【探索实战】从技术选型到生态赋能:Kurator助力企业云原生转型的实战之旅
·
1. 引言:云原生时代监控的挑战与Kurator的破局之道
1.1 云原生监控的痛点
在云原生(Cloud Native)架构下,企业普遍采用多Kubernetes集群(如生产、测试、预发布环境)和微服务架构,但传统监控方式面临以下挑战:
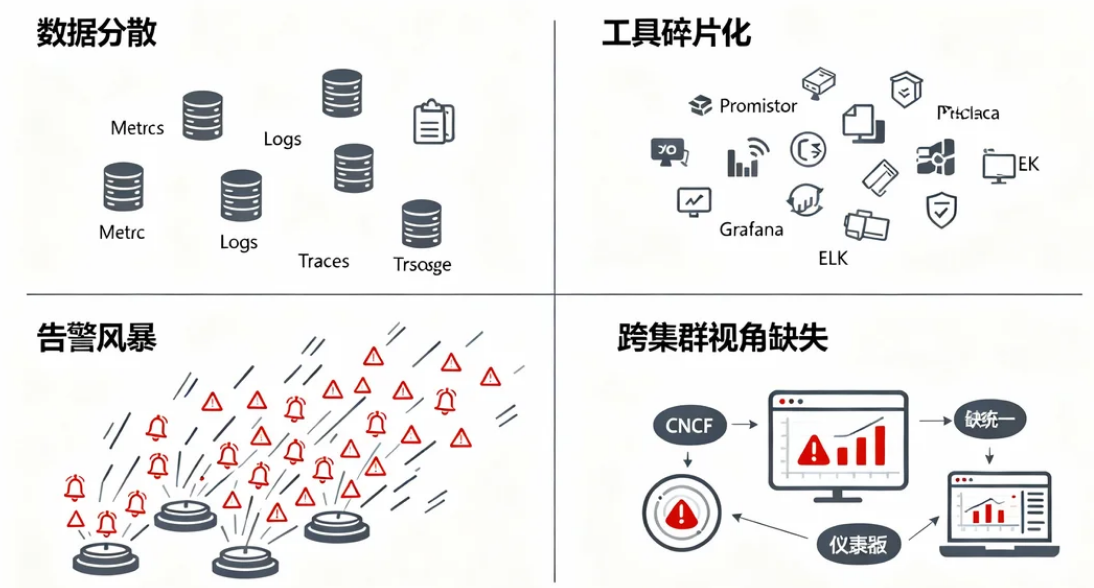
- 数据分散:每个集群、每个服务的监控数据(Metrics、Logs、Traces)独立存储,难以统一分析。
- 工具碎片化:Prometheus、Grafana、ELK等工具各自为政,运维成本高。
- 告警风暴:多集群告警信息分散,难以快速定位根因。
- 跨集群视角缺失:无法从全局视角观察整体系统健康状态。
1.2 Kurator的解决方案
Kurator 是一款专注于分布式云原生运维的平台,其统一监控方案通过以下核心能力解决上述问题:
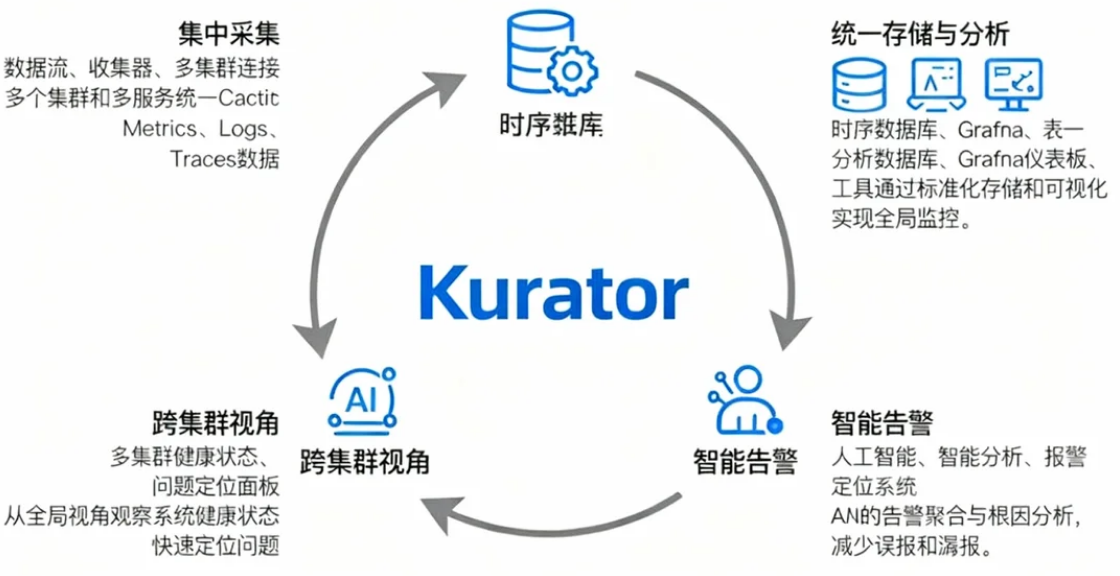
- 集中采集:统一采集多集群、多服务的Metrics、Logs、Traces数据。
- 统一存储与分析:通过标准化存储(如时序数据库)和可视化(如Grafana)实现全局监控。
- 智能告警:基于AI的告警聚合与根因分析,减少误报和漏报。
- 跨集群视角:从全局视角观察系统健康状态,快速定位问题。
2. Kurator分布式统一监控核心原理剖析
2.1 监控数据流转闭环
Kurator的统一监控基于 “数据采集 → 集中存储 → 可视化分析 → 智能告警” 的闭环流程,核心组件包括:
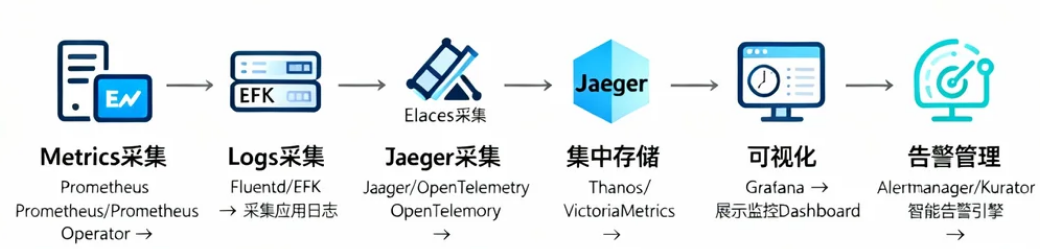
- Metrics采集:Prometheus/Prometheus Operator(采集Kubernetes资源指标)。
- Logs采集:Fluentd/EFK(Elasticsearch + Fluentd + Kibana,采集应用日志)。
- Traces采集:Jaeger/OpenTelemetry(采集分布式追踪数据)。
- 集中存储:Thanos/VictoriaMetrics(跨集群Metrics存储与查询)。
- 可视化:Grafana(展示监控Dashboard)。
- 告警管理:Alertmanager/Kurator智能告警引擎(告警路由与通知)。
2.2 关键技术栈
| 技术 | 作用 |
|---|---|
| Prometheus | 采集Kubernetes Metrics(CPU、内存、请求延迟等) |
| Grafana | 可视化监控数据,支持自定义Dashboard |
| Thanos/VictoriaMetrics | 跨集群Metrics存储与查询 |
| Fluentd/EFK | 采集应用日志(Logstash/Elasticsearch/Kibana) |
| Jaeger/OpenTelemetry | 分布式追踪(Traces) |
| Alertmanager | 告警路由与通知(邮件、Slack、钉钉) |
3. 环境搭建:从零构建Kubernetes与Kurator监控体系
3.1 环境准备
- 3个Kubernetes集群(生产、测试、预发布)。
- Kurator监控控制平面(部署在管理集群)。
- Prometheus + Grafana(用于Metrics采集与可视化)。
3.2 搭建Kubernetes集群(kubeadm示例)
# 所有节点安装Docker和Kubernetes
yum install -y docker-ce kubelet kubeadm kubectl
systemctl enable --now docker kubelet
# Master节点初始化
kubeadm init --pod-network-cidr=10.244.0.0/16
mkdir -p $HOME/.kube && cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# Worker节点加入集群
kubeadm join <MASTER_IP>:6443 --token <TOKEN>
3.3 部署Kurator监控体系
# 部署Prometheus Operator
kubectl apply -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/main/bundle.yaml
# 部署Grafana
kubectl apply -f https://raw.githubusercontent.com/grafana/helm-charts/main/charts/grafana/values.yaml
# 部署Kurator监控控制平面
kubectl apply -f kurator-monitoring.yaml
4. Kurator统一监控功能深度解析
4.1 核心功能
| 功能 | 说明 |
|---|---|
| 多集群Metrics采集 | 统一采集所有K8s集群的CPU、内存、请求延迟等数据 |
| 集中式存储 | 使用Thanos/VictoriaMetrics存储跨集群Metrics |
| 可视化Dashboard | 通过Grafana展示全局监控视图 |
| 智能告警 | 基于AI的告警聚合与根因分析 |
| 日志与追踪 | 集成EFK(日志)和Jaeger(追踪) |
4.2 监控数据流转
- Metrics:Prometheus → Thanos → Grafana
- Logs:Fluentd → Elasticsearch → Kibana
- Traces:Jaeger → 存储 → 可视化
5. 代码实战:多集群监控数据采集与处理
5.1 部署Prometheus采集K8s Metrics
# prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: k8s-prometheus
spec:
serviceMonitorSelector:
matchLabels:
app: kubernetes
resources:
requests:
memory: 400Mi
5.2 部署Grafana Dashboard
# 导入Kubernetes监控Dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes-monitoring/kubernetes-mixin/master/dashboards/out/kubernetes-cluster.json
5.3 配置跨集群监控
# 使用Thanos Query聚合多个Prometheus数据
kubectl apply -f thanos-query.yaml
6. Kurator监控数据流转与告警
6.1 Metrics采集
6.2 告警
6.3 全链路监控
8. 常见问题与优化策略
8.1 常见问题
| 问题 | 解决方案 |
|---|---|
| Prometheus数据丢失 | 使用Thanos长期存储 |
| Grafana Dashboard加载慢 | 优化查询语句 |
| 告警过多 | 使用告警分组与抑制 |
8.2 优化建议
- 使用VictoriaMetrics替代Prometheus(更高性能)。
- 结合OpenTelemetry实现全栈可观测性。
- 定期清理旧数据(避免存储爆炸)。
9. 未来展望:Kurator在可观测性领域的演进
- 支持更多数据源(如AWS CloudWatch、Azure Monitor)。
- AI驱动的自动调优(如自动扩缩容建议)。
- 更强大的安全机制(RBAC、数据加密)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)