【探索实战】从“集群拼装工”到“舰队总指挥”:我与 Kurator 的云原生分布式实战之路!
一、写在前面:为什么我开始关注 Kurator?
如果你现在正在做平台运维、SRE 或云原生平台开发,很大概率在日常工作里会遇到这几个场景:
- 集群越来越多:测试集群、预发集群、生产集群、海外集群、离线集群、边缘集群……
- 组件越来越杂:Kubernetes、Istio、Prometheus、Karmada、KubeEdge、Volcano、Elastic、各种 Operator……
- 脚本越来越长:每个集群有自己的初始化脚本、升级脚本、修复脚本、迁移脚本,换个同事接手就开始头大。
我之前一直在一个偏平台性质的团队做工程实践,最真实的感受就是——大家都在做同一件事:把一堆优秀的开源组件「拼」成一个能用的平台,但真正统一管理和治理这些组件的东西却很少。
随着业务从「单集群」走向「多集群 + 多云 + 边缘」,单靠脚本和 Wiki 文档已经 hold 不住了。
在这样的背景下,我开始系统性地调研「多集群 + 分布式云原生平台」的方案,而 Kurator 就是在这个过程中被我关注到、并且真正落地实践的一套开源方案。
Kurator 社区的定位大概可以概括成一句话:
在 Karmada、KubeEdge、Volcano、Istio 等主流云原生技术栈之上,提供一套统一的「舰队管理」与「分布式云原生平台能力」。
换句话说,它不是要「推翻重来」,也不是另造一个「大而全」的封闭平台,而是更多扮演一个「统一编队」的角色:
- 把你现有或未来可能用到的云原生关键组件纳入同一套框架内;
- 在其之上封装出「多集群生命周期管理、统一应用分发、统一流量治理、统一监控和统一策略管理」等能力;
- 最终对上承接业务与运维人员,对下连接多云、多集群和边缘。
也正是因为这个「不造轮子、而是整合轮子」的理念,我决定拉一条从 0 到 1 的 Kurator 实战路线:
既看看它在实验环境里的体验,也试着逐步在实际业务场景里落地,看看能不能从一个「集群拼装工」变成真正的「舰队总指挥」。
这篇文章就是这一路实践过程的完整复盘和思考,希望能给正在做或准备做多集群平台的你一点参考。🚀
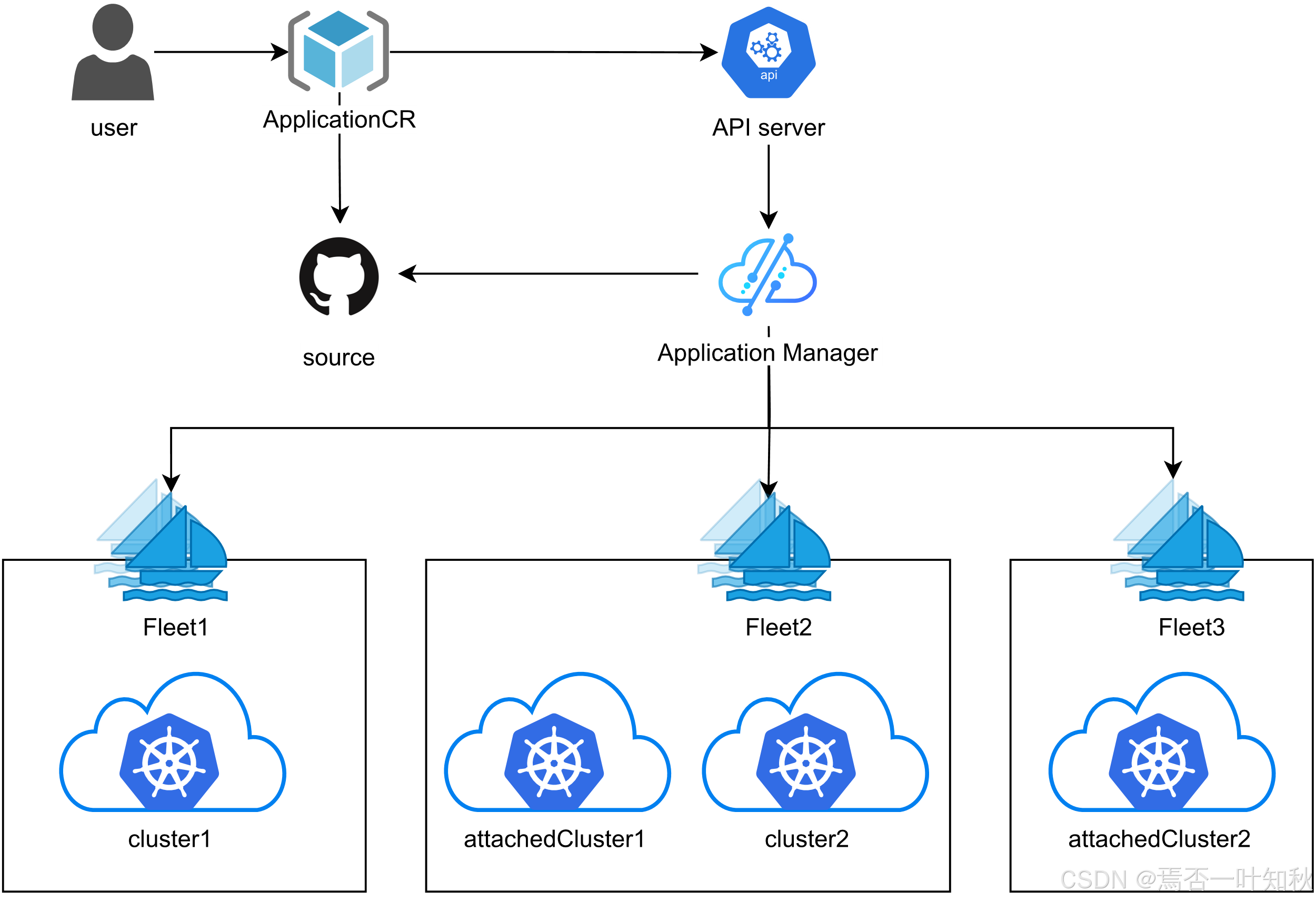
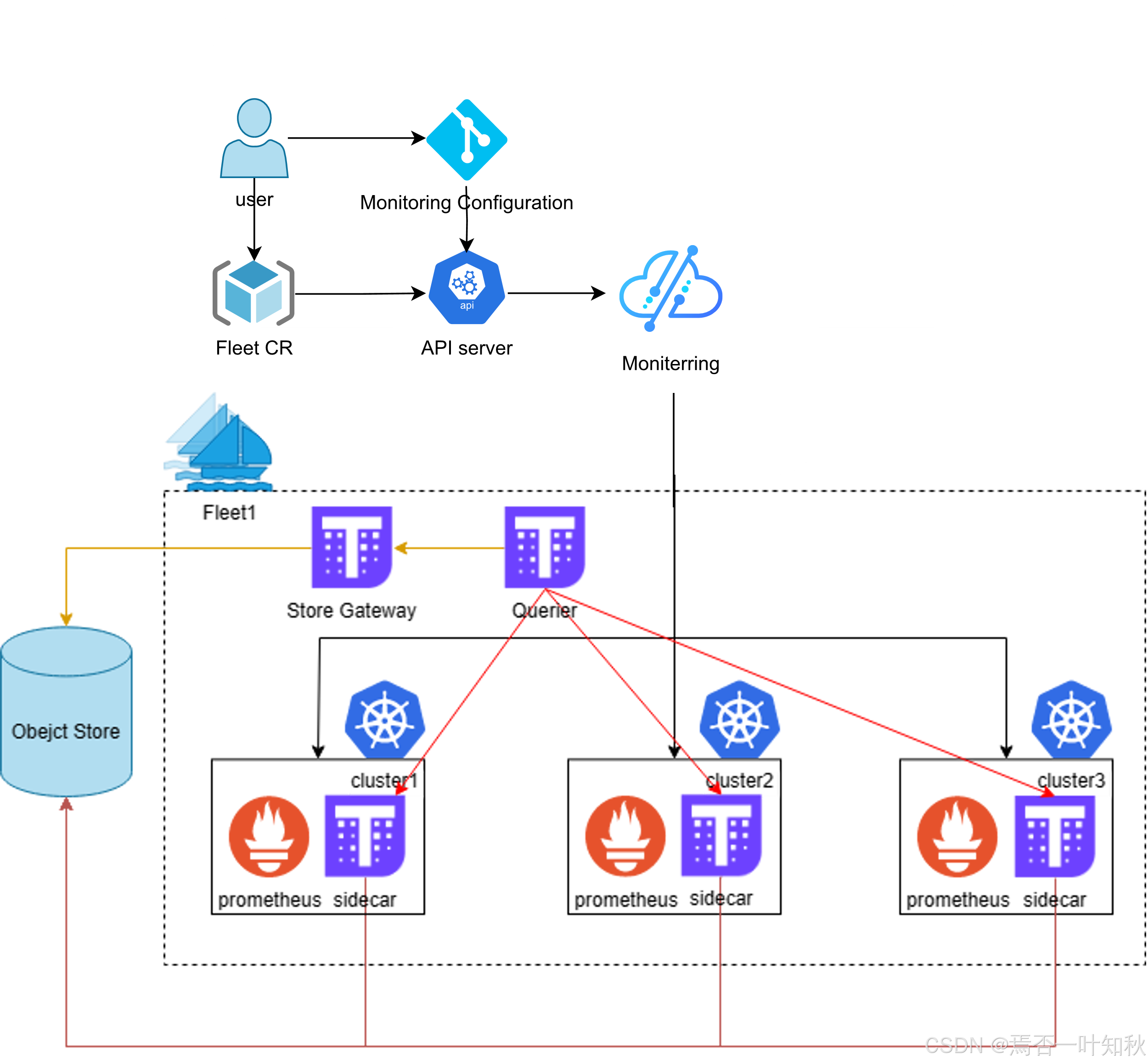
如下是Kurator的相关架构流程图,可参考:
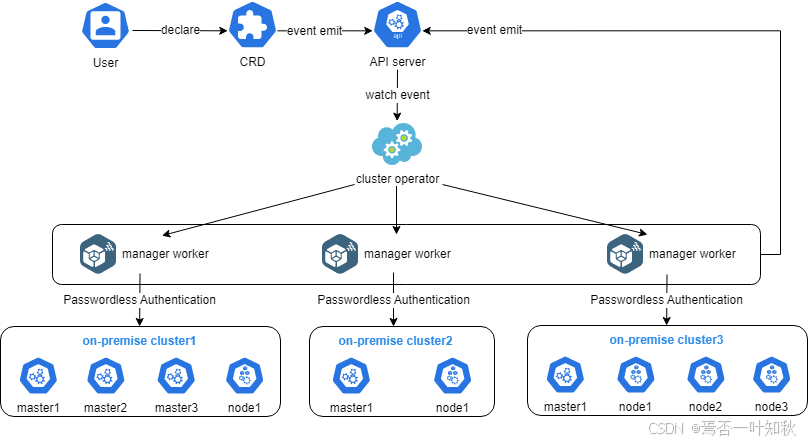
二、实践背景:从“单集群舒适区”走向“多集群现实世界”
2.1 团队和业务背景
先简单交代一下我这边的背景(你可以根据自己的实际情况改):
-
团队定位:平台基础架构团队,主要负责:
- 统一 Kubernetes 平台建设;
- CI/CD、发布系统;
- 监控告警与 SRE 体系;
- 部分内部开发者平台的能力建设。
-
业务形态:
- 有长时间运行的在线服务(ToC / ToB API 和网页应用);
- 有定时/批量任务(离线计算、报表生成);
- 有一些 AI 推理 / 训练任务;
- 还有零散的边缘设备采集数据的场景。
在最开始,我们是典型的「从单集群开始」:
- 业务全部部署在一套比较大的 Kubernetes 集群上;
- 所有环境隔离靠命名空间 + 标签 + 网关路由;
- 故障影响面经常比较大(一个集群问题,影响一大片业务)。
随着业务体量变大、场景变多,几个变化逼着我们从单集群舒适区走向多集群现实世界:
- 爆炸式增长的资源需求——单集群 size 太大,控制平面压力升高。
- 安全与合规要求——某些业务必须独占集群,或者必须部署在指定地域。
- 边缘业务——同城/异地 IDC、边缘节点需要离用户/设备更近。
- 算力类型差异——在线服务 vs AI 训练/推理,对节点和调度的要求完全不同。
于是,我们的集群从一套,慢慢扩展成:
- 若干线上生产集群(按业务域或地域划分);
- 一套或多套预发集群;
- 多套测试/实验集群;
- 一些边缘/边缘侧接入集群;
- 若干以 GPU / 高配算力为主的任务型集群。
乍一看,这样的架构挺符合「云原生」的理念,但落到平台运维同学头上,就是非常现实的几个问题:
2.2 多集群运维的现实痛点
- 集群生命周期难管理
- 新建一个集群:需要压脚本、对齐版本、申请资源、配置初始化组件、调试网络…
- 升级一个集群:得查一堆兼容矩阵,挨个验证组件,生怕动了谁就炸。
- 回收一个集群:各种遗留资源、外部依赖、DNS、存储、监控都得人肉清理。
这些事情理论上都能做,但一旦集群数量上来了,会非常消耗团队精力。
- 多集群应用分发混乱
- 有的业务是多集群部署,发布时需要手工切到不同 kubeconfig;
- 不同集群上同一个应用配置不一致:镜像 tag、资源规格、副本数、参数配置……
- 灰度与回滚策略没有统一视图,只存在脚本和脑袋里。
- 流量治理缺乏统一视角
- 即使有 Istio / Service Mesh,很多规则仍是以单集群为单位管理;
- 跨集群流量(例如边缘回源、跨地域服务调用)缺乏统一、更高层次的治理;
- 故障排查时,很难快速看到「同一个服务在不同集群上的流量策略差异」。
- 监控、告警、策略“各自为政”
- 每个集群都有一套监控配置、告警规则;
- 安全策略(如 Pod 安全策略、NetworkPolicy、OPA Policy)散落在各个仓库、环境;
- 当出现合规要求时,很难回答「我们所有集群是否都满足统一基线」。
简单总结:多集群带来了业务弹性和架构弹性,但也让平台复杂度和运维成本急剧上升。
在这样的背景下,我们给自己设定了一个目标:
我们不只是要多个 Kubernetes 集群,而是要一套「统一视角的分布式云原生平台」。
Kurator,正是我们用来尝试实现这个目标的关键组件之一。
大体流程可参考如下:
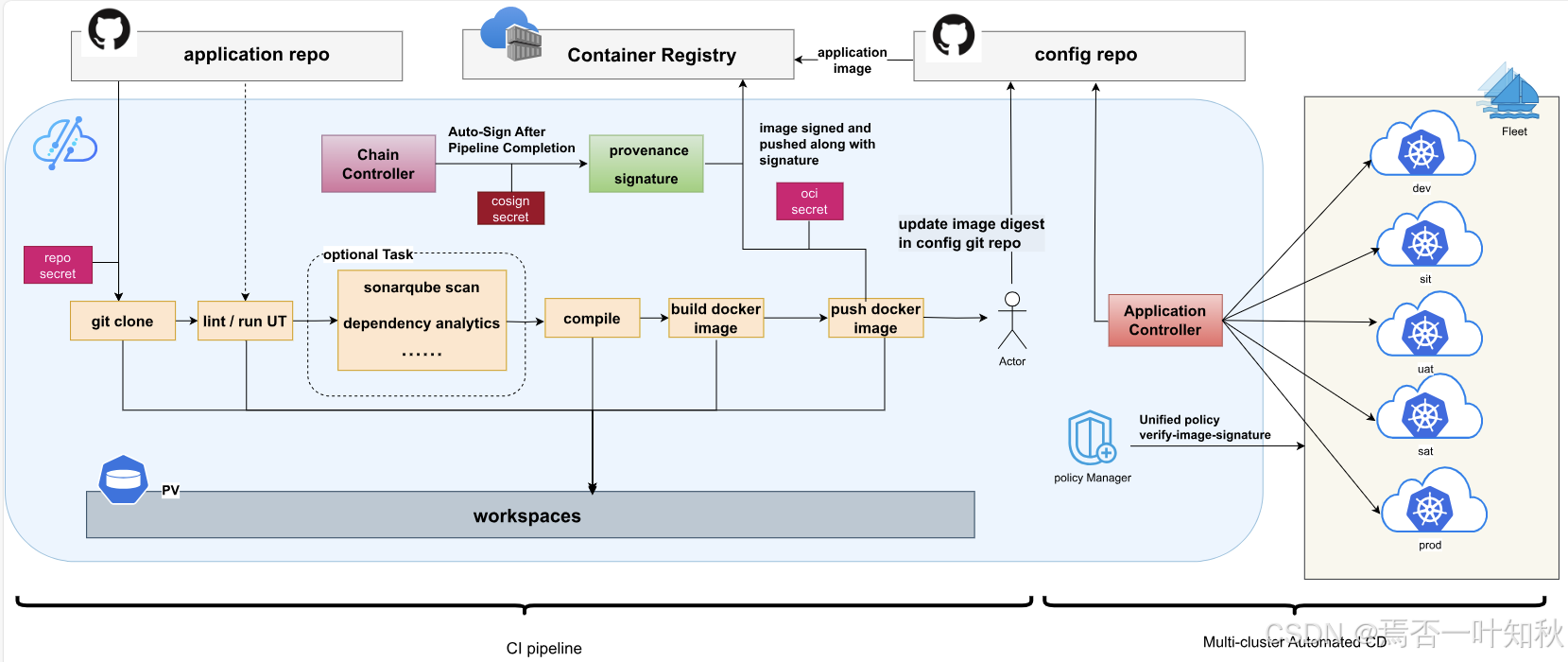
三、技术选型:为什么把 Kurator 拉进体系?
3.1 我们想要的“理想能力清单”
在正式接触 Kurator 之前,我们内部先做了一个「理想能力清单」,主要包括:
-
多集群生命周期管理
- 一处定义,批量拉起、升级、回滚集群;
- 能通过模板控制集群规格、版本和基础组件。
-
统一应用分发
- 业务盯应用,而不是盯集群;
- 同一个应用可以按策略分发到多个集群,支持差异化配置。
-
统一流量治理
- 跨集群、跨环境流量有一套统一治理模型;
- 灰度、限流、熔断、故障演练等可以在平台级配置。
-
统一观测与策略
- 多集群监控数据能汇聚成统一视图;
- 安全、合规、资源等策略可以在平台层统一下发。
-
基于开源生态,而不是完全闭源黑盒
- 希望在 Karmada、KubeEdge、Istio、Volcano 等优秀开源生态之上构建;
- 减少重造轮子,尽量发挥社区力量。
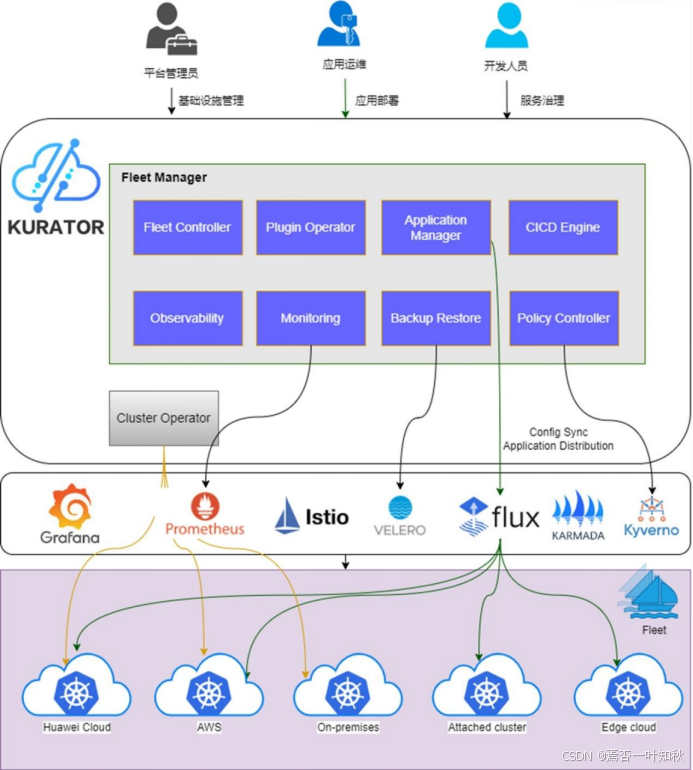
3.2 Kurator 在整个技术版图中的位置
在我们最终确立的技术架构里,Kurator 所处的位置大致如下(文字版架构描述):
-
最底层:各类基础设施
- 公有云(集群 A/B/C)
- 私有云 / IDC
- 边缘节点 / 小型 K8s 集群
-
中间层:云原生基础组件
- Kubernetes 作为基础调度与资源管理
- Karmada 用于多集群编排与资源联邦
- KubeEdge 连接云和边缘
- Istio 提供服务网格和流量治理能力
- Volcano 承接 AI/批任务调度
-
上层:Kurator
- 以「舰队管理」的视角整合上述组件;
- 提供「多集群生命周期管理、统一应用分发、统一流量治理、监控与策略统一」等能力;
- 面向平台运维和业务开发提供一个更统一的入口。
从这个位置来看,Kurator 更像是一个「平台平台」——
它不是替代 Kubernetes,也不是替代 Karmada / Istio,而是:
把一群已经非常强大的「战舰」(各个云原生组件)整成「舰队」,
并提供「舰队级」的编队、指挥和治理能力。
这个定位,是我们最终选择在现有体系中引入 Kurator 的关键原因。
而且,也可以参考如下示意图:
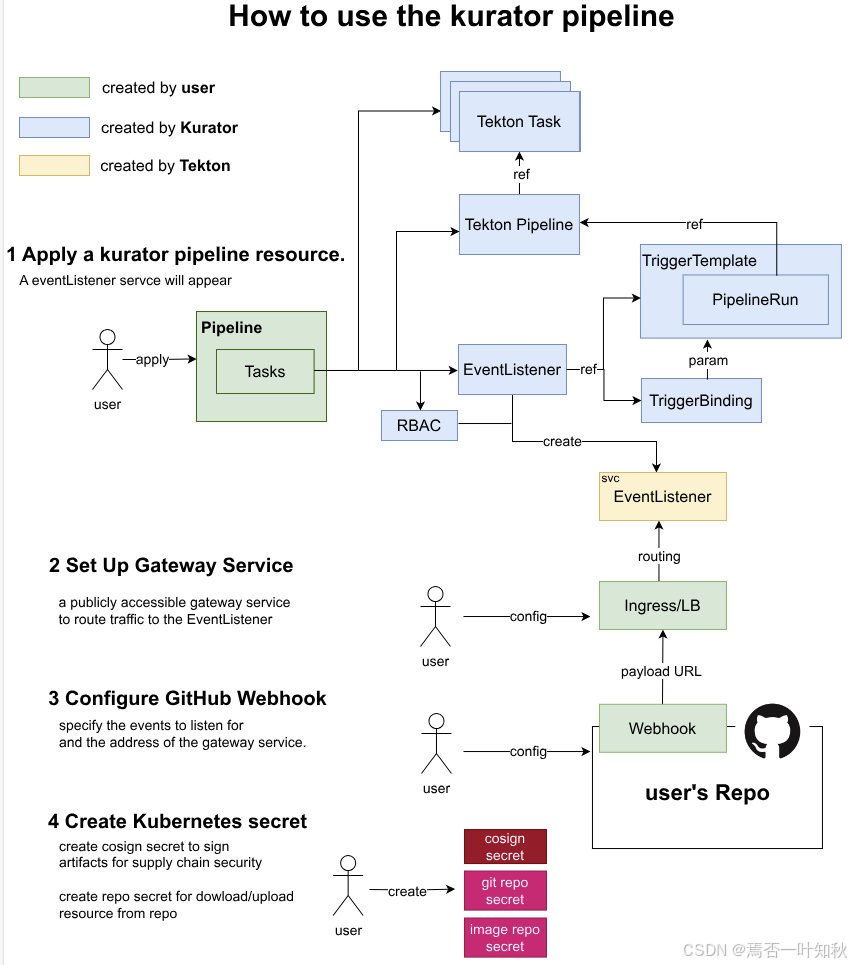
四、从 0 到 1:Kurator 分布式云原生环境搭建全过程
本节会从「实战教程」的角度,梳理我们从 0 开始搭建的完整过程。你可以根据自己的环境直接调整细节后复用。
4.1 环境规划:谁做管理集群?谁变成受管集群?
在引入 Kurator 之前,我们先做了一个非常重要的决策:选定 Kurator 的管理集群(host cluster)。
我们的考虑是:
- 管理集群本身尽量稳定、规模适中;
- 尽量不要同时承担最核心业务流量,避免两者强耦合;
- 最好是团队运维控制力比较强的一套集群。
于是,我们选择:
- 集群
cluster-admin:作为 Kurator 控制面所在的管理集群; - 集群
cluster-prod-a/cluster-prod-b:作为生产业务集群; - 集群
cluster-staging:作为预发集群; - 若干测试集群:在后续逐步接入。
边缘集群则根据业务紧迫度分批接入,避免一上来就把所有节点都拖进来导致排查困难。
4.2 安装前准备:版本、权限和基础设施
在正式部署 Kurator 之前,我们梳理了以下几个准备点:
-
Kubernetes 版本统一在一个合理区间内
- 尽量不要出现版本跨度过大的情况,例如 1.20、1.23、1.27 混在一起;
- 方便后续 Kurator 统一管理时减少 API 版本差异带来的坑。
-
kubeconfig 权限准备
- 需要为每个受管集群准备一份具备
cluster-admin权限的 kubeconfig, - 用于 Kurator 接入时创建所需 CRD、Controller 和系统命名空间。
- 需要为每个受管集群准备一份具备
-
网络连通性确认
- 管理集群需要能够访问各个受管集群的 API Server;
- 尤其是在专线/VPN/边缘场景下,需要提前打通网络或者配置好代理。
-
基础组件检查
- 检查各集群上是否已经安装 Service Mesh、监控、日志等组件;
- 评估这些组件在 Kurator 引入后,是交由 Kurator 控制,还是保持部分独立。
4.3 安装 Kurator 控制平面:从脚本到 Pod Ready
出于篇幅和版权考虑,这里不直接贴完整安装脚本,而是概述关键步骤(你可以在官方文档上对照具体操作):
-
在管理集群部署 Kurator CRD 和 Controller
- 首先应用一组 CRD 清单,使得集群中具备 Kurator 所需的资源类型;
- 然后部署 Kurator 的核心控制器和相关组件。
-
确认 Kurator 核心组件状态
- 使用
kubectl get pods -n <kurator-namespace>检查所有 Pod 是否处于 Running / Ready 状态; - 若有异常,则通过
kubectl logs检查具体报错。
- 使用
-
确认 CRD 是否已成功注册
- 可以通过
kubectl get crd | grep kurator等方式查看; - 不同版本 CRD 名称略有差异,具体可按照官方文档校验。
- 可以通过
在这个阶段,我们遇到过一个典型小坑:
-
问题:CRD 版本不兼容导致安装失败
- 现象:应用 CRD 时出现冲突或校验失败;
- 排查:发现是之前测试其他方案遗留了一部分类似资源类型的 CRD;
- 解决:清理旧 CRD 或者更换测试环境,避免遗留资源与 Kurator 定义发生冲突。
这也提醒我们:在多次试验不同开源平台方案后,最好用一个相对干净的集群来部署 Kurator 控制面。
如下是Kurator产品的官方架构图,很清晰可以看到Kurator的设计组成等:
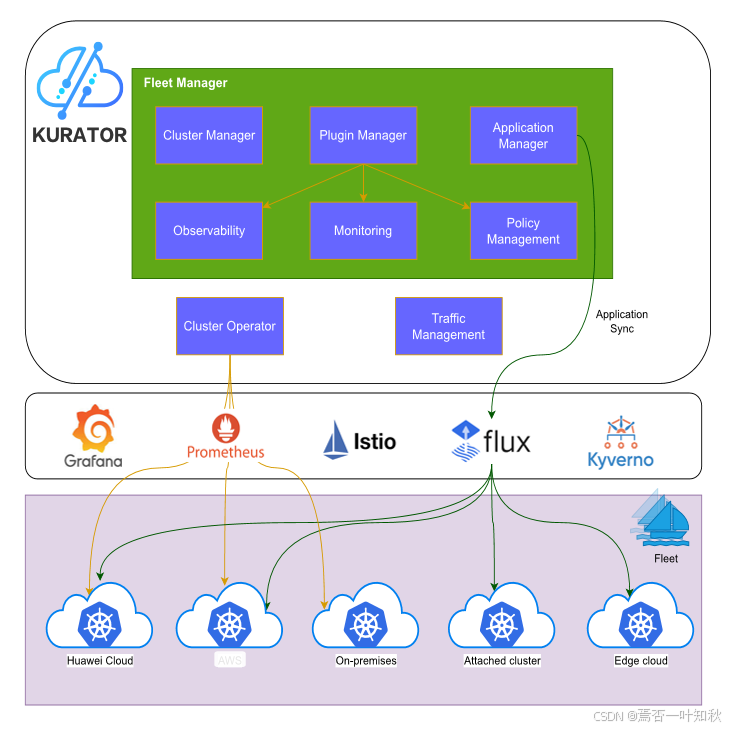
4.4 接入受管集群:把“散兵游勇”拉入“舰队编制”
安装完 Kurator 控制平面之后,下一步就是把现有的业务集群纳入 Kurator 的管理范围。
这个过程大致包括几个动作:
-
为每个受管集群准备接入描述(类似 Cluster 对象)
- 配置集群访问地址、认证信息(如 kubeconfig)、区域信息、标签等;
- 这些信息决定了 Kurator 如何访问该集群,以及后续按标签进行编组。
-
在 Kurator 管理集群中创建对应的受管集群对象
- Kurator 会根据这些对象信息,完成对目标集群的注册与探测;
- 成功后,可以在 Kurator 的视图中看到这些受管集群的基本信息和状态。
-
校验接入结果
- 确认 Kurator 能够正确拉取受管集群的节点、命名空间等基础信息;
- 若使用 Karmada 等多集群编排组件,则需要检查资源同步是否正常。
在这个过程中,我们也遇到了几个典型问题:
-
问题一:网络不通导致集群状态长时间 Unknown
-
现象:某个集群在 Kurator 视图中一直显示 Unknown 或 NotReady;
-
排查路径:
- 在管理集群节点上测试访问目标集群 API Server 是否畅通;
- 检查 kubeconfig 中的 server 地址是否为外网 / 专线可达地址;
- 检查是否有防火墙或安全组策略拦截。
-
-
问题二:权限不足导致 Kurator 无法在受管集群中创建资源
- 现象:接入之后部分功能异常,例如无法创建相关命名空间或 CRD;
- 解决:将用于接入的 kubeconfig 权限提升到
cluster-admin,或者按官方推荐配置相应的 RBAC。
-
问题三:边缘集群连接不稳定
-
现象:边缘集群的心跳状态经常波动;
-
解决:
- 在网络层面优化边缘节点与管理集群之间的链路稳定性;
- 在配置上适当放宽心跳超时策略,防止频繁抖动。
-
随着这些问题逐个排除,我们陆续把若干业务集群接入到了 Kurator 的「舰队视图」中。
从这个时间点开始,我们就不再是单纯在「多个集群页面之间来回切换」,而是在一个更上层的视角里看待集群和应用。
如下是它开源的截图展示:
而且,如下是它的一些开源数据。

五、核心能力实战体验:Kurator 是怎么帮我“减负”的?
下面这部分,是我认为最贴合「探索实战」主题、也最有参考价值的一段经历:
将 Kurator 的几个核心能力,逐个在真实业务场景中试用,并总结它们分别在运维层面产生了什么改变。
5.1 集群生命周期治理:不再人肉维护“集群黑历史”
在 Kurator 引入之前,每个集群的创建、升级、扩容、回收过程,往往长这样:
-
一堆 Shell 脚本、Ansible Playbook、Terraform 模板散落在各个仓库;
-
每个集群背后都有一些「黑历史」:
- 某个版本的 kubelet 被替换过;
- 某个节点曾被手动改过内核参数;
- 某些组件是手动部署不在 IaC 里;
-
结果是:没有一个人能完全说清某个集群“现在是个什么状态、经历过什么变化”。
而在 Kurator 模式下,我们开始尝试用一种更「声明式」的方式来管理集群生命周期:
-
定义集群模板(Cluster Template)
- 指定基础镜像、Kubernetes 版本、节点规格、基础组件等;
- 可以为不同业务场景准备不同模板(在线服务模板、离线任务模板、边缘场景模板等)。
-
使用模板创建集群
- 通过平台 API/CRD/界面,一次性完成集群创建;
- 所有集群都可以追溯到某个模板版本。
-
统一执行升级/扩容操作
- 通过 Kurator 对某一类集群执行统一升级操作;
- 或者以「滚动」的方式平滑升级,保证业务连续性。
-
集群回收与生命周期审计
- 回收集群时,Kurator 负责清理与之关联的多种资源和配置;
- 生命周期的每一次操作都可以记录在案,形成审计链路。
运维视角的变化:
-
之前:
- 集群就像一个个「活体系统」,个性化痕迹很重,生命周期管理很依赖人;
-
之后:
- 集群更像「实例化出来的模板」,生命周期有迹可循、可审计、可复盘。
这极大减少了我们在集群层面「救火」的频率和复杂度,把精力释放出来做更多平台层的抽象。
5.2 统一应用分发:用“策略”替代“复制 YAML”
统一应用分发是 Kurator 给我带来最直接体验的一块能力。
以前,我们的多集群发布体验大概是这样的:
-
CI/CD 跑完之后,生成一堆 YAML 或 Helm Value;
-
然后通过脚本将这些配置分发到不同集群;
-
每个环境、每个集群都有少量杂乱差异,比如:
- 测试环境副本数低一点;
- 某个边缘集群禁用某些功能;
- 某个海外集群使用不同的域名或配置;
-
这些差异逐渐演变成大量不可视、不透明的「环境特性」。
在 Kurator 中,我们开始用一种更「平台化」的方式来定义应用分发:
-
定义跨集群的应用描述(开箱即用也好、结合 Helm/Operator 也好)
- 描述应用的通用部分:镜像版本、服务端口、探针、基础资源需求等;
- 将差异部分通过参数化形式抽离,比如
replicaPerCluster,featureFlags,regionSpecificConfig等。
-
定义目标集群集合(舰队 / ClusterSet)
- 可以按业务线、按地域、按环境维度进行分组;
- 例如:「所有生产集群组成的舰队」、「所有边缘集群组成的舰队」。
-
定义分发策略
-
指定哪些应用分发到哪些集群集合;
-
在策略中组合应用模版和集群集合,以及差异化配置规则;
-
支持灰度策略,例如:
- 先只发一个集群;
- 再按批量扩展到更多集群。
-
-
执行分发与观测结果
- Kurator 负责在后台执行对各集群的操作;
- 在统一视图中可以看到各个集群上的部署进度、健康状态等。
带来的改变:
-
开发同学看到的是:
- 「我的应用在不同集群的状态」,而不是「N 份看起来差不多但不完全一样的 YAML」。
-
运维同学看到的是:
- 「某个策略驱动的一系列多集群发布动作」,而不是「一连串互相依赖的脚本执行记录」。
简单一句话:
Kurator 帮我们从「复制粘贴 YAML + 改几行」的操作模式,升级成了「按策略统一分发」的应用管理方式。
所以说,如果你感兴趣,可以参考官方文档部署:
5.3 统一流量治理:从“流量规则堆”到“治理视图”
在服务网格逐渐普及的今天,流量治理本身并不是稀缺能力,
但跨集群、跨环境的流量治理统一视图,依然是很多团队欠缺的一块。
在 Kurator 的实践中,我们主要针对两类场景做了尝试:
-
跨集群流量治理
- 例如:边缘集群请求需要回源到中心集群;
- 或者不同地域的生产集群之间需要做流量调度(比如计划性的流量迁移或容灾切换)。
-
统一灰度策略管理
- 不再在每个集群单独配置灰度规则;
- 而是在平台层统一定义某个应用的灰度策略,然后由 Kurator 下沉到各集群。
在 Kurator 中,这类能力通常会结合 Istio 的 Gateway、VirtualService、DestinationRule 等资源进行封装和编排。
在平台层面,我们能看到的是:
- 某个服务在整个「舰队」中的流量拓扑视角;
- 跨集群的流量路径;
- 灰度、熔断、重试策略的整体分布情况。
运维收益:
- 故障排查时,不用再「集群挨个看配置」,而是可以在平台视图中快速对比不同集群的流量策略;
- 跨集群灰度可以用统一的 YAML / 策略对象来声明,而不是靠脚本硬做;
- 对安全团队、架构团队来说,流量治理策略也更加「可解释」。
5.4 统一监控和策略管理:从“数据杂乱”到“视图统一”
监控这块的升级,是比较「润物细无声」的——
因为技术上我们一直使用 Prometheus + Grafana 等标准方案,但在 Kurator 引入之后,多了一层更统一的组织视角。
主要体现在:
-
按舰队、按业务、按环境组织监控视图
- 不再按单个集群去打开各种 Dashboard;
- 而是通过 Kurator 把这些 Dashboard 聚合在一套更上层的视图中。
-
统一告警基线与策略
-
将通用的告警规则抽象成一组「平台级策略」,由 Kurator 分发到目标集群;
-
例如:
- CPU/内存/磁盘基础告警;
- Pod 重启、CrashLoopBackOff;
- 服务延迟、错误率超标等;
-
这样可以保证不同集群的告警基线是一致的,不会出现「某个集群忘了配」的情况。
-
-
安全与合规策略统一
- 将一些 Pod 安全、网络策略、镜像安全策略等抽象为统一 Policy;
- 在 Kurator 中绑定对应集群集合,统一下发与审计。
从平台演进的角度来看,这一步的核心意义在于:
观测和策略不再是“每个集群一份”,而是 “平台一份 + 按需下发”。
六、企业级案例:用 Kurator 支撑「跨云 + 边缘 + AI」的一次升级
接下来这一节,可以视为一个完整落地案例,你可以据此改成自己公司/项目的真实经历,或者做成「半真实半虚构」的故事用于投稿。
6.1 场景概述
假设我们公司有这样一条业务线:
-
在线业务:
- Web / API 服务,面对全国用户,部署在多个地域的公有云集群。
-
边缘业务:
- 在各个城市的边缘节点部署数据采集与简单处理服务;
- 对时延较敏感,希望就近处理。
-
AI 推理业务:
- 在少数几个具有 GPU 大集群的云上执行模型推理任务;
- 同时为线上服务提供智能推荐、智能风控等能力。
我们希望:
-
有一套统一的平台来管理所有这些集群和服务;
-
能够更方便地:
- 按区域拉起新的集群;
- 将应用分发到合适的集群;
- 做跨集群流量调度和容灾;
- 统一观测和策略。
6.2 技术架构设计
在这个案例中,整体架构大致如下:
-
基础层:多云 + 边缘 + GPU 集群
-
云原生组件层:
- Kubernetes:所有集群的统一基础;
- Karmada:负责多集群资源联邦和编排;
- KubeEdge:负责边缘场景与云的连通;
- Volcano:负责 GPU / AI 任务的调度;
- Istio:负责服务间流量治理。
-
平台层:Kurator
-
负责:
- 多集群生命周期管理;
- 应用跨集群分发;
- 流量治理协调;
- 监控和策略整合;
- 在某些场景下,还负责与 CI/CD、内部平台等协同。
-
6.3 落地阶段划分
整个落地过程,我们分成了三个阶段:
-
阶段一:POC 与核心能力验证
-
选择 1 套管理集群 + 2 套业务集群,完成 Kurator 控制面部署和多集群接入;
-
在这三套集群上试验:
- 基础的集群生命周期管理;
- 简单应用的跨集群部署;
- 基础流量治理策略。
-
-
阶段二:扩展到更多集群与业务线
- 在第一个阶段稳定后,将 Kurator 的管理范围扩展到更多集群;
- 让部分较「勇敢」的业务线率先使用 Kurator 进行多集群发布;
- 同步对接监控告警、CI/CD 等已有系统。
-
阶段三:深入到边缘与 AI 场景
- 将边缘节点纳入 Kurator 体系,测试边缘场景下的应用分发和故障自愈能力;
- 在 GPU / AI 集群上尝试结合 Volcano,对推理任务与在线服务形成更紧密的联动;
- 最终建设出一套可以支撑「跨云 + 边缘 + AI」综合场景的分布式平台。
6.4 具体收益:不仅是“能跑”,而是“好管”
在这个完整案例中,我们最后梳理出的收益大概可以分成几个层面:
- 平台团队层面
- 从「到处救火 + 写脚本」变成「维护平台规则和模板」;
- 集群不再是一个个「独立世界」,而是一个个「受管对象」;
- 对集群的变更(扩容、升级、迁移)可以在统一视图下进行规划和执行。
- 业务团队层面
-
对多集群、多环境的感知被大幅弱化,只需要关心:
- 我的应用在哪些区域/环境上线;
- 它们的健康状态如何;
- 灰度和回滚策略是什么。
-
不必再记住各种
kubeconfig和上下文切换命令。
- 组织与管理层面
-
可以更清晰地回答类似问题:
- 我们现在有多少集群,分布在什么区域?
- 每个集群承担了哪些业务角色?
- 安全与合规策略有没有覆盖到所有集群?
-
当谈到跨云采购、边缘扩展、新业务接入时,有一套统一的底层「基建语言」。
七、与传统方案对比:为什么说 Kurator 更像“一栈统一”的平台中枢?
在实践 Kurator 之前,我们也走过好几条其他路线,最典型的两条是:
- 全部用脚本与自研系统来管理多集群和多组件;
- 各业务线自己搭一套小规模平台方案,平台组只负责底层集群。
对比之后,我们有几个比较深的感受:
7.1 与“脚本驱动”的多集群方案对比
-
优点:
- 脚本灵活、迭代快,遇到问题马上写一个脚本解决。
-
缺点:
- 随着集群和业务增多,脚本会越来越多、越来越难维护;
- 脚本之间互相耦合,知识高度集中在少数「老员工」手里;
- 缺乏统一的「视图」,所有事情都要从命令行和日志里一点点抠。
而 Kurator 则:
- 用统一的 CRD/策略对象,把脚本里的逻辑抽象成平台能力;
- 提供统一视图,帮你看见「整个舰队」的状态,而不仅是「一个个集群」。
7.2 与“各自为营”的小平台方案对比
-
优点:
- 每条业务线可以按自己的节奏演进;
- 平台组压力看起来没那么大。
-
缺点:
- 资源利用率低,重复建设多;
- 没有真正意义上的「企业级统一底座」;
- 安全与合规策略难以统一推进。
而 Kurator 试图做的是:
- 给整个企业提供一套统一的分布式云原生基础框架;
- 在这套框架上,不同业务线可以有差异化配置,但底层能力是统一复用的。
总结一下:
如果你正在从「单集群脚本时代」迈向「多集群平台时代」,
Kurator 提供的是一条“踩在成熟开源生态之上、往上做一栈统一”的路径。
八、Kurator 在 AI 与边缘场景下的进一步探索
最后再简单聊一下 Kurator 在 AI 和边缘场景下的一些玩法,这也是我个人比较感兴趣的方向。
8.1 结合 Volcano:面向 AI/批任务的多集群调度
当业务中有越来越多的 AI 训练、推理和大规模批处理任务时,单靠 Kubernetes 默认调度往往不够用。
Volcano 为这类场景提供了更强大的队列、优先级和任务管理能力。
在 Kurator 的框架下,可以考虑这样一种组合方式:
- 在某些特定集群中(GPU 集群、离线计算集群),部署 Volcano;
- 将这些集群纳入 Kurator 的舰队视图;
- 通过 Kurator 统一管理这些集群的生命周期和资源;
- 在业务层,通过 Kurator 的应用分发能力,将 AI 任务调度请求分流到合适的集群中。
这样做的几个好处是:
- AI 任务不再是「单集群孤岛」,而是企业整体资源池的一部分;
- 通过 Kurator,可以更清晰地掌握各 GPU 集群的负载和健康状态;
- 在有需要时,可以更平滑地把 AI 场景扩展到新的集群或新的云上。
8.2 结合 KubeEdge:云边协同的应用治理与分发
边缘场景天然有几个特点:
- 网络不稳定、带宽有限;
- 节点算力有限且异构;
- 对本地处理能力有一定要求。
在 Kurator 的场景下,我们可以:
- 使用 KubeEdge 作为边缘节点与云之间的连接层;
- 在 Kurator 中将这些边缘集群视为「舰队的一部分」;
- 通过 Kurator 的应用分发能力,在云端统一编排哪些应用应该下沉到哪些边缘点;
- 通过统一监控与策略能力,观察边缘节点的健康状态、应用运行情况。
在一次 POC 中,我们做过这样一个实验场景:
-
让边缘节点负责数据采集与初步预处理;
-
将处理结果按一定策略回传到中心集群;
-
在 Kurator 平台上,统一观察:
- 边缘节点状态;
- 应用的部署情况;
- 数据传输是否异常。
这个过程让我比较深的感受是:
云边协同不再是“单独的一套体系”,而是被 Kurator 纳入整个舰队的一部分。
九、总结与展望:下一步,我准备这么继续玩 Kurator
写到这里,差不多已经把我从 0 到 1 引入 Kurator,并在多个场景下尝试实践的一整条路径说完了。
最后,我想用几个问题来做个简单收束,也作为对下一步演进的思考:
-
对于平台团队而言:
- 我们还可以把多少「脚本逻辑」抽象成 Kurator 的策略与能力?
- 我们能否让新来的同学,在更短时间内理解「整个舰队」的结构,而不是迷失在脚本和文档中?
-
对于业务团队而言:
- 如何让他们尽量少关心底层集群,而更多从「应用在多个区域/环境的部署视角」理解平台?
- 是否可以进一步在 Kurator 的基础上,为业务侧提供更友好的自助入口和可观测面板?
-
对于企业整体而言:
- 当未来有更多云厂商、更多边缘场景和更多 AI 需求涌入时,
- 我们是否已经拥有了一套足够通用、足够弹性的基础框架去接住这些变化?
在我目前的实践视角下,Kurator 已经给了一个还不错的起点:
- 它不像某些「一体化平台」那样完全封闭;
- 它也不像仅仅是一个「多集群工具」,而是往「一栈统一的分布式云原生开源解决方案」的方向走;
- 对于像我们这样既想用好开源生态,又不想被平台复杂度压垮的团队来说,是值得投入时间和精力认真实践的一条路。
如果你刚好也在往「多集群 + 分布式云原生平台」的方向迈进,
我真心建议你可以找时间搭一个 Kurator 的测试环境,
从最简单的两个集群开始,
先用它做一次跨集群应用分发或集群生命周期管理的尝试——
可能你也会像我一样,慢慢从「集群拼装工」变成「舰队总指挥」。😄
声明:如上内容配图,部分来自网络。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)