【探索实战】搞定多云和边缘计算:手把手带你玩转Kurator云原生平台这把瑞士军刀
【探索实战】搞定多云和边缘计算:手把手带你玩转Kurator云原生平台这把瑞士军刀
你知道的,现在搞K8s,光有一个集群那哪够啊,多云、边缘计算、还要搞流水线,头都大了。Kurator 这玩意儿就是为了解决这些破事儿诞生的。它就像是一个超级管家,把你那些散落在各地的集群、边缘设备、还有乱七八糟的流水线全给统管起来。
这一块咱就得好好唠唠,Kurator 到底咋帮咱省心的。
1. 撸起袖子干:环境搭建那是第一步
说一千道一万,不动手都是耍流氓。咱得先把环境支棱起来。你也别想得太复杂,这玩意儿安装其实挺顺手的。
在我们开启正式篇章之前,我们先来学习下如何克隆Kurator项目吧,如下附上如何获取Kurator项目详细步骤教程:
我们可直接下载zip压缩包:
直接点击下载:
接下来,我们只需要解压即可。
环境搭好只是个开始,接下来的才是重头戏。
2. 舰队管理:怎么把一堆集群管得服服帖帖
在这个多云的时代,谁手里没个三五个集群啊?如果每个集群都得切来切去地操作,那运维小哥的头发早就掉光了。Kurator 引入了一个概念叫“Fleet”,也就是舰队。
舰队里的“双胞胎”:命名空间相同性
这就好比你有好几个分公司(集群),总部(Fleet)下达一个命令,说“每个人都要有个财务部”。在 Kurator 的舰队里,这就叫命名空间相同性(Namespace Sameness)。
啥意思呢?就是说,只要我在舰队层面定义了一个叫 production 的命名空间,那么这个舰队管理下的所有集群,都会自动给你生成这个 production 命名空间。你不需要跑去十个集群里敲十次 kubectl create ns。这不仅仅是省事,更重要的是一致性。你往这个命名空间里丢策略,所有集群都能吃到一样的配置,不会出现“哎呀,A集群忘了配权限,B集群配错了”这种烂事。
这是Fleet舰队中命名空间相同性的示意图,展示了多集群间命名空间的对齐逻辑与统一编排映射关系: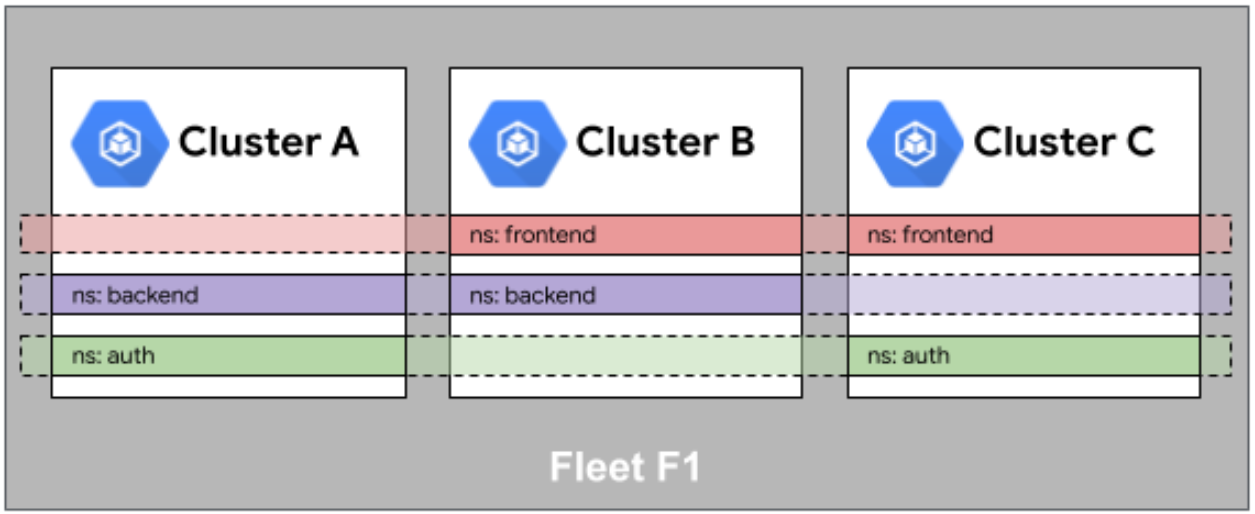
身份映射:Fleet 怎么访问外面的资源
再来说说身份映射。你的应用跑在 Fleet 里的某个集群上,它想访问外部的一个数据库,或者云厂商的一个 S3 桶,咋整?
传统的做法是把 AK/SK(密钥)写死在代码或者 Secret 里,但这太不安全了。Kurator 在这里搞了一套身份映射的机制。简单说,就是给舰队里的工作负载(Workload)发一张“通行证”。当这个工作负载要访问外部资源时,Kurator 会帮它把这个内部的 ServiceAccount 映射成外部系统能认的身份(比如 AWS IAM Role 或者 阿里云的 RAM 角色)。
这样一来,你的应用就不用揣着钥匙满街跑了,刷脸就能进门。这在多集群环境下特别好使,因为你不需要给每个集群都去配置一遍复杂的权限,在 Fleet 层面统一配置好映射规则就行。
这是Fleet访问队列外部资源的身份映射示意图,展示了跨集群服务与云平台服务账户的统一身份关联机制: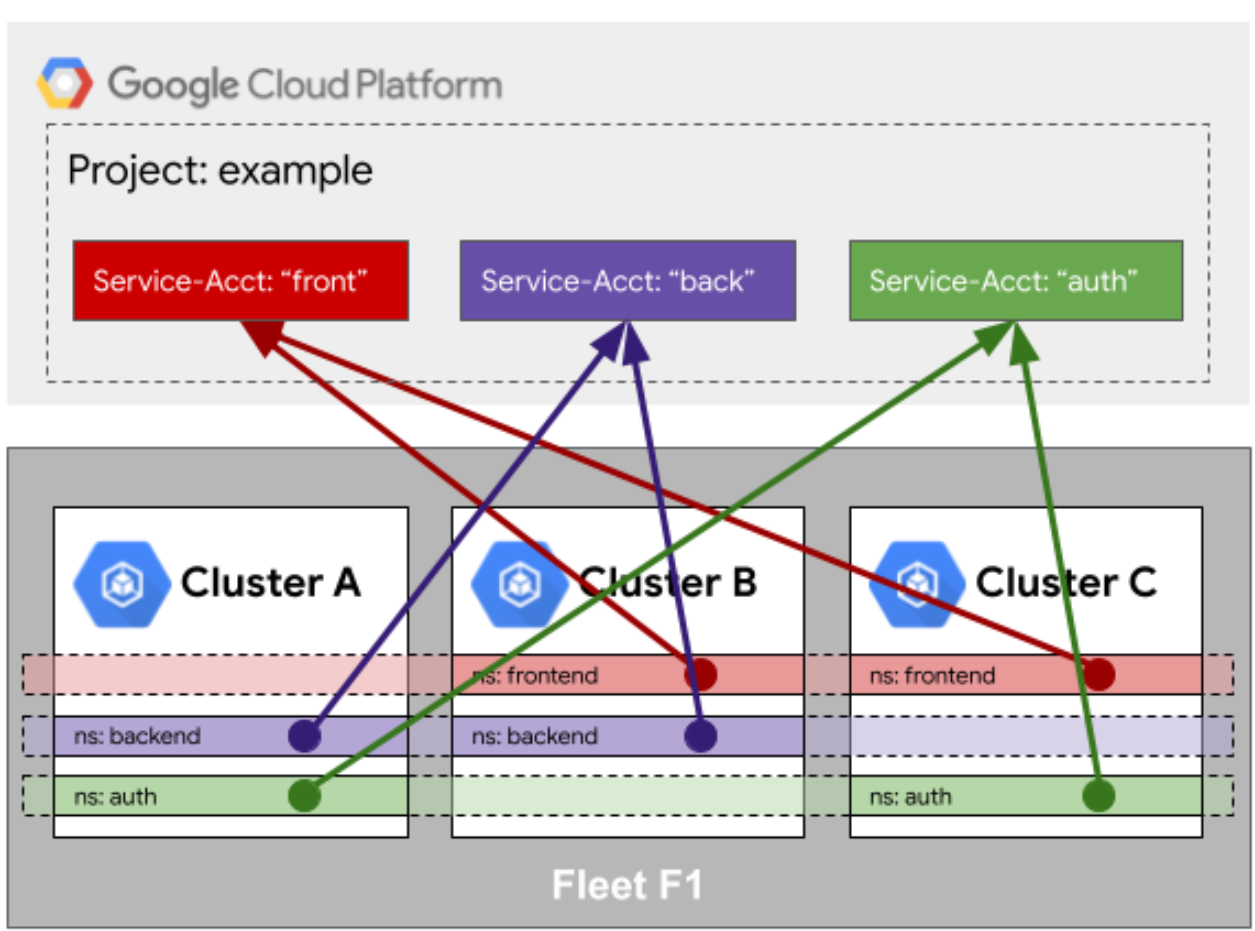
3. 应用分发与 GitOps:FluxCD 的那些事儿
现在的云原生,不懂 GitOps 出门都不好意思跟人打招呼。Kurator 在这一块集成了 FluxCD,而且把它玩出了花。
FluxCD Helm 应用在多集群下的工作流
这是FluxCD Helm应用在多集群环境下的工作流程示意图,展示了控制器如何基于Helm模板与差异化配置,实现跨集群应用的统一编排与同步: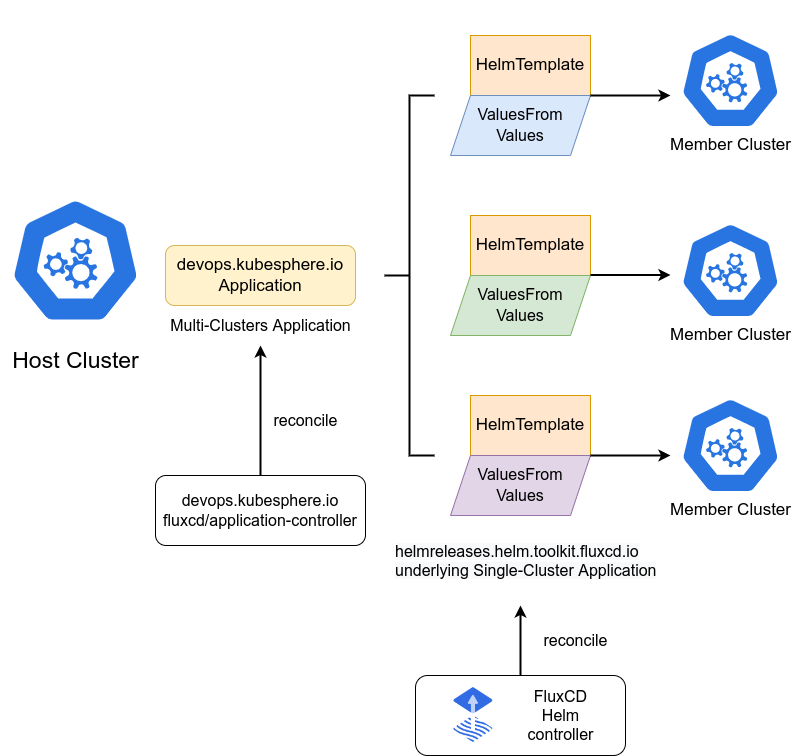
你想想,如果你要在三个集群里部署同一个 Helm Chart,比如部署个 Redis,以前你得分别去 helm install。在 Kurator 里,这事儿变成了全自动的流水线。
流程大概是这样的:
- 你先把你的 Helm Chart 或者 Kustomize 配置扔到 Git 仓库里。
- 你在 Kurator 侧定义一个
Application对象,告诉它:“嘿,盯着这个 Git 仓库”。 - Kurator(底层的 FluxCD 控制器)发现 Git 仓库更新了,它就把配置拉下来。
- 关键点来了,它会根据你定义的分发策略,看看到底该把这个应用推给谁。是推给所有集群?还是只推给打标了
region=beijing的集群? - 最后,它自动把 Helm Chart 渲染好,应用到目标集群里。
这就叫GitOps 实现方式。你的 Git 仓库就是唯一真理。你想回滚?简单,Git revert 一下,Kurator 自己就帮你把集群的状态回退回去了。
这里我给你手写一段 Application 的配置,看着就像是咱们平时调试用的:
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: my-fancy-app
namespace: default
spec:
source:
# 告诉它去哪里拉代码
gitRepository:
url: https://github.com/my-org/my-app-config.git
ref:
branch: main
interval: 1m
syncPolicies:
# 这里定义我们要分发给谁
- destination:
# 这里是个骚操作,直接选所有带标签 env=prod 的集群
fleet: my-fleet
clusters:
matchLabels:
env: prod
# 用 Helm 的方式去部署
helm:
releaseName: backend-service
chart: ./charts/backend
values:
# 还可以覆盖一些值
replicaCount: 3
4. 流量治理:金丝雀发布与流量路由
应用部署下去了,流量怎么进?怎么切?这时候 Kurator 的流量路由功能就派上用场了。它底层其实很大程度上利用了 Istio 的能力,但给你封装得更人性化了。
Kurator 的流量路由
这是Kurator的流量路由参考图,展示了其如何通过入口网关和服务网格技术,在金丝雀发布中实现精确的流量分割与路由控制: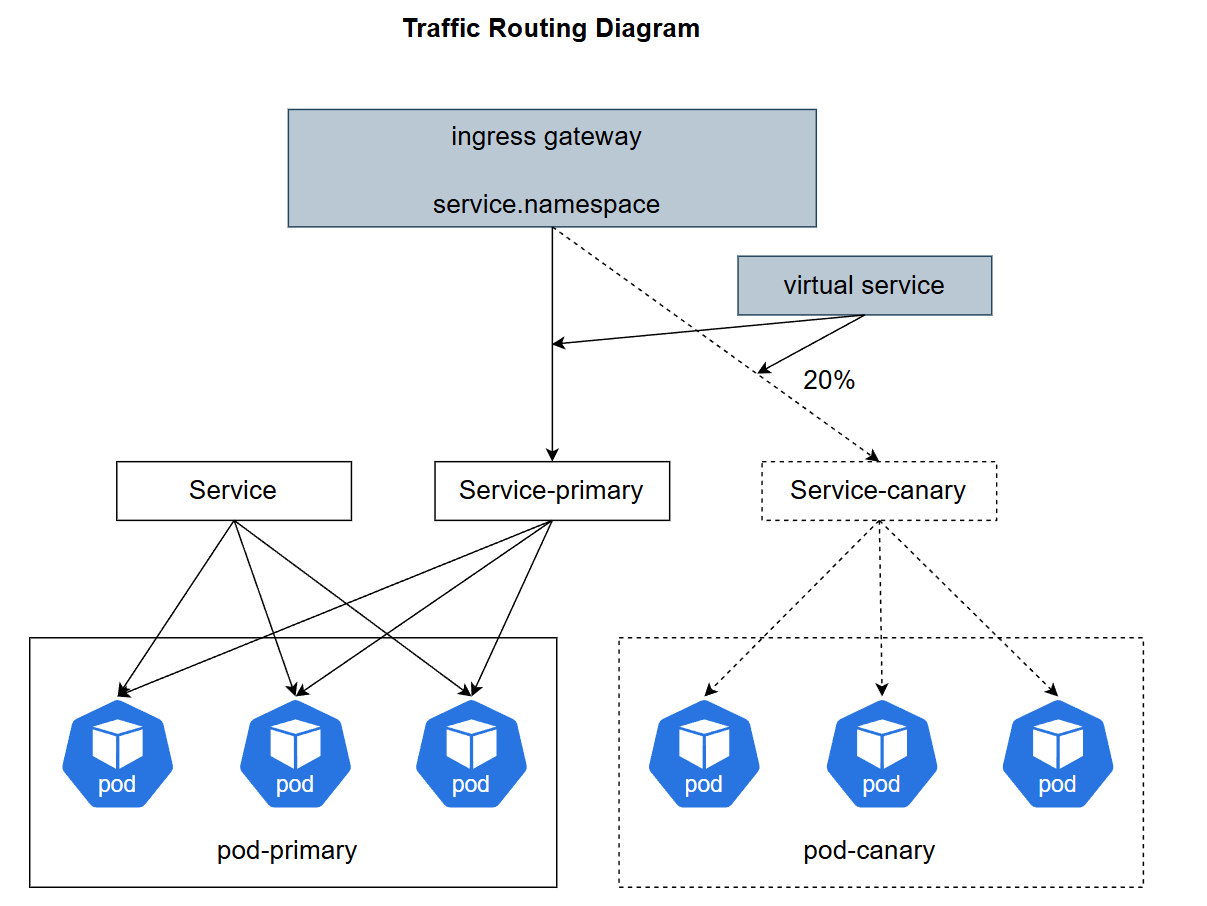
你不用再去手写那些复杂的 VirtualService 和 DestinationRule 了(虽然底层还是它们)。Kurator 让你能在更高的维度定义流量规则。比如你可以定义:来自 iPhone 用户的请求走集群 A,来自 Android 的走集群 B。或者更常见的:按照路径转发,/api/v1 走老版本,/api/v2 走新版本。
通过 Kurator 配置金丝雀
金丝雀发布(Canary Release)是咱们做平滑升级的神器。你想上新版本,但怕有 Bug 炸了,就可以先放 5% 的流量过去看看。
在 Kurator 里配置这个特别直观。你只需要在发布策略里写清楚,我要做 Canary,权重是多少。Kurator 会自动帮你去调整底层的路由权重。比如一开始是 weight: 5,观察十分钟没报错,自动调整成 weight: 20,最后 weight: 100。整个过程对用户是无感知的,如果中间出了错,监控指标一报警,它还能自动给你切回来。
这是通过Kurator配置金丝雀发布的YAML示例,展示了如何基于Istio进行流量路由、指标监控及渐进式权重调整的完整策略定义: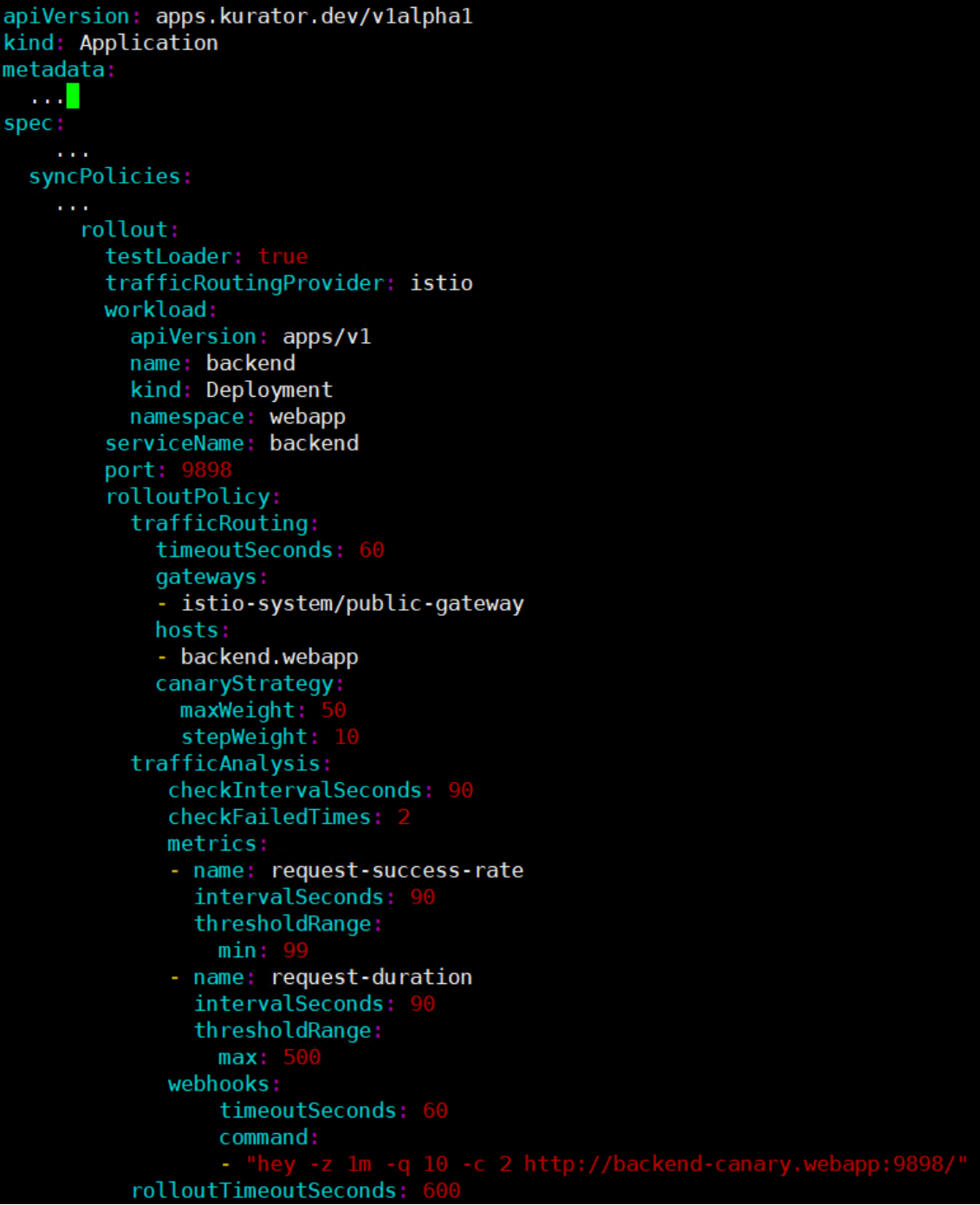
5. 云边协同:KubeEdge 的核心组件与隧道
现在很多场景都要用到边缘计算,比如工厂里的机械臂、高速公路上的摄像头。这时候就轮到 KubeEdge 出场了。
KubeEdge 云边协同架构的核心组件
这是KubeEdge云边协同架构的核心组件图,展示了云端控制平面、消息通道与边缘节点的全链路组件及交互方式: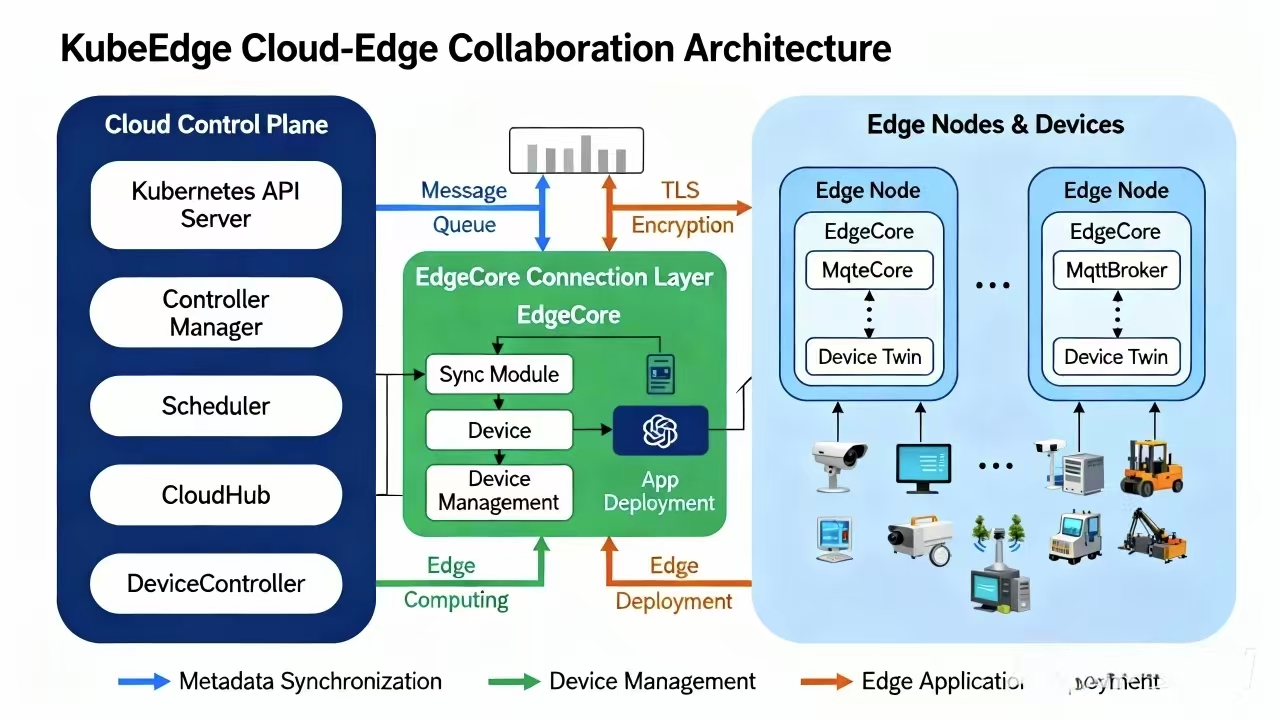
KubeEdge 把 K8s 的能力延伸到了边缘。它主要拆成了两头:
- CloudCore(云端):这是大脑,部署在你的 K8s Master 节点或者云端管控面。它负责监听 K8s 的事件,比如你创建了一个 Pod,CloudCore 就会收到消息,然后通过下行通道发给边缘。
- EdgeCore(边缘端):这是手脚,部署在那些树莓派啊、工控机啊上面。它里面有个轻量级的 Kubelet(叫 Edged),负责真正把容器跑起来。
隧道机制
云和边缘之间,网络往往是不稳定的,而且边缘设备通常躲在防火墙或者 NAT 后面,云端没法直接连过去。这时候就需要隧道机制。KubeEdge 维护了一个长连接(通常是 WebSocket),就像是打了一条专用的地道。不管边缘设备怎么变 IP,只要这条地道通着,云端的指令(比如“给我重启这个容器”)就能顺着地道滑下去,边缘的监控数据(比如“温度过高报警”)也能顺着地道爬上来。
云边协同计算场景
这种架构能干啥?太能干了。比如在这个场景里:你在云端训练好了一个 AI 模型(因为云端算力强),然后通过 Kurator 把这个模型下发到边缘的摄像头上(通过 GitOps)。摄像头在本地进行实时的人脸识别(边缘计算,低延迟),只把识别结果(比如“发现陌生人”)回传给云端。这就叫云边协同。既利用了云的算力,又利用了边的低延迟。
6. 任务调度:Volcano 的 Job、Queue 与 PodGroup
普通的 K8s 调度器对于批处理任务(比如 AI 训练、大数据分析)其实挺笨的。它只管一个一个 Pod 调度,很容易出现“资源死锁”。这时候就需要 Volcano 这个调度引擎。
Job、Queue 与 PodGroup 关系
这三个概念是 Volcano 的核心铁三角:
- Job(作业):就是你要干的那件事,比如训练一个大模型。一个 Job 会包含很多个 Pod。
- PodGroup(Pod组):这是一组强关联的 Pod 集合。Volcano 最厉害的地方就在这儿,它支持“Gang Scheduling”(帮派调度)。意思是,如果一个 Job 需要 10 个 Pod 才能跑,但资源只够起 8 个,普通的 K8s 可能会先把这 8 个起起来占坑,结果任务跑不了,资源也浪费了。Volcano 看到只有 8 个资源,它会说:“兄弟们,人不够,先别进场”,一个都不起,直到资源够了 10 个,才把整个 PodGroup 一起调度进去。
- Queue(队列):这是资源池。你可以给不同的部门分不同的 Queue,比如研发部一个 Queue,测试部一个 Queue。每个 Queue 可以设置权重和配额。Job 是提交到 Queue 里的。
关系就是:用户提交 Job -> Job 生成 PodGroup -> PodGroup 进入 Queue 排队 -> 调度器根据 Queue 的资源情况把 PodGroup 塞给节点。
来个手搓的 Volcano YAML 感受一下:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: train-model-job
spec:
# 最小得有3个跑起来,不然就别跑,这就是帮派调度的精髓
minAvailable: 3
schedulerName: volcano
# 指定放到哪个队列里排队
queue: research-dept
tasks:
- replicas: 3
name: trainer
template:
spec:
containers:
- command: ["sleep", "300s"]
image: nginx
name: trainer-container
resources:
requests:
cpu: "1"
memory: "512Mi"
restartPolicy: OnFailure
7. 最后的拼图:流水线与排查
Kurator 来搭建 CI/CD 流水线
以前我们要在 K8s 上搞流水线,可能得装 Jenkins 或者 Tekton,配置一大堆。Kurator 现在想把这个门槛降下来。它提供了一套更简化的流水线定义。你可以在 Kurator 里定义 Source(代码源)、Build(构建镜像)、Deploy(部署)这几个阶段。它会自动帮你串联起来。重点是,它是云原生原生的(Cloud Native Native…有点绕),也就是说,你的流水线本身也是 K8s 的 CRD 对象,可以用 kubectl 管理,状态一目了然。
网络连通性排查
搞这一套系统,最怕的就是网络不通。尤其是云边环境。如果你的边缘节点状态变成了 NotReady,或者应用分发不下去,通常都是网络锅。
排查的时候,你得顺藤摸瓜:
- 先看 CloudCore 的日志,看有没有报错说隧道断了。
- 去边缘节点看 EdgeCore 的日志,看它能不能连上云端的公网 IP。
- 检查防火墙,云端的 10000 端口(默认)是不是开了。
- 有时候是 CNI 插件的问题,Pod 起来了但是连不通外网,这时候得进 Pod 打个
ping试试。
总之,Kurator 就像是一个极其强大的粘合剂,它把 Fleet(多集群)、FluxCD(GitOps)、KubeEdge(边缘)、Volcano(高性能调度)、Istio(流量网格)全部串在了一起。你不再需要去分别学习怎么维护这五个原本独立的庞然大物,Kurator 给你提供了一套统一的界面和逻辑。
这玩意儿一旦用顺手了,你会发现,原来管一千个集群和管一个集群,在逻辑上其实没多大区别。这就是云原生平台化的魅力啊,兄弟们!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)