自定义迭代器的实现:深入 Rust 的抽象机制
自定义迭代器的实现:深入 Rust 的抽象机制
实现自定义迭代器是掌握 Rust 核心抽象能力的重要里程碑。通过为自定义类型实现 Iterator trait,我们不仅能够复用标准库的丰富适配器生态,更能深入理解 Rust 类型系统和生命周期管理的精妙设计。这个过程涉及对所有权、借用、状态管理等核心概念的综合运用,是从使用者向设计者转变的关键一步。
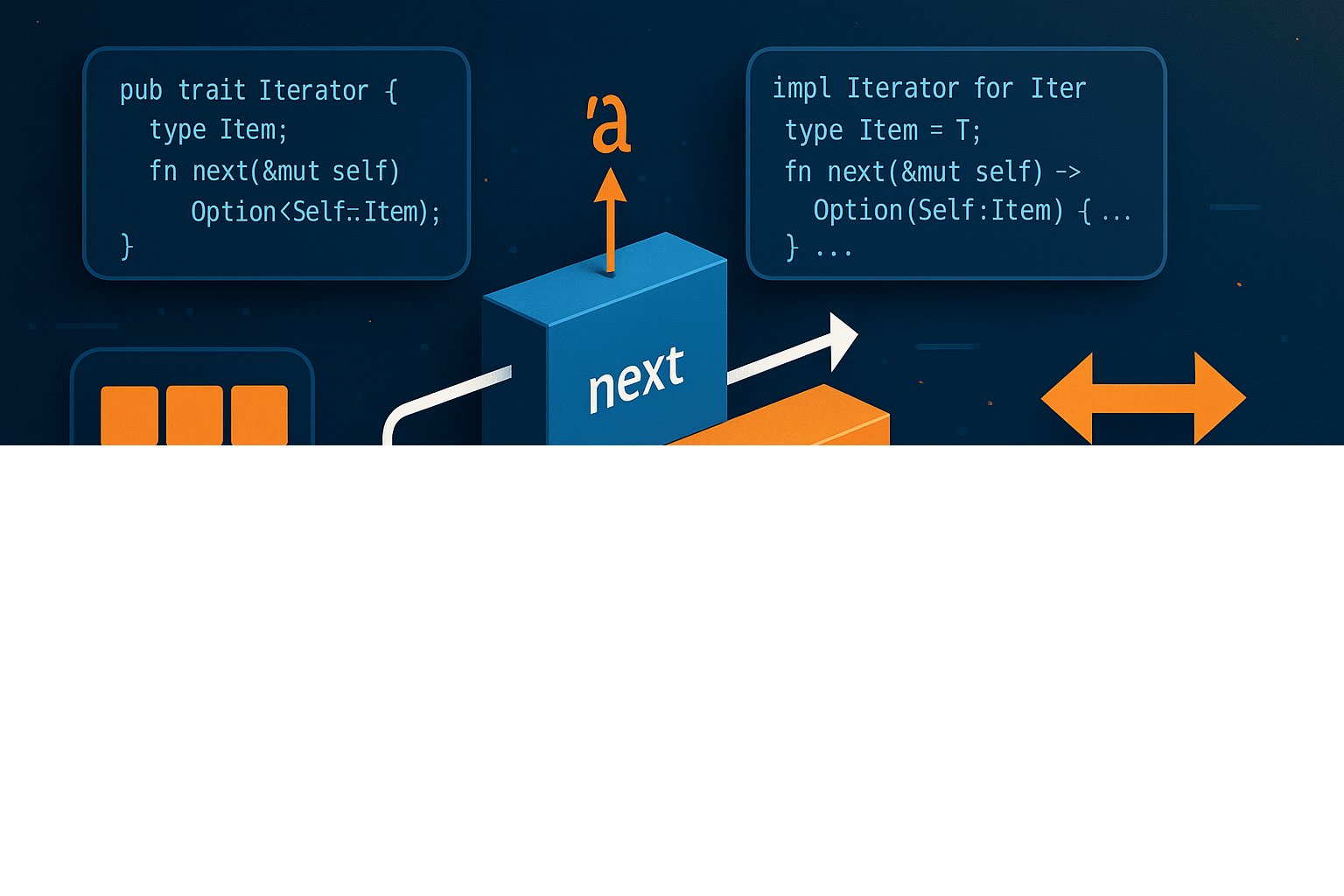
Iterator trait 的核心契约
实现 Iterator trait 的核心在于定义关联类型 Item 和实现 next() 方法。这看似简单的接口背后,蕴含着 Rust 对迭代抽象的深刻思考。Item 关联类型决定了迭代器产出元素的类型,而 next() 返回 Option<Self::Item> 则优雅地表达了"有界迭代"的语义——Some 表示还有元素,None 表示迭代结束。
这种设计与 C++ 的迭代器范式有本质区别。C++ 使用开始和结束迭代器对来表示范围,需要比较操作符判断终止条件;而 Rust 将状态封装在迭代器内部,通过 Option 的类型安全特性自然表达终止。这不仅简化了接口,更重要的是消除了迭代器失效等常见的 C++ 陷阱。
状态管理的艺术:以窗口迭代器为例
让我们通过实现一个滑动窗口迭代器来展示状态管理的复杂性。这个迭代器接受一个切片和窗口大小,按滑动窗口方式产出子切片:
struct SlidingWindows<'a, T> {
data: &'a [T],
window_size: usize,
position: usize,
}
impl<'a, T> SlidingWindows<'a, T> {
fn new(data: &'a [T], window_size: usize) -> Self {
Self {
data,
window_size,
position: 0,
}
}
}
impl<'a, T> Iterator for SlidingWindows<'a, T> {
type Item = &'a [T];
fn next(&mut self) -> Option<Self::Item> {
if self.position + self.window_size <= self.data.len() {
let window = &self.data[self.position..self.position + self.window_size];
self.position += 1;
Some(window)
} else {
None
}
}
}
这个实现展示了几个关键设计决策。首先是生命周期参数 'a 的使用,它确保迭代器产出的切片引用不会超过原始数据的生命周期。其次是可变借用 &mut self 的使用,这允许 next() 修改内部状态(position),同时通过借用检查器保证了在迭代过程中原始数据不会被修改。最后是边界检查逻辑,确保不会产出越界的切片。
所有权模式的选择:值迭代器 vs 引用迭代器
设计自定义迭代器时,最关键的决策之一是选择所有权模式。是产出拥有所有权的值(T),还是产出引用(&T 或 &mut T)?这个选择深刻影响了迭代器的使用场景和性能特征。
产出值的迭代器(consuming iterator)会消耗原始数据结构,适合一次性的转换场景,例如将 Vec<T> 转换为 Vec<U>。这种方式避免了不必要的复制,但意味着原始数据在迭代后不可用。相比之下,产出引用的迭代器(borrowing iterator)允许多次迭代同一数据,但需要仔细管理生命周期,避免悬垂引用。
在实践中,通常为同一数据结构提供多个迭代器实现:into_iter() 消耗所有权产出 T,iter() 借用产出 &T,iter_mut() 可变借用产出 &mut T。这种模式在标准库中随处可见,体现了 Rust 对灵活性和安全性的平衡追求。
高级技巧:双端迭代器与精确大小
除了基本的 Iterator trait,Rust 还提供了 DoubleEndedIterator 和 ExactSizeIterator 等扩展 trait,允许实现更高级的迭代功能。DoubleEndedIterator 要求实现 next_back() 方法,支持从后向前迭代,这对于反向遍历和高效的 rev() 操作至关重要。ExactSizeIterator 则提供了 len() 方法,返回剩余元素的精确数量。
实现这些扩展 trait 不仅仅是功能上的增强,更重要的是为编译器优化提供了更多信息。例如,已知长度的迭代器可以预分配精确大小的内存,避免 Vec::push 的多次重分配;双端迭代器可以支持更多的适配器组合,如 rfold()。
实现双端迭代器需要特别注意状态一致性。前向和后向的位置指针必须正确维护,避免重叠或遗漏元素。这通常需要更复杂的状态管理逻辑,例如维护开始和结束位置,在每次 next() 或 next_back() 调用时同步更新。
性能优化与内存布局
自定义迭代器的性能不仅取决于算法逻辑,还受到内存布局和编译器优化的显著影响。迭代器结构体应该尽可能紧凑,避免不必要的填充字节。对于包含引用的迭代器,使用 #[repr(C)] 或 #[repr(packed)] 属性可以控制内存布局,在某些情况下提升缓存友好性。
另一个关键优化点是避免在 next() 方法中进行昂贵的计算。由于 next() 会被频繁调用,任何额外的开销都会被放大。应当将一次性的初始化逻辑放在构造函数中,只在 next() 中进行必要的状态更新和元素产出。对于涉及复杂计算的迭代器,考虑使用惰性求值模式,将计算推迟到真正需要时。
工程实践中的权衡
在实际项目中实现自定义迭代器时,需要在抽象程度和实现复杂度之间权衡。不是所有场景都适合抽象为迭代器——对于简单的一次性遍历,直接使用闭包或方法可能更直观。迭代器的真正价值在于可组合性和可复用性,当需要与标准库适配器链配合,或者作为公共 API 暴露时,实现 Iterator trait 才能发挥最大效益。
同时要注意文档和测试的重要性。自定义迭代器的行为应当清晰文档化,特别是边界情况、空序列处理、以及是否实现了扩展 trait。完善的单元测试应覆盖正常流程、边界条件、以及与标准适配器的组合使用,确保实现的正确性和健壮性。
实现自定义迭代器是理解 Rust 抽象机制的最佳实践。它要求我们深入思考类型系统、所有权模型、生命周期管理等核心概念,将理论知识转化为可工作的代码。通过这个过程,我们不仅获得了强大的抽象工具,更培养了系统性的工程思维,这正是 Rust 编程的精髓所在。🦀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)