【前瞻创想】从边缘计算到多云协同:Kurator分布式云原生平台架构深度解析与企业级多集群管理应用场景实战指南
【前瞻创想】从边缘计算到多云协同:Kurator分布式云原生平台架构深度解析与企业级多集群管理应用场景实战指南
【前瞻创想】从边缘计算到多云协同:Kurator分布式云原生平台架构深度解析与企业级多集群管理应用场景实战指南
摘要
随着企业数字化转型深入,分布式云原生架构成为支撑业务创新的关键基础设施。Kurator作为开源的分布式云原生平台,集成了Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等众多优秀云原生项目,为企业提供统一的多云、多集群管理能力。本文深入剖析Kurator的核心架构设计,通过实战演示环境搭建、Fleet多集群管理、GitOps工作流、边缘计算集成、Volcano调度优化等关键场景,揭示其在统一资源编排、统一调度、统一流量管理、统一遥测等方面的创新优势。文章结合真实业务场景,探讨Kurator在企业级应用中的最佳实践,并对其未来发展方向提出前瞻性见解,为云原生技术从业者提供全面的技术参考和实践指南。
一、Kurator云原生平台概述与核心架构
分布式云原生架构参考图: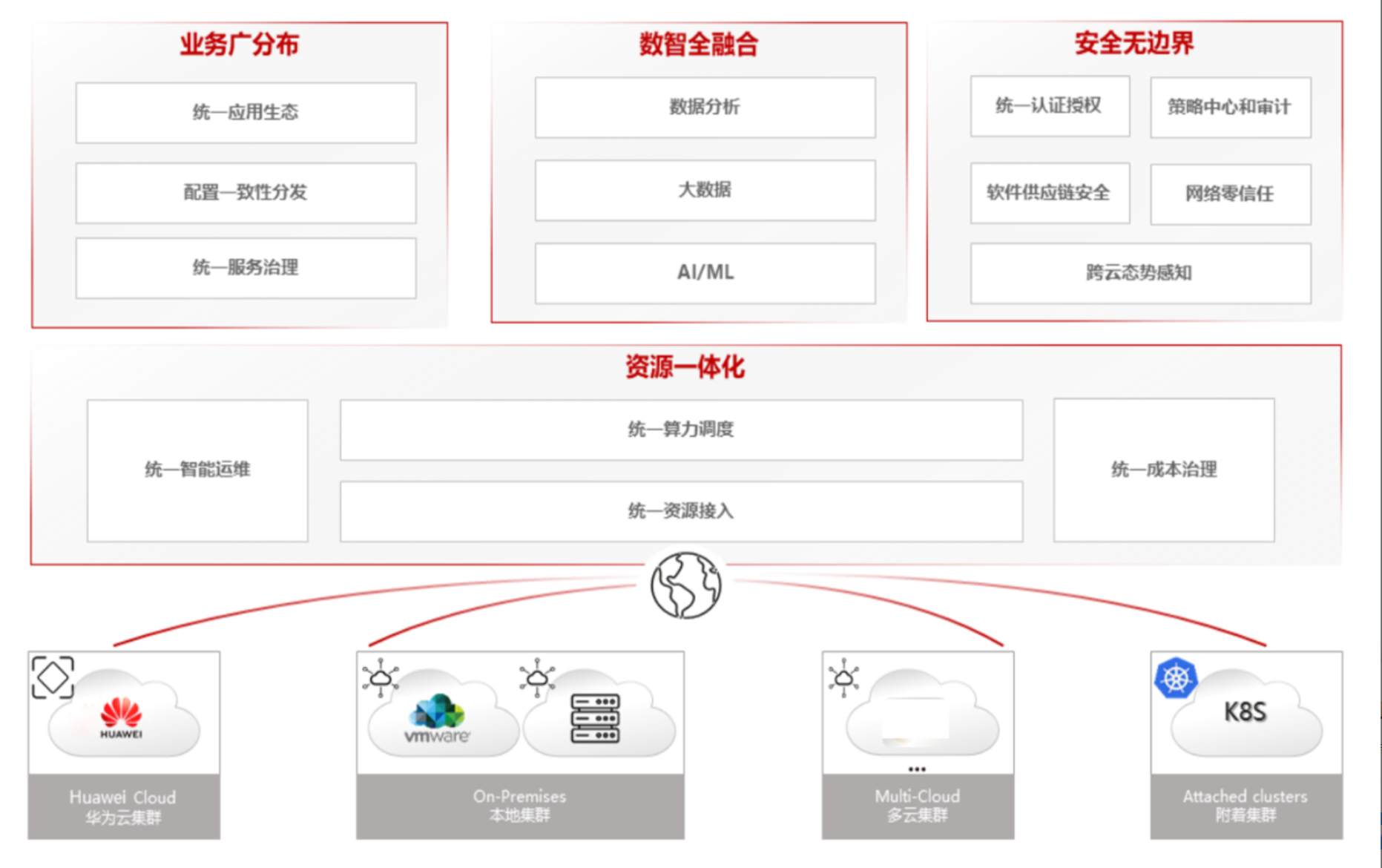
1.1 分布式云原生的演进与挑战
随着企业业务向数字化、智能化转型,传统的单集群Kubernetes架构已难以满足复杂业务场景需求。多云、混合云、边缘计算等新兴场景催生了分布式云原生架构的发展。然而,分布式环境带来了一系列挑战:集群管理复杂度指数级增长、应用跨集群分发困难、资源调度缺乏全局视角、网络连通性保障复杂、监控与治理碎片化等。
Kurator应运而生,作为站在"巨人肩膀上"的分布式云原生平台,它不仅继承了Kubernetes生态的丰富能力,更通过创新性的架构设计,将多集群管理、边缘计算、批处理调度等能力有机整合,为用户提供开箱即用的分布式云原生解决方案。Kurator的核心价值在于提供统一的抽象层,屏蔽底层基础设施差异,让开发者能够专注于业务创新而非基础设施管理。
1.2 Kurator的架构设计与核心组件
kurator架构参考图: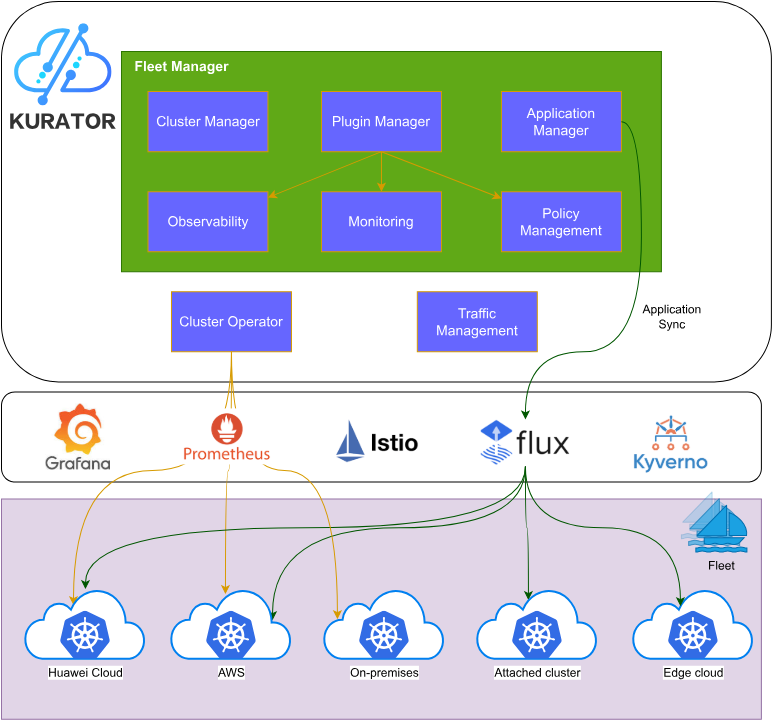
Kurator采用分层架构设计,底层依托于Kubernetes生态,中间层集成Karmada、KubeEdge、Volcano等专项能力组件,上层通过Fleet提供统一的管理接口和策略引擎。这种架构既保证了技术先进性,又确保了工程可实施性。
核心组件包括:
- Fleet Manager:负责多集群的注册、生命周期管理、资源拓扑展示
- GitOps Controller:基于FluxCD实现声明式配置管理和应用分发
- Policy Engine:基于Kyverno提供跨集群策略统一管理
- Scheduler Framework:整合Volcano调度器,支持复杂的批处理和AI工作负载
- Edge Controller:集成KubeEdge,实现边缘节点管理和边缘-云协同
- Telemetry Hub:聚合多集群指标,提供统一监控视图
这种模块化设计使得Kurator能够灵活适应不同业务场景,同时保持架构的清晰度和可扩展性。
1.3 Kurator与传统云原生平台的差异化优势
与传统云原生平台相比,Kurator在以下方面具有显著优势:
- 统一性:提供统一的资源编排、调度、流量管理和遥测能力,避免了多套系统带来的管理复杂度
- 开放性:完全开源且兼容CNCF生态,避免厂商锁定,保护企业技术投资
- 场景化:针对边缘计算、AI/ML、大数据等特定场景提供优化解决方案
- 声明式:通过Infrastructure-as-Code理念,将基础设施管理提升到代码级别,支持版本控制和自动化
- 企业级:内置的安全策略、合规检查、审计日志等功能,满足企业级应用需求
这些优势使Kurator成为企业构建分布式云原生基础设施的理想选择,特别是在需要跨地域、跨云、跨边缘环境协同的复杂业务场景中。
二、Kurator集成的开源云原生技术栈
Kurator开源项目参考图:
2.1 Karmada多集群管理的核心价值
Karmada作为Kurator的核心组件之一,提供了强大的多集群调度和管理能力。它通过Cluster API抽象不同云厂商和自建集群,实现了统一的集群生命周期管理。Karmada的核心价值在于其先进的调度策略,支持基于资源配额、故障域、延迟等多维度的集群选择,并提供应用跨集群分发的弹性伸缩能力。
在Kurator中,Karmada不仅负责集群管理,还与Fleet深度集成,实现了命名空间、ServiceAccount、Service等资源的跨集群一致性保证。这种设计大大简化了多集群应用的开发和运维复杂度,开发者只需关注业务逻辑,而不必担心底层集群差异。
2.2 KubeEdge边缘计算架构解析
KubeEdge是Kurator在边缘计算场景的关键组件,它将Kubernetes原生能力扩展到边缘节点,实现了云-边-端的统一管理。KubeEdge架构包含云端组件(CloudCore)和边缘组件(EdgeCore),通过WebSocket和Quic协议建立安全连接,支持离线场景下的边缘自治。
在Kurator中,KubeEdge与Karmada协同工作,实现了边缘集群的自动注册、边缘应用的统一调度和边缘数据的高效同步。这种集成架构使得企业能够轻松构建边缘计算平台,支持物联网、智能制造、智慧城市等场景的快速落地。KubeEdge的核心组件包括:
- EdgeHub:负责云端与边缘的通信
- EdgeMesh:提供边缘节点间的服务发现和通信
- DeviceTwin:管理边缘设备状态
- MetaManager:本地元数据存储,支持离线运行
2.3 Volcano批处理调度与资源优化
Volcano作为CNCF沙箱项目,专为AI/ML、大数据、HPC等批处理工作负载设计。Kurator深度集成了Volcano,提供了先进的队列管理、作业调度和资源优化能力。Volcano的核心概念包括Queue(队列)、PodGroup(Pod组)和Job(作业),通过这些抽象,实现了复杂的调度策略如gang scheduling(全有或全无调度)、fair-share(公平共享)、priority(优先级)等。
在Kurator中,Volcano不仅服务于单集群场景,还能与Karmada协同实现跨集群的工作负载调度。这种能力对于需要大量计算资源的AI训练任务尤为重要,可以充分利用多集群资源,提升整体资源利用率。Volcano的调度架构采用插件化设计,支持多种调度策略的灵活组合,满足不同业务场景的需求。
三、Kurator环境搭建与初始化配置
3.1 本地环境准备与依赖安装
在开始搭建Kurator环境前,需要准备以下基础设施:
- 至少一台Linux服务器(推荐Ubuntu 20.04+或CentOS 7+)
- 4核8G内存配置(最小要求,生产环境建议更高)
- Docker 20.10+ 或 containerd 1.4+
- Kubernetes 1.21+ 集群(可以使用Kind、Minikube或云厂商托管集群)
- kubectl 1.21+ 客户端工具
- Helm 3.8+ 包管理工具
安装基础依赖:
# 安装基础工具
sudo apt-get update
sudo apt-get install -y curl wget git jq
# 安装kubectl
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
# 安装Helm
curl https://baltocdn.com/helm/signing.asc | sudo apt-key add -
sudo apt-get install apt-transport-https --yes
echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
# 验证安装
kubectl version --client --short
helm version
3.2 Kurator源码获取与编译构建
获取Kurator源码是环境搭建的关键步骤,根据要求使用git命令:
# 克隆Kurator源代码
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 或者使用wget方式
# wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
# unzip main.zip
# mv kurator-main kurator
# cd kurator
# 查看源码结构
ls -la
# 主要目录包括:
# charts/ - Helm chart定义
# cmd/ - 命令行工具源码
# config/ - 配置文件
# docs/ - 文档
# examples/ - 示例配置
# pkg/ - 核心包代码
# scripts/ - 构建和部署脚本
# test/ - 测试代码
# 构建Kurator CLI工具
make build
# 生成的二进制文件在_bin/目录下
ls _bin/
在项目地址中,可以看到可以clone到本地
https://gitcode.com/kurator-dev/kurator.git
或者我们也可以下载到本地
可以看到我们资源文件已经下载下来了
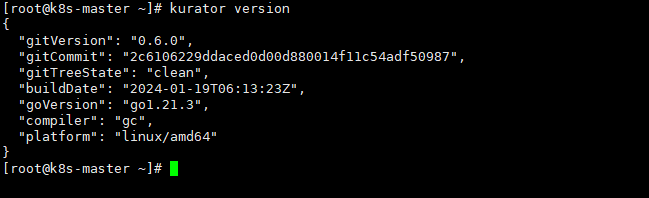
可以看到版本是0.6.0
源码结构清晰,符合Go项目的标准布局。cmd/目录包含CLI工具的入口,pkg/目录包含核心业务逻辑,charts/目录定义了Helm chart,便于部署。理解源码结构对于深入掌握Kurator的工作原理至关重要。
3.3 集群初始化与核心组件部署
使用构建好的CLI工具初始化Kurator集群:
# 安装Kurator CLI到系统路径
sudo cp _bin/kurator /usr/local/bin/
# 初始化Kurator控制平面
kurator init --components=core,karmada,volcano,kubeedge
# 验证安装
kubectl get pods -n kurator-system
# 应该看到类似以下输出:
# NAME READY STATUS RESTARTS AGE
# kurator-controller-manager-7df859b9bd-2jklm 2/2 Running 0 5m
# karmada-controller-manager-6b7c8d9f45-xcvbn 1/1 Running 0 4m
# volcano-admission-5d6f7b8c9d-qwerty 1/1 Running 0 3m
# kubeedge-cloudcore-7c6b9d8f54-asdfg 1/1 Running 0 2m
# 配置kubectl上下文
kurator kubeconfig --admin
# 部署示例应用验证功能
kubectl apply -f examples/fleet/quick-start.yaml
kubectl get fleet -n kurator-fleet-system
初始化过程会自动部署Kurator的核心组件,包括Fleet Manager、Karmada控制器、Volcano调度器和KubeEdge云端组件。这个过程可能需要10-15分钟,取决于网络速度和集群性能。初始化完成后,可以通过kubectl命令验证各个组件的运行状态。
四、Fleet多集群管理实践与深度剖析
4.1 Fleet架构设计与集群注册机制
Fleet架构官方参考图: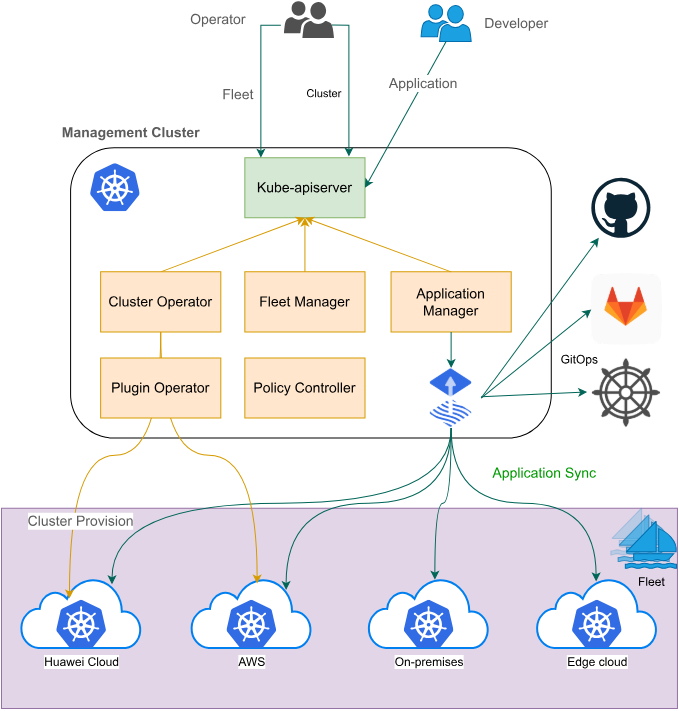
Fleet是Kurator多集群管理的核心抽象,它将多个Kubernetes集群组织成一个逻辑单元,提供统一的管理视图。Fleet架构采用中心化控制平面+分布式执行的设计,控制平面负责策略定义和状态聚合,执行平面负责具体策略的实施。
集群注册是Fleet管理的第一步,Kurator支持两种注册方式:主动注册和被动注册。主动注册由集群管理员发起,使用kurator命令行工具;被动注册由Fleet控制平面发起,适用于大规模自动化场景。注册过程中,Kurator会自动配置集群间的安全通信,生成必要的证书和RBAC策略。
# fleet.yaml - 定义Fleet资源
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
namespace: kurator-fleet-system
spec:
clusters:
- name: cluster-east
kubeconfigSecret: cluster-east-kubeconfig
- name: cluster-west
kubeconfigSecret: cluster-west-kubeconfig
- name: edge-cluster-01
kubeconfigSecret: edge-cluster-01-kubeconfig
placement:
clusterSelector:
region: production
Fleet资源定义了集群成员和放置策略,通过标签选择器动态管理集群成员。这种声明式设计使得集群管理变得简单而灵活,管理员只需关注"什么"而非"如何"。
4.2 跨集群服务发现与通信实现
在多集群环境中,服务发现和通信是最具挑战性的问题之一。Kurator通过Service Export和Service Import机制实现了跨集群服务发现。当一个服务在某个集群中被标记为可导出时,Kurator会自动将其元数据同步到其他集群,其他集群中的应用可以通过标准的Kubernetes DNS访问该服务。
# serviceexport.yaml - 导出服务到Fleet
apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceExport
meta
name: frontend
namespace: default
spec: {}
Service Export资源标记了需要导出的服务,Kurator会自动处理跨集群的服务同步。对于服务通信,Kurator支持多种模式:
- ClusterIP模式:通过全局唯一的VIP实现跨集群访问
- Headless模式:直接访问Pod的Endpoint,适用于有状态服务
- Gateway模式:通过Istio网关实现跨集群流量管理
这些模式可以根据业务需求灵活选择,平衡性能、可用性和复杂度。
4.3 Fleet策略引擎与合规性保障
在多集群环境中,保持策略一致性是运维的核心挑战。Kurator基于Kyverno构建了强大的策略引擎,支持跨集群的策略统一管理和执行。策略类型包括:
- 安全策略:Pod安全标准、网络策略、镜像签名验证
- 资源策略:资源配额、资源限制、命名规范
- 合规策略:PCI-DSS、HIPAA、GDPR等法规合规
# policy.yaml - 跨集群策略示例
apiVersion: kyverno.io/v1
kind: ClusterPolicy
meta
name: require-pod-probes
spec:
validationFailureAction: enforce
rules:
- name: check-readiness-probe
match:
any:
- resources:
kinds:
- Pod
validate:
message: "Readiness probe is required"
pattern:
spec:
containers:
- readinessProbe:
periodSeconds: ">0"
策略引擎支持dry-run模式,可以在强制执行前评估策略影响。同时,提供详细的审计日志和通知机制,帮助团队快速响应策略违规事件。这种设计不仅提升了安全性,还降低了合规成本。
五、GitOps工作流在Kurator中的实现
GitOps流水线参考图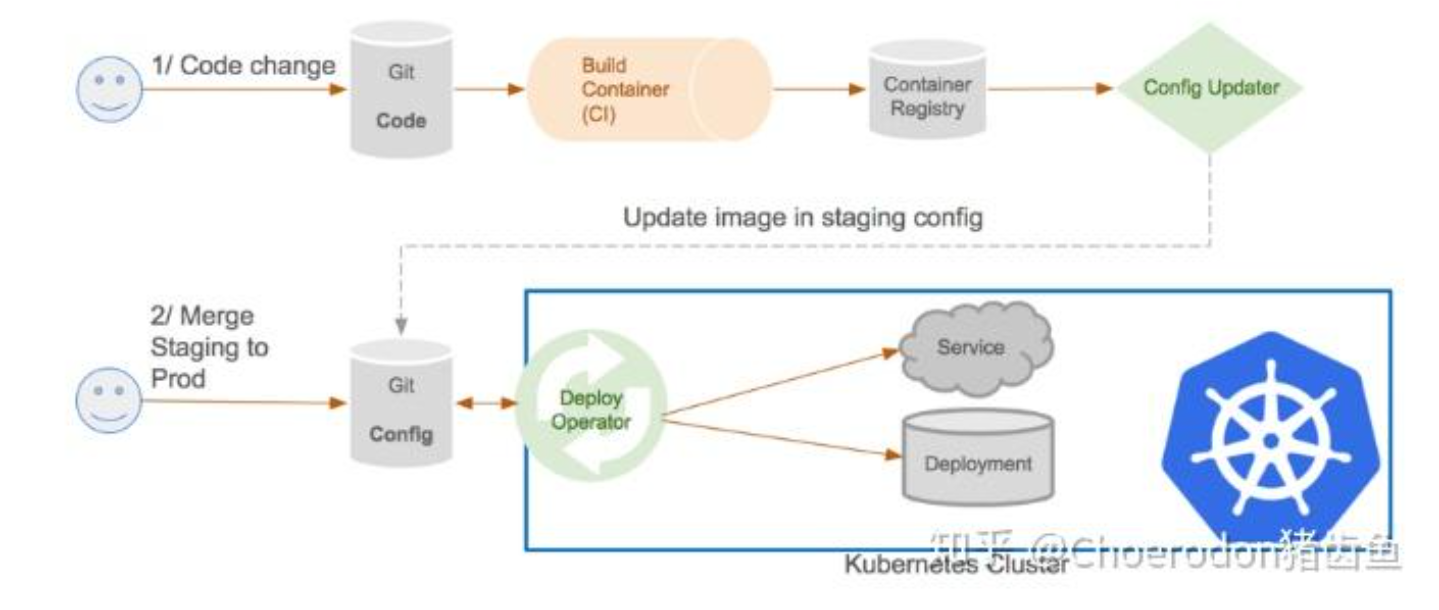
5.1 FluxCD与Kurator的集成架构
GitOps作为云原生领域的新兴范式,强调通过Git仓库作为系统状态的唯一数据源。Kurator深度集成了FluxCD,构建了完整的GitOps工作流。集成架构包含三个核心组件:
- Source Controller:管理Git仓库、Helm仓库等源
- Kustomize Controller:处理Kustomize配置
- Helm Controller:管理Helm chart部署
这些组件与Kurator的Fleet管理深度集成,实现了跨集群的配置同步。当Git仓库中的配置发生变化时,FluxCD会自动检测变更并应用到目标集群,确保系统状态与期望状态一致。
# gitrepository.yaml - 定义Git源
apiVersion: source.toolkit.fluxcd.io/v1
kind: GitRepository
metadata:
name: app-config
namespace: flux-system
spec:
interval: 1m0s
url: https://github.com/organization/app-config
ref:
branch: main
secretRef:
name: git-auth
GitRepository资源定义了配置源,Kurator会自动将其与Fleet关联,实现跨集群同步。
5.2 基于GitOps的多集群应用分发
多集群应用分发是Kurator GitOps实现的核心场景。通过Kustomize overlays和Helm values文件,可以为不同集群定制差异化配置,同时保持核心配置的一致性。
# 目录结构示例
app-config/
├── base/
│ ├── deployment.yaml
│ ├── service.yaml
│ └── kustomization.yaml
├── overlays/
│ ├── cluster-east/
│ │ ├── replicas.yaml
│ │ └── kustomization.yaml
│ ├── cluster-west/
│ │ ├── replicas.yaml
│ │ └── resources.yaml
│ │ └── kustomization.yaml
│ └── edge-cluster/
│ ├── resources.yaml
│ ├── nodeSelector.yaml
│ └── kustomization.yaml
└── fleet.yaml
在base目录中定义通用配置,在overlays目录中为每个集群定义差异化配置。fleel.yaml文件定义了如何将这些配置应用到不同的集群:
# fleet.yaml - 多集群部署配置
apiVersion: fleet.kurator.dev/v1alpha1
kind: Application
meta
name: my-app
namespace: kurator-fleet-system
spec:
source:
git:
repoURL: https://github.com/organization/app-config
path: base
targetRevision: main
destinations:
- cluster: cluster-east
namespace: production
kustomize:
path: overlays/cluster-east
- cluster: cluster-west
namespace: production
kustomize:
path: overlays/cluster-west
- cluster: edge-cluster-01
namespace: edge
kustomize:
path: overlays/edge-cluster
这种设计使得团队可以高效管理多环境配置,同时保持变更的可追溯性和可审计性。
5.3 CI/CD流水线与自动化运维
Kurator CI/CD 的结构参考图: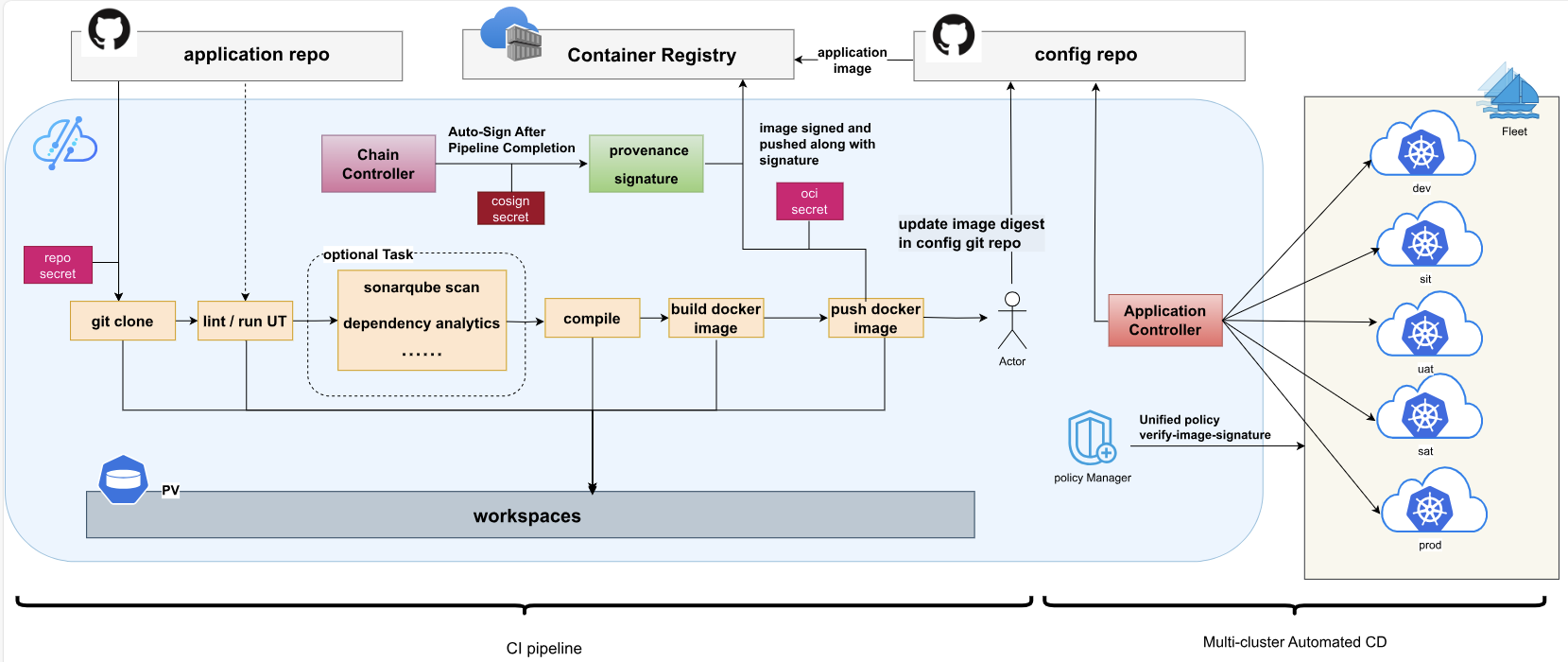
在Kurator中,CI/CD流水线与GitOps工作流紧密结合。典型的流水线包含以下阶段:
- 代码构建:编译应用代码,生成容器镜像
- 镜像推送:将镜像推送到容器仓库,打上版本标签
- 配置更新:更新Git仓库中的部署配置,引用新镜像
- 自动化测试:在staging环境中验证新版本
- 金丝雀发布:逐步将流量切换到新版本
- 监控告警:实时监控应用健康状态,异常时自动回滚
# .github/workflows/ci-cd.yaml - GitHub Actions示例
name: Kurator CI/CD Pipeline
on:
push:
branches: [ main ]
paths:
- 'app/**'
pull_request:
branches: [ main ]
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
- name: Login to Container Registry
uses: docker/login-action@v2
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push Docker image
uses: docker/build-push-action@v4
with:
context: ./app
push: true
tags: ghcr.io/${{ github.repository }}/app:${{ github.sha }}
- name: Update deployment configuration
run: |
sed -i "s|image: .*|image: ghcr.io/${{ github.repository }}/app:${{ github.sha }}|" \
app-config/base/deployment.yaml
git config user.name "github-actions"
git config user.email "github-actions@github.com"
git add app-config/base/deployment.yaml
git commit -m "Update app image to ${{ github.sha }}"
git push
这个流水线实现了从代码提交到生产部署的全自动化,通过GitOps原则确保了部署过程的可靠性和可审计性。Kurator的策略引擎会验证所有配置变更,防止不合规的部署进入生产环境。
六、边缘计算场景下的Kurator实践
6.1 边缘-云协同架构设计
KubeEdge架构参考图: 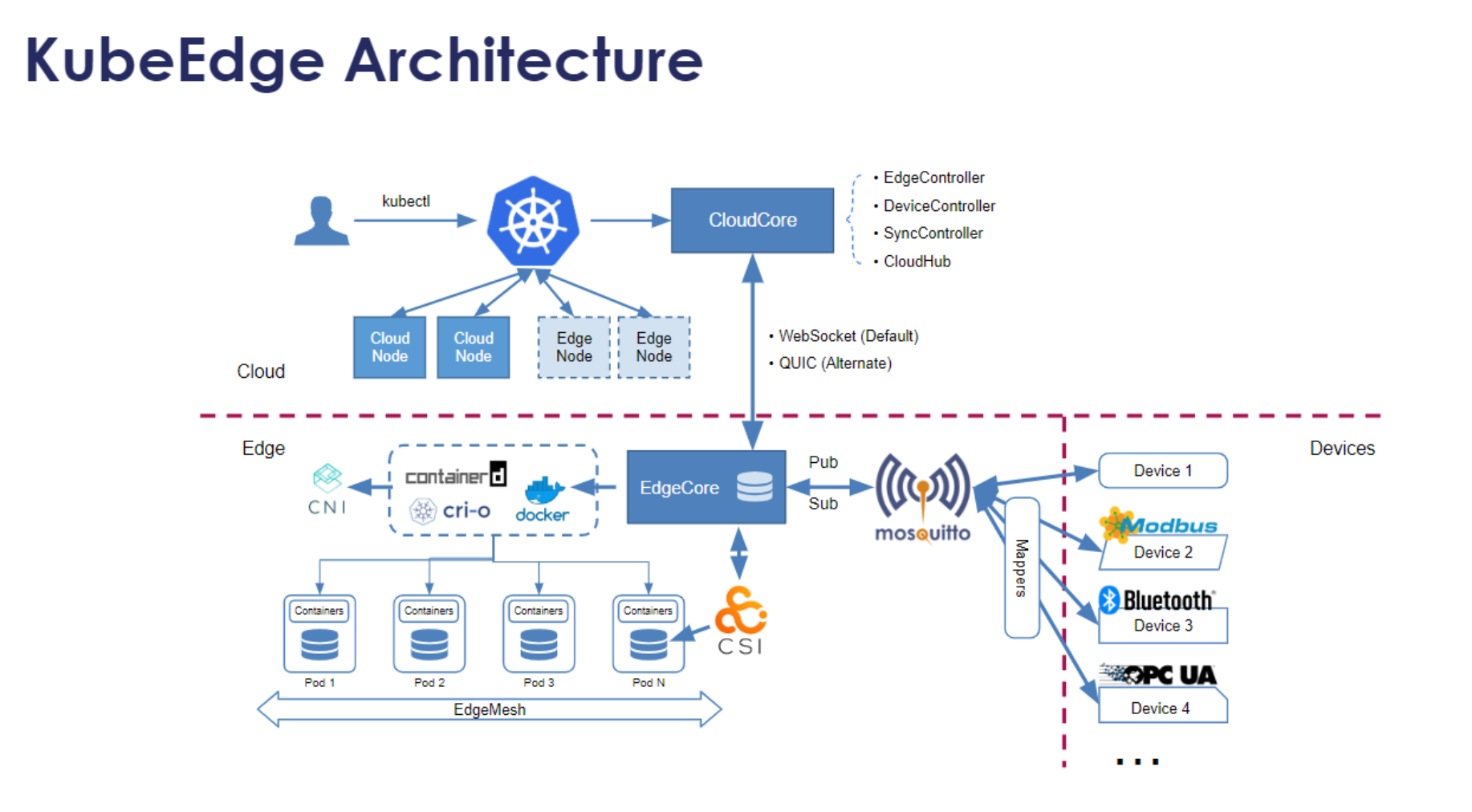
边缘计算场景要求系统在低带宽、高延迟、不稳定网络条件下仍能正常工作。Kurator通过KubeEdge实现了边缘-云协同架构,将云原生能力无缝扩展到边缘。
核心架构包括:
- 云端控制面:运行在中心数据中心,负责全局调度、策略管理和状态聚合
- 边缘节点:部署在靠近数据源的边缘位置,运行EdgeCore和业务应用
- 边缘自治:在网络断开时,边缘节点能够基于本地状态继续运行
- 增量同步:网络恢复后,仅同步变更状态,减少带宽消耗
# edge-node.yaml - 注册边缘节点
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeNode
meta
name: edge-node-01
spec:
cluster: edge-cluster-01
labels:
location: factory-floor
zone: production
annotations:
kurator.dev/edge-type: industrial
resources:
cpu: "4"
memory: 16Gi
storage: 500Gi
EdgeNode资源定义了边缘节点的元数据和资源规格,Kurator会根据这些信息进行智能调度。
6.2 边缘节点资源调度与优化
边缘节点资源调度参考图: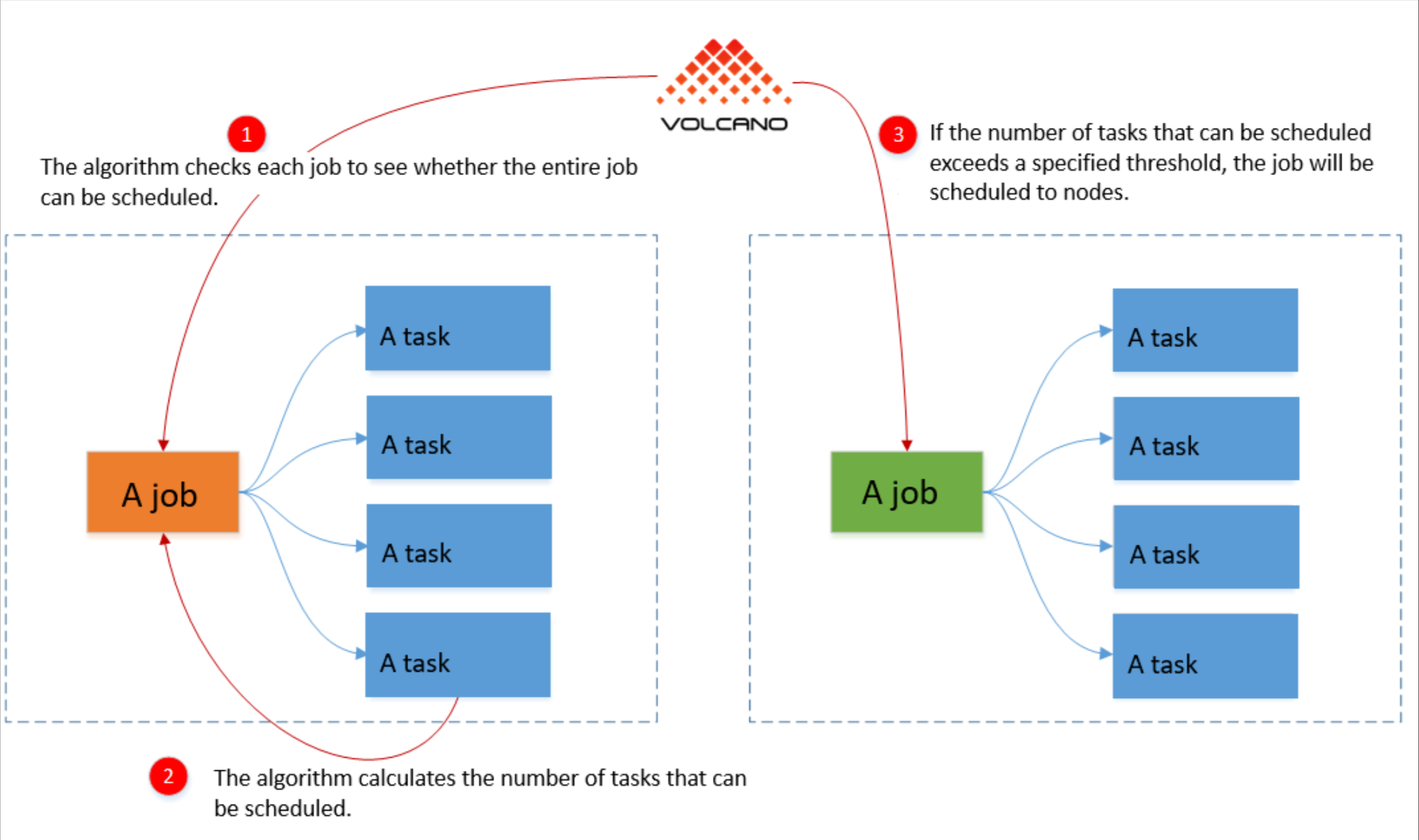
在边缘场景中,资源通常受限且异构。Kurator结合Volcano和Karmada,提供了针对边缘环境优化的调度策略:
- 拓扑感知:考虑边缘节点的物理位置和网络拓扑
- 延迟敏感:将延迟敏感型应用调度到靠近用户的边缘节点
- 资源碎片整理:自动合并碎片化资源,提高利用率
- 能效优化:对于电池供电的边缘设备,优化任务调度以延长电池寿命
# volcano-job.yaml - 边缘AI推理任务
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: edge-ai-inference
spec:
minAvailable: 1
schedulerName: volcano
queue: edge-low-priority
tasks:
- replicas: 3
name: inference
policies:
- event: PodEvicted
action: RestartJob
template:
spec:
containers:
- name: model-serving
image: edge-ai/model-serving:1.0
resources:
limits:
cpu: "2"
memory: 4Gi
nvidia.com/gpu: 1
env:
- name: MODEL_PATH
value: "/models/production"
volumeMounts:
- name: model-volume
mountPath: /models
nodeSelector:
kurator.dev/edge-type: industrial
tolerations:
- key: "edge"
operator: "Equal"
value: "true"
effect: "NoSchedule"
volumes:
- name: model-volume
persistentVolumeClaim:
claimName: edge-model-pvc
这个Volcano Job定义了一个边缘AI推理任务,通过nodeSelector和tolerations确保任务被调度到合适的边缘节点,同时利用GPU资源加速推理。
6.3 边缘场景网络连通性保障
网络连通性排查参考图: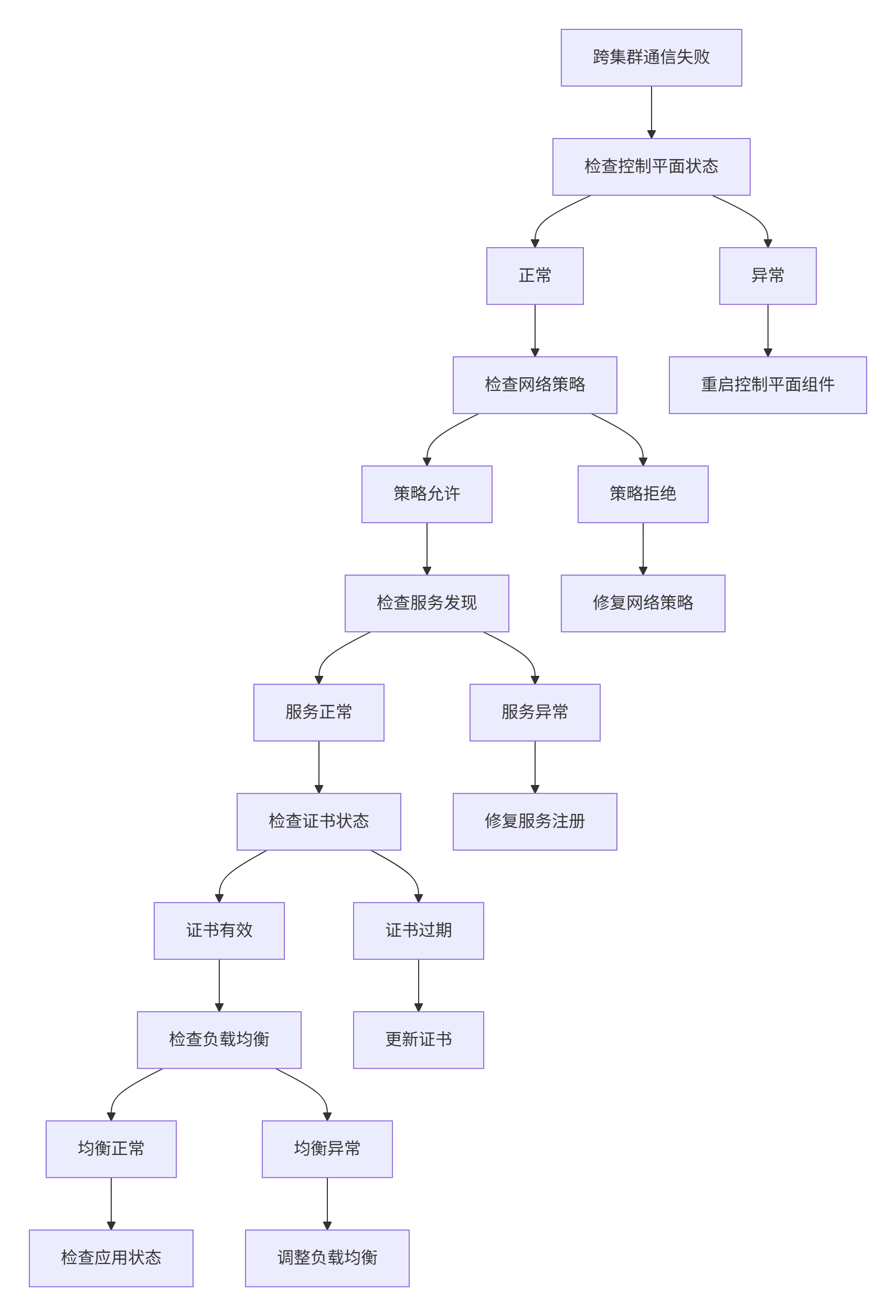
边缘环境的网络条件通常复杂多变,Kurator提供了多种机制保障网络连通性:
- 多协议支持:支持WebSocket、Quic、MQTT等多种通信协议,适应不同网络条件
- 连接复用:通过长连接和连接池技术,减少连接建立开销
- 断线重连:自动检测网络故障,实现无缝重连
- 流量压缩:对同步数据进行压缩,减少带宽消耗
- 隧道技术:在NAT或防火墙环境下,通过隧道建立连接
# 配置边缘节点网络隧道
kubectl exec -n kubeedge edge-controller-0 -- \
edgecore config set --tunnel.enable=true \
--tunnel.token=your-secure-token \
--tunnel.server=cloud-tunnel-server:10000
# 验证隧道连接状态
kubectl logs -n kubeedge edge-controller-0 | grep tunnel
# 应该看到类似输出:
# I1221 10:30:45.321847 1 tunnel.go:123] Tunnel connection established successfully
# I1221 10:30:45.322014 1 tunnel.go:156] Tunnel health check passed
隧道配置是边缘-云通信的关键,Kurator通过可视化界面简化了这一过程,管理员可以直观地查看隧道状态和流量统计,快速诊断网络问题。
七、Kurator调度体系与资源优化
7.1 Volcano Scheduler工作流
Volcano Scheduler是Kurator批处理调度的核心组件,专为AI/ML、大数据等计算密集型工作负载设计。其工作流包含以下关键阶段:
- 预选(Predicates):过滤不符合基本要求的节点
- 优先级排序(Priorities):为剩余节点打分排序
- 绑定(Binding):将Pod分配到最佳节点
- 抢占(Preemption):必要时驱逐低优先级任务
- 重调度(Rescheduling):动态优化资源分配
Volcano的插件化架构允许灵活组合不同的调度策略,满足多样化业务需求。在Kurator中,Volcano与Karmada集成,实现了跨集群的全局调度视图。
# volcano-scheduler-config.yaml - 调度器配置
apiVersion: volcano.sh/v1beta1
kind: SchedulerConfiguration
plugins:
preFilter:
enabled:
- name: PodGroup
- name: ResourceFit
filter:
enabled:
- name: NodeAffinity
- name: PodAffinity
- name: TaintToleration
score:
enabled:
- name: BalancedResourceAllocation
- name: NodeAffinity
- name: PodAffinity
preBind:
enabled:
- name: VolumeBinding
bind:
enabled:
- name: DefaultBinder
reserve:
enabled:
- name: Gang
这个配置定义了一个典型的Volcano调度器,启用了多种插件来处理不同的调度场景。
7.2 Karmada跨集群弹性伸缩策略实现
Karmada为Kurator提供了跨集群弹性伸缩能力,通过PropagtionPolicy和ClusterPropagationPolicy定义应用的分发策略。弹性伸缩策略包括:
- 基于指标:根据CPU、内存、自定义指标动态调整副本数
- 基于时间:按预定时间表调整资源分配
- 基于事件:响应外部事件(如促销活动)快速扩缩容
- 基于成本:在满足SLA前提下,选择成本最优的集群
# propagation-policy.yaml - 跨集群策略
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: web-app-policy
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: web-app
placement:
clusterAffinity:
clusterNames:
- cluster-east
- cluster-west
replicaScheduling:
replicaSchedulingType: Duplicated
replicaDivisionPreference: Weighted
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- cluster-east
weight: 70
- targetCluster:
clusterNames:
- cluster-west
weight: 30
spreadConstraints:
- spreadByField: cluster
maxGroups: 2
这个策略定义了web-app应用的跨集群分发规则,70%的流量导向cluster-east,30%导向cluster-west,同时确保应用在两个集群都有部署,提供高可用性。
7.3 资源拓扑感知与分组调度
在AI/ML和大数据场景中,任务通常需要访问特定的硬件资源(如GPU、TPU)或数据位置。Kurator通过Volcano的PodGroup和Queue机制,实现了资源拓扑感知和分组调度:
# podgroup.yaml - 定义Pod组
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
meta
name: training-job
spec:
minMember: 8
minTaskMember:
- name: worker
minMember: 6
- name: ps
minMember: 2
queue: ai-training
PodGroup定义了任务的最小成员要求,确保所有Pod同时调度成功。Queue机制实现了资源的公平共享和优先级管理:
# queue.yaml - 定义队列
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: ai-training
spec:
weight: 50
capability:
cpu: "100"
memory: 500Gi
nvidia.com/gpu: "16"
reclaimable: true
Queue定义了资源配额和权重,Kurator会根据队列优先级动态分配资源。这种设计特别适合共享的AI训练平台,可以高效利用昂贵的GPU资源。
八、Kurator未来发展方向与技术展望
8.1 分布式云原生技术趋势
随着5G、物联网、边缘计算的普及,分布式云原生架构将成为主流。Kurator作为这一领域的先行者,正在引领多项技术创新:
- 统一服务网格:跨集群、跨边缘的服务治理,实现无缝的服务通信
- 智能调度:结合AI/ML技术,实现预测性调度和自适应资源分配
- 安全增强:零信任架构、机密计算、同态加密等技术在分布式环境的应用
- 可观测性统一:跨集群、跨边缘的统一监控、日志和追踪
- WebAssembly集成:利用WASM实现轻量级、高性能的边缘计算
这些技术趋势将推动Kurator向更智能、更安全、更高效的分布式云原生平台演进。
8.2 Kurator社区生态建设
开源社区是Kurator成功的关键。未来将重点建设以下方面:
- 开发者体验:简化贡献流程,完善文档和示例
- 多语言支持:除Go外,支持Python、Rust等语言的SDK
- 认证体系:建立Kurator专业认证,培养专业人才
- 行业解决方案:为金融、医疗、制造等行业提供特定解决方案
- 全球协作:建立多时区的社区协作机制,促进国际交流
健康的社区生态将确保Kurator的长期可持续发展,并加速技术创新。
8.3 企业级应用最佳实践建议
基于实践经验,为企业采用Kurator提出以下建议:
- 渐进式采用:从非关键业务开始,逐步扩展到核心系统
- 能力培养:投资团队培训,建立云原生能力中心
- 架构治理:制定清晰的架构标准和治理策略
- 度量驱动:建立完善的度量体系,持续优化资源利用率
- 安全优先:将安全设计融入架构,而非事后补救
- 生态整合:与现有IT系统平滑集成,避免孤岛
Kurator不仅是一个技术平台,更是一种新的IT运营模式。企业需要在技术、流程和人员三方面同步转型,才能真正发挥分布式云原生的价值。
结语
Kurator作为开源的分布式云原生平台,通过集成Kubernetes生态中的优秀项目,为企业提供了统一的多云、多集群、边缘计算管理能力。本文从架构设计、环境搭建、Fleet管理、GitOps工作流、边缘计算、调度优化等多个维度,深入剖析了Kurator的核心技术和实践方法。
在数字化转型的浪潮中,分布式云原生架构将成为企业创新的基础设施。Kurator以其开放性、统一性和场景化优势,正在成为这一领域的领导者。随着社区的不断壮大和技术的持续演进,Kurator将为企业提供更强大、更灵活的云原生能力,助力业务创新和价值创造。
对于云原生技术从业者,掌握Kurator不仅意味着掌握了一项新技术,更意味着把握了分布式云原生的发展趋势。我们期待更多开发者和企业加入Kurator社区,共同推动云原生技术的发展,构建更美好的数字未来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)