【探索实战】从平台 SRE/平台工程视角落地 Kurator:把“多集群碎片化运维”收敛到 Fleet 控制面!
1. 为什么平台团队需要 Kurator:把“集群组”当成一等对象 Fleet 🧠
多云、多集群、云边协同的现实里,平台团队的痛苦往往不在“能不能装”,而在:
- 标准不统一:应用分发、监控、策略、网络互通、灰度发布……每个集群各一套,最后变成“工具堆”;
- 变更不可控:同一个策略/监控规则/发布动作在不同集群效果不一致,排障像开盲盒;
- 规模不经济:新增集群 = 新增一整套运维工作量;
- 平台没有控制面:缺少能统一编排、统一观测、统一合规的抽象边界。
Kurator 的“平台化关键”是把一组物理集群抽象成逻辑单元 Fleet,然后让 Fleet Manager 以 operator 的方式对 Fleet 做一致性治理与统一编排:包括 Fleet 控制面生命周期、集群注册/注销、应用编排、跨集群一致性对象(namespace/serviceaccount/service)、跨集群服务发现与通信、以及聚合指标等能力。
平台工程解读:你不再“按集群管理”,而是“按 Fleet(集群组/业务域/环境/地域)管理”。平台的边界因此清晰:一个 Fleet = 一个治理域。🙂
2. 平台控制面组成:Setup 里的“最小骨架”与职责拆分 🧱
Kurator 官方 Setup 明确:当前主要包含 kurator cli 与 cluster operator 两个组件,并提供源码构建与 release 包两种安装方式。
在平台工程实践里,你可以把 Kurator 的能力拆成三层(对应官方文档结构):
- Cluster Operator(集群侧/基础设施侧):把集群生命周期管理变成 Kubernetes 风格的声明式对象;官方给了基于 Cluster API 的最短 quickstart。
- Fleet Manager(平台控制面/多集群治理层):围绕 Fleet 做统一编排,并依赖 FluxCD 实现 GitOps 分发。
- Fleet Plugins(平台能力包):监控(Prometheus+Thanos)、策略(Kyverno)、网络(Submariner)、灰度发布(Flagger,支持 Istio/Kuma/Nginx)、以及统一备份/恢复/迁移(Velero)与统一分布式存储(Rook)等。
3. Day0:先把“实验场”搭起来——本地 Kind 多集群 + Host/Member kubeconfig 🧪
平台落地最怕“起不来”。Kurator 在安装 Cluster Operator 的文档里给了本地体验路径:通过仓库脚本启动 Kind,生成 host 与 member 的 kubeconfig,并提示你如何 export KUBECONFIG 管理远端集群。
如果你们感兴趣,可直接下载该源码:
下载到本地之后
我们只需要进行项目解压即可:
可以看到清晰的目录结构,剩下的就看大家想怎么玩了。
而且附带很多文档说明,绝绝子。
3.1 启动本地环境(以官方脚本为准)
官方文档展示了脚本跑完后会出现
kurator-host.config / kurator-member1.config / kurator-member2.config等文件,并提示 export KUBECONFIG。
建议你在平台开发机(或 CI runner)上固定以下约定:
- Host(Kurator 所在管理集群):负责运行 cluster operator / fleet manager 控制面;
- Member(被管理集群):代表你的业务工作负载集群(可以是已有集群 AttachedCluster,也可以是 Kurator Cluster API 创建的集群)。
4. Day0:安装 Cluster Operator——平台“造集群/管集群”的地基 🔧
4.1 cert-manager 前置
Cluster Operator 安装文档中明确先安装 cert-manager(通过 Jetstack Helm Chart,并启用 CRDs)。
4.2 三种安装路径(平台团队最常用:Helm Repo / Release Chart)
官方提供三条路径:源码构建 chart、release 包 chart、以及 helm repo 安装。
平台建议:
- 研发/验证环境:用源码构建 + kind load image,便于调试;
- 准生产/生产:用 release chart 或 helm repo,保证版本可控与可追溯。
5. Day0:用 Kurator Cluster API 跑通“声明式建集群”的最小闭环 🏗️
Kurator Cluster API 教程给的最短路径非常适合平台团队做“验收门槛”:apply quickstart.yaml → 观察 cluster ready → clusterctl 拿 kubeconfig → 看 nodes。
kubectl apply -f examples/cluster/quickstart.yaml
kubectl get cluster -w
clusterctl get kubeconfig quickstart > /root/.kube/quickstart.kubeconfig
kubectl --kubeconfig=/root/.kube/quickstart.kubeconfig get nodes
这一步的意义不是“再造一个工具”,而是把“建集群/拿 kubeconfig/验收节点”标准化为声明式 API + 固定命令,为后续 Fleet 纳管打基础。
6. Day0:安装 Fleet Manager——平台多集群治理控制面 🧭
Fleet Manager 安装页明确写到两点关键依赖:
- Fleet manager 依赖 cluster operator(因此先按 cluster operator 安装指南);
- Fleet manager 依赖 FluxCD,并说明 Kurator 使用 FluxCD 社区 Helm Chart 来安装(官方给出了安装 FluxCD 的小节)。
平台工程解读:这意味着 Kurator 的“统一应用分发”走的是**GitOps(FluxCD)**路线,而 Fleet 负责把 GitOps 的“目标范围”从单集群提升到“集群组”。
7. Day0→Day1 过渡:把“已有集群”纳管进来——AttachedCluster + Secret 🔌
真实企业里,多数集群不是你新建的,而是历史遗留。Kurator 文档在多个插件教程里都使用 AttachedCluster 表示预置集群,并通过 kubeconfig Secret 来接入(示例流程在 Submariner/监控等教程的前置步骤中出现)。
平台建议:把“纳管”流程产品化成一个标准作业:
- 收集 kubeconfig(或平台生成受限凭证)
- 创建 Secret
- 创建 AttachedCluster
- 把它加入 Fleet(统一治理域)
(这种“接入即纳管”的模式,就是平台规模化的第一步。)🙂
当然,我们还可以参考如下流程图:
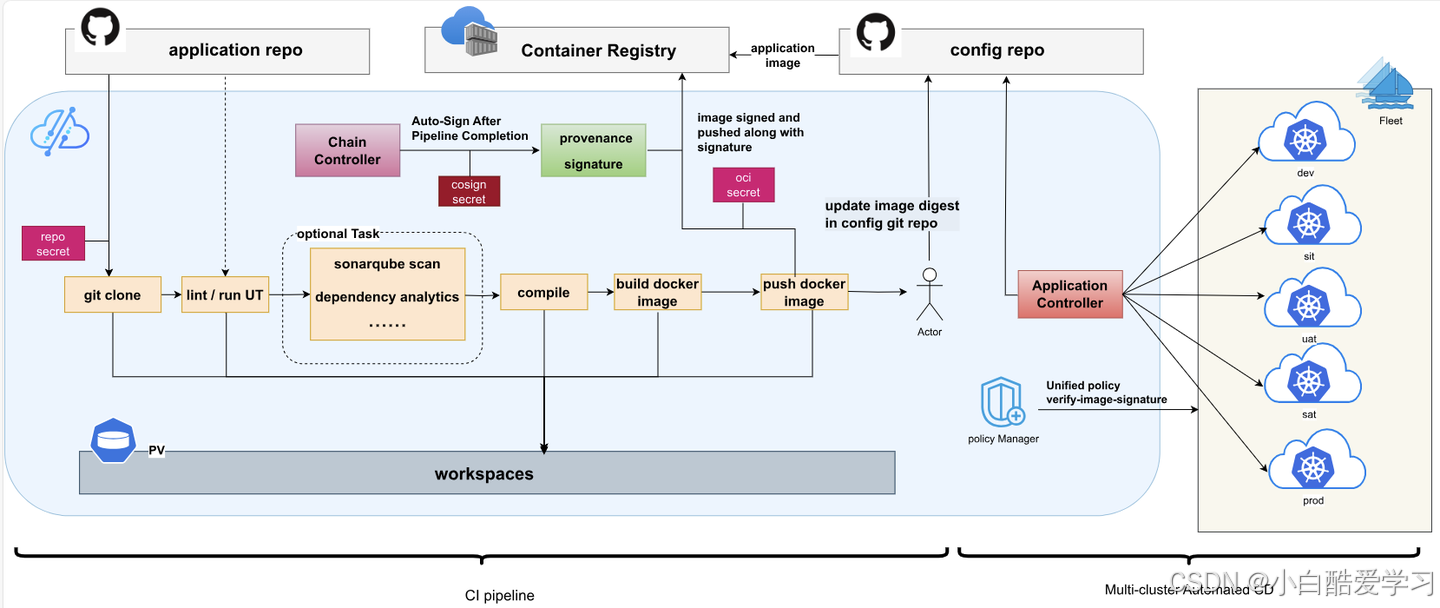
8. Day1:创建 Fleet——平台治理域(环境/业务域/地域)的落地载体 🧩
创建 Fleet 的教程明确:Fleet manager 既能管理 Kurator Cluster API 创建的集群,也能管理 AttachedCluster。
同时,Fleet API Reference 把 FleetSpec 的关键字段抽象得很清晰:
spec.clusters:注册到 Fleet 的集群列表spec.plugin:该 Fleet 要安装的插件配置status.phase:Fleet 当前阶段(Pending/Running/Ready 等)
平台工程解读:Fleet = “治理域”,插件配置 = “域能力包”。这就是平台化的“统一入口”。🙂
讲到这里,如果这里你已经感兴趣了,你可以直接去克隆代码或者下载:
9. Day1:统一应用分发——用 Application 把 GitOps 从“单集群”提升到 Fleet 🚚
应用分发教程给出了官方定义:Kurator 提供跨多集群的统一分发系统,由 Fleet 驱动;采用 GitOps,通过 FluxCD 自动同步与部署,使过程更快更精准。
9.1 官方示例的核心结构:Application → source(Git)+ syncPolicies(fleet destination)
官方页面展示的 Application 示例 YAML(关键字段:source.gitRepository 与 syncPolicies.destination.fleet):
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: gitrepo-kustomization-demo
namespace: default
spec:
source:
gitRepository:
interval: 3m0s
ref:
branch: master
timeout: 1m0s
url: https://github.com/stefanprodan/podinfo
syncPolicies:
- destination:
fleet: quickstart
kustomization:
interval: 5m0s
path: ./deploy/webapp
9.2 “不需要多集群时”的简化:直接部署到 Host Cluster
同一篇应用分发文档还提供了“不指定 destination(fleet)”的例子,适合单集群/先验证 GitOps 流水线的场景。
平台落地经验(不引入新事实,只做方法论总结):
你可以把 Application 定义为平台“交付协议”:业务只需提交 Git URL + path + interval,平台通过 fleet destination 决定发布范围。🙂
可看下如下分发示意图,以便于理解:
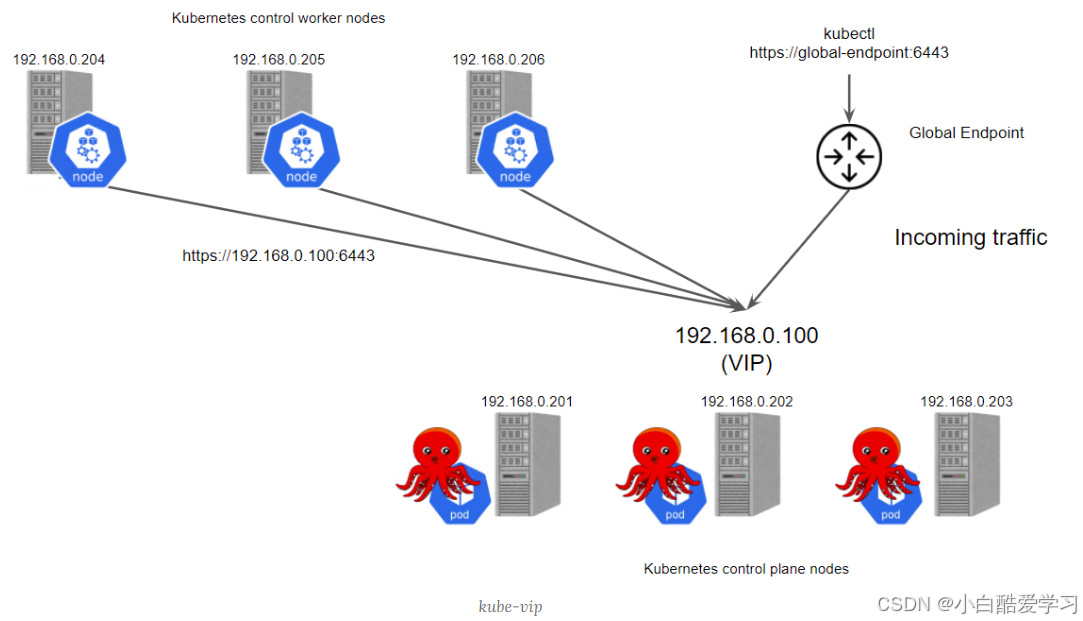
10. Day2:统一可观测——Metric Plugin(Prometheus+Thanos)让 Fleet 成为“指标聚合域”📈
监控插件教程明确:Fleet 的多集群监控构建在 Prometheus 与 Thanos 之上,并需要对象存储;示例使用 MinIO。
你可以把它理解为:
- 每个集群都有自己的采集与 sidecar;
- Fleet 侧通过 Thanos 统一聚合与查询;
- 对象存储用于 Thanos 的长期存储与数据共享。
这类“平台级监控聚合”是多集群治理的核心,因为它把排障入口从“到每个集群开 Prometheus”变成“在 Fleet 统一看”。
11. Day2:统一合规与策略——Policy(Kyverno)+ PolicyReport 把合规变成可审计对象 🛡️
策略教程明确:Fleet 的多集群策略管理构建在 Kyverno 之上,并给出完整闭环:启用策略 → 下发违规对象 → 查看 PolicyReport 与事件。
平台价值:
- “策略下发”只是第一步;
- 真正平台化的是 PolicyReport/事件 这种可审计输出,让合规从“口头约束”变成“可查询、可追踪、可回归”的对象。
12. Day2:跨集群互通——Submariner Plugin 让 Fleet 内服务通信可验证 🌐
Submariner 插件教程给出了一整套官方步骤:
- 创建访问 attached clusters 的 secret;
- 给每个集群标记 gateway 节点;
- 生成 PSK 并应用 submariner-plugin.yaml;
- 使用
subctl diagnose与subctl verify做双向验证。
平台工程解读:
网络互通是“跨集群分发/跨集群服务发现”的前置地基。Kurator 把它收敛到 Fleet plugin,并提供可验证工具链(subctl),比“手工装 CNI/写脚本”更可控。
13. Day2:统一灰度发布入口——Rollout(Flagger)+ Provider(Istio/Kuma/Nginx)🚦
Rollout 相关文档显示:Kurator 的统一 Rollout 基于 Flagger,并在教程中提供不同 provider 的实践页面(例如 Nginx Canary)。
平台工程解读:
灰度发布在多集群里之所以难,是因为流量入口实现差异大。Kurator 把差异显式化为 provider(Istio/Kuma/Nginx),让平台可以分阶段统一:先统一一种 provider,再逐步扩展。
14. Day2:统一容灾与迁移——Unified Backup/Restore/Migration(Velero)🧯
Kurator 的 Unified Backup 文档明确:它提供跨 Fleet 所有集群的统一备份方案,覆盖从 namespace 到整个集群不同粒度;并在“Unified Backup, Restore, and Migration”章节说明这是为了解决多环境下备份/恢复/迁移的清晰一致性问题。
同时,安装 Backup Plugin 的页面明确:该能力以 Velero-based backup plugin 为基础,需要先配置 Fleet 的 backup plugin。
平台工程解读:
多集群时代,容灾不是“某个集群备份了就行”,而是“治理域(Fleet)整体可恢复”。Kurator 把备份/恢复/迁移收敛到 Fleet 的统一能力模型,这非常符合平台工程思路。
如果你对其部署过程有疑问,可进行其官网文档进行求解。
15. Day2:统一分布式存储——DistributedStorage Plugin(Rook)🗄️
Unified Distributed Storage 文档明确:Kurator 的统一分布式存储建立在 Rook 之上,并把它作为 Fleet 的 distributed storage plugin。
平台工程解读:
存储往往是“跨集群应用迁移/容灾”的硬前置。把存储能力也收敛到 Fleet plugin 的声明式配置,会显著降低跨环境差异导致的“迁移失败/恢复失败”。
16. 另一个“换角度”的加分点:Pipeline(把平台交付流程也声明式化)🧰
Kurator 文档中还有 Pipeline 章节(Setting Up Your Pipeline),给出“按步骤搭建 pipeline”的说明,并展示了自定义 task 的结构(包含 customTask.image/command/args/env 等字段)。
平台工程解读:
很多团队平台化最后卡在“流程不统一”:集群变更、应用交付、策略变更、回滚审批……各自为政。Pipeline 章节提供了把任务编排也纳入声明式配置的思路,适合作为投稿文章的“前瞻平台化补强”部分(且仍属官方资料范围)。
如下是它的架构图:
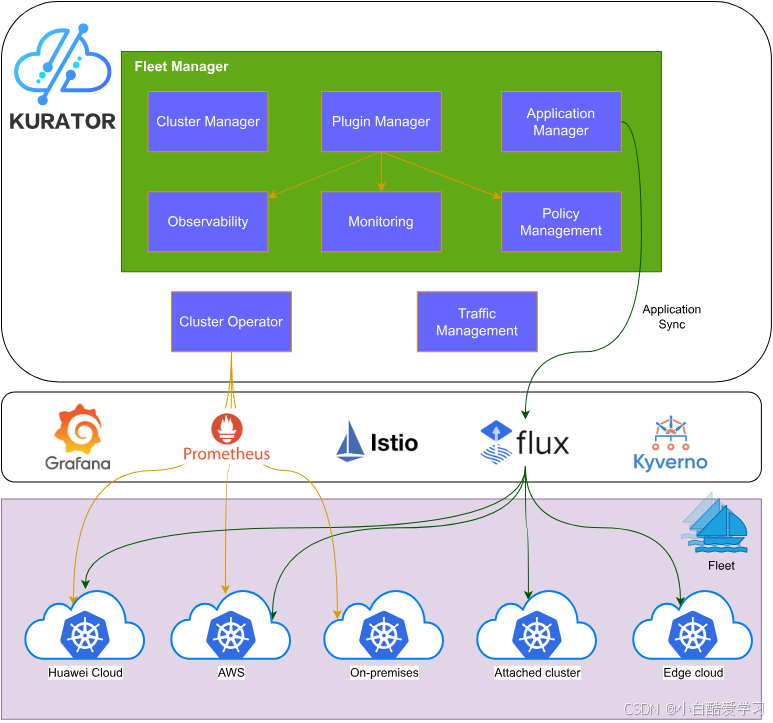
17. 总结:用 Fleet 把 Day0/Day1/Day2 的“平台职责”收敛到一个控制面 ✅
从官方文档可以看到 Kurator 的平台化路径非常一致:
- Day0:Setup(cluster operator / cli)奠定安装与集群生命周期基座
- Day0→Day1:Fleet manager + Fleet API 把“集群组”变治理域
- Day1:Application(FluxCD GitOps)把交付范围从集群提升到 Fleet
- Day2:监控(Prometheus+Thanos)、策略(Kyverno)、网络(Submariner)、灰度发布(Flagger)与容灾(Velero)/存储(Rook)形成“平台常驻能力包”
这套体系的最大价值不是“集成了很多组件”,而是把这些组件的安装、配置、分发、治理都统一收敛到 Fleet + Plugins + Application 的声明式模型中,让平台团队能以“治理域”为单位持续演进,而不是以“单集群”为单位疲于救火。
最后,附上Kurator 开源地址:
- Kurator分布式云原生开源社区地址:https://gitcode.com/kurator-dev
- Kurator分布式云原生项目部署指南:https://kurator.dev/docs/setup/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 22
22 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)