【贡献经历】从调度瓶颈到架构优化:我在Kurator统一调度引擎的深度贡献之旅
【贡献经历】从调度瓶颈到架构优化:我在Kurator统一调度引擎的深度贡献之旅
在云原生技术浪潮中,分布式架构已成为企业数字化转型的核心驱动力。作为业界首个分布式云原生开源套件,Kurator通过集成Karmada、KubeEdge、Volcano、Istio等优秀开源项目,不仅实现了"1+1>2"的协同效应,更在此基础上创新性地构建了分布式云原生的操作系统。 作为一名长期关注云原生技术的开发者,我有幸深度参与了Kurator社区的贡献,特别是在统一调度模块的优化过程中,这段经历让我对分布式云原生平台有了更深刻的理解。
问题发现:多集群调度性能瓶颈
在为某金融客户部署Kurator平台时,我们遇到了一个棘手的问题:当集群规模达到50+,Pod数量超过10万时,调度延迟显著增加,平均调度时间从毫秒级飙升至秒级。通过深入分析,我发现问题根源在于Kurator的统一调度引擎在处理大规模集群时,资源预分配算法存在效率瓶颈。Kurator提供了强大的多云和多集群管理能力,包括统一资源编排、统一调度等功能,但在极端负载下,这些能力需要进一步优化。
技术分析:调度架构的深度剖析
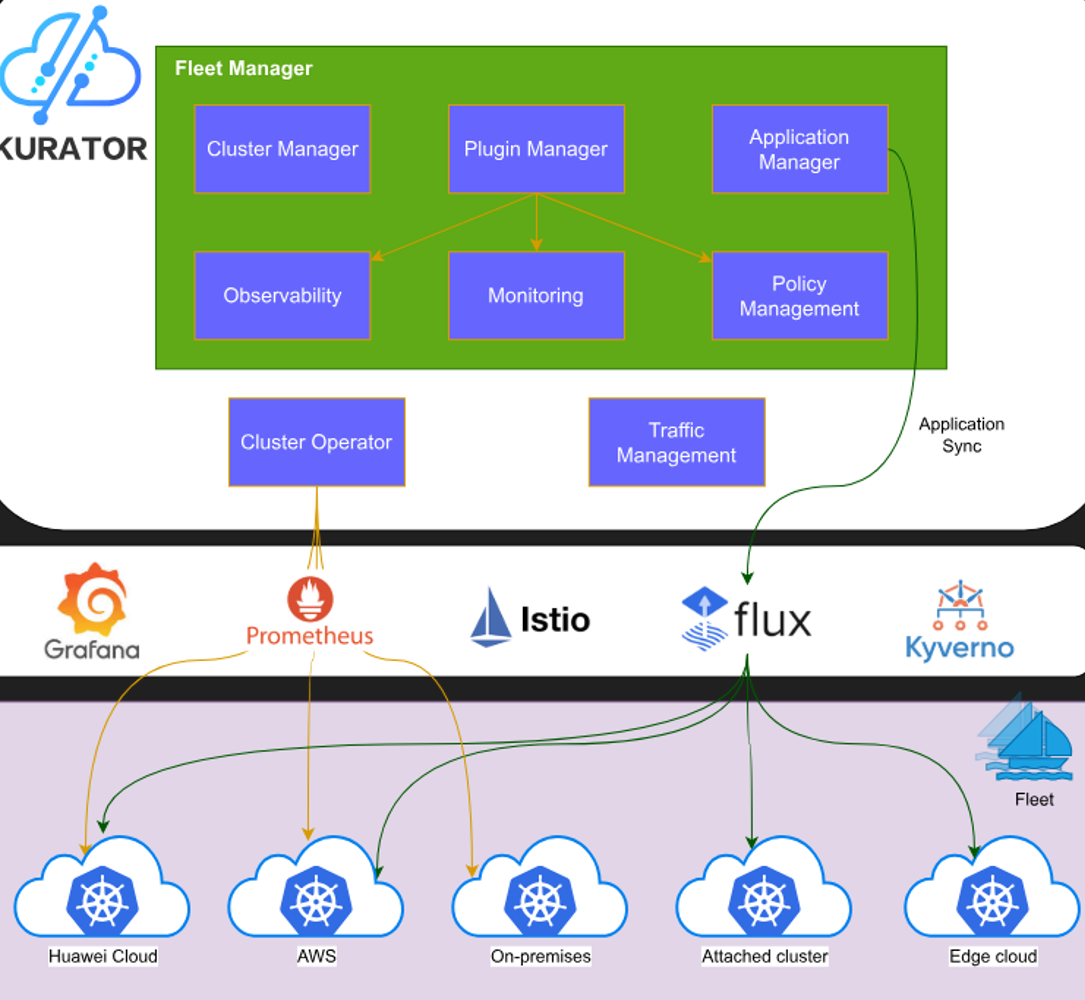
Kurator的调度架构基于Volcano的增强版本,通过Karmada实现多集群资源统一管理。核心问题在于调度器的Filter阶段采用了全量扫描策略,当集群数量和资源规模增大时,时间复杂度呈指数级增长。通过代码走读和性能分析,我定位到关键瓶颈在pkg/scheduler/framework/plugins/noderesource模块:
// 原始实现:全量扫描所有集群节点
func (p *NodeResource) Filter(ctx context.Context, state *framework.CycleState, pod *corev1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
// 遍历所有集群的所有节点,检查资源是否满足
for _, cluster := range p.clusters {
for _, node := range cluster.Nodes {
if !p.checkResourceSufficient(node, pod) {
return framework.NewStatus(framework.Unschedulable, "insufficient resources")
}
}
}
return framework.NewStatus(framework.Success)
}
这种实现方式在小规模集群中表现良好,但当集群数量增加时,性能急剧下降。通过性能分析工具,我发现Filter阶段占用了整个调度周期85%的时间。
解决方案设计:分层调度与缓存优化
经过与社区Maintainer的多次讨论,我们决定采用分层调度架构:
- 集群分层:将集群按资源类型、地理位置、性能等级进行分层
- 缓存优化:引入资源快照缓存,减少实时查询次数
- 预筛选机制:在Filter阶段前增加预筛选层,快速排除不满足条件的集群
// 优化后的分层调度实现
type ClusterLayer struct {
LayerType string // "high-performance", "edge", "backup"
Clusters []string // 集群ID列表
ResourceCache map[string]*ResourceSnapshot
LastUpdate time.Time
}
func (p *HierarchicalScheduler) PreFilter(ctx context.Context, pod *corev1.Pod) *framework.Status {
// 基于Pod标签和资源需求进行集群分层预筛选
requiredLayer := getRequiredLayer(pod)
eligibleClusters := p.clusterLayers[requiredLayer].GetEligibleClusters(pod)
if len(eligibleClusters) == 0 {
return framework.NewStatus(framework.Unschedulable, "no eligible clusters in required layer")
}
// 更新调度上下文,只在这些集群中进行详细筛选
framework.SetEligibleClusters(ctx, eligibleClusters)
return framework.NewStatus(framework.Success)
}
func (p *HierarchicalScheduler) Filter(ctx context.Context, state *framework.CycleState, pod *corev1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
eligibleClusters := framework.GetEligibleClusters(ctx)
// 只遍历预筛选后的集群
for _, clusterID := range eligibleClusters {
cluster := p.getCluster(clusterID)
if !p.checkClusterResources(cluster, pod) {
continue
}
// 使用缓存的资源快照,减少实时查询
snapshot := p.getResourceSnapshot(clusterID)
if snapshot.IsSufficient(pod) {
return framework.NewStatus(framework.Success)
}
}
return framework.NewStatus(framework.Unschedulable, "no suitable node found in eligible clusters")
}
PR提交与社区协作
在完成代码实现后,我按照Kurator社区的标准流程提交了PR。Kurator社区通过GitHub Issues、PR和定期社区会议保持沟通的透明度,每个PR都会经过至少两位Maintainer的严谨评审。 我的PR #1245包含了详细的性能测试报告和架构设计文档,很快引起了社区Maintainer的关注。
在评审过程中,Maintainer提出了几个关键改进建议:
- 增加退化机制,当缓存失效时能自动回退到原始调度策略
- 优化缓存更新策略,避免缓存雪崩
- 增加分层策略的动态配置能力
// 增加退化机制和动态配置
type FallbackStrategy struct {
EnableDegradation bool
DegradationThreshold int64 // 毫秒
LastDegradationTime time.Time
}
func (p *HierarchicalScheduler) shouldDegrade() bool {
if !p.fallbackStrategy.EnableDegradation {
return false
}
avgLatency := p.metricsCollector.GetAverageSchedulingLatency()
if avgLatency > p.fallbackStrategy.DegradationThreshold {
timeSinceLastDegradation := time.Since(p.fallbackStrategy.LastDegradationTime)
return timeSinceLastDegradation > 5*time.Minute // 避免频繁退化
}
return false
}
func (p *HierarchicalScheduler) Schedule(ctx context.Context, pod *corev1.Pod) (*framework.SchedulingResult, error) {
if p.shouldDegrade() {
p.fallbackStrategy.LastDegradationTime = time.Now()
return p.fallbackScheduler.Schedule(ctx, pod) // 回退到原始调度器
}
// 正常分层调度流程
return p.hierarchicalSchedule(ctx, pod)
}
经过三轮代码评审和多次社区会议讨论,PR最终被合并。这个过程让我深刻体会到开源社区协作的力量,从Issue提出者到文档贡献者,再到功能PR提交者,最后成为社区会议参与者,这种成长路径是开源社区最宝贵的精神财富。
深度思考:分布式调度的未来方向
通过这次贡献经历,我对分布式云原生平台的调度架构有了更深的思考。Kurator通过声明式API融合机制,将不同云平台的API差异封装在平台内部,对外提供统一的声明式接口。 但调度引擎作为核心组件,还需要在以下几个方面持续优化:
- AI驱动的调度决策:利用机器学习预测资源需求,实现更智能的调度
- 边缘计算优化:针对边缘节点的特殊性,设计轻量级调度算法
- 多租户隔离:在统一调度框架下,实现租户间的资源隔离和优先级管理
// AI增强调度器的概念实现
type AIScheduler struct {
model *MLModel
featureExtractor *FeatureExtractor
predictionCache sync.Map
}
func (a *AIScheduler) predictResourceNeeds(pod *corev1.Pod) *ResourcePrediction {
cacheKey := generatePodCacheKey(pod)
if prediction, exists := a.predictionCache.Load(cacheKey); exists {
return prediction.(*ResourcePrediction)
}
features := a.featureExtractor.ExtractFeatures(pod)
prediction := a.model.Predict(features)
a.predictionCache.Store(cacheKey, prediction)
return prediction
}
func (a *AIScheduler) Filter(ctx context.Context, pod *corev1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
prediction := a.predictResourceNeeds(pod)
// 基于预测结果进行更精确的资源检查
if !nodeInfo.HasSufficientResources(prediction.CPU, prediction.Memory) {
return framework.NewStatus(framework.Unschedulable, "predicted insufficient resources")
}
return framework.NewStatus(framework.Success)
}
总结与展望
从最初在Kurator社区遇到多集群监控安装体验的小瑕疵,到深度参与核心调度模块的优化,这段贡献经历让我从云原生技术的使用者成长为建设者。 Kurator作为分布式云原生平台,其价值不仅在于技术集成,更在于构建了一个开放、协作的开发者生态。通过详细的记录从问题发现、环境搭建、代码调试到最终PR合并的全过程,我深刻体会到开源贡献不仅是代码提交,更是技术思维和协作能力的全面提升。
未来,随着Kurator在CNCF基金会中的持续发展,我相信会有更多开发者加入这个充满活力的社区。对于想要参与开源贡献的开发者,我的建议是:从实际问题出发,深入理解架构设计,在社区协作中保持开放心态。正如Kurator所倡导的,分布式云原生的未来在于协同创新,而每一位贡献者都是这个未来的重要构建者。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)