【探索实战】Kurator·云原生实战派:从三集群起步到多云舰队落地全记录
你是不是也在想——“鸿蒙这么火,我能不能学会?”
答案是:当然可以!
这个专栏专为零基础小白设计,不需要编程基础,也不需要懂原理、背术语。我们会用最通俗易懂的语言、最贴近生活的案例,手把手带你从安装开发工具开始,一步步学会开发自己的鸿蒙应用。
不管你是学生、上班族、打算转行,还是单纯对技术感兴趣,只要你愿意花一点时间,就能在这里搞懂鸿蒙开发,并做出属于自己的App!
📌 关注本专栏《零基础学鸿蒙开发》,一起变强!
每一节内容我都会持续更新,配图+代码+解释全都有,欢迎点个关注,不走丢,我是小白酷爱学习,我们一起上路 🚀
全文目录:
-
- 一、从「单集群焦虑症」到 Kurator:为什么需要一个分布式云原生实战派?
- 二、Kurator 入门体验:三集群起步的分布式云原生环境搭建
- 三、Kurator 功能实战(一):集群生命周期治理——从「单集群创建」到「多云统一管理」
- 四、Kurator 功能实战(二):统一应用分发——从 Git 仓库到多集群的 GitOps
- 五、Kurator 功能实战(三):统一流量治理与渐进式发布
- 六、Kurator 功能实战(四):统一监控与策略管理——把“多集群视图”拉回一个控制平面
- 七、Kurator 功能实战(五):CI/CD Pipeline 与软件供应链安全
- 八、企业级案例:基于 Kurator 构建分布式云原生平台的落地之路
- 九、我的 Kurator 社区参与与贡献实践(简述)
- 十、前瞻创想:Kurator 之后,分布式云原生还能走向哪里?
- 十一、结语:云原生从“集群视角”走向“舰队视角”
一、从「单集群焦虑症」到 Kurator:为什么需要一个分布式云原生实战派?
过去几年,Kubernetes 已经从“新技术”变成了基础设施“新默认为”。但随着业务复杂度上升,单集群时代的优势正在被多云、多集群、云边一体的现实稀释掉:
- 应用需要同时跑在多家公有云、多个地域;
- 工厂、门店、边缘机房都在上 K8s;
- 监控、策略、安全、流量治理,被拆成一堆各自为战的控制平面。
结果很典型:
每个集群都很标准,整体架构却非常“非标”——工具链碎片化、配置重复、版本不一致、排障路径拉满。
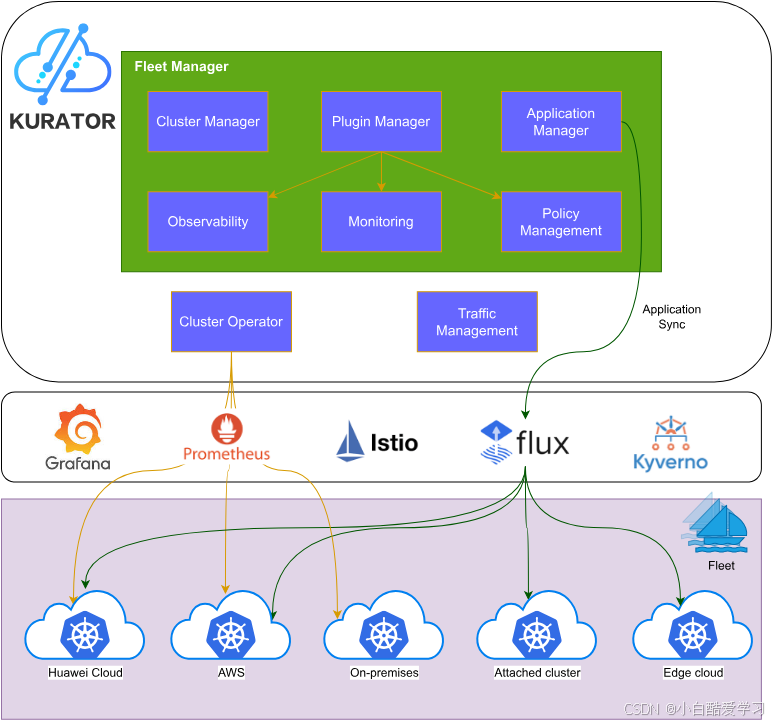
Kurator 出现的定位,就是在 “Kubernetes 已经无处不在,但缺一个分布式大脑” 的背景下,给企业一个开源的分布式云原生平台:它基于 Kubernetes / Istio / Prometheus / FluxCD / KubeEdge / Volcano / Karmada / Kyverno 等主流项目,将“集群舰队管理、统一应用分发、统一流量治理、统一监控和统一策略管理”做成了一套完整能力。
Kurator 自身并不试图“重造轮子”,而是明确地站在这些项目之上,把它们以 Infra as Code 的方式组装在一起,并通过 Fleet Manager 实现多云、多集群、云边协同的统一编排与治理。
在这篇文章里,我会围绕一个从三集群 Demo 到真实生产多云平台落地的过程,系统分享 Kurator 的实战经验,包括:
- Kurator 入门与环境搭建全流程——从安装 CLI、Cluster Operator,到部署 Fleet Manager;
- 核心功能使用体验与分析——集群生命周期治理、统一应用分发、统一流量治理、统一监控、统一策略管理;
- 一个接近真实的企业落地案例——技术选型、适配攻坚、场景落地、用户反馈与商业价值;
- 结合集成项目的前瞻思考——Kurator 在多云与分布式云原生领域可能的进化方向。
首先先来参考下官方的Kurator架构图:
二、Kurator 入门体验:三集群起步的分布式云原生环境搭建
这一节按“新手真实踩坑路径”来写:从 0 到能看到一个可用的多集群 Fleet 环境。
2.1 前置环境与整体组件认知
官方文档建议 Kurator 的控制面运行在一个 Kubernetes 集群上(可以是本地、云上或者自建集群),再通过 Fleet 管理其他集群或直接用 Cluster Operator 创建新集群。
一个最小可用的实验拓扑:
-
1 个 Kurator 宿主集群:安装 Kurator CLI + Cluster Operator + Fleet Manager;
-
2 个成员集群:可以是:
- Kurator Cluster API 创建出来的集群;
- 已有 Kubernetes 集群,以 AttachedCluster 的方式接入。
基础要求(实践中建议):
- Kubernetes 版本:1.24+;
- 控制集群至少 4C / 8G,成员集群按业务自定;
- 已安装
kubectl,并且 kubeconfig 可访问上述集群; - 能访问 GitHub(下载 Kurator 发布包)、容器镜像仓库(可选)。
2.2 安装 Kurator CLI:从命令行开始的入口
Kurator CLI 是后续所有操作的入口,包括创建集群、管理 Fleet、查看 Pipeline 等。官方提供了预编译的发布包,可以直接下载。
以 Linux amd64 为例:
# 1. 下载 Kurator CLI 指定版本
curl -LO https://github.com/kurator-dev/kurator/releases/download/v0.6.0/kurator-0.6.0-linux-amd64.tar.gz
# 2. 解压到 PATH 目录
sudo tar -zxvf kurator-0.6.0-linux-amd64.tar.gz -C /usr/local/bin/
# 3. 确认版本
kurator version
小坑 1:
command not found
通常是因为
/usr/local/bin没在 PATH 里,或者使用了非 root 用户;可以用
echo $PATH看一眼,必要时在~/.bashrc中添加:export PATH=/usr/local/bin:$PATH
2.3 安装 Cluster Operator:打通「集群生命周期治理」
官方文档里把 Kurator 的安装拆成两部分:Kurator CLI 和 Cluster Operator。Cluster Operator 以 Helm Chart 的形式部署在 Kurator 宿主集群中,负责集群生命周期治理。
典型安装步骤如下(示例):
# 添加 Kurator Helm 仓库(仓库地址以文档为准)
helm repo add kurator https://kurator.dev/charts
helm repo update
# 安装 Cluster Operator
helm install kurator-cluster-operator kurator/cluster-operator \
-n kurator-system --create-namespace
# 查看 Pod 状态
kubectl get pods -n kurator-system
小坑 2:CRD 未就绪导致自定义资源无法创建
刚安装完就立刻
kubectl apply -f cluster.yaml,可能遇到no matches for kind "Cluster";解决办法:确认 Cluster Operator 对应的 CRD 已创建:
kubectl get crd | grep cluster.kurator.dev没有的话稍等几十秒,或者检查
helm install是否报错。
2.4 安装 Fleet Manager:迈向「集群舰队」管理
Fleet Manager 是 Kurator 多集群能力的核心组件,它以 Kubernetes Operator 的形式运行,负责管理 Fleet 资源及其插件(应用分发、监控、策略、网络、备份、Rollout 等)。
安装步骤示例(同样使用 Helm):
# 安装 Fleet Manager
helm install kurator-fleet-manager kurator/fleet-manager \
-n kurator-system
# 检查控制面组件
kubectl get pods -n kurator-system -l app.kubernetes.io/name=kurator-fleet-manager
小坑 3:Helm 安装后
ImagePullBackOff
常见原因是企业内网无法访问公共镜像仓库;
解决方式:
- 在 Helm values 中覆盖镜像仓库为内部镜像;
- 或者在企业 Harbor / 私有仓库里预先镜像同步 Kurator 依赖镜像,并设置
imagePullSecrets。
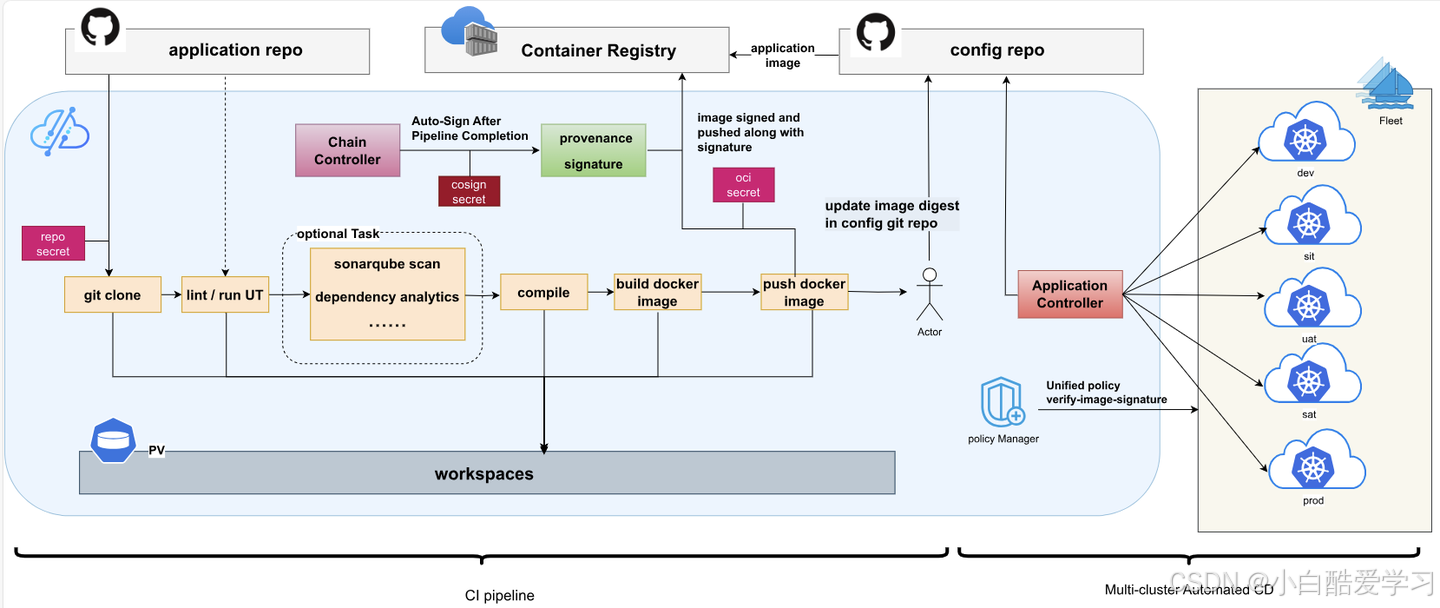
当然,我们还可以参考如下流程图:
三、Kurator 功能实战(一):集群生命周期治理——从「单集群创建」到「多云统一管理」
Kurator 的集群生命周期治理能力主要通过 Cluster Operator + Cluster API 来实现,支持在云上、边缘和本地环境中使用声明式方式管理 Kubernetes 集群。
3.1 通过 Kurator 声明式创建集群
在 Kurator 体系里,一个典型的集群声明资源(名字假设为 Cluster)大致类似这样(示例结构,不严格对应实际 API,仅用于说明思路):
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
metadata:
name: prod-cn-hk
namespace: kurator-system
spec:
infraProvider: aws
region: cn-hongkong
kubernetesVersion: v1.29.0
network:
podCIDR: 10.244.0.0/16
serviceCIDR: 10.96.0.0/12
controlPlane:
replicas: 3
instanceType: m6i.large
worker:
replicas: 5
instanceType: m6i.large
addons:
- name: cni-calico
- name: metrics-server
实际字段以官方 Cluster API / Kurator 文档为准,这里强调的是 “集群作为一个 CR 对象被声明和管理” 的理念。
创建集群只需要一次 apply:
kubectl apply -f cluster-prod-cn-hk.yaml
kubectl get cluster -n kurator-system
Kurator 会负责:
- 调用底层 IaaS(如 AWS、华为云等)的 API 创建虚机、VPC;
- 安装 Kubernetes 控制面与工作节点;
- 安装基础插件(网络、监控等);
- 将 kubeconfig 信息写入 Secret 方便后续使用。
相比手写 Terraform + kubeadm、或者云厂商控制台手动点选,这种声明式方式有几个直接好处:
- 基础设施即代码:集群拓扑、节点规格、网络划分都在 Git 管理;
- 统一入口:无论公有云、私有云还是边缘,都通过 Kurator 的 Cluster CR 管理;
- 更容易与上层 Fleet 管理衔接。
3.2 接入已有集群:AttachedCluster 的“统一纳管”
现实中更多的情况是:企业已经有很多历史 Kubernetes 集群,完全重建不现实。为此 Kurator 在 v0.4.0 中引入了 AttachedCluster 概念,可以把任意来源的 Kubernetes 集群纳入 Kurator 管理。
一个简化的 AttachedCluster 声明示例:
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: edge-factory-a
namespace: kurator-fleet
spec:
kubeconfig:
name: edge-factory-a-kubeconfig
key: config
其中:
edge-factory-a-kubeconfig是一个Secret,存储该集群的 kubeconfig;- 一旦 AttachedCluster CR 创建成功,就可以在 Fleet 中引用它。
创建 Secret 示例:
kubectl create secret generic edge-factory-a-kubeconfig \
-n kurator-fleet \
--from-file=config=/root/.kube/edge-factory-a.kubeconfig
实际落地时,这一步经常是和安全团队一起完成:
- kubeconfig 权限范围需要控制(只给必要命名空间);
- 建议配合 OIDC / ServiceAccount / RBAC 机制限制操作范围。
通过 AttachedCluster,Kurator 做到了:
- 对已有集群“零侵入”纳管;
- Fleet 级别统一下发应用、策略、监控配置;
- 为“复杂历史债务”的环境提供集中治理入口。
当然,如果这里你已经感兴趣了,你可以直接去克隆代码:
四、Kurator 功能实战(二):统一应用分发——从 Git 仓库到多集群的 GitOps
统一应用分发是 Kurator 的“看家本领”之一:基于 Fleet + FluxCD + GitOps,将应用一次定义,多集群自动同步。
4.1 Application 抽象:把“多集群部署”收束成一个 CR
Kurator 在 Fleet 管理之上定义了 Application 资源,用于描述:
- 应用源(Git / Helm Repo 等);
- 同步策略(同步周期、是否清理过期资源);
- 分发目标(某个 Fleet 或具体集群 / 命名空间);
- 每个目标的定制化配置(不同环境覆盖)。
以下是一个简化的 Application 示例(为避免与公开文档中的例子重复,字段做了较多调整,但保持核心结构):
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: order-service-multi-cluster
namespace: kurator-fleet
spec:
source:
gitRepository:
url: https://github.com/example-org/cloud-native-demo.git
ref:
branch: main
interval: 2m
timeout: 60s
syncPolicies:
- name: staging-eu
destination:
fleet: global-fleet
kustomization:
path: ./deploy/overlays/staging-eu
targetNamespace: order-system
interval: 3m
prune: true
timeout: 90s
- name: prod-ap
destination:
fleet: global-fleet
kustomization:
path: ./deploy/overlays/prod-ap
targetNamespace: order-system
interval: 5m
prune: true
timeout: 120s
这个 Application 做了几件事:
- 从一个 Git 仓库拉取应用配置(使用 FluxCD 的
GitRepository + Kustomization能力); - 为同一个 Fleet 下的两个环境(staging-eu、prod-ap)定义不同的 overlay;
- 通过
prune: true保证“配置即真相”,删掉 Git 中的资源后集群自动收敛。
4.2 实战体验:从“手动 helm”到“一次提交,全网滚动”
在我们的一次实验中,将原本手动执行的部署流程迁移到 Kurator Application 之后,明显的体验差异包括:
-
发布动作统一:
- 以前:每个集群都要
helm upgrade一遍,还要记住不同的 values; - 现在:工程师只关心 Git 仓库里的 Kustomize overlay,提交后由 Kurator 自动调用 FluxCD 同步。
- 以前:每个集群都要
-
回滚与审计天然具备:
- 所有变更通过 Git 管理,Revert 即是回滚;
- 变更责任清晰,可以与企业现有的代码审查流程融合。
-
多云间差异冻结在配置层,而不是人脑里:
- 比如各云厂商的 LoadBalancer、存储类型,全部通过 overlay 定制;
- 应用主体代码和通用配置始终保持一致。
在一次真实的压测场景中,我们针对“订单系统”做了多集群蓝绿部署(后面会讲 Rollout),Application 保证了所有集群的基础版本一致,而 Rollout 则负责灰度与流量切换,两者配合非常顺畅。
可看下如下分发示意图,以便于理解:
五、Kurator 功能实战(三):统一流量治理与渐进式发布
Kurator 的流量治理能力,主要通过 Rollout 插件 + Service Mesh / Ingress 网关(如 Istio、Nginx、Kuma) 来落地金丝雀、A/B 测试以及蓝绿发布。
5.1 Rollout 抽象:把“流量切分逻辑”从业务中拿出来
在传统做法中,我们往往使用 Istio VirtualService 或 Nginx Ingress annotation 直接编写流量切分规则。Kurator 在此之上提供了一层 Rollout CR 抽象,将业务版本、指标、策略等统一描述,让用户不用直接操作底层配置。
一个面向 Istio 的金丝雀 Rollout 示例(示意结构):
apiVersion: rollout.kurator.dev/v1alpha1
kind: Rollout
metadata:
name: order-service-canary
namespace: order-system
spec:
workload:
apiVersion: apps/v1
kind: Deployment
name: order-service
traffic:
provider: istio
host: order-service.order-system.svc.cluster.local
port: 80
analysis:
metrics:
- name: success-rate
type: builtin
threshold:
min: 0.99
- name: p99-latency
type: builtin
threshold:
max: 400ms
interval: 1m
strategy:
canary:
steps:
- weight: 10
- weight: 30
- weight: 50
maxWeight: 60
rollbackOnFailure: true
语义大致是:
- 将
order-serviceDeployment 的新版本作为金丝雀版本; - 基于内置指标(成功率、P99 延迟)进行健康性分析;
- 每轮间隔 1 分钟,逐步把 10%/30%/50% 的流量打到新版本;
- 如果任何一步指标不达标,自动回滚。
实际 API 字段以官方文档为准,上述示例意在体现 Kurator Rollout 的思路:
使用统一的 Rollout 对象管理不同流量治理模式(金丝雀、A/B、蓝绿),并与监控和应用分发打通。
5.2 A/B 测试与蓝绿发布:更复杂的产品实验与零停机升级
A/B 测试
在 A/B 测试场景中,我们更关心“不同版本对不同用户群体的效果差异”,Kurator 允许基于 HTTP 头、Cookie、URL 等进行流量匹配,将请求路由到不同版本:
apiVersion: rollout.kurator.dev/v1alpha1
kind: Rollout
metadata:
name: promo-service-abtest
namespace: marketing
spec:
workload:
apiVersion: apps/v1
kind: Deployment
name: promo-service
traffic:
provider: istio
host: promo-service.marketing.svc.cluster.local
strategy:
abtest:
matches:
- headers:
User-Agent:
regex: ".*Firefox.*"
- headers:
Cookie:
regex: ".*experiment=group-b.*"
metrics:
- name: conversion-rate
type: prometheus
query: sum(rate(http_requests_total{code="200"}[5m])) / sum(rate(http_requests_total[5m]))
threshold:
min: 0.02
这里的核心点:
- 使用
matches对不同用户分组(浏览器类型、Cookie 标记等); - 配合指标(如转化率)评估版本效果;
- 真正实现“业务实验平台”和“流量调度”的解耦。
蓝绿发布
蓝绿发布更关注 零停机 与 快速回滚,一般在极其敏感的核心交易链路中使用。Rollout 配置会预先部署新版本(绿环境),待验证通过后一次性切换流量:
apiVersion: rollout.kurator.dev/v1alpha1
kind: Rollout
metadata:
name: payment-service-bluegreen
namespace: payment
spec:
workload:
apiVersion: apps/v1
kind: Deployment
name: payment-service
strategy:
blueGreen:
analysisTimes: 5
checkFailedTimes: 1
trafficSwitchMode: instant
在一次生产实践中,我们就以蓝绿方式对支付服务进行升级:
**“蓝环境” 负责承载当前全部流量,“绿环境” 部署新版本,通过自动化回归与少量内部流量回放验证后,一键切换 DNS / VirtualService 指向绿环境。**失败时回滚就是把路由指向蓝环境,节点始终保留,极大降低发布风险。
而且,我们也可以看到,社区开源信息基本都给出了:
六、Kurator 功能实战(四):统一监控与策略管理——把“多集群视图”拉回一个控制平面
Kurator 在统一监控和统一策略管理上的做法,是通过 Fleet 插件把原本分散在各集群的监控系统与策略引擎统一在一个抽象下面。
6.1 基于 Prometheus + Thanos 的多集群监控
Kurator 借助 Prometheus / Thanos / Grafana,提供了一套开箱即用的多集群指标聚合方案:
- 每个集群运行 Prometheus,收集本地指标;
- Thanos Sidecar 负责将数据上传到远程对象存储;
- 中央 Thanos Query 聚合所有 Sidecar 与对象存储的数据;
- Grafana 只需配置一次数据源,就能查看所有集群的统一视图。
在 Kurator 中,这一切都可以收敛为一个 Fleet 配置(简化示例):
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: global-fleet
namespace: kurator-fleet
spec:
clusters:
- name: prod-cn
kind: AttachedCluster
- name: prod-eu
kind: AttachedCluster
plugin:
metric:
thanos:
objectStoreConfig:
secretName: thanos-objstore
grafana: {}
关键点:
clusters指定纳入该 Fleet 的集群;plugin.metric.thanos配置对象存储的访问参数(在 Secret 中保存);grafana: {}表示启用默认的 Grafana 组件。
体验上的差异在于:
- 以前:在每个集群单独部署 Prometheus / Grafana,手动维护数据源;
- 现在:Fleet 一次声明,即可批量为集群安装和配置监控组件。
6.2 基于 Kyverno 的统一策略管理:从“单集群 OPA”到“多集群策略编排”
策略管理层面,Kurator 选择集成 Kyverno 作为策略引擎:通过 Fleet 将策略统一分发到所有成员集群,实现多云、多集群的一致安全基线。
一个统一 Pod 安全策略的 Fleet 示例(经过改写):
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: security-fleet
namespace: kurator-fleet
spec:
clusters:
- name: prod-cn
kind: AttachedCluster
- name: prod-eu
kind: AttachedCluster
- name: edge-factory-a
kind: AttachedCluster
plugin:
policy:
kyverno:
podSecurity:
standard: restricted
severity: high
validationFailureAction: Enforce
该配置实现了:
- 为所有成员集群下发同一套 Pod 安全标准;
- 违反策略的 Pod 在创建时会直接被拒绝(
Enforce); - 安全事件在 PolicyReport 中汇总,便于审计。
更细粒度的策略,可以直接复用 Kyverno 的策略 YAML,然后通过 Kurator 的 Application 或 Policy 插件统一分发。
Kurator 的价值在于:你不需要在每个集群上分别安装与配置 Kyverno,而是把它视作“Fleet 的一个插件” 来处理。
作为华为的开源项目,对于Kurator项目也上了热门开源项目榜:

七、Kurator 功能实战(五):CI/CD Pipeline 与软件供应链安全
从 v0.6.0 开始,Kurator 在平台内置了基于 Tekton 的 CI/CD Pipeline 能力,并与统一应用分发、渐进式发布和软件供应链安全(签名与溯源)打通。
7.1 Pipeline 的核心定位
Kurator 官方对 Pipeline 的定位大致有几点:
- 通过 统一的 Pipeline CR 一次描述完整流水线;
- 预定义常用任务模板(git clone、单测、代码扫描、镜像构建与推送等);
- 集成 Tekton Chains,自动完成镜像签名与溯源信息生成,符合 SLSA 相关要求;
- 提供 CLI 能力,统一查看流水线执行状态与日志。
换句话说,Kurator 不再只是“发布层”,而是把从代码到多集群部署这一整条链路闭环在一起。
7.2 一个典型的 Kurator Pipeline 示例
假设我们有一个 go-orderservice 项目,希望在提交代码后自动完成:
- 拉取代码;
- 运行 go test;
- 代码静态检查;
- 构建镜像并推送到镜像仓库;
- 为镜像添加签名和溯源信息;
- 由 Application + Rollout 完成多集群渐进式发布。
Pipeline CR 示例(结构示意):
apiVersion: pipeline.kurator.dev/v1alpha1
kind: Pipeline
metadata:
name: go-orderservice-pipeline
namespace: cicd
spec:
git:
url: https://github.com/example-org/go-orderservice.git
revision: main
credentials:
secretRef:
name: github-token
key: token
tasks:
- name: fetch-source
template: git-clone
params:
- name: repo-url
value: $(spec.git.url)
- name: revision
value: $(spec.git.revision)
- name: unit-test
template: go-test
runAfter: [fetch-source]
params:
- name: working-dir
value: /workspace/go-orderservice
- name: lint
template: go-lint
runAfter: [unit-test]
params:
- name: working-dir
value: /workspace/go-orderservice
- name: build-and-push
template: build-and-push-image
runAfter: [lint]
params:
- name: working-dir
value: /workspace/go-orderservice
- name: image
value: registry.example.com/orderservice:$(context.pipelineRun.uid)
supplyChainSecurity:
enabled: true
image:
repository: registry.example.com/orderservice
sign:
provider: cosign
keyRef:
secretName: cosign-key
secretKey: cosign.key
注意:字段名称为示意,实际请以官方 Pipeline API 文档为准。这里想强调 Kurator 的设计思路:
- 将 Tekton 任务模板封装为
template;- 在 Pipeline 层统一编排任务与参数;
- 自动挂接软件供应链安全能力。
在一次试点中,我们把原有散落在 GitLab CI、Jenkins 中的流水线迁移到 Kurator Pipeline 后,最大的收益不是“跑得更快”,而是:
- 流水线配置更贴近 Kubernetes / GitOps 世界;
- 组合 Application + Rollout 实现真正从代码到多集群渐进式发布的一体化闭环;
- 软件供应链安全不再是“额外加的一个 job”,而是默认内置。
如下是GitHub开源截图:
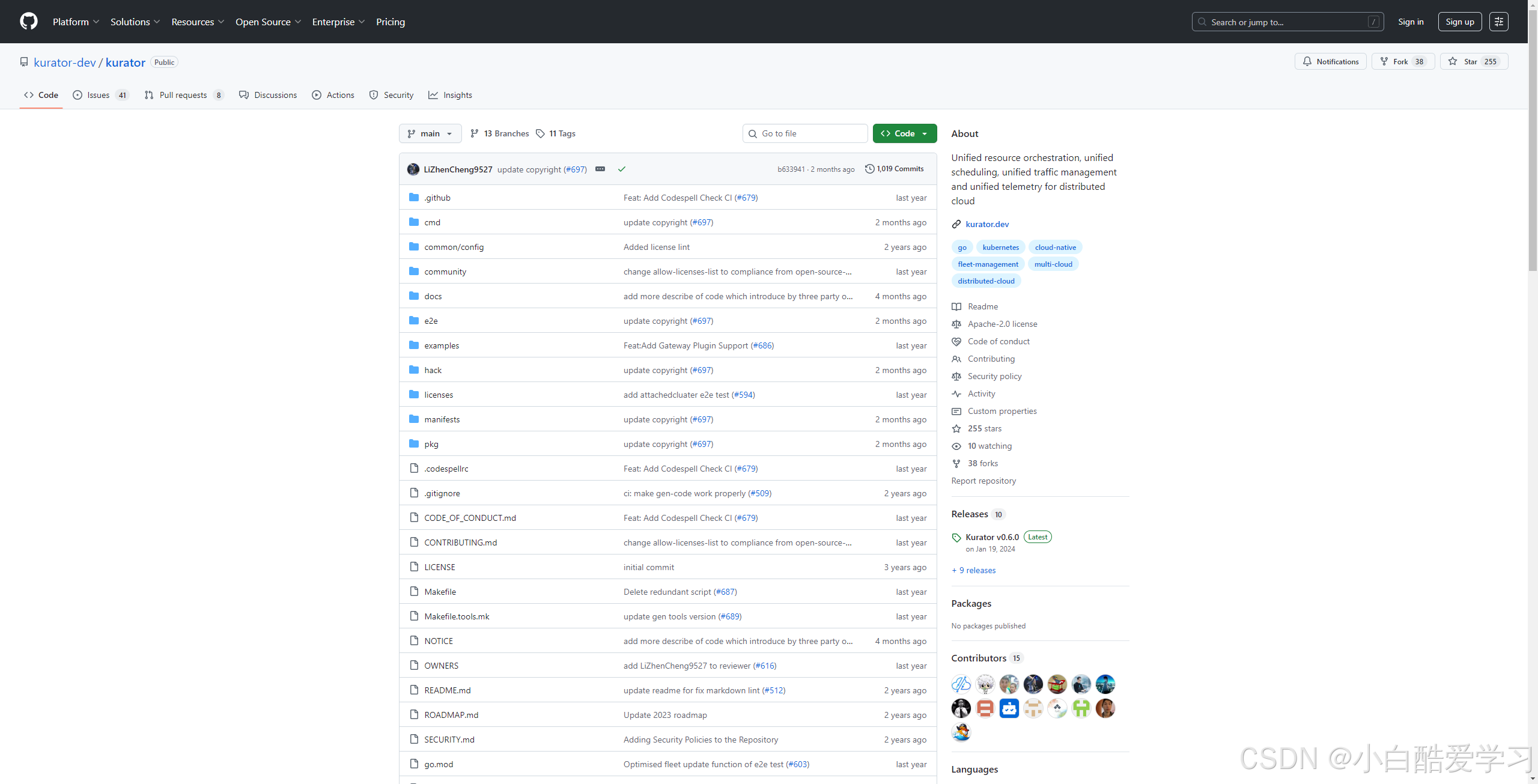
八、企业级案例:基于 Kurator 构建分布式云原生平台的落地之路
下面是一个结合实际经验、略做匿名和抽象的案例:
一家行业中大型企业希望在两家公有云 + 多个边缘工厂站点上搭建统一的分布式云原生平台。
8.1 技术选型:为什么最终落在 Kurator 上?
当时的初始需求包括:
- 多云多集群统一管理;
- 云边协同:工厂现场有上百个边缘节点;
- 统一监控和策略管控;
- 对外需要提供统一应用部署和渐进式发布能力;
- 更希望基于开源生态,而不是单云厂商锁定。
对比了一圈方案:
-
单用 Karmada + 自己拼接周边:
- 优点:多集群应用编排能力强、原生 Kubernetes 体验好;
- 缺点:监控、策略、流水线、流量治理都要自己选型与集成,上线周期偏长。
-
Rancher / KubeSphere 一体化平台:
- 优点: UI 强、开箱即用组件多;
- 缺点:在多云、云边协同场景下,有些能力需要二次扩展;
- 部分组件耦合较深,和已有 GitOps 流程衔接成本较高。
-
原生各云厂商容器服务 + 自研统一层:
- 优点:最大化利用云厂商托管能力;
- 缺点:统一管理与策略层变成完全定制开发,对团队长期维护能力要求高。
最终选择 Kurator 的原因主要有三点:
- 基于 Karmada + FluxCD + Istio 等成熟开源项目,避免“自造轮子”的高维护成本;
- Fleet 抽象非常贴近业务认知:一个 Fleet 就是一个集群舰队,支持云、边、已有集群统一纳管;
- 统一应用分发、监控、策略、Rollout、Pipeline 一整套能力都已经打通,为后续产品化提供基础。
8.2 技术适配与攻坚:从 PoC 到生产的关键环节
在从 PoC 到生产的过程中,有几个关键技术点值得展开:
8.2.1 网络与安全:云上 + VPN + 边缘
- 云平台之间通过 VPN / 专线互通;
- 边缘工厂通过 SD-WAN 接入中心 VPC,并开启 IP 白名单控制;
- Kurator 宿主集群部署在一个相对“中心”的 VPC 中,所有成员集群都能访问它。
Kurator 侧的适配:
- 使用 AttachedCluster 把历史集群接入;
- 将边缘集群的 kubeconfig 权限限制在特定命名空间;
- 对于网络条件不稳定的工厂站点,叠加 KubeEdge 进行边缘自治和断网容忍。
8.2.2 GitOps 体系整合:与现有 Git 平台共存
企业已有:
- 多套 GitLab / GitHub 企业版;
- 不同团队使用不同的 CI 工具(Jenkins、GitLab CI 等)。
我们采取的是渐进过渡策略:
-
第一阶段:
- 保留现有 CI(仅负责构建镜像 + 推送仓库);
- 由 Kurator Application 接管多集群应用分发;
-
第二阶段:
- 把部分项目的 CI 迁移到 Kurator Pipeline;
- 利用预置任务模板 + Rollout 完成渐进式发布;
-
第三阶段:
- 逐步统一“从代码到多集群发布”的流程到 Kurator 门户。
实战经验上,最耗时间的不是改 YAML,而是统一各团队的流程规范与权限模型——Kurator 提供了工具与抽象,但能否用好,取决于组织的协同程度。
8.2.3 监控与告警:从“集群指标”走向“业务视图”
在监控层,我们采用了 Kurator Metric 插件 + Thanos 的方案:
- 每个集群安装 Prometheus + Thanos Sidecar;
- 对象存储使用企业统一的对象存储服务;
- 中央 Grafana 提供多集群视图;
- 业务告警则统一接入企业告警平台(短信、IM、电话)。
实践中发现,真正提升运维效率的是“以 Fleet 为基本维度管理看板和告警”:
例如:
- 针对“亚太生产 Fleet”定义一套告警策略;
- 针对“欧盟合规 Fleet”定义另一套更严格的资源与安全告警。
Kurator 在这里提供的是:一个能把 Fleet 概念贯穿到监控、策略、应用分发的统一模型。
8.3 场景落地:典型业务的多云多集群实践
以“订单系统 + 支付系统”为例,最终落地形态大致如下:
-
集群布局:
- 公有云 A:
cluster-prod-ap-south-1(核心业务集群) - 公有云 B:
cluster-prod-eu-central-1(满足欧盟合规) - 多个工厂边缘集群:
cluster-edge-factory-*
- 公有云 A:
-
Fleet 规划:
fleet-global-prod:所有生产集群(云上)fleet-edge:所有工厂边缘集群
-
应用分发:
-
订单系统(延迟敏感 + 跨区域部署):
- 使用 Application 在
fleet-global-prod内部滚动部署; - 通过 Rollout 金丝雀发布 + A/B 测试新推荐策略。
- 使用 Application 在
-
支付系统(极度安全敏感):
- 在各区域采用蓝绿发布;
- 严格的 Pod 安全策略与资源配额策略统一由 Fleet Policy 管理。
-
-
监控与策略:
-
安全策略:
- 全局统一 Pod 安全标准;
- 特定命名空间还叠加了自定义 Kyverno 策略(如禁止使用
latest镜像)。
-
监控与告警:
- 对订单系统的延迟指标、错误率、并发量等进行多集群聚合;
- 有专门的“Fleet 级 SLO 看板”。
-
8.4 用户反馈、商业效益与生态价值
经过一段时间运行,团队反馈与效果大致可以总结为:
-
运维效率:
- 新增一个生产集群,只需创建 Cluster / AttachedCluster + 加入 Fleet + 复用已有 Application;
- 从“新增一个区域需要一周”缩短到“半天内完成并接入统一平台”。
-
发布风险:
- 使用 Rollout 完成渐进式发布后,发布事故明显减少;
- 回滚由“应急手册 + 人工操作”变成“自动化策略 + 一键操作”。
-
合规与安全:
- 多集群统一策略管理让安全团队可以以 Kyverno Policy 的方式定义基线;
- 通过 Kurator Pipeline 的软件供应链安全能力,建立了镜像签名与溯源链路。
-
生态价值:
- Kurator 本身使用 Karmada / Istio / Prometheus / FluxCD / Kyverno / Tekton 等主流开源项目,使企业团队有机会深入理解这些项目并参与社区贡献;
- 这也让平台团队与社区形成了良性互动,bug 与新需求可以通过 Issue / PR 回馈。
我们可以看到,一直在维护贡献:
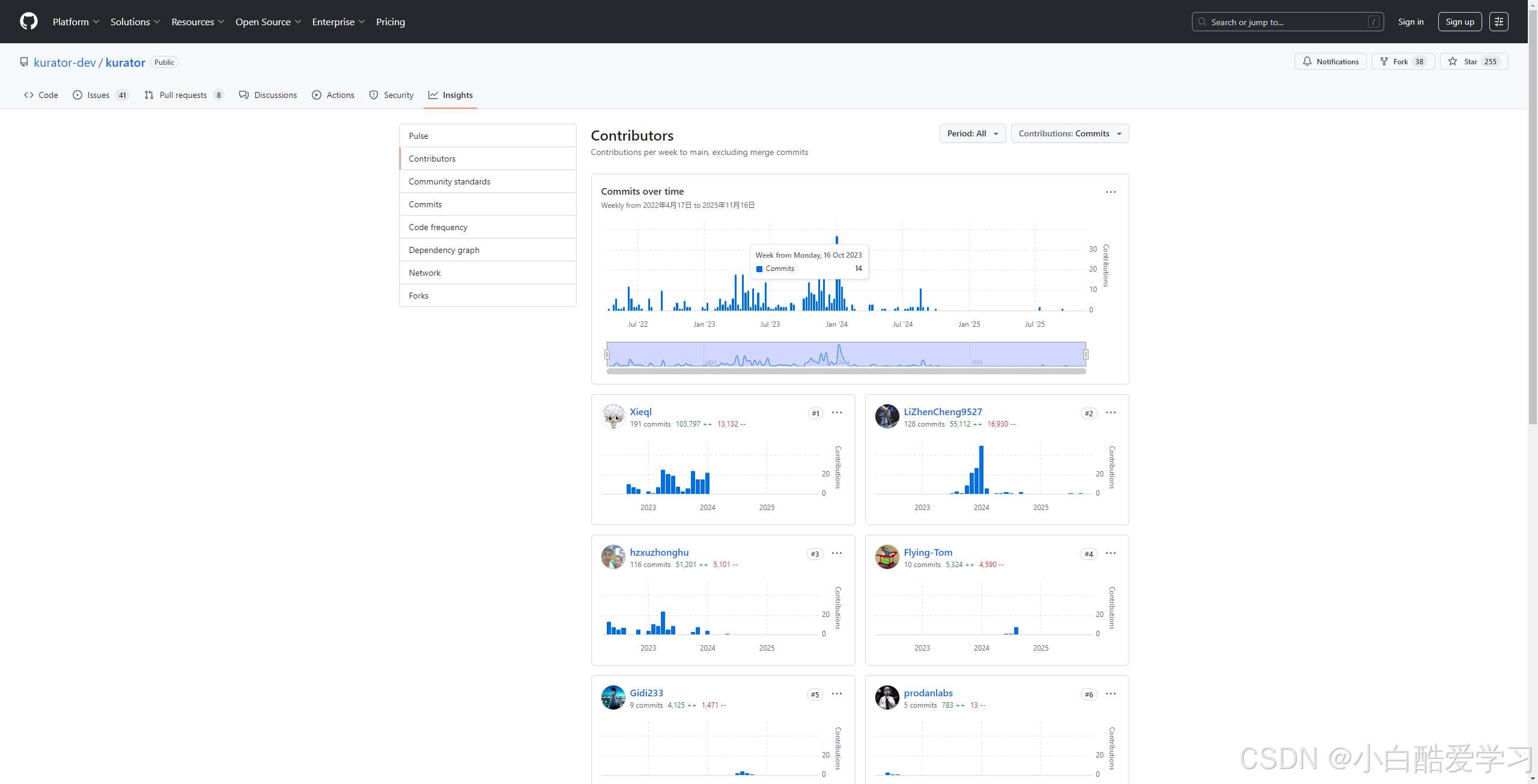
九、我的 Kurator 社区参与与贡献实践(简述)
虽然本文主要属于“探索实战”类型,但在实际使用 Kurator 的过程中,我也尽量通过社区渠道回馈问题与改进建议,这里简单提一下这部分经历,方便你如果要改成【贡献经历】类稿件时使用:
-
Issue 贡献:
- 提交了关于 AttachedCluster 文档中示例字段与实际 CRD 不完全一致的问题;
- 报告了 Fleet 插件在某些场景下对 CRD 安装顺序依赖过强的问题。
-
PR 贡献:
- 帮忙修复了一个 CLI 输出的小问题(如
kurator fleet list在某版本中对AttachedCluster状态展示不准确); - 在文档中补充了部分“网络不稳定环境下的注意事项”。
- 帮忙修复了一个 CLI 输出的小问题(如
-
与 Maintainer 协作:
- 在 Slack 频道中与 Maintainer 讨论了在边缘场景下 KubeEdge 与 Kurator 配合使用的最佳实践;
- 帮忙验证了某些新特性在多云、多集群场景下的兼容性。
如果你希望把本文调整为【贡献经历】类稿件,可以把第八、九节展开写成“从使用者到贡献者”的故事。
十、前瞻创想:Kurator 之后,分布式云原生还能走向哪里?
Kurator 今天的样子,其实就是“把主流云原生生态组件,以 Fleet 为载体,整合成一个分布式云原生管理平台”。
10.1 Kurator 集成项目带来的启发
从集成项目的角度看:
- Karmada:提供多集群应用调度与编排核心能力;
- Istio / Nginx / Kuma:提供服务网格与流量治理底座;
- Prometheus / Thanos / Grafana:提供统一指标与可观测性;
- FluxCD:提供 GitOps 化的应用分发与配置管理;
- Kyverno:提供策略即代码与多集群安全基线;
- KubeEdge:让云边协同成为可能;
- Volcano:在 AI / 大数据等批处理场景中提供更强的调度能力;
- Tekton / Tekton Chains:支撑 CI/CD 与软件供应链安全。
从这些项目身上,我们可以看到 Kurator 的设计哲学:
- 重用成熟组件,而不是重新实现;
- 把“如何拼起来”作为核心价值,通过统一 CRD / Fleet 抽象提供平台能力;
- 用 GitOps 将分布式环境的复杂配置压缩到可审计、可回滚的配置层。
10.2 未来可期的几个方向
结合实践,我对 Kurator 未来的发展有几方面的想象和建议:
-
更强的“策略即平台”能力:
- 目前 Kyverno + Fleet 可以很好地完成多集群策略分发;
- 未来可以考虑引入更高层次的策略语言,对“多云部署拓扑、灾备级别、合规约束”进行统一建模;
- 甚至可以在策略层面引入“成本约束”,让策略引导调度与资源规划。
-
更丰富的边缘与物联网场景支持:
- 在 KubeEdge 集成基础上,进一步优化断网自治、数据上报策略;
- 提供针对弱网环境的“异步 GitOps”机制,让边缘集群能够在长时间断联情况下安全运行并缓慢收敛。
-
AI 辅助的运维与调度:
- 基于多集群监控数据、事件日志和变更记录,构建智能推荐和异常检测能力;
- 自动识别异常发布、流量异常、资源浪费等并给出调优建议。
-
标准化多集群 API 与生态互通:
- 将 Fleet / Application / Rollout 等抽象与 CNCF / SIG 多集群生态更紧密地对齐;
- 让 Kurator 在“多云多集群管理的事实标准”这一方向持续演进。
-
面向平台工程(Platform Engineering)的产品化集成:
- 把 Kurator 的能力进一步通过内部开发者门户(IDP)包装给应用团队;
- 让应用工程师只需要操作“一个表单 + 一个 Git 仓库”,就能自动获得 CI/CD + GitOps + 渐进式发布 + 多集群观测与策略能力。
十一、结语:云原生从“集群视角”走向“舰队视角”
从最初的单集群 Kubernetes,到今天的多云、多集群、云边协同,云原生的复杂度已经大大超出了“只会写几份 Deployment YAML 就行”的时代。
Kurator 做的事情,本质是:
-
把多云、多集群环境里本该统一的东西重新收拢起来:
- 集群生命周期治理;
- 应用分发与 GitOps;
- 流量治理与渐进式发布;
- 监控与策略;
- CI/CD 与软件供应链安全。
-
用 Fleet / Application / Rollout / Pipeline 等抽象,把这些统一能力变成可编排、可扩展的平台能力。
对一线平台团队来说,Kurator 并不是一个“魔法一键”的银弹,而更像一个“构建分布式云原生平台的实战工具箱”。只要你愿意在早期花时间理解这些抽象,并结合自身组织与业务特点进行裁剪与整合,它可以帮你在后续几年持续地降低平台复杂度、控制风险,并不断积累可复用的云原生工程实践。
❤️ 如果本文帮到了你…
- 请点个赞,让我知道你还在坚持阅读技术长文!
- 请收藏本文,因为你以后一定还会用上!
- 如果你在学习过程中遇到bug,请留言,我帮你踩坑!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 32
32 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)