【探索实战】想让多集群听话?咱今天就把 Kurator 掰开揉碎,从架构到云边协同带你一次性玩透分布式云原生
【探索实战】想让多集群听话?咱今天就把 Kurator 掰开揉碎,从架构到云边协同带你一次性玩透分布式云原生
说起现在的云原生,大家脑子里第一反应肯定是 Kubernetes。但要是手里只有一两个集群,日子还算好过,要是集群一多,散落在各处,有的在公有云,有的在自己家机房,甚至还有一堆边缘节点在几千里外,这时候你再想靠人力去一个个盯着看、手动部署应用,那真的能让人头大。Kurator 这玩意儿其实就是为了解决这些“成长的烦恼”而生的。它不是那种冷冰冰的工具,更像是一个经验丰富的老管家,帮你把分布式云原生的那摊子杂事儿全都打理得井井有条。
Kurator 本质上是一个开源的分布式云原生平台,把舰队管理、云边协同、批量调度、甚至连监控和发布流程都给整到了一块儿。说白了,它就是想让你在管一百个集群的时候,感觉跟管一个集群一样省心。
准备工作得先做足,先把 Kurator 这套工具箱搬回家 🛠️
别急着开工,环境得先撸顺了
在咱们深入研究它的架构之前,总得先把东西装上看看吧。这环境搭建其实没啥神秘的,主要就是得把源码给整下来,然后再根据里面的脚本去跑。很多人一看到搭建环境就觉得烦,其实只要你环境里 Git、Docker 和 K8s 基础环境是好的,剩下的就是敲几行命令的事儿。
动手操作:把代码拉下来并检查依赖
咱们第一步就是要把 Kurator 的代码仓库给克隆到本地。这里建议大家专门开一个目录来搞,别跟其他乱七八糟的项目混在一块。
在项目地址中,可以看到可以clone到本地
https://gitcode.com/kurator-dev/kurator.git
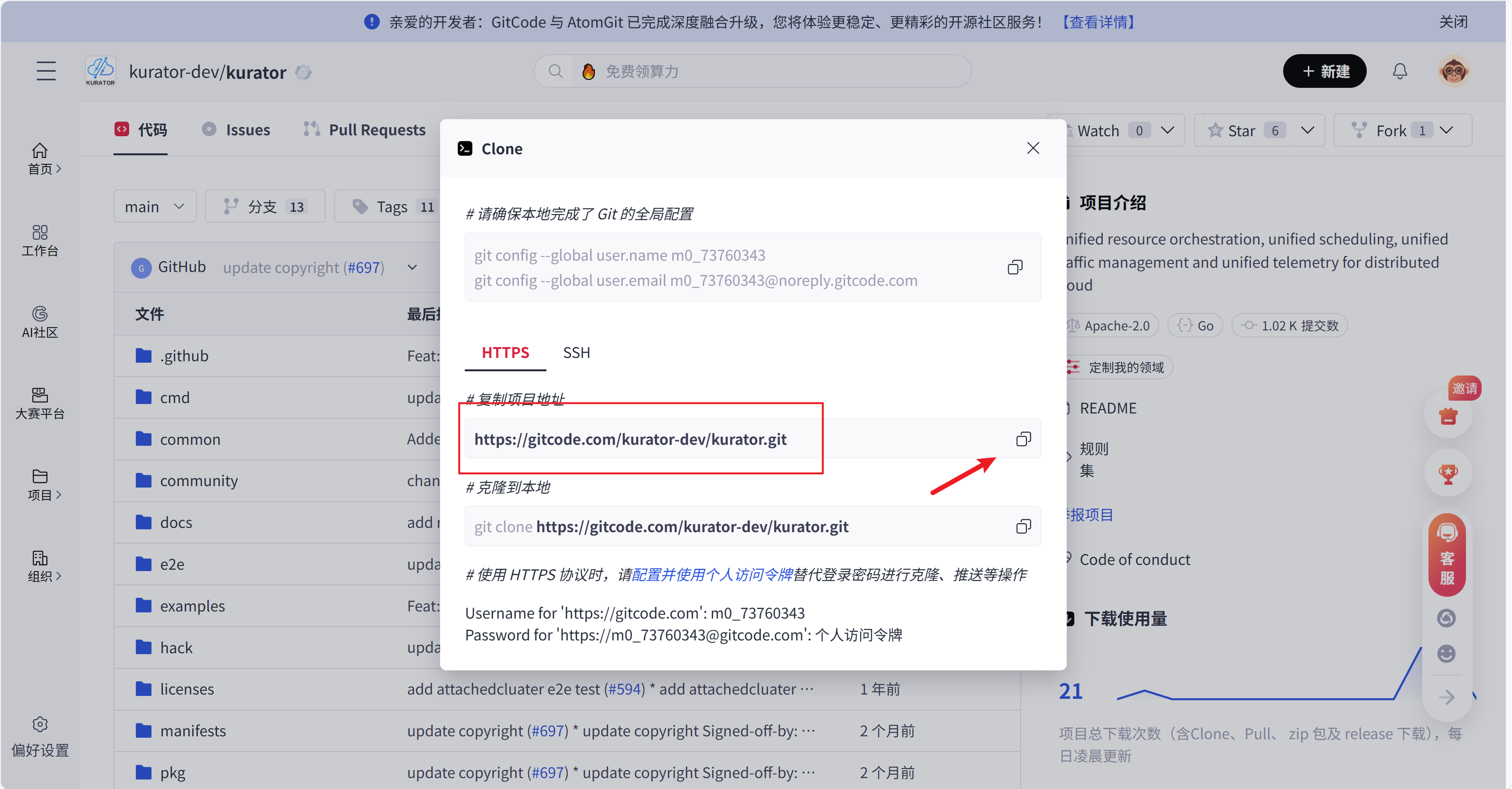
或者我们也可以下载到本地
可以看到我们资源文件已经下载下来了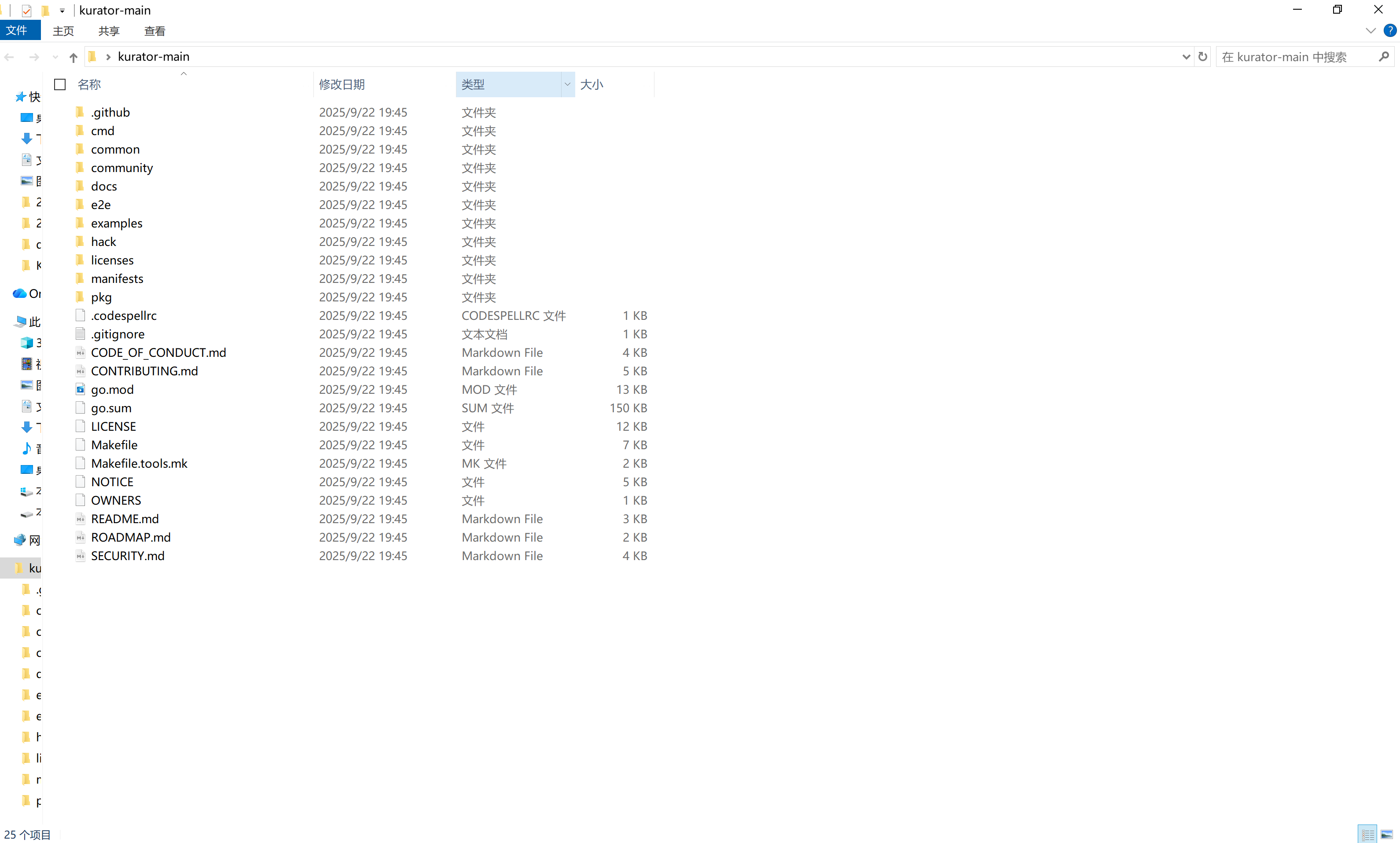
可以看到版本是0.6.0
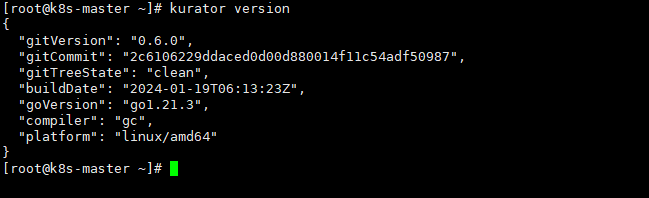
代码拉下来之后,你得看看里面的各种部署文件。
# 咱先找个干净的地方,把源码拉下来
mkdir -p ~/kurator-study && cd ~/kurator-study
git clone https://gitcode.com/kurator-dev/kurator.git
# 进到目录里瞅瞅
cd kurator
# 简单写个小脚本检查下本地的 kubectl 还有 helm 是不是都在
check_tools() {
for tool in kubectl helm docker; do
if ! command -v $tool &> /dev/null; then
echo "哎呀,没找到 $tool,得先装一下这个。"
else
echo "$tool 已经就绪,版本是: $($tool version --short 2>/dev/null || $tool version)"
fi
done
}
check_tools
环境初始化的小细节
把代码拉下来后,你会发现里面有很多现成的配置模板。其实搭建 Kurator 环境的核心逻辑就是通过它的控制面(Control Plane)去接管其他集群。你得确保你的主集群有足够的权限去访问其他子集群。通常我们会用它提供的安装脚本去初始化一些 CRD(自定义资源定义),这些东西就是 Kurator 能够指挥动集群的“军令状”。
聊聊 Fleet 架构:怎么像指挥舰队一样管理成百上千的集群 🚢
Fleet 核心架构的底子
这是Fleet的核心架构图,展示了其如何基于Bundle定义和集群分组实现多集群应用的分发、同步与状态追踪: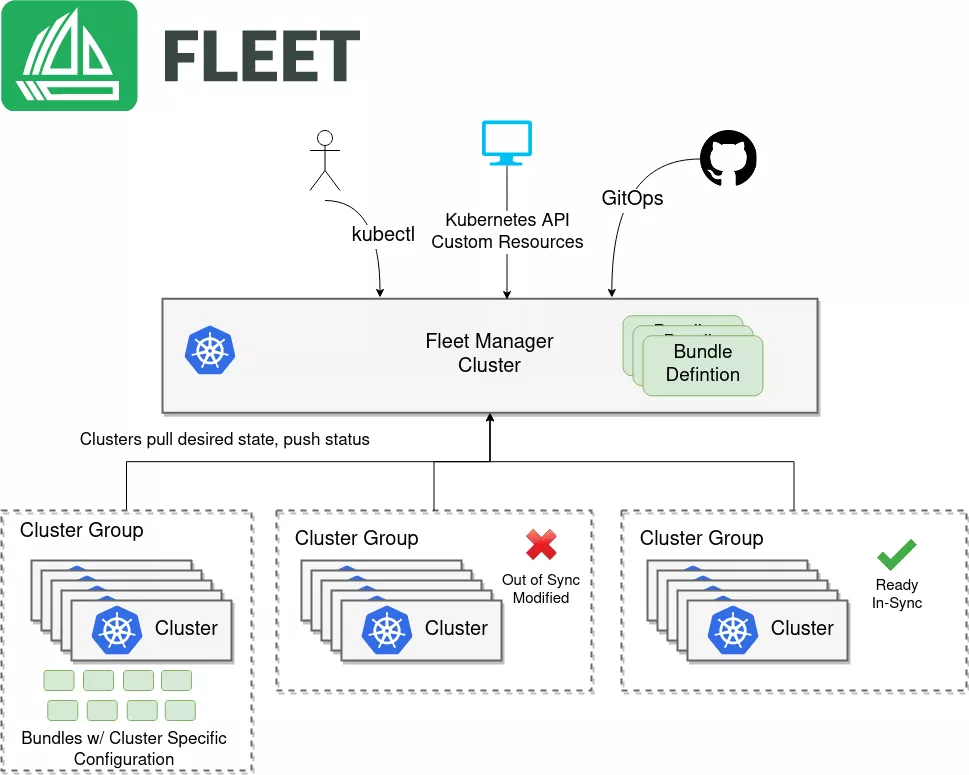
“Fleet”这个词在英文里就是舰队的意思。在 Kurator 里,Fleet 架构其实就是为了解决“多集群一致性”的问题。你想想,如果你有几十个集群,每个集群都要装一套监控、一套日志,那得累死。Fleet 架构的核心理念就是把这些集群编成一个队,通过一个统一的入口来下达指令。
Fleet 是如何运作的
说得直白点,Fleet 的架构里有一个“司令部”,通常我们叫它 Host Cluster。在这个司令部里,Kurator 集成了像 Karmada 这样优秀的项目。它的 Fleet 架构不仅仅是简单的连接,它能感知到每个集群的状态。当你定义了一个 Fleet 资源时,你其实是在告诉 Kurator:“嘿,这五个集群以后就是一家人了,我要在这一家人里部署同样的一套防火墙规则。”然后 Kurator 就会通过分发机制,自动把这些配置同步过去。这种架构保证了你不需要去每个集群里敲重复的命令,简直是懒人的福音。
云边协同不是梦:KubeEdge 怎么把手伸到千里之外的边缘端 🌐
KubeEdge 的详细架构解密
这是KubeEdge的详细架构参考图,展示了云端核心组件、边缘节点及其与设备之间的完整管理、通信与应用部署链路: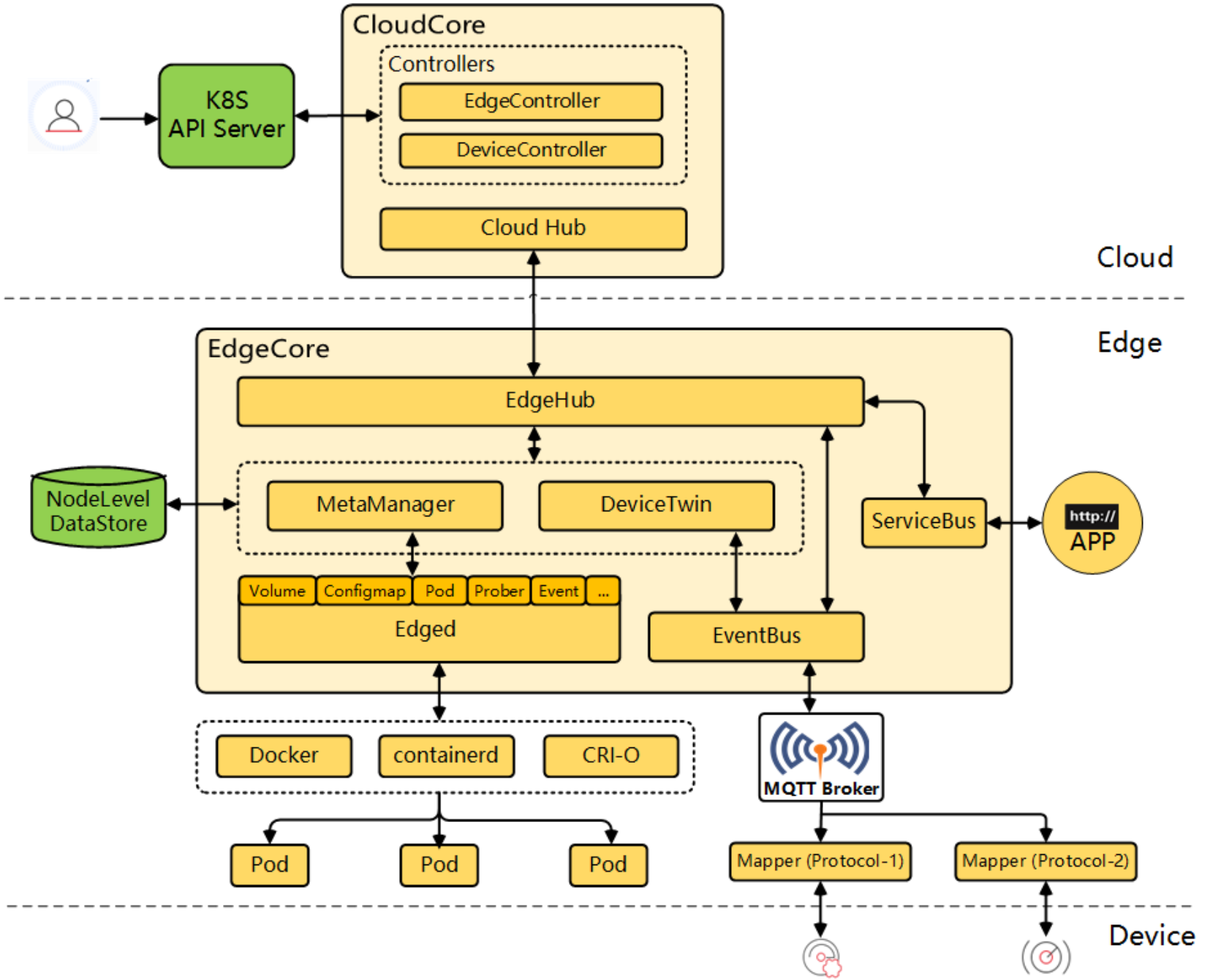
一提到云原生,大家总觉得是在宽敞明亮的机房里跑。但现在很多场景,比如自动驾驶、智能工厂,算力其实是在边缘端的。Kurator 聪明的地方在于它集成了 KubeEdge。KubeEdge 的架构其实是一个典型的“分身术”。在云端,它有一个 CloudCore,负责和 K8s 的 API Server 打交道;在边缘端,它跑着一个 EdgeCore。
这两个核心组件之间不是简单的连接,它们用的是一套经过优化的消息协议。即便边缘端的网络断了,EdgeCore 也能让本地的容器继续跑,等网络恢复了,再把数据同步回云端。这种架构解决了边缘设备带宽窄、网络不稳定的心头大患。
云边协同应用的部署架构
这张图展示了云边协同应用的部署架构,从设备层到边缘层、企业层再到产业平台,层层联动,实现工业数据在本地和云端的高效协同处理,支持智能制造和数字化转型: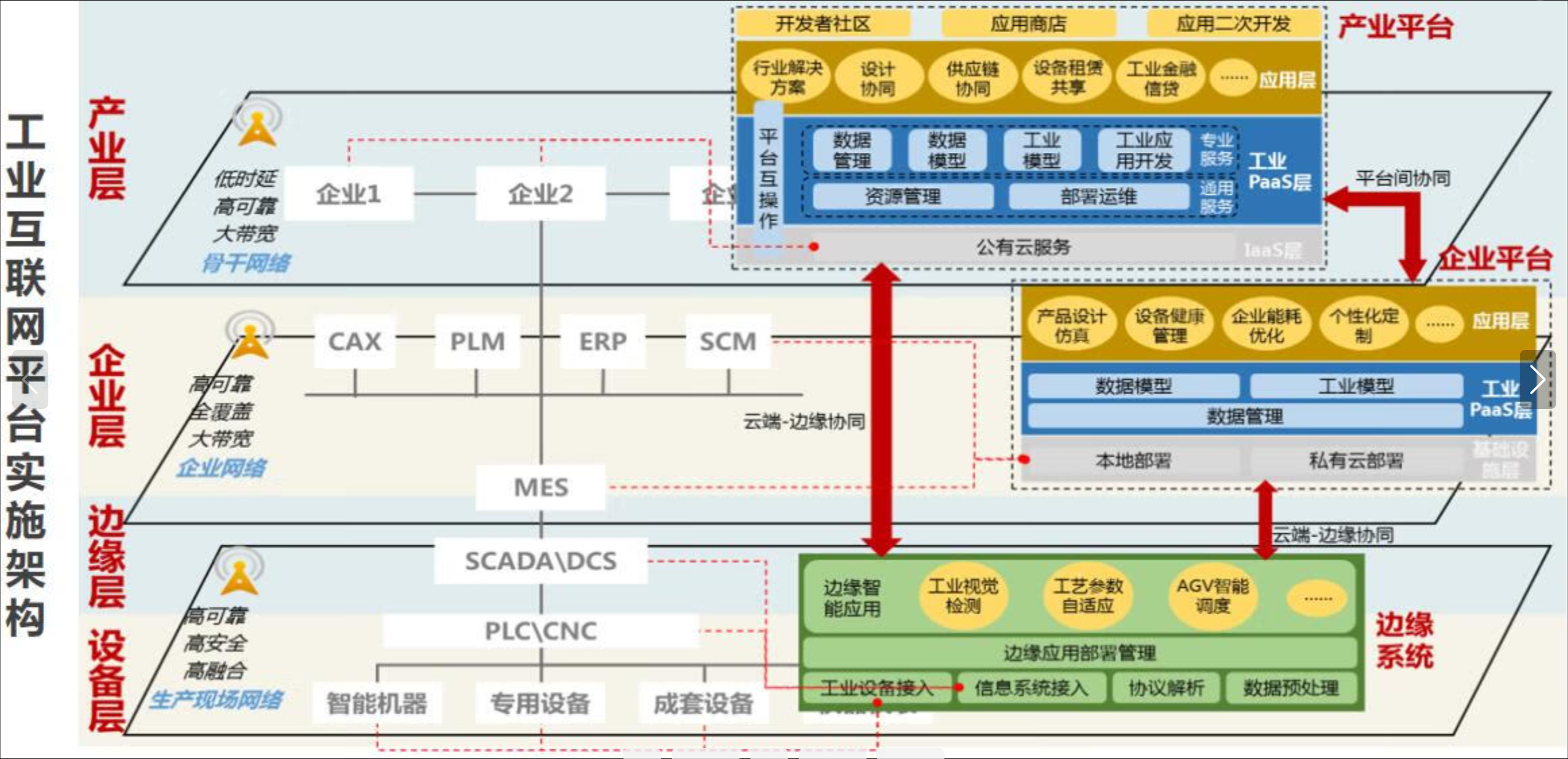
在 Kurator 看来,边缘节点也是集群的一部分,只不过是比较特殊的“远房亲戚”。它的部署架构让你可以像在云端部署应用一样,给应用打上一个标签,说“这个应用要去边缘跑”。
Kurator 会利用 KubeEdge 的特性,把镜像分发到边缘。这里面最巧妙的是,它把边缘的复杂性给屏蔽掉了。对于开发者来说,你只是把 YAML 往主集群一丢,Kurator 和 KubeEdge 就会在后台商量好,谁该去哪个边缘节点,谁该在云端做数据汇总。这种云边一体化的感觉,真的让运维工作少了一大半的压力。
Volcano 为什么是 AI 和大数据的救星?调度架构深蹲起跳 🌋
Volcano 的应用场景到底在哪
这是Volcano的应用场景参考图,展示了它如何作为统一调度平台,支撑AI训练、大数据及科学计算等多种分布式工作负载: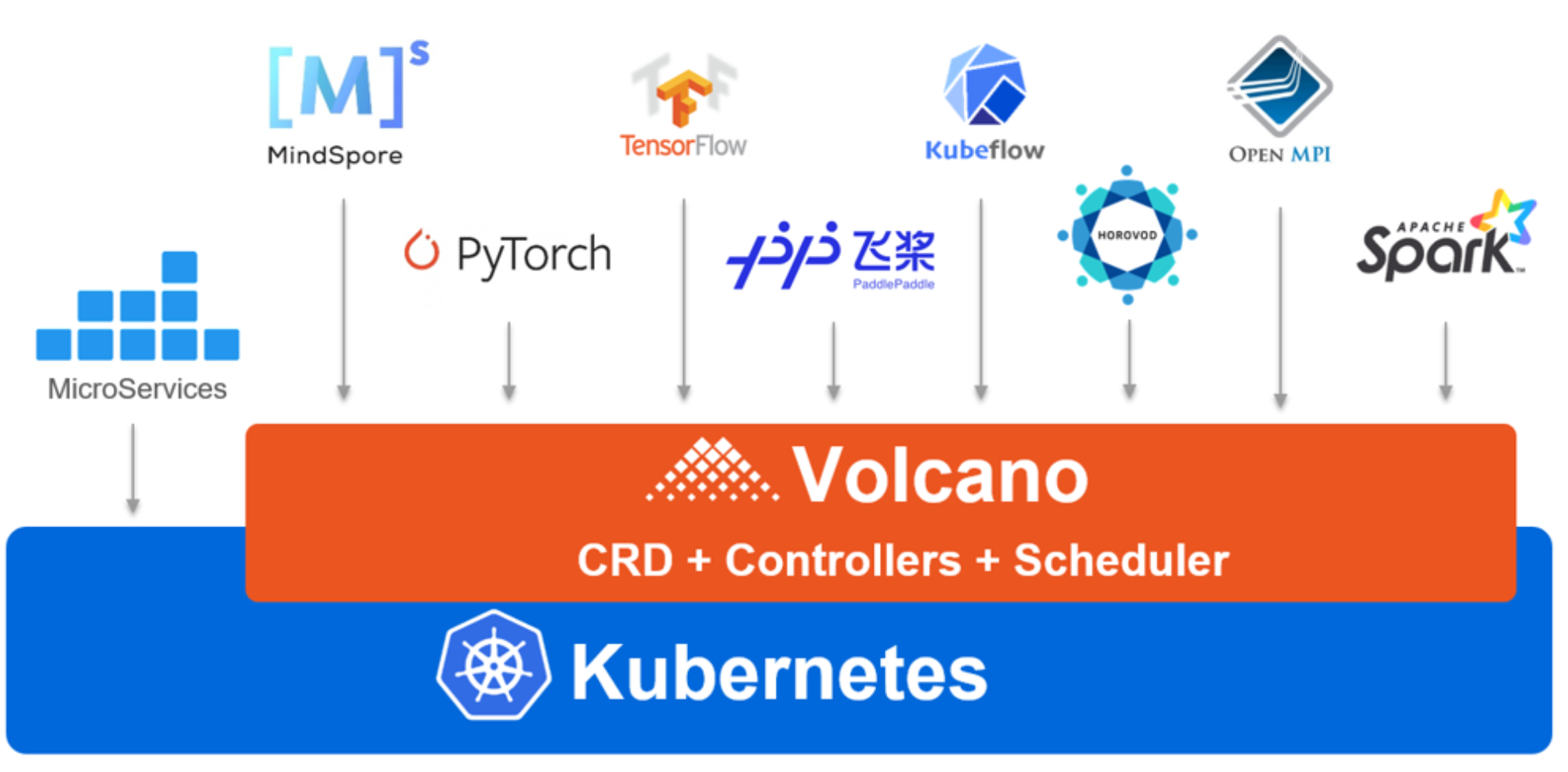
咱们平常用的 K8s 默认调度器,其实是为那些“一直跑着”的微服务准备的。但是 AI 训练或者大数据计算不一样,它们往往是任务制的,而且是一来来一堆。比如你训练一个模型,需要 8 个 GPU 节点,如果只给了 7 个,剩下那个死活等不到,那这 7 个节点其实也是在浪费电。这就是 Volcano 派上用场的地方——批量调度(Batch Scheduling)。
深入看一眼 Volcano 的调度架构
这是Volcano调度架构参考图,展示了其核心组件如何通过CRD、控制器和调度器协同工作,实现对批量计算作业的统一管理: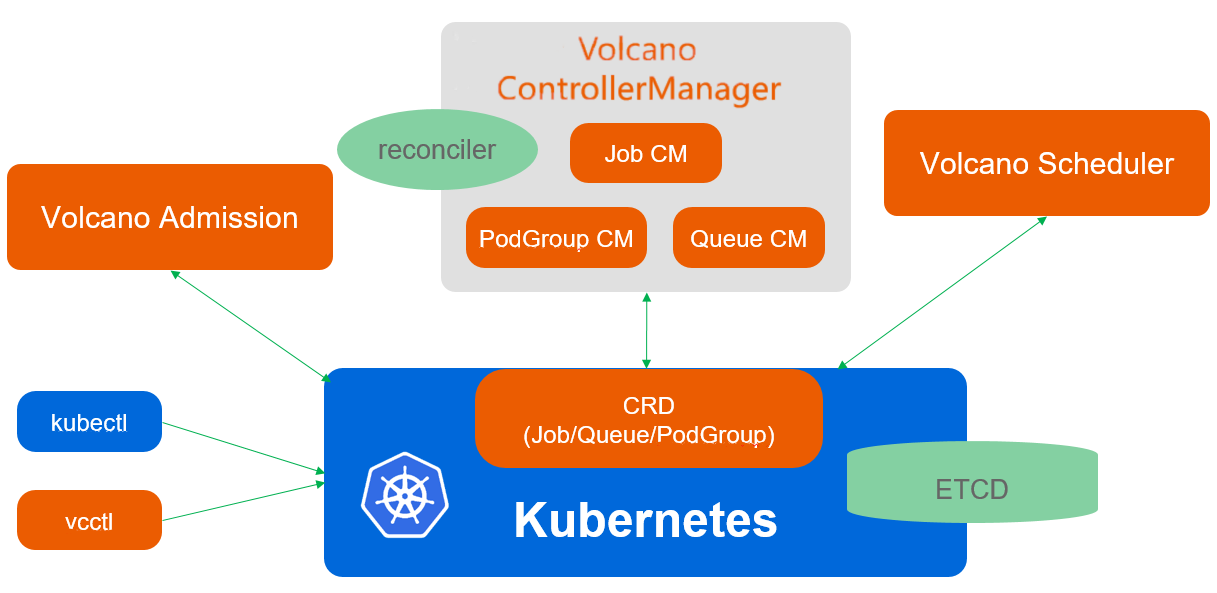
Volcano 的调度架构和 K8s 原生的完全不一样。它引入了“会话(Session)”的概念。它不是一个一个看 Pod,而是把一堆相关的 Pod 看成一个 Job。它的调度过程分了好几个阶段,比如预选、优选,还有最重要的“帮派调度(Gang Scheduling)”。
它能做到“要么全上,要么一个都不上”,这样就避免了资源死锁。而且它的架构里还有丰富的插件机制,你可以自己定义权重。比如公司里老板的任务优先级最高,你可以写个简单的配置,让 Volcano 优先把资源拨给老板的 AI 模型训练。
# 这是一个简单的 Volcano Job 配置,看起来就像咱们手写的一样
# 主要是定义了一个最小启动数量(minAvailable),不到这个数它就不开工
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: kurator-ai-training-job
spec:
minAvailable: 3
schedulerName: volcano # 明确告诉 K8s,这活儿归 Volcano 管
tasks:
- replicas: 3
name: worker
template:
spec:
containers:
- name: training-container
image: my-ai-model:v1.0
resources:
requests:
cpu: "2"
memory: "4Gi"
restartPolicy: OnFailure
应用发布不翻车:Kurator Rollout 与 CI/CD 的全自动流程 🚀
Kurator CI/CD 的完整流程
咱们写代码的,最怕的就是发布应用。Kurator 提供了一整套 CI/CD 流程,把从代码提交到集群上线的活儿全包了。流程大概是这样的:你把代码往 Git 一推,Webhook 就会触发 Kurator 里的流水线。
它会自动帮你做镜像构建、安全扫描,最关键的一步是它会把新版本的 YAML 文件自动同步到 Fleet 定义的那些集群里。这个流程是全自动的,中间不需要人去介入,极大地降低了人为出错的概率。
Kurator Rollout 功能的架构
发布了之后,如果新代码有 Bug 怎么办?这时候 Kurator Rollout 架构就显神威了。它支持金丝雀发布(Canary)和蓝绿部署。它的架构核心是一个 Rollout 控制器,它会盯着你的应用状态看。
当你发一个新版本,它不会一下子全换掉。它先启动一小部分新版本的 Pod,然后分一点流量过去。它会结合监控指标,如果发现新版本的错误率上去了,它会立马自动回滚。这种自动化的防御机制,简直是运维同学的救命稻草,再也不用大半夜起来手动回滚代码了。
统一监控架构:不管集群在哪,一眼望穿所有性能指标 📊
Kurator 的统一监控架构
最后咱们得聊聊监控。集群多了,最痛苦的就是看监控。如果每个集群都开一个 Grafana 页面,切来切去都能把人切晕。Kurator 搞了一套统一监控架构。它在每个子集群里部署轻量级的采集器,然后把这些指标汇聚到主集群的一个中心仓库里。
这个架构最牛的地方在于它能做“多维度聚合”。你可以一眼看到全公司所有集群的 CPU 使用率,也可以钻取到某个具体边缘节点的内存占用。它把 Prometheus 那套东西玩得非常溜,通过联邦模式或者是远程写的方式,把分散的数据变成了一张完整的网。
监控数据的定制与呈现
在 Kurator 这种架构下,监控不仅仅是看图表,它还能和前面的调度、发布流程联动。比如监控发现某个集群负载太高,它可以触发自动扩容;如果发现新发布的应用响应变慢,Rollout 控制器就会收到信号。
# 这是一个简单的 PrometheusRule,咱们手动配一下用来监控 Kurator 里的异常
# 只要有集群不可用了,立马报警,别等出事了才知道
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: kurator-cluster-health-rules
labels:
role: alert-rules
spec:
groups:
- name: cluster-health
rules:
- alert: ClusterDown
expr: kurator_cluster_status == 0
for: 5m
labels:
severity: critical
annotations:
summary: "哎呀,集群 {{ $labels.cluster_name }} 挂掉了!"
description: "这都五分钟没动静了,赶紧去看看是不是网络断了还是炸了。"
写到这儿,估计你对 Kurator 也有个大概的了解了。说白了,它就是把多集群管理、云边协同、高级调度这些原本散装的珠子,用一套完美的架构串成了一根项链。虽然里面的技术细节挺深,但只要你理顺了 Fleet 管理、KubeEdge 协同、Volcano 调度这几大板块,再配合全自动的 CI/CD 和 Rollout,搞定分布式云原生其实也没那么难。
要是你也正头疼手里的集群管理不过来,或者正想折腾云边协同,真的可以去试试 Kurator。毕竟,能让咱们少加班、少背锅的工具,才是真的好工具,你说是不?有什么想法或者在搭环境时踩了坑,随时跟我交流,咱们一起把这玩意儿玩转!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)