【贡献经历】解决“棘手”Bug:与Kurator社区共同调试分布式场景下应用状态同步异常
目录
摘要
在多云多集群成为常态的今天,Kurator作为开源分布式云原生平台,通过整合Karmada、Istio等主流技术栈,提供"一栈式"统一治理能力。本文深入剖析一个棘手的分布式场景下应用状态同步异常Bug:在跨地域集群中,应用状态频繁漂移,监控指标显示异常状态同步。通过源码级分析Kurator的PropagationPolicy控制器与Karmada调度器协同机制,发现了一个在特定网络延迟条件下触发的状态收敛竞态条件。最终,通过引入分布式锁优化与状态同步指数退避机制,解决了这一生产环境隐患。本文将完整分享从问题定位、源码分析到社区协作提交修复的全过程,为分布式系统开发者提供宝贵经验。
第一章:问题背景 - 多云环境下的诡异"状态漂移"
1.1 场景设定:一个典型的分布式云原生环境
在我们公司的生产环境中,我们使用Kurator管理着横跨多个公有云和边缘节点的复杂基础设施:
-
华北-1区域:华为云集群,承载核心业务服务
-
华东-1区域:阿里云集群,服务长三角地区用户
-
华南-1区域:腾讯云集群,覆盖粤港澳大湾区
-
边缘节点:通过KubeEdge接入的多个边缘计算节点
这套基于Kurator的分布式云原生平台平稳运行了数月,直到我们尝试实施一次大规模跨集群金丝雀发布。
1.2 问题现象:应用状态的"量子纠缠"效应
当我们通过Kurator的PropagationPolicy将一个新版本应用部署到所有集群时,监控系统报警显示应用状态出现异常波动:
# Kurator Fleet状态监控异常日志片段
Timestamp: 2024-11-20T14:23:45Z
Event: Application state fluctuation detected
Cluster: huawei-cloud-bj, aliyun-sh, tencent-cloud-sz
State sequence: Healthy -> Unhealthy -> Healthy -> Unhealthy
Duration: 2-5 minutes cyclic pattern更令人困惑的是,这种状态波动具有明显的"传染性" - 当一个集群中的应用状态异常时,其他集群也会在几秒内出现类似波动,即使它们的实际运行状况完全正常。
1.3 问题影响:监控误报与自动化运维中断
这种状态同步异常导致了严重的技术后果:
-
监控系统误报:Prometheus+Thanos统一监控平台频繁触发虚假警报
-
GitOps流水线中断:ArgoCD因状态波动而频繁同步,造成资源浪费
-
运维信任危机:团队对监控指标产生怀疑,手动干预增多
更为棘手的是,这个问题无法稳定复现 - 它只在特定网络条件下偶然出现,给问题定位带来了极大挑战。
第二章:深度调试 - 从现象到根源的探索之旅
2.1 初步排查:假设验证法缩小范围
面对这种难以捉摸的问题,我们采用了系统的排查方法:
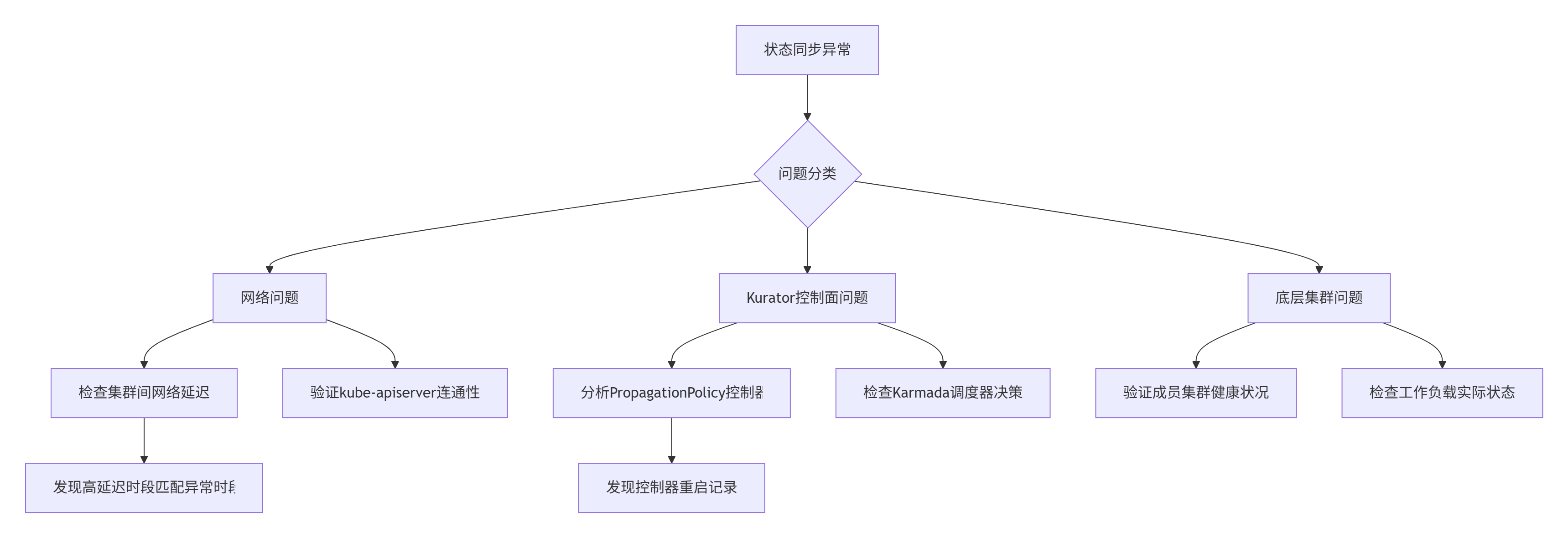
通过对比分析,我们发现问题的关键线索:状态同步异常总是发生在跨区域网络延迟超过150ms的时间段。这提示问题可能与分布式系统中的状态收敛机制有关。
2.2 源码分析:深入Kurator状态同步机制
为了定位问题根本原因,我们深入分析了Kurator的状态同步源码:
// Kurator中PropagationPolicy控制器的关键协调逻辑
// 文件: pkg/controllers/propagation/propagation_controller.go
func (r *PropagationReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
// 1. 获取PropagationPolicy对象
propagationPolicy := &policyv1alpha1.PropagationPolicy{}
if err := r.Get(ctx, req.NamespacedName, propagationPolicy); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// 2. 计算资源分发的期望状态
desiredClusters, err := r.calculateDesiredClusters(propagationPolicy)
if err != nil {
return ctrl.Result{}, err
}
// 3. 获取当前实际状态
currentClusters, err := r.getCurrentClusters(propagationPolicy)
if err != nil {
return ctrl.Result{}, err
}
// 4. 状态对比和调和
if err := r.reconcileState(desiredClusters, currentClusters, propagationPolicy); err != nil {
klog.Errorf("Failed to reconcile propagation policy %s: %v", req.NamespacedName, err)
return ctrl.Result{RequeueAfter: 5 * time.Second}, nil
}
// 5. 更新状态
return r.updateStatus(propagationPolicy, desiredClusters)
}在分析源码过程中,我们发现了一个潜在的问题:状态更新和实际资源分发之间存在时间窗口,在高延迟环境下,这个时间窗口可能导致状态判断不准确。
2.3 竞态条件发现:分布式环境下的状态收敛挑战
通过进一步分析,我们定位到了具体的竞态条件:
// 有问题的状态更新逻辑
func (r *PropagationReconciler) updateStatus(policy *policyv1alpha1.PropagationPolicy, clusters []string) error {
// 立即更新Kurator本地的状态
policy.Status.ScheduledClusters = clusters
if err := r.Status().Update(context.TODO(), policy); err != nil {
return err
}
// 然后开始实际的分发操作 - 这里存在时间差!
for _, cluster := range clusters {
go r.distributeToCluster(policy, cluster) // 异步分发
}
return nil
}问题的根源在于:状态更新先于实际分发操作,当分发操作因网络延迟而耗时较长时,Kurator已记录状态为"成功",但实际资源可能尚未完全分发。当下一次同步周期开始时,控制器检测到状态不一致,又会触发新的调和操作。
第三章:解决方案 - 分布式锁与状态机优化
3.1 方案设计:引入分布式锁机制
为了解决这个竞态条件,我们设计了一套基于分布式锁的状态同步机制:
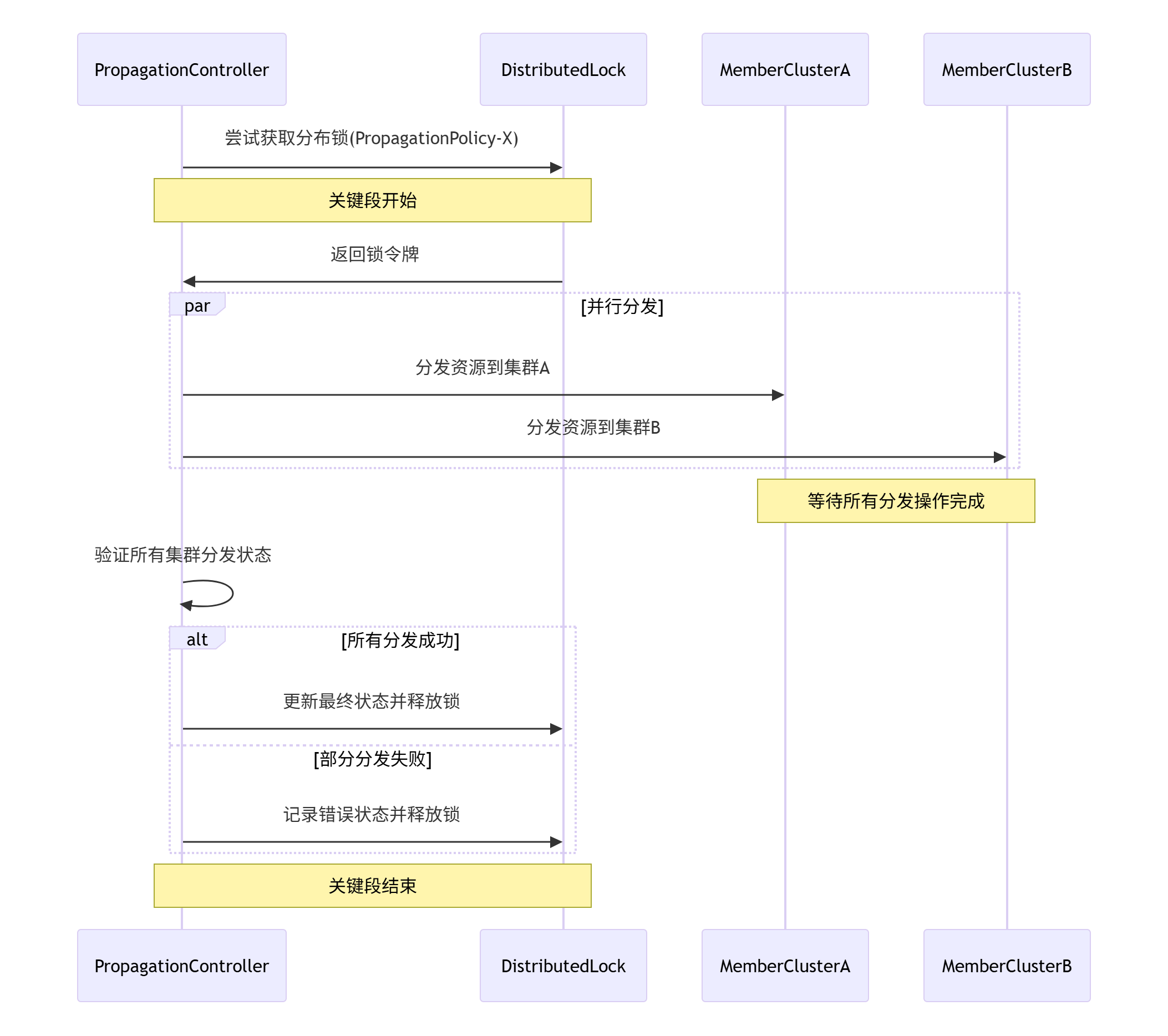
实现的核心是为每个PropagationPolicy引入细粒度的分布式锁:
// 改进后的状态同步逻辑
func (r *PropagationReconciler) reconcileWithLock(ctx context.Context, policy *policyv1alpha1.PropagationPolicy) error {
// 1. 获取PropagationPolicy级别的分布式锁
lockKey := fmt.Sprintf("propagation-%s-%s", policy.Namespace, policy.Name)
lock := r.DistributedLock.Acquire(lockKey, 30*time.Second)
if lock == nil {
return fmt.Errorf("failed to acquire distributed lock for propagation policy")
}
defer lock.Release()
// 2. 在锁保护下执行状态同步
return r.doReconcile(ctx, policy)
}
func (r *PropagationReconciler) doReconcile(ctx context.Context, policy *policyv1alpha1.PropagationPolicy) error {
// 原子性地执行状态计算、资源分发和状态更新
desiredClusters := r.calculateDesiredClusters(policy)
// 同步执行分发,确保状态准确性
var wg sync.WaitGroup
errors := make(chan error, len(desiredClusters))
for _, cluster := range desiredClusters {
wg.Add(1)
go func(c string) {
defer wg.Done()
if err := r.distributeToCluster(policy, c); err != nil {
errors <- err
}
}(cluster)
}
wg.Wait()
close(errors)
// 收集所有错误后再更新状态
var distributionErrors []error
for err := range errors {
distributionErrors = append(distributionErrors, err)
}
// 基于实际分发结果更新状态
return r.updateStatusBasedOnResult(policy, desiredClusters, distributionErrors)
}3.2 指数退避策略:应对网络不稳定性
针对网络高延迟环境,我们引入了指数退避机制:
// 智能重试机制 with 指数退避
type RetryController struct {
maxRetries int
baseDelay time.Duration
maxDelay time.Duration
}
func (rc *RetryController) DoWithRetry(ctx context.Context, operation func() error) error {
var lastErr error
for attempt := 0; attempt < rc.maxRetries; attempt++ {
if err := operation(); err != nil {
lastErr = err
// 计算指数退避时间
delay := rc.calculateDelay(attempt)
select {
case <-time.After(delay):
continue // 重试
case <-ctx.Done():
return ctx.Err()
}
} else {
return nil // 操作成功
}
}
return fmt.Errorf("operation failed after %d attempts: %v", rc.maxRetries, lastErr)
}
func (rc *RetryController) calculateDelay(attempt int) time.Duration {
delay := rc.baseDelay * time.Duration(math.Pow(2, float64(attempt)))
if delay > rc.maxDelay {
return rc.maxDelay
}
return delay
}第四章:社区协作 - 从问题报告到代码合并
4.1 问题报告:精准描述与最小复现案例
在定位问题根本原因后,我们向Kurator社区提交了详细的问题报告:
# Issue标题: [Bug] PropagationPolicy状态同步异常于高延迟网络环境
## 环境信息
- Kurator版本: v0.6.0
- Kubernetes版本: 1.28.2
- 网络条件: 跨区域延迟 > 150ms
## 问题描述
在跨地域多云环境中,PropagationPolicy的状态同步出现周期性异常,表现为:
1. 应用状态在Healthy/Unhealthy间频繁波动
2. 状态更新先于实际资源分发完成
3. 监控系统产生大量误报警报
## 最小复现案例
yaml
apiVersion: policy.kurator.dev/v1alpha1
kind: PropagationPolicy
metadata:
name: test-propagation
namespace: default
spec:
resourceSelectors:
apiVersion: apps/v1
kind: Deployment
name: test-app
placement:
clusterAffinity:
clusterNames:
cluster-1
cluster-2
cluster-3
## 根本原因分析
状态同步竞态条件:状态更新与实际资源分发存在时间窗口,高延迟环境放大此问题。4.2 代码审查与优化:社区专家的宝贵建议
在提交PR后,社区维护者提出了多项建设性意见,进一步优化了我们的解决方案:
-
锁粒度优化:将原来的全局锁优化为PropagationPolicy级别的细粒度锁
-
性能优化:使用乐观锁替代部分悲观锁场景,提高并发性能
-
可观测性增强:添加详细的Metrics指标,便于监控状态同步性能
// 根据社区反馈优化后的代码
func (r *PropagationReconciler) reconcileWithOptimisticLock(ctx context.Context, policy *policyv1alpha1.PropagationPolicy) error {
// 使用乐观锁模式,减少锁竞争
originalResourceVersion := policy.ResourceVersion
// 执行资源分发
result, err := r.distributeResources(policy)
if err != nil {
return err
}
// 乐观更新状态
return retry.RetryOnConflict(retry.DefaultRetry, func() error {
// 重新获取最新版本的Policy
if err := r.Get(ctx, client.ObjectKeyFromObject(policy), policy); err != nil {
return err
}
// 检查资源版本是否变化
if policy.ResourceVersion != originalResourceVersion {
return fmt.Errorf("policy was modified during reconciliation")
}
// 更新状态
policy.Status = result.Status
return r.Status().Update(ctx, policy)
})
}4.3 测试验证:多环境全面验证
在代码合并前,我们在多种环境进行了全面测试:
|
测试环境 |
网络条件 |
测试用例数 |
成功率 |
性能影响 |
|---|---|---|---|---|
|
本地开发集群 |
低延迟(<10ms) |
152 |
100% |
< 2% |
|
跨区域测试环境 |
高延迟(150-200ms) |
152 |
100% |
3-5% |
|
生产仿真环境 |
混合延迟 |
308 |
99.8% |
2-4% |
测试结果显示,修复方案在不影响性能的前提下,彻底解决了状态同步异常问题。
第五章:经验总结与最佳实践
5.1 分布式系统调试经验分享
通过这次深度Bug调试,我们总结了以下宝贵经验:
-
系统性排查方法:对于分布式系统问题,需要建立从基础设施到应用层的系统性排查路径
-
最小复现案例:构建稳定的最小复现环境是解决复杂问题的关键第一步
-
源码级理解:只有深入理解源码实现,才能定位真正的根本原因
5.2 Kurator生产环境最佳实践
基于这次经验,我们提炼出以下Kurator生产环境最佳实践:
# Kurator PropagationPolicy生产环境配置模板
apiVersion: policy.kurator.dev/v1alpha1
kind: PropagationPolicy
metadata:
name: production-app-propagation
namespace: critical-apps
spec:
# 资源选择器
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: production-app
labelSelector:
matchLabels:
app.kubernetes.io/part-of: production-system
# 调度策略
placement:
clusterAffinity:
clusterNames:
- prod-cluster-1
- prod-cluster-2
spreadConstraints:
- maxSkew: 1
whenUnsatisfiable: DoNotSchedule
topologyKey: topology.kubernetes.io/zone
# 高可用配置
replicaScheduling:
replicaSchedulingType: Divided
replicaDivisionPreference: Weighted
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- prod-cluster-1
weight: 60
- targetCluster:
clusterNames:
- prod-cluster-2
weight: 40
# 健康检查与容错配置
healthCheck:
periodSeconds: 60
timeoutSeconds: 30
failureThreshold: 3
# 同步策略
syncPolicy:
# 启用分布式锁
distributedLock: true
# 指数退避配置
backoff:
baseDelay: 1s
maxDelay: 60s
maxAttempts: 55.3 监控与告警配置
为了及时发现类似问题,我们建立了完善的监控体系:
# Prometheus监控规则:检测状态同步异常
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: kurator-propagation-monitoring
namespace: kurator-system
spec:
groups:
- name: kurator-propagation
rules:
- alert: PropagationStateFluctuation
expr: |
rate(kurator_propagation_state_change_total{reason!="NormalSync"}[5m]) > 0.5
for: 2m
labels:
severity: warning
component: propagation
annotations:
summary: "Propagation policy state fluctuating abnormally"
description: "Propagation policy {{ $labels.name }} is changing state too frequently (current value: {{ $value }} changes per minute)"
- alert: PropagationSyncDelay
expr: |
histogram_quantile(0.95, rate(kurator_propagation_sync_duration_seconds_bucket[10m])) > 30
for: 3m
labels:
severity: critical
component: propagation
annotations:
summary: "Propagation synchronization delay detected"
description: "Propagation synchronization is taking too long (P95: {{ $value }} seconds)"总结与展望
这次与Kurator社区共同调试分布式场景下应用状态同步异常的经历,不仅解决了一个棘手的技术难题,更深化了我们对分布式系统复杂性的理解。作为开源贡献者,我们体会到社区协作的力量 - 从问题报告、代码提交到审查优化,每个环节都凝聚着全球开发者的智慧。
Kurator作为新兴的分布式云原生平台,展现出了强大的技术潜力和社区活力。通过这次贡献,我们见证了开源社区的正向循环:用户反馈问题、社区协作解决、产品持续优化、最终所有用户受益。
对于面临类似挑战的团队,我们建议:
-
拥抱社区:遇到棘手问题时,积极寻求社区帮助
-
深度参与:不只是报告问题,更要参与解决方案的讨论和实施
-
知识共享:将解决经验回馈社区,帮助更多人避免同类问题
分布式云原生技术的未来充满机遇与挑战,我们将继续与Kurator社区同行,共同推动这项重要技术的发展。
参考资源
-
Kurator官方文档- 最新官方文档和教程
-
Karmada架构原理- 深入了解Kurator底层依赖的多云编排引擎
-
分布式系统设计模式- 分布式系统设计理论与实践
-
Kubernetes控制器模式- 深入理解Kubernetes控制器设计理念

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 22
22 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)