【前瞻创想】Kurator云原生实战指南:从入门到精通的完整学习路径
【前瞻创想】Kurator云原生实战指南:从入门到精通的完整学习路径
【前瞻创想】Kurator云原生实战指南:从入门到精通的完整学习路径
摘要
在云原生技术快速发展的今天,企业面临着多集群管理、边缘计算、服务网格等复杂挑战。Kurator作为一款开源的云原生套件,通过深度集成Prometheus、Istio、Karmada、KubeEdge、Volcano等优秀开源项目,为企业提供了一站式的分布式云原生解决方案。本文将深入探讨Kurator的核心架构、实践应用以及未来发展方向,通过丰富的实战案例和专业思考,帮助读者全面掌握Kurator的技术精髓,为企业云原生转型提供切实可行的技术路径。
1. Kurator云原生平台概述
1.1 什么是Kurator:定义与定位
Kurator的核心价值与定位如图所示: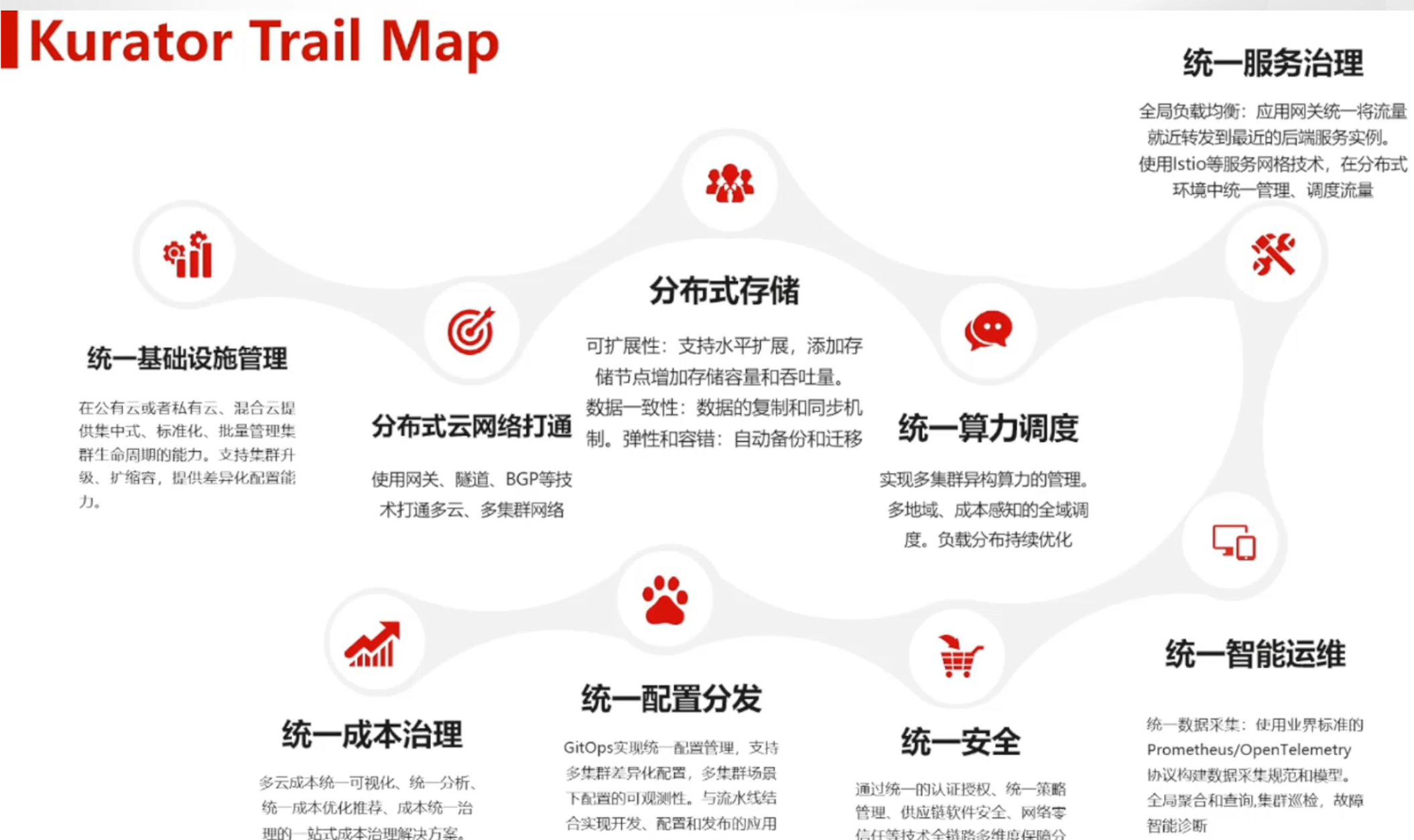
Kurator是一个开源的云原生套件,旨在简化多集群、混合云和边缘计算环境下的应用部署和管理。它不是简单的工具集合,而是一个深度整合的平台,通过统一的API和管理界面,将多个优秀的云原生项目无缝集成在一起。Kurator的核心定位是"分布式云原生操作系统的构建者",它帮助企业构建跨云、跨地域、跨基础设施的应用交付和运维体系。
Kurator的独特之处在于它不仅仅是一个管理工具,更是一个技术创新的平台。它通过抽象底层基础设施的复杂性,为开发者提供统一的开发体验,同时为运维团队提供强大的可观测性和管理能力。在当今企业面临数字化转型的关键时期,Kurator提供了一条从传统架构向云原生架构平滑过渡的技术路径。
1.2 Kurator技术生态全景图
Kurator架构图: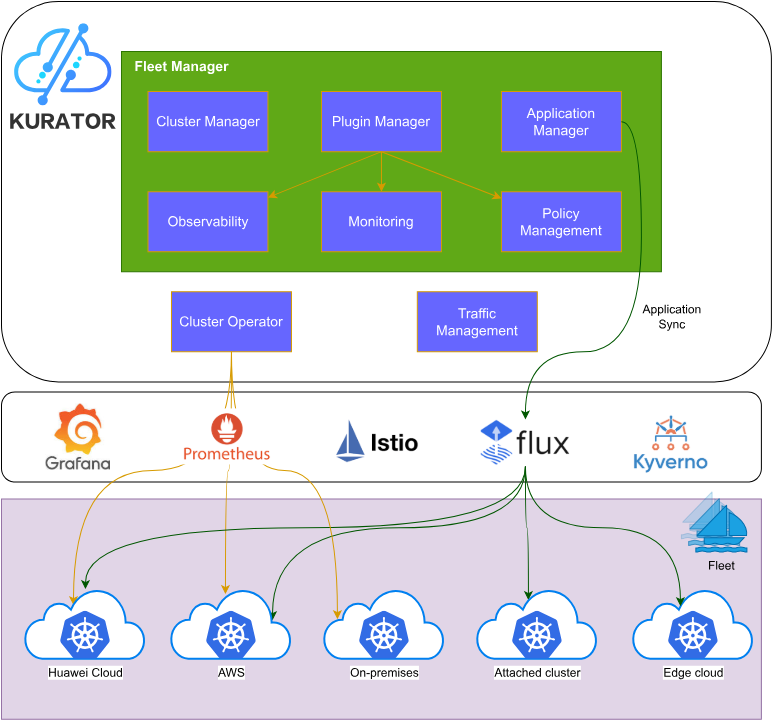
Kurator的技术生态是一个精心设计的分层架构。在基础设施层,它支持Kubernetes、虚拟机、物理机等多种部署环境;在平台层,深度集成了Karmada(多集群管理)、KubeEdge(边缘计算)、Volcano(批处理调度)、Istio(服务网格)等核心组件;在应用层,提供了GitOps、CI/CD、监控告警等完整的DevOps能力。
这种分层设计使得Kurator具有极强的扩展性和灵活性。企业可以根据自身需求,选择性地启用特定功能模块,逐步构建完整的云原生平台。例如,对于刚开始云原生转型的企业,可以从基础的多集群管理开始;而对于已经具备一定云原生经验的企业,可以直接利用Kurator的高级功能,如服务网格、边缘计算等。
1.3 为什么选择Kurator:核心优势分析
与市场上其他云原生解决方案相比,Kurator具有几个显著的优势。首先,它是完全开源的,这意味着企业可以自由定制和扩展,避免了厂商锁定的风险。其次,Kurator采用模块化设计,各个组件之间松耦合,可以根据业务需求灵活组合。第三,Kurator拥有活跃的社区支持和持续的技术创新,确保了技术的先进性和可持续性。
更重要的是,Kurator解决了企业云原生实践中的关键痛点:复杂性管理。在传统的云原生架构中,企业需要分别管理多个独立的工具链,这不仅增加了学习成本,还带来了集成和维护的复杂性。Kurator通过统一的抽象层和标准化的接口,大大简化了这种复杂性,让企业能够专注于业务创新,而不是基础设施管理。
2. 环境搭建与基础配置
2.1 基础环境准备与依赖安装
在开始Kurator的安装之前,需要确保基础环境满足要求。首先,需要准备至少一台Linux服务器(推荐Ubuntu 20.04或CentOS 7+),配置至少4核CPU、8GB内存和50GB磁盘空间。其次,需要安装基础依赖组件,包括Docker、kubectl、helm等。
# 安装Docker
sudo apt-get update
sudo apt-get install -y docker.io
sudo systemctl enable docker
sudo systemctl start docker
# 安装kubectl
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
# 安装helm
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
2.2 Kurator源码获取与编译部署
接下来,使用指定的命令获取Kurator源码。这个步骤是整个安装过程的关键,需要确保网络连接正常,能够访问GitHub资源。
# 获取Kurator源码
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
unzip main.zip
cd kurator-main
# 安装依赖
make deps
# 编译Kurator
make build
# 验证安装
./bin/kurator --version
kurator源码已经下载下来了
接下来解压就可以
在编译过程中,可能会遇到各种依赖问题。建议使用容器化的方式来构建,这样可以避免环境差异带来的问题。Kurator项目提供了Dockerfile,可以使用以下命令构建:
用docker确实可以避免很多问题,比如环境错误的问题,你们可以试试,我是本地安装的
docker build -t kurator-builder .
docker run -v $(pwd):/workspace kurator-builder make build
2.3 集群初始化与验证测试
完成编译后,需要初始化Kurator集群。Kurator支持多种部署模式,包括单集群模式和多集群模式。对于初次接触的用户,建议从单集群模式开始。
# 初始化单集群
./bin/kurator init --mode single
# 查看集群状态
kubectl get pods -n kurator-system
# 验证核心功能
./bin/kurator check
在初始化过程中,Kurator会自动部署核心组件,包括Karmada、KubeEdge、Volcano等。可以通过查看日志来监控部署进度:
kubectl logs -f deployment/kurator-controller-manager -n kurator-system
验证测试是确保安装成功的关键步骤。Kurator提供了内置的测试套件,可以验证各个组件的功能是否正常:
# 运行基础测试
./bin/kurator test basic
# 运行高级功能测试
./bin/kurator test advanced
3. Kurator核心架构解析
3.1 Fleet管理机制深入剖析
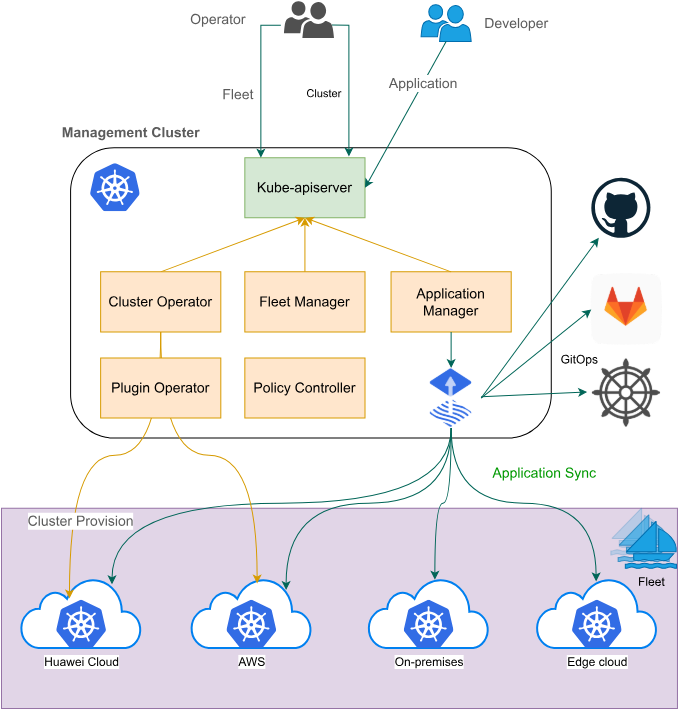
Fleet是Kurator的核心概念之一,它代表了一组具有相同特性的集群集合。Fleet管理机制是Kurator实现多集群管理的关键。在Kurator中,Fleet不仅仅是集群的简单分组,它还包含了丰富的策略定义,如调度策略、安全策略、网络策略等。
Fleet的设计哲学是"策略即代码"。通过声明式的API,用户可以定义Fleet级别的策略,这些策略会自动应用到Fleet中的所有集群。例如,可以定义一个策略,要求所有集群都必须启用特定的安全配置;或者定义一个调度策略,根据地理位置或资源负载来分配应用。
Fleet管理的核心优势在于它提供了统一的管理视角。运维人员不再需要逐个集群地配置和管理,而是可以在Fleet级别进行批量操作。这大大提高了管理效率,减少了人为错误的可能性。同时,Fleet机制还支持动态扩展,当新的集群加入时,可以自动继承Fleet的策略配置。
3.2 多集群资源分发流程
Kurator分发流程如图所示: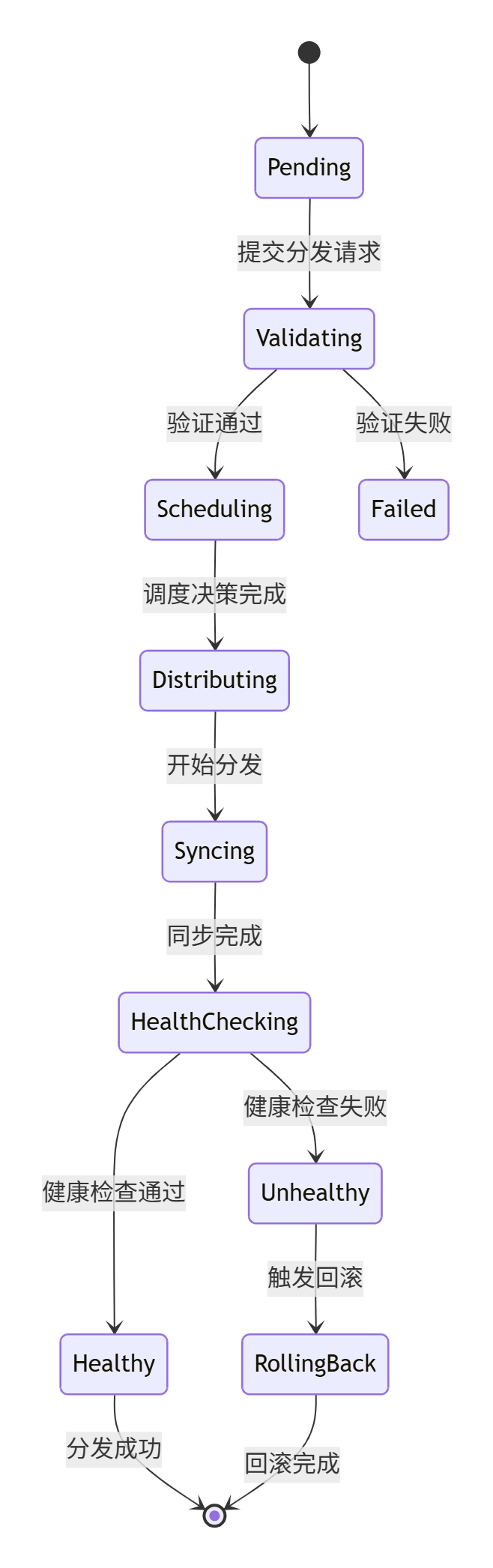
Kurator的多集群资源分发流程是一个高度优化的过程。当用户在中心集群创建一个资源时,Kurator会根据预定义的策略,自动将该资源分发到目标集群。这个过程涉及多个关键步骤:策略匹配、资源转换、分发执行和状态同步。
策略匹配是分发流程的第一步。Kurator会根据资源的标签、注解以及Fleet的策略定义,确定哪些集群应该接收该资源。这个过程支持复杂的条件表达式,可以基于集群的属性(如区域、环境、资源容量等)进行精细的控制。
资源转换是确保资源在不同集群中正确运行的关键步骤。由于不同集群可能存在配置差异,Kurator会自动对资源进行必要的转换。例如,对于Service资源,可能需要根据目标集群的网络配置调整ClusterIP;对于Deployment资源,可能需要根据目标集群的资源配额调整副本数。
分发执行采用异步机制,确保即使部分集群暂时不可用,也不会影响整体分发流程。Kurator会记录分发状态,并在集群恢复后自动重试。状态同步机制则确保中心集群能够实时了解各个目标集群的资源状态,为运维决策提供准确的数据支持。
3.3 身份与命名空间一致性设计
Fleet 舰队中的命名空间相同性如图所示: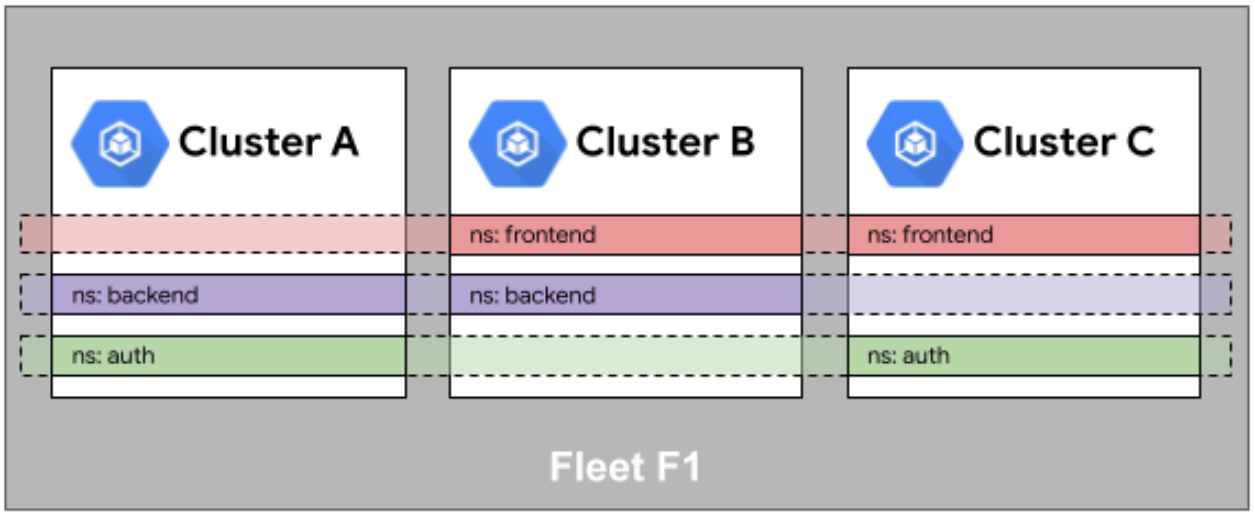
Fleet 队列中的身份相同性如图所示: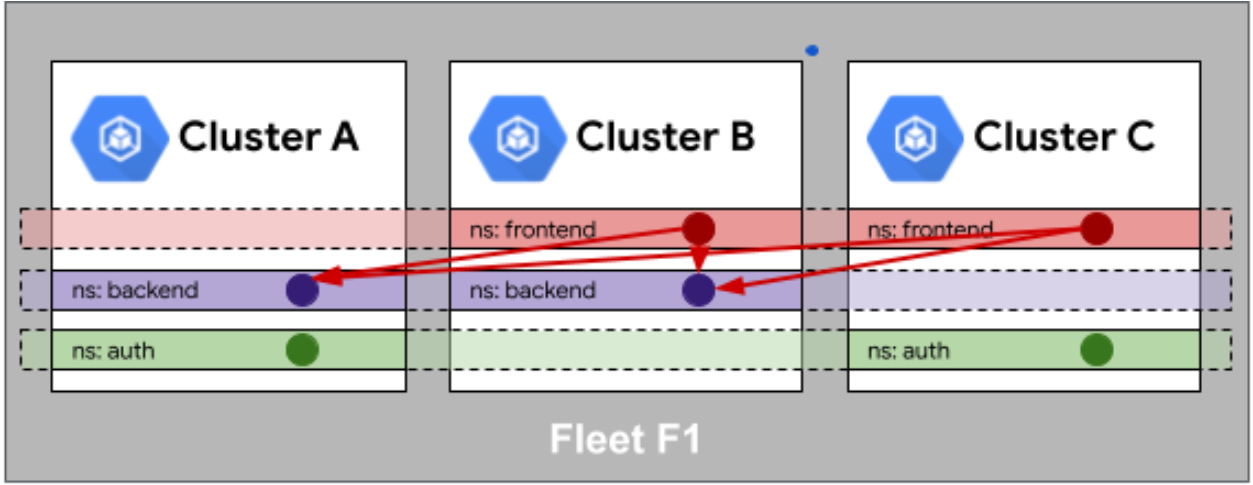
在多集群环境中,身份和命名空间的一致性管理是一个复杂的挑战。Kurator通过创新的设计,解决了这个问题。在身份管理方面,Kurator实现了统一的身份认证和授权体系,支持多种身份提供者(如LDAP、OIDC、Kubernetes ServiceAccount等),并确保身份信息在所有集群中保持一致。
命名空间一致性是另一个关键问题。在传统的多集群管理中,不同集群的命名空间往往是独立的,这导致了配置复杂性和管理困难。Kurator引入了"全局命名空间"的概念,通过统一的命名空间管理API,确保相同名称的命名空间在所有集群中具有相同的配置和策略。
这种一致性设计不仅简化了管理,还提高了安全性和合规性。例如,当需要更新某个命名空间的资源配额时,只需在中心集群操作一次,所有目标集群会自动同步更新。同样,当需要撤销某个用户的访问权限时,可以立即在所有集群中生效,避免了安全漏洞。
4. 多集群管理与Karmada集成
4.1 Karmada核心概念与架构
Karmada的核心 如图所示: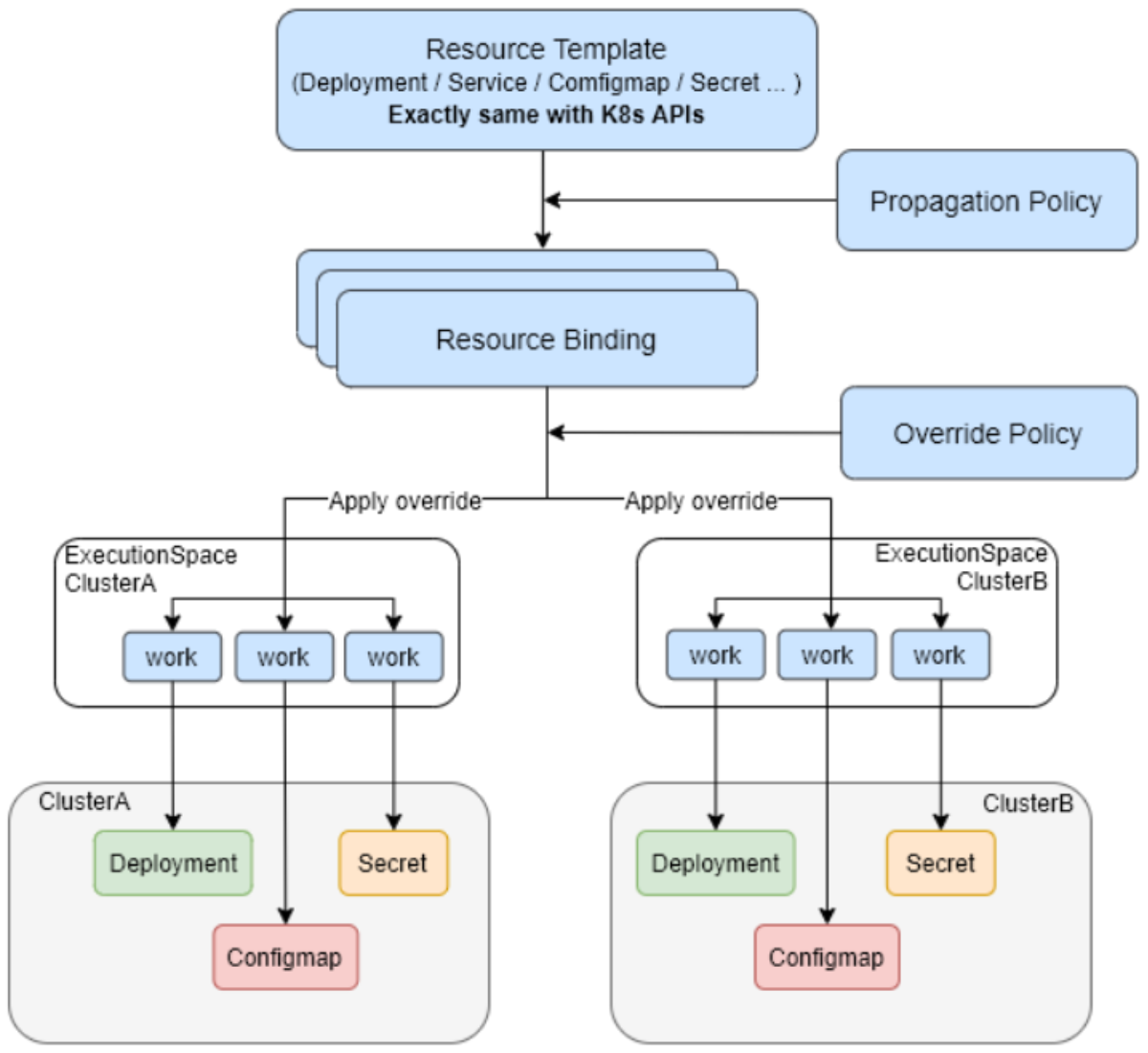
Karmada是Kurator集成的多集群管理核心组件,它基于Kubernetes Federation v1/v2的经验,提供了更强大和灵活的多集群管理能力。Karmada的核心概念包括PropagationPolicy、Cluster、ResourceBinding等。
PropagationPolicy是Karmada的灵魂,它定义了资源如何在不同集群间分发。通过PropagationPolicy,可以精确控制资源的分发策略,包括目标集群的选择、副本数的分配、故障转移策略等。Cluster对象代表了被管理的Kubernetes集群,Karmada通过Cluster API与这些集群进行通信。ResourceBinding则负责将PropagationPolicy应用到具体的资源上,实现策略的执行。
Karmada的架构设计非常精巧。它采用控制平面与数据平面分离的设计,控制平面运行在中心集群,负责策略管理和调度决策;数据平面分布在各个成员集群,负责策略的执行和状态上报。这种设计确保了高可用性和可扩展性,即使中心集群出现故障,成员集群仍能继续运行。
4.2 跨集群应用分发实战
让我们通过一个实际的例子来演示跨集群应用分发。假设我们有一个Web应用,需要部署到三个不同的集群:生产集群、测试集群和开发集群。我们希望在生产集群部署5个副本,在测试集群部署2个副本,在开发集群部署1个副本。
首先,定义PropagationPolicy:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: web-app-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: web-app
placement:
clusterAffinity:
clusterNames:
- production-cluster
- staging-cluster
- dev-cluster
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weights:
production-cluster: 5
staging-cluster: 2
dev-cluster: 1
然后,创建Deployment资源:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app
spec:
replicas: 8
selector:
matchLabels:
app: web-app
template:
metadata:
labels:
app: web-app
spec:
containers:
- name: web-app
image: nginx:latest
ports:
- containerPort: 80
应用这两个资源后,Karmada会自动将Deployment分发到三个集群,并根据权重分配副本数。可以通过以下命令查看分发状态:
kubectl get resourcebinding web-app-deployment -o yaml
4.3 弹性伸缩与故障转移策略
弹性伸缩如图所示: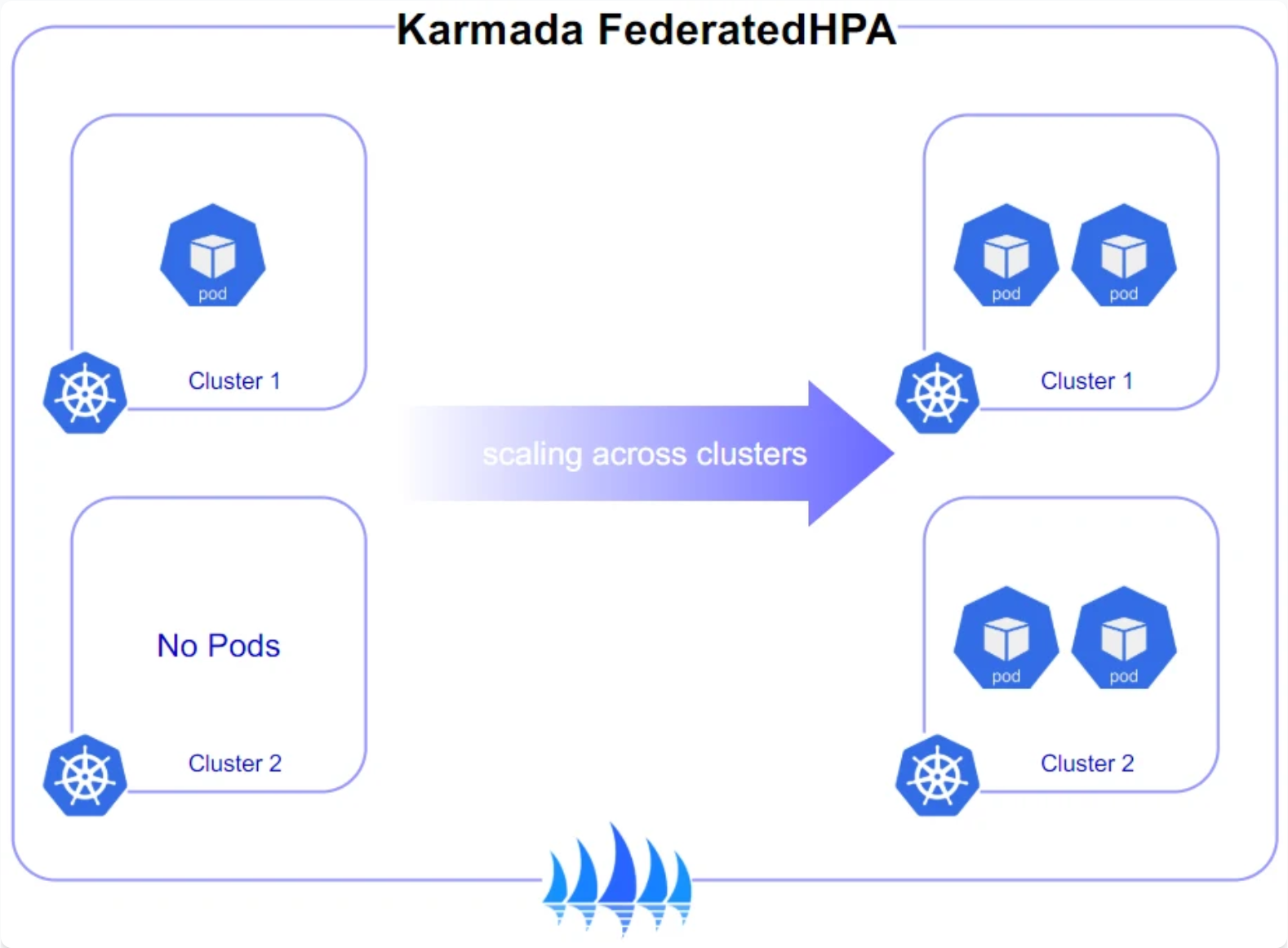
在多集群环境中,弹性伸缩和故障转移是确保应用高可用的关键。Kurator结合Karmada提供了强大的弹性伸缩能力。通过ClusterResourceBinding,可以定义跨集群的弹性伸缩策略。
例如,可以定义一个策略,当某个集群的CPU使用率超过80%时,自动将部分流量转移到其他集群:
apiVersion: autoscaling.karmada.io/v1alpha1
kind: ClusterResourceBinding
metadata:
name: web-app-binding
spec:
clusters:
- name: production-cluster
replicas: 5
- name: backup-cluster
replicas: 2
policy:
autoFailover: true
failoverThreshold: 80%
scaleStrategy:
type: Dynamic
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
故障转移策略则更加智能。当检测到某个集群出现故障时,Karmada会自动将流量转移到健康的集群。这个过程是透明的,对用户无感知。更重要的是,Karmada支持渐进式故障转移,避免一次性转移大量流量导致目标集群过载。
# 监控故障转移状态
kubectl get failoverrecord -w
这种智能的弹性伸缩和故障转移机制,大大提高了应用的可用性和可靠性,是企业级云原生架构的重要组成部分。
5. 边缘计算与KubeEdge实践
5.1 KubeEdge架构与核心组件
KubeEdge架构如图所示: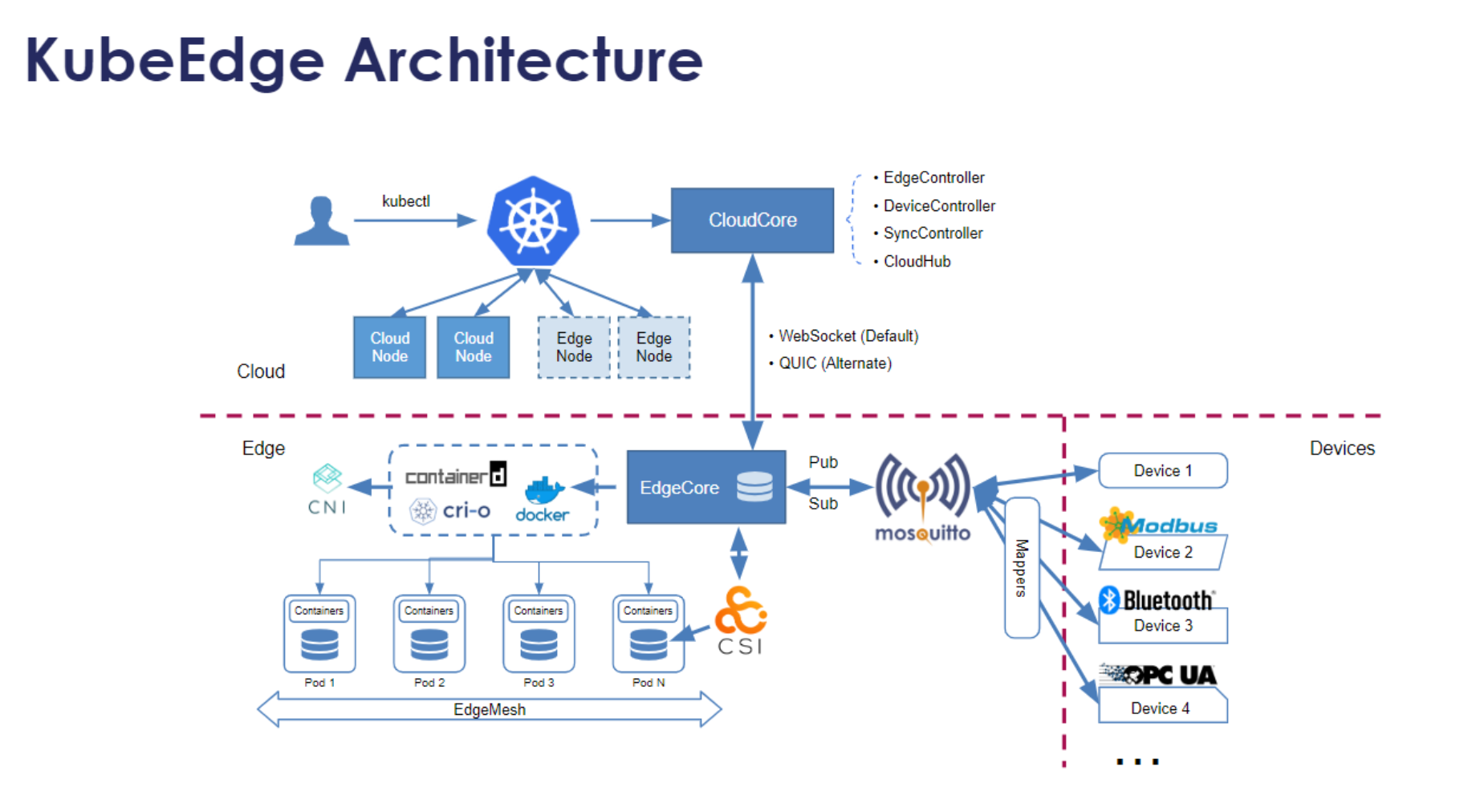
KubeEdge是Kurator集成的边缘计算核心组件,它将Kubernetes的能力扩展到边缘设备。KubeEdge的架构分为云上部分和边缘部分。云上部分包括CloudCore,负责与Kubernetes API Server通信;边缘部分包括EdgeCore,运行在边缘设备上,负责管理边缘应用。
KubeEdge的核心组件如图所示: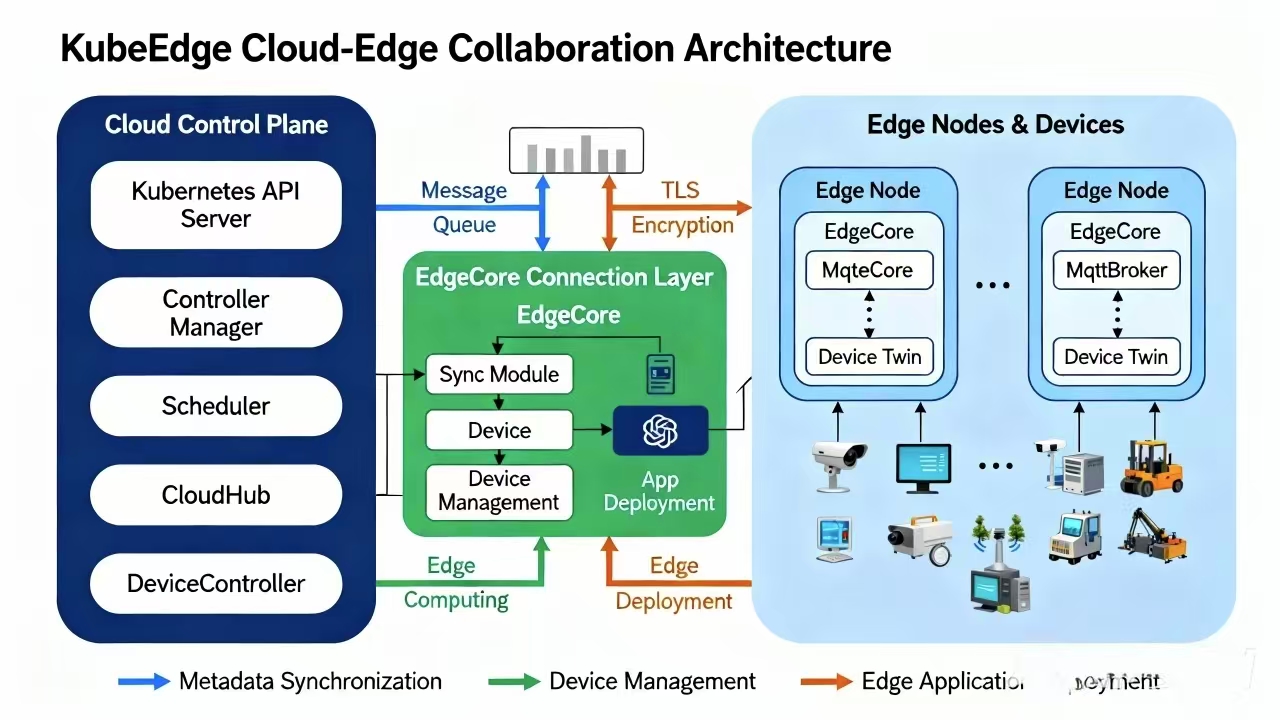
KubeEdge的核心组件包括:EdgeHub(负责云边通信)、EdgeMesh(提供边缘服务发现)、DeviceTwin(管理设备状态)、MetaManager(缓存元数据)等。这些组件协同工作,确保边缘设备能够像普通Kubernetes节点一样被管理,同时支持离线运行和弱网络环境。
KubeEdge的创新之处在于它解决了边缘计算的特殊挑战:网络不稳定、资源受限、安全要求高。通过消息总线和MQTT协议,KubeEdge实现了可靠的云边通信;通过本地缓存和状态同步,确保了离线场景下的服务连续性;通过双向证书认证和数据加密,保障了边缘设备的安全性。
5.2 云边协同部署方案
在Kurator中,云边协同部署是一个标准化的流程。首先,需要在中心集群部署CloudCore,然后在边缘设备上部署EdgeCore。Kurator提供了简化的部署命令:
# 部署CloudCore
./bin/kurator deploy cloudcore --namespace kubeedge
# 生成EdgeCore配置
./bin/kurator generate edgecore-config --edge-node=edge-node-1
# 在边缘设备上部署EdgeCore
# 将生成的配置文件复制到边缘设备
scp edgecore.yaml edge-user@edge-node-1:/etc/kubeedge/
# 在边缘设备上启动EdgeCore
sudo edgecore --config /etc/kubeedge/edgecore.yaml
部署完成后,边缘节点会自动注册到中心集群。可以通过以下命令查看边缘节点状态:
kubectl get nodes -l node-role.kubernetes.io/edge=
5.3 边缘节点管理与监控
边缘节点的管理和监控是边缘计算的关键挑战。Kurator集成了Prometheus和Grafana,提供了完整的边缘监控解决方案。通过EdgeExporter,可以收集边缘节点的资源使用情况、网络状态、设备状态等指标。
# 边缘监控配置示例
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: edge-node-monitor
spec:
selector:
matchLabels:
app: edge-exporter
endpoints:
- port: metrics
interval: 30s
path: /metrics
Kurator还提供了边缘应用的生命周期管理能力。通过定义EdgeApplication,可以控制应用在边缘节点的部署策略,如基于地理位置的部署、基于设备类型的部署等:
apiVersion: apps.kurator.dev/v1alpha1
kind: EdgeApplication
metadata:
name: sensor-app
spec:
selector:
matchLabels:
edge-type: industrial
template:
spec:
containers:
- name: sensor-collector
image: sensor-collector:v1
resources:
limits:
memory: 512Mi
cpu: "0.5"
这种精细化的边缘管理能力,使得企业能够充分发挥边缘计算的优势,实现数据就近处理、降低延迟、节省带宽等业务价值。
6. 高级调度与Volcano应用
6.1 Volcano调度架构解析
Volcano调度架构如图所示: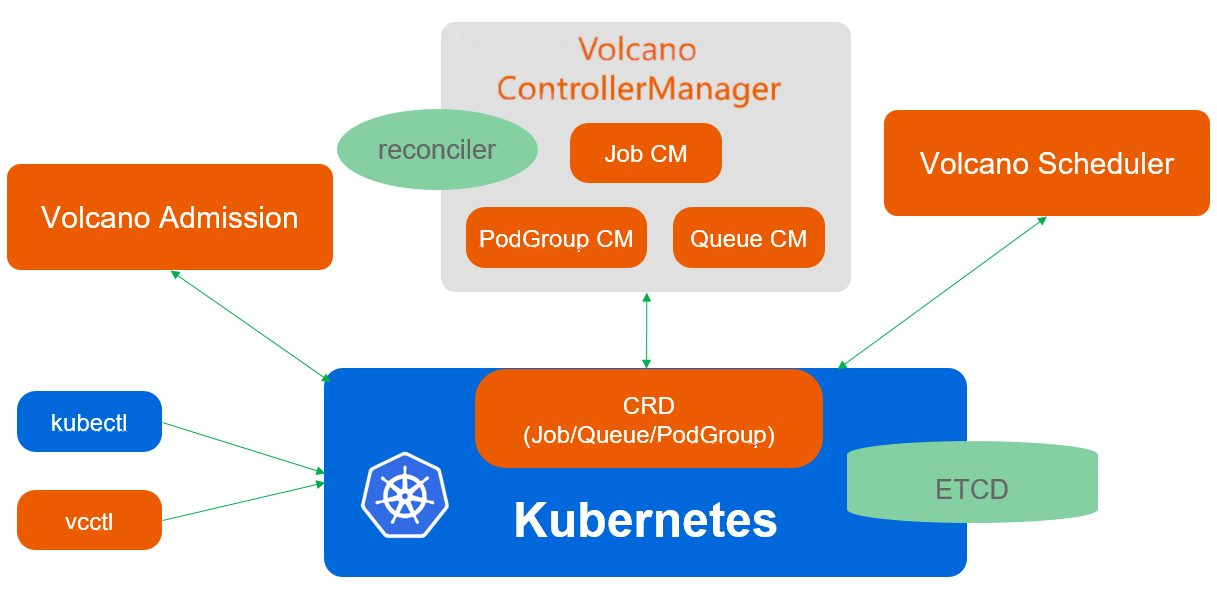
Volcano是Kurator集成的批处理调度器,专为AI/ML、大数据、HPC等计算密集型工作负载设计。Volcano的架构基于Kubernetes调度框架,但进行了深度优化,支持更复杂的调度策略。
Volcano的核心组件包括Scheduler、Controller和Admission。Scheduler负责核心调度逻辑,支持多种调度算法如Binpack、Spread、DRF等;Controller负责作业生命周期管理;Admission则负责作业准入控制。Volcano还引入了Queue的概念,用于资源配额管理和多租户隔离。
Volcano的创新之处在于它解决了传统Kubernetes调度器在批处理场景下的不足。例如,支持任务依赖关系、支持抢占式调度、支持公平共享等。这些特性使得Volcano成为处理复杂计算工作负载的理想选择。
6.2 批量作业调度优化实践
让我们通过一个AI训练作业的例子来演示Volcano的调度能力。假设我们有一个分布式训练作业,需要8个GPU节点,且要求所有任务同时启动(gang scheduling)。
首先,定义Queue和PodGroup:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: ai-training-queue
spec:
weight: 1
capability:
cpu: "40"
memory: 200Gi
nvidia.com/gpu: "8"
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: training-job-pg
spec:
minMember: 8
minTaskMember:
worker: 8
然后,定义Job:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: distributed-training
spec:
minAvailable: 8
schedulerName: volcano
queue: ai-training-queue
tasks:
- replicas: 8
name: worker
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: 1
cpu: "4"
memory: 16Gi
nodeSelector:
node-type: gpu-node
这个配置确保了8个worker任务会同时调度到8个GPU节点上,实现真正的分布式训练。如果资源不足,整个作业会等待,而不是部分启动,这避免了资源浪费和训练效率低下。
6.3 Queue与PodGroup资源管理
Queue和PodGroup是Volcano的核心概念,它们提供了细粒度的资源管理能力。Queue用于定义资源配额和调度策略,PodGroup则用于定义任务组和依赖关系。
在多租户环境中,可以通过Queue实现资源隔离和公平共享:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: research-team
spec:
weight: 3
reclaimable: true
capability:
cpu: "100"
memory: 500Gi
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: production-team
spec:
weight: 2
reclaimable: false
capability:
cpu: "50"
memory: 200Gi
PodGroup则支持复杂的任务依赖关系:
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: data-processing-pipeline
spec:
minMember: 3
scheduleTimeoutSeconds: 300
dependencies:
- name: data-preparation
minAvailable: 1
- name: model-training
minAvailable: 1
dependsOn:
- data-preparation
- name: result-analysis
minAvailable: 1
dependsOn:
- model-training
这种精细化的资源管理能力,使得Volcano能够满足各种复杂计算场景的需求,是企业级批处理工作负载的理想选择。
7. 持续交付与GitOps实现
7.1 GitOps理念与Kurator实现
GitOps是一种以Git为中心的持续交付方法,它将Git作为唯一的事实来源,通过声明式配置和自动化流程,实现应用的持续部署。Kurator深度集成了FluxCD,提供了完整的GitOps解决方案。
在Kurator中,GitOps的核心组件包括Source Controller(管理Git仓库)、Kustomize Controller(处理Kustomize配置)、Helm Controller(管理Helm Charts)等。这些组件协同工作,确保应用配置与Git仓库中的声明保持一致。
Kurator的GitOps实现具有几个显著特点:首先,它支持多环境管理,可以通过不同的分支或目录结构来管理开发、测试、生产环境;其次,它提供了自动化的安全扫描和策略验证,确保只有符合安全标准的配置才能部署;第三,它支持渐进式交付,如金丝雀发布、蓝绿部署等。
7.2 FluxCD集成与Helm应用管理
Kurator通过FluxCD实现了Helm应用的自动化管理。以下是一个典型的HelmRelease配置示例:
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: nginx-app
namespace: default
spec:
chart:
spec:
chart: nginx
version: "4.0.0"
sourceRef:
kind: HelmRepository
name: bitnami
namespace: flux-system
interval: 5m
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
values:
replicaCount: 3
service:
type: NodePort
port: 80
这个配置定义了一个Nginx应用,使用Bitnami仓库中的Helm Chart。FluxCD会定期检查Chart版本的变化,并自动升级应用。如果升级失败,会自动回滚到之前的版本。
Kurator还提供了Helm仓库管理的能力:
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
metadata:
name: bitnami
namespace: flux-system
spec:
interval: 10m
url: https://charts.bitnami.com/bitnami
7.3 CI/CD流水线设计与优化
Kurator的CI/CD流水线基于Tekton,提供了完整的构建、测试、部署能力。一个典型的流水线包括以下几个阶段:代码拉取、构建、测试、安全扫描、部署。
以下是一个简单的Tekton Pipeline配置:
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: app-ci-pipeline
spec:
tasks:
- name: git-clone
taskRef:
name: git-clone
workspaces:
- name: source
workspace: source-workspace
- name: build-image
taskRef:
name: kaniko
runAfter: [git-clone]
workspaces:
- name: source
workspace: source-workspace
- name: run-tests
taskRef:
name: pytest
runAfter: [build-image]
workspaces:
- name: source
workspace: source-workspace
- name: deploy-to-staging
taskRef:
name: flux-deploy
runAfter: [run-tests]
params:
- name: environment
value: staging
Kurator对CI/CD流水线进行了深度优化。首先,它支持并行执行,多个任务可以同时运行,大大缩短了流水线执行时间;其次,它提供了智能缓存机制,避免重复的构建和下载;第三,它集成了质量门禁,只有通过所有测试和安全扫描的代码才能进入生产环境。
# 触发流水线
tkn pipeline start app-ci-pipeline \
-w name=source-workspace,volumeClaimTemplateFile=workspace-template.yaml \
--showlog
这种优化的CI/CD流水线,使得企业能够实现快速、安全、可靠的软件交付,是DevOps实践的核心支撑。
总结
展望未来,分布式云原生技术将向几个方向发展:首先是边缘智能,边缘设备将具备更强的计算能力,能够运行复杂的AI模型;其次是跨云管理,企业将需要统一管理公有云、私有云和边缘云资源;第三是安全增强,随着攻击面的扩大,安全将成为云原生架构的首要考虑因素。
Kurator作为分布式云原生操作系统的核心,将持续创新,引领这些技术趋势。通过深度集成更多优秀的开源项目,构建更完善的生态系统,Kurator将成为企业云原生转型的首选平台。最终,Kurator的目标是让云原生技术真正普及,让每个企业都能享受到云原生带来的敏捷性、可靠性和创新力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)