Kurator 老司机带你玩转云原生“多对多”高阶治理
Kurator 老司机带你玩转云原生“多对多”高阶治理
嘿,兄弟,听我一句劝
咱们搞技术的,最怕陷在无休止的重复造轮子和“填坑”循环里。前几年大家都在卷 K8s 单集群,那时候能把一个集群玩溜了就是大神。但现在呢?业务上云、边缘计算、多云灾备,手里没个十几二十个集群都不好意思出门跟人打招呼。
这就是我今天要跟你们聊聊 Kurator 的原因。别去啃那些晦涩的官方文档了,那上面写的“统一资源编排”、“分布式云原生平台”虽然都对,但太干。在我这个“老司机”眼里,Kurator 就是一把云原生时代的瑞士军刀。它不是要替代 K8s,而是把 Karmada(多集群编排)、Volcano(批量计算调度)、KubeEdge(边缘计算)、Prometheus(监控)这些顶级开源项目揉在了一起,给你提供了一个开箱即用、逻辑自洽的“总控台”。
简单说,以前你需要分别去学怎么管多集群、怎么做边缘、怎么搞批量任务,现在 Kurator 告诉你:“歇着吧,这些脏活累活我全包了。”它就像是一个经验丰富的包工头,你只需要告诉它“我要盖楼”,剩下的找人(集群)、买料(资源)、施工(部署),它都有现成的套路。
一、 把集群当“牛羊”管:Fleet 与生命周期管理野路子
我们要聊的第一个点,不是怎么安装,而是思维方式的转变。以前我们把集群当“宠物”,精心呵护;现在有了 Kurator,你得把它们当“牛羊”(Cattle),这就要用到 Fleet(舰队) 的概念。
1. 揭秘 Fleet 集群注册的“暗箱操作”
这是Fleet集群注册机制的官方示意图,展示了中央控制器如何通过令牌统一纳管边缘及多区域集群: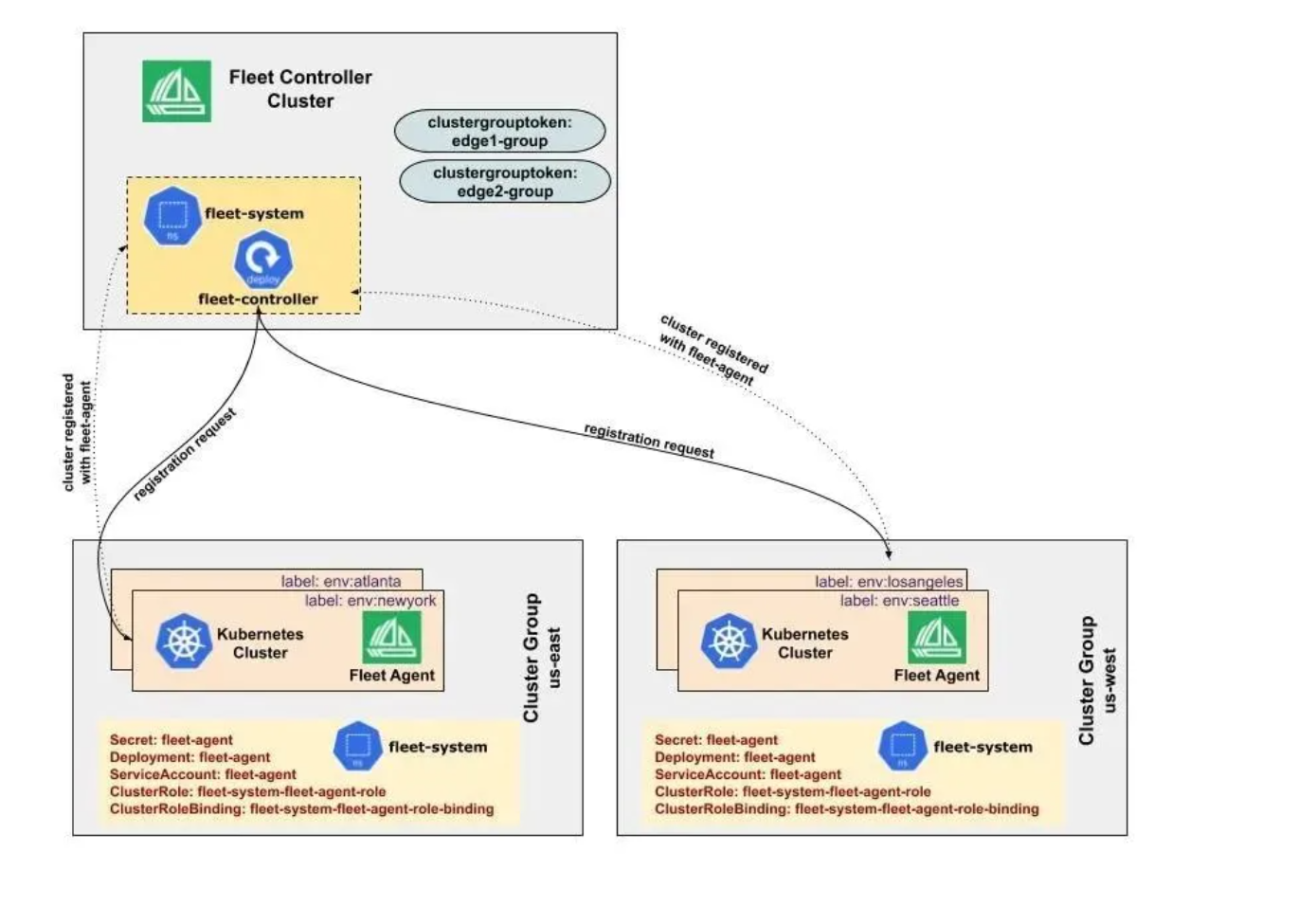
很多兄弟用 Kurator 最爽的一点就是“纳管”。不管你是谁家的集群,只要想进我的舰队,流程那叫一个丝滑。这背后其实是 Fleet 集群注册机制在发力。
当你发起一个注册请求时,Kurator 会生成一个 ClusterRegistrationToken。这玩意儿就像是“入场券”。目标集群里运行的 fleet-agent 拿到这个 Token 后,会通过 import.go 里的逻辑,向控制面发起“投诚”请求。
这里有个坑要注意:网络连通性。控制面必须能被 Agent 访问到。一旦握手成功,Kurator 会自动下发 kubeconfig,并在管理面创建一个对应的 Cluster 对象。这整个过程,就像是给新员工发工牌、开权限,全自动流水线。
2. Kurator Cluster Operator:从出生到入土的一条龙
这张图展示了Kurator Cluster Operator的整体架构,它通过监听API Server的资源变化,自动管理不同环境下的集群和机器: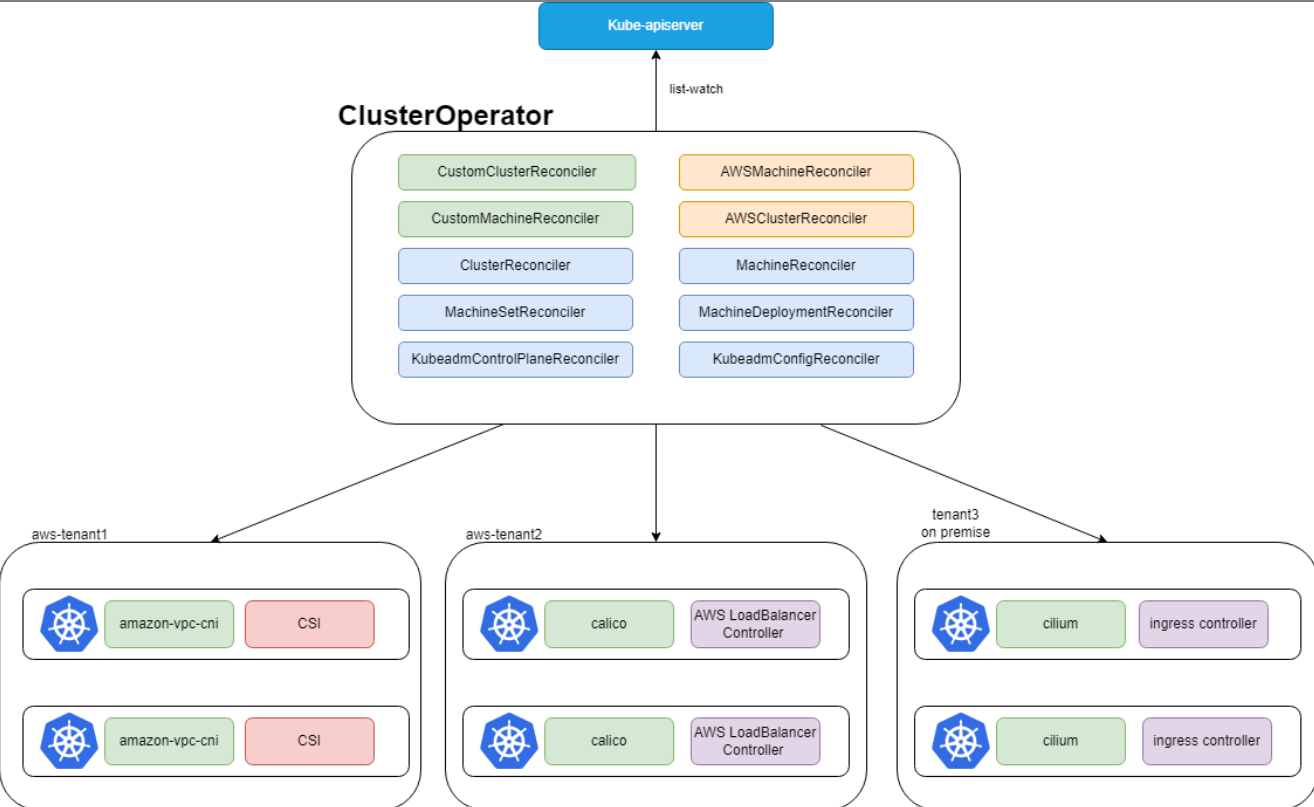
要是你连集群都没有怎么办?这时候 Kurator Cluster Operator 就派上用场了。它的架构设计非常聪明,底层其实是基于 Cluster API (CAPI) 的。它把“建集群”这件事也变成了写 YAML。
你定义好通过 AWS、Azure 还是裸金属(Bare Metal)来起集群,Operator 就会像不知疲倦的工人一样,去对接底层的 Infra API。针对不同规模集群的分级优化策略在这里体现得淋漓尽致:对于小规模测试集群,它会精简控制面组件,节省资源;而对于生产级的大规模集群,它会自动配置高可用的 etcd 和控制面副本,还能根据负载动态调整节点池的大小。
3. 【实战插播】十分钟搞定环境搭建
光说不练假把式。咱们现在就来把环境拉起来。我知道很多教程都让你去配各种复杂的依赖,但在 Kurator 里,这事儿被简化了。
随便找台 Linux 机器(建议 4核8G 起步),打开终端,咱们开搞:
⚠️ 老司机提醒:国内网络环境有时候拉 GitHub 会抽风,所以我强烈建议用 gitcode 这个镜像源,速度起飞。
# 既然是实战,咱们就得快!直接拉取源码
git clone https://gitcode.com/kurator-dev/kurator.git
cd kurator
如果这个方法拉取不到的话,也可以用wget的方法拉取
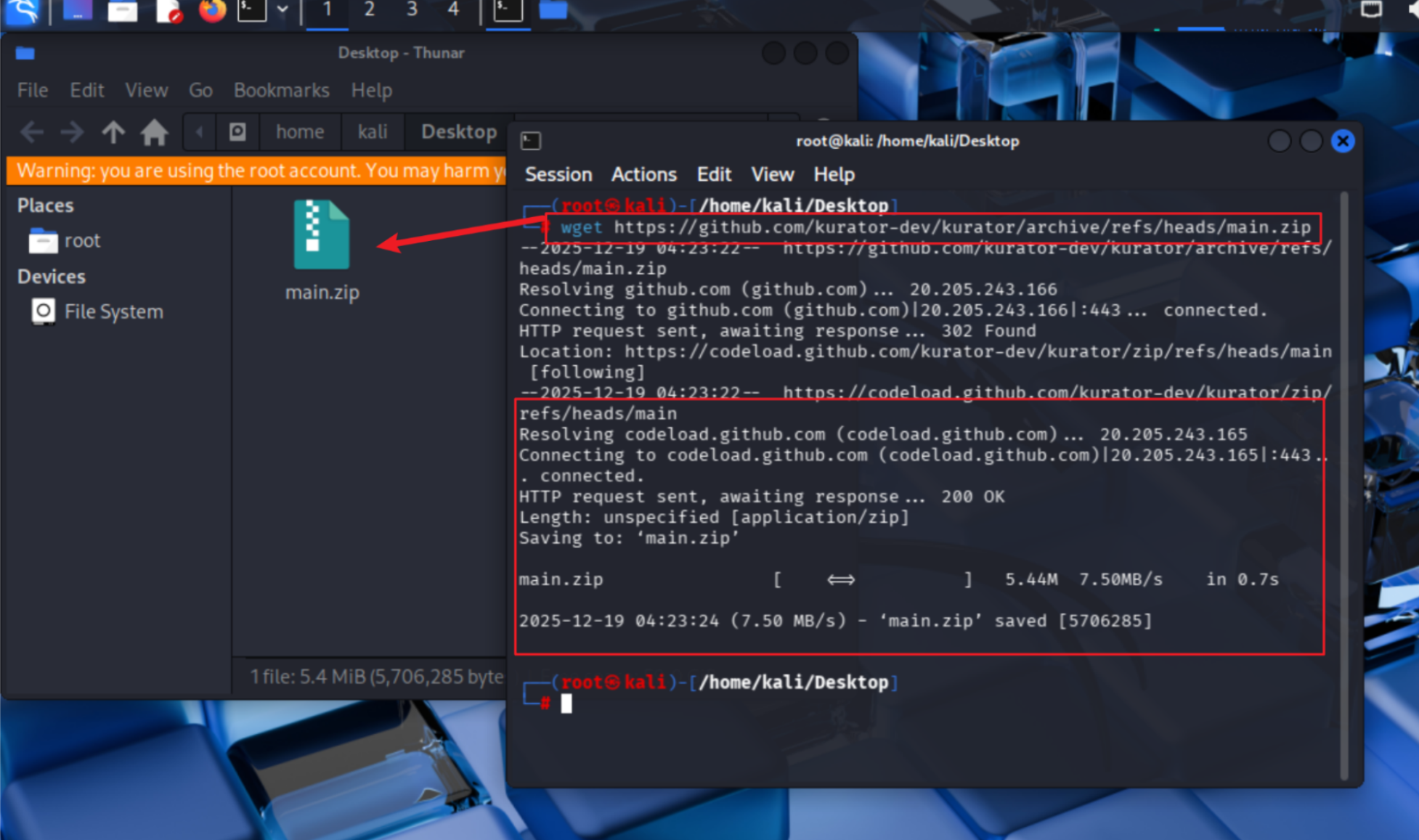
# 下载最新源代码zip包
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
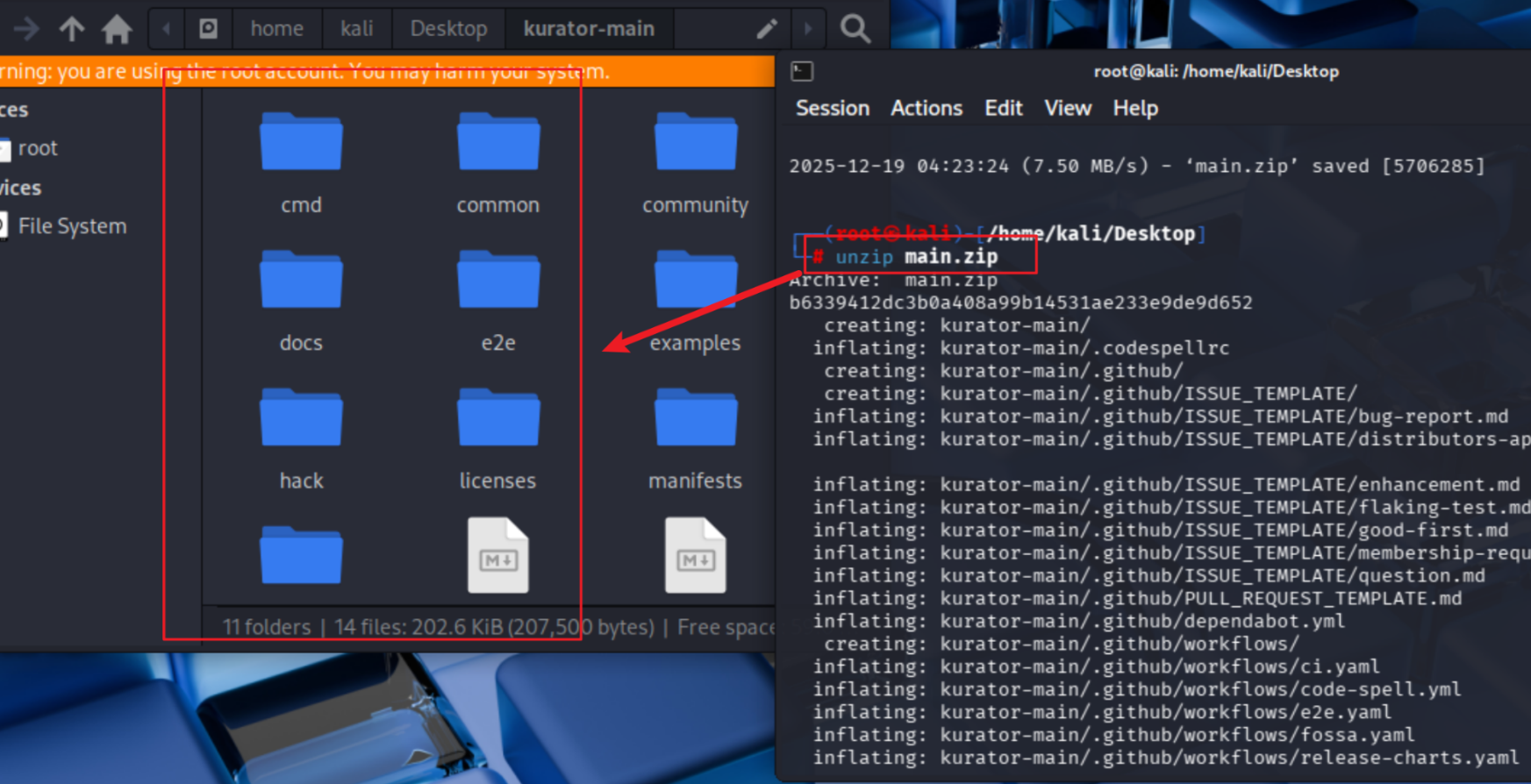
然后再解压文件
unzip main.zip
源码下载下来以后我们可以开始玩耍啦,接下来我们拿着源码就可以进行其他设置操作了。
二、 掌控全局的大脑:调度与多云编排的艺术
环境好了,集群有了,接下来的核心就是怎么用这些资源。Kurator 的核心价值全景路线图中,最性感的部分就是它的“大脑”。
1. Karmada:多集群管理的“上帝视角”
Kurator 集成了 Karmada 作为多集群管理的核心。Karmada 的总体架构分为控制面(Control Plane)和成员集群(Member Cluster)。它的精髓在于调度引擎。
传统的 K8s 调度是把 Pod 调度到 Node 上,而 Karmada 是把 应用(Resource)调度到集群(Cluster)上。它支持基于语义的调度策略(PropagationPolicy)。比如,你可以告诉它:“把这个应用给我部署到所有标签为 region=beijing 的集群里,且每个集群最多跑 3 个副本。”
Karmada 的调度器会实时收集各集群的剩余资源信息,结合 集群资源拓扑结构(比如带宽成本、延迟、资源碎片率),计算出最优的分布方案。这一步对用户是完全透明的,你感觉就像是在操作一个无限大的超级集群。
2. Volcano:不仅能算,还能“抢”
如果你的业务里有 AI 训练、大数据分析这种“吃资源大户”,K8s 原生的调度器绝对会让你崩溃(比如死锁、资源碎片)。Kurator 把 Volcano 搬进来就是为了解决这个问题。
Volcano 的工作流非常硬核。它引入了 Queue(队列)和 PodGroup 的概念。当一批任务提交上来时,Volcano 不会一个一个处理,而是把它们看作一个整体(Gang Scheduling)。
流程拆解:
- Enqueue:任务进队,根据优先级排序。
- Allocate:预分配资源,这里有个骚操作叫“DRF(主导资源公平算法)”,保证不同部门别打架。
- Preempt:关键时刻,高优先级任务可以直接抢占低优先级任务的资源。
- Backfill:利用大任务留下的碎片时间,塞进去小任务跑一跑,榨干集群的每一滴性能。
这是Volcano调度架构参考图,展示了其核心组件如何通过CRD、控制器和调度器协同工作,实现对批量计算作业的统一管理: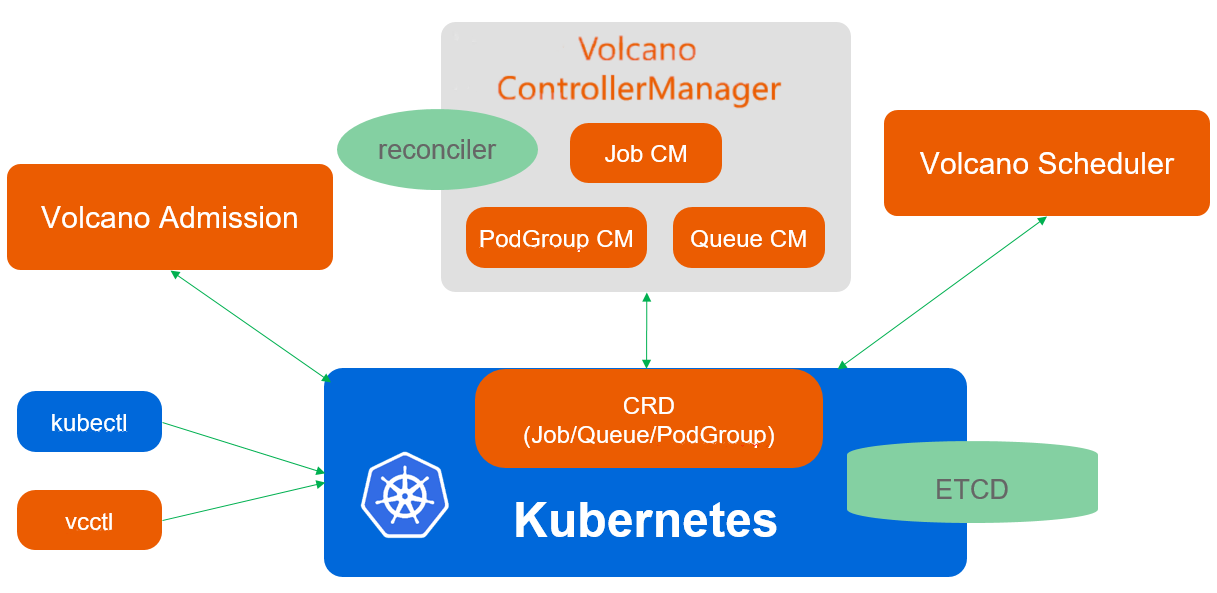
三、 像做手术一样精准:流量治理与应用交付
咱们继续深入。资源有了,应用跑起来了,接下来就是流量和升级的事儿。这块儿 Kurator 结合了 GitOps 和 Service Mesh,玩得那叫一个花。
1. GitOps 流水线:把运维变成代码 Commit
这是GitOps工作流的官方参考图,展示了从代码提交到镜像构建,最终由GitOps控制器实现集群自动部署的完整流程: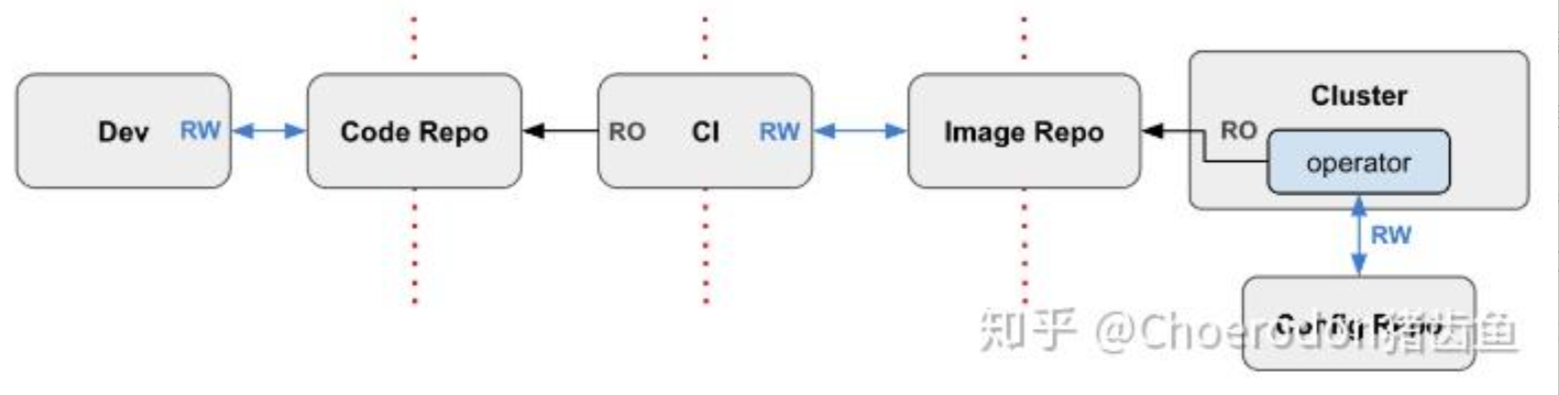
在 Kurator 里,GitOps 不仅仅是个概念,是实实在在的操作流程。它集成了 FluxCD。你不需要再手动 kubectl apply 了。
真实操作流程:
- 你把应用的 YAML 文件推送到 Git 仓库。
- Kurator 里的 Source Controller 监测到 Git 变动。
- Kustomize Controller 自动拉取代码,根据预定义的 应用配置策略(比如不同环境注入不同环境变量),生成最终的 Manifest。
- 自动应用到目标集群。
这种方式最大的好处是可追溯和防漂移。谁改了配置,Git Log 里清清楚楚。
2. 蓝绿发布避坑指南
说到发布,蓝绿发布(Blue/Green Deployment)是大家最爱也最怕的。Kurator 通过 统一应用发布(Unified Application Rollout) 功能,结合 Istio 等网关能力,把这事儿标准化了。
这里有个巨大的坑:Service 的 Selector 标签管理。
很多新手在做蓝绿发布时,忘了给新旧版本的 Pod 打上区分标签(比如 version: v1 和 version: v2),导致 Service 直接把流量负载均衡到了所有 Pod 上,瞬间“蓝绿”变“乱炖”。
# Kurator 风格的 Rollout 配置示例
# 这里的重点是 canary 和 stable 的 service 必须严格区分
apiVersion: rollout.kurator.dev/v1alpha1
kind: Rollout
metadata:
name: my-app-rollout
spec:
strategy:
blueGreen:
# ⚠️ 坑点预警:确保这个 activeService 指向的是现在的生产 Service
activeService: my-app-active
# 这个 previewService 是给测试人员验证新版本用的,别搞混了!
previewService: my-app-preview
autoPromotionEnabled: false # 建议首次上线设为 false,人工确认后再切流量
workloadRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
这是在Kurator中配置蓝绿发布的YAML示例,展示了基于Istio的流量路由、多轮次健康分析及自动化回滚机制的完整策略定义: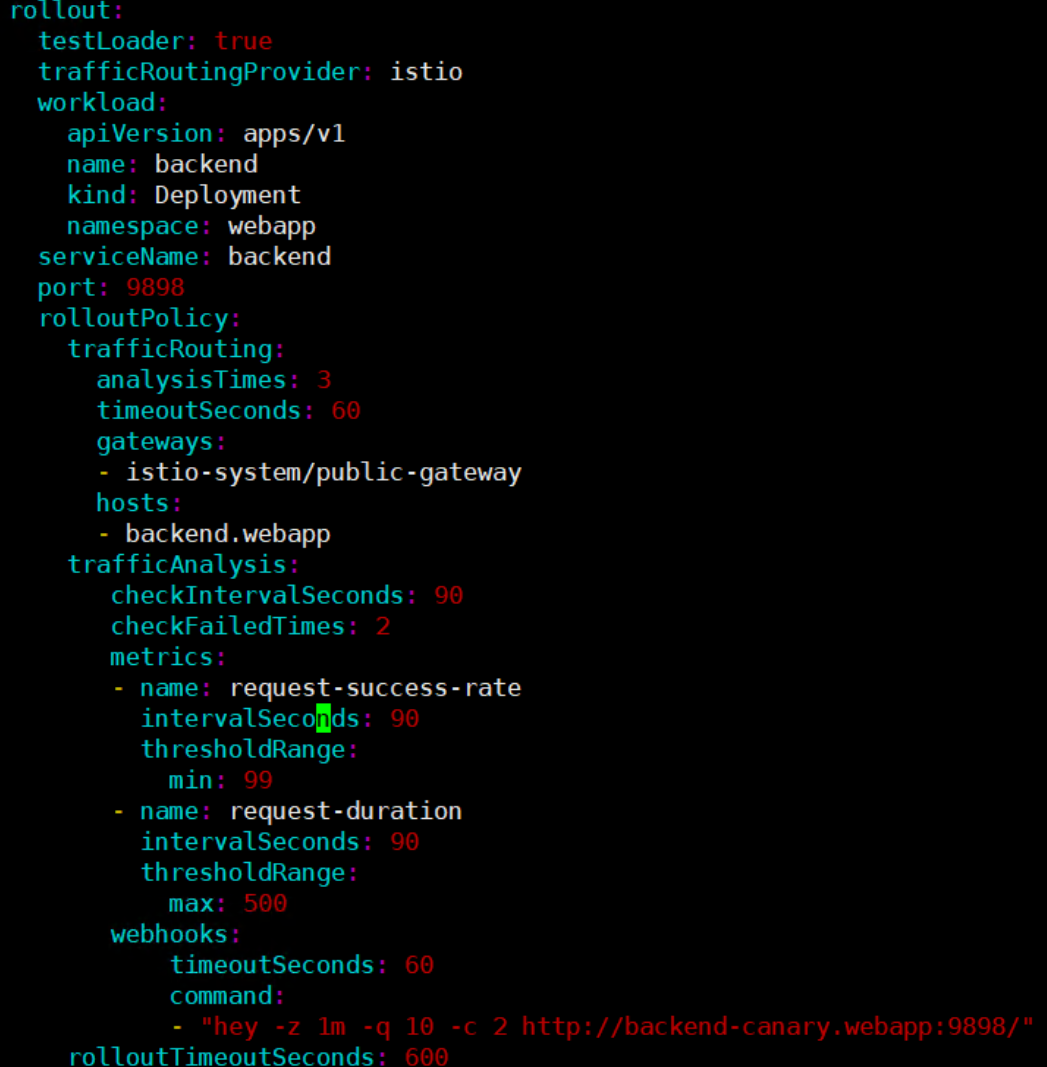
四、 边缘与迁移:从中心到天涯海角
最后,咱们聊聊两个极具挑战的场景:边缘计算和“搬家”。
1. KubeEdge:断网也能活
在边缘场景下,KubeEdge 的架构简直是神来之笔。Kurator 将其无缝集成。
它的核心是 CloudCore(云端)和 EdgeCore(边缘端)。
工作流分析:
云端下发指令 -> CloudCore 通过 WebSocket 长连接推送到边缘 -> EdgeHub 接收消息 -> EdgeCore 像个微型 Kubelet 一样管理本机容器。
最绝的是,如果边缘断网了,EdgeCore 会把元数据存在本地 SQLite 里,保证业务不挂。等网通了,自动同步数据。这对于那些在海上钻井平台或者偏远基站的业务来说,简直是救命稻草。
2. Kurator 的统一迁移流程:乾坤大挪移
这张图展示了Kurator的统一迁移流程,用户只需要创建一个自定义资源,后面就由系统自动完成备份、上传、下载和恢复,把数据从源集群平滑迁移到多个目标集群,整个过程简单又高效: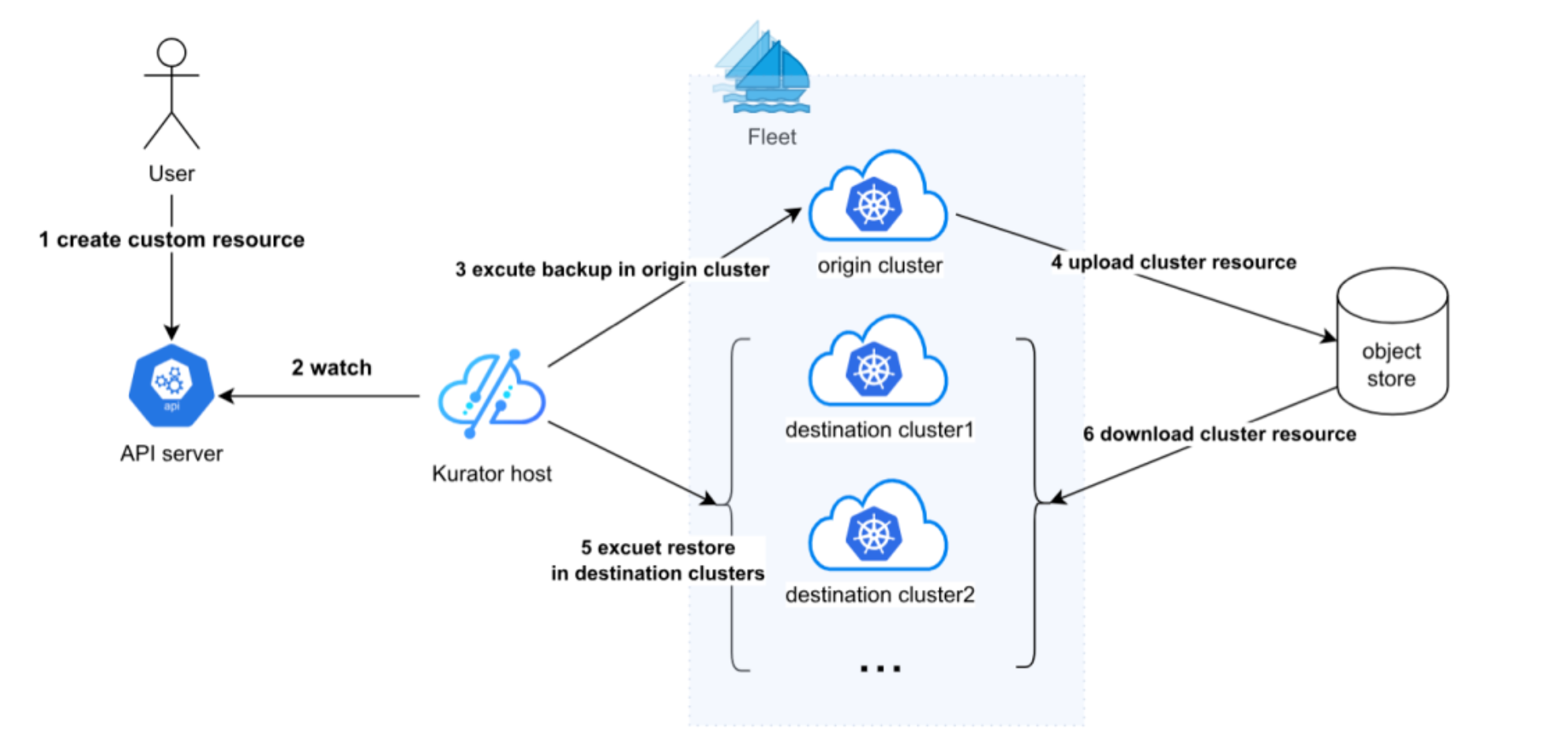
这可是 Kurator 的杀手锏之一:Unified Backup, Restore, and Migration。
很多时候我们需要把业务从一个集群搬到另一个集群(比如从私有云搬到公有云)。以前这得脱层皮,现在 Kurator 基于 Velero 封装了一套统一迁移流程。
它不是简单的拷贝文件,而是基于快照的全量资源迁移。
- Backup:在源集群,Kurator 调用备份插件,把 PV 数据和 K8s 资源对象打包上传到对象存储(如 S3)。
- Restore:在目标集群,你可以通过过滤标签(Label Selector)选择性地恢复资源。
# 统一迁移的 Restore 任务配置
apiVersion: backup.kurator.dev/v1alpha1
kind: Restore
metadata:
name: migrate-to-cloud
spec:
# 指定之前的备份点
backupName: on-prem-backup-20260103
# 目标集群列表,想迁哪里迁哪里
targetClusters:
- cloud-cluster-01
# 排除掉不需要迁移的系统级资源
excludedNamespaces:
- kube-system
- kurator-system
# ⚠️ 避坑:如果你的 StorageClass 在两个集群名字不一样,记得用 PV 映射功能
深度解析:这个流程最强的地方在于它屏蔽了底层集群的差异。不管你源端是 K8s 1.24 还是 1.28,只要 API 兼容,Kurator 就能帮你把家搬过去。
结语
Kurator 这个项目,我看重的不是它有多少新功能,而是它整合的能力。在云原生碎片化如此严重的今天,能有一个工具把集群管理、调度、边缘、监控、发布串成一条线,这本身就是巨大的生产力解放。
咱们做技术的,工具是手段,业务稳定高效才是目的。希望这篇“老司机”指南能帮你少踩几个坑,早点把 Kurator 用起来,到时候你也能在团队里吹一波:“看,这就叫云原生治理!”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)