【前瞻创想】Kurator云原生舰队管理的终极指南:多云环境下的那些事儿
【前瞻创想】Kurator云原生舰队管理的终极指南:多云环境下的那些事儿
咱们今天不整那些虚头巴脑的客套话,直接切入正题。现在的云原生圈子,单集群玩得溜已经不算啥本事了,真正让人头大的,是手里握着几十上百个集群,分布在不同的云厂商、边缘节点甚至自家机房里,那场面,简直就是“群雄割据”。这时候你就需要一个能统领三军的帅才,Kurator 就是这么个角色。它不仅仅是个工具,更像是一个懂你心意的“大管家”,帮你把这些散落在各地的 Kubernetes 集群给归拢起来,形成一支纪律严明的“舰队”。
今天咱们就来扒一扒 Kurator 到底神在哪儿,怎么用它把咱们的云原生基础设施管得服服帖帖。
01. 搞起:先把环境搭起来,家伙事儿得备好
要想玩转 Kurator,第一步肯定得先把环境给支棱起来。这玩意儿安装其实没那么玄乎,不用你对着黑底白字的屏幕敲半天配置。咱们主打的就是一个“快”字。
环境搭建的那些坑与路
你得准备一台 Linux 机器,配置别太寒碜,毕竟是要跑管理平面的。网络得通畅,尤其是要去 GitHub 拉代码的时候,别卡在半路上。咱们采用源码安装的方式,这样以后你想改点啥配置,或者深入研究下源码,都方便得很。
如图这是kurator的gitCode站内资源
点击项目中可以看到如下的源码文件内容
到这一步我们下载源码就分成方便啦
如果我们有git环境就可以直接用命令clone到本地
如果没有的话也可以直接下载zip包
下载下来解压缩就能得到源码文件啦
如下是源码文件
代码拉下来之后,解压进目录,咱们的征程就算正式开始了。这只是第一步,后面还有好戏看。环境搭好了,你手里的这台机器就成了“指挥部”,接下来的所有指令,都将从这里发向你的各个集群。
02. Kurator平台的总体架构:上帝视角看盘子
这时候你可能要问了,这 Kurator 到底长啥样?别急,咱们这就把它拆开了揉碎了讲。
Kurator平台的总体架构
这是Kurator平台的总体架构图,展示了控制平面、集群网络、成员集群及应用层在统一管理框架下的数据流与组件关系: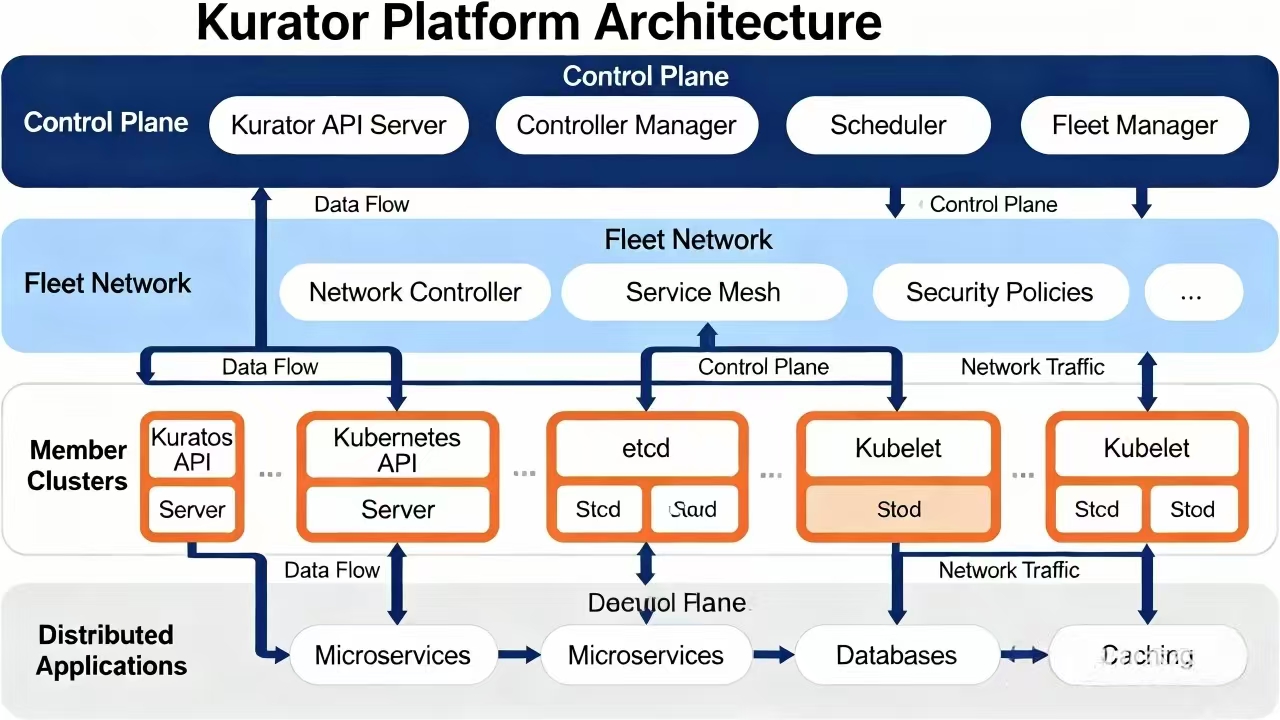
想象一下,你手里有一个巨大的控制台,这个控制台就是 Kurator 的核心。它的架构设计非常讲究“分层”和“解耦”。最上面这层,是咱们的用户接口,不管是你用命令行工具(CLI)还是将来可能有的 Web 界面,都是通过这层跟系统打交道。
往下走,就是核心控制平面。这里面住着几个“大将”。其中最核心的当然是舰队管理(Fleet Management)模块,它负责维护所有集群的生命周期。旁边还有应用分发中心,负责把你的业务代码撒向各个集群。再底层,Kurator 并没有重复造轮子,而是站在了巨人的肩膀上。它集成了 Karmada、Istio、Rook 这些业界顶级的开源项目,把它们通过一种巧妙的胶水逻辑粘合在一起,对外提供统一的 API。这就好比你买了一辆豪车,发动机是法拉利的,内饰是宾利的,底盘是保时捷的,但你只需要握好这一个方向盘就行。
Kubernetes集群的标准架构
在 Kurator 的眼里,不管是管理集群(Host Cluster)还是成员集群(Member Cluster),它们都得讲规矩。这个规矩就是 Kubernetes 的标准架构。每个集群必须有标准的 API Server、Controller Manager 和 Scheduler,还得有 etcd 做数据存储。Kurator 不会去魔改 K8s 的原生组件,这一点非常关键,保证了兼容性。不管你是阿里的 ACK,腾讯的 TKE,还是自己用 kubeadm 搓出来的集群,只要符合 K8s 标准,Kurator 都能接管。它通过标准的 KubeConfig 文件跟这些集群建立连接,然后在里面安装一个小小的 Agent,就像是派驻过去的“联络员”,负责上情下达。
Cluster Operator的实现
这时候你可能会担心,这么多集群,光是创建和销毁就够累死人的。这时候 Cluster Operator 就派上用场了。这玩意儿的实现逻辑其实是基于 Cluster API 的。它定义了一套自定义资源(CRD),比如 Cluster、Machine、MachineSet。
当你在 Kurator 里告诉它:“嘿,给我搞个新集群”,Cluster Operator 就会监听到这个指令。它会根据你定义的模板(比如你是要 AWS 的虚拟机,还是 vSphere 的虚拟机),去调用底层基础设施的 API 接口,自动要把虚拟机拉起来,把 K8s 组件装好,最后把网络插件(CNI)和存储插件(CSI)都配齐。这一切都是自动化的,不用你再去手动 SSH 到机器上一顿操作。
这张图展示了Cluster Operator的实现细节,其实就是用户通过声明一个CRD,触发API Server事件,然后由Operator监听并调度多个管理worker去自动对接和管理不同的本地集群,整个过程用无密码认证打通,既安全又高效: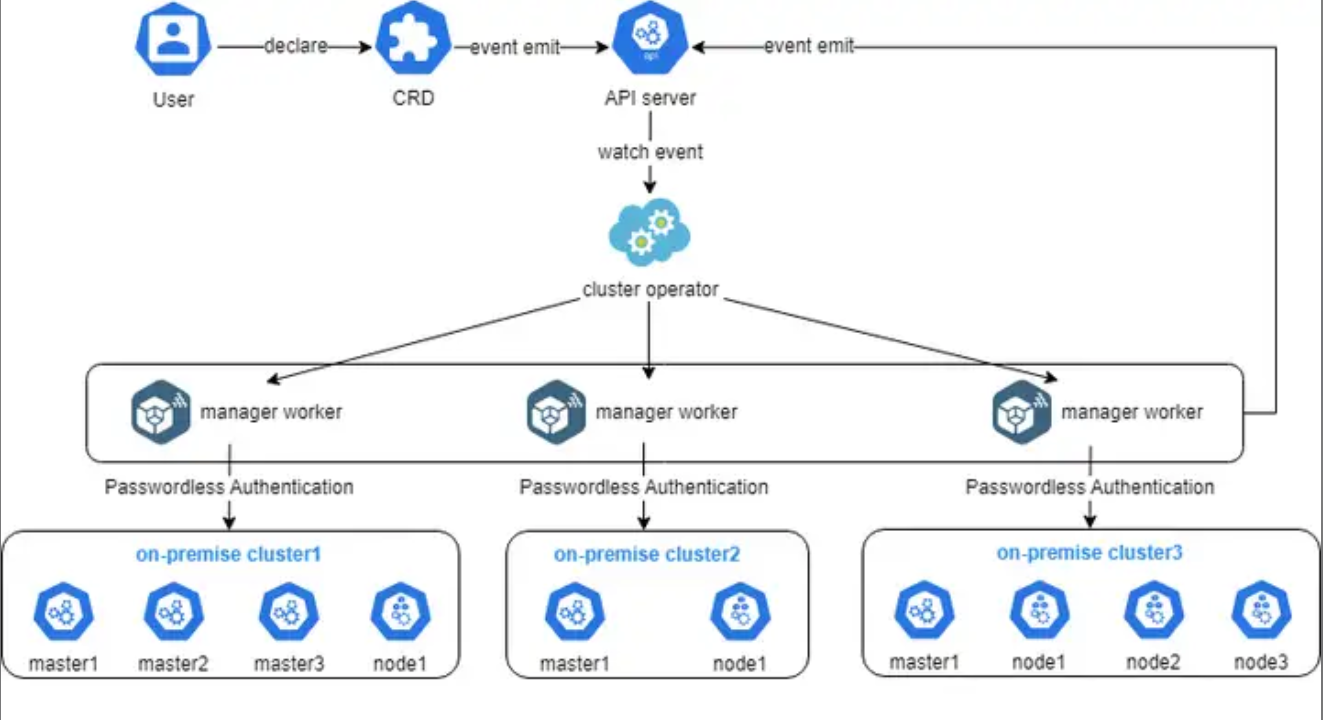
03. 云原生舰队管理:千军万马怎么带
集群多了,就不能叫“多集群”了,那叫“舰队”(Fleet)。这一块是 Kurator 的看家本领。
云原生舰队管理
所谓的舰队管理,就是把一堆集群当成一个大集群来管。在 Kurator 里,你不再需要记住哪个集群叫 cluster-a,哪个叫 cluster-b,也不用切来切去 kubectl config use-context。你只需要给这些集群打上标签,比如 region=beijing,env=prod。
当你需要在这个舰队里做操作时,Kurator 会自动根据这些标签去筛选目标集群。比如你想看所有生产环境集群的节点状态,一条命令下去,Kurator 会自动聚合所有符合 env=prod 标签集群的信息反馈给你。这就好比你是总司令,你下令“第一方面军进攻”,你不需要给每个连长打电话,指令自然会传达到位。
这张图讲的是云原生舰队管理,就是通过一个管理中心集群来统一管理多个下属集群,不管是创建、注册还是部署应用,都可以集中控制: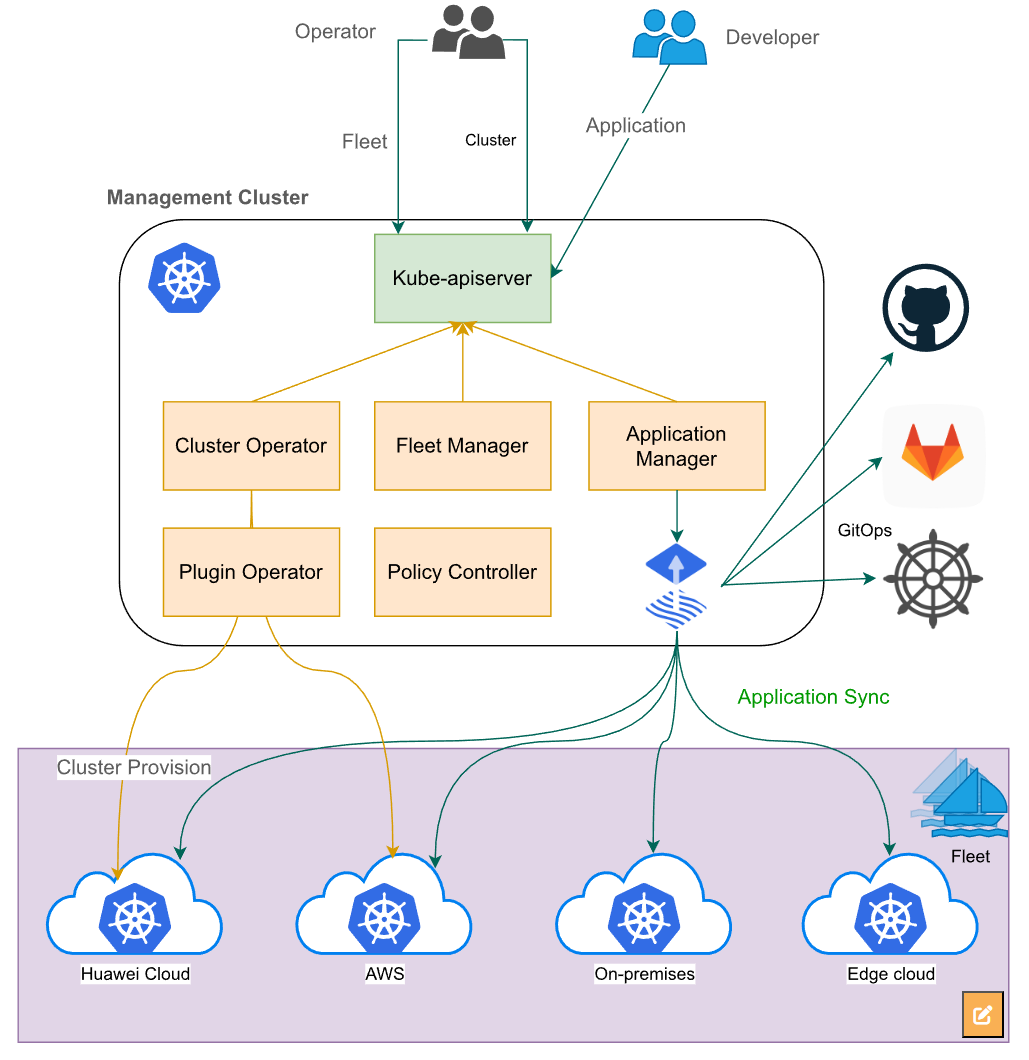
Karmada集成实践
Kurator 的舰队管理能力,底层很大程度上是依赖 Karmada 实现的。Karmada 这个项目很牛,它专门解决 K8s 跨集群调度的问题。Kurator 把 Karmada 集成得非常丝滑。
在 Kurator 中,Karmada 充当了“调度大脑”的角色。当你提交一个 Deployment 时,你不需要指定它具体跑在哪个集群。Kurator 会把这个请求转给 Karmada,Karmada 会根据你预先设定的策略(比如资源剩余量、网络延迟、甚至是用电成本),智能地把这个 Deployment 拆分或者复制,分发到最合适的成员集群上去。我们在实践中发现,这种集成方式极大地降低了运维复杂度,你甚至感觉不到 Karmada 的存在,它就像空气一样,无处不在但又不可见。
这是Karmada集成实践的参考架构图,展示了其控制平面如何通过统一的策略API纳管多云、私有云及边缘异构集群: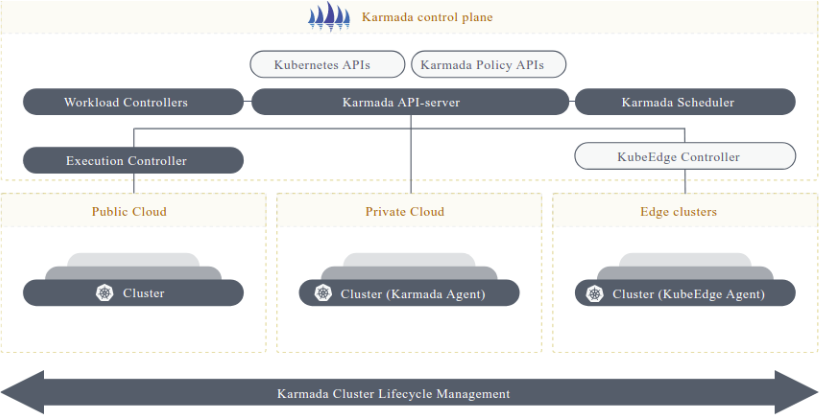
Fleet队列中服务相同性
这个点非常重要,咱们得好好唠唠。在舰队里,最怕的就是“同名不同义”。比如你在 A 集群有个服务叫 user-service,在 B 集群也有个 user-service,它俩到底是不是同一个服务?
Kurator 引入了“服务相同性”(Service Sameness)的概念。简单说,就是它通过一种机制(通常是基于 Namespace 和 Service Name 的映射),保证了在整个舰队范围内,只要名字一样的 Service,就被视为同一个逻辑服务。这在跨集群调用时简直是救命稻草。上层应用不需要关心 user-service 到底在哪个集群,也不用管它的 IP 是多少,直接调这个名字,Kurator 底层的网络机制会自动帮你把流量导向离你最近、或者最健康的那个 user-service 实例。这保证了服务发现的一致性,避免了“裂脑”的尴尬。
这是Fleet队列中服务相同性参考图,展示了其如何在不同集群间跨命名空间智能识别并分发关联服务: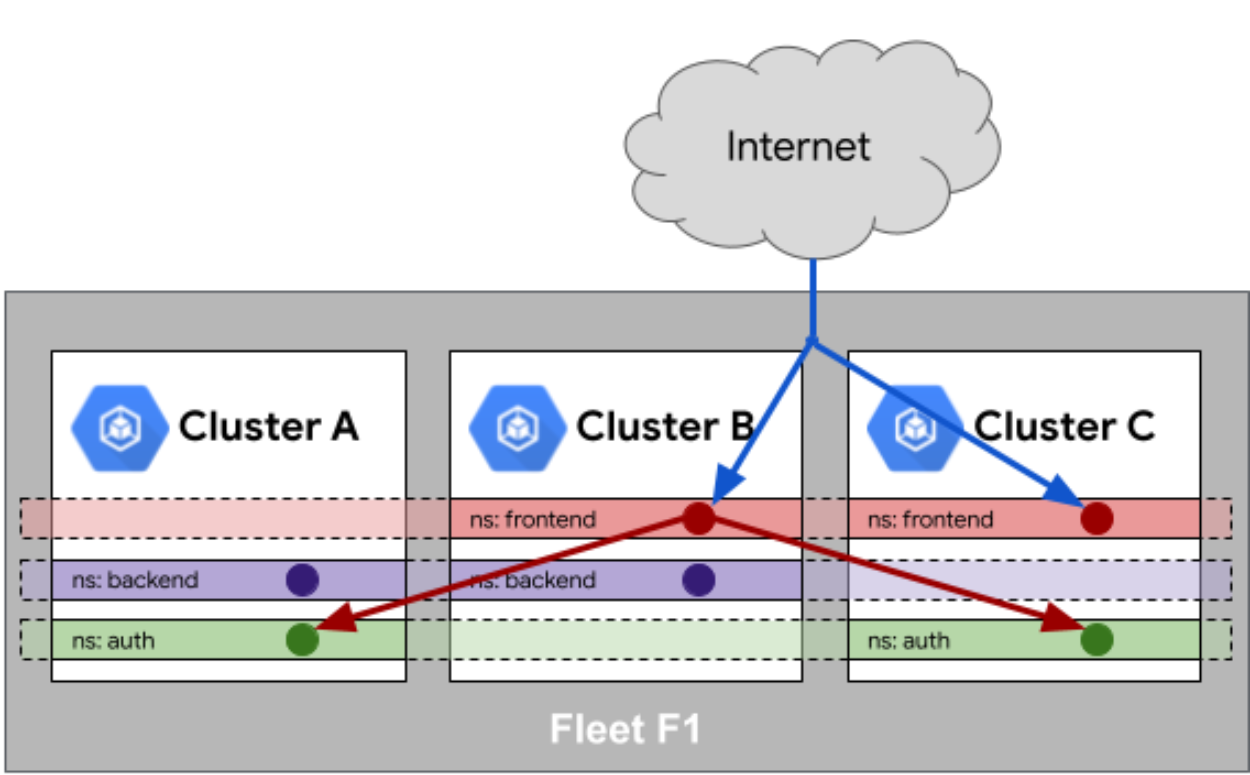
04. 应用分发与GitOps:让代码自己长腿跑
集群管好了,接下来就是往上跑应用。Kurator 在这方面也是下了狠功夫的。
Kurator统一应用分发的管理架构
Kurator 搞了一套统一的应用分发模型。它定义了一个叫 Application 的抽象对象。在这个对象里,你不仅定义了应用长啥样(比如镜像版本、副本数),还定义了它该去哪儿(分发策略)。
这个架构的核心在于“一次定义,到处运行”。你写好一份 YAML,Kurator 会根据你定义的策略,把它渲染成适合不同集群的配置。比如在开发集群,你可能只需要 1 个副本,资源配额给得少点;在生产集群,你要 10 个副本,还要开启 HPA。Kurator 允许你在分发策略里做这些差异化的配置(Override),但源头始终只有一份。这避免了配置漂移,让你时刻清楚线上到底跑的是啥版本。
这张图展示了Kurator统一应用分发的管理架构,实现跨多集群的一致化部署和管理,整个流程简单又可控: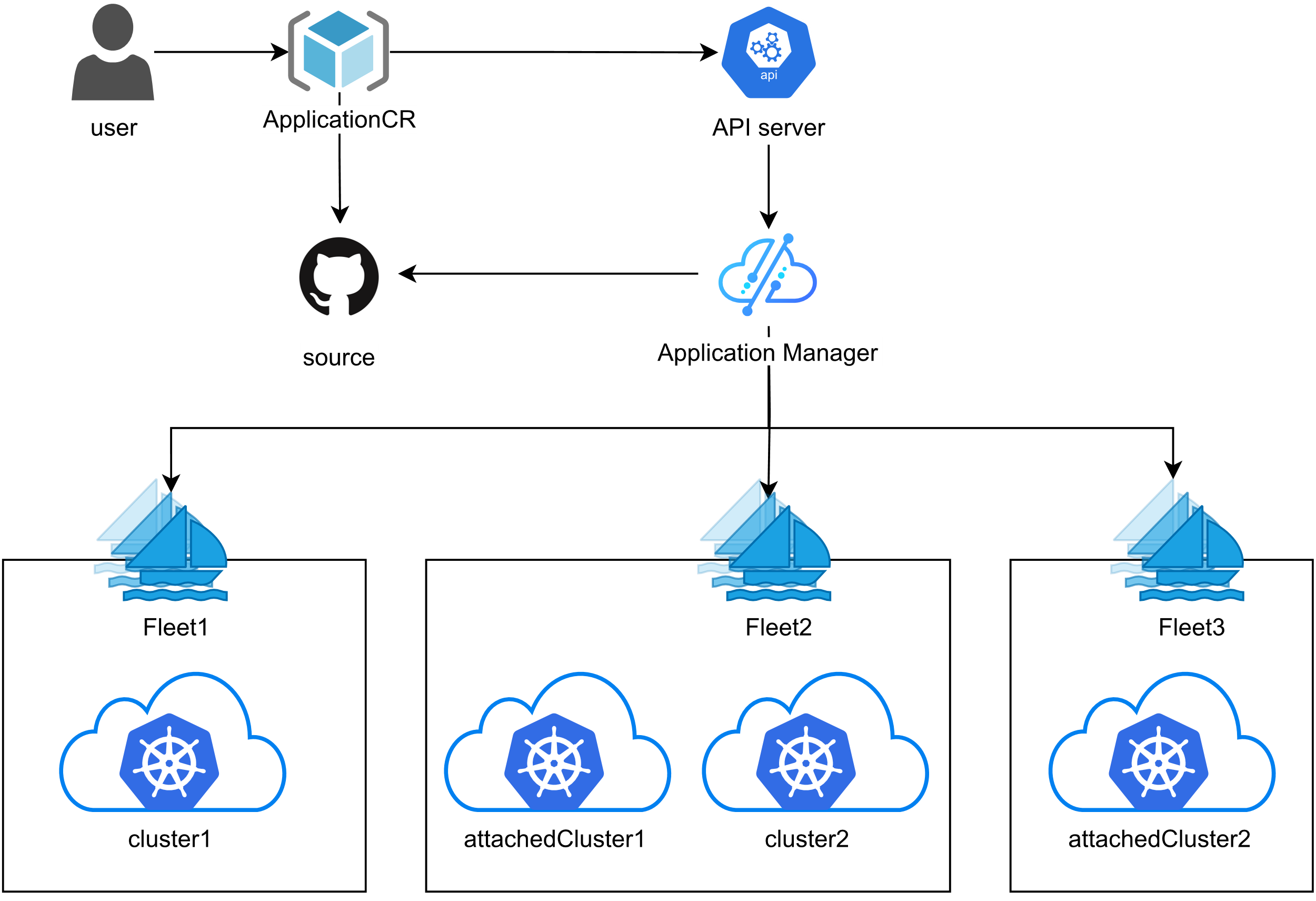
GitOps工作流
现在做云原生,不说 GitOps 都不好意思跟人打招呼。Kurator 天生就是为 GitOps 设计的。它的工作流大致是这样的:你的代码仓库(Git Repo)是唯一的事实来源。
当开发人员把新的代码推送到 Git 仓库后,Kurator 里的 Source Controller 就会感知到这个变化。它不会立马傻乎乎地去更新集群,而是先通过 Kustomize 或者 Helm 对配置进行渲染和校验。校验通过后,Sync Controller 才会把这些变更同步到目标集群。
咱们来看一段手搓的 GitOps 策略配置,这大概就是你平时在 Kurator 里要写的样子:
# 这是一个模拟的手写 ApplicationPolicy
apiVersion: apps.kurator.dev/v1alpha1
kind: ApplicationPolicy
metadata:
name: my-backend-policy
namespace: default
spec:
# 告诉它要去哪个仓库拉代码
source:
repoURL: https://github.com/my-org/my-backend.git
branch: main
path: ./deploy/overlays/prod
# 怎么同步?自动的还是手动的?
syncPolicy:
automated:
prune: true # 仓库里删了,集群里也得删
selfHeal: true # 集群里被人改乱了,自动给它改回来
# 往哪发?这里选用了标签选择器
destination:
clusterSelector:
matchLabels:
env: production
region: us-west
# 这是给某些集群开的小灶(差异化配置)
overrides:
- clusterName: cluster-us-west-1
components:
- name: deployment-replicas
value: 5 # 西部集群负载高,多给点副本
这个流程保证了所有变更都有迹可循,谁在什么时候改了什么,Git 记录得清清楚楚。
05. 统一分布式存储:数据存哪里才放心
有计算就得有存储,尤其是对于有状态应用,存储是个老大难问题。
Kurator的统一分布式存储架构
Kurator 的存储架构不仅仅是给你挂个盘那么简单。它的目标是构建一个跨集群的、统一的存储池。不管你的集群是在 AWS 的 EBS 上,还是在物理机的本地盘上,Kurator 都试图把它们抽象成统一的 StorageClass。
在这个架构里,Kurator 引入了存储中间件层。这一层屏蔽了底层物理存储的差异。对于上层应用来说,它申请的只是一个 PersistentVolumeClaim (PVC),至于这个 PVC 背后到底是块存储还是对象存储,数据是不是做了多副本复制,应用完全不需要关心。
Fleet基于Rook构建统一分布式存储的架构
具体落地时,Kurator 选择了 Rook 作为它的带刀侍卫。Rook 是 Ceph 在 K8s 里的最佳实践。Kurator 会在每个成员集群里(或者专门的存储集群里)自动部署 Rook Operator。
这个架构妙就妙在“超融合”。它利用集群节点的本地磁盘,通过 Rook 把它们组织成一个巨大的分布式存储池(Ceph Cluster)。Kurator 负责协调这些 Rook 实例。比如,你可以定义一个策略,要求某个关键业务的数据必须跨集群备份。Kurator 就会指挥 Rook,通过 Ceph 的多站点(Multi-site)同步功能,把数据从 A 集群的 Ceph 实时复制到 B 集群的 Ceph。这样哪怕 A 集群整个挂了,数据在 B 集群还有一份热备,业务可以秒级切换过去。
06. Istio服务网格与AB测试:流量调度的艺术
最后,咱们聊聊流量。流量是应用的血液,管不好流量,集群再稳也是白搭。
Istio服务网格的完整架构
Kurator 集成了 Istio,并且是那种“完整版”的集成。它不是简单装个 Istio 就完事了,它配置的是多集群网格(Multi-cluster Service Mesh)。
在这个架构中,有一个统一的控制平面(Istiod),通常跑在管理集群或者某个中心集群上。每个成员集群里部署了 Ingress Gateway 和 Egress Gateway,以及每个 Pod 里的 Sidecar 代理(Envoy)。Kurator 会自动打通这些集群之间的网络,通过 mTLS(双向认证)建立安全隧道。这意味着,A 集群的 Pod 访问 B 集群的 Pod,就像访问本地服务一样简单,而且全程加密,安全感拉满。
Kurator中配置AB测试
有了 Istio 的加持,做 AB 测试在 Kurator 里简直是小菜一碟。传统的 AB 测试要在代码里写一堆 if-else,现在不用了,直接在基础设施层搞定。
你想把 10% 的流量切给新版本(v2),90% 的流量留给老版本(v1),只需要在 Kurator 里下发一个流量规则。Kurator 会把它翻译成 Istio 的 VirtualService 和 DestinationRule。
这里给大伙儿看一段手搓的流量切分代码,这可比直接写 Istio 的原生配置要直观一些(这是 Kurator 封装后的逻辑示意):
# Kurator 风格的 AB 测试配置片段
apiVersion: networking.kurator.dev/v1beta1
kind: TrafficSplit
metadata:
name: user-service-ab-test
spec:
service: user-service # 目标服务
# 定义参与测试的后端
backends:
- service: user-service-v1
weight: 90 # 老版本,稳如老狗,扛大旗
- service: user-service-v2
weight: 10 # 新版本,先放点流量试试水
# 还可以加上 HTTP 头的匹配规则
matches:
- headers:
user-group:
exact: "beta-testers" # 只有 beta 组的用户才可能撞到 v2 版本
还有更骚的操作,比如你想验证 Cluster Operator 的升级逻辑。你得确保存储和计算都能平滑过渡。这里再补一个跟 Cluster Operator 相关的配置片段,虽然不是直接的 AB 测试,但体现了如何在代码层面控制集群的升级节奏:
# Cluster Operator 升级策略配置
apiVersion: cluster.kurator.dev/v1alpha1
kind: ClusterUpgradePlan
metadata:
name: upgrade-to-1-30
spec:
targetVersion: v1.30.0
maxUnavailable: 1 # 每次只允许坏一个节点,稳字当头
# 升级前的钩子,比如先排空节点
preUpgradeHooks:
- name: drain-node
command: ["/bin/sh", "-c", "kubectl drain ${NODE_NAME} --ignore-daemonsets"]
selector:
matchLabels:
role: worker
通过这些配置,你可以极其精细地控制流量和集群变更,把风险降到最低。
好啦,讲了这么多,其实 Kurator 的核心逻辑就一条:把复杂留给架构,把简单留给用户。不管是环境搭建、舰队管理,还是应用分发、存储和流量控制,Kurator 都在试图帮你屏蔽底层多云环境的差异。如果你正在为手里那一堆乱七八糟的集群发愁,不妨试试 Kurator,没准儿它就是你一直在找的那把“瑞士军刀”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)