【前瞻创想】Kurator:构建下一代分布式云原生智能平台
【前瞻创想】Kurator:构建下一代分布式云原生智能平台
【前瞻创想】Kurator:构建下一代分布式云原生智能平台

摘要
在云原生技术快速演进的今天,分布式云原生架构已成为企业数字化转型的核心驱动力。Kurator作为一款开源的分布式云原生套件,通过深度集成Karmada、KubeEdge、Volcano、Istio等优秀开源项目,为企业提供了从中心到边缘、从开发到运维的全栈解决方案。本文从实战角度出发,深入剖析Kurator的核心架构、关键组件及高级特性,结合真实场景的代码实践,探讨如何构建高效、可靠、智能的分布式云原生平台。文章不仅涵盖环境搭建、多集群管理、边缘计算等基础能力,更深入GitOps、高级发布策略、资源调度优化等进阶话题,为云原生从业者提供一套完整的分布式云原生落地指南。
一、Kurator框架概述
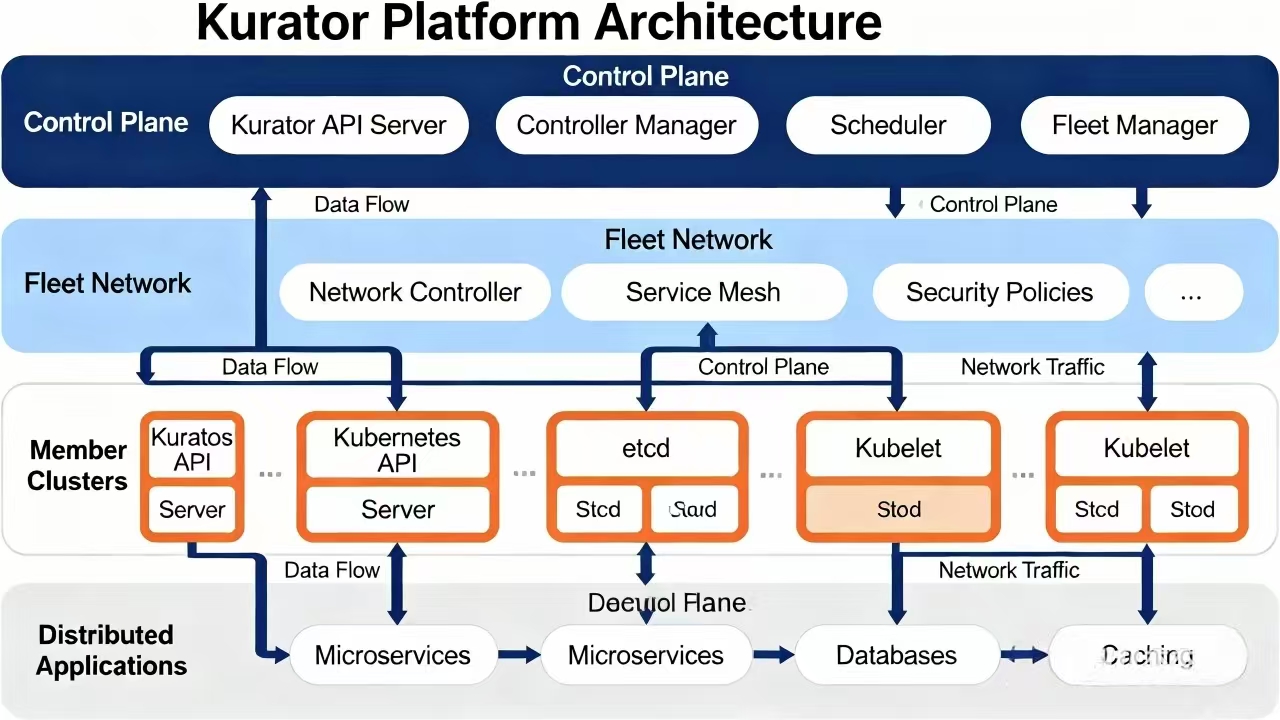
1.1 分布式云原生的挑战与机遇
随着企业业务场景的复杂化,传统的单集群架构已无法满足全球化部署、边缘计算、多云协同等需求。分布式云原生架构应运而生,但同时也带来了集群管理复杂、应用分发困难、资源调度低效等挑战。Kurator正是在这样的背景下诞生,它不是简单的工具集合,而是通过深度整合多个开源项目,构建了一个统一的分布式云原生操作系统。
Kurator的核心价值在于提供了一套标准化的接口和抽象层,让开发者无需关心底层基础设施的差异,专注于业务逻辑的开发。这种设计理念体现了云原生技术从"基础设施为中心"向"应用为中心"的转变趋势。
1.2 核心组件与架构设计
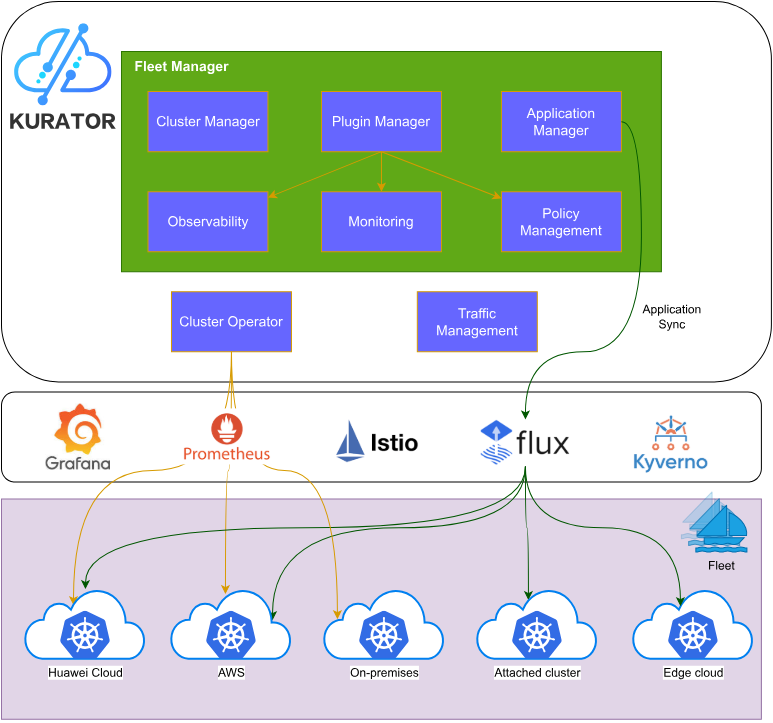
Kurator的架构设计充分体现了"分层解耦、能力复用"的原则。其核心组件包括:
- Fleet Manager:负责集群生命周期管理和资源调度
- Distributed Scheduler:基于Volcano构建的高级调度器,支持队列、公平调度等企业级特性
- Edge Controller:集成KubeEdge,实现云边协同
- GitOps Engine:基于FluxCD,提供声明式的应用交付
- Service Mesh Integration:深度集成Istio,实现高级流量管理
这种模块化设计不仅保证了系统的可扩展性,也为社区贡献者提供了清晰的参与路径。每个组件都可以独立演进,同时通过统一的API进行协同工作。
二、环境搭建与基础配置
2.1 快速部署Kurator集群
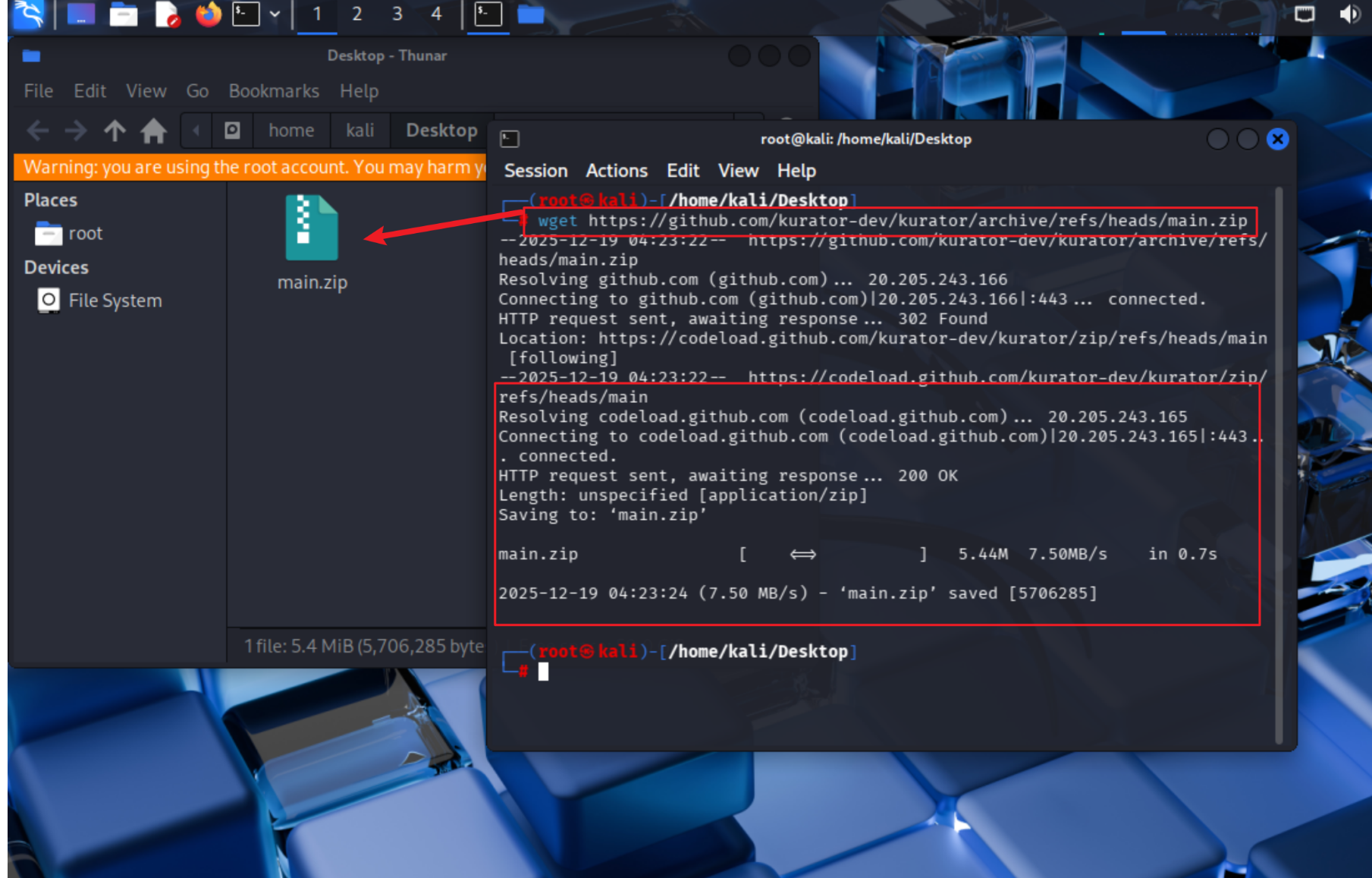
环境搭建是使用Kurator的第一步。我们从官方仓库获取最新的代码,使用指定的命令进行下载:
可以用wget的方法拉取
# 下载最新源代码zip包
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
这解压文件
unzip main.zip
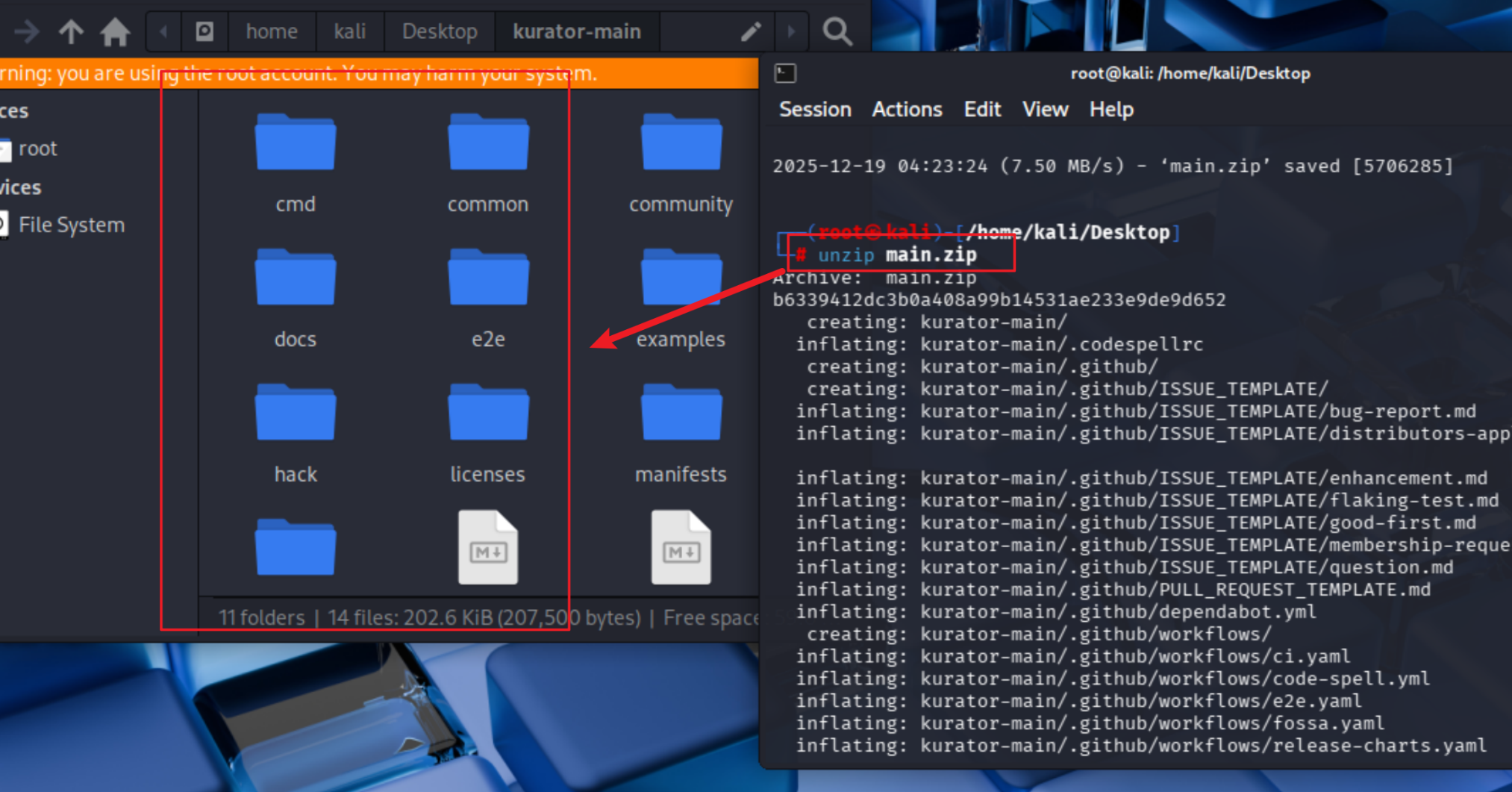
拉取下来以后就可以使用啦
接下来,我们需要准备基础环境。确保已安装kubectl、helm等必要工具,并且有一个可用的Kubernetes集群作为管理集群。Kurator支持多种部署模式,这里我们采用标准模式:
# 安装依赖
./scripts/install-dependencies.sh
# 初始化Kurator
./scripts/install-kurator.sh --registry ghcr.io
安装过程中,脚本会自动检测系统环境,下载所需的Docker镜像,并部署Kurator的核心组件。这个过程通常需要10-15分钟,具体时间取决于网络状况和机器性能。
2.2 验证安装与基础配置
安装完成后,我们需要验证各个组件是否正常运行:
kubectl get pods -n kurator-system
预期输出应该显示所有Pod都处于Running状态。接下来,配置kubectl context以便与Kurator集群交互:
kubectl config use-context kurator-admin@kurator
为了提升开发体验,建议配置Kurator的命令行工具:
go install sigs.k8s.io/kustomize/kustomize/v4@latest
kurator completion bash > /etc/bash_completion.d/kurator
这个环境搭建过程虽然简单,但背后涉及了复杂的依赖管理和配置协调。Kurator通过自动化脚本和合理的默认配置,大大降低了用户的使用门槛,这正是其设计理念的体现——让复杂性对用户透明。
三、Fleet管理与多集群调度
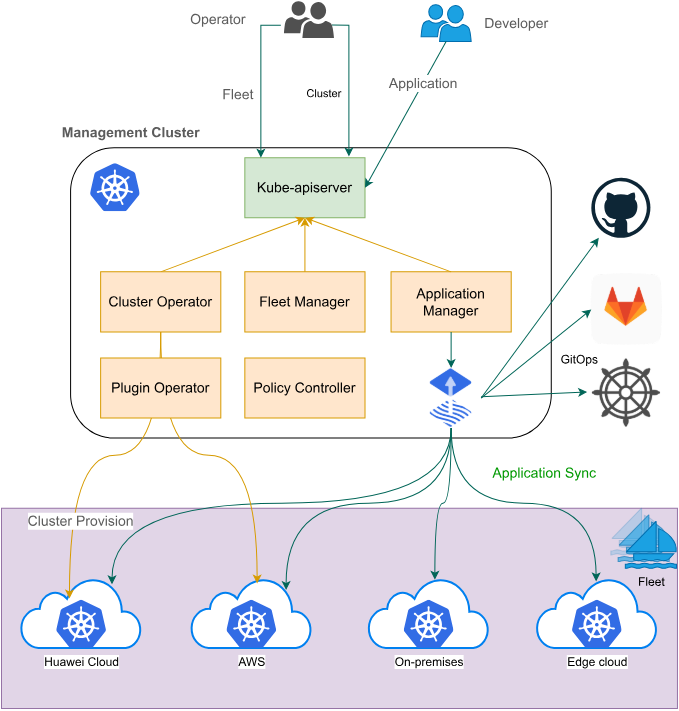
3.1 Fleet概念与资源模型
Fleet是Kurator中管理集群资源的核心抽象。一个Fleet代表一组具有相同特性的集群集合,可以是地域相近的集群,也可以是承担相同业务功能的集群。Fleet的设计解决了传统多集群管理中的几个关键问题:
- 资源隔离:不同Fleet之间的资源完全隔离,避免相互影响
- 策略统一:可以在Fleet级别定义统一的调度策略、安全策略
- 身份管理:提供统一的身份认证和授权机制
Fleet的YAML定义示例:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- name: cluster-east
kubeconfigSecret: cluster-east-kubeconfig
- name: cluster-west
kubeconfigSecret: cluster-west-kubeconfig
placement:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/region
operator: In
values: [east, west]
3.2 跨Fleet资源调度策略
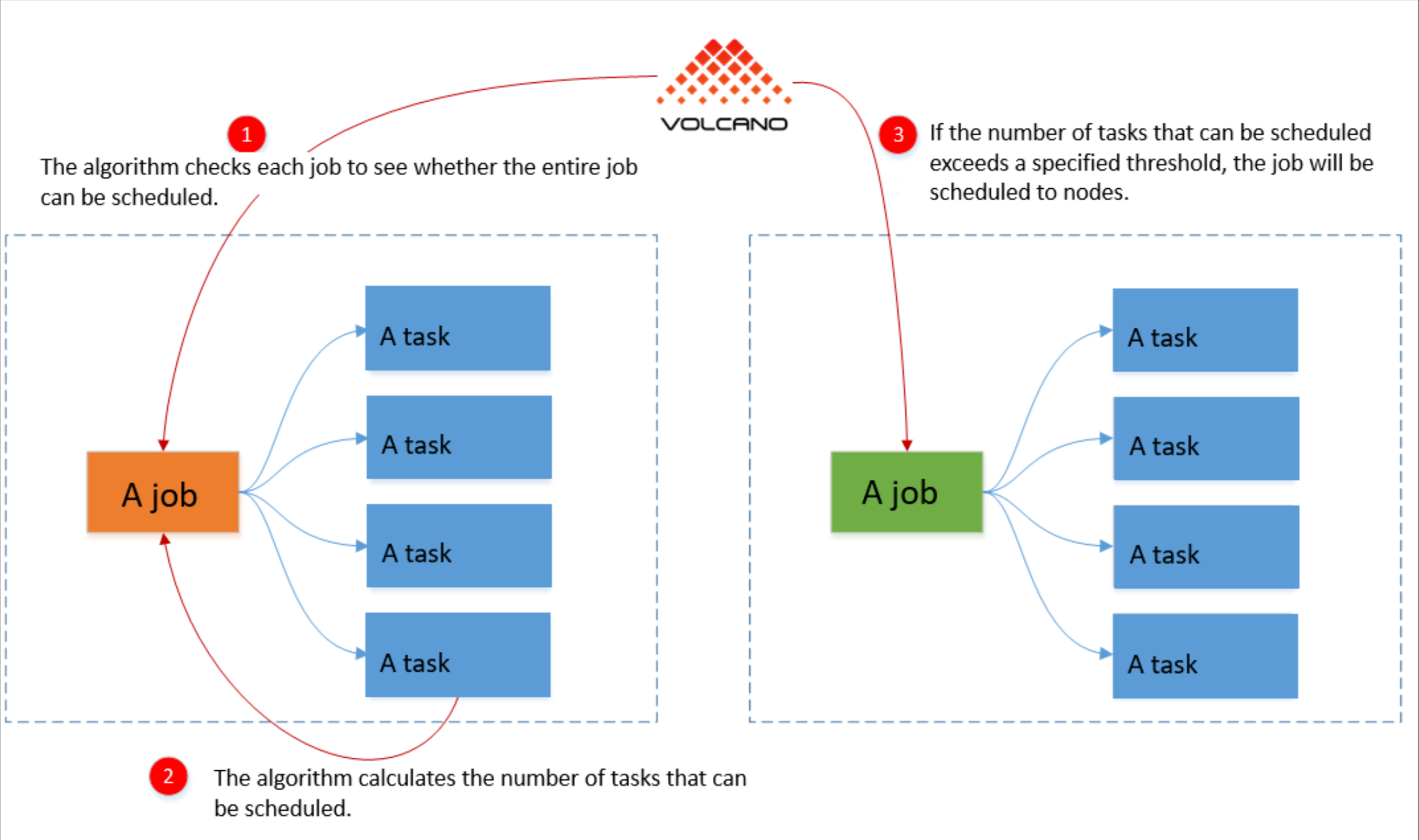
Kurator基于Volcano调度器实现了高级的跨Fleet调度能力。与传统的Kubernetes调度器相比,Volcano提供了队列、公平调度、抢占等企业级特性。在多集群场景下,这些特性尤为重要。
以下是一个基于队列的调度策略配置:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: high-priority-queue
spec:
weight: 100
capability:
cpu: "100"
memory: 200Gi
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
meta
name: critical-app-group
spec:
minMember: 3
queue: high-priority-queue
这种调度策略确保了关键业务应用能够获得足够的资源保障,即使在集群资源紧张的情况下也能优先调度。Kurator通过将Volcano与Fleet管理深度集成,为用户提供了细粒度的资源控制能力。
四、Karmada集成与跨集群弹性伸缩
4.1 Karmada架构与Kurator集成
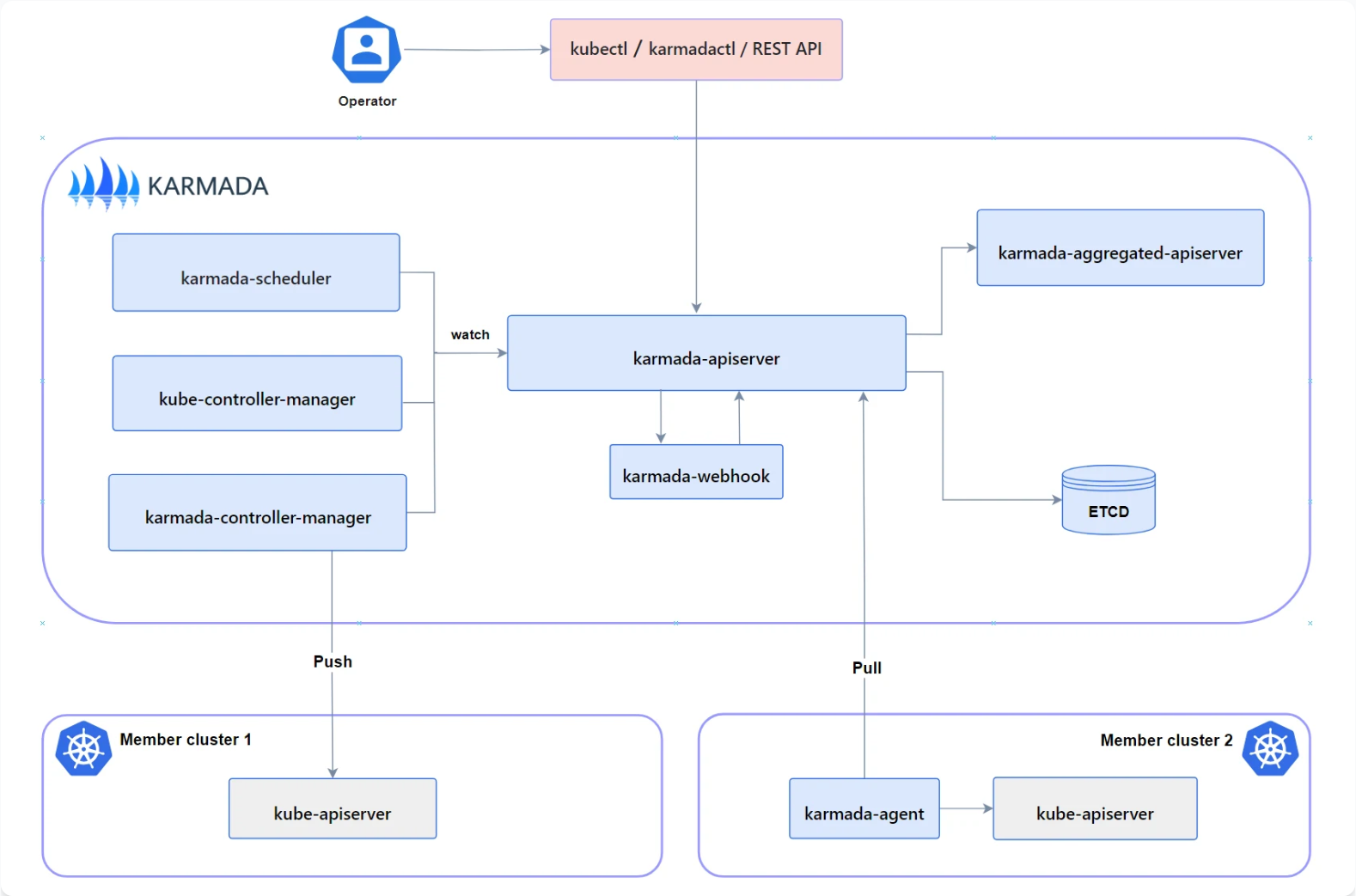
Karmada是CNCF的多集群管理项目,Kurator通过深度集成Karmada,实现了跨集群应用分发和管理。Karmada的核心优势在于其强大的策略引擎,可以基于集群的健康状态、资源使用率、地理位置等因素,智能地决定应用应该部署在哪些集群。
在Kurator中,Karmada的集成是通过自定义资源定义(CRD)实现的:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weights:
cluster-east: 70
cluster-west: 30
这个配置定义了一个传播策略,将nginx部署按照70:30的比例分发到两个集群。Kurator通过这种方式,将Karmada的能力无缝集成到自己的生态系统中。
4.2 跨集群弹性伸缩实践
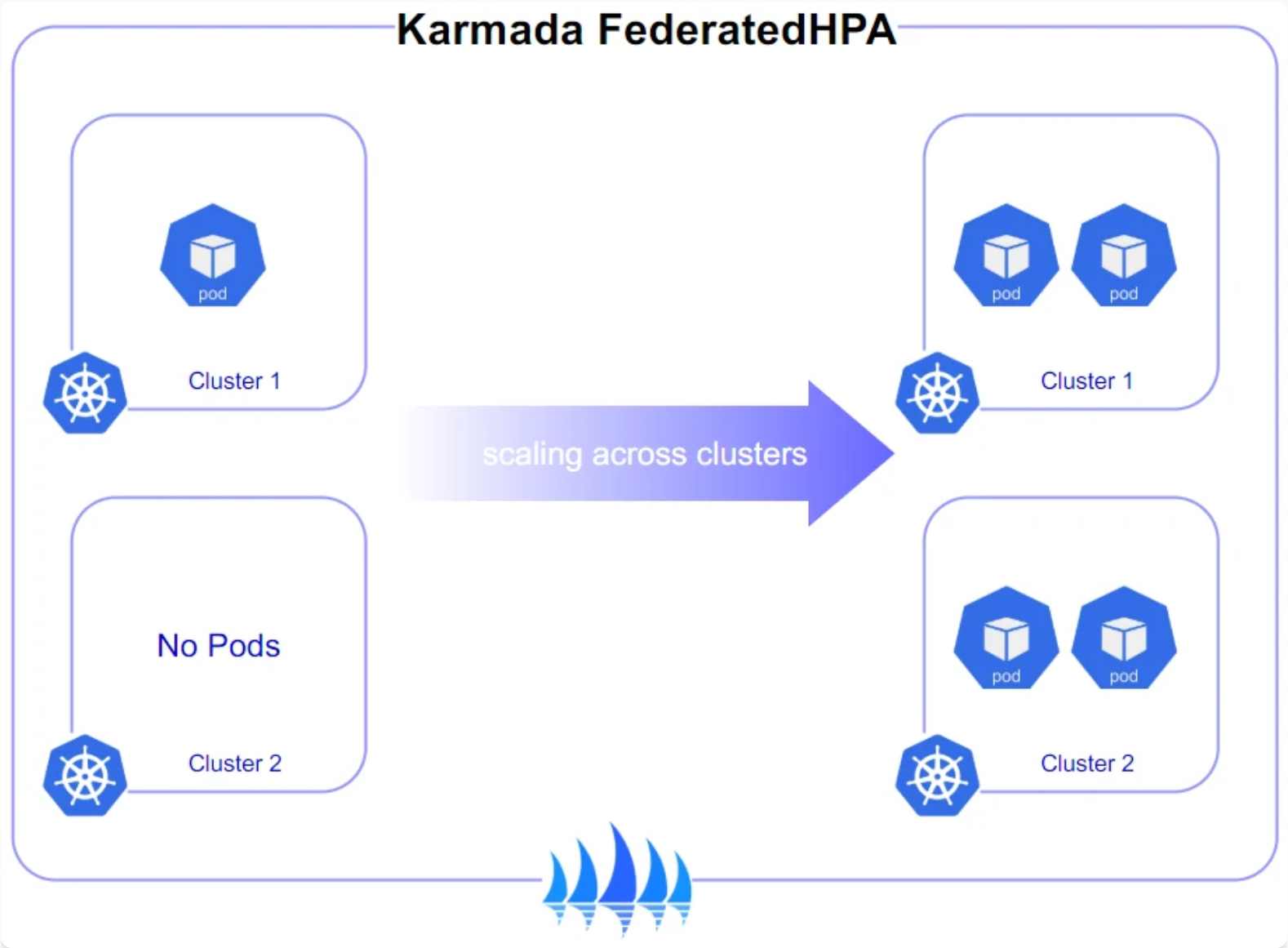
在实际业务场景中,不同地域的用户访问量可能存在显著差异。Kurator结合Karmada实现了智能的跨集群弹性伸缩:
package main
import (
"context"
"fmt"
"time"
"k8s.io/apimachinery/pkg/api/resource"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"sigs.k8s.io/karmada/pkg/apis/autoscaling/v1alpha1"
)
func setupCrossClusterHPA() {
config, err := rest.InClusterConfig()
if err != nil {
panic(err)
}
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
hpa := &v1alpha1.HorizontalPodAutoscaler{
ObjectMeta: metav1.ObjectMeta{
Name: "global-nginx-hpa",
Namespace: "default",
},
Spec: v1alpha1.HorizontalPodAutoscalerSpec{
ScaleTargetRef: v1alpha1.CrossVersionObjectReference{
Kind: "Deployment",
Name: "nginx",
APIVersion: "apps/v1",
},
MinReplicas: func() *int32 { i := int32(3); return &i }(),
MaxReplicas: 20,
Metrics: []v1alpha1.MetricSpec{
{
Type: v1alpha1.ResourceMetricSourceType,
Resource: &v1alpha1.ResourceMetricSource{
Name: "cpu",
TargetAverageUtilization: func() *int32 { i := int32(50); return &i }(),
},
},
},
ClusterMetrics: []v1alpha1.ClusterMetricSpec{
{
Type: v1alpha1.ClusterResourceMetricSourceType,
ClusterResource: &v1alpha1.ClusterResourceMetricSource{
Name: "cpu",
TargetAverageUtilization: func() *int32 { i := int32(70); return &i }(),
},
},
},
},
}
// 创建HPA
_, err = clientset.AutoscalingV1().HorizontalPodAutoscalers("default").Create(context.TODO(), hpa, metav1.CreateOptions{})
if err != nil {
panic(err)
}
fmt.Println("跨集群HPA创建成功")
}
这段代码展示了如何创建一个跨集群的HPA,它不仅监控单个集群内的资源使用情况,还能根据集群整体的负载情况进行伸缩决策。这种能力在应对突发流量时尤为重要,可以确保服务的高可用性。
五、KubeEdge边缘计算集成
5.1 KubeEdge架构与核心组件
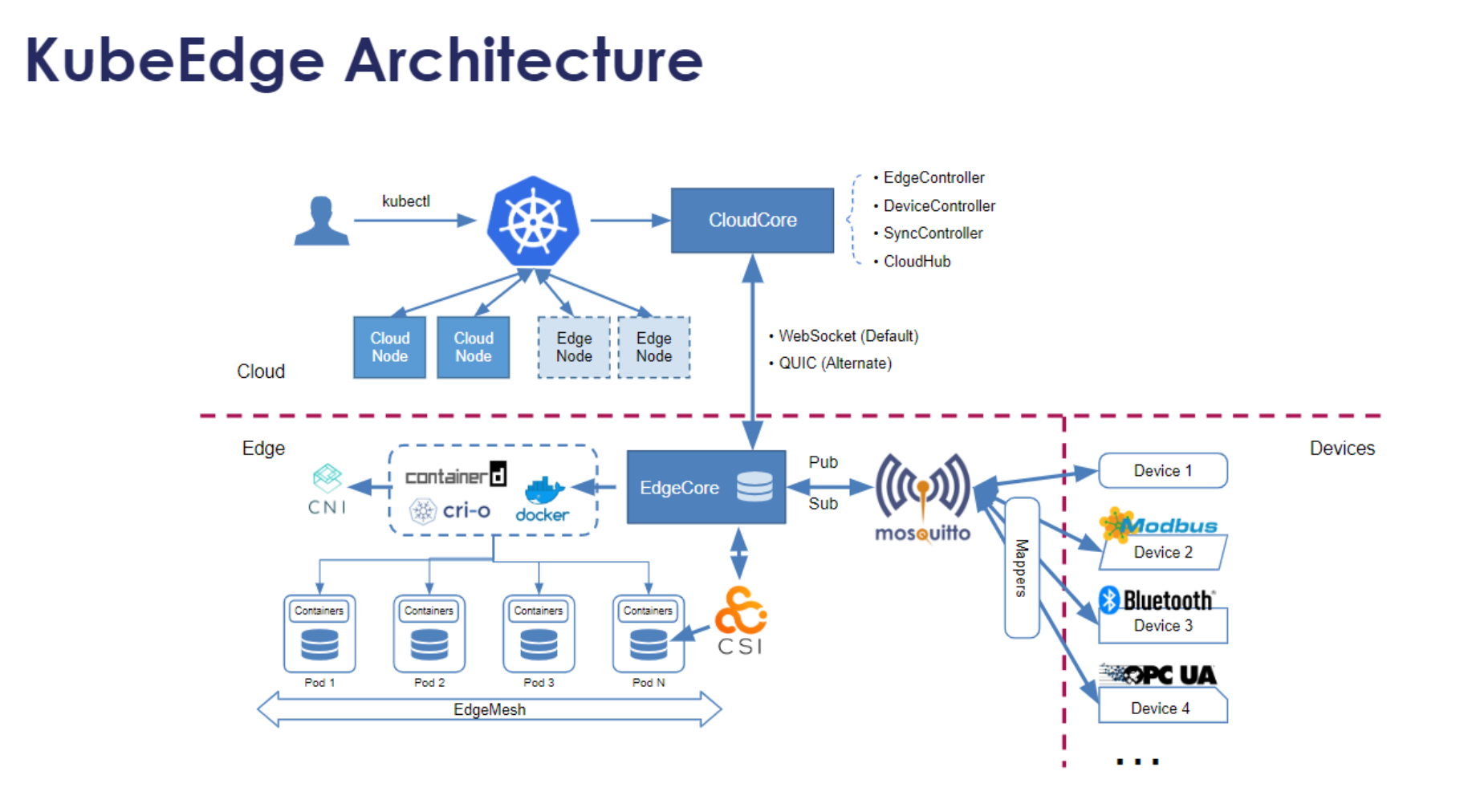
KubeEdge是CNCF的边缘计算项目,Kurator通过集成KubeEdge,将云原生能力延伸到边缘设备。KubeEdge的架构分为云上和边缘两个部分:
- CloudCore:运行在云端,负责与Kubernetes API Server通信
- EdgeCore:运行在边缘设备上,负责管理边缘容器和设备
Kurator对KubeEdge的集成不仅仅是简单的部署,而是通过Fleet Manager实现了统一的边缘集群管理。用户可以通过Kurator的API,像管理普通Kubernetes集群一样管理边缘集群。
5.2 云边协同实践
在实际应用中,云边协同是一个复杂的问题。Kurator提供了几种典型的云边协同模式:
apiVersion: apps.kurator.dev/v1alpha1
kind: EdgeApplication
meta
name: edge-ai-inference
spec:
selector:
edgeDeviceType: camera
template:
spec:
containers:
- name: inference-engine
image: ai-inference:v1
resources:
limits:
nvidia.com/gpu: 1
volumeMounts:
- name: model-cache
mountPath: /models
volumes:
- name: model-cache
edgePersistentVolume:
capacity:
storage: 10Gi
edgeStorageClass: local-ssd
syncPolicy:
cloudToEdge:
interval: 5m
paths:
- /models/latest
edgeToCloud:
enabled: true
paths:
- /logs/inference
这个配置定义了一个边缘AI推理应用,它从云端同步最新的模型文件到边缘设备,同时将推理日志同步回云端进行分析。Kurator通过这种声明式的方式,简化了云边数据同步的复杂性。
六、GitOps与CI/CD流水线实践
6.1 GitOps实现方式
GitOps是云原生时代的一种现代化部署模式,Kurator基于FluxCD实现了完整的GitOps能力。与传统的CI/CD相比,GitOps具有以下优势:
- 声明式配置:所有配置都存储在Git仓库中,版本可控
- 自动同步:当Git仓库发生变化时,自动同步到集群
- 回滚简单:通过Git的历史记录,可以轻松回滚到任意版本
Kurator的GitOps配置示例:
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: GitRepository
meta
name: app-repo
namespace: flux-system
spec:
interval: 1m
url: https://github.com/company/app-manifests
ref:
branch: main
secretRef:
name: git-secret
---
apiVersion: kustomize.toolkit.fluxcd.io/v1beta1
kind: Kustomization
meta
name: app-kustomization
namespace: flux-system
spec:
interval: 5m
sourceRef:
kind: GitRepository
name: app-repo
path: "./production"
prune: true
validation: client
6.2 Kurator CI/CD流水线设计
Kurator的CI/CD流水线采用了分层架构设计,将构建、测试、部署等环节解耦:
// CI/CD流水线定义
type Pipeline struct {
Name string
Description string
Stages []Stage
Triggers []Trigger
}
type Stage struct {
Name string
Type string // build, test, deploy, validate
Services []string
Steps []Step
}
type Step struct {
Name string
Command string
Args []string
Timeout time.Duration
OnFailure string // continue, stop, rollback
}
func createProductionPipeline() *Pipeline {
return &Pipeline{
Name: "production-deployment",
Description: "Production deployment pipeline with canary testing",
Stages: []Stage{
{
Name: "build-and-test",
Type: "build",
Steps: []Step{
{Name: "build-docker", Command: "docker", Args: []string{"build", "-t", "app:${VERSION}", "."}},
{Name: "run-unit-tests", Command: "go", Args: []string{"test", "./..."}},
},
},
{
Name: "staging-deploy",
Type: "deploy",
Steps: []Step{
{Name: "deploy-to-staging", Command: "kubectl", Args: []string{"apply", "-f", "staging.yaml"}},
{Name: "run-integration-tests", Command: "pytest", Args: []string{"integration_tests/"}},
},
},
{
Name: "canary-release",
Type: "deploy",
Steps: []Step{
{Name: "deploy-canary", Command: "kurator", Args: []string{"deploy", "--canary", "10%", "--namespace", "production"}},
{Name: "monitor-canary", Command: "kurator", Args: []string{"monitor", "--duration", "30m"}},
{Name: "promote-to-production", Command: "kurator", Args: []string{"promote", "--namespace", "production"}},
},
},
},
Triggers: []Trigger{
{Type: "git-push", Branch: "main"},
{Type: "schedule", Cron: "0 2 * * *"}, // 每天凌晨2点
},
}
}
这个流水线设计体现了Kurator对现代软件交付流程的深刻理解。通过将canary发布作为独立的阶段,确保了新版本在全面上线前得到充分的验证。同时,流水线的触发机制支持事件驱动和定时触发,满足了不同业务场景的需求。
七、高级发布策略:金丝雀、蓝绿与A/B测试
7.1 金丝雀发布配置
金丝雀发布是一种渐进式发布策略,Kurator通过集成Istio实现了细粒度的流量控制:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: frontend
spec:
hosts:
- frontend.example.com
http:
- route:
- destination:
host: frontend-v1
weight: 90
- destination:
host: frontend-v2
weight: 10
timeout: 5s
retries:
attempts: 3
perTryTimeout: 2s
---
apiVersion: kurator.dev/v1alpha1
kind: CanaryRelease
meta
name: frontend-canary
spec:
deployment:
name: frontend
namespace: production
strategy:
type: Progressive
steps:
- weight: 10
duration: "5m"
- weight: 30
duration: "10m"
- weight: 100
duration: "0s"
metrics:
- name: request-success-rate
threshold: 99.9
interval: "1m"
- name: latency-p99
threshold: "200ms"
interval: "1m"
这个配置定义了一个渐进式的金丝雀发布策略,流量从10%逐步增加到100%,同时监控关键指标,如果指标不达标,自动回滚。
7.2 A/B测试与业务指标驱动
A/B测试不仅关注技术指标,更需要结合业务指标进行决策。Kurator提供了与业务监控系统的集成能力:
package abtest
import (
"context"
"fmt"
"time"
"istio.io/client-go/pkg/apis/networking/v1alpha3"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
type BusinessMetric struct {
Name string
Threshold float64
Comparison string // "greater", "less", "equal"
MetricType string // "conversion_rate", "revenue", "engagement"
DataSource string // "prometheus", "datadog", "custom"
}
type ABTestConfig struct {
Name string
Variants []string
Traffic []int32
Duration time.Duration
Metrics []BusinessMetric
AutoPromote bool
}
func createABTest(ctx context.Context, config *ABTestConfig) error {
// 创建VirtualService进行流量分发
vs := &v1alpha3.VirtualService{
ObjectMeta: metav1.ObjectMeta{
Name: config.Name,
Namespace: "production",
},
Spec: v1alpha3.VirtualServiceSpec{
Hosts: []string{"app.example.com"},
Http: []v1alpha3.HTTPRoute{{
Route: createWeightedRoutes(config.Variants, config.Traffic),
}},
},
}
// 同时创建业务指标监控
for _, metric := range config.Metrics {
err := setupBusinessMetricMonitoring(ctx, config.Name, metric)
if err != nil {
return fmt.Errorf("failed to setup metric monitoring: %v", err)
}
}
fmt.Printf("A/B测试 %s 已创建,持续时间: %v\n", config.Name, config.Duration)
return nil
}
func createWeightedRoutes(variants []string, weights []int32) []v1alpha3.DestinationWeight {
routes := make([]v1alpha3.DestinationWeight, len(variants))
for i, variant := range variants {
routes[i] = v1alpha3.DestinationWeight{
Destination: v1alpha3.Destination{
Host: fmt.Sprintf("%s.%s.svc.cluster.local", variant, "production"),
},
Weight: weights[i],
}
}
return routes
}
这段代码展示了如何创建一个A/B测试,它不仅配置了流量分发,还集成了业务指标监控。这种能力使得团队能够基于真实的业务效果来做出发布决策,而不仅仅是技术指标。
八、Kurator未来发展方向与社区贡献
8.1 技术演进路线
Kurator作为新兴的分布式云原生平台,其未来发展将聚焦于几个关键方向:
- 智能化:引入AI/ML能力,实现自动化的资源优化、故障预测、安全防护
- 标准化:推动分布式云原生标准的制定,减少生态碎片化
- 用户体验:简化配置复杂性,提供更直观的可视化工具和诊断能力
- 安全增强:构建端到端的安全体系,包括零信任架构、数据加密、合规审计
特别是智能化方向,Kurator正在探索将LLM技术应用于运维场景,例如自动生成配置、解释系统行为、预测潜在问题等。这种能力将极大地提升运维效率,降低人为错误风险。
8.2 社区建设与最佳实践
开源项目的成功离不开活跃的社区。Kurator社区正在建立一套完整的贡献者体验:
- 新手友好:提供详细的开发文档、贡献指南、沙盒环境
- 多样化的贡献路径:代码贡献、文档改进、案例分享、社区运营
- 定期技术分享:每周的技术讨论会、月度的用户案例分享
- 认证与激励:贡献者等级认证、年度优秀贡献者评选
对于想要参与Kurator开发的工程师,建议从以下几个方面入手:
- 理解核心架构:深入研究Fleet Manager、调度器等核心组件
- 解决实际问题:从自己的业务场景出发,提出改进需求
- 从小处着手:先修复文档问题、添加单元测试,逐步深入核心代码
- 参与社区讨论:在GitHub Issues、Slack等渠道积极参与技术讨论
Kurator的愿景是成为分布式云原生领域的"Linux",通过开放、协作、创新的精神,构建一个繁荣的生态系统。每个参与者的贡献,都将推动这个愿景的实现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)