【前瞻创想】Kurator·云原生实战派:以“分布式控制平面”重塑多云与云边一体化
👋 你好,欢迎来到我的博客!我是【菜鸟不学编程】
我是一个正在奋斗中的职场码农,步入职场多年,正在从“小码农”慢慢成长为有深度、有思考的技术人。在这条不断进阶的路上,我决定记录下自己的学习与成长过程,也希望通过博客结识更多志同道合的朋友。
🛠️ 主要方向包括 Java 基础、Spring 全家桶、数据库优化、项目实战等,也会分享一些踩坑经历与面试复盘,希望能为还在迷茫中的你提供一些参考。
💡 我相信:写作是一种思考的过程,分享是一种进步的方式。
如果你和我一样热爱技术、热爱成长,欢迎关注我,一起交流进步!
全文目录:
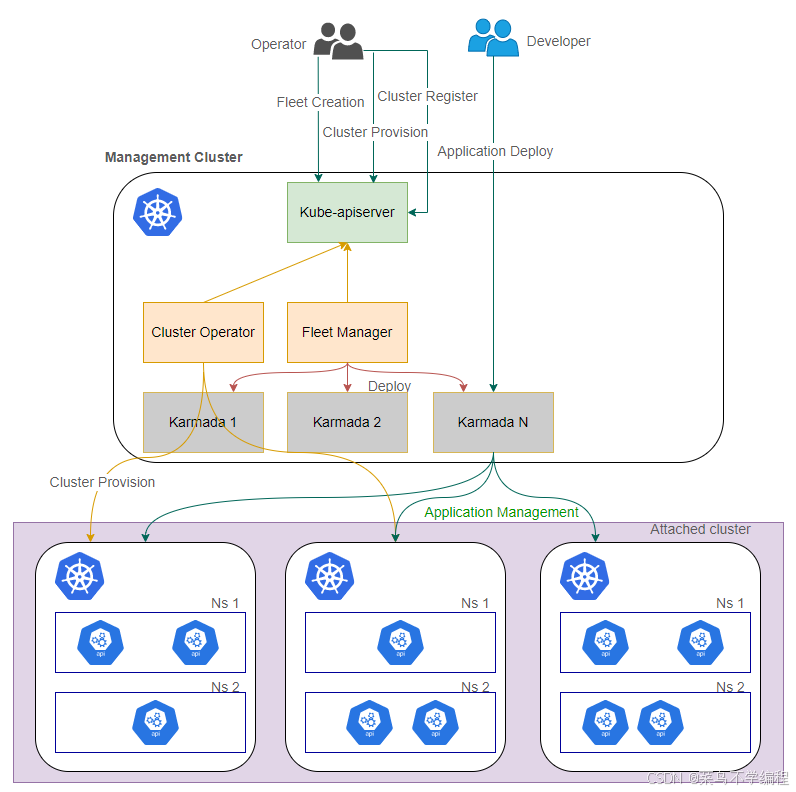
一、从“集群为中心”到“舰队为中心”:为什么需要 Kurator 这一层?
Kubernetes 解决了“单集群”维度的资源编排问题,但真实企业场景已经很难用“单集群视角”来描述:
- 不同地区的多云部署:同一业务在多家公有云上运行;
- 边缘节点成百上千:门店、工厂、基站都有自己的 K8s;
- 历史技术栈复杂:有自建集群、托管集群,也有各种发行版。
传统做法往往是每个集群配一套工具:
一套监控、一套策略、一套 CI/CD、一套服务网格……
每套都“能用”,整体看却是“不可控”:版本漂移、配置不一致、策略难统一、发布策略无法全局把控。
Kurator 的定位,就是在 Kubernetes 之上,再抬一层“分布式云原生控制平面”:
- 持久化基础设施即代码(IaC)理念,以声明式方式创建和管理集群;
- 利用 Fleet 概念管理“集群舰队”,而不是单个 cluster;
- 站在 Kubernetes / Istio / Prometheus / FluxCD / KubeEdge / Volcano / Karmada / Kyverno 等项目肩膀上,做统一编排和治理,而非重造轮子。
如果把单集群 Kubernetes 类比为“船舶”,Kurator 更像是“舰队指挥系统”:
它不改变每一艘船的内部结构,而是负责协同、调度、视图与策略。
下面这篇文章,从“架构+前瞻”的角度拆解 Kurator 的价值和潜力:
- Kurator 的整体架构与设计取舍;
- 对核心集成项目(Karmada、Istio、Prometheus、KubeEdge、Volcano 等)的再理解;
- 基于 Kurator 的三类典型分布式场景设计与代码示例;
- 站在社区参与者视角,对分布式云原生发展方向的一些建议。
我们先来看看官方所给的Kurator产品架构图:
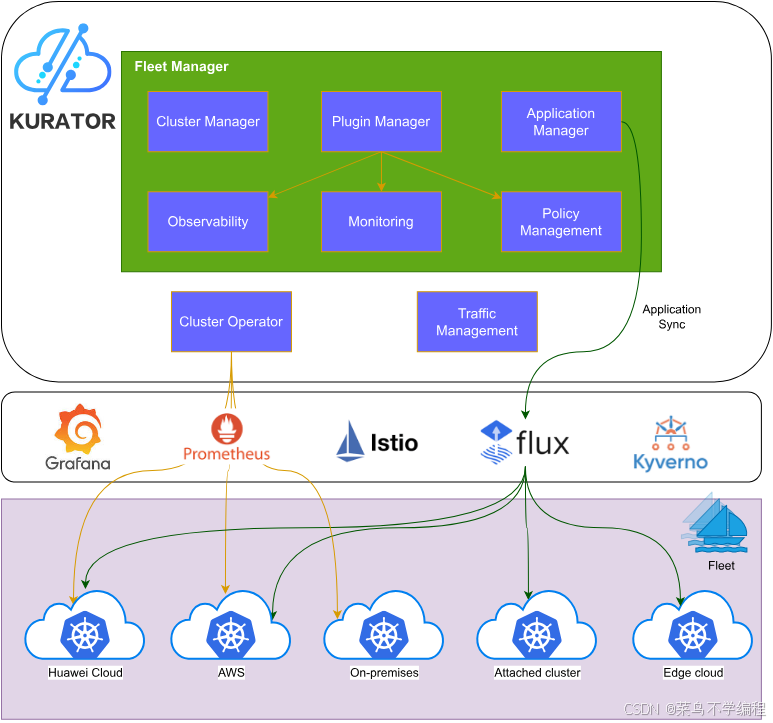
二、Kurator 的架构视角:一份“多云控制平面”的设计蓝图
官方给出的 Kurator 核心描述是:
“Kurator is an open source distributed cloud native platform that helps users to build their own distributed cloud native infrastructure.”
结合公开代码与文档,其整体可以拆成三层:
-
资源层(Resource Plane):
- 各种 Kubernetes 集群:公有云托管、自建集群、边缘集群;
- 集群内部署了 Istio、Prometheus、Kyverno、Volcano 等运行时组件。
-
控制层(Control Plane):
- Kurator CLI + Cluster Operator:负责集群生命周期、基础设施即代码;
- Fleet Manager:负责多集群编排、插件管理、统一应用分发、统一监控、统一策略、Rollout 等。
-
体验层(Experience Plane):
- GitOps 工作流(基于 FluxCD);
- Tekton/Argo 为核心的 Pipeline 与软件供应链安全;
- 对上层 Portal、IDP(内部开发者平台)友好的 API 和 CRD。
2.1 Fleet:Kurator 的第一性抽象
在 Kurator 世界里,“Fleet” 是最重要的概念之一:一个 Fleet 就是一组逻辑相关的集群及其插件配置。
一个简化的 Fleet 定义示例(经改写):
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: global-online
namespace: kurator-fleet
spec:
clusters:
- name: prod-ap-south
kind: AttachedCluster
- name: prod-eu-west
kind: AttachedCluster
plugin:
metric:
thanos:
objectStoreConfig:
secretName: thanos-s3-config
policy:
kyverno:
podSecurity:
standard: restricted
validationFailureAction: Enforce
rollout:
provider: istio
defaultStrategy: canary
要点:
clusters指定构成 Fleet 的成员集群,可以是 Kurator 创建的,也可以是 AttachedCluster;plugin.metric、plugin.policy、plugin.rollout等描述该 Fleet 统一启用的插件;- 上层 Application、Rollout、Pipeline 都可以以 Fleet 为单位进行编排。
从架构视角看,Fleet 把“多云多集群”这个问题抽象为一个普通的 CR 对象,使得:
- 多集群监控、策略、应用分发等能力都可以以“Fleet 级”声明展开;
- 组织结构可以与 Fleet 对应:比如“一条业务线一个 Fleet”,或者“一个区域一个 Fleet”。
2.2 AttachedCluster:从“我创建的集群”到“我负责的所有集群”
另一个重要抽象是 AttachedCluster:用于纳管 Kurator 之外创建的 Kubernetes 集群(云厂商托管、自建、边缘都可以)。
示例(简化):
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: legacy-billing
namespace: kurator-fleet
spec:
kubeconfig:
name: legacy-billing-kubeconfig
key: config
优势在于:
- 对已有集群“零侵入”:不要求修改发行版,不强制安装特定组件;
- 用 Secret 封装 kubeconfig,将访问控制与 GitOps、RBAC 体系结合;
- 结合 Fleet,统一纳入监控、策略、应用分发与 Rollout 的治理范围。
这就意味着 Kurator 不仅适用于“绿色田地重建”,也适用于“棕地整合”。
当然,这个项目是直接开源的,你们可以去拉取:
三、Kurator 内置开源项目再解读:为什么选它们,Kurator 又做了什么?
官方说明 Kurator “站在多个主流云原生项目的肩膀上”,包括 Kubernetes、Istio、Prometheus、FluxCD、KubeEdge、Volcano、Karmada、Kyverno 等。
从架构设计角度看,这些组件承担了不同的职责。
3.1 Karmada:把“多集群调度”做成底座
Karmada 为多集群应用调度提供了原生 Kubernetes 风格的控制平面:通过 CRD(如 PropagationPolicy、ClusterPropagationPolicy)把跨集群部署策略显式化。
Karmada 的特点:
- 与 K8s API 同构:对应用开发者几乎透明;
- 支持跨集群故障转移、主动-主动、跨地域容灾等高级调度策略;
- 避免深度云厂商绑定,可以同时管理公有云、私有云和边缘集群。
在 Kurator 里,Karmada 是实现“多集群编排”的关键基础。统一应用分发和 Rollout 能力,很多时候最终是通过 Karmada 驱动多个成员集群中的资源变化。
从架构角度看:
Kurator 把 Karmada 的“多集群调度”能力提升到更高一层:借助 Fleet 将不同集群组合成策略域,然后通过 Application、Rollout、Policy 在该域内统一落地。
3.2 Istio / Gateway:统一流量治理与渐进式发布
在服务网格和流量治理方面,Kurator 并没有试图自研数据面,而是基于 Istio 和 Ingress Gateway 来构建统一流量治理能力:
- Istio 提供细粒度路由、熔断、限流、可观测性基础;
- Kurator 通过 Rollout 插件,将金丝雀、A/B、蓝绿策略抽象为 Rollout CR,并通过 Flagger 等实现与 Istio 的联动。
一个简化的 Rollout 示例(面向 Istio):
apiVersion: rollout.kurator.dev/v1alpha1
kind: Rollout
metadata:
name: checkout-canary
namespace: commerce
spec:
workload:
apiVersion: apps/v1
kind: Deployment
name: checkout
traffic:
provider: istio
host: checkout.commerce.svc.cluster.local
port: 80
strategy:
canary:
steps:
- weight: 10
- weight: 30
- weight: 60
maxWeight: 70
autoPromotionEnabled: true
autoRollbackEnabled: true
与直接写 VirtualService 相比:
- Kurator 用 Rollout 统一描述“发布目标 + 流量策略 + 自动化行为”;
- Istio 聚焦于数据面转发,避免用户被路由细节绑死;
- 同样的 Rollout 抽象未来可映射到 Nginx、Kuma 等不同 data plane 上。
3.3 Prometheus / Thanos / Grafana:观测能力的“多集群放大器”
Kurator 的统一监控方案采用 Prometheus + Thanos + Grafana 组合,通过 Fleet 插件自动为每个集群安装 Prometheus + Thanos Sidecar,并在中心侧搭建 Thanos Query 与 Grafana。
典型 Fleet 监控配置(改写):
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: observe-all
namespace: kurator-fleet
spec:
clusters:
- name: prod-cn
kind: AttachedCluster
- name: prod-eu
kind: AttachedCluster
- name: prod-us
kind: AttachedCluster
plugin:
metric:
thanos:
objectStoreConfig:
secretName: thanos-oss-config
grafana:
enabled: true
价值在于:
- 把“多集群统一视图”的复杂部署步骤隐藏在 Fleet plugin 背后;
- 使用对象存储做长周期指标存储,多集群数据统一聚合;
- 未来可以在指标上叠加 SLO/SLA 管理,甚至AI驱动告警优化。
3.4 Kyverno:让“策略即代码”从单集群走向多云域
Kyverno 提供了以 Kubernetes 原生风格编写策略的能力(使用 YAML 而非 Rego),可以对 Pod、Namespace、Ingress 等资源进行校验、变更和生成。
Kurator 利用 Kyverno 构建统一策略管理插件,通过 Fleet 把策略批量分发到多集群:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: security-baseline
namespace: kurator-fleet
spec:
clusters:
- name: prod-cn
kind: AttachedCluster
- name: prod-eu
kind: AttachedCluster
plugin:
policy:
kyverno:
podSecurity:
standard: baseline
severity: high
validationFailureAction: Audit
这里 Kurator 提供的是“策略编排层”:
- 把 Kyverno 定位为策略执行引擎;
- 通过 Fleet 统一控制策略的作用范围;
- 未来可以在策略之上叠加更高层的“规范模型”(如合规模板)。
3.5 KubeEdge / Volcano:云边一体与算力密集场景的延伸
在边缘场景与批处理计算方面,Kurator 集成了 KubeEdge 与 Volcano:
-
KubeEdge:
- 让边缘节点具备离线自治能力,支持弱网场景;
- 与 Kurator 结合后,边缘集群可以通过 AttachedCluster + Fleet 接入统一控制面。
-
Volcano:
- 面向 AI 训练、大数据批处理、科学计算等场景提供更强的作业调度能力;
- Kurator 可以通过 Application 和策略将 Volcano 能力按 Fleet 范围进行下发与治理。
这些项目的引入意味着:
Kurator 的目标不只是“多云管理”,而是面向“分布式算力形态”的统一抽象。
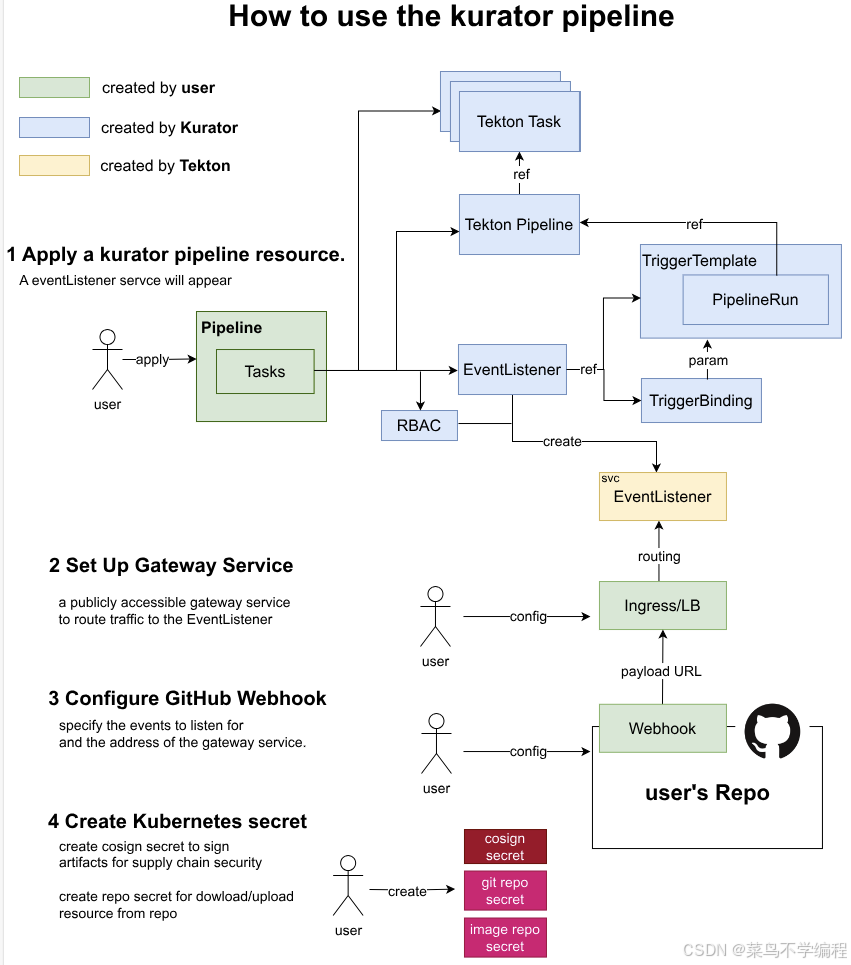
如下是其相关架构流程图:
四、三个典型场景设计:从架构图到 Kurator CR 的落地示例
下面通过三个典型场景,从“架构-抽象-CR YAML”的角度展示 Kurator 的前瞻价值。
场景一:跨云主动-主动的订单系统
目标:订单系统在两家公有云(A、B)同时在线,一家云故障时另一家自动接管,用户基本无感知。
4.1.1 架构设计要点
- 集群:
cluster-ap-a(云 A)、cluster-ap-b(云 B); - Fleet:
fleet-ap-orders,将两个集群组合为一个逻辑“生产域”; - Karmada:负责跨集群副本分布与故障转移;
- Istio:跨云入口统一,通过 Global Gateway 或 Global DNS + 各区域 Gateway 实现;
- Kurator Application:统一应用分发;
- Kurator Rollout:跨集群渐进式发布。
4.1.2 关键 Kurator 配置示例
Fleet 定义:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: fleet-ap-orders
namespace: kurator-fleet
spec:
clusters:
- name: cluster-ap-a
kind: AttachedCluster
- name: cluster-ap-b
kind: AttachedCluster
plugin:
metric:
thanos:
objectStoreConfig:
secretName: thanos-orders
policy:
kyverno:
podSecurity:
standard: restricted
Application 定义:
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: orders-service
namespace: kurator-fleet
spec:
source:
gitRepository:
url: https://github.com/example/orders.git
ref:
branch: main
interval: 2m
syncPolicies:
- name: ap-a
destination:
fleet: fleet-ap-orders
kustomization:
path: ./deploy/ap-a
targetNamespace: orders
- name: ap-b
destination:
fleet: fleet-ap-orders
kustomization:
path: ./deploy/ap-b
targetNamespace: orders
Rollout 定义(跨集群金丝雀):
apiVersion: rollout.kurator.dev/v1alpha1
kind: Rollout
metadata:
name: orders-cross-cloud-canary
namespace: orders
spec:
workload:
apiVersion: apps/v1
kind: Deployment
name: orders-api
traffic:
provider: istio
host: orders.global.example.com
strategy:
canary:
steps:
- weight: 10
- weight: 30
- weight: 60
analysis:
interval: 1m
metrics:
- name: error-rate
type: prometheus
query: |
sum(rate(http_requests_total{app="orders-api", code=~"5.."}[5m])) /
sum(rate(http_requests_total{app="orders-api"}[5m]))
threshold:
max: 0.01
从“前瞻创想”的角度看,这个模式可以进一步演化:
- 将跨云故障转移策略上升到策略层统一建模(如“跨可用区、跨云”多层 HA 策略模板);
- 结合成本信息(实例价、带宽价),实现“成本感知”的多云调度策略。
场景二:云边协同的实时质检平台
目标:工厂边缘节点运行实时质检模型,云侧负责模型管理与数据汇总;边缘网络不稳定时需要保障本地自治。
4.2.1 架构设计要点
- 边缘集群:
edge-factory-01~edge-factory-n,运行 KubeEdge; - 中心集群:
central-ops,运行 Kurator 控制面; - Fleet:
fleet-edge-quality,纳管所有边缘集群; - Application:推送推理服务、数据采集 agent;
- Metric 插件:将关键指标(模型延迟、错误率、设备状态)聚合到中心。
4.2.2 Kurator 配置示例
AttachedCluster 与 Fleet:
apiVersion: cluster.kurator.dev/v1alpha1
kind: AttachedCluster
metadata:
name: edge-factory-01
namespace: kurator-fleet
spec:
kubeconfig:
name: edge-factory-01-kubeconfig
key: config
---
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: fleet-edge-quality
namespace: kurator-fleet
spec:
clusters:
- name: edge-factory-01
kind: AttachedCluster
- name: edge-factory-02
kind: AttachedCluster
plugin:
metric:
thanos:
objectStoreConfig:
secretName: thanos-edge
policy:
kyverno:
podSecurity:
standard: baseline
Application:为所有工厂分发模型服务
apiVersion: apps.kurator.dev/v1alpha1
kind: Application
metadata:
name: vision-quality
namespace: kurator-fleet
spec:
source:
gitRepository:
url: https://github.com/example/edge-vision.git
ref:
tag: v1.2.0
interval: 5m
syncPolicies:
- name: edge-all
destination:
fleet: fleet-edge-quality
kustomization:
path: ./deploy/edge
targetNamespace: vision
prune: true
这里的关键前瞻点是:
- 未来可以为边缘场景引入“断网 GitOps”模式:在网络完全不可达时,边缘节点根据本地缓存继续运行,网络恢复后进行差异合并;
- 将模型版本、数据分发策略与 Application / Policy 结合,形成“模型即策略”的统一治理模式。
场景三:AI 训练集群的批处理算力池
目标:将多套 GPU 集群组合为统一算力池,对 AI 训练任务进行批处理调度和资源弹性分配。
4.3.1 架构设计要点
- 多个 GPU 集群:
gpu-cn-1、gpu-eu-1; - Volcano 作为批处理调度器;
- Fleet:
fleet-ai-training,统一启用 Volcano 插件与监控插件; - Application:将训练任务描述(Job、MPIJob 等)统一以 GitOps 方式下发;
- Pipeline:从代码到模型镜像构建,再到训练任务提交的一体化流水线。
4.3.2 关键配置与 Code 片段示例
Fleet 开启 Volcano 插件(概念示例):
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: fleet-ai-training
namespace: kurator-fleet
spec:
clusters:
- name: gpu-cn-1
kind: AttachedCluster
- name: gpu-eu-1
kind: AttachedCluster
plugin:
batch:
volcano:
enabled: true
一个典型的 Volcano Job(训练任务)YAML:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: bert-pretrain
namespace: ai-lab
spec:
minAvailable: 4
schedulerName: volcano
tasks:
- replicas: 4
name: worker
template:
spec:
containers:
- name: trainer
image: registry.example.com/ai/bert-pretrain:v2025.01
resources:
requests:
nvidia.com/gpu: 1
cpu: "8"
memory: 32Gi
restartPolicy: Never
Kurator Pipeline(构建镜像并提交任务)的示例:
apiVersion: pipeline.kurator.dev/v1alpha1
kind: Pipeline
metadata:
name: bert-train-pipeline
namespace: cicd
spec:
git:
url: https://github.com/example/bert-train.git
revision: main
tasks:
- name: clone
template: git-clone
- name: unit-test
template: python-test
runAfter: [clone]
- name: build-image
template: build-and-push-image
runAfter: [unit-test]
params:
- name: image
value: registry.example.com/ai/bert-pretrain:$(context.pipelineRun.uid)
- name: submit-job
template: kubectl-apply
runAfter: [build-image]
params:
- name: manifests
value: ./deploy/volcano/job.yaml
在这个场景中,Kurator 的前瞻价值是:
- 帮助企业把“多套 GPU 集群”收敛成统一算力池;
- 将 AI 训练的工作流(代码、镜像、训练任务、监控)纳入统一 Pipeline 与 Fleet 控制;
- 未来可叠加成本、碳排放、能源利用等维度做“绿色调度”。
五、基于 Kurator 实战后,对分布式云原生发展的几点建议
结合对 Kurator 和相关开源项目的使用与观察,这里从“分布式云原生未来”角度,提出几条建议和创想。
建议一:从“多集群编排”走向“策略驱动的分布式基础设施”
当前 Kurator 已经通过 Fleet + Karmada 实现了多集群应用编排与管理;下一步可以进一步把“部署拓扑”与“策略”融合起来:
- 将“同城双活、跨地域冷备、多云混合部署”等模式抽象为标准策略模板;
- 在策略中同时描述 RPO/RTO、可用区拓扑、合规约束(如数据不出境);
- Kurator 负责根据策略自动生成 Karmada Policy、Application、Rollout 等低层资源。
这样,平台工程团队可以用一个高层策略对象描述整个分布式部署,而不是手工维护多层 YAML。
建议二:让“算力与数据”成为 Fleet 的一等公民
目前 Fleet 对集群的抽象更多集中在“集群本身”,未来完全可以把算力与数据纳入同一逻辑单元:
- 在 Fleet 中声明“算力配额”和“数据域边界”;
- 使用 Policy 定义“数据跨境”、“敏感数据仅在某区域处理”等约束;
- 结合 Volcano 等组件,按 Fleet 维度进行 AI 训练作业调度。
这将使 Kurator 从“多云控制面”进化为“多云+多算力+多数据域”的统一编排层。
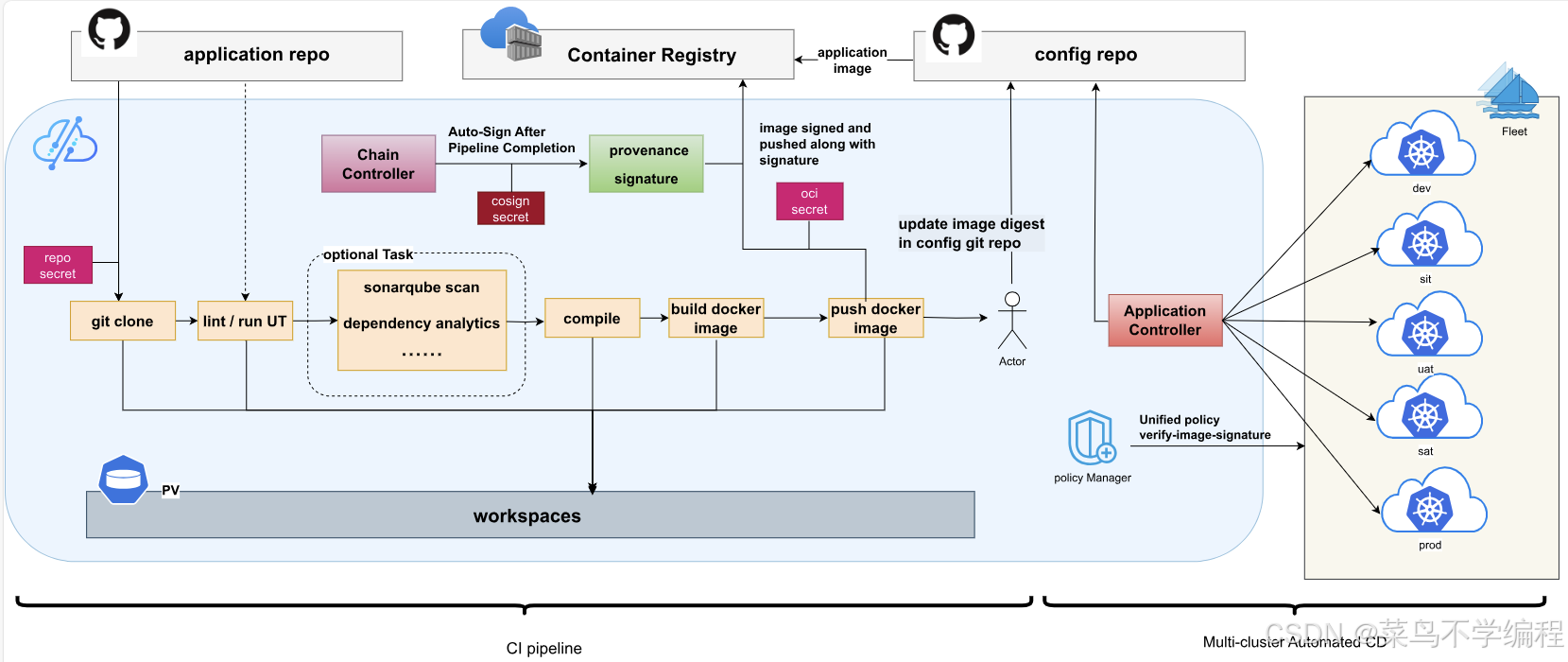
建议三:把软件供应链安全做成默认能力,而不是附加组件
Kurator 已经引入了基于 Tekton Chains 的供应链安全能力,以满足 SLSA 对签名与溯源的要求。
前瞻方向上可以进一步加强:
- 在 Pipeline 中,将签名、SBOM 生成、合规扫描设为默认步骤;
- 在 Policy 层,强制要求仅允许带有效签名且通过 SBOM 校验的镜像运行;
- 与 Rollout 集成:若新版本镜像不满足供应链要求,禁止进入流量灰度阶段。
这会让“安全”真正成为默认内建的能力,而不是后补。
建议四:面向平台工程实践,抽象出“应用平台层”的通用模型
当前不少企业都在做内部开发者平台(IDP),Kurator 提供的是“平台的基础设施底座”。未来可以考虑:
- 在 Kurator 之上构建统一的应用模板(Application Template),提供高层 DSL;
- 把常见应用形态(Web 服务、API 服务、数据流水线、AI 训练/推理)固化为平台级产品;
- 通过 CRD 与自定义控制器,把平台能力以 Kubernetes 原生方式暴露给 IDP。
这样,应用团队只看到“一个界面 + 一个仓库”,而平台团队在背后使用 Kurator 实现多云多集群与安全策略。
建议五:与社区深度融合,推动多云标准化
Kurator 本身建立在众多 CNCF 生态项目之上(Karmada、Istio、Prometheus 等),未来可以:
- 与 Karmada / Flux 等项目共同探索多集群 API 标准化;
- 在 SIG-MultiCluster / WG-MultiTenant 等社区工作组中推动实践经验标准化;
- 让 Kurator 中的抽象(Fleet、Application、Rollout、Policy)成为社区可参考的实践模型。
当然,讲到这里,感兴趣的话,直接去clone 代码体验下吧:
六、结语:Kurator 不是“终点产品”,而是一条可持续演进的道路
在多云、多集群、云边一体已经成为常态的大背景下,企业需要的不只是一套“好用的工具”,而是一条“可持续演进的云原生架构路径”。
从这个角度看 Kurator:
- 它并不试图替代 Kubernetes、Istio、Prometheus、Karmada 等项目,而是将它们组合成一个可编排、可扩展的分布式控制平面;
- 它提供的 CR 抽象(Fleet、Application、Rollout、Policy、Pipeline),让平台团队可以站在“舰队视角”设计系统,而不是困在单集群视角里做局部优化;
- 它与 GitOps、Pipeline、供应链安全的结合,为未来的“平台工程”提供了坚实的基础。
从实践者角度,我更看重 Kurator 的一个特质:
它不是一个“封闭产品”,而是一个“持续与社区共同演进的开放平台”。
这意味着,只要你有足够的想象力和工程能力,就可以基于 Kurator 构建出符合自己行业特点的分布式云原生平台,而不必从零开始搭积木。
并且提供详细的文档资料等开源资料:
部分文章配图来自互联网,如有侵权,还请联系下架删除。
📝 写在最后
如果你觉得这篇文章对你有帮助,或者有任何想法、建议,欢迎在评论区留言交流!你的每一个点赞 👍、收藏 ⭐、关注 ❤️,都是我持续更新的最大动力!
我是一个在代码世界里不断摸索的小码农,愿我们都能在成长的路上越走越远,越学越强!
感谢你的阅读,我们下篇文章再见~👋
✍️ 作者:某个被流“治愈”过的 Java 老兵
📅 日期:2025-11-20
🧵 本文原创,转载请注明出处。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 29
29 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)