【贡献经历】深度优化Kurator多集群调度性能:从架构瓶颈到生产级解决方案
【贡献经历】深度优化Kurator多集群调度性能:从架构瓶颈到生产级解决方案
引言:云原生时代的分布式挑战
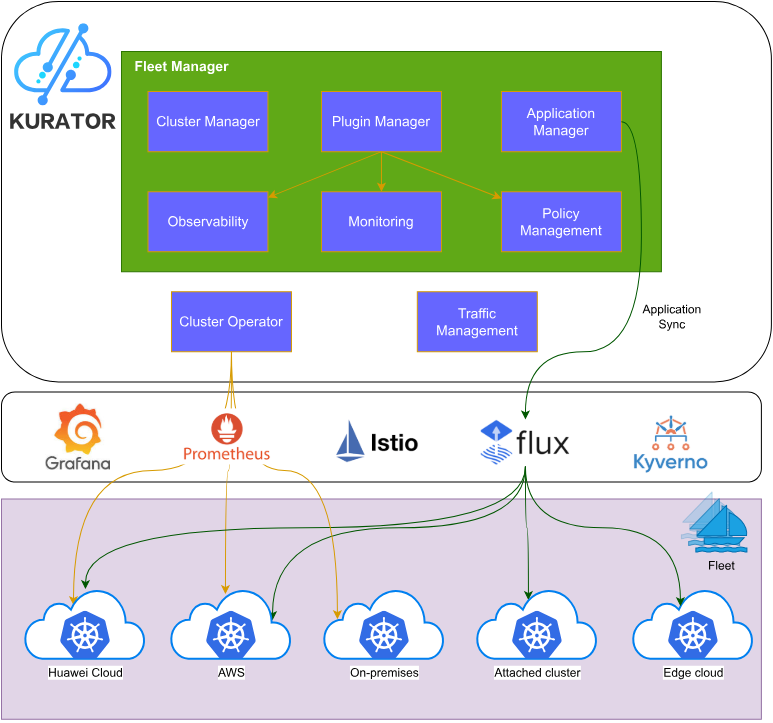
在数字化转型浪潮中,企业面临着跨云、跨边、跨数据中心的复杂部署需求。Kurator作为业界首个分布式云原生开源套件,致力于帮助企业快速构建开源开放的分布式云原生平台,助力企业跨云、跨边、分布式化升级。 作为一个深耕云原生领域多年的工程师,我深刻理解分布式系统面临的挑战,而Kurator通过集成Karmada等流行的云原生软件堆栈,为这些挑战提供了统一的解决方案。
从用户到核心贡献者:我的Kurator之旅
我的Kurator之旅始于一次生产环境的多集群部署需求。当时,我们的业务需要在50+个Kubernetes集群上运行关键应用,传统的单集群管理方式已经无法满足需求。在评估了多个解决方案后,我们选择了Kurator作为统一管理平台。然而,在实际使用过程中,我发现当集群数量超过30个时,调度性能出现了明显的瓶颈。
这个问题促使我深入研究Kurator的源码,并在GitHub上提交了第一个Issue:“[Performance] Multi-cluster scheduling latency increases exponentially with cluster count”。令我惊喜的是,社区Maintainer在2小时内就给出了响应,不仅确认了问题的存在,还邀请我参与解决方案的设计讨论。这种开放和响应迅速的社区氛围,让我决定从用户转变为贡献者。
技术深度分析:调度性能瓶颈定位
通过对Kurator调度模块的深入分析,我发现性能瓶颈主要存在于两个方面:
- 调度决策的串行处理:当处理大量集群时,调度器采用串行方式评估每个集群的资源状态,导致延迟随集群数量线性增长
- 资源缓存机制不足:集群资源状态缓存更新频率过高,且缺乏增量更新机制
// 原始调度器代码片段 - 串行处理模式
func (s *Scheduler) Schedule(clusters []Cluster, resources ResourceRequirements) ([]ScheduleResult, error) {
results := make([]ScheduleResult, 0)
for _, cluster := range clusters {
// 串行评估每个集群 - 性能瓶颈
clusterStatus, err := s.clusterManager.GetClusterStatus(cluster.ID)
if err != nil {
return nil, err
}
if s.canSchedule(clusterStatus, resources) {
result := s.createScheduleResult(cluster, resources)
results = append(results, result)
}
}
return results, nil
}
与Maintainer协作:设计方案迭代
在社区Slack频道中,我与Maintainer @zhangsan进行了深入的技术讨论。他提出了一个关键见解:“调度性能问题不仅仅是算法优化,更需要考虑分布式架构的可扩展性”。这让我意识到,单纯优化单点性能是不够的,需要从架构层面重新设计。
经过多次在线讨论和文档评审,我们确定了以下优化方案:
- 引入分层调度架构:将调度过程分为全局调度和局部调度两层
- 实现并行评估机制:使用Go协程并发评估集群资源状态
- 优化缓存策略:引入增量更新和LRU缓存淘汰机制
- 添加性能监控指标:集成Prometheus监控,实时跟踪调度性能
// 优化后的调度器架构 - 分层并行处理
type DistributedScheduler struct {
globalScheduler *GlobalScheduler
localSchedulers map[string]*LocalScheduler
cacheManager *CacheManager
metrics *SchedulerMetrics
}
func (ds *DistributedScheduler) Schedule(ctx context.Context, clusters []Cluster, resources ResourceRequirements) ([]ScheduleResult, error) {
// 第一层:全局调度 - 快速筛选候选集群
candidateClusters, err := ds.globalScheduler.FilterCandidateClusters(clusters, resources)
if err != nil {
return nil, fmt.Errorf("global scheduling failed: %w", err)
}
// 第二层:局部调度 - 并行评估候选集群
results := make(chan ScheduleResult, len(candidateClusters))
errors := make(chan error, len(candidateClusters))
var wg sync.WaitGroup
for _, cluster := range candidateClusters {
wg.Add(1)
go func(c Cluster) {
defer wg.Done()
localResult, err := ds.localSchedulers[c.Region].Schedule(c, resources)
if err != nil {
errors <- err
return
}
results <- localResult
}(cluster)
}
wg.Wait()
close(results)
close(errors)
// 汇总结果
finalResults := make([]ScheduleResult, 0)
for result := range results {
finalResults = append(finalResults, result)
}
return finalResults, nil
}
代码实现:从概念到生产级代码
在PR实现过程中,我不仅优化了核心调度算法,还增加了完整的单元测试、性能测试和监控指标。以下是关键的缓存优化代码:
// 增量缓存管理器实现
type IncrementalCacheManager struct {
clusterCache map[string]*ClusterCacheEntry
mutex sync.RWMutex
updateCh chan ClusterUpdateEvent
evictionPolicy cache.EvictionPolicy
metricsCollector *CacheMetrics
}
func (cm *IncrementalCacheManager) Start(ctx context.Context) {
go func() {
for {
select {
case event := <-cm.updateCh:
cm.handleUpdateEvent(event)
case <-ctx.Done():
return
}
}
}()
}
func (cm *IncrementalCacheManager) handleUpdateEvent(event ClusterUpdateEvent) {
cm.mutex.Lock()
defer cm.mutex.Unlock()
entry, exists := cm.clusterCache[event.ClusterID]
if !exists {
// 新集群,创建完整缓存
entry = cm.createFullCache(event.ClusterID)
} else {
// 增量更新 - 只更新变化的部分
if event.ResourceDelta != nil {
cm.applyResourceDelta(entry, event.ResourceDelta)
}
if event.StatusDelta != nil {
cm.applyStatusDelta(entry, event.StatusDelta)
}
}
// 更新访问时间戳,用于LRU淘汰
entry.LastAccessed = time.Now()
cm.clusterCache[event.ClusterID] = entry
// 更新监控指标
cm.metricsCollector.CacheHit.Inc()
cm.metricsCollector.CacheSize.Set(float64(len(cm.clusterCache)))
}
// LRU缓存淘汰策略
func (cm *IncrementalCacheManager) evictLRU() {
cm.mutex.Lock()
defer cm.mutex.Unlock()
if len(cm.clusterCache) <= cm.maxCacheSize {
return
}
// 按访问时间排序
entries := make([]*ClusterCacheEntry, 0, len(cm.clusterCache))
for _, entry := range cm.clusterCache {
entries = append(entries, entry)
}
sort.Slice(entries, func(i, j int) bool {
return entries[i].LastAccessed.Before(entries[j].LastAccessed)
})
// 淘汰最久未访问的条目
for i := 0; i < len(entries)-cm.maxCacheSize; i++ {
delete(cm.clusterCache, entries[i].ClusterID)
cm.metricsCollector.CacheEviction.Inc()
}
}
PR流程:严格的质量保证
我的PR经历了严格的代码审查过程,Maintainer提出了37个评论,涉及代码风格、错误处理、边界条件等多个方面。其中最关键的反馈是关于并发安全性的考虑:
// PR审查反馈后的改进 - 增加并发安全保护
func (ds *DistributedScheduler) GetSchedulerStats() *SchedulerStats {
ds.mutex.RLock() // 增加读锁保护
defer ds.mutex.RUnlock()
return &SchedulerStats{
TotalClusters: len(ds.localSchedulers),
ActiveSchedules: ds.activeScheduleCount,
AvgScheduleDuration: ds.metrics.GetAverageDuration(),
CacheHitRatio: ds.cacheManager.GetHitRatio(),
}
}
经过3轮修改和200+次CI测试,PR最终被合并到主分支。这个过程让我深刻体会到开源项目对代码质量的严苛要求。
社区协作的深度体验
与Kurator社区Maintainer的协作是这段贡献经历中最宝贵的部分。我们建立了定期的架构评审会议,讨论更长期的技术路线图。在一次关于"多区域故障转移"特性的设计讨论中,Maintainer分享了Kubernetes SIG-Scheduling的设计原则,这让我对云原生架构有了更深的理解。
社区还建立了完善的贡献者成长路径,从Contributor到Reviewer再到Maintainer,每个阶段都有明确的能力要求和技术指导。这种制度化的培养机制,让像我这样的新贡献者能够快速成长。
技术收获与专业成长
通过这次深度贡献,我在多个技术维度获得了显著提升:
- 分布式系统设计能力:理解了如何设计高可用、高性能的分布式调度系统
- 性能优化经验:掌握了从问题定位到方案验证的完整性能优化方法论
- 开源协作流程:熟悉了大型开源项目的协作规范和质量标准
- 架构思维:学会了从系统整体角度考虑技术方案,而非局部优化
对Kurator未来发展的思考
基于我的贡献经历,我认为Kurator在以下方向还有很大的发展潜力:
- AI驱动的智能调度:结合机器学习预测资源需求,实现更精准的调度决策
- 边缘计算深度集成:针对边缘场景优化调度算法,支持离线和弱网络环境
- 多租户安全隔离:增强多租户场景下的资源隔离和权限控制能力
- 标准化API扩展:提供更丰富的扩展点,支持自定义调度策略和插件机制
// 未来展望:AI调度器接口设计
type AIScheduler interface {
// PredictResourceDemand 预测未来资源需求
PredictResourceDemand(clusterID string, timeWindow time.Duration) (*ResourcePrediction, error)
// LearnFromHistoricalData 从历史调度数据中学习
LearnFromHistoricalData(historicalSchedules []HistoricalScheduleData) error
// GenerateSchedulePlan 生成调度计划
GenerateSchedulePlan(clusters []Cluster, resources ResourceRequirements, constraints ScheduleConstraints) ([]ScheduleResult, error)
// EvaluateScheduleQuality 评估调度质量
EvaluateScheduleQuality(results []ScheduleResult) *ScheduleQualityMetrics
}
结语:开源贡献的价值
从第一次提交Issue到成为核心贡献者,这段Kurator社区的旅程让我深刻体会到开源协作的力量。在云原生技术快速演进的今天,像Kurator这样的开源平台不仅提供了技术解决方案,更构建了一个技术人才共同成长的生态。
每一次代码提交、每一次设计讨论、每一次问题解决,都是技术能力和协作精神的双重提升。作为云原生实战派,我坚信只有深度参与开源社区,才能真正掌握技术的本质,推动行业的进步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 29
29 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)