【前瞻创想】搞定分布式云原生不再难:深度解析 Kurator 如何帮你统一管集群、分发策略还能玩转高阶流量调度
【前瞻创想】搞定分布式云原生不再难:深度解析 Kurator 如何帮你统一管集群、分发策略还能玩转高阶流量调度
说起现在的云原生,大家脑子里第一反应肯定是对着一堆 Kubernetes 集群发愁。以前管一个集群,咱还能说是“精耕细作”,现在手里动不动就是几十个甚至上百个集群,有的在公有云,有的在自己家机房,这种分布式云原生的场面,光靠人力去盯着看、敲命令,那真是要了命了。这时候 Kurator 就冒出来了,它就像是一个经验丰富的“舰队司令”,专门为了解决这种多集群乱象而生的。简单来说,Kurator 就是要把那些散落在各处的集群给拧成一股绳,让你像管理一个集群那样,轻轻松松把整个分布式云原生的摊子给支棱起来。
一、 咱先从全局扫一眼:Kurator 的大本营到底是咋设计的?🏗️
1. 拨开迷雾看 Kurator 平台的总体架构
咱得先明白 Kurator 到底长啥样。Kurator 的平台总体架构,说白了就是一个“一加多”的模式。中心有一个主控集群,也就是咱说的“旗舰”,其他的集群就是它的从属。这个架构的核心逻辑就是“解耦”和“插件化”。它不是把所有功能都塞到一个死板的盒子里,而是通过各种 Controller 和 Operator,把集群管理、应用分发、监控告警这些活儿给分派下去。你想要什么功能,Kurator 就给你接什么插件。这种分布式云原生架构最大的好处就是灵活性贼高,不管你的业务跑在哪个旮旯里,Kurator 都能把触手伸过去。
这是Kurator平台的总体架构图,展示了控制平面、集群网络、成员集群及应用层在统一管理框架下的数据流与组件关系: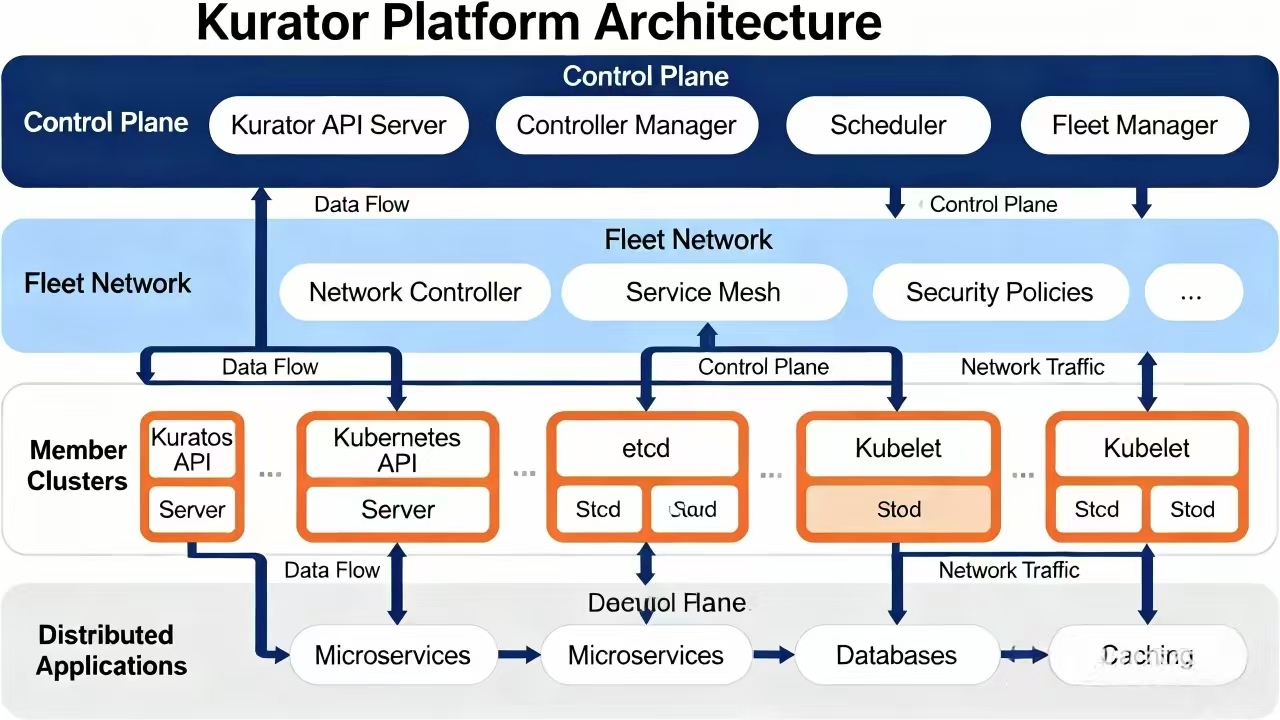
2. 云原生舰队管理:为啥说它是多集群的救星
以前咱们管集群,那叫“打散工”,一个集群配一套班子。但 Kurator 玩的是“舰队管理”。想象一下,你手里有一支庞大的舰队,你不需要去每一艘小船上指挥怎么划桨,你只需要在旗舰上发个信号,整个舰队就齐刷刷地调头或者加速。Kurator 做的就是这件事。它通过统一的入口,把成百上千个 Kubernetes 集群的标准架构给抽象出来。不管你的底层是基于什么虚拟化技术,在 Kurator 眼里,它们都是受它调遣的“船只”。这种管理方式直接把运维的复杂度从指数级降到了线性级。
这张图讲的是云原生舰队管理,就是通过一个管理中心集群来统一管理多个下属集群,不管是创建、注册还是部署应用,都可以集中控制: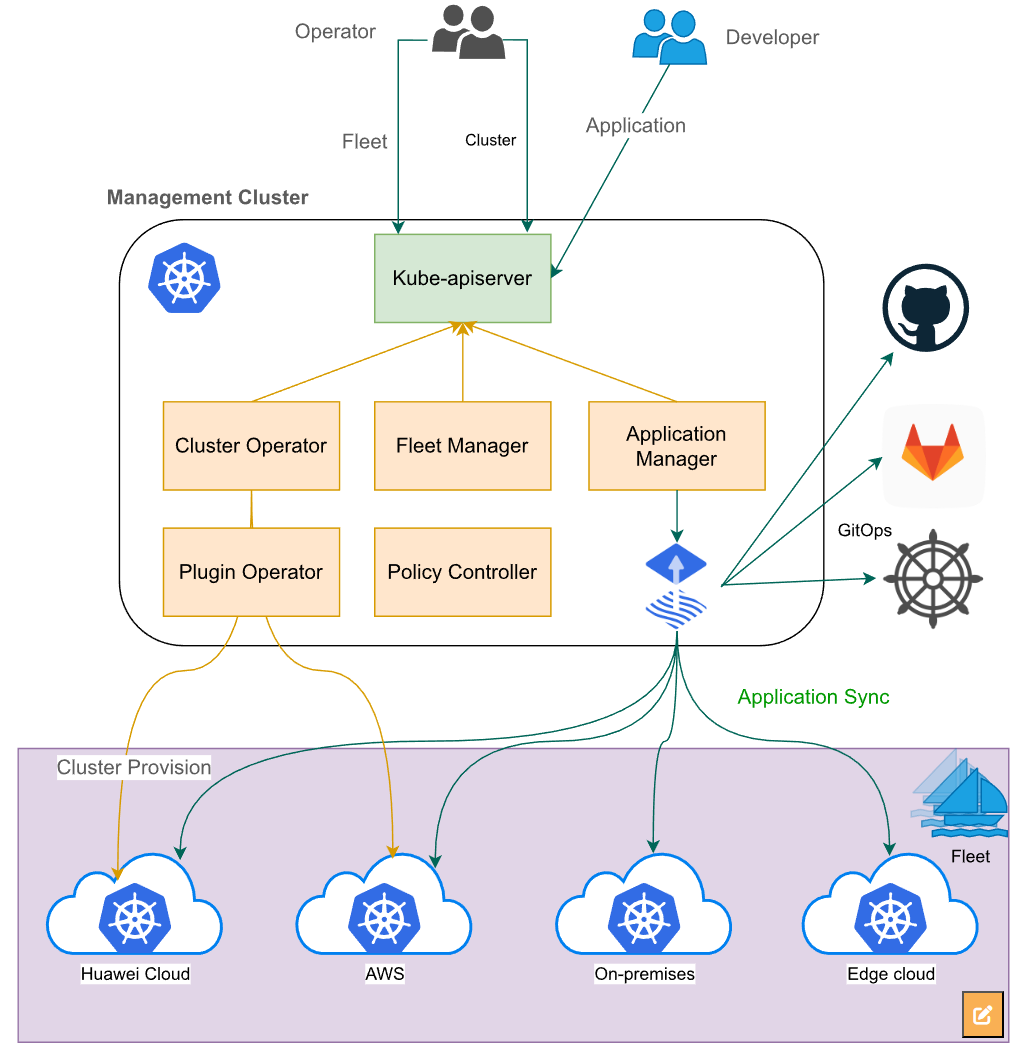
二、 别光看,上手试:环境搭建和集群底座的那些事儿 🛠️
1. 动手开搞:把 Kurator 的代码拉回家
聊了这么多虚的,咱得看点真家伙。要研究 Kurator,第一步肯定是得把人家的代码仓库给搬过来。在项目地址中,可以看到可以clone到本地
https://gitcode.com/kurator-dev/kurator.git
或者我们也可以下载到本地
可以看到我们资源文件已经下载下来了
可以看到版本是0.6.0
2. 聊聊 Kubernetes 集群的标准架构长啥样
在用 Kurator 之前,咱得对 Kubernetes 集群的标准架构心里有个数。一个标准的 K8s 集群,无非就是 Control Plane(控制面)和 Nodes(工作节点)组成的。控制面里有 ApiServer、Etcd、Scheduler 这些大脑部门,而 Node 节点就是干苦力的。Kurator 在接管这些集群的时候,非常看重这种标准化。它要求你的集群得符合它的对接规范,这样它才能通过统一的接口去调动资源。只有底座稳了,上面的舰队管理才不会“翻船”。
三、 集群是怎么“活”过来的?生命周期与 Operator 的幕后逻辑 🧠
1. 集群生命周期管理:从“出生”到“养老”一条龙
很多人觉得集群搭好就完事了,其实真正的坑在后面。集群的升级、扩容、缩容,甚至是最后的销毁,这些全属于集群生命周期管理的范畴。Kurator 厉害的地方就在于,它把这些琐碎的操作给自动化了。你只需要定义一个 YAML 文件,告诉它你想要什么样的集群,Kurator 就会自动去走流程。比如你要升级版本,它会一个节点一个节点地帮你稳妥替换,不用你大半夜盯着进度条看。
这是Kurator集群生命周期管理的详细参考图,展示了从用户声明、多租户插件配置,到控制器协同工作实现异构集群统一纳管的全过程。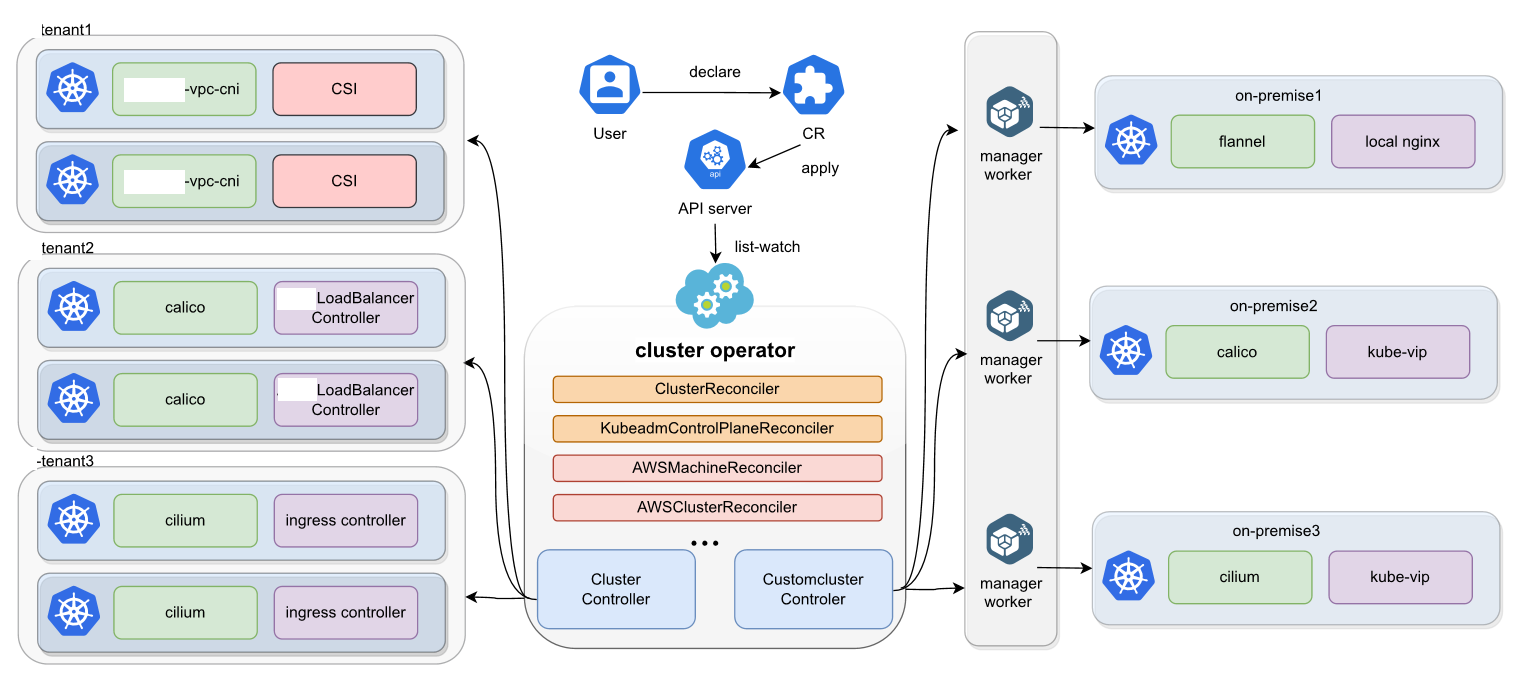
2. Cluster Operator 的实现:那个在幕后操盘的“大脑”
这张图展示了Cluster Operator的实现细节,其实就是用户通过声明一个CRD,触发API Server事件,然后由Operator监听并调度多个管理worker去自动对接和管理不同的本地集群,整个过程用无密码认证打通,既安全又高效: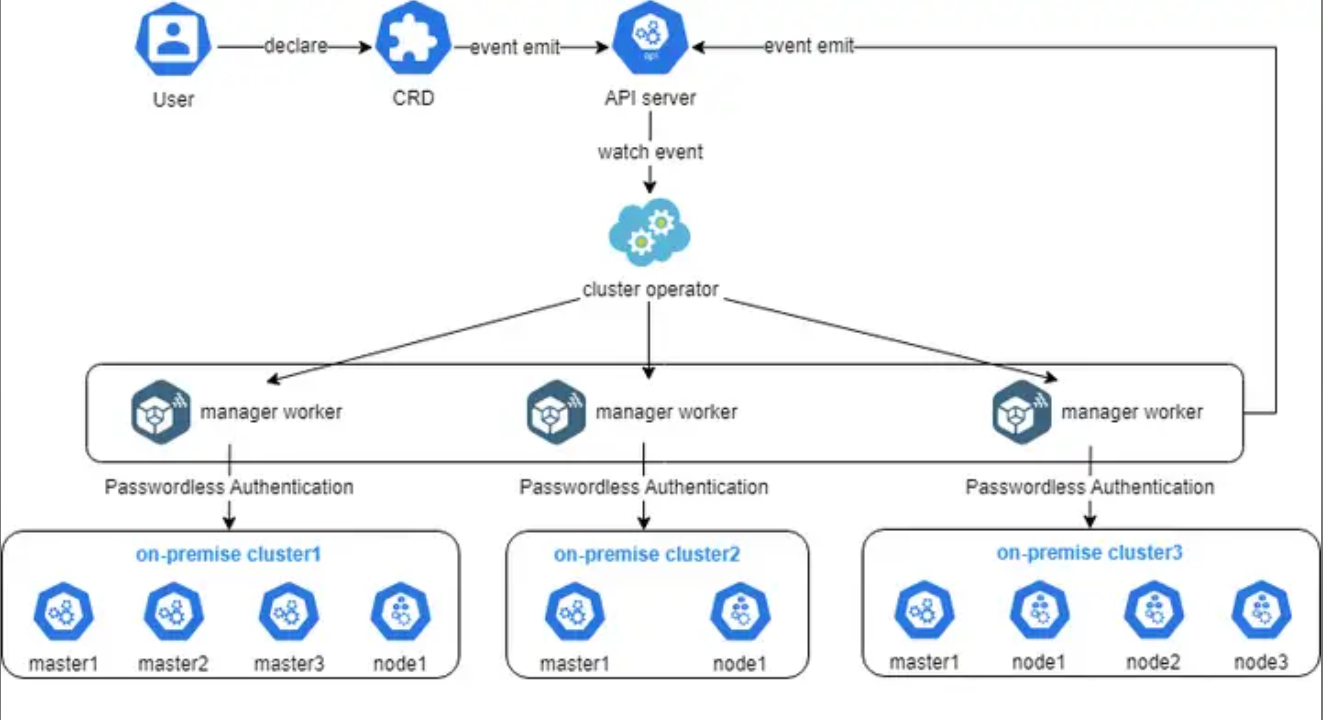
要实现上面说的这些自动化,全靠 Cluster Operator 这里的逻辑。它其实就是一个不停运行的死循环,专业点叫 Reconcile Loop(调谐循环)。它会不断比对你“想要的集群状态”和“集群当前的实际状态”。如果发现不一样,它就开始“施法”,通过调用各种底层 API 把状态给掰回来。
这里我随便写一段逻辑,大家感受一下这种 Reconcile 的感觉,大概就是这么个意思:
// 这是一个简化的集群状态检查逻辑,看看咱们的集群是不是老实按规矩跑着
func (r *ClusterReconciler) ReconcileCluster(ctx context.Context, cluster *v1alpha1.Cluster) error {
// 1. 先去查查现在的集群到底是个啥情况
actualStatus, err := r.CloudProvider.GetStatus(cluster.Name)
if err != nil {
return fmt.Errorf("哎呀,查不到集群状态: %v", err)
}
// 2. 看看用户在 YAML 里写的状态和实际状态对不对得上
if actualStatus.NodeCount < cluster.Spec.MinNodes {
// 如果节点少了,咱就得赶紧加人
log.Printf("集群 %s 节点不够了,赶紧扩容!", cluster.Name)
return r.CloudProvider.ScaleUp(cluster.Name, cluster.Spec.MinNodes - actualStatus.NodeCount)
}
// 3. 没啥事就歇着,过会儿再来瞧瞧
log.Println("集群状态挺稳的,没啥好操心的。")
return nil
}
四、 策略和分发:别让繁琐的配置搞乱了你的分布式系统 📋
1. 统一策略管理架构:一份命令,全军出击
这张图展示了Kurator的统一策略管理架构,用户只需要在一处定义策略,就能通过Fleet和FluxCD自动同步到多个集群,配合Kyverno实现跨集群的一致性治理,真正做到“一次配置,全栈生效”: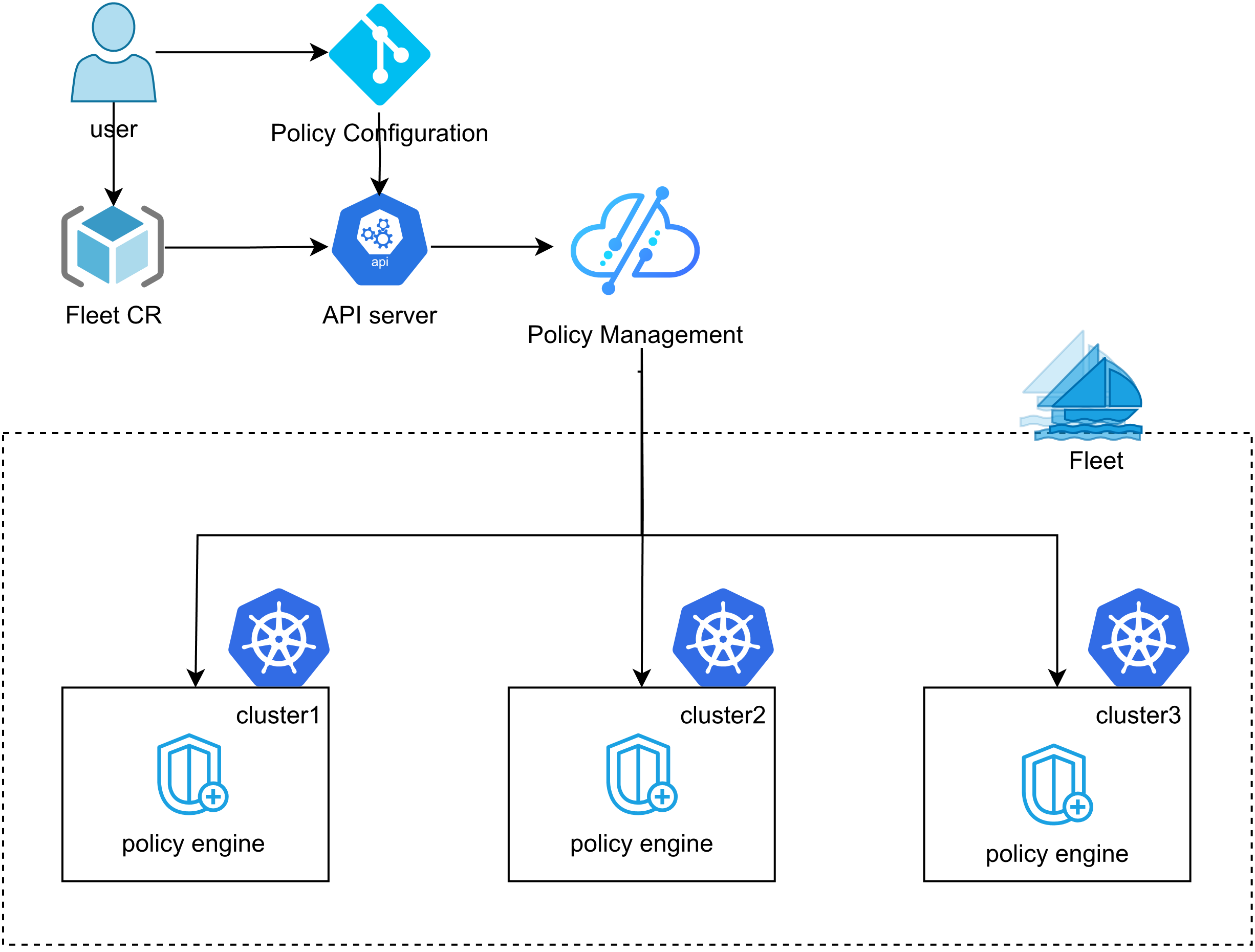
在分布式云原生架构下,最头疼的就是配置一致性。要是你有 50 个集群,每个集群都要设个安全策略,你手动去敲 50 次,那非得累吐血不可。Kurator 的统一策略管理架构,就是为了让你“写一次,管全身”。你在主控端定义一个策略,它会自动像血液一样流向所有的子集群。无论你的策略是关于资源限制的,还是关于访问控制的,只要主控端一点头,全舰队立刻同步生效。
2. 拆解分发流程的状态机:看 Kurator 怎么死磕一致性
这是Kurator分发流程的状态机参考图,展示了从请求提交、调度、同步到健康检查与回滚的完整自动化发布生命周期: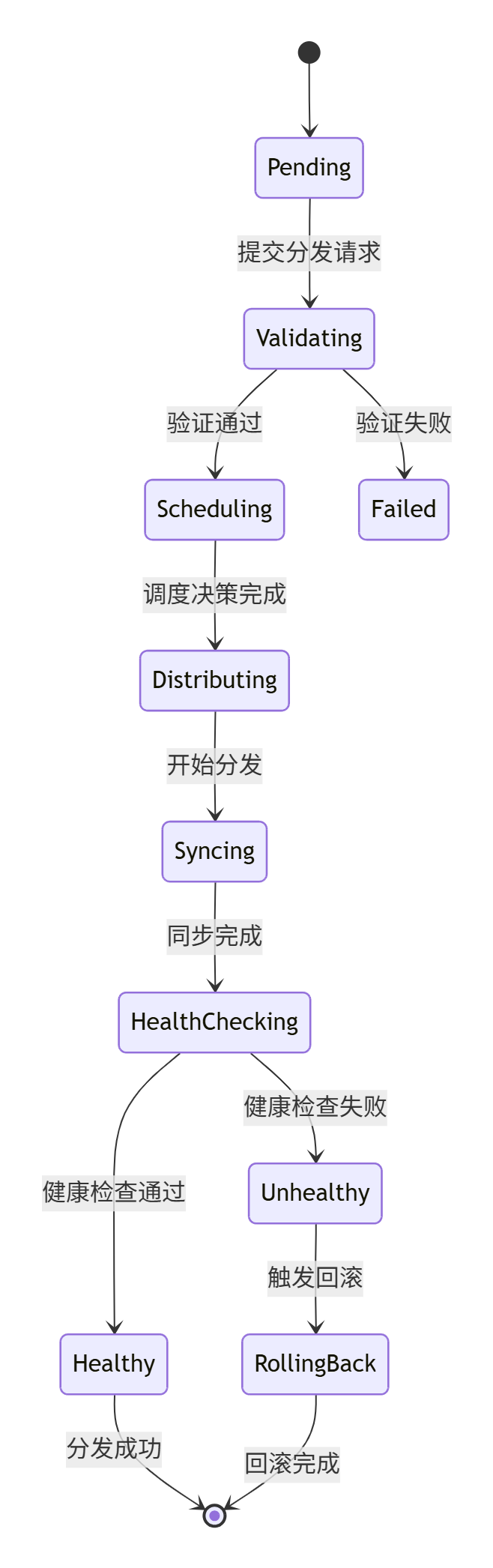
配置发下去了,怎么确定每个集群都收到了且执行成功了?这就涉及到了分发流程的状态机。Kurator 内部维护了一个非常严密的状态机,每个分发任务都会经历“准备、同步中、成功/失败、重试”这些环节。它不是发完就不管了,而是会死磕到底。
下面这段伪代码展示了一个简单的分发任务状态转换逻辑,咱们可以看看它是怎么管理这些状态的:
// 定义几个分发的状态,简单明了
const (
StatePending = "待命"
StateSyncing = "同步中"
StateSuccess = "搞定"
StateFailed = "翻车了"
)
type DistributionTask struct {
ID string
Status string
Retry int
}
// 模拟状态机的流转过程
func MoveState(task *DistributionTask, event string) {
switch task.Status {
case StatePending:
if event == "start" {
task.Status = StateSyncing
fmt.Printf("任务 %s 开始干活了,状态变更为: %s\n", task.ID, task.Status)
}
case StateSyncing:
if event == "done" {
task.Status = StateSuccess
} else if event == "error" && task.Retry < 3 {
task.Retry++
fmt.Printf("任务 %s 报错了,第 %d 次尝试重来...\n", task.ID, task.Retry)
} else {
task.Status = StateFailed
}
}
}
五、 流量调度的高级玩法:路由、AB测试与任务分组 🚀
1. Kurator 的流量路由与 A/B 测试:怎么在多集群里玩灰度
说到云原生,流量控制肯定是重头戏。Kurator 的流量路由能力非常强,它能实现跨集群的请求转发。最香的功能还是它在配置 AB 测试上的表现。你可以定义一套规则,让 10% 的流量去访问集群 A 里的新版本应用,剩下的 90% 还是访问集群 B 的老版本。这种配置 AB 测试的操作,在 Kurator 里也就是改改几行配置的事儿。它通过服务网格或者网关层,把复杂的路由逻辑给屏蔽掉了,你只需要在面上点点划划。
2. Volcano 分组调度:别让复杂的任务把集群拖垮
这是Volcano分组调度参考图,展示了其如何通过整体资源检查与阈值判断,实现批处理作业的成组调度与资源保障: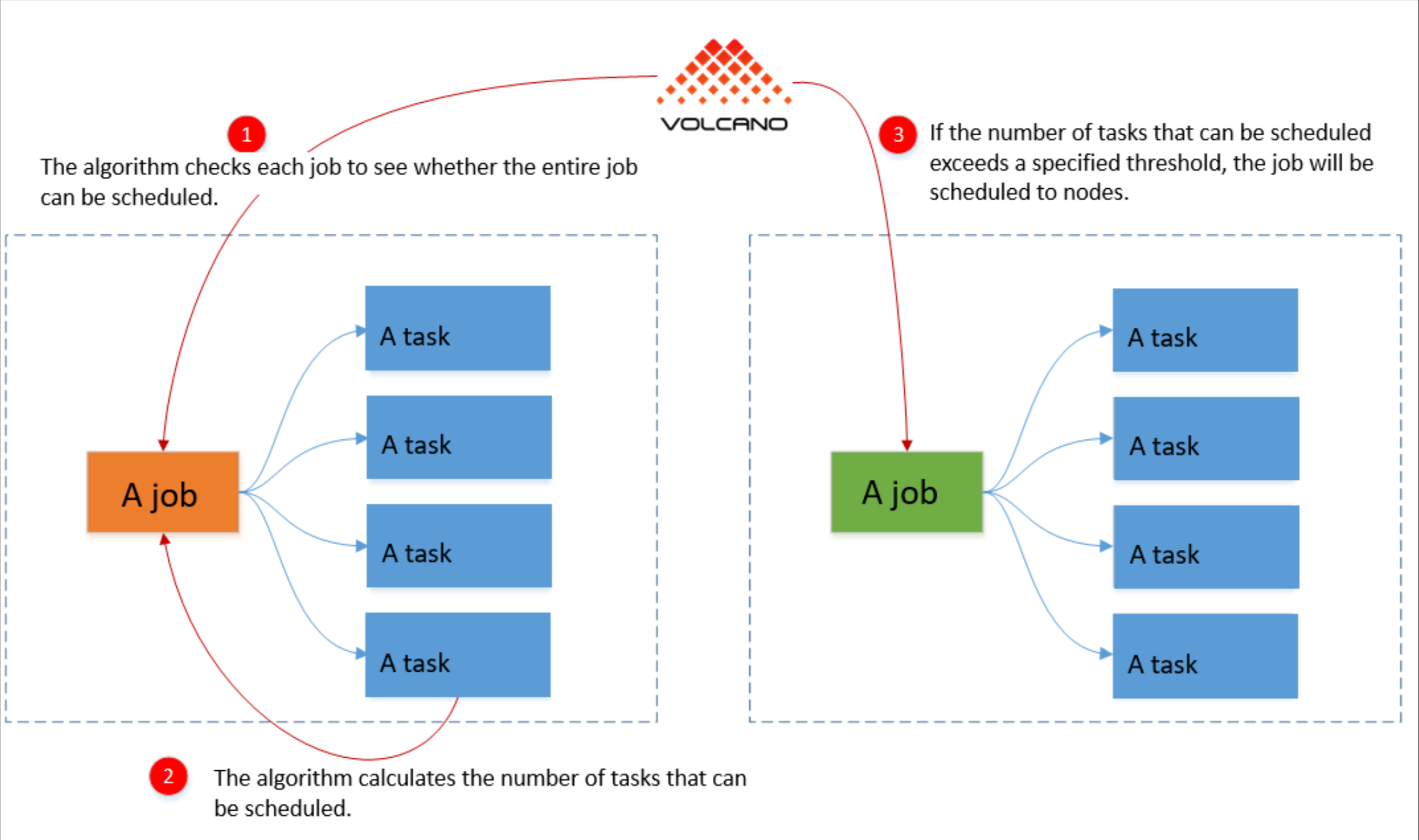
最后咱得聊聊高性能计算。如果你的集群里跑的不只是简单的 Web 应用,还有一堆 AI 训练或者大数据处理任务,那普通的 K8s 调度器可能就有点吃力了。Kurator 引入了 Volcano 分组调度。Volcano 是专门为这种批量任务(Batch Job)设计的。它可以把相关的任务组成一个 Group,要么全跑,要么全不跑(Gang Scheduling),防止资源被互相锁死。这种分组调度能极大地提升多集群环境下的资源利用率,让你的昂贵的算力资源不被白白浪费。
为了让大家看明白流量是怎么分配的,我写一个模拟路由规则的配置片段,大家参考一下:
# 这是一个模拟的流量路由规则,咱们来搞个灰度发布看看
trafficRouting:
serviceName: "my-awesome-app"
routes:
- cluster: "cluster-shanghai-01"
weight: 80 # 80% 的老用户还是走上海一号集群
version: "v1.0"
- cluster: "cluster-beijing-02"
weight: 20 # 抽出 20% 的幸运观众去北京二号集群试用新功能
version: "v2.0-beta"
abTestRules:
- header: "user-type"
match: "vip"
action: "force-to-v2" # VIP 用户必须给安排上最新的 beta 版,咱得宠着
写到最后,其实 Kurator 给我们带来的不只是一个工具,而是一整套管理分布式云原生的新思路。它把那些晦涩难懂的 K8s 底层逻辑,包装成了咱们看得懂、好上手的舰队管理模式。从环境搭建到生命周期管理,从策略分发到高阶流量调度,Kurator 基本上把分布式场景下的痛点都给戳了个遍。如果你正被手里那堆乱七八糟的集群搞得头大,不如真去拉一份代码下来,照着我说的这几块内容钻研一下,保准能让你对云原生管理有不一样的认识。怎么样,要不要现在就去 git clone 试一试?咱们评论区见,有问题随时拍我!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)