Triton-Ascend 算子开发经验谈:从入门到性能调优实战
最近一段时间,我一直在深度体验和研究华为昇腾(Ascend)平台上的 Triton 算子开发。众所周知,Triton 作为 OpenAI 推出的类 Python 高性能算子开发语言,以其极低的学习门槛和接近手写 CUDA/Ascend C 的性能,迅速成为了 AI 编译领域的宠儿。
随着昇腾生态的日益完善,Triton 对 Ascend NPU 的支持也越来越成熟。今天,我就结合我最近在 triton-ascend 项目上的实战经验,为大家分享一篇关于 Triton 在昇腾 NPU 上的开发经验谈。本文将从环境搭建、编程范式、性能调优、到调试避坑,全方位地为大家复盘我的开发心路历程。
一、 初识 Triton-Ascend
在昇腾平台上,我们通常使用 Ascend C 来开发高性能算子。Ascend C 确实强大,它赋予了我们对硬件的极致控制权,但不可否认,它的上手门槛相对较高,需要开发者对 Tiling(切分)、流水线同步、内存管理有非常深刻的理解。
而 Triton 的出现,仿佛是一股清流。它允许我们用 Python 语法来描述计算逻辑,同时自动处理复杂的内存同步和指令调度。在昇腾 NPU 上,Triton 的后端会自动将 Python AST(抽象语法树)转换为 TTIR,再进一步降级为 AscendNPU IR,最终生成可以在 AI Core 上运行的二进制代码。
对于想要快速验证算法原型,或者对性能要求极高但不想陷入底层指令细节的开发者来说,Triton-Ascend 是一个完美的平衡点。
二、 环境准备与项目结构解析
一切的开始,都源于源码的获取。我首先从 GitCode 上拉取了官方的仓库:
git clone https://gitcode.com/Ascend/triton-ascend.git
cd triton-ascend
在开始写代码之前,我习惯先通读一下项目的目录结构,这有助于我们理解整个编译栈的运作流程。
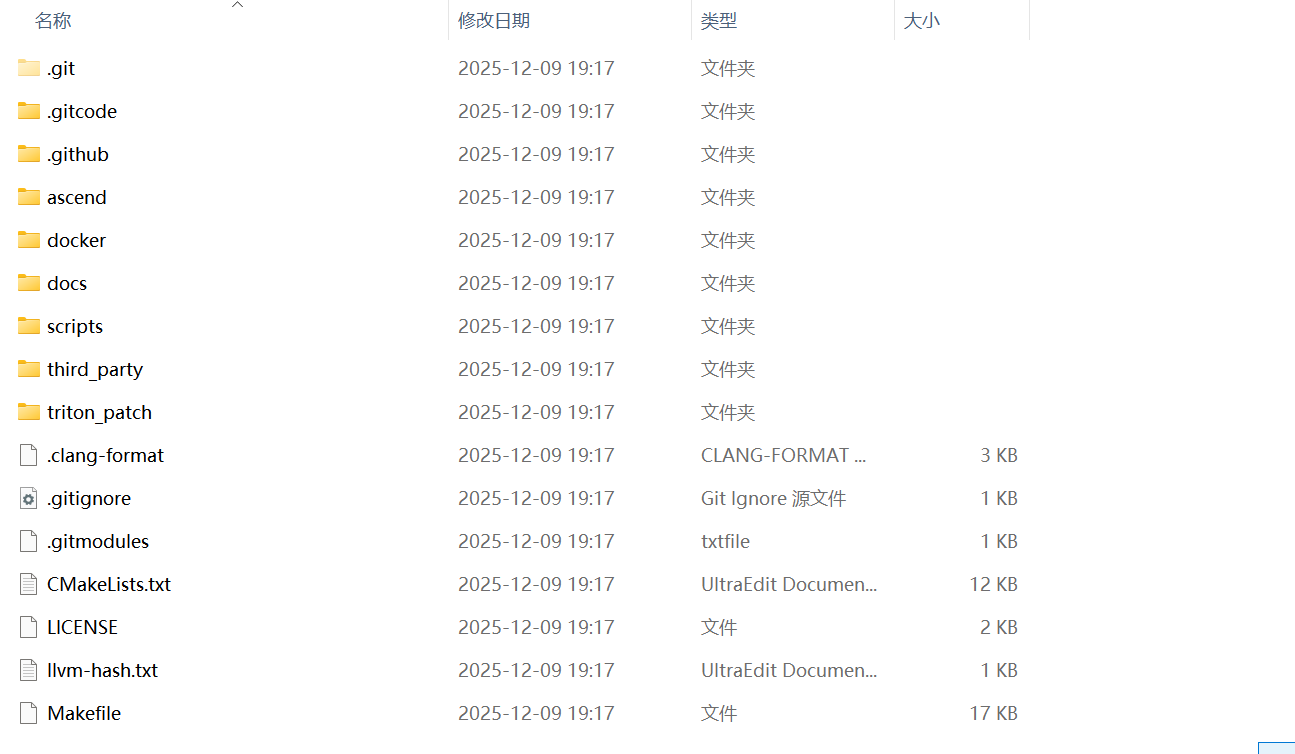
- 功能文件夹:
-
.gitcode/.github:代码仓库的版本管理、CI/CD 配置文件夹;- ascend:昇腾平台适配的核心代码目录(如算子、驱动相关逻辑);
- docker:容器化部署的配置文件目录;
- docs:项目文档(如使用说明、开发指南);
- scripts:自动化脚本(如编译、测试脚本);
- third_party:第三方依赖库;
- triton_patch:针对 Triton(高性能计算框架)的补丁文件目录。
- 配置 / 说明文件:
-
- .clang-format/CMakeLists.txt/Makefile:代码格式化、编译构建配置文件;
.gitignore/.gitmodules:Git 版本管理的忽略规则、子模块配置;LICENSE/OPEN_Source_Software_Notice:开源协议、开源软件声明;README.md/SECURITYNOTE.md:项目说明、安全注意事项;requirements.txt/setup.py:Python 依赖、项目安装配置文件。
这个目录结构是典型的开源项目工程化组织方式,既包含了昇腾平台的业务适配代码,也覆盖了编译、部署、文档等工程化支撑文件。
经验之谈:
建议大家在环境搭建好之后,不要急着写复杂的算子,先跑通 01-vector-add.py。这个例子虽然简单,但它涵盖了 Triton 开发的完整流程:内核定义 -> 自动调优 -> JIT 编译 -> 运行验证。
三、 编程范式
Triton 的核心魅力在于其编程范式。在昇腾 NPU 上开发 Triton 算子,我们主要关注的是 Block 级别的并行。
让我们以 01-vector-add.py 为例,来看看一个标准的 Triton Kernel 长什么样。
01-vector-add.py代码:
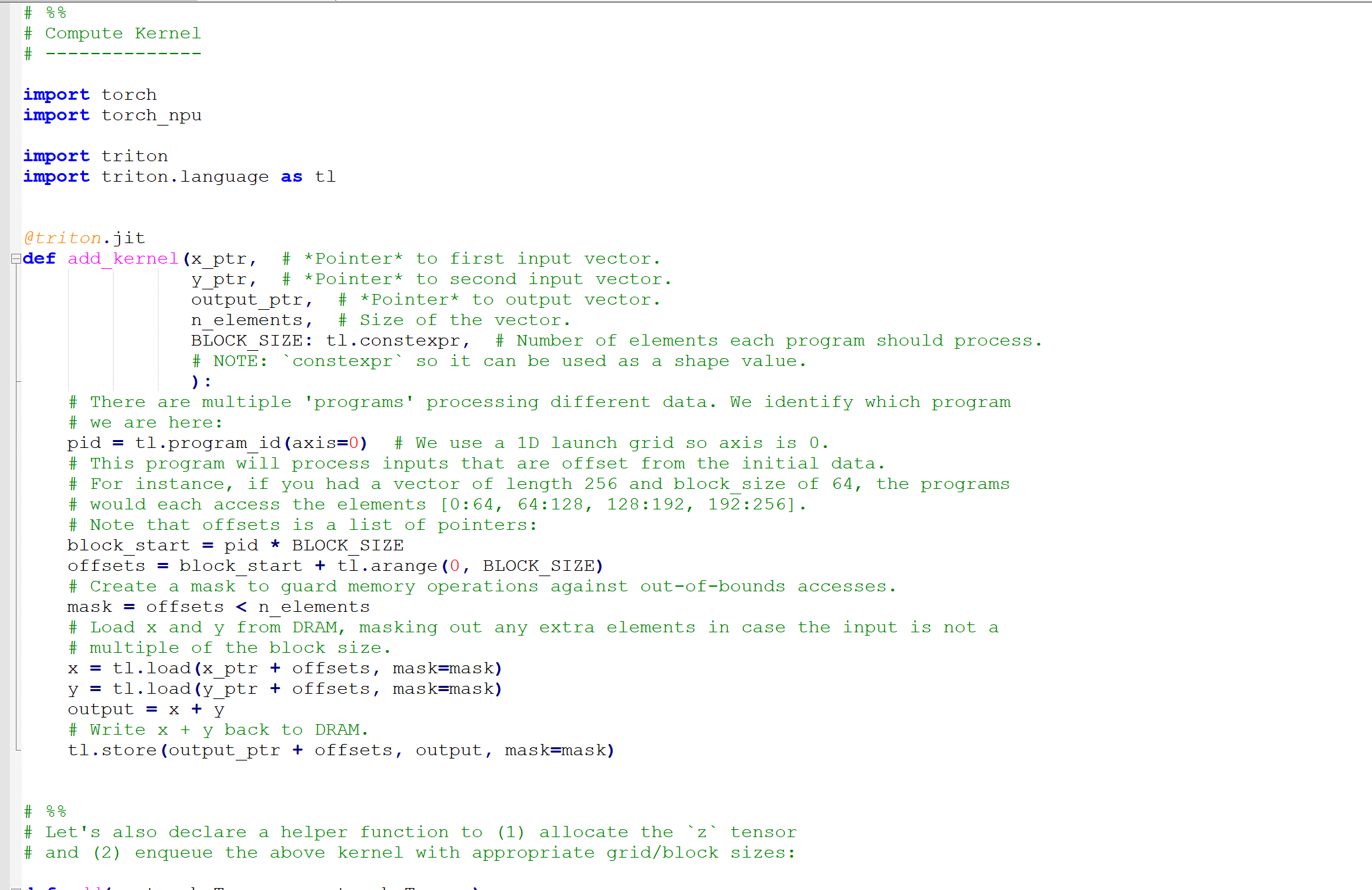
1. 核心组件解析
- 装饰器
@triton.jit:告诉编译器,下面这个函数需要在 NPU 上运行。 - 装饰器
@triton.autotune:这是性能调优的神器(后面详细讲)。它允许我们定义多个配置(Config),运行时会自动寻找最优解。 tl.program_id(axis=0):这是并行计算的基石。Ascend NPU 拥有大量的 AI Core,每个 Core 处理一部分数据。pid就是当前 Core 处理的数据块的 ID。- Masking(掩码):这是新手最容易忽略的地方。由于 NPU 的计算通常是按 Block 进行的(比如 128、256),当数据总量
n_elements不是 Block Size 的整数倍时,如果不加mask,就会导致内存越界访问,程序直接 Crash。
2. 内存加载与计算
在 Triton 中,我们不需要像 Ascend C 那样显式地管理 Global Memory 到 Local Memory (UB) 的搬运(DataCopy)。我们只需要写 tl.load,编译器会自动分析数据的生命周期,生成最优的 DMA 搬运指令。
# 加载数据
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
# 计算
output = x + y
# 回写数据
tl.store(output_ptr + offsets, output, mask=mask)这种“看似单线程,实则多线程”的写法,极大地降低了心智负担。
四、 编译与运行:从 Python 到 AI Core
当我们运行 Python 脚本时,Triton 的 JIT(Just-In-Time)编译器开始工作。在昇腾后端,这个过程大致如下:
- Python AST 解析:读取 kernel 代码。
- TTIR 生成:生成 Triton 自己的中间表示。
- Optimizer:进行一系列机器无关的优化(如死代码消除、常量折叠)。
- Backend CodeGen:昇腾后端接手,将 TTIR 转换为 AscendNPU IR,并调用 CANN 的编译器栈(BiSheng Compiler/TBE)生成最终的
.o或.json算子文件。 - Runtime Launch:通过 ACL (Ascend Computing Language) 接口将算子分发到 Device 端执行。
五、 性能调优经验谈:压榨 NPU 的每一滴性能
这部分是我最想和大家分享的。写出能跑的算子不难,写出高性能的算子才是挑战。在昇腾 NPU 上,性能瓶颈通常出现在两个地方:计算密度和内存带宽。
1. Autotune(自动调优)是第一生产力
不要试图手动硬编码 Block Size。不同的 NPU 型号,其 AI Core 的数量、L1/L0 Buffer 的大小都不同。
使用 @triton.autotune,我们可以定义一个搜索空间:
@triton.autotune(
configs=[
triton.Config({'BLOCK_SIZE': 128}),
triton.Config({'BLOCK_SIZE': 256}),
# ... 更多配置
],
key=['n_elements'],
)经验:
- BLOCK_SIZE:通常选择 128 的倍数(128, 256, 512...),这与昇腾 AI Core 的向量计算单元长度(256 Bytes = 128 * FP16)相契合。
2. 访存优化:连续访问与对齐
昇腾 NPU 的 DMA 搬运单元对连续内存访问(Coalesced Access)非常敏感。如果你的 offsets 是连续的(如 tl.arange(0, BLOCK_SIZE)),DMA 效率最高。如果是跨步访问(Strided),带宽利用率会急剧下降。
案例:
在实现矩阵转置或某些特殊卷积时,尽量使用 tl.view 或 tl.reshape 来保持逻辑上的连续性,或者利用 Local Memory 进行数据重排,而不是直接在 Global Memory 上进行跳跃读取。
3. 流水线并行(Pipeline Parallelism)
Triton 在编译阶段会自动分析数据依赖,尝试生成 Double Buffering(双缓冲)或 Triple Buffering 的指令序列。这意味着,当 AI Core 在计算当前 Block 时,DMA 单元已经在预取下一个 Block 的数据了。
经验:为了让流水线跑起来,你的计算逻辑和加载逻辑最好不要有强依赖。保持 Loop 的结构清晰,有助于编译器识别并进行流水线优化。
六、 总结与展望
通过这段时间对 Triton-Ascend 的深入使用,我深刻体会到了它在开发效率与运行性能之间取得的绝佳平衡。
- 对于算法工程师:Triton 让你无需学习复杂的 Ascend C 语法,就能将自定义算子部署到 NPU 上,极大加速了模型迭代。
- 对于性能优化工程师:Triton 提供了足够的“旋钮”(如 Block Size, Warps, Swizzle),让我们依然拥有手动调优的空间。
当然,目前的 Triton-Ascend 还在快速发展中,部分高级特性(如某些特定的 Tensor Core 指令)可能支持得还不够完美。但我相信,随着社区的努力和官方的持续投入,Triton 必将成为昇腾生态中不可或缺的一环。
如果你还没有尝试过在昇腾 NPU 上写 Triton,强烈建议你去 Clone 一下官方仓库,跑一跑那个 vector-add 的例子。相信我,打开新世界大门的感觉,真的很棒!
昇腾PAE案例库对本文写作亦有帮助

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)