【前瞻创想】搞定云原生多云舰队管理:手把手带你玩转Kurator,分布式云不再头大!
【前瞻创想】搞定云原生多云舰队管理:手把手带你玩转Kurator,分布式云不再头大!
说到现在这云原生技术栈,东西是真多,尤其是当你的业务扩张到了多云、混合云,甚至还有一大堆边缘设备的时候,那个管理难度简直是指数级上升。Kurator 这项目就是为了解决这个痛点生的,它就像是一个超级指挥官,把你的各种集群、舰队(Fleet)还有边缘节点治理得服服帖帖。别觉得它深奥,其实只要理清楚了脉络,这就是一把趁手的瑞士军刀。咱们今天不整那些虚头巴脑的概念,直接聊聊怎么用它来解决实际问题,把你的分布式云环境给盘活了。😎
一、 开局先要把环境搞起来:别废话,动手才是硬道理
想玩转 Kurator,光看不练那是假把式。咱们得先弄个环境出来,让你能摸得着、看得见。其实搭建这套东西没那么复杂,只要你有一台 Linux 机器,咱们就能开搞。
1.1 准备工作与源码获取
首先,你得确保你的机器上 Docker 或者 Containerd 这种容器运行时是好的,Go 语言环境最好也有,毕竟咱们是搞云原生的嘛。接下来,最关键的一步就是把 Kurator 的代码搞下来。这一步很多教程写得乱七八糟,咱们这里简单粗暴点,直接上命令。
你可以选择下载压缩包,简单快捷,也不用担心 Git 配置的问题:
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
当然了,如果你是个老手,习惯用 Git 来管理版本,以后还想拉取最新的更新,那我强烈建议你直接克隆仓库:
如图这是kurator的gitCode站内资源
点击项目中可以看到如下的源码文件内容
到这一步我们下载源码就分成方便啦
如果我们有git环境就可以直接用命令clone到本地
如果没有的话也可以直接下载zip包
下载下来解压缩就能得到源码文件啦
如下是源码文件
拿到代码解压或者进入目录之后,通常咱们会用 Makefile 来编译或者直接运行安装脚本。这时候你要注意观察终端输出,别一看到报错就慌,缺啥补啥就行。环境搭好是万里长征第一步,这一步稳了,后面玩各种花活才有底气。🛠️
1.2 验证你的环境是否就绪
装完之后,别急着立马去接集群,先敲几个简单的命令看看 Kurator 的 CLI 工具能不能响应。这就好比买了个新手机,先把机开开,看看屏幕亮不亮。如果 CLI 能正常打印出版本号,说明你的底座已经打好了。接下来,咱们就要深入到多云管理的深水区了。
二、 多云舰队管理的那些事儿:给集群发个“身份证”
在 Kurator 的世界里,最大的概念就是“舰队”(Fleet)。你可以把 Fleet 想象成一个超级大的资源池,里面装着你在阿里云、AWS、甚至是自建机房里的 K8s 集群。但是问题来了,这么多集群,谁是谁?怎么管?
2.1 Fleet访问队列外部资源的身份映射
咱们先聊聊身份映射这个痛点。想象一下,你有一个外部的 CI/CD 系统,或者是一个监控系统,它需要访问舰队里的某个集群。以前的做法是啥?在这个集群里建个 ServiceAccount,把 Token 拷出来,放到外部系统里。那如果你有 100 个集群呢?你要拷 100 次 Token 吗?那简直是运维噩梦!🤯
Kurator 在这块做得特别聪明,它引入了一种身份映射机制。简单来说,就是建立一种信任关系。你可以定义一组规则,说:“嘿,只要是从这个外部系统(比如 GitHub Actions 或者某个特定的 OIDC 提供商)来的请求,并且带着合法的凭证,我就把它映射成我舰队里某个集群的特定用户。”
这就好比是你拿着一张通用的“通行证”,到了任何一个集群门口,门卫大爷(也就是认证组件)拿个扫码枪一扫,就知道你是谁了,不用你在每个小区都办一张门禁卡。这种机制底层其实是用到了 Workload Identity 的概念,通过这种映射,我们既保证了安全性(不用到处散落 Token),又极大地简化了运维复杂度。你只需要在 Kurator 的控制平面配置好这个映射规则,剩下的事儿,Kurator 会帮你搞定。
这是Fleet访问队列外部资源的身份映射示意图,展示了跨集群服务与云平台服务账户的统一身份关联机制: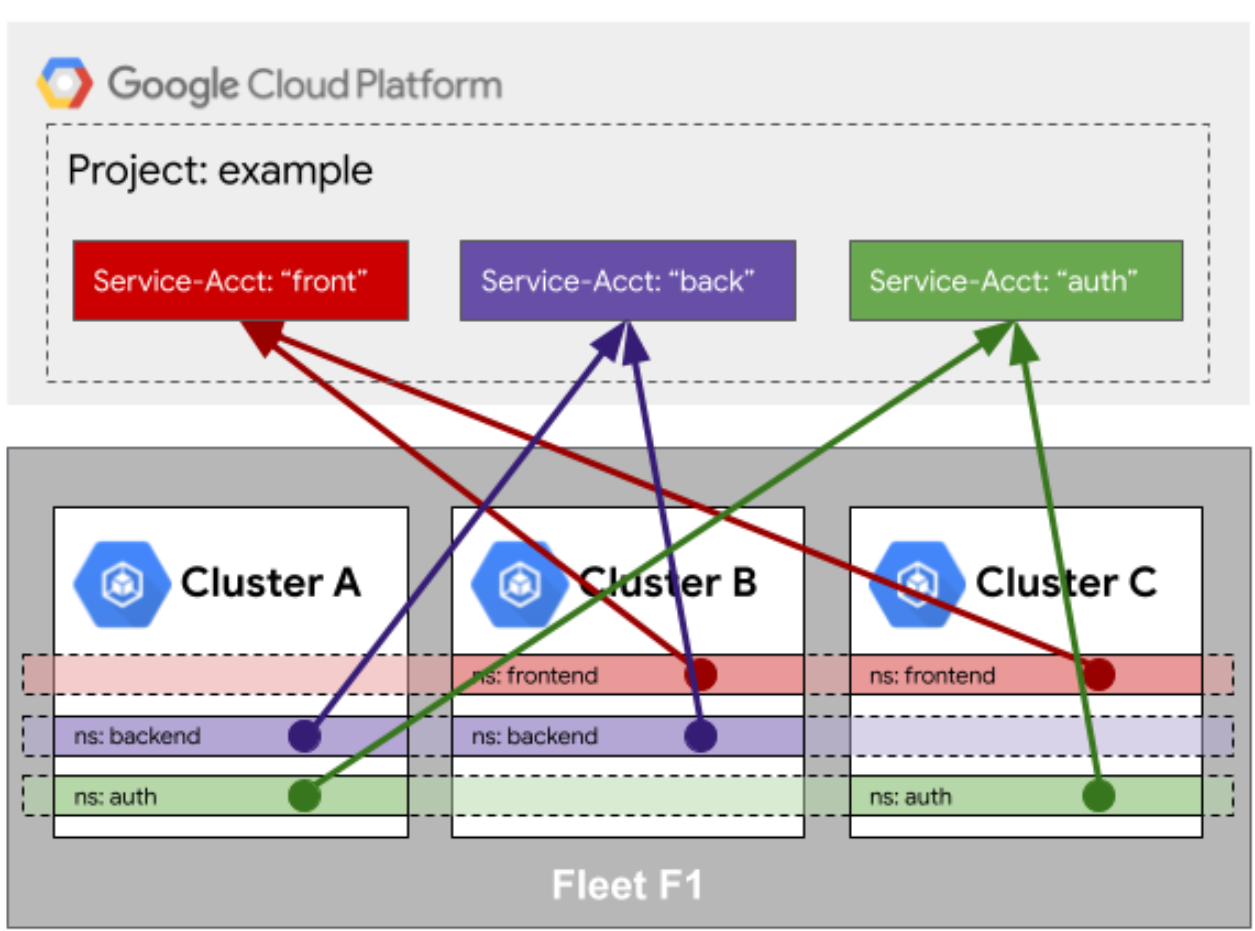
2.2 舰队中命名空间相同性(Namespace Sameness)
这也是个非常有意思的概念。在单集群里,Namespace 是用来做隔离的。但是在多集群舰队里,我们希望它能起到“连接”的作用。
啥意思呢?比如你在集群 A 里有个 Namespace 叫 production,在集群 B 里也有个 production。在 Kurator 的视角里,如果你开启了“命名空间相同性”,那么这两个 Namespace 就被视为同一个逻辑空间的切片。这就好像连锁店一样,北京的星巴克和上海的星巴克,虽然物理位置不同,但它们都叫“星巴克”,里面的装修、卖的咖啡(也就是服务)应该是一致的。
有了这个特性,管理起来就太舒服了。你只需要针对 production 这个逻辑概念下发策略,Kurator 会自动把这些策略同步到所有集群的 production 命名空间里。你不用担心说:“哎呀,我集群 B 的名字是不是写错了?”不存在的。这对于跨集群的服务发现和网络策略配置来说,简直就是神技。它抹平了物理集群之间的差异,让你感觉像是在操作一个巨大的超级集群。✨
这是Fleet舰队中命名空间相同性的示意图,展示了多集群间命名空间的对齐逻辑与统一编排映射关系: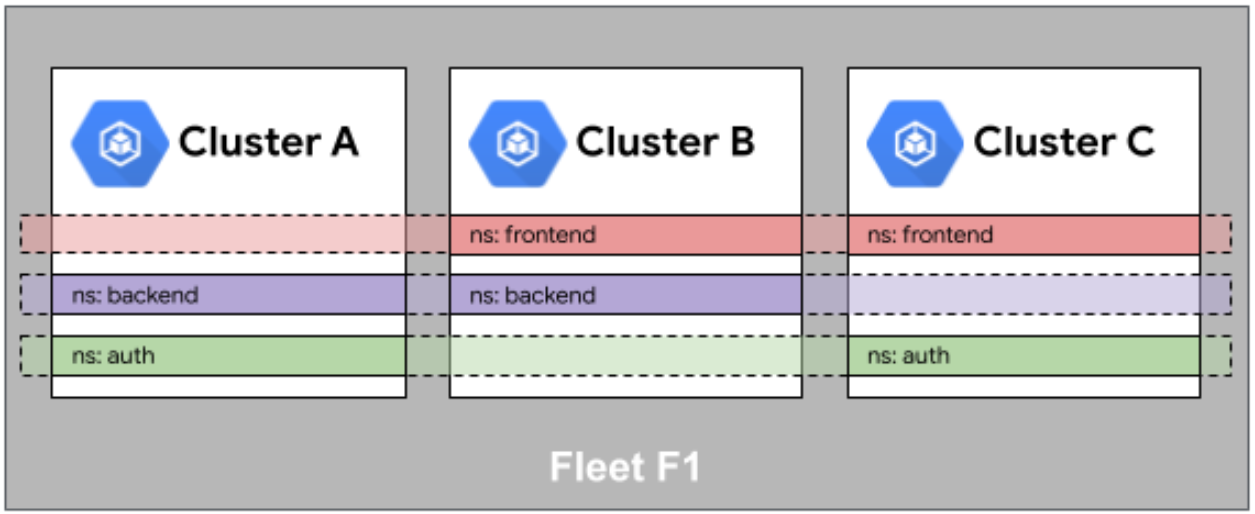
三、 GitOps与FluxCD的魔法秀:自动化才是王道
现在搞云原生,谁还手动 kubectl apply 啊?那太 Low 了,也太容易出错了。GitOps 才是现代运维的标准姿势。Kurator 在这方面深度集成了 FluxCD,让我们来看看它是怎么玩的。
3.1 GitOps实现方式:代码即基础设施
GitOps 的核心逻辑其实特简单:Git 仓库里存的就是你系统的“期望状态”,而集群里跑的是“实际状态”。Kurator 里面集成的 GitOps 控制器,就是个不知疲倦的搬运工。它会死死盯着你的 Git 仓库,一旦你提交了代码修改(比如改了个镜像版本,或者加了个环境变量),它立马就发现了。
发现之后咋办?它会自动把这些变更拉取下来,应用到你的目标集群里。如果集群里有人手欠,手动改了配置,导致和 Git 里的不一样了,控制器还会把配置强行改回来,确保“期望状态”和“实际状态”永远一致。这就是为什么我们说 GitOps 能防止配置漂移。在 Kurator 中,你只需要配置好 Source(仓库地址)和 Kustomization(怎么拼装资源),剩下的就交给它自动循环吧。
这是GitOps实现方式的官方参考图,展示了从代码变更到多环境(开发、预生产、生产)自动同步与部署的完整流程: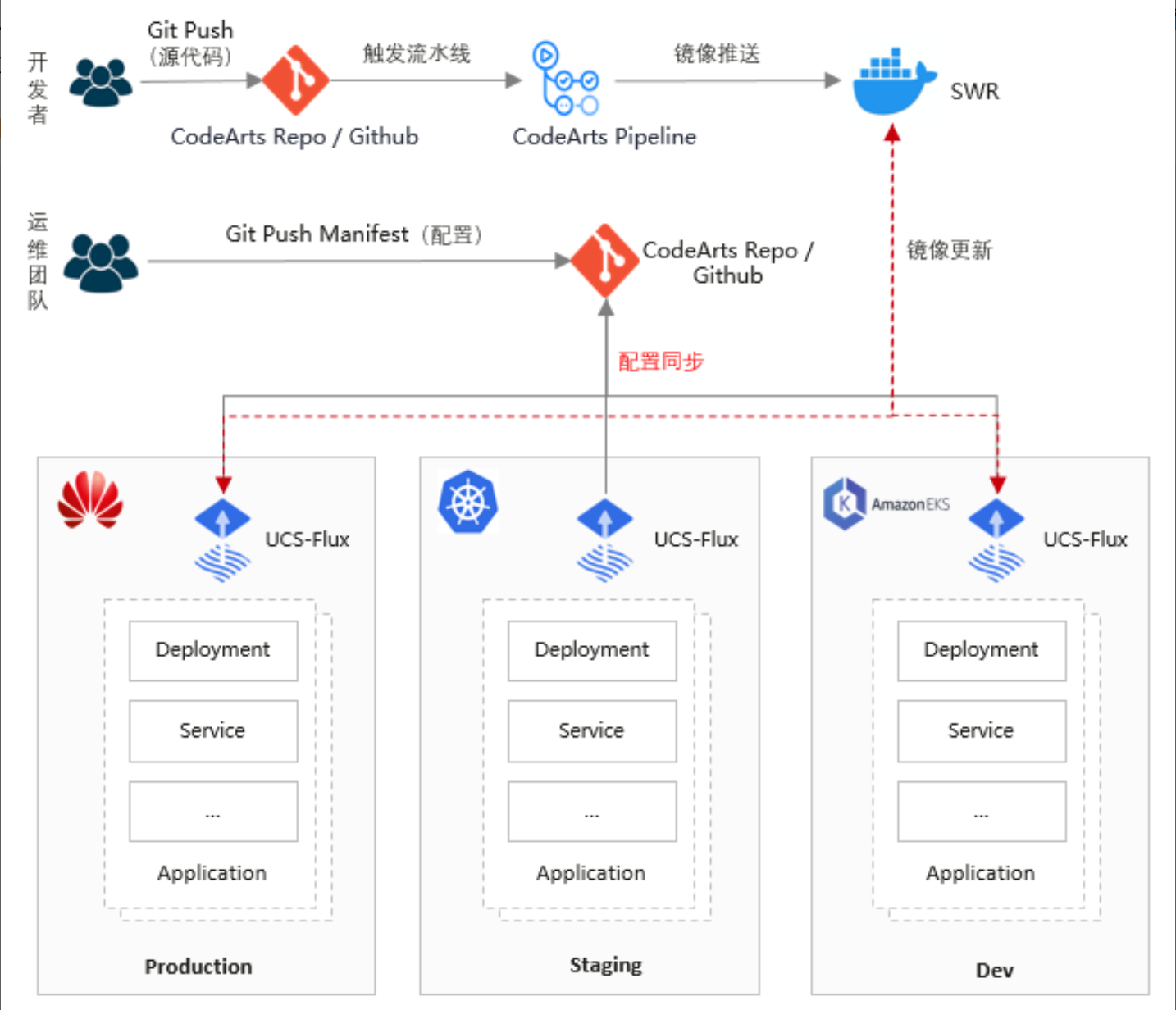
3.2 FluxCD Helm应用在多集群环境下的工作流程
FluxCD 是 GitOps 的一把好手,特别是处理 Helm Chart 的时候。在多集群环境下,这套流程是相当丝滑的。
首先,你需要定义一个 HelmRepository,告诉 Kurator 去哪下载 Chart。然后,你定义一个 HelmRelease,这个资源对象描述了你到底想怎么装这个应用(比如用哪个版本,Values 怎么覆盖)。Kurator 的控制器会把这个 HelmRelease 分发到目标集群。
这里有个关键点:在多集群场景下,你可能希望不同的集群用不同的配置。比如美国节点的集群用英文版 UI,中国节点的用中文版。FluxCD 允许你在 HelmRelease 里引用不同的 Values 文件,或者使用 Post-Build 变量替换。
这是FluxCD Helm应用在多集群环境下的工作流程示意图,展示了控制器如何基于Helm模板与差异化配置,实现跨集群应用的统一编排与同步: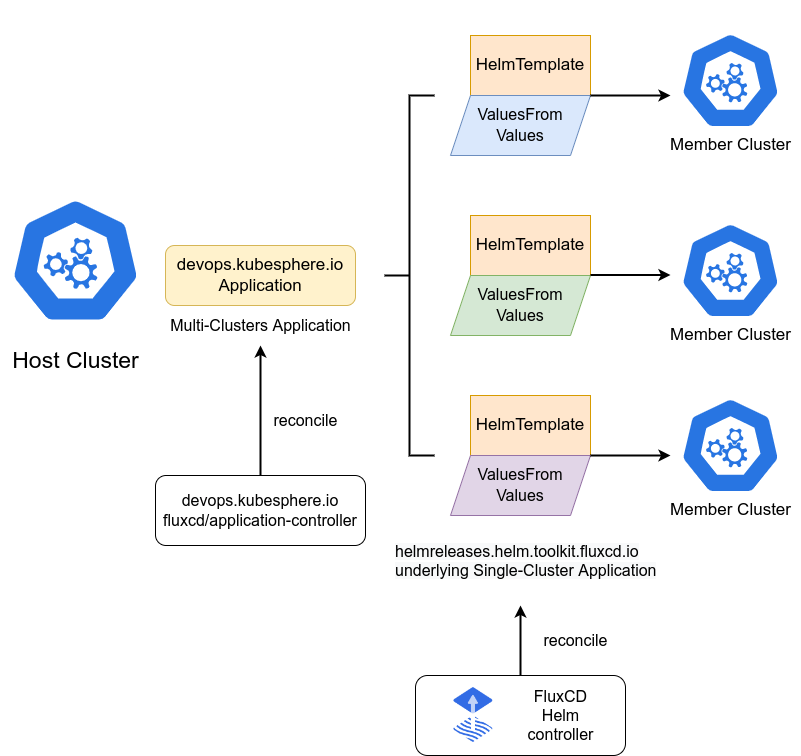
咱们来看一段手写的 HelmRelease 配置文件,大概长这样,是不是很眼熟:
# app-release.yaml
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: my-backend-app
namespace: prod-apps
spec:
interval: 5m
chart:
spec:
chart: backend-service
version: "1.2.3"
sourceRef:
kind: HelmRepository
name: internal-charts
namespace: flux-system
values:
replicaCount: 3
image:
repository: myregistry.io/backend
tag: "v1.0.5" # 刚才这里写错了,还好改过来了
service:
type: ClusterIP
port: 8080
# 这里是针对多集群的关键配置,注入特定集群的ID
clusterId: ${CLUSTER_ID}
看到那个 ${CLUSTER_ID} 没?在实际下发的时候,Kurator 配合 FluxCD 可以动态把这个变量替换成实际集群的 ID,这样一套配置就能通吃所有集群,又保留了差异化。这就是流水线式管理的魅力!🤖
四、 云边协同,KubeEdge显身手:把云延伸到世界的尽头
Kurator 不光管云上的大集群,它还能管边缘设备。这时候就轮到 KubeEdge 出场了。
4.1 KubeEdge云边协同架构的核心组件
这是KubeEdge云边协同架构的核心组件图,展示了云端控制平面、消息通道与边缘节点的全链路组件及交互方式: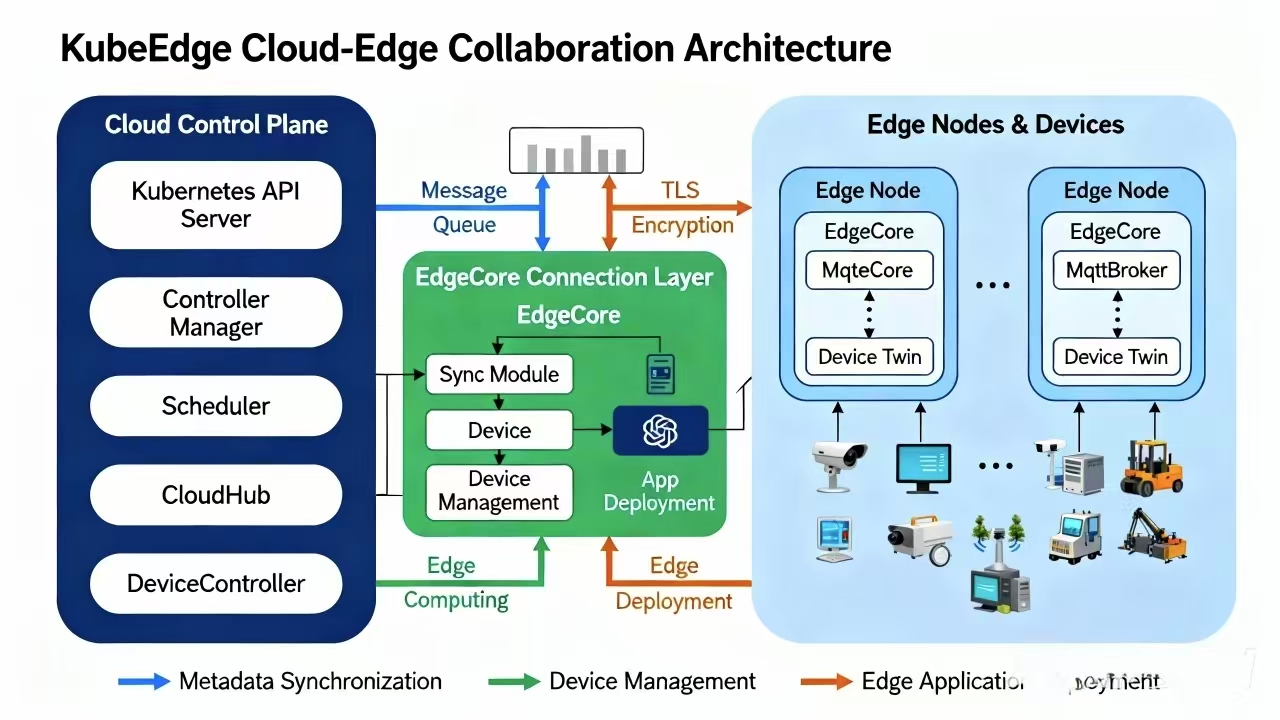
KubeEdge 的架构其实特别清晰,就分成两头:“云端”和“边缘端”。
云端的核心叫 CloudCore。你就把它当成是边缘节点的“大脑”或者是“指挥塔”。它运行在 K8s Master 节点或者云端节点上,负责监听 K8s 的 API Server,把云端的指令(比如“给我起个 Pod”)转换成边缘能听懂的消息,通过 WebSocket 下发下去。
边缘端的核心叫 EdgeCore。这玩意儿跑在树莓派、工控机这些资源受限的设备上。它里面是个轻量级的 Kubelet,负责管理本机上的容器。它最牛的地方在于,它有离线自治能力。万一网断了,EdgeCore 不会傻掉,它会基于本地的缓存继续让业务跑着,等网好了再把数据同步回云端。
4.2 隧道机制与网络连通性排查
云和边之间,网络环境通常很复杂,经常隔着防火墙或者 NAT。这时候就需要隧道机制。Kurator 集成的 KubeEdge 使用了一种云边隧道技术,让云端可以直接访问边缘端的 Pod 里的端口,或者查看边缘节点的日志。
这张图是隧道机制的参考流程,讲的是控制平面怎么跟成员集群之间建立安全连接的:先是控制平面发起隧道请求,成员集群返回端点信息,然后创建配置、建立双向TLS隧道,确认连通后就开始心跳检测和健康检查,之后进入一个循环,不断上报集群状态、接收控制指令,整个过程既安全又稳定,特别适合跨网络环境下的集群通信: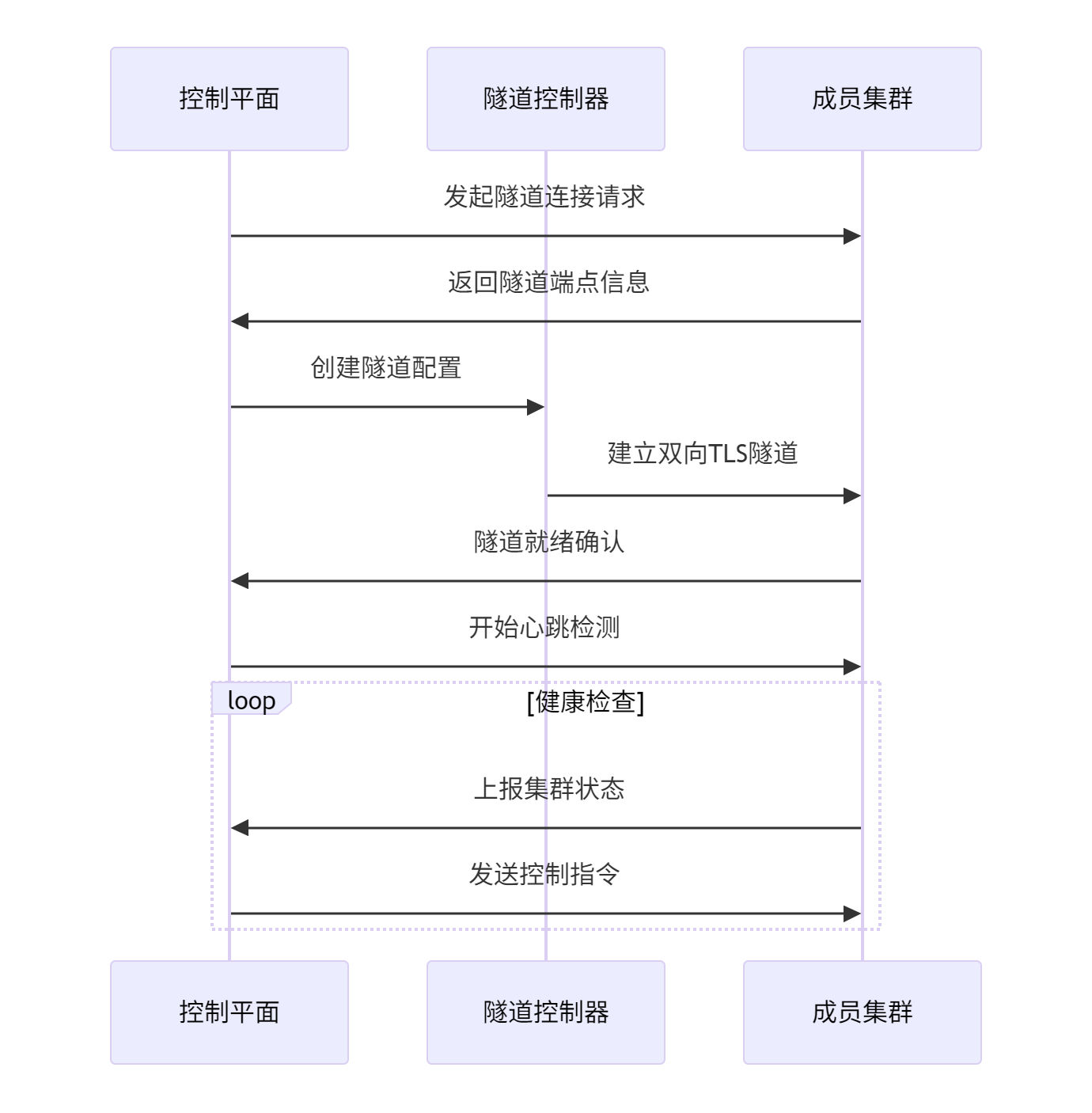
但这块也是最容易出问题的。如果你发现云端死活连不上边缘,或者 kubectl logs 看不到边缘 Pod 的日志,这时候就要排查网络连通性了。
首先,检查 CloudCore 的外网 IP 端口是不是通的。然后,去边缘节点看 EdgeCore 的日志,通常在 /var/log/kubeedge/ 下面。重点看那个 WebSocket 连接是不是 Established 状态。如果一直报 Handshake failed 或者 Connection refused,多半是证书不对,或者防火墙把端口(默认 10000 和 10002)给掐了。还有一个坑是 MTU 设置问题,有时候隧道封装会导致包太大被丢弃,这一块排查起来得有点耐心。🕵️♂️
4.3 云边协同计算场景:不只是连上网那么简单
这张图展示了云边协同计算场景:终端数据在边缘侧实时处理,再与云端协同分析,实现低时延、高效率的智能应用,适用于工业、交通等对响应速度要求高的领域: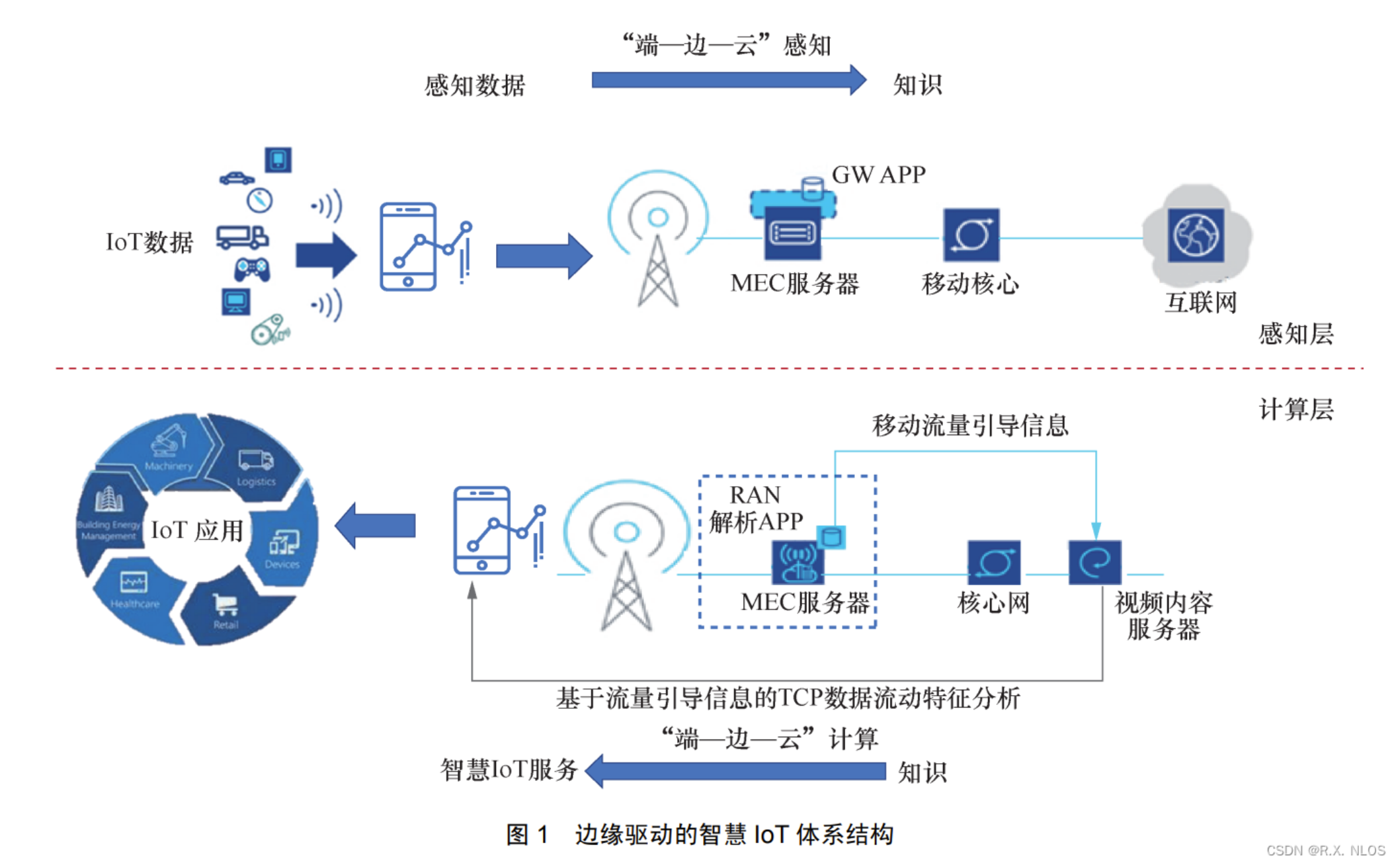
把边连上云有啥用?场景太多了!
一个是AI 推理在边缘。你在云端用强大的 GPU 训练好模型,通过 Kurator 把模型下发到边缘的摄像头或者网关上。边缘设备实时处理视频流,只把“发现异常”这个结果回传给云端。这就叫“云端训练,边缘推理”,极大地节省了带宽。
还有一个是数据预处理。工厂里的传感器每秒钟产生海量数据,直接传上云带宽费受不了。可以在边缘节点先做个清洗、聚合,把 1GB 的数据压缩成 1MB 的有效信息再上传。这些场景,都是 Kurator 结合 KubeEdge 能大展拳脚的地方。
五、 流量治理与金丝雀发布:稳才是硬道理
业务上线,最怕的就是“一波全挂”。所以我们需要精细化的流量控制和金丝雀发布。
5.1 Kurator的流量路由
Kurator 在流量路由这块,通常会结合 Istio 或者 Gateway API 来做。它允许你定义非常细致的规则。比如说,你可以配置:“所有来自 iPhone 用户的请求,去 v1 版本;所有 Android 用户的请求,去 v2 版本”。或者按照 Header、Cookie 来分流。
在多集群环境下,这个路由还能跨集群。比如北京集群压力大了,Kurator 可以动态调整 DNS 或者负载均衡策略,把一部分流量切到上海集群去。这就像是城市交通指挥中心,哪里堵车了,立马调整红绿灯,引导车流走别的路。
5.2 通过Kurator配置金丝雀
金丝雀发布(Canary Release)是保证上线质量的神器。它的逻辑是:新版本上了,先别急着全量,先放 5% 的流量过去看看有没有报错。如果没有,再增加到 20%,50%,最后 100%。
在 Kurator 里配置金丝雀,我们通常会定义一个 Canary 对象。你需要指定目标 Deployment,指定分析指标(比如 HTTP 500 错误率不能超过 1%),以及流量步进的策略。
这里有个手搓的 Canary 配置片段,你可以感受一下这个逻辑:
# canary-deploy.yaml
apiVersion: flagger.app/v1beta1
kind: Canary
metadata:
name: user-service
namespace: prod
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: user-service
service:
port: 80
targetPort: 8080
analysis:
interval: 1m # 每分钟检查一次
threshold: 5 # 错5次就回滚
stepWeight: 10 # 每次增加10%的流量
maxWeight: 50 # 到50%如果还稳,就全量
metrics:
- name: request-success-rate
thresholdRange:
min: 99 # 成功率必须大于99%
interval: 1m
# 还可以加webhooks做通知
配好这个之后,每次你更新镜像,Kurator 就会自动开始这个“小心翼翼”的发布过程。你会看到流量曲线一点点爬升,一旦出问题,立马切回旧版本,业务方可能都还没感知到故障就恢复了,稳得一匹!🛡️
六、 作业调度与流水线:让计算跑得更欢快
对于批处理任务或者 AI 训练任务,K8s 原生的调度器其实有点力不从心。Kurator 引入了 Volcano 来增强这块能力,并且能搭建完整的 CI/CD 流水线。
6.1 Volcano中Job、Queue与PodGroup关系
Volcano 是个高级调度器,它的核心概念有三个:Queue(队列)、Job(作业)和 PodGroup(Pod 组)。
这三个关系其实很好理解。Queue 就像是不同部门的资源配额。比如“大数据部”有一个 Queue,“AI 实验室”有一个 Queue。每个 Queue 分配了一定的 CPU 和内存权重。
Job 就是你要干的具体活儿,比如“训练一个大模型”。一个 Job 往往包含多个 Pod。
PodGroup 是 Volcano 引入的一个关键概念。它把属于同一个 Job 的一组 Pod 绑在一起。为啥要这样?因为在 AI 训练里,经常是“All-or-Nothing”。比如我需要 10 个 Pod 一起跑参数服务器,如果资源只够起 8 个,那这 8 个跑起来也没用,还占着茅坑不拉屎。PodGroup 就能保证,要么这 10 个一起调度成功,要么就都别调度,这就是 Gang Scheduling(帮派调度)。
所以在 Kurator 里,你的任务提交给 Job,Job 属于某个 Queue,调度器根据 Queue 的优先级和容量,以 PodGroup 为单位把任务扔到节点上。
这是Volcano中Job、Queue与PodGroup关系的参考图,直观展示了任务队列如何管理多个PodGroup及其Pod的调度分组: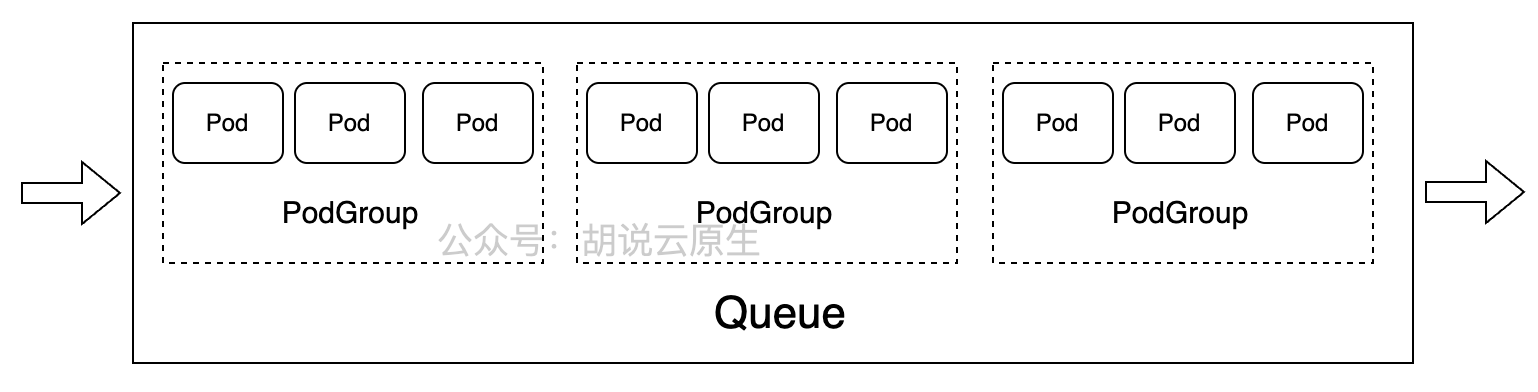
6.2 Kurator来搭建CI/CD流水线
虽然有很多外部的 CI/CD 工具,但 Kurator 自身也能串联起一套流水线,特别是针对云原生应用的构建和部署。通常我们会结合 Tekton 这样的云原生流水线工具。
你可以定义一系列的 Task(任务),比如“拉代码”、“编译”、“打镜像”、“推镜像”、“部署到测试环境”。Kurator 可以把这些 Task 编排成一个 Pipeline。
这里展示一段简单的 PipelineRun 定义,这就是流水线跑起来的“发令枪”:
# pipeline-run.yaml
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: build-and-deploy-run-
spec:
pipelineRef:
name: build-deploy-pipeline
params:
- name: git-url
value: "https://github.com/my-org/my-app.git"
- name: image-tag
value: "v2.0.0-rc1"
workspaces:
- name: source-storage
persistentVolumeClaim:
claimName: pipelinerun-pvc
- name: docker-credentials
secret:
secretName: docker-hub-creds
通过这种方式,你的构建过程也变成了 K8s 里的原生资源对象,可以被监控、被管理,而且完全融入了 Kurator 的生态圈里。
好啦,关于 Kurator 的核心玩法,今天咱们就先聊到这儿。从环境搭建到多云治理,从 GitOps 到云边协同,再到流量和调度,这一圈走下来,你应该对这个强大的工具有了更直观的感受。
云原生这条路,坑虽然多,但像 Kurator 这样的工具就是为了填坑而生的。希望这篇文章能帮你把思路理顺。如果你在实际操作中遇到了什么奇葩问题,比如网络不通啊、调度卡死啊,别灰心,多看看日志,多查查文档,解决问题的过程才是成长的过程嘛!加油,我看好你!💪🚀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)