【前瞻创想】Kurator分布式云原生平台:多云协同与边缘计算的企业级实战指南与架构深度解析
【前瞻创想】Kurator分布式云原生平台:多云协同与边缘计算的企业级实战指南与架构深度解析
【前瞻创想】Kurator分布式云原生平台:多云协同与边缘计算的企业级实战指南与架构深度解析
摘要
本文深入探讨Kurator这一开源分布式云原生平台的核心架构、技术原理与企业级实践。作为站在Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno等优秀开源项目肩膀上的集大成者,Kurator为企业提供了一站式的多云、边缘计算与分布式架构解决方案。文章从平台概述入手,详细解析其多集群管理、统一调度、GitOps实现等核心能力,并通过环境搭建、Fleet集群管理、Karmada集成、KubeEdge边缘协同等实战案例,展示Kurator在企业数字化转型中的关键作用。最后,结合云原生技术发展趋势,探讨Kurator的未来演进方向与企业落地建议,为企业架构师和技术决策者提供全面的技术参考与实践指南。
一、Kurator平台概述与核心价值
Kurator的核心价值参考图: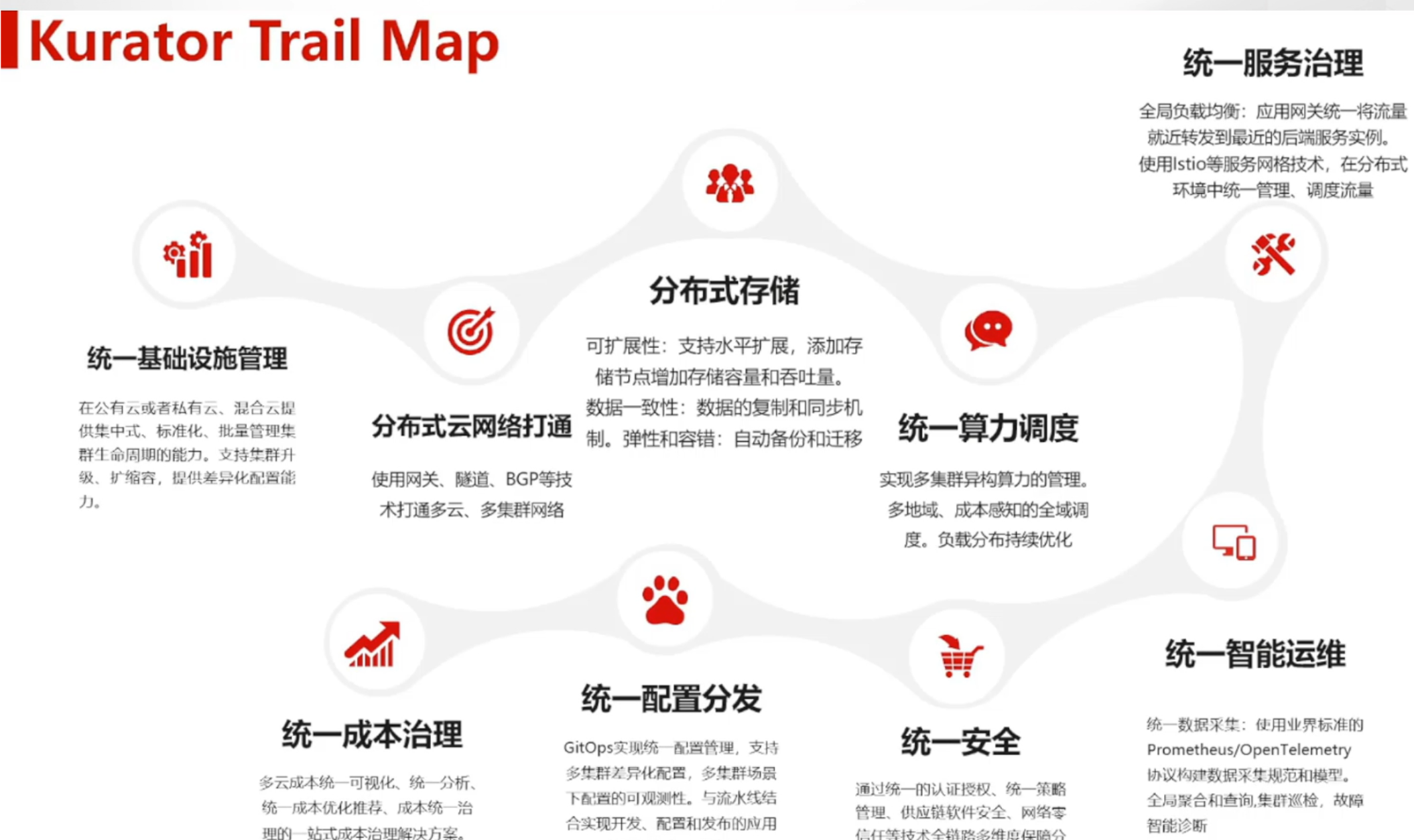
1.1 分布式云原生的演进与挑战
随着企业数字化转型的深入,传统的单集群Kubernetes架构已无法满足现代应用的需求。多云部署、边缘计算、混合云架构等新兴场景带来了资源分散、管理复杂、运维困难等挑战。Kurator应运而生,作为一个开源分布式云原生平台,它致力于帮助用户构建自己的分布式云原生基础设施,实现真正的多云协同与边缘智能。
分布式云原生的核心挑战在于如何在异构环境中实现资源的统一管理、应用的一致部署、流量的智能调度以及监控的全局视角。Kurator通过整合多个优秀开源项目,构建了一个完整的解决方案体系,使得企业能够以较低的学习成本和实施风险,快速拥抱分布式云原生架构。
1.2 Kurator的技术定位与架构优势
Kurator并非简单的技术堆砌,而是通过深度整合与创新设计,实现了1+1>2的效果。它站在众多流行云原生软件栈的肩膀上,包括Kubernetes作为基础容器编排引擎,Istio提供服务网格能力,Prometheus负责监控告警,FluxCD实现GitOps持续交付,KubeEdge支持边缘计算场景,Volcano优化批处理调度,Karmada实现多集群管理,Kyverno提供策略引擎等。
这种技术整合的优势在于:
- 统一抽象层:为上层应用提供一致的API和操作体验,屏蔽底层基础设施差异
- 能力互补:各组件专注于自己的领域,通过标准化接口协同工作
- 渐进式演进:企业可以根据实际需求,逐步引入和启用相关能力
- 开源生态:充分利用开源社区的创新成果,避免重复造轮子
1.3 核心能力全景图
Kurator提供了一系列强大的多云和多集群管理能力,构成了其核心价值主张:
- 多云、边缘-云、边缘-边缘协同:打破云边界限,实现资源与应用的全局调度
- 统一资源编排:通过声明式API统一管理跨集群资源
- 统一调度策略:支持多种调度策略,包括亲和性、反亲和性、拓扑感知等
- 统一流量管理:基于Istio的服务网格能力,实现跨集群服务发现与通信
- 统一遥测体系:聚合各集群指标,提供全局监控视图
- 基础设施即代码:通过GitOps方式管理集群、节点、VPC等基础设施
- 开箱即用:一键安装完整的云原生软件栈,降低入门门槛
这些能力共同构成了Kurator的独特价值,使其成为企业数字化转型的重要技术支撑。
二、Kurator技术架构深度剖析
kurator架构参考图: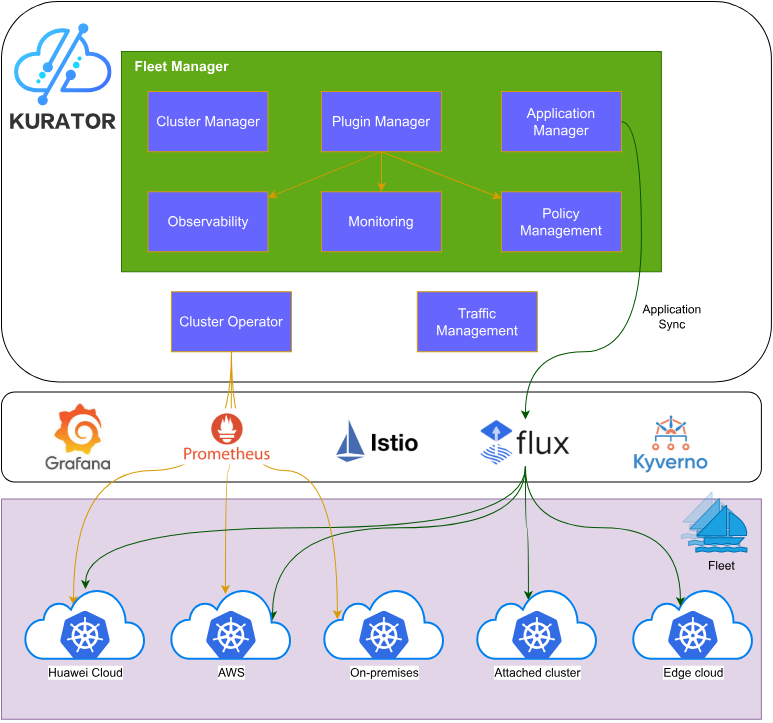
2.1 Control Plane架构设计
Kurator的Control Plane是整个平台的大脑,负责协调各组件的工作。其核心架构采用分层设计:
// Control Plane核心组件伪代码
type ControlPlane struct {
ClusterManager *ClusterManager // 集群生命周期管理
FleetController *FleetController // Fleet队列管理
PolicyEngine *PolicyEngine // 策略引擎
Scheduler *Scheduler // 统一调度器
GitOpsEngine *GitOpsEngine // GitOps引擎
}
Control Plane通过CRD(Custom Resource Definition)扩展Kubernetes API,定义了如Fleet、Cluster、Policy等自定义资源。这些资源通过控制器模式(Controller Pattern)实现声明式配置的自动同步,确保系统状态与期望状态一致。
Control Plane的关键设计原则是解耦与可扩展。各组件之间通过标准接口通信,新功能可以作为插件方式集成,而不影响核心架构的稳定性。这种设计为未来的功能扩展预留了充足空间。
2.2 数据平面与通信机制
Kurator的数据平面负责实际工作负载的执行与数据传输。在多集群、多云环境中,数据平面的设计尤为关键。Kurator采用了多层次的通信机制:
- 服务通信层:基于Istio的服务网格,实现跨集群服务发现与调用
- 数据同步层:通过FluxCD实现Git仓库与集群状态的同步
- 控制指令层:API Server之间的安全通信,用于集群管理指令传递
- 指标采集层:Prometheus联邦机制,聚合各集群监控数据
通信安全是数据平面设计的重点。Kurator通过mTLS(双向TLS)、证书轮换、RBAC等机制,确保跨集群通信的安全性。同时,针对边缘场景的网络不稳定特性,设计了重试、断点续传、本地缓存等容错机制。
2.3 统一策略引擎与治理框架
在分布式环境中,保持策略一致性是巨大挑战。Kurator集成了Kyverno作为策略引擎,提供了强大的策略管理能力:
# 示例:跨集群Pod安全策略
apiVersion: kyverno.io/v1
kind: ClusterPolicy
meta
name: require-pod-security
spec:
validationFailureAction: enforce
rules:
- name: check-pod-security
match:
any:
- resources:
kinds:
- Pod
validate:
message: "Pod必须包含安全上下文配置"
pattern:
spec:
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
策略引擎支持多种策略类型:
- 安全策略:容器安全上下文、网络策略、镜像签名验证
- 资源策略:资源配额、请求限制、命名规范
- 合规策略:符合企业标准、行业法规的配置检查
- 运维策略:备份策略、日志收集策略、升级策略
通过统一策略引擎,Kurator确保了在异构环境中策略的一致性执行,大大降低了管理复杂度。
三、环境搭建与基础配置实战
3.1 环境准备与依赖安装
在开始Kurator安装前,需要准备合适的环境。推荐使用Linux服务器或虚拟机,配置至少4核8G内存,确保网络畅通。首先安装基础依赖:
# 安装基础工具
sudo apt-get update
sudo apt-get install -y curl wget git docker.io kubectl
# 配置Docker
sudo systemctl enable docker
sudo systemctl start docker
# 配置kubectl
mkdir -p ~/.kube
sudo cp -i /etc/kubernetes/admin.conf ~/.kube/config
sudo chown $(id -u):$(id -g) ~/.kube/config
环境准备完成后,开始获取Kurator源码。根据要求,使用以下命令:
git clone https://github.com/kurator-dev/kurator.git
cd kurator
或
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
unzip main.zip
cd kurator-main
在项目地址中,可以看到可以clone到本地
https://gitcode.com/kurator-dev/kurator.git
或者我们也可以下载到本地
可以看到我们资源文件已经下载下来了
可以看到版本是0.6.0
3.2 Kurator安装流程详解
Kurator提供了一键安装脚本,大大简化了部署流程。安装过程分为几个关键步骤:
# 查看安装脚本
cat scripts/install.sh
# 执行安装
./scripts/install.sh --all
安装脚本会自动检测环境,下载所需镜像,并部署各组件。关键步骤包括:
- 环境检查:验证Docker、Kubernetes、网络连通性
- 镜像准备:拉取Kurator核心组件镜像
- CRD部署:注册自定义资源定义
- 控制器部署:部署Fleet控制器、策略控制器等
- 集成组件:安装集成的开源组件(可选)
- 配置验证:执行基本功能测试
安装过程中可能会遇到网络问题,特别是在国内环境。可以通过配置镜像仓库加速:
# 配置Docker镜像加速
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
EOF
sudo systemctl restart docker
3.3 配置验证与基础使用
安装完成后,需要验证Kurator是否正常工作:
# 检查Kurator组件状态
kubectl get pods -n kurator-system
# 验证CRD注册
kubectl get crd | grep kurator
# 创建测试Fleet
cat <<EOF | kubectl apply -f -
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: test-fleet
spec:
clusters:
- name: member1
kubeconfigSecret: member1-kubeconfig
EOF
基础配置包括:
- 集群注册:将现有集群注册到Kurator管理
- 网络配置:配置跨集群通信网络
- 存储配置:配置共享存储或存储类
- 监控配置:配置Prometheus联邦采集
通过这些步骤,一个基础的Kurator环境已经搭建完成,可以开始探索更多高级功能。
四、多集群管理与Fleet实践
4.1 Fleet架构与设计哲学
Fleet架构官方参考图: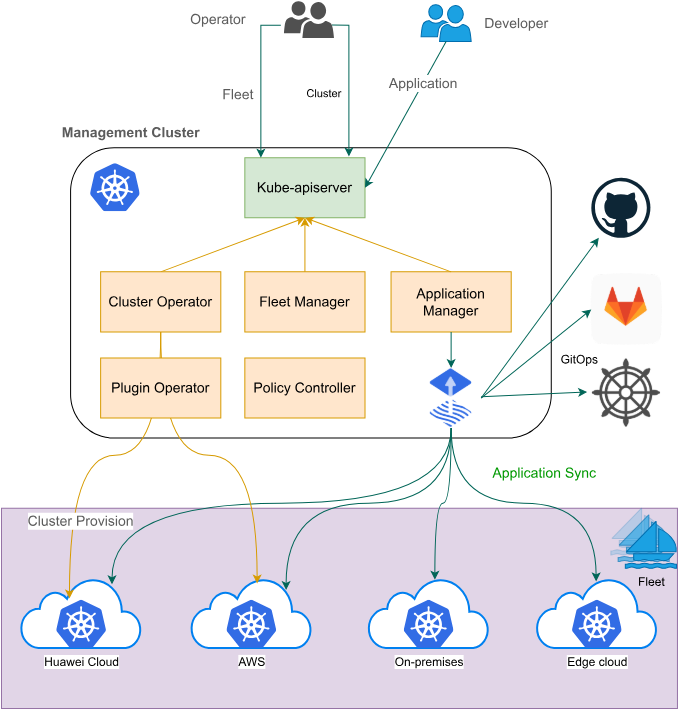
Fleet是Kurator多集群管理的核心抽象,代表一组逻辑上相关的集群。Fleet的设计哲学是"逻辑统一,物理分散",即在逻辑层面提供统一的管理视图,同时保留各集群的物理独立性。
Fleet架构的关键组件包括:
- Fleet Controller:负责Fleet生命周期管理
- Cluster Registration:集群注册与注销机制
- Resource Synchronization:资源同步引擎
- Service Sameness:服务相同性实现
- Identity Sameness:身份相同性实现
Fleet通过声明式API定义,示例如下:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- name: cluster-east
kubeconfigSecret: cluster-east-kubeconfig
- name: cluster-west
kubeconfigSecret: cluster-west-kubeconfig
placement:
clusterSelector:
region: production
syncResources:
- kind: Namespace
name: business-app
- kind: ServiceAccount
name: app-service-account
4.2 集群注册与资源同步实战
Fleet 的集群注册官方参考图: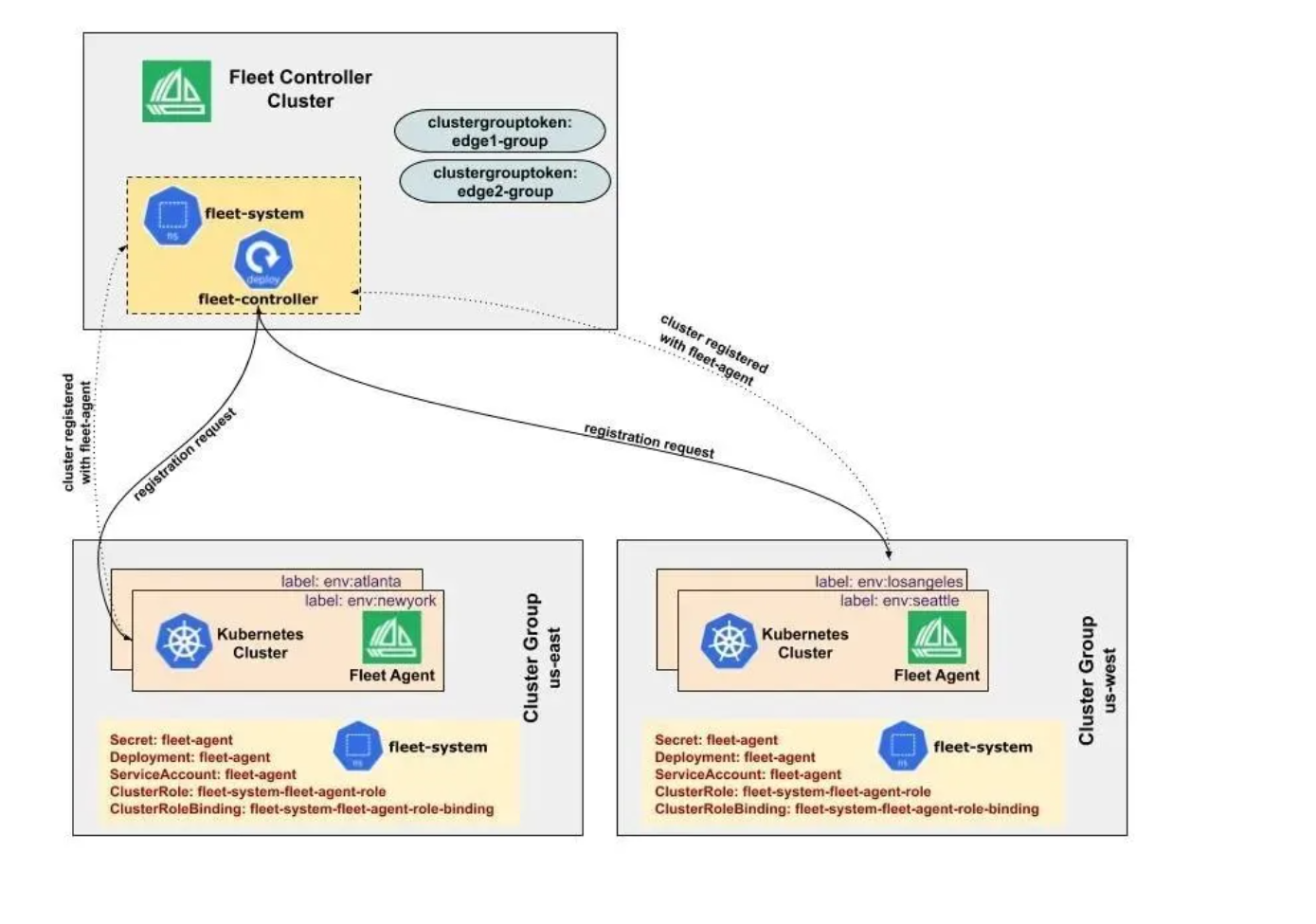
将集群注册到Fleet是多集群管理的第一步。注册过程包括生成kubeconfig、创建Secret、更新Fleet配置等步骤:
# 为member集群生成kubeconfig
kubectl config view --flatten --minify > member1-kubeconfig.yaml
# 创建Secret
kubectl create secret generic member1-kubeconfig \
--from-file=kubeconfig=member1-kubeconfig.yaml \
-n kurator-system
# 更新Fleet配置
kubectl edit fleet test-fleet
资源同步是Fleet的核心功能。以下示例展示了如何同步命名空间、ServiceAccount和ConfigMap:
apiVersion: fleet.kurator.dev/v1alpha1
kind: ResourceSync
meta
name: common-resources
spec:
fleet: test-fleet
resources:
- kind: Namespace
name: shared-namespace
definition:
apiVersion: v1
kind: Namespace
meta
name: shared-namespace
- kind: ServiceAccount
name: shared-service-account
namespace: shared-namespace
definition:
apiVersion: v1
kind: ServiceAccount
meta
name: shared-service-account
namespace: shared-namespace
- kind: ConfigMap
name: app-config
namespace: shared-namespace
definition:
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
namespace: shared-namespace
config.yaml: |
log_level: info
timeout: 30s
通过ResourceSync资源,Kurator会自动将这些资源同步到Fleet中的所有集群,确保配置一致性。
4.3 跨集群服务发现与通信
在多集群环境中,服务发现与通信是关键挑战。Kurator通过集成Istio,提供了强大的跨集群服务发现能力:
# 跨集群ServiceEntry配置
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
meta
name: remote-service
spec:
hosts:
- remote-service.shared-namespace.global
location: MESH_INTERNAL
ports:
- number: 8080
name: http
protocol: HTTP
resolution: DNS
endpoints:
- address: cluster-east-istio-ingressgateway.istio-system.svc.cluster.local
ports:
http: 80
- address: cluster-west-istio-ingressgateway.istio-system.svc.cluster.local
ports:
http: 80
身份相同性(Identity Sameness)是跨集群通信的基础。Kurator通过统一的证书颁发机构(CA)和SPIFFE/SPIRE框架,确保跨集群服务身份的一致性:
# ServiceAccount相同性配置
apiVersion: fleet.kurator.dev/v1alpha1
kind: IdentitySync
meta
name: service-accounts
spec:
fleet: test-fleet
serviceAccounts:
- name: app-service-account
namespace: business-app
clusterRoleBindings:
- name: app-reader
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: view
通过这些机制,Kurator实现了无缝的跨集群服务调用,应用程序无需关心服务实际部署在哪个集群。
五、边缘计算与KubeEdge集成
5.1 KubeEdge架构与核心组件
KubeEdge架构参考图: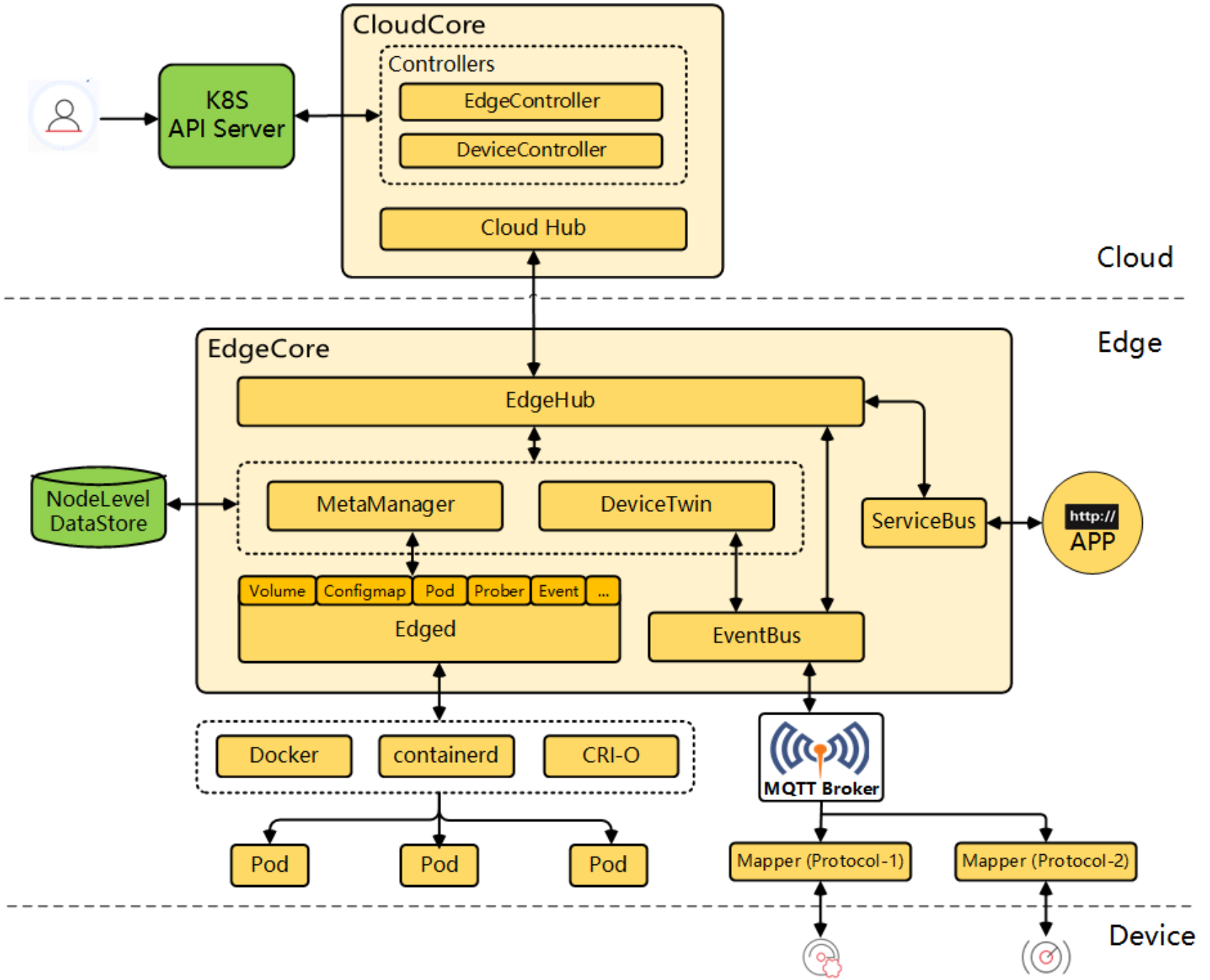
KubeEdge的核心组件参考图: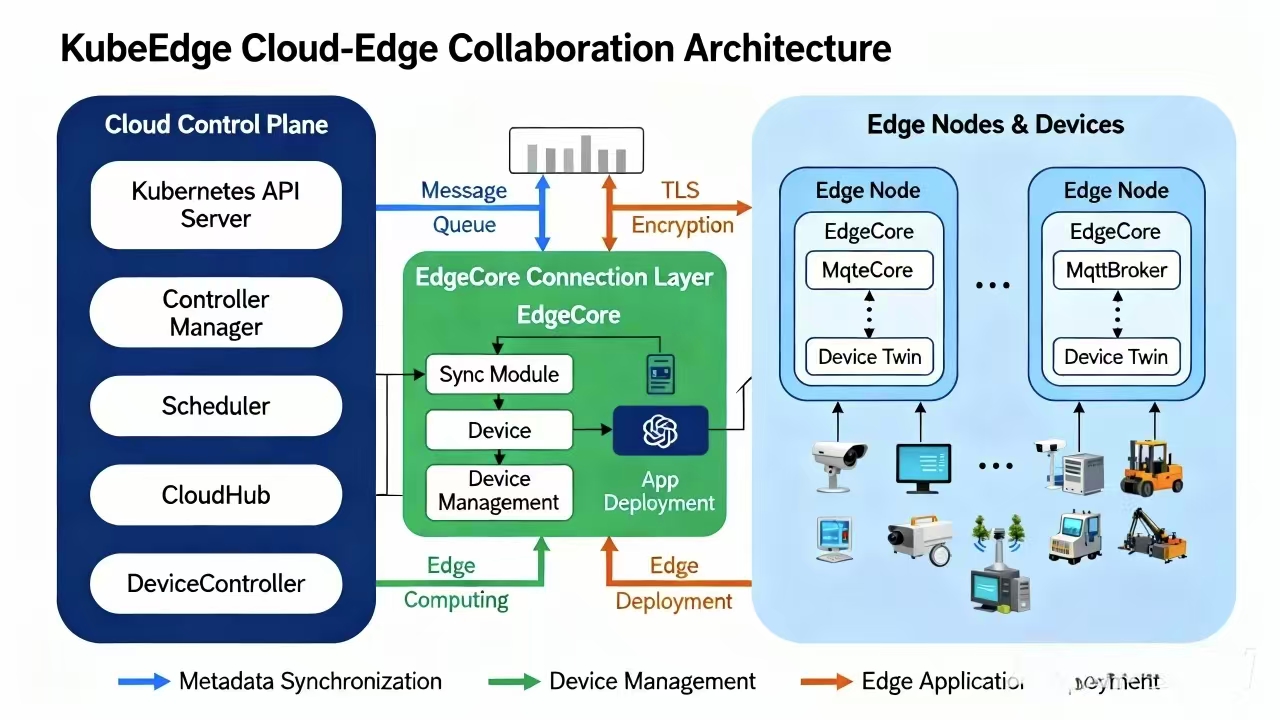
KubeEdge是Kurator集成的边缘计算解决方案,其架构分为云边两部分:
云端组件:
- CloudCore:云端核心组件,负责与Kubernetes API Server通信
- EdgeController:管理边缘节点和应用
- DeviceController:管理边缘设备
边缘组件:
- EdgeCore:边缘核心组件,包括Edged(轻量级Kubelet)、MetaManager、EdgeHub等
- EdgeMesh:边缘服务网格
- DeviceTwin:设备数字孪生
KubeEdge通过WebSocket/Quic隧道实现云边通信,解决了边缘网络不稳定的问题。其架构设计充分考虑了边缘场景的特殊性:弱网络、资源受限、离线运行等。
5.2 Kurator与KubeEdge集成实践
karmada集成实践参考图: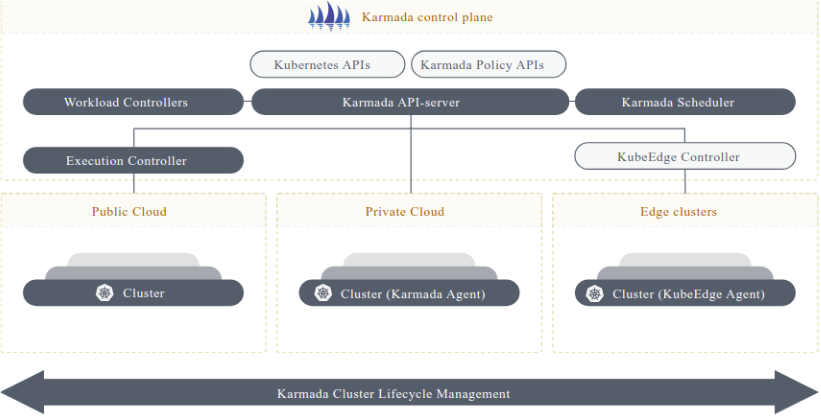
将KubeEdge集成到Kurator平台,可以实现云边协同的统一管理。集成步骤如下:
# 在Kurator中启用KubeEdge
./scripts/install.sh --components kubeedge
# 验证KubeEdge组件
kubectl get pods -n kubeedge
创建边缘集群并注册到Fleet:
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
meta
name: edge-cluster-1
spec:
type: edge
kubeedge:
version: v1.12.1
cloudCore:
nodePort: 30000
edgeNode:
arch: arm64
os: linux
clusterConfig:
apiServerAddress: https://edge-cluster-api.example.com
在边缘集群上部署应用时,需要考虑边缘特性:
# 边缘应用部署示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: edge-app
spec:
replicas: 3
selector:
matchLabels:
app: edge-app
template:
metadata:
labels:
app: edge-app
annotations:
kubeedge.io/edgemesh: "true" # 启用EdgeMesh
spec:
nodeSelector:
node-role.kubernetes.io/edge: "true" # 选择边缘节点
containers:
- name: app
image: edge-app:latest
resources:
limits:
memory: "256Mi" # 限制资源使用
cpu: "500m"
volumeMounts:
- name: local-storage
mountPath: /data
volumes:
- name: local-storage
hostPath:
path: /var/lib/edge-app
5.3 云边协同场景实践
云边协同计算场景参考图: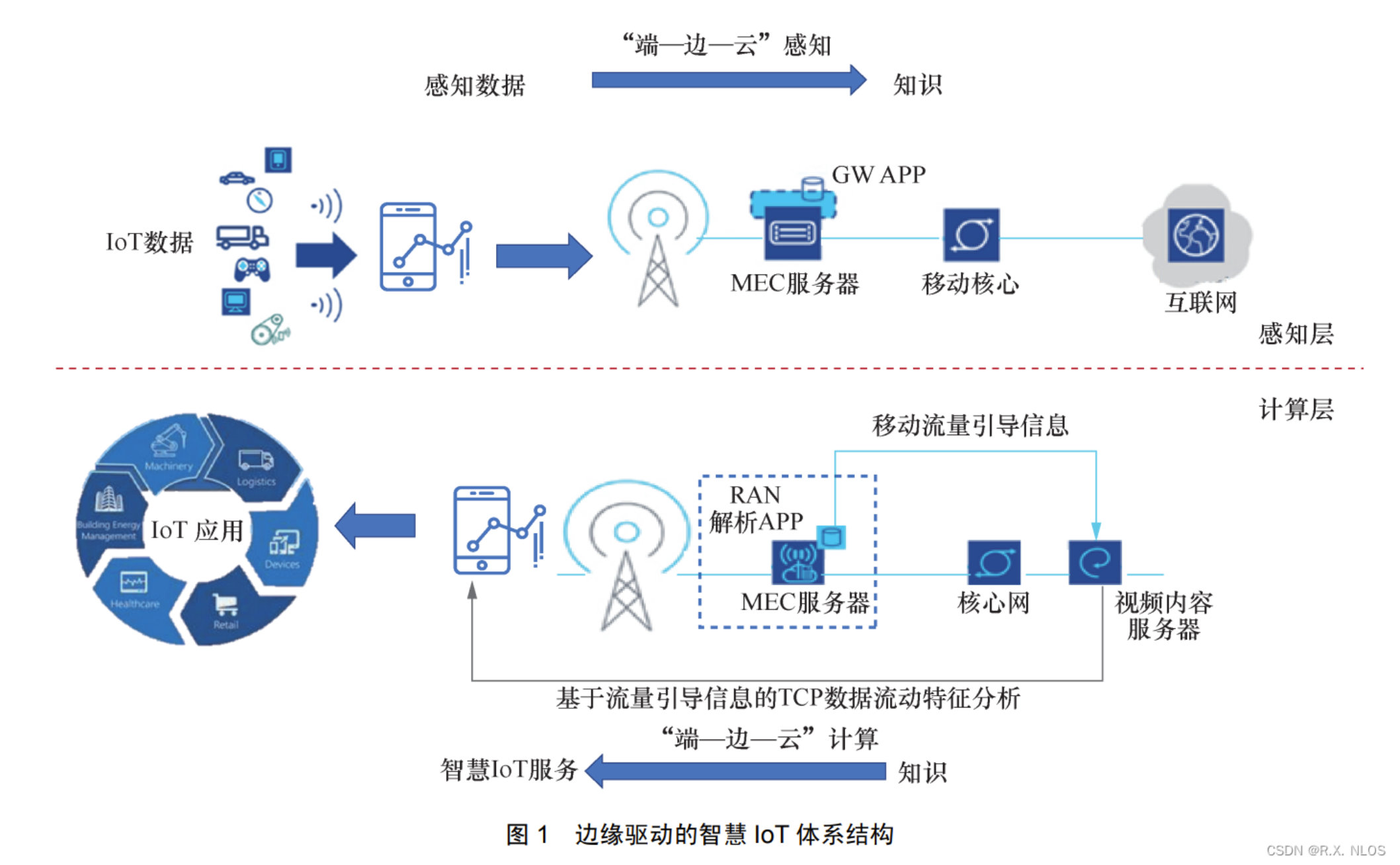
云边协同是边缘计算的核心价值。Kurator通过统一的Fleet管理,实现了云边资源的协同调度。以下是一个典型的云边协同场景:
场景描述:AI推理应用,训练在云端,推理在边缘
# 云端训练任务
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: ai-training
spec:
minAvailable: 1
schedulerName: volcano
tasks:
- replicas: 1
name: trainer
template:
spec:
containers:
- name: trainer
image: ai-trainer:latest
command: ["python", "train.py"]
volumeMounts:
- name: model-storage
mountPath: /models
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: model-pvc
# 边缘推理服务
apiVersion: apps/v1
kind: Deployment
meta
name: ai-inference
annotations:
kurator.dev/sync-to-fleet: edge-fleet # 同步到边缘Fleet
spec:
replicas: 5
selector:
matchLabels:
app: ai-inference
template:
meta
labels:
app: ai-inference
spec:
nodeSelector:
node-role.kubernetes.io/edge: "true"
containers:
- name: inference
image: ai-inference:latest
env:
- name: MODEL_PATH
value: /models/latest-model
volumeMounts:
- name: model-storage
mountPath: /models
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: edge-model-pvc
通过Kurator的统一管理,模型训练完成后自动同步到边缘节点,实现无缝的云边协同。这种架构充分利用了云端强大的计算能力和边缘节点的低延迟特性,是分布式AI应用的理想选择。
六、高级调度与资源优化
6.1 Volcano调度架构解析
Volcano调度架构参考图: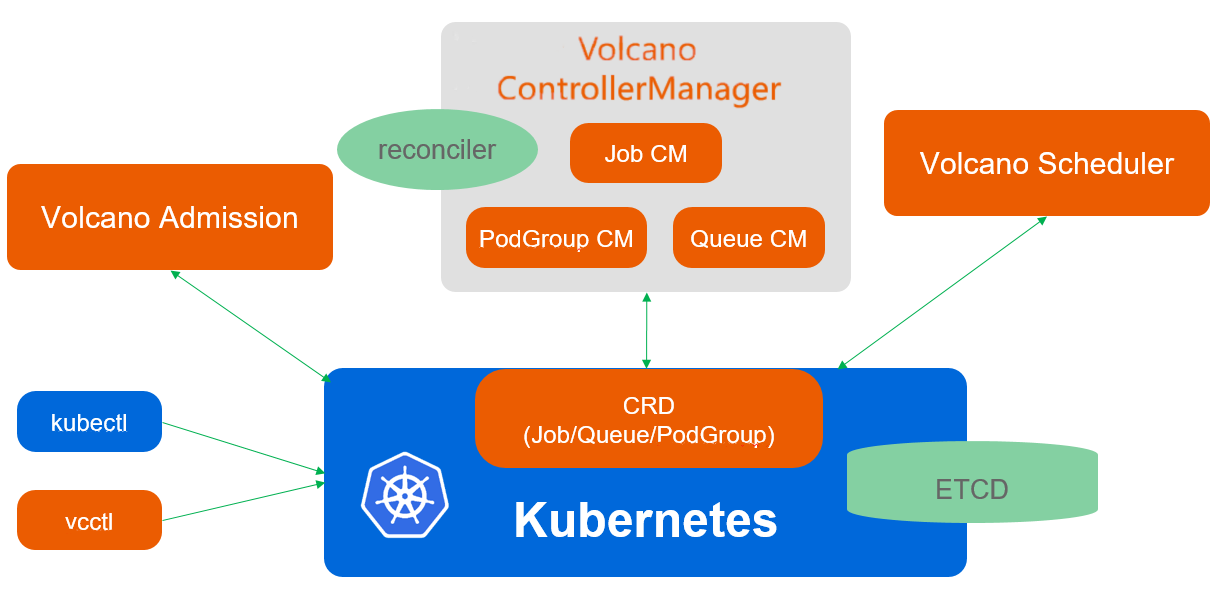
Volcano是Kurator集成的批处理调度器,专为AI/ML、大数据、HPC等计算密集型工作负载优化。其架构包括多个核心组件:
- Scheduler:核心调度引擎,支持多种调度策略
- Controllers:Job Controller、Queue Controller等
- Webhook:准入控制,实现自定义逻辑
- Cache:集群状态缓存,提高调度性能
Volcano通过PodGroup、Queue等抽象,实现了作业级别的调度语义,解决了Kubernetes原生调度器在批处理场景的不足。
6.2 Volcano在Kurator中的集成实践
在Kurator中启用Volcano,并创建一个AI训练队列:
# 创建训练队列
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: ai-training-queue
spec:
weight: 1
capability:
cpu: "100"
memory: 500Gi
reclaimable: true
定义PodGroup实现作业协同调度:
# AI训练作业
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: distributed-training
spec:
minAvailable: 8 # 需要8个Pod同时就绪
schedulerName: volcano
queue: ai-training-queue
tasks:
- replicas: 4
name: ps # 参数服务器
template:
spec:
containers:
- name: ps
image: tensorflow/tensorflow:latest
command: ["python", "ps.py"]
resources:
limits:
cpu: "2"
memory: "8Gi"
- replicas: 4
name: worker # 工作节点
template:
spec:
containers:
- name: worker
image: tensorflow/tensorflow:latest
command: ["python", "worker.py"]
resources:
limits:
cpu: "8"
memory: "32Gi"
nvidia.com/gpu: 1
这个配置确保了4个参数服务器和4个工作节点能够同时调度,避免了部分调度导致的资源浪费。Volcano还支持gang scheduling、bin packing、topology-aware等高级策略,满足不同场景需求。
6.3 跨集群弹性伸缩与资源优化
Kurator通过集成Karmada,实现了跨集群的弹性伸缩能力。Karmada的PropagationPolicy定义了资源如何分发到成员集群:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: service-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: frontend
placement:
clusterAffinity:
clusterNames: ["cluster-east", "cluster-west"]
replicaScheduling:
replicaSchedulingType: Divided # 分片调度
replicaDivisionPreference: Weighted # 按权重分配
weightList:
- targetCluster:
clusterNames: ["cluster-east"]
weight: 70
- targetCluster:
clusterNames: ["cluster-west"]
weight: 30
基于指标的弹性伸缩策略:
apiVersion: autoscaling.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
meta
name: auto-scaling-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: backend
placement:
clusterAffinity:
clusterNames: ["cluster-east", "cluster-west"]
replicaScheduling:
replicaSchedulingType: Aggregated # 聚合调度
autoScaling:
enabled: true
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: External
external:
metricName: request-per-second
targetValue: 1000
这种跨集群弹性伸缩策略可以根据全局负载情况,动态调整各集群的副本数量,实现资源的最优利用。Kurator通过统一的监控指标收集,为弹性伸缩提供了准确的数据基础。
七、GitOps与CI/CD流水线构建
7.1 GitOps实现原理与架构
GitOps是Kurator的核心理念之一,通过将系统状态声明在Git仓库中,实现可审计、可回溯、可协作的基础设施管理。Kurator基于FluxCD实现了完整的GitOps能力:
- Source Controller:监控Git仓库、Helm仓库、OCI仓库的变化
- Kustomize Controller:处理Kustomize资源配置
- Helm Controller:管理Helm chart部署
- Notification Controller:处理事件通知
GitOps的核心原则是"声明式配置+自动同步",系统状态与Git仓库保持最终一致性。这种模式大大简化了多环境管理,提高了发布可靠性和团队协作效率。
7.2 FluxCD Helm应用实践
在Kurator中,通过FluxCD部署Helm应用是常见场景。以下是一个完整的示例:
# 创建Helm仓库
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
meta
name: bitnami
namespace: flux-system
spec:
interval: 10m
url: https://charts.bitnami.com/bitnami
# 部署Redis应用
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
meta
name: redis
namespace: default
spec:
chart:
spec:
chart: redis
version: "17.0.0"
sourceRef:
kind: HelmRepository
name: bitnami
namespace: flux-system
interval: 5m
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
values:
auth:
enabled: true
password: "secure-password"
master:
persistence:
enabled: true
size: 8Gi
replica:
replicaCount: 3
persistence:
enabled: true
size: 8Gi
这个配置会自动从Bitnami Helm仓库拉取Redis chart,并部署到集群中。FluxCD会持续监控仓库变化,自动同步配置更新。这种声明式方式使得应用部署可审计、可回溯,大大提高了运维效率。
7.3 Kurator CI/CD流水线构建
Kurator通过整合GitOps与多集群能力,构建了强大的CI/CD流水线。一个典型的流水线包括:
- 代码构建:CI工具(如Jenkins、GitHub Actions)构建镜像
- 镜像推送:将镜像推送到容器仓库
- 配置更新:更新Git仓库中的Kubernetes manifest
- 自动同步:FluxCD检测变更并同步到集群
- 多环境发布:通过Kurator策略控制发布顺序和比例
# 多环境发布策略
apiVersion: fleet.kurator.dev/v1alpha1
kind: ReleasePolicy
meta
name: canary-release
spec:
fleet: production-fleet
targetResource:
kind: Deployment
name: frontend
namespace: default
phases:
- name: staging
clusters: ["staging-cluster"]
replicas: 1
duration: 1h
verification:
metrics:
- name: error-rate
threshold: 0.01
- name: canary
clusters: ["production-cluster-1"]
replicas: 10% # 10%流量
duration: 2h
verification:
metrics:
- name: latency
threshold: 200ms
- name: production
clusters: ["production-cluster-1", "production-cluster-2"]
replicas: 100%
这种渐进式发布策略大大降低了发布风险,确保了业务连续性。Kurator通过统一的策略定义,简化了多环境管理的复杂性,使团队能够快速、安全地交付价值。
八、Kurator未来展望与企业数字化转型
8.1 技术演进与创新方向
Kurator作为分布式云原生平台,其未来发展将聚焦于几个关键方向:
智能化调度:结合AI/ML技术,实现更精准的资源预测和调度决策。通过历史数据分析,预测应用负载变化,提前进行资源调配,提高资源利用率。
安全增强:零信任架构的深度集成,实现细粒度的访问控制和威胁检测。包括服务身份认证、数据加密、安全策略自动执行等能力。
边缘智能:更强大的边缘计算支持,包括边缘AI推理、边缘数据处理、离线场景支持等。通过轻量级运行时和优化的通信协议,降低边缘节点资源需求。
多云治理:增强的多云治理能力,包括成本优化、合规检查、资源回收等。通过统一的策略引擎,实现跨云资源的标准化管理。
8.2 企业落地实践建议
企业在采用Kurator进行数字化转型时,应遵循渐进式演进策略:
阶段一:单集群优化:首先在单集群中实施Kurator的基础能力,如GitOps、监控告警、策略管理等,积累经验并建立团队能力。
阶段二:多集群试点:选择非关键业务,试点多集群部署,验证跨集群服务发现、资源同步等能力,优化网络架构和安全策略。
阶段三:边缘扩展:根据业务需求,逐步引入边缘计算能力,构建云边协同架构,重点关注数据同步、离线运行、弱网络适应等挑战。
阶段四:全局优化:基于前期经验,实施全局资源优化、成本管理、自动化运维等高级能力,实现真正的分布式云原生架构。
关键成功因素包括:
- 组织协同:打破技术孤岛,建立跨职能团队
- 技能培养:投资团队能力建设,掌握云原生技术栈
- 度量驱动:建立明确的度量指标,持续优化架构
- 文化转型:拥抱DevOps文化,促进快速迭代和学习
8.3 开源生态与社区共建
Kurator的成功离不开活跃的开源社区。作为Apache 2.0许可的开源项目,Kurator鼓励社区参与和贡献:
贡献方式:
- 代码贡献:修复bug、实现新功能、优化性能
- 文档贡献:完善文档、编写教程、分享案例
- 社区支持:回答问题、组织活动、推广项目
- 生态集成:开发插件、集成第三方工具、扩展能力
社区治理:
- 透明决策:RFC(Request for Comments)流程,公开讨论重大决策
- 贡献者成长:明确的贡献者晋升路径,从Member到Committer到Maintainer
- 多样性包容:欢迎不同背景、不同技能的贡献者参与
- 企业参与:鼓励企业投入资源,共同推动项目发展
通过社区共建,Kurator将持续演进,成为分布式云原生领域的标杆项目,为企业数字化转型提供强大支撑。我们期待更多开发者和企业加入Kurator社区,共同塑造云原生的未来。
结语
Kurator作为分布式云原生平台的集大成者,为企业提供了从传统架构向云原生架构演进的完整路径。通过深度整合Kubernetes生态中的优秀项目,并在多集群管理、边缘计算、统一调度等关键领域进行创新,Kurator解决了企业数字化转型中的核心挑战。
本文从平台概述、技术架构、环境搭建、多集群管理、边缘计算、高级调度、GitOps实践到未来展望,全面解析了Kurator的技术原理和企业级应用。通过丰富的代码示例和实践案例,展示了Kurator在真实场景中的应用价值。
随着云原生技术的持续演进,Kurator将继续发挥其在分布式架构中的关键作用。我们相信,通过开源社区的共同努力,Kurator将成为企业构建现代化应用基础设施的重要选择,推动云原生技术在更广泛领域的落地应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)