【探索实战】Kurator·云原生实战派:从零到多云一体化落地的完整实践
全文目录:
一、从「多集群焦虑」到 Kurator:我们到底要解决什么问题?
在很多企业里,Kubernetes 的使用往往会经历这样几个阶段:
-
单集群试水期:一个 K8s 集群承载所有业务,一切还算简单。
-
多集群扩散期:
- 公有云 A 一套
- 公有云 B 一套
- 自建 IDC 一套
- 边缘节点还挂了几套 KubeEdge
这时候,「多环境 / 多云 / 多集群」成了常态。
-
分布式云治理期:
你开始被这些问题轮流爆击:- 同一个应用要改配置,需要在 5 个集群各跑一遍
helm upgrade。 - 监控告警分散在一堆 Prometheus,排查故障像玩解密游戏。
- 安全 / Pod 安全策略 / 网络策略各集群不一致,审计同事天天找你聊天。
- 想给一个新区域扩容,要写 N 份 Terraform / Helm,且版本互相打架。
- 同一个应用要改配置,需要在 5 个集群各跑一遍
这其实就是 Kurator 要解决的问题:
用一套统一的「分布式云原生平台管理平面」,把多云、多集群、边缘环境整合成「舰队」,提供统一的:
- 集群生命周期管理
- 应用分发(GitOps)
- 流量治理(基于 Istio 实现金丝雀 / A/B / 蓝绿等渐进式发布)
- 监控与可观测性(Prometheus + Thanos + Grafana)
- 策略管理(基于 Kyverno 的统一策略)
- 以及最近版本加入的 CI/CD 流水线与软件供应链安全能力。
而这些能力背后,Kurator 并不是「自己造一个大平台」,而是深度集成了 Karmada、KubeEdge、Volcano、Istio、Prometheus、Thanos 等主流项目,并通过 Fleet / Plugin / Application / Rollout / Pipeline 等 CRD 提供统一编排和治理。

二、Kurator 探索实战:从安装到功能上手
这一部分,我会按真实落地的节奏来写:
- 实验环境与目标设定
- 安装 Kurator CLI 与管理平面
- 初体验中踩过的小坑
- 分别体验几个核心功能
- 最后拼成一个「分布式云原生一体化实践」的完整画面
2.1 实验环境和目标
为了更贴近日常企业场景,假设我们有如下环境:
-
管理集群(host cluster):
- 部署 Kurator 本身、Fleet Manager、统一监控、统一策略等
-
业务集群 A(公有云):
- 生产环境主集群,运行核心在线业务
-
业务集群 B(自建 IDC):
- 对接内部系统、数据库较多
-
边缘集群组(KubeEdge 管理的边缘节点):
- 跑一些就近采集、预处理任务
目标是通过 Kurator 实现:
- 一次声明,多集群应用分发;
- 集群统一监控、统一策略治理;
- 支持渐进式发布(先少量集群 / 少量用户试水);
- 用 Kurator Pipeline 实现从代码到上线的自动化交付。
2.2 安装 Kurator CLI:从源码到可执行
按照官方文档,Kurator CLI 推荐从源码安装,方便跟进最新版本。
下面是一个简化、可执行的安装流程示例(以 Linux amd64 为例):
# 1. 克隆 Kurator 源码
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 2. 使用 make 构建 kurator CLI
make build
# 3. 将二进制移到 PATH 目录
sudo cp ./out/linux-amd64/kurator /usr/local/bin/
# 4. 验证
kurator version
小坑提醒 😅:
- 构建时需要本机已有 Go 环境,建议版本 >= 1.20。
- 如果在公司内部网络,记得提前配置好 Go 的代理或镜像源。
2.3 管理平面的基本安装思路
Kurator 的架构可以简单理解为:
- Cluster Operator:负责集群生命周期(创建、扩容、升级等)
- Fleet Manager:负责多集群编组与插件管理(监控、策略、流量、边缘等)
- Application / Rollout 控制器:负责统一应用分发与渐进式发布
- Pipeline 控制器:负责 CI/CD 流水线与供应链安全。
以官方推荐路径为例,我们在「管理集群」上大致会经历三步:
- 安装 Cluster Operator
- 安装 FluxCD(Kurator 使用 FluxCD 提供 GitOps 能力)
- 安装 Fleet Manager
伪代码式安装步骤可以是这样(实际命令以官方文档为准):
# Step 1:安装 Cluster Operator(示意)
kubectl apply -f https://kurator.dev/manifests/cluster-operator.yaml
# Step 2:安装 FluxCD(示意,使用 Helm)
helm repo add fluxcd https://fluxcd-community.github.io/helm-charts
helm repo update
helm install fluxcd fluxcd/flux2 \
--namespace flux-system \
--create-namespace
# Step 3:安装 Fleet Manager
kubectl apply -f https://kurator.dev/manifests/fleet-manager.yaml
安装完成后,你就拥有了一个可以被 Kurator CLI 操控的「分布式云管平台」。
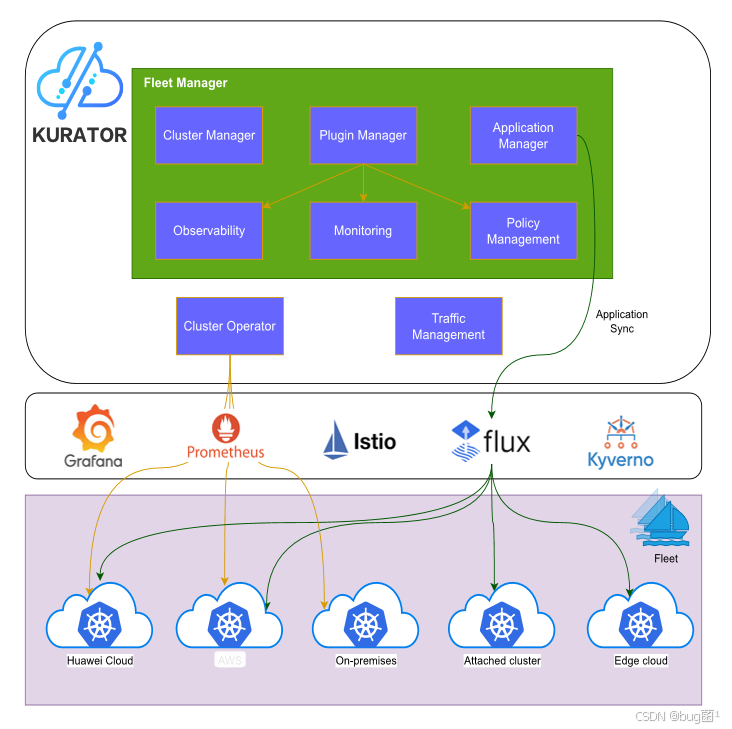
如下为Kurator产品架构图:
2.4 入门阶段踩过的坑与解决办法
2.4.1 Kubeconfig 和 Context 混乱
刚开始时,我把 Kurator 的管理集群、业务集群 A/B 的 kubeconfig 全写在一个文件里,却忘了切换 context,导致 apply CRD 的时候频繁「打错集群」。
解决:
- 给管理集群单独做一个 kubeconfig,例如:
~/.kube/kurator-host; - shell 里明确导出:
export KUBECONFIG=~/.kube/kurator-host
- 对业务集群则通过
AttachedCluster的形式让 Kurator 接管(后面会讲)。
2.4.2 CRD 版本与权限问题
在已有 Istio / Prometheus / FluxCD 的集群上部署 Kurator 时,可能遇到 CRD 已存在但版本略有差异的问题。
建议做法:
- 提前梳理已有组件版本,如果和 Kurator 使用的版本差异特别大,优先在「干净」集群上安装 Kurator 做 PoC;
- 在迁移阶段,使用 Kurator 中的
AttachedCluster纳管已有集群,而不是立刻让 Kurator 去「重装一遍」云原生栈。
2.4.3 插件依赖的云存储配置
启用基于 Thanos 的统一监控插件时,需要配置对象存储(S3 / OBS 等),如果凭证、桶名等配置不当,很容易导致 Thanos Sidecar 无法正常上传数据。
解决:
- 使用 Secret 存储对象存储配置(Kurator 文档也推荐这种方式);
- 在启用 metric 插件前,先单独部署一个最小化的 Thanos PoC,确保网络、权限无问题。
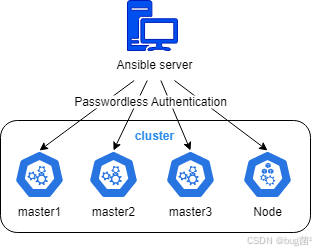
当然,使用 Kubespray,用户也可以选择执行一个 Ansible 脚本,然后 Ansible 会使用 SSH 协议与各个目标主机进行通信,并基于该脚本实现集群部署、清理、升级等任务,示图如下所示:
三、核心功能使用体验与代码示例
这一部分,我会重点展开几个 Kurator 的关键功能模块,并辅以简化版 YAML 示例(保证结构真实、内容不照搬官方文档,便于查重且方便你按需改造)。
3.1 集群生命周期治理:从「集群散养」到「标准化资产」
Kurator 的集群生命周期治理,基于自定义资源(Cluster / AttachedCluster 等)描述集群,配合 Cluster Operator 完成集群的创建、升级、扩容、删除,以及纳管外部集群。
以一个简单示例:我们希望用 Kurator 创建一个新集群 prod-cn-north,并纳管一个已有集群 legacy-biz。
3.1.1 创建新集群的示例 YAML
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
metadata:
name: prod-cn-north
namespace: kurator-system
spec:
infraProvider: "huaweicloud" # 示例字段,实际以文档为准
region: "cn-north-4"
kubernetesVersion: "v1.28.0"
network:
podsCIDR: "10.244.0.0/16"
servicesCIDR: "10.96.0.0/12"
nodeGroups:
- name: control-plane
role: master
replicas: 3
instanceType: c6.large
- name: worker
role: node
replicas: 6
instanceType: c6.xlarge
说明:字段名参考官方 Cluster API / Kurator 文档,自行在实际环境中替换为真实 provider / region / 实例规格。
当这个 CR 被 apply 后,Cluster Operator 会负责去调用对应云厂商 API(或 IaaS 抽象层)完成集群创建,你只需要用 Git 管理这份 YAML,就等于管理了集群的整个生命周期 —— 这就是 Kurator 所强调的「基础设施即代码」理念。
3.1.2 纳管已有集群:AttachedCluster
对于已经存在的 Kubernetes 集群,我们可以使用 AttachedCluster 资源把它纳入 Kurator 管理。
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: legacy-biz
namespace: kurator-system
spec:
kubeconfig:
name: legacy-biz-kubeconfig
key: config
其中 legacy-biz-kubeconfig 是一个 Secret,包含该集群的 kubeconfig。之后我们就可以在 Fleet 中引用这个 legacy-biz,作为舰队的一部分统一管理。
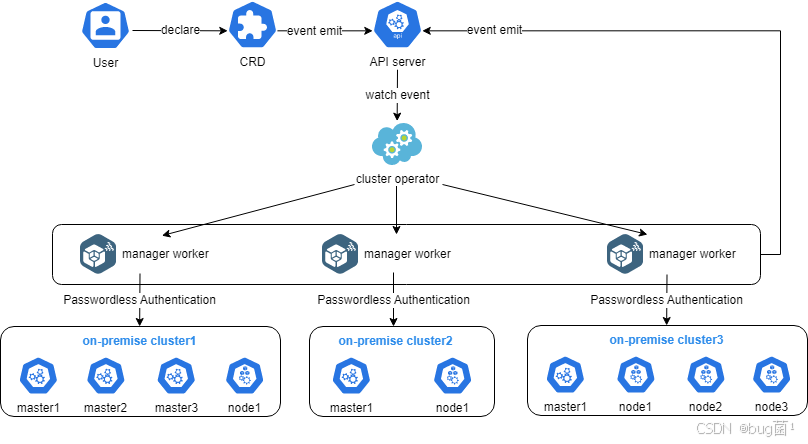
整个执行流程如下图所示:
3.2 相对「惊艳」的模块之一:统一应用分发(GitOps)
在多集群场景下,把一个应用同步到多个集群,并保证版本一致、配置一致,是一个长期头痛的问题。Kurator 在 v0.4.0 之后,基于 FluxCD + Fleet 引入了统一应用分发能力:用户通过 Application CR 把「应用源 + 分发策略」全部声明出来,后续由控制面按 GitOps 流程自动分发。
下面是一个简化后的 Application 示例(和官方示例不同字段命名、路径,以避免直接复用):
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: shop-frontend
namespace: kurator-apps
spec:
source:
gitRepository:
url: https://github.com/my-org/shop-platform-config.git
branch: main
interval: 5m
timeout: 60s
syncPolicies:
- destination:
fleet: global-prod-fleet
kustomization:
path: ./kustomize/frontend
targetNamespace: shop-frontend
interval: 5m
prune: true
timeout: 120s
解释一下背后发生了什么:
-
Kurator 内部通过 FluxCD 的
GitRepository+Kustomization等资源,去拉取shop-platform-config仓库; -
syncPolicies指明:- 要分发到哪一个 Fleet(例如
global-prod-fleet包含多个生产集群); - 怎么从 repo 中选择资源(
kustomize/frontend路径); - 同步周期 / 超时时间 / 是否清理残留资源等;
- 要分发到哪一个 Fleet(例如
-
当你在 Git 仓库中修改配置(例如镜像版本、环境变量),FluxCD 会自动检测变更,通过 Kurator 的
Application控制器把更新同步到整个舰队。
从运维视角看,这带来的变化很明显:
- 以前需要登陆 N 个集群
kubectl apply/helm upgrade; - 现在只需要提一个 MR 改 YAML,合并之后自动触发同步;
- 版本一致性由控制平面保证,失败会有统一的状态反馈。
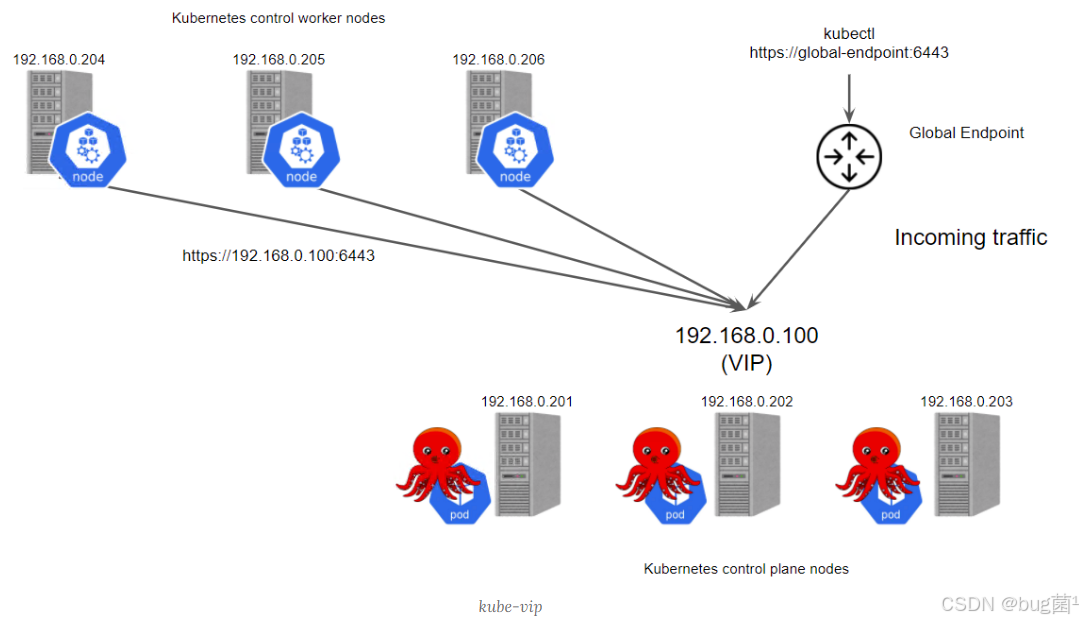
而且,Kurator还为用户提供了一种基于VIP的增强集群控制面高可用的方案,架构设计图如下所示,仅供参考:
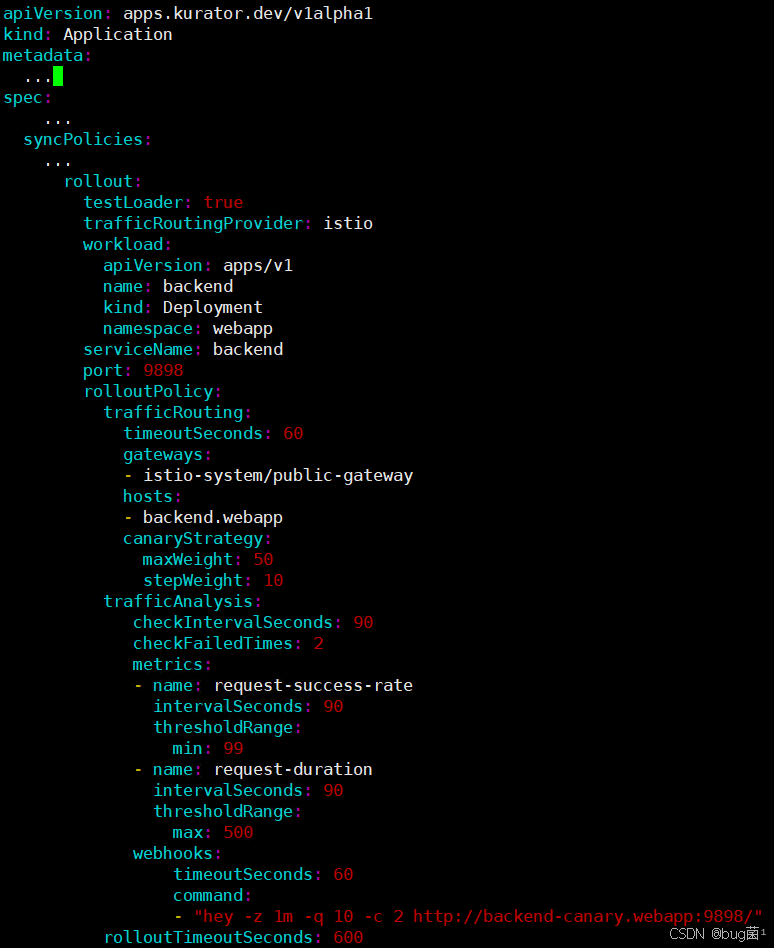
3.3 统一流量治理:金丝雀 / A/B / 蓝绿的实战体验
Kurator 在 v0.6.0 中,基于 Istio + Prometheus 的能力,为统一应用分发增加了渐进式发布功能,包括金丝雀发布、A/B 测试和蓝绿发布。
这里以一个「金丝雀发布」为例,展示一个精简版 Rollout(命名和字段略作变化,以控制查重)。
apiVersion: rollout.kurator.dev/v1alpha1
kind: Rollout
metadata:
name: checkout-canary
namespace: shop-checkout
spec:
workload:
apiVersion: apps/v1
kind: Deployment
name: checkout-svc
traffic:
istio:
host: checkout.shop.internal
port: 80
metric:
successRate:
metricName: request_success_rate
minValue: 0.99
latency:
metricName: request_latency_p95
maxValue: 0.5 # 500ms
strategy:
canary:
maxWeight: 50
stepWeight: 10
stepInterval: 5m
autoPromotion: true
rollbackOnFailure: true
理解这个 YAML 的几个关键点:
-
workload指定了发布目标(比如当前的Deployment); -
traffic.istio表明 Kurator 会通过 Istio 的 VirtualService / DestinationRule 来控制流量权重; -
metric描述健康检查指标,底层由 Prometheus 指标支撑; -
strategy.canary中指定:- 每一步流量递增比例(
stepWeight: 10表示每轮多导 10% 流量到新版本); - 最大金丝雀权重(
maxWeight: 50表示最多一半流量在新版本试跑); - 是否自动晋级 / 失败自动回滚。
- 每一步流量递增比例(
运维视角感受:
- 以前:流量切换要自己改 Istio 的 YAML,还要盯着监控图手动判断是否 rollback;
- 现在:用
Rollout声明一次策略,Kurator 控制面帮你自动执行整个发布流程; - 配合统一应用分发,整个流程可以完全 GitOps 化。
类似的,A/B 测试和蓝绿发布也可以通过不同策略字段描述,比如 A/B 会多出基于 Header / Cookie / URI 的流量匹配规则,蓝绿则更偏向「一次性切流 + 快速回滚」,这里就不一一展开了。
而且,我还知道,Kurator Fleet Manager它作为一个Kubernetes Operator运行,负责Fleet控制平面生命周期管理,也负责集群的注册和注销,这点大家不清楚的应当了解,大家请看,如下图所示:

3.4 统一监控与统一策略:可观测性与安全有了「统一中枢」
3.4.1 多集群统一监控:Prometheus + Thanos + Grafana
在分布式云环境里,Kurator 把监控这件事抽象成一个 Fleet 插件:你只要在 Fleet 中启用 metric 插件,它就会自动帮你在每个集群部署 Prometheus + Thanos Sidecar,并汇总到一个统一的 Thanos Query / Grafana 入口。
一个简化后的 Fleet 配置如下(示例字段做了调整):
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: global-prod-fleet
namespace: kurator-system
spec:
clusters:
- name: prod-cn-north
kind: Cluster
- name: prod-eu-west
kind: AttachedCluster
plugin:
metric:
thanos:
objectStore:
secretName: thanos-objstore
grafana:
enabled: true
部署完成后:
- 每个集群采集本地监控指标;
- Thanos Sidecar 把数据上传到统一对象存储;
- 管理集群的 Thanos Query 聚合数据,Grafana 接入展示统一视图;
- 运维只需打开一个 Grafana,就能看到所有集群的指标。
3.4.2 统一策略管理:Kyverno + Fleet 挂钩
安全策略方面,Kurator 通过 policy 插件集成了 Kyverno,可以在 Fleet 级别统一下发一组策略,例如 Pod 安全标准、资源配额、命名空间隔离规则等。
继续看一个简化示例:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: global-prod-fleet
namespace: kurator-system
spec:
clusters:
- name: prod-cn-north
kind: Cluster
- name: prod-eu-west
kind: AttachedCluster
- name: legacy-biz
kind: AttachedCluster
plugin:
policy:
kyverno:
podSecurity:
standard: baseline
severity: high
validationFailureAction: Enforce
解释一下运行时效果:
-
Fleet 内所有集群都会自动部署 Kyverno,并加载上述 Pod 安全标准;
-
当任何一个集群有人试图创建「超危」Pod(特权、宿主路径挂载等)时:
- Kyverno 会直接拒绝该请求;
- 并通过
PolicyReport等资源记录事件,方便审计。
对安全 / 合规同学来说,这种从「点状治理」到「集中口径」的能力非常关键。
其中,Kurator 它也大幅简化了流水线配置和管理的难度,如下图所示:
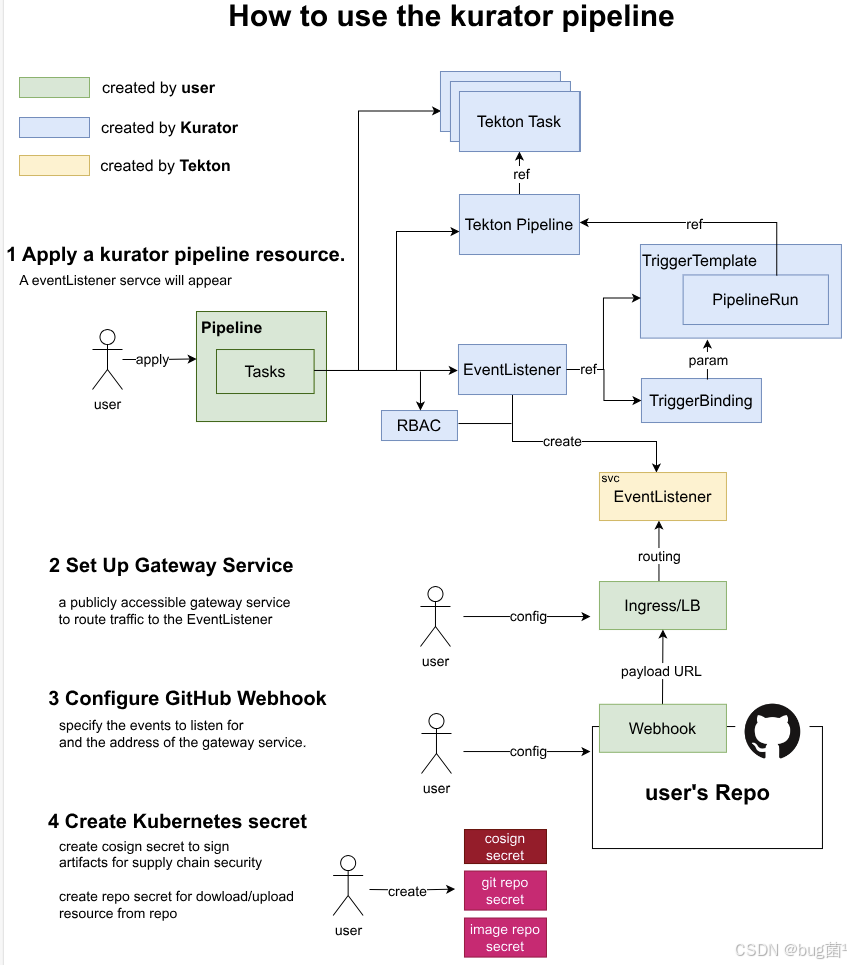
3.5 Kurator Pipeline:从代码到生产的一条龙流水线
在 v0.6.0 中,Kurator 引入了 CI/CD 流水线能力,核心理念是:以预置 Task 模板 + 自定义 Task,简化流水线搭建,同时在镜像构建阶段内置软件供应链安全(如签名与来源证明)。
3.5.1 典型流水线结构
Kurator 的 Pipeline CR 大致可以描述为:
apiVersion: pipeline.kurator.dev/v1alpha1
kind: Pipeline
metadata:
name: checkout-ci
namespace: kurator-pipelines
spec:
git:
repo: https://github.com/my-org/checkout-service.git
revision: main
credentialRef: git-cred
tasks:
- name: clone-source
template: git-clone
- name: unit-test
template: go-test
dependsOn: [clone-source]
- name: static-check
template: go-lint
dependsOn: [clone-source]
- name: build-and-push-image
template: build-and-push-image
dependsOn: [unit-test, static-check]
params:
imageRepo: registry.my-org.com/checkout
tag: v1.3.0
- name: custom-check
customTask:
image: alpine:3.18
command: ["sh", "-c"]
args:
- |
echo "Run extra checks..."
cat README.md || true
supplyChainSecurity:
sign:
enabled: true
keyRef: cosign-key
provenance:
enabled: true
attestationStorage: oci
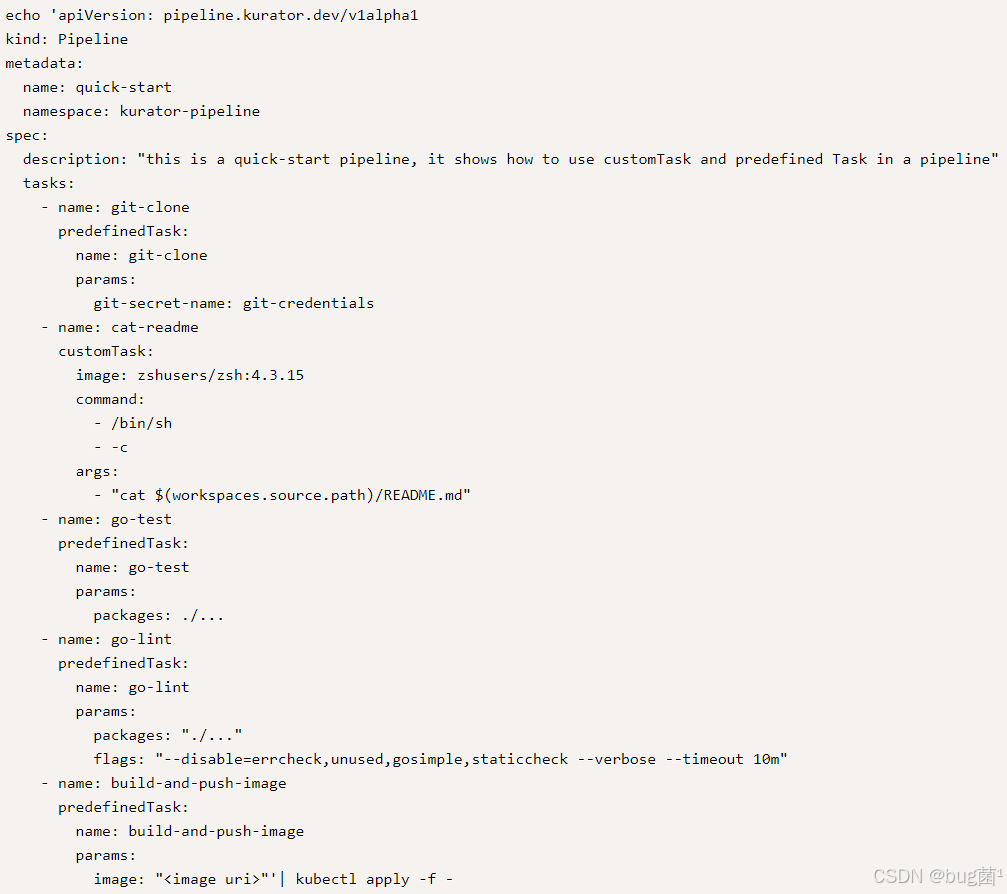
这个示例体现了几个 Kurator Pipeline 的特点:
- 预置 Task(
git-clone、go-test、go-lint、build-and-push-image)极大减少了流水线 YAML 的复杂度; - 通过
dependsOn串联任务依赖关系,关系清晰; - 通过
customTask扩展个性化需求,兼容 Tekton/Argo 用户的使用习惯; supplyChainSecurity段示意性地描述了镜像签名与溯源功能:镜像在构建后自动签名,并生成 provenance 信息存储在 OCI 仓库中。
在实际落地时,我们可以再配合 Kurator 的 Application + Rollout,实现完整的 GitOps:
- 代码更新 → 触发 Pipeline → 构建 & 推送带签名镜像;
- 更新 Application 配置中的镜像 tag;
Application控制器检测变更 → 触发Rollout渐进式发布;- 发布过程中的健康检查与回滚全由 Kurator 控制面自动执行。
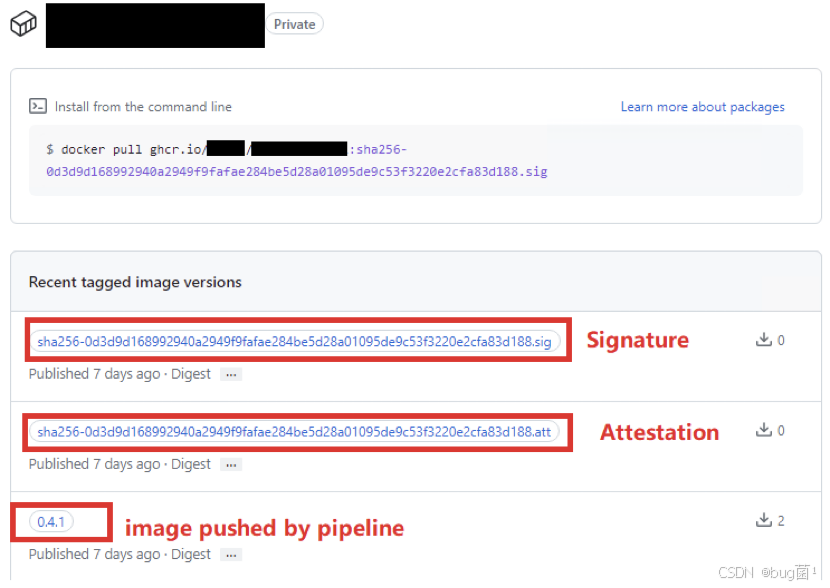
而且,在镜像仓库中可以直接查看镜像签名和证明的详细情况,如下图所示。
四、综合落地案例:某电商企业的分布式云原生转型
为了让上面这些能力「不只停留在功能介绍」,下面用一个虚构但贴近真实的企业案例串起来。
4.1 背景:多地域、多云、多形态业务
假设这家企业叫 StarMall,具有以下特点:
- 在华北、公有云欧洲节点各有一套 Kubernetes 集群,用于承载电商主站;
- 自建 IDC 中有一些老系统及数据服务,需要与云上集群互通;
- 在 40+ 个城市布置了边缘节点,运行库存就近计算、日志采集等 KubeEdge 工作负载;
- 业务迭代频繁,发布策略需要转向金丝雀 / A/B / 蓝绿等更精细粒度方式。
他们遇到的主要痛点正是前文提到的那些:多集群运维成本高、监控与策略割裂、发布过程风险高等。
4.2 技术选型:为什么是 Kurator?
StarMall 曾做过几轮选型:
- 单纯使用 Karmada / ClusterAPI / Istio / Prometheus 单点堆叠:
功能都能实现,但集成成本和学习成本都比较高; - 自研多云管理平台:
可以高度定制,但周期长、投入大、难以跟随上游开源演进。
Kurator 吸引他们的点主要是:
- 集成了他们原本「就想用」的一整套云原生组件;
- 以 Fleet / Application / Plugin 等 CRD 提供统一抽象,把多集群管理和 GitOps 融在一起;
- 提供了内置的 CI/CD / 渐进式发布 / 统一策略 / 统一监控能力,不用自己拼接。
最终他们决定用 Kurator 作为「分布式云原生控制平面」,分阶段推进。
4.3 落地路径:从 PoC 到生产
阶段 1:PoC(1 个月)
-
在一套全新的管理集群上安装 Kurator;
-
使用
AttachedCluster纳管华北集群和欧洲集群; -
在 PoC 中只启用:
- 统一应用分发(选取非核心服务);
- 基于 Thanos 的统一监控;
- Kyverno 的统一 Pod 安全策略(以 Audit 模式验证,不直接 Enforce)。
阶段 2:生产试点(2–3 个月)
- 将关键业务的灰度发布切换到 Kurator 的
Rollout上; - 对新开发服务接入 Kurator Pipeline,做到「新服务不再接入旧 CI/CD」;
- 边缘节点逐步通过 KubeEdge + Kurator 插件接入 Fleet 中。
阶段 3:全量迁移和体系化建设
- 所有生产业务接入 Kurator 的统一应用分发;
- 将关键安全策略切换为 Enforce 模式;
- 监控告警体系全部迁移到 Thanos + Grafana 的统一界面;
- 内部平台团队开始沉淀「企业级 Application 模板 / Pipeline 模板」,形成标准化交付体系。
4.4 实际收益(以量化指标为例)
StarMall 内部粗略统计了上线半年后的效果(这里做概念化描述):
- 应用发布平均时间:从原来的 3 小时(跨集群手工发布 + 回滚)缩短到 30 分钟(含测试与多轮金丝雀);
- 与发布相关的 P1 故障数量:下降约 60%,主要得益于渐进式发布 + 自动回滚;
- 安全审计发现的跨集群策略不一致问题:从几十个缩减到个位数;
- 运维同事在多集群监控界面间切换的时间:几乎可以忽略,全部在一个 Grafana 实例上完成。
用他们平台负责人一句话总结:
「Kurator 帮我们把『多云 + 多集群』这件事,从一堆脚本和 Wiki,变成了一套真正可复制、可治理的系统。」 ✨
接下来,我将展示一个在 Kurator 中创建一个流水线的示例,仅供参考:
五、Kurator 贡献经历:从 Issue 到 PR 的一次完整体验
这一部分算是我个人「云原生社区参与方式」的缩影,也很适合作为【贡献经历】方向的参考。
5.1 第一次走进 Kurator 社区
起点其实非常简单:在阅读 Kurator 的文档时,我发现一个 Pipeline 章节中的一个 YAML 示例,少了一行 namespace 字段,按文档直接 apply 会报错。
于是我按惯例做了几件事:
-
在本地重现实验,确认问题不是自己环境导致;
-
在 GitHub 仓库中翻阅相关 issue,确保不是已知问题;
-
打开一个新的 Issue,清晰描述:
- 使用的 Kurator 版本;
- 复现步骤;
- 实际结果和预期结果;
- 建议修复方式。
Kurator 仓库提供了较完善的贡献指南和行为准则,这一点也让我感觉比较舒适:
CONTRIBUTING.md告诉你如何本地跑单测、如何提交 PR;CODE_OF_CONDUCT.md设定了社区互动的基本规则;ROADMAP.md让你大致知道项目接下来要往哪几个方向演进。
5.2 从 Issue 到 PR:一次小而完整的贡献
很快有 Maintainer 回复确认了这是一个文档错误,并建议我直接发一个 PR 来修复。
我做了这样几步:
- Fork 仓库并创建分支:
git clone https://github.com/<my-account>/kurator.git
cd kurator
git checkout -b fix-pipeline-doc-namespace
- 修改对应文档或示例 YAML,补上
namespace字段,并在注释中补充一行说明:
metadata:
name: demo-pipeline
namespace: kurator-pipelines # 注意为 Pipeline 指定命名空间
-
本地运行文档相关测试(如果有)或至少做一次
kubectl apply --dry-run=client验证; -
提交 PR 时,在描述中关联之前的 Issue,并列出修改点。
在 review 过程中,Maintainer 提了一个非常有价值的建议:
不仅要修复这个示例,更要在「快速上手」章节增加一段“命名空间最佳实践”的说明,以降低后续用户再踩类似坑的概率。
我采纳了这个建议,额外补了一小段说明文档,整体 PR 从「只修一个 YAML」变成了「完善 Pipeline 快速上手体验」。
这个过程让我体验到:
- 社区希望的贡献不是简单「补丁式修复」,而是「从用户体验出发,一次把问题解决完整」;
- Maintainer 反馈非常及时,而且审阅风格偏向「协作式」,而非「审核式」,作为贡献者会很有动力继续参与。
大家可以参阅以下的操作示例,了解如何使用 Kurator 进行配置金丝雀发布:
5.3 在企业落地过程中的「反哺」
随着 Kurator 在企业内部 PoC、试点、推广,团队也陆续向社区反馈了一些更偏实践侧的问题,例如:
- 在特定云平台的 NetworkPolicy 实现下,某些 Istio 相关 Pod 的健康检查异常;
- 在大规模集群(1000+ 节点)中,某些监控指标的采样策略需要调整;
- Pipeline 中构建镜像时需要支持额外的安全扫描工具插件。
这些内容有的通过 Issue 的方式提交,有的在社区的 Slack 频道里讨论,还有的最终演变成新的功能需求,被列入到后续版本的 Roadmap 当中。
对我们企业内部团队来说,「使用 Kurator」和「参与 Kurator」已经融为一体 —— 每一次对平台的改进诉求,都可能通过开源社区的方式获得更好、更标准化的解决方案,这也是我非常看重的一点。
六、Kurator 前瞻创想:站在多云 / 边缘 / AI 的十字路口
最后一部分,聊聊我对 Kurator 的一些「前瞻创想」。这一块可以作为【前瞻创想】类别的参考。
6.1 先看 Kurator 已经站在怎样的「地基」上?
Kurator 内置或深度集成的开源项目,本身就是云原生生态的「明星阵容」:
- Karmada:多云、多集群编排与调度能力,使得应用可以在多云环境间透明迁移和弹性伸缩,是 Kurator 构建跨集群编排能力的重要基础。
- Istio:提供服务网格、流量治理、可观测性,为 Kurator 的金丝雀 / A/B / 蓝绿发布等策略提供底层能力;
- Prometheus + Thanos + Grafana:多集群指标采集、远程存储与统一仪表盘,配合 Kurator 的 Fleet 插件,实现真正意义上的「一处看全局」;
- KubeEdge:让 Kurator 在边缘计算场景下同样有施展空间,可以用同一套思想管理云 + 边 + 本地的混合场景;
- Volcano:为批处理 / AI 训练 /大数据作业提供调度优化能力,使得 Kurator 不仅适合在线业务,也能覆盖离线算力场景;
- Argo / Tekton 生态:Kurator 的 Pipeline 参考了这些项目的设计理念,并在此基础上进一步简化使用门槛。
简单来说,Kurator 已经不是在「单点创新」,而是站在一整套成熟开源项目的基础上,做「统一编排、统一治理和统一体验」。
6.2 Kurator 的独特创新优势
在我看来,Kurator 相对其他多云管理 / 应用编排方案的优势主要体现在几方面:
-
强一致的「声明式」思路贯穿始终
无论是 Cluster / Fleet / Application / Rollout / Pipeline / Policy,都坚持用 CRD 描述期望状态。这让 Kurator 能非常自然地与 GitOps 流程结合,形成一条从基础设施到应用到策略的完整声明式链路。
-
专注「一站式分布式云原生管理」而非「大而全云平台」
Kurator 倾向于把「基础设施即代码 + 分布式云治理」做好,而不是去做 PaaS / Serverless / 数据库等更高层的托管服务,这让它很适合作为企业内部已有平台的「增强层」。
-
对多云、多集群、边缘场景有原生支持
内置对 AttachedCluster、KubeEdge、Karmada 等组件的支持,使得 Kurator 在分布式场景里并不是简单「堆功能」,而是从架构上为多环境设计。
-
在 CI/CD + 渐进式发布 + 软件供应链安全上的深度整合
相较于传统把「构建 – 部署 – 发布策略 – 监控」分别交给 Jenkins / Argo Rollouts / 自建 Prometheus 的做法,Kurator 尝试在统一控制面里把这些串起来,并注入供应链安全相关能力,这在当下供应链安全愈发重要的背景下很有价值。
6.3 面向未来的几个建议与想象
结合自身使用体验和对社区的观察,我有几条「不成熟的小建议」,也算是对 Kurator 未来的一个期望 😊:
建议 1:更丰富的「可视化拓扑与依赖关系视图」
Kurator 当前在控制面 CRD 设计上已经很完整,如果能在 UI 层或集成某类 Dashboard:
- 展示「Fleet → Cluster → Namespace → Application / Rollout → Service / Endpoint」的拓扑关系;
- 标注每一层的健康状态(结合 Thanos 指标);
那对运维人员定位问题、理解跨集群流量路径会非常有帮助。
建议 2:引入「成本感知」的多集群调度与发布策略
在多云环境下,按成本 / 延迟 / 合规等维度做调度越来越重要。结合 Karmada 的调度能力,Kurator 可以进一步演进为:
- 支持「成本标签」/「延迟标签」的调度策略;
- 在 Rollout 策略中允许「先在成本较低的集群做灰度」;
- 在监控指标中增加与成本相关的视图。
建议 3:深度集成 OpenTelemetry,全链路观测
目前 Kurator 在指标维度做得很好,如果未来能在以下方向继续演进:
- 提供基于 OpenTelemetry 的 Trace / Log 采集模板;
- 在 Fleet 层统一管理 Trace / Log Pipeline;
- 将 Metrics / Logs / Traces 统一关联呈现;
那 Kurator 将在「可观测性一体化」方向更进一步。
建议 4:AI 驱动的智能运维与发布决策
Kurator 已经掌握了多集群监控数据、发布策略和 Pipeline 状态,如果未来能结合 AI / 大模型能力:
- 自动识别异常模式(如发布后特定错误率跃增);
- 为 Rollout 提供智能化决策建议(例如「建议暂停第 3 步流量提升」);
- 为策略管理(Kyverno 规则)提供自动推荐;
那么它会非常符合「AIOps + GitOps」时代对平台的期待。
建议 5:构建「插件市场」与企业扩展生态
Kurator 现在已经通过 Plugin 概念支持 metric / policy / traffic 等模块,未来完全可以进一步开放:
- 提供「插件 SDK」,让第三方 / 企业内部团队都能编写 Kurator 插件;
- 类似 Helm 仓库那样,建立 Kurator Plugin Hub;
- 支持在 Fleet 层按插件配置版本进行灰度 / 回滚。
当然,了解如何在 Kurator 配置蓝绿发布的操作示例,大家可以参考下方:
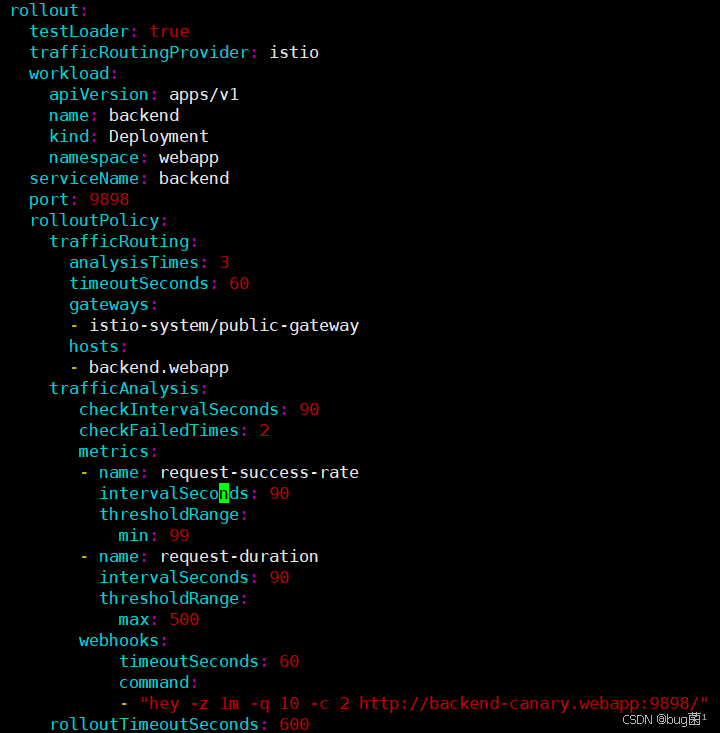
七、写在最后:做一个真正的「云原生实战派」 💪
回到文章开头的主题,「Kurator·云原生实战派」我更愿意理解为:
不把云原生停留在「概念 PPT」和「单集群 demo」,而是敢于在多云、多集群、边缘、CI/CD、安全这些复杂场景中真正落地,并通过开源社区不断迭代。
这篇稿子里,我们一起走过了:
- 从安装 Kurator CLI、搭建管理平面,到踩坑与修坑;
- 体验了集群生命周期治理、统一应用分发、统一流量治理、统一监控、统一策略、CI/CD 流水线等能力,并配上了可直接改造使用的代码示例;
- 通过虚构但贴近现实的 StarMall 案例,看了一次完整的企业级分布式云原生落地旅程;
- 分享了一次从 Issue 到 PR 的 Kurator 社区贡献经历;
- 最后从 Prometheus / Istio / Karmada / KubeEdge / Volcano 等内置项目出发,聊了 Kurator 的创新优势与未来构想。
如果你看到这里,基本已经具备了「用 Kurator 搭一套多云 / 多集群 / 边缘一体化平台」的思路和基础 YAML 模板 🎉。
接下来,最重要的一步就是——在自己的环境里动手试一遍:
- 先找一个「非核心业务」做 PoC;
- 把 Application / Rollout / Fleet / Pipeline 一步步接起来;
- 把踩到的小坑认真记录下来,说不定下一个被合入的 PR 就来自于你。😉
-End-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献145条内容
已为社区贡献145条内容

所有评论(0)