【探索实战】Kurator 集群算子:自动化集群运维的核心引擎
【探索实战】Kurator 集群算子:自动化集群运维的核心引擎
一、传统集群运维的痛点与集群算子解决方案


在分布式云原生架构中,随着集群数量激增,传统手动 / 半自动化运维模式面临三大核心瓶颈:
-
重复性操作繁琐:集群创建、升级、配置同步等操作需逐个执行,步骤重复且易出错;
-
状态一致性难保障:人工维护多集群状态,易出现 “配置漂移”,导致环境差异引发故障;
-
运维响应滞后:集群故障、资源不足等问题需人工发现并处理,无法实现实时响应;
-
扩展性差:新增运维场景(如自定义健康检查、集群合规校验)需开发大量脚本,集成成本高。
Kurator 集群算子(Cluster Operator)作为自动化运维的核心引擎,基于 Kubernetes Operator 模式,将集群运维操作封装为 “声明式 API + 控制器” 的组合,实现三大核心价值:
-
自动化执行:通过 CRD 定义集群期望状态,算子自动完成状态同步,无需人工干预;
-
状态自愈:实时监控集群状态,发现异常(如节点故障、组件崩溃)自动触发修复;
-
可扩展插件化:支持自定义算子插件,快速适配企业专属运维场景。
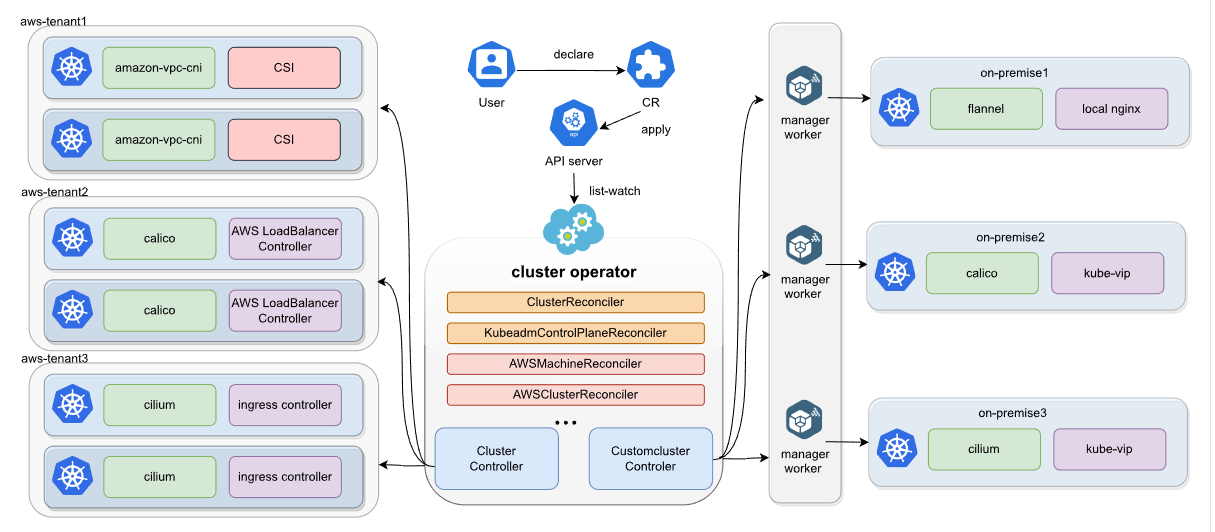
二、集群算子核心架构与工作原理
Kurator 集群算子的核心架构由 “API 层、控制器层、插件层、执行层” 四层组成:
-
API 层:提供集群全生命周期管理的 CRD(如Cluster、ClusterUpgrade、ClusterHealthCheck),支持声明式定义集群状态;
-
控制器层:核心逻辑处理单元,通过 Informer 机制监听 CRD 状态变化,对比 “期望状态” 与 “实际状态”,触发调和逻辑;
-
插件层:支持运维能力扩展,内置集群创建、升级、备份、健康检查等插件,同时支持自定义插件集成;
-
执行层:对接云厂商 API、Kubernetes 客户端、SSH 等工具,执行具体运维操作(如创建云服务器、部署组件、重启节点)。
其核心工作流程遵循 “观察 - 对比 - 调和”(Reconcile Loop)模式:
-
观察(Observe):监听Cluster等 CRD 的状态变化,同步集群实际状态;
-
对比(Compare):对比 CRD 定义的 “期望状态” 与集群 “实际状态”,识别差异;
-
调和(Reconcile):调用对应插件执行操作,消除状态差异,确保集群始终符合期望配置。
三、实战:集群算子自动化运维全流程
1. 环境前置条件
-
已部署 Kurator 控制平面(v0.7.1+),集群算子默认随控制平面部署;
-
已配置云厂商凭证(阿里云 / AWS / 私有云),存储在 Secret 中;
-
安装 kubectl、kurator CLI 工具,具备集群管理员权限;
-
目标环境:计划创建 3 个集群(dev、test、prod),实现全生命周期自动化管理。
2. 集群算子核心能力实战:自动化集群创建与配置
2.1 声明式创建多环境集群
通过ClusterCRD 定义多环境集群配置,集群算子自动完成创建、网络配置、组件部署全流程:
# multi-env-clusters.yaml
# 开发环境集群
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
metadata:
name: dev-cluster
namespace: kurator-system
spec:
kind: Provisioned
provider: aliyun
region: cn-beijing
version: v1.26.5
nodePools:
- name: master-pool
type: Master
instanceType: ecs.g6.xlarge
replicas: 1 # 开发环境单主节点
diskSize: 100
- name: worker-pool
type: Worker
instanceType: ecs.g6.2xlarge
replicas: 2
diskSize: 200
network:
vpcId: vpc-xxx
podCIDR: 10.244.0.0/16
credential:
secretRef:
name: aliyun-credential
# 开发环境专属配置(自动部署测试工具链)
plugins:
testing:
enabled: true
tools: ["sonarqube", "junit"]
---
# 生产环境集群(高可用配置)
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
metadata:
name: prod-cluster
namespace: kurator-system
spec:
kind: Provisioned
provider: aliyun
region: cn-beijing
version: v1.26.5
nodePools:
- name: master-pool
type: Master
instanceType: ecs.g6.4xlarge
replicas: 3 # 生产环境3主节点高可用
diskSize: 200
- name: worker-pool
type: Worker
instanceType: ecs.g6.8xlarge
replicas: 6
diskSize: 500
dataDisks:
- size: 1000
type: cloud_essd
network:
vpcId: vpc-xxx
podCIDR: 10.245.0.0/16
credential:
secretRef:
name: aliyun-credential
# 生产环境专属配置(高可用、监控、备份)
plugins:
highAvailability:
enabled: true
monitoring:
enabled: true
storage:
type: oss
config:
bucket: prod-monitor
backup:
enabled: true
schedule: "0 3 * * *"
应用 CRD 配置,集群算子自动执行集群创建:
# 应用集群配置
kubectl apply -f multi-env-clusters.yaml
# 查看集群创建状态(集群算子自动调和)
kubectl get clusters -n kurator-system -w
# 输出示例:
# NAME TYPE PROVIDER VERSION STATUS AGE
# dev-cluster Provisioned aliyun v1.26.5 Ready 25m
# prod-cluster Provisioned aliyun v1.26.5 Ready 40m
集群算子创建集群的核心自动化步骤:
-
调用云厂商 API 创建 ECS 实例(主节点 + 工作节点);
-
配置网络(VPC、安全组、路由表);
-
部署 Kubernetes 核心组件(kube-apiserver、etcd、kube-controller-manager);
-
安装网络插件(Calico/Cilium);
-
部署插件配置的工具(如开发环境的 SonarQube、生产环境的监控组件)。
2.2 自动化集群配置同步
通过ClusterConfigCRD 定义统一配置,集群算子自动同步到目标集群,避免配置漂移:
# cluster-config-sync.yaml
apiVersion: cluster.kurator.dev/v1alpha1
kind: ClusterConfig
metadata:
name: global-cluster-config
namespace: kurator-system
spec:
target:
fleet: prod-fleet # 同步到生产舰队所有集群
# 统一内核参数配置
kernelParams:
- key: net.ipv4.ip_forward
value: "1"
- key: vm.swappiness
value: "0"
# 统一容器运行时配置
containerRuntime:
type: containerd
config:
maxContainerCount: 100 # 最大容器数限制
# 统一命名空间创建
namespaces:
- name: app-prod
- name: infra-prod
# 统一资源配额配置
resourceQuotas:
- name: default-quota
namespace: app-prod
hard:
pods: "200"
cpu: "100"
memory: "200Gi"
应用配置后,集群算子自动将配置同步到 prod-fleet 下的所有集群:
kubectl apply -f cluster-config-sync.yaml
# 验证prod-cluster的配置同步结果
kubectl --context=prod-cluster get namespaces | grep app-prod
kubectl --context=prod-cluster get resourcequotas -n app-prod
3. 集群算子自动化升级与扩容
3.1 自动化集群版本升级
通过ClusterUpgradeCRD 定义升级策略,集群算子自动执行滚动升级,避免业务中断:
# cluster-upgrade.yaml
apiVersion: cluster.kurator.dev/v1alpha1
kind: ClusterUpgrade
metadata:
name: prod-cluster-upgrade
namespace: kurator-system
spec:
clusterName: prod-cluster # 目标集群
targetVersion: v1.27.3 # 目标版本
upgradeStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # 升级时最大不可用节点数
interval: 10m # 节点升级间隔(预留组件启动时间)
componentOrder: # 组件升级顺序(先升级控制平面,再升级工作节点)
- controlPlane
- worker
preUpgradeCheck: # 升级前预检查(确保集群状态正常)
enabled: true
checks:
- nodeHealth # 节点健康检查
- componentHealth # 核心组件健康检查
- resourceUsage # 资源使用率检查(CPU/内存<80%)
应用升级配置,集群算子自动执行升级流程:
kubectl apply -f cluster-upgrade.yaml
# 查看升级进度(集群算子实时更新状态)
kubectl get clusterupgrades -n kurator-system -w
# 输出示例:
# NAME CLUSTER TARGETVERSION STATUS PROGRESS AGE
# prod-cluster-upgrade prod-cluster v1.27.3 PreUpgradeCheck 0% 5m
# prod-cluster-upgrade prod-cluster v1.27.3 UpgradingControlPlane 33% 15m
# prod-cluster-upgrade prod-cluster v1.27.3 UpgradingWorker 60% 45m
# prod-cluster-upgrade prod-cluster v1.27.3 Completed 100% 70m
升级完成后验证版本:
kubectl --context=prod-cluster get nodes
# 节点版本均已更新为v1.27.3
3.2 自动化集群扩容 / 缩容
通过修改ClusterCRD 的replicas字段,集群算子自动执行节点扩容 / 缩容:
# prod-cluster-scale.yaml(扩容工作节点到8个)
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
metadata:
name: prod-cluster
namespace: kurator-system
spec:
nodePools:
- name: worker-pool
type: Worker
replicas: 8 # 从6个扩容到8个
# 其他配置保持不变...
应用配置后,集群算子自动创建 2 个新的工作节点并加入集群:
kubectl apply -f prod-cluster-scale.yaml
# 验证扩容结果
kubectl --context=prod-cluster get nodes | grep worker
# 输出8个worker节点
缩容操作同理,修改replicas为目标数量,集群算子自动移除多余节点(默认按 “最早创建” 原则选择节点,支持自定义缩容策略)。
4. 集群算子状态自愈与健康检查
4.1 配置自动健康检查
通过ClusterHealthCheckCRD 定义健康检查规则,集群算子实时监控集群状态:
# cluster-health-check.yaml
apiVersion: cluster.kurator.dev/v1alpha1
kind: ClusterHealthCheck
metadata:
name: prod-cluster-health-check
namespace: kurator-system
spec:
clusterName: prod-cluster
# 节点健康检查
nodeCheck:
enabled: true
thresholds:
notReadyDuration: 5m # 节点未就绪持续5分钟触发告警
diskUsageThreshold: 85% # 磁盘使用率>85%触发告警
cpuUsageThreshold: 90% # CPU使用率>90%触发告警
# 核心组件健康检查
componentCheck:
enabled: true
components:
- kube-apiserver
- etcd
- kube-controller-manager
- calico-node
thresholds:
crashCount: 3 # 10分钟内崩溃3次触发修复
# 网络健康检查
networkCheck:
enabled: true
pingTargets:
- 10.245.0.1 # 集群网关
- 114.114.114.114 # 公网地址
thresholds:
packetLossRate: 10% # 丢包率>10%触发告警
# 告警配置
alert:
enabled: true
notification:
webhook:
url: https://your-alert-system.com/webhook
secretRef:
name: alert-webhook-secret
应用配置后,集群算子定期执行健康检查:
kubectl apply -f cluster-health-check.yaml
# 查看健康检查状态
kubectl get clusterhealthchecks -n kurator-system
4.2 配置自动修复策略
当健康检查发现异常时,通过ClusterAutoHealCRD 配置自动修复策略,集群算子自动触发修复:
# cluster-auto-heal.yaml
apiVersion: cluster.kurator.dev/v1alpha1
kind: ClusterAutoHeal
metadata:
name: prod-cluster-auto-heal
namespace: kurator-system
spec:
clusterName: prod-cluster
# 节点未就绪修复
nodeNotReady:
action: RestartNode # 修复动作:重启节点
retryCount: 2 # 重试2次(失败则告警)
# 组件崩溃修复
componentCrash:
action: RedeployComponent # 修复动作:重新部署组件
excludeComponents: [] # 无排除组件
# 磁盘使用率过高修复
highDiskUsage:
action: CleanupLog # 修复动作:清理日志文件
cleanupPath:
- /var/log/containers
- /var/log/kubernetes
retentionDays: 7 # 保留7天内日志
应用配置后,当 prod-cluster 的某个节点磁盘使用率超过 85% 时,集群算子自动清理日志文件,释放磁盘空间;若节点未就绪,自动重启节点。
5. 集群算子常见问题与解决方案
5.1 集群创建失败
错误现象:Cluster状态显示ProvisioningFailed,日志提示 “云厂商 API 调用失败”
解决方案:
- 检查云厂商凭证 Secret 是否正确:
kubectl describe secret aliyun-credential -n kurator-system
-
验证云厂商配额是否充足(如 ECS 实例数量、弹性公网 IP 配额);
-
查看集群算子日志,定位具体错误:
kubectl logs -l app=kurator-cluster-operator -n kurator-system
5.2 配置同步未生效
错误现象:ClusterConfig已应用,但目标集群未创建命名空间 / 资源配额
解决方案:
- 检查ClusterConfig的target字段是否正确关联舰队 / 集群:
spec:
target:
fleet: prod-fleet # 确保舰队存在且包含目标集群
- 手动触发集群算子调和:
kubectl annotate clusterconfig global-cluster-config -n kurator-system kurator.dev/reconcile=force
5.3 集群升级卡住
错误现象:ClusterUpgrade状态长时间停留在UpgradingControlPlane
解决方案:
- 查看升级日志,定位失败节点:
kubectl logs -l app=kurator-cluster-upgrader -n kurator-system
-
检查目标节点的网络连通性、资源状态(如内存是否充足);
-
暂停升级后重试:
kubectl annotate clusterupgrades prod-cluster-upgrade -n kurator-system kurator.dev/pause=true
# 修复问题后取消暂停并重试
kubectl annotate clusterupgrades prod-cluster-upgrade -n kurator-system kurator.dev/pause=false
kubectl annotate clusterupgrades prod-cluster-upgrade -n kurator-system kurator.dev/retry=true

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 28
28 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)