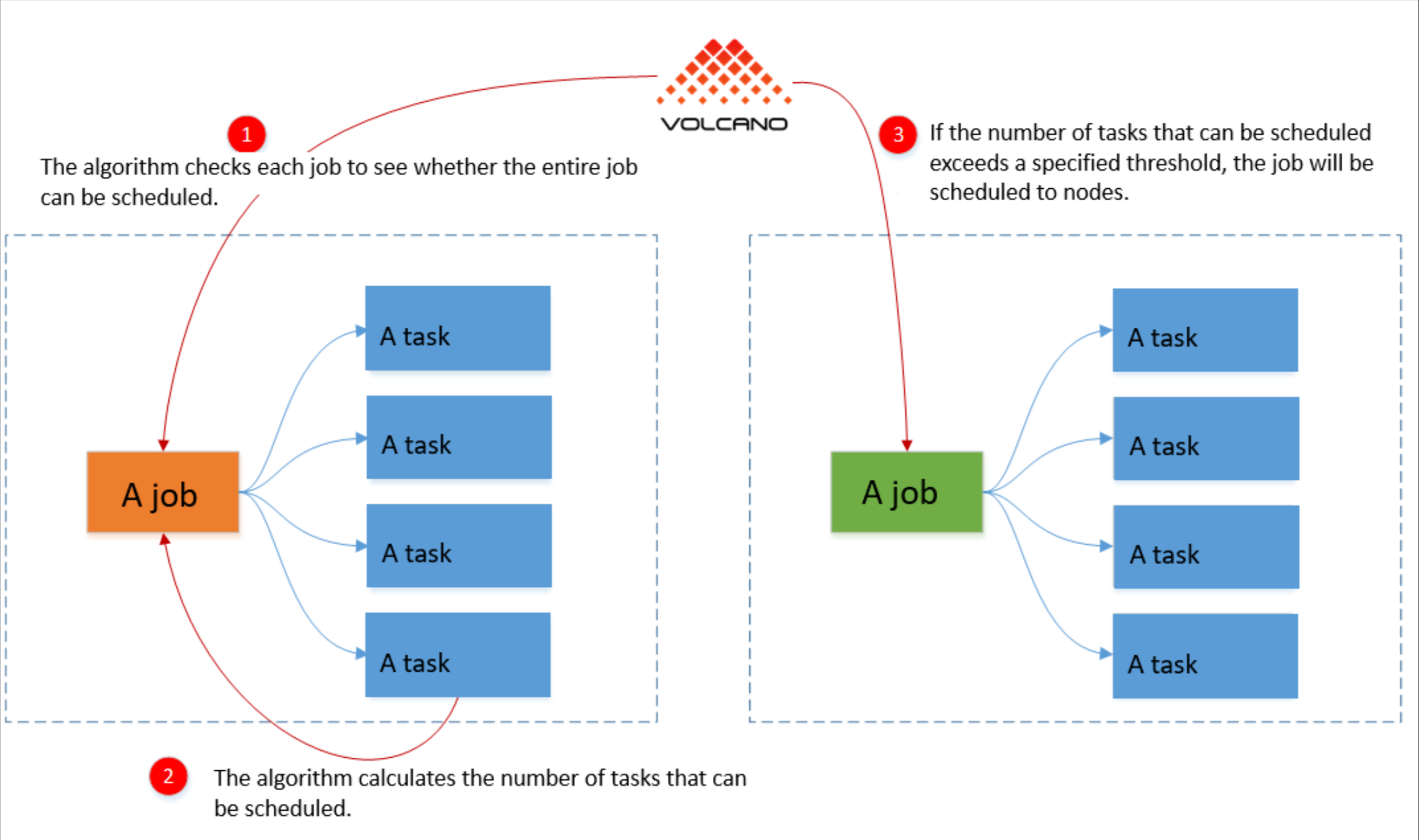
在Kurator里启用Volcano能力后,我们可以定义PodGroup。Volcano分组调度的核心就是Gang Scheduling(帮派调度)。意思是:这帮兄弟(Pod),要么一起上,要么谁也别上,别占着茅坑不拉屎。
这对于资源昂贵的GPU集群来说太重要了。Kurator允许你在定义应用分发时,直接挂载Volcano的调度策略。
下面这个代码块,展示了如何在Kurator管理的集群中声明一个需要Gang Scheduling的任务:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: ai-training-job
spec:
# 最小成员数,必须要够3个兄弟才能开工
minAvailable: 3
schedulerName: volcano
queue: default
tasks:
- replicas: 3
name: worker
template:
spec:
containers:
- command:
- "python"
- "/app/train.py"
image: my-ai-image:v1
# 申请点硬通货资源
resources:
limits:
nvidia.com/gpu: 1
restartPolicy: OnFailure
5.3 总结一下Kurator的架构优势
写到这,大家应该看出来了。Kurator不仅仅是一个工具,它是一种分布式云原生架构的最佳实践落地。
从最底层的Kubernetes集群的标准架构接入,到中间利用Cluster Operator进行Kurator集群生命周期管理,再通过云原生舰队管理把几十个集群拧成一股绳。
在应用层面,它通过Kurator的流量路由和Kurator分发流程的状态机保证业务平滑上线,利用Kurator中配置AB测试提升业务敏捷性,最后还能通过Volcano分组调度榨干硬件性能。
说实话,云原生走到今天,单打独斗的时代结束了。Kurator这种大一统的平台架构,才是咱们SRE和DevOps未来的救命稻草。希望这篇实操文能帮大家入个门,还是那句话,别光看,赶紧把 git clone 敲起来,跑起来才是自己的!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 30
30 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)