【前瞻创想】Kurator·云原生实战派:从“一站式集成”走向分布式云原生操作系统!
一、换个视角看 Kurator:不是“多集群面板”,而是一层“分布式内核”
如果说上一篇【探索实战】更多是站在“使用者 + 落地实践”的视角,这次我们换个角度——
站在“架构师 + 开源参与者”的视角,去拆 Kurator 的技术底座和前瞻方向。
Kurator 在官方介绍里被定义为:
一个开源的分布式云原生平台,帮助用户构建自己的分布式云原生基础设施,加速企业数字化转型。
更具体一点:
它不是再造一套 Kubernetes,而是站在 Kubernetes / Istio / Prometheus / FluxCD / KubeEdge / Volcano / Karmada / Kyverno 等一整套云原生栈肩膀上,在上面加了一层“统一的、分布式的控制平面”。
从这个视角看:
-
Kubernetes ≈ 单集群的“操作系统内核”;
-
各云厂商托管 K8s + 自家周边能力 ≈ 不同“发行版”;
-
而 Kurator 更像是“多云多集群的统一内核 + 管理平面”:
- 它不替代具体云厂商的计算存储网络;
- 而是在它们之上,提供统一的资源编排、调度、流量、监控、策略等能力。
这篇文章会重点围绕三件事展开:
- 逐个拆解 Kurator 集成的那些“明星开源项目”到底解决什么问题;
- 分析 Kurator 在这些项目之上的“二次创新”——它到底做了哪些统一和抽象;
- 站在未来 3~5 年的时间尺度,聊聊“分布式云原生”还能往哪儿走,Kurator 可以怎样演进。
目标是:
让你不只是“会用 Kurator”,还可以从架构与社区角度,判断它适不适合你的下一代平台规划。✨
正如如下封面所言的那样:

二、Kurator 集成生态图谱:每一个组件背后的问题域
先不急着看 Kurator 本身,我们先把它“站在谁的肩膀上”捋清楚。根据官网与仓库说明,Kurator 集成了多种 CNCF 生态项目:
- Kubernetes:集群与工作负载编排基础;
- Istio:服务网格与流量治理;
- Prometheus + Thanos + Grafana:监控与长周期指标存储和可视化;
- FluxCD / GitOps 能力:声明式应用分发与持续交付;
- Karmada:多集群调度与资源编排;
- KubeEdge:云边协同与边缘节点治理;
- Volcano:面向批处理和 AI 任务的队列式调度器;
- Kyverno:策略治理与安全基线管理。
从问题域拆解一下,每个项目对应的“世界缺口”大致是:
| 项目 | 典型解决的问题 |
|---|---|
| Kubernetes | 单集群容器编排,Pod/Service/Deployment 等基础对象管理 |
| Istio | 服务间的可观测 / 熔断 / 灰度 / 安全通信,特别适合微服务与多集群 Mesh |
| Prometheus | 指标采集与时间序列存储 |
| Thanos | 多集群 / 多 Prometheus 的集中查询、长期存储 |
| FluxCD | 让 Git 成为“真实状态源”的 GitOps 引擎 |
| Karmada | 把多个 K8s 集群的资源调度成“逻辑一体”的多集群编排 |
| KubeEdge | 解决边缘节点弱网、离线场景的应用与设备管理 |
| Volcano | 批处理 / AI 作业按队列调度,抢占、Gang 调度等高级功能 |
| Kyverno | 用 YAML 写策略,做合规 / 准入 / 配置模板等 |
Kurator 做的事情,可以理解为:
它接受“多云 + 多集群 + 多边 + 多种负载”的现实,然后基于这些基础组件,
再往上加了一层“统一的、Fleet 维度的抽象”,把原本“点状孤立”的能力变成“纵向贯通”的平台。
三、Kurator 的关键创新点:统一抽象而不是“再做一套 UI”
从官方文档、Roadmap、Release Note 来看,Kurator 的关键创新集中在几个方向:
- 以 Fleet 为中心的统一管理模型;
- 把“应用分发 + 流量策略 + 监控 + 策略”组合成一个分布式控制平面;
- 在多集群维度支持现代发布模型:灰度、A/B、蓝绿等统一发布。
下面我们聚焦几个核心点展开说,并穿插一些代码示例。
所以说,可以去体验下:
四、能力一:以 Fleet 抽象“成组集群”的管理单元
4.1 为什么需要 Fleet 抽象?
过去我们很多“多集群操作”是这样的:
- 要在 10 个集群里部署 Prometheus?写 10 份 values 或脚本;
- 要在 3 个 Region 做同一套服务?手动在 3 套 kubeconfig 上各 deploy 一次;
- 要对一批集群开启同一策略?一顿 copy & paste。
本质问题在于:
你缺少一个“成组管理”的一等公民概念。
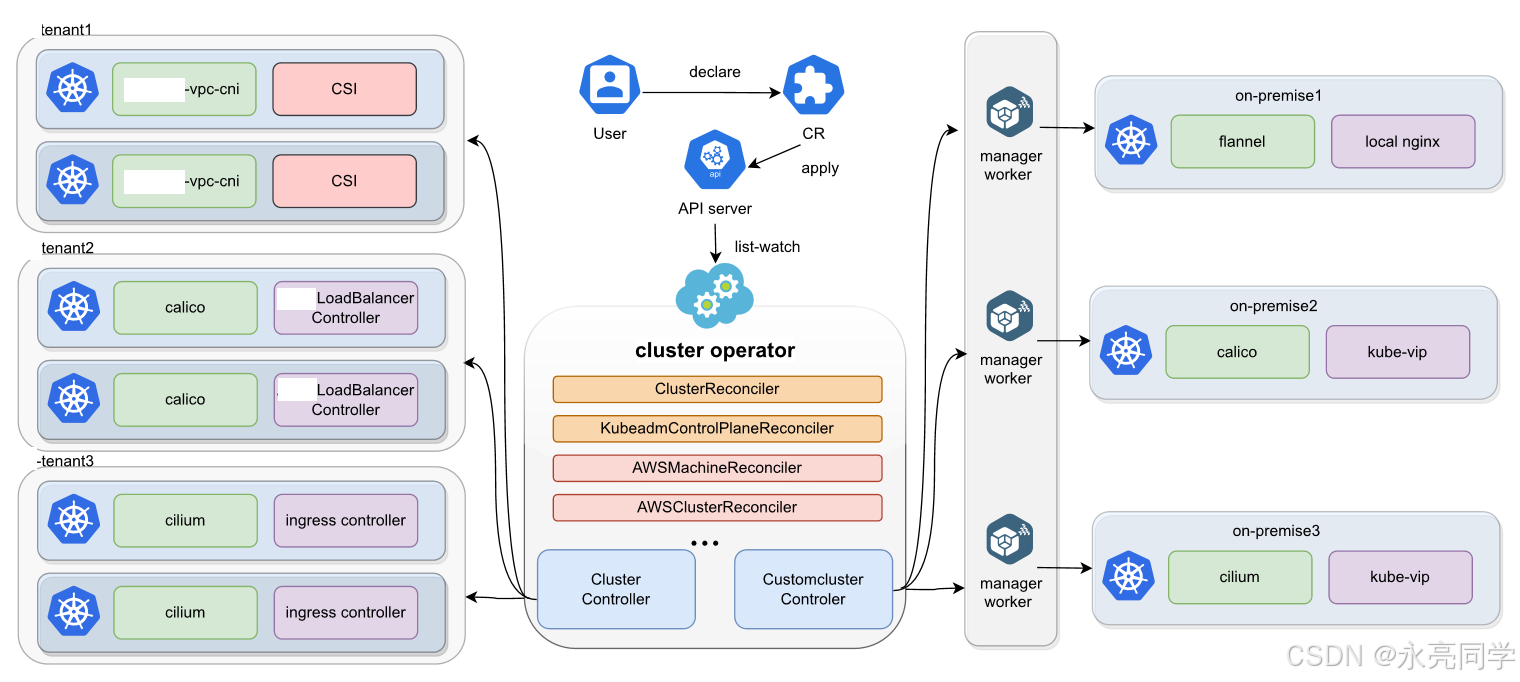
Kurator 引入 Fleet 概念,把一组具备某种共性的集群(同地域 / 同环境 / 同业务)当成一个逻辑对象来治理。
4.2 一个简化的 Fleet 示例(代码)
下面是一个抽象的 Fleet CR 样例(示例字段为说明用法,非严格对照官方 schema):
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: fleet-global-prod
namespace: kurator-system
spec:
# 被纳管的集群列表,可以是 AttachedCluster / ManagedCluster 等
clusters:
- name: prod-cn-north
kind: AttachedCluster
- name: prod-cn-south
kind: AttachedCluster
- name: prod-ap-sg
kind: AttachedCluster
# Fleet 维度启用的一些插件能力
plugin:
metric:
thanos:
objectStoreConfig:
secretName: thanos-objstore
policy:
kyverno:
podSecurity:
standard: restricted
validationFailureAction: Audit
traffic:
istio:
enableMultiClusterMesh: true
思路可以归纳为一句话:
“我声明这几个集群是一支舰队(Fleet),
再声明这支舰队统一需要哪些能力(监控、策略、流量等),
剩下的下发部署和联动由 Kurator 自动完成。”
这就是“分布式云原生操作系统”的味道:你定义需求,Kurator 帮你在各集群里“铺开”。
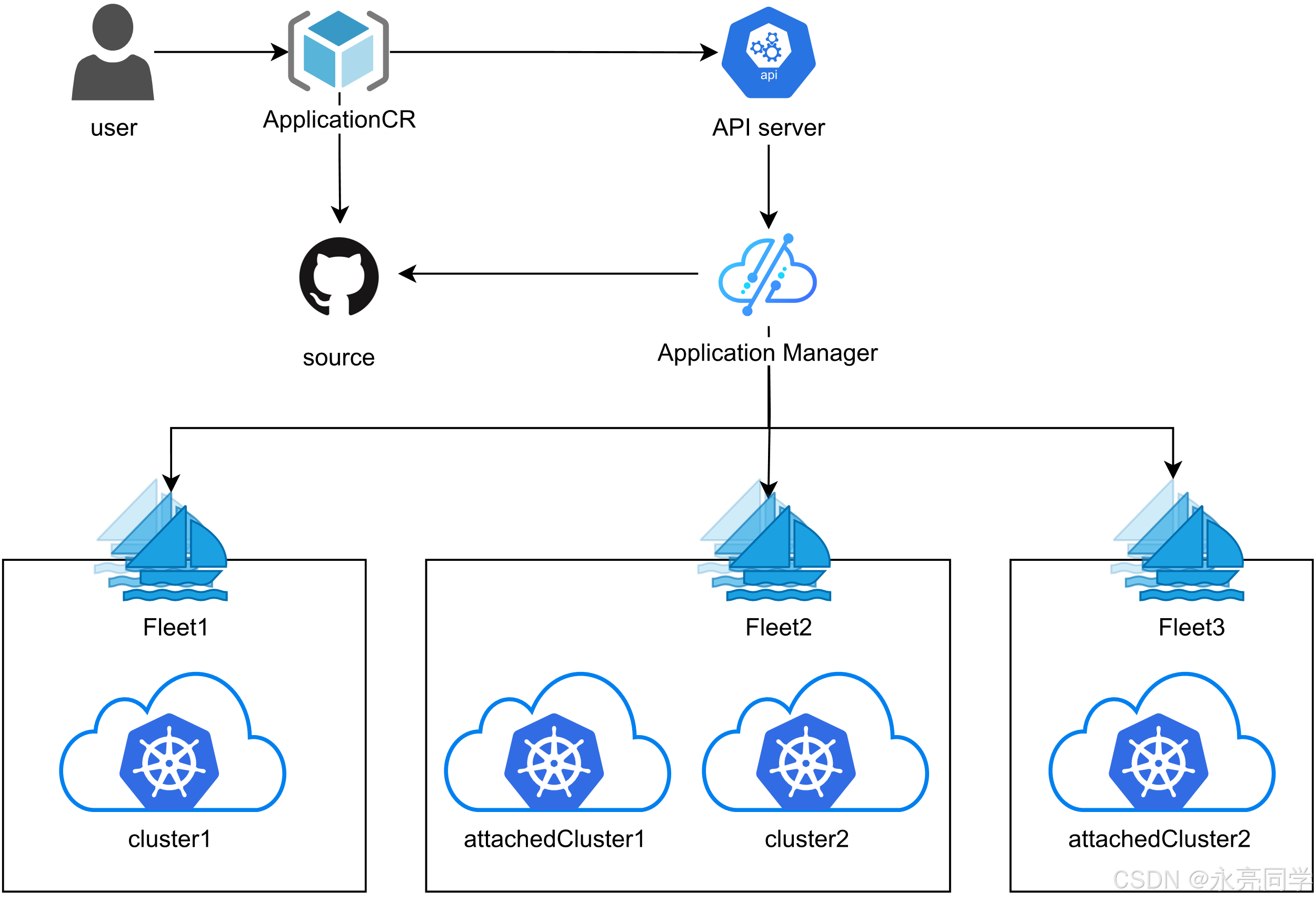
当然,你也可以结合如下架构图进行分析:
五、能力二:在集成项目之上做“统一编排”和“分布式发布”
这一节我们从几个典型能力出发,看看 Kurator 在已有项目之上的“加法”。
5.1 基于 FluxCD 的多集群 GitOps:让 Git 真正变成“全局真实源”
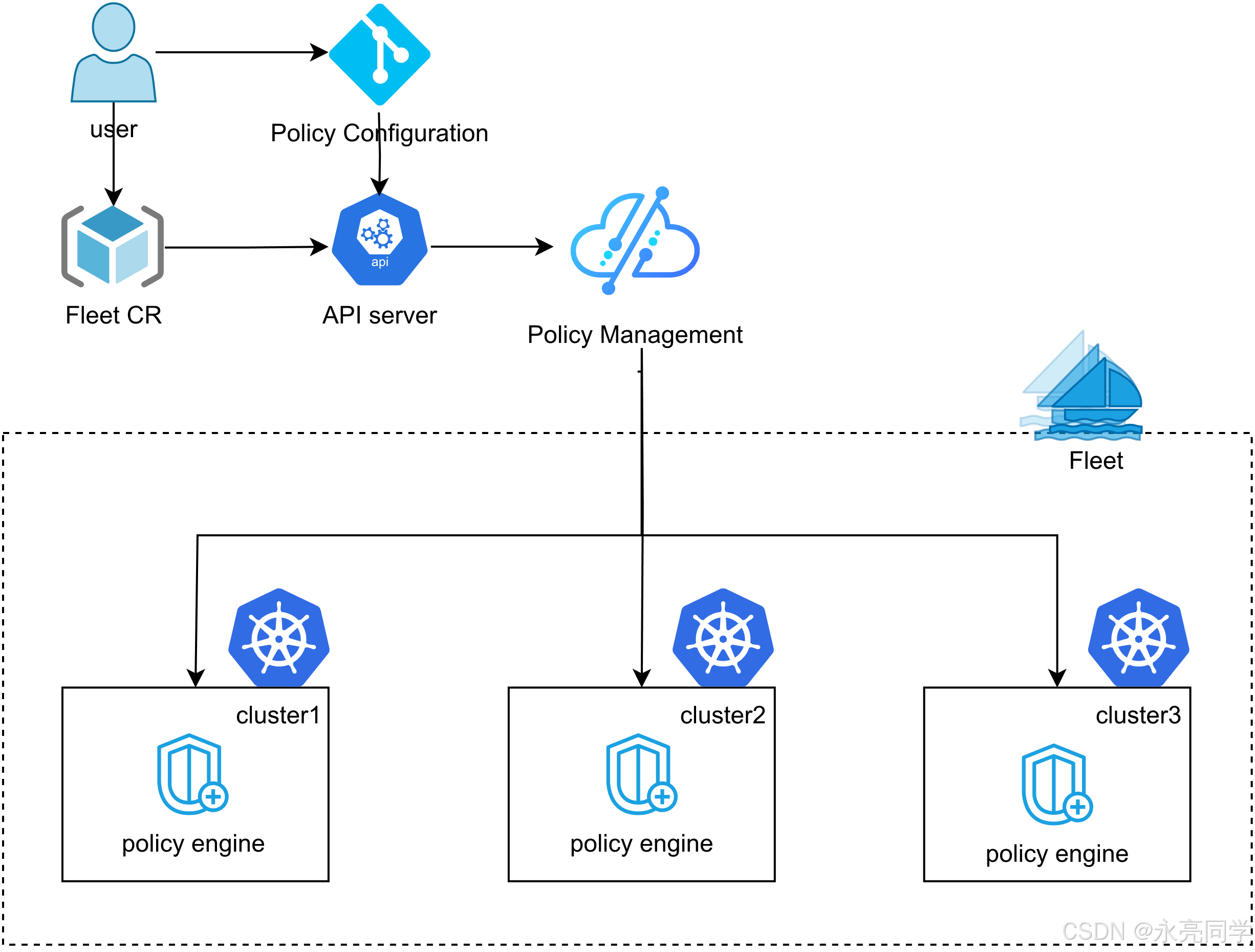
Kurator 自身并不重新造 GitOps 轮子,而是基于 FluxCD/类似能力封装了一套 多集群应用分发模型。v0.4.0 版本开始,引入了基于 Fleet + GitOps 的统一应用分发能力。
5.1.1 一个多集群 Application 示例
下面是一个虚构的 Application CR,用来把 payment-service 分发到全球多个生产集群:
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: payment-service-global
namespace: app-system
spec:
source:
git:
url: https://github.com/example-org/payment-platform-config.git
ref:
branch: main
interval: 1m
timeout: 60s
# 同一个 Git 仓库,可以面向多个 Fleet 使用不同 Overlay
rollouts:
- name: global-prod-rollout
targetFleet: fleet-global-prod
kustomize:
path: ./overlays/prod
prune: true
interval: 2m
# 不同环境可以继续扩展
- name: staging-rollout
targetFleet: fleet-staging
kustomize:
path: ./overlays/staging
关键点:
- Git 仓库作为唯一事实源;
- Kurator 负责在 Fleet 维度做渲染与分发;
- 多集群应用状态统一由 Kurator 控制器对齐。
在实践中,这个模式直接把“多集群发布”变成了:
“改一次 Git + 看一次 Application 状态”。
对于有几十 / 上百个集群的大型企业,这是极大的心智负担收敛。
再者,大家请看如下架构图:
5.2 跨集群统一发布模型:灰度、A/B、蓝绿一把抓
在 v0.6.0 版本中,Kurator 支持了在 Fleet 中进行统一发布模型,包括 Canary、A/B Testing、Blue/Green 等。
这点非常关键——
过去很多 Mesh 或网关项目都支持灰度与 AB,但大多仍局限于“单集群或者单 Gateway”视角。
Kurator 把它提升到了“多集群统一发布”层面。
5.2.1 一个跨集群 Canary Rollout 示例(代码)
下面是一个概念性的 Rollout CR 示例,描述如何在多个集群中做统一的 Canary 发布(示意结构,字段为说明用途):
apiVersion: rollout.kurator.dev/v1alpha1
kind: FleetRollout
metadata:
name: payment-service-canary
namespace: app-system
spec:
fleetRef:
name: fleet-global-prod
namespace: kurator-system
# 需要进行灰度的目标 Workload
targetRef:
apiVersion: apps/v1
kind: Deployment
name: payment-service
namespace: payment-system
strategy:
type: Canary
canary:
steps:
- setWeight: 10
pause:
duration: 5m
- setWeight: 30
pause:
duration: 10m
- setWeight: 50
pause:
duration: 10m
- setWeight: 100
trafficRouting:
istio:
virtualService:
name: payment-service-vs
namespace: istio-system
# 可以在这里指定分流规则、header 等
# 比如 header: x-user-group: beta
注意,这个 Rollout 是在 Fleet 维度定义的。意味着:
- 同一套灰度策略可以在多个 Region / 多个集群中同步执行;
- 每个集群里的 Istio / Gateway 配置由 Kurator 统一下发和调整;
- 失败回滚可以统一由 Rollout 控制器决策。
这让“分布式发布”从“每个集群写一套”变成了“只写一套 FleetRollout”。
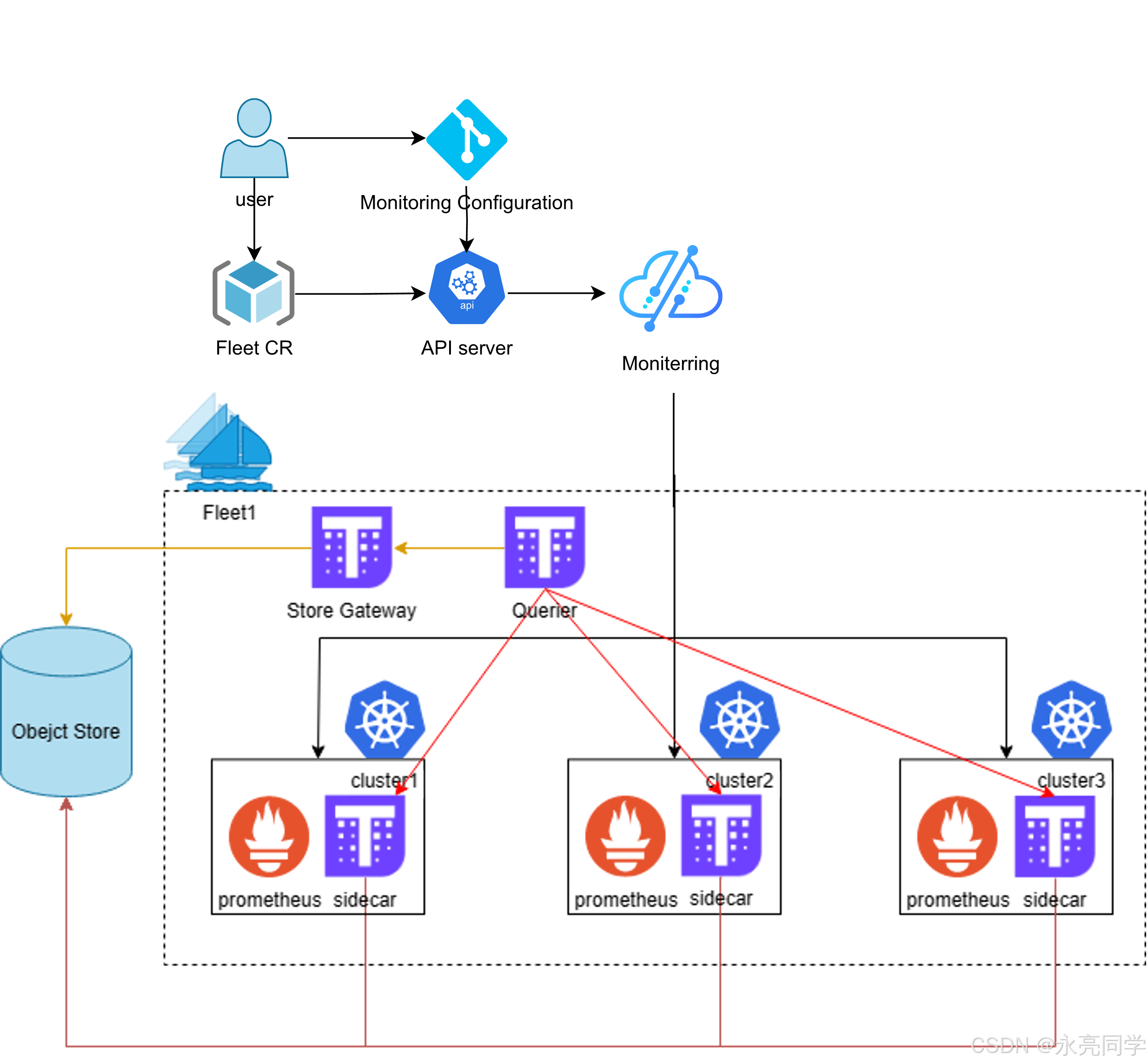
5.3 统一监控:Prometheus + Thanos + Fleet Metric 插件
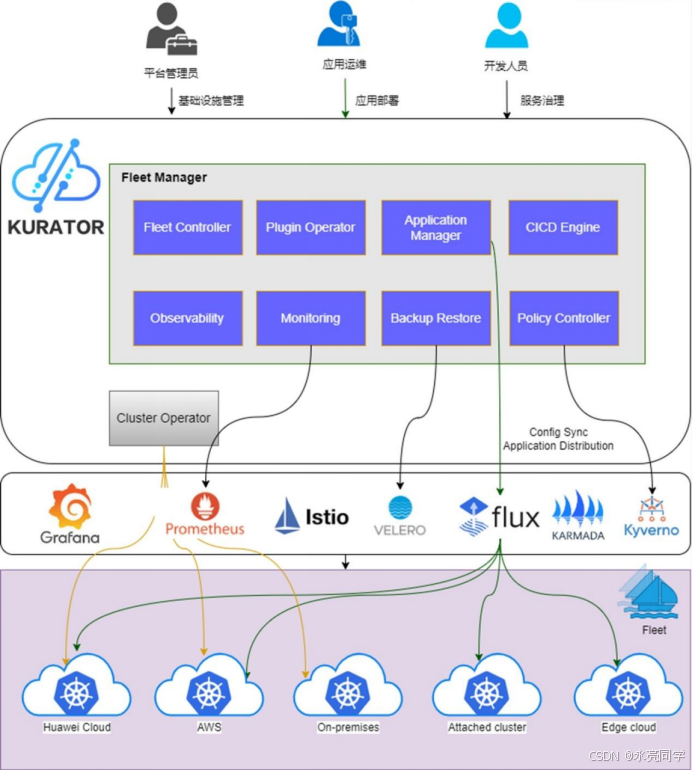
Kurator 在监控方面的设计可以用一句话概括:
“每个集群一套 Prometheus + Sidecar,上层有 Thanos + Grafana 做统一视图,
再用 Fleet 的 metric 插件统一部署和管理。”
5.3.1 Metric 插件配置示例
Kurator 文档中给出了使用 Fleet 管理 metric 插件的示例,大致类似下面这样的结构(这里做了适当简化):
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: fleet-observed
namespace: kurator-system
spec:
clusters:
- name: prod-cn-north
kind: AttachedCluster
- name: prod-cn-south
kind: AttachedCluster
plugin:
metric:
thanos:
objectStoreConfig:
secretName: thanos-objstore
prometheus:
scrapeInterval: 30s
retention: 15d
grafana:
adminUser: "admin"
adminPasswordSecretRef:
name: grafana-admin
key: password
效果就是:
- 在纳管集群里自动铺开 Prometheus + Sidecar;
- 在宿主集群部署 Thanos Query / Store / Query Frontend;
- 完成多集群指标的一体化查询与可视化。
这比“每个集群手动部署 + 自己接 Thanos”要省去一大堆重复劳动。
而且——Kurator 把这件事做成了“一个 CR 的声明”。
正如这张,官方所给的架构图:
5.4 统一策略管理:Kyverno + Fleet 的“多集群安全基线”
在分布式云原生环境里,“统一安全策略”是个很容易被忽略但后期成本极高的点。Kurator 使用 Kyverno 作为策略引擎,并配合 Fleet 做策略集群间分发。
5.4.1 示例:统一禁止特权容器 + 要求资源配额
可以在 Git 中维护一套 Kyverno Policy 模板,然后通过 Kurator/Fleet 分发到多集群。
一个示意性的 Policy(代码):
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: pod-security-baseline
spec:
validationFailureAction: Enforce
background: true
rules:
- name: disallow-privileged
match:
any:
- resources:
kinds:
- Pod
validate:
message: "Privileged containers are not allowed."
pattern:
spec:
containers:
- =(securityContext):
=(privileged): "false"
- name: require-resources
match:
any:
- resources:
kinds:
- Pod
validate:
message: "Container resources.requests/limits are required."
pattern:
spec:
containers:
- resources:
requests:
cpu: "?*"
memory: "?*"
limits:
cpu: "?*"
memory: "?*"
在 Kurator 里,你可以通过 Application 或专门的 Policy 分发 CR,把它发到特定 Fleet,保证“所有生产集群都执行同一个安全基线”。
六、从前瞻视角看:Kurator 未来可以走向哪些方向?
讲完“当下能做什么”,我们再来大胆一点,从趋势角度谈谈 Kurator 作为“分布式云原生平台内核”未来可以演进的几个维度。(以下属于个人判断与期望)
6.1 从“多集群”到“跨栈多运行时”:不仅仅是 K8s
当前 Kurator 的主战场还是 Kubernetes,以及围绕 K8s 的周边项目。
但如果拉长时间看,企业的计算面会越来越多样化:
- K8s 只是其中一种调度器;
- 还会有 Serverless 平台、函数计算、数据库即服务、消息中间件即服务等多种托管运行时;
- 在边缘会有更多形态的轻量运行时(如 K3s、边缘容器/函数甚至 WebAssembly)。
前瞻想象:
-
Kurator 可以扩展出“多运行时插件模型”:
- 把当前的 K8s 集群视作
runtime.k8s; - 未来可以更自然地接入 Serverless/Function 平台、Wasm 运行时等;
- 把当前的 K8s 集群视作
-
Fleet 不再只是“K8s 集群舰队”,而是一个“异构运行时舰队”的抽象。
这样,Kurator 可能从“多集群平台”升级为“多运行时统一调度与编排平台”。
还有这张,技术架构图,结合起来理解:
6.2 AI-Native 的调度与发布:结合 Volcano / Karmada 做“算力视角的 Fleet”
在 AI 大模型 / 推理 / 训练任务成为主流负载后,调度视角正在从“纯 K8s 资源维度(CPU/内存)”转向:
- 支持 GPU / NPU / 显存等资源类型;
- 在线服务与离线训练竞争资源;
- 多 Region 多集群之间做算力流动。
Kurator 已经引入 Volcano 和 Karmada 作为多集群调度与批处理作业的基础能力,这为其做 “AI Native” 平台提供了很好的起点。
前瞻设想:
-
在 Fleet 层增加“算力视图”:
- 把跨集群的 GPU/NPU 资源抽象成一个“算力池”;
- 提供 AI Job 在 Fleet 层的统一队列与配额管理;
-
联合 Volcano 的队列/抢占能力,实现“多集群、跨 Region 的 AI 作业动态调度”;
-
在 Rollout 模型中对“在线推理服务”的灰度发布做原生支持,比如:
- v1/v2 模型同时在多个集群部署;
- 由 Kurator 控制跨集群、跨版本的流量迁移与自动回滚。
这会让 Kurator 在“AI 平台基础设施”赛道上具备天然优势。
6.3 FinOps 和成本可视化:从“资源视角监控”到“成本视角决策”
有了多集群监控之后,下一步的自然需求就是——多云成本分析和 FinOps 体系。
Kurator 已经通过 Thanos + Fleet 解决了“多集群指标聚合”问题。
在此基础上,完全有空间做:
-
不同云厂商、不同 Region 的成本模型接入;
-
将指标数据与账单数据关联,生成“按业务 / 按服务 / 按 Fleet 的使用与成本视图”;
-
帮助平台团队在多云场景下决策:
- 哪些工作负载更适合放在成本较低的 Region;
- 哪些批处理任务可以迁移到更便宜的集群上执行。
简化的设想:
apiVersion: finops.kurator.dev/v1alpha1
kind: CostPolicy
metadata:
name: fleet-prod-finops
spec:
fleetRef:
name: fleet-global-prod
objectives:
- name: reduce-cross-region-cost
target:
maxMonthlyUSD: 50000
strategies:
- preferRegion: ap-southeast-1
- avoidProvider: cloud-x
这类 CR 并不存在于当前版本中,但你能想象——
一旦 Kurator 引入 FinOps 模型,多云平台组会多一个非常硬核的“决策武器”。
6.4 零信任与安全一体化:策略从“静态 YAML”走向“实时评估”
今天 Kurator 通过 Kyverno + Fleet 做统一策略分发。
但“零信任”和“动态策略”会带来越来越复杂的安全治理需求,例如:
- 不只是创建 Pod 时做静态校验,还要结合运行时信息做动态判断;
- 将指标 / 日志 / 审计事件纳入策略判定的一部分;
- 对用户、设备、环境等身份进行统一建模。
一个前瞻方向是:
-
在 Kurator 控制平面加入“策略评估引擎”,
- 将 Kyverno 的 YAML 策略扩展为可组合、可编排的策略图;
- 允许策略引用 Thanos 指标、审计日志、外部身份源等信号;
-
在 Fleet 维度定义“零信任安全域”:
- 不同 Fleet 之间的访问,由 Kurator 统一管理 Service Mesh / 网关 / 策略联动。
这对于跨云、跨 Region 访问控制特别关键。
6.5 Cloud-Edge-Device 一体化:KubeEdge 只是第一步
Kurator 已经将 KubeEdge 纳入生态,用来解决云边协同。
未来更极端的场景是:
- 边缘节点算力越来越强(GPU 直插边缘);
- 设备数量级从“几百个节点”变成“几十万 IoT 设备”;
- 需要从 Kurator 这一层去统一编排“云 + 边 + 端”的应用流转与数据通路。
可以想象的几个增强点:
-
Fleet 中专门引入“EdgeFleet / DeviceFleet”概念:
- 云侧 Fleet 管理数据中心和公有云集群;
- 边缘 Fleet 管理 KubeEdge / 轻量集群;
- Kurator 在两者之间提供“场景化编排”,例如边缘缓存、就近推理等。
-
与数据/流处理项目结合:
- 把 Flink / Spark / Pulsar / Kafka 这类引擎抽象为“数据工作负载”;
- 统一在 Kurator 平台上进行调度和拓扑治理。
这将让 Kurator 有机会成为“端边云一体的编排控制平面”。
如下这张,技术架构图,结合起来理解:
七、站在社区角度:Kurator 如何更好地发展?
从 GitHub 仓库、官方站点以及社区文章来看,Kurator 的开源节奏和文档建设在逐步完善:
- 仓库中有清晰的
README、ROADMAP、CONTRIBUTING等; - 文档网站对 Fleet、Metric 插件、统一应用分发等能力有具体教程;
- 版本发布内容会强调重要特性(比如统一应用发布模型、Canary 发布等)。
从一个“潜在贡献者”的角度,我个人对 Kurator 社区有几点期待:
-
更多“场景化”的官方样例仓库
比如提供几个完整的 Demo 仓库:
kurator-demo-ecommerce:完整电商系统在多集群 + 多 Region 的部署示例;kurator-demo-ai-platform:多集群 + Volcano + GPU 的 AI 平台样例;kurator-demo-edge-iot:云边协同的 IoT 场景。
这样新用户可以“照抄 + 改配置”快速上手,也能减少文章与文档之间的重复劳动。
-
把“分布式发布模型”进一步产品化
目前 v0.6.0 支持的 Canary/A/B/蓝绿能力,如果配合可视化界面 + 指标联动(SLO 门槛、安全回滚等),会极大提升平台推广难度——平台工程师可以给业务团队一个非常直观的发布面板。
-
开放更多可插拔扩展点
比如:
- 允许用户在 Fleet 插件体系中方便地接入自研组件;
- 将 Metric / Policy / Traffic / FinOps 等能力都做成“标准化插件接口”。
这样 Kurator 不会变成“强意见的超级平台”,而是一块“可编程的基础设施内核”。
-
和其它多集群项目的协同而不是竞争
比如 Karmada、OCM、Rancher 等:
- 可考虑以“集成现有多集群控制面”为目标,而不是强行替换;
- 用 Kurator 的统一编排能力去包装现有部署,降低迁移门槛。
八、一个“前瞻创想”小示例:把“应用 + 流量 + 观测”绑成一个声明式整体
最后,用一个完整但简化的 YAML 组合例子来收个尾:
想象 Kurator 未来的某个版本,我们可以用“一份声明”把应用、发布、流量和观测目标绑一起。
apiVersion: platform.kurator.dev/v1alpha1
kind: DistributedApp
metadata:
name: checkout-service
namespace: app-system
spec:
fleetRef:
name: fleet-global-prod
source:
git:
url: https://github.com/example-org/checkout-platform.git
ref:
branch: main
path: ./deploy/overlays/prod
rollout:
strategy: Canary
steps:
- setWeight: 20
pause:
duration: 5m
- setWeight: 50
pause:
duration: 10m
- setWeight: 100
trafficRouting:
istio:
virtualServiceName: checkout-vs
headerRouting:
- header: "x-user-group"
value: "beta"
observability:
slo:
availability:
objective: "99.9"
query: |
sum(rate(http_requests_total{app="checkout",status!~"5.."}[5m]))
/
sum(rate(http_requests_total{app="checkout"}[5m]))
latency:
objective: "95%<200ms"
query: |
histogram_quantile(0.95,
sum(rate(http_request_duration_seconds_bucket{app="checkout"}[5m])) by (le)
)
policy:
securityBaseline: "restricted"
extraKyvernoPoliciesRef:
- name: checkout-extra-rules
namespace: policy-system
虽然这个 DistributedApp 资源现在还不存在,但它背后的想法就是:
“分布式云原生设计的终极形态,是让‘应用本身 + 发布策略 + 观测目标 + 安全策略’
一起变成一个声明式的整体,然后交给平台去保障实现。”
从这个角度看,Kurator 已经在路上了:
- Application 管理部分
source与rollout; - Metric + SLO 部分可以基于 Prometheus/Thanos + 额外 CR 实现;
- Policy 部分有 Kyverno + Fleet 打底;
- 流量则由 Istio Mesh + Rollout 控制。
剩下的,就是把这些能力设计为自然、好用的统一抽象。
九、结语:Kurator 的“前瞻价值”,在于帮我们少走弯路
站在“前瞻创想”的视角,我更愿意把 Kurator 看成:
-
不是一个“又一套多集群控制台”;
-
而是一块逐步成型的分布式云原生操作系统内核——
- 它尝试把现有云原生组件组合成一个“工程上可落地”的整体;
- 又保持开源与可扩展,让企业可以在上面继续做定制与增强。
对正在规划多云、多集群、云边一体平台的团队来说,Kurator 的价值有三点:
- 少踩坑: 很多“自己拼一套 Istio + Thanos + Karmada + GitOps”的坑,Kurator 已经帮你踩过一遍;
- 更统一: 用 Fleet / Application / Rollout / Metric / Policy 等一系列 CRD,把分布式复杂度包装成有边界的抽象;
- 可演进: 它的架构天然适合向 AI、FinOps、零信任、端边云一体等方向扩展。
如果你已经在用 Kubernetes、Istio、Prometheus、GitOps 等组件,却仍然觉得“多云多集群越来越难管”,
不妨把 Kurator 作为你下一阶段平台演进的一个可选基石,
让自己少写一点脚本,多写一点声明式“分布式内核配置”。😉

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 22
22 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)