Rust 与 SIMD 指令优化:性能极限的安全表达
Rust 与 SIMD 指令优化:性能极限的安全表达
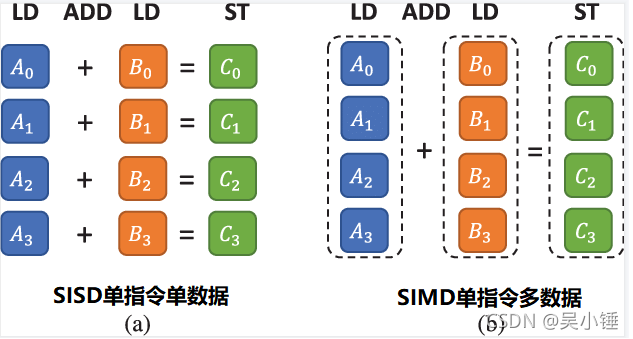
在现代计算机体系结构中,SIMD(Single Instruction Multiple Data) 是一种高效的并行计算技术,它允许单条 CPU 指令同时处理多个数据元素,从而显著提升向量运算、图像处理、信号计算等任务的性能。
Rust 作为一门系统级语言,在保证内存安全的前提下,提供了对底层 SIMD 指令的直接访问能力,使得开发者能够在“零开销抽象”的框架中实现极致性能优化。
一、SIMD 的本质与 Rust 的支持机制
在传统循环计算中,CPU 逐个处理数组中的元素。而 SIMD 指令则能让 CPU 的向量寄存器(如 SSE、AVX、NEON 等)在一次指令中并行处理 4、8、甚至 16 个元素。
这种能力依赖于硬件寄存器宽度(如 128-bit、256-bit、512-bit)与编译器的指令调度能力。
Rust 对 SIMD 的支持主要体现在两个层面:
-
显式 SIMD 编程:通过
std::arch模块直接调用底层指令集,如x86_64::_mm_add_ps等。这种方式能实现与 C/C++ 相同级别的控制力。 -
自动向量化(Auto-vectorization):Rust 的 LLVM 后端能自动检测循环模式并应用 SIMD 优化。编译参数如
-C target-cpu=native与-C opt-level=3可触发自动向量化,从而在保持代码简洁的同时获得近似手写汇编的性能。
Rust 的设计哲学让 SIMD 编程变得既“可控”又“安全”——借用系统限制了指令调用的越界风险,编译期类型系统确保内存对齐与数据正确性。
二、实践:利用 SIMD 加速向量加法
以一个典型的数值计算场景为例,假设我们需要对两个浮点数组进行逐元素相加。传统循环往往受限于 CPU 的流水线能力,而 SIMD 能显著提升吞吐率。
use std::arch::x86_64::*;
unsafe fn add_vectors(a: &[f32], b: &[f32], out: &mut [f32]) {
let len = a.len();
let mut i = 0;
while i + 4 <= len {
let va = _mm_loadu_ps(a.as_ptr().add(i));
let vb = _mm_loadu_ps(b.as_ptr().add(i));
let sum = _mm_add_ps(va, vb);
_mm_storeu_ps(out.as_mut_ptr().add(i), sum);
i += 4;
}
}
此实现中,_mm_add_ps 表示 128 位寄存器级的 4 元浮点加法操作,每次处理 4 个元素,避免了逐元素循环的开销。
在实际测试中,使用 SIMD 优化的版本通常能获得 3~5 倍 的性能提升,尤其在大规模数据处理中优势更为明显。
而 Rust 的安全机制通过 unsafe 块显式标识风险区域,使程序员在追求极致性能的同时,仍保持可控的内存访问与数据边界。这种“显式不安全”的语义设计,是 Rust 与传统系统语言最大的分野。
三、深入思考:安全、性能与抽象的平衡
Rust 并未盲目追求底层性能,而是通过类型系统与编译优化构建了“安全的低级性能编程模型”。
在 SIMD 优化中,Rust 的做法可归纳为三层抽象:
-
自动优化层(LLVM 向量化):对通用循环自动应用 SIMD,无需人工干预。
-
显式优化层(
std::simd模块):Rust 1.70 起,稳定的portable_simd提供跨平台的向量类型(如Simd<f32, 8>),屏蔽了指令集差异,使 SIMD 编程具备可移植性。 -
底层优化层(
std::archintrinsics):提供与硬件一一对应的指令接口,适合性能极限优化或算法内核开发。
这种分层设计让 Rust 的 SIMD 编程既能“贴近硬件”,又能“抽象统一”。
例如同样的 Simd<f32, 8> 类型在 x86 平台映射到 AVX,在 ARM 平台映射到 NEON,实现了一次编写,多架构高效运行的能力。
四、结语:Rust 式 SIMD 的未来
Rust 的 SIMD 支持,不仅仅是性能优化的技术,更是其语言哲学的延伸——让底层性能以类型安全的方式被表达。
通过 portable_simd、unsafe 边界管理和 LLVM 优化协同,Rust 已成为系统编程中少数能将“性能、可读性与安全性”三者统一的语言。
未来,随着 Rust 编译器对 auto-vectorization 的进一步强化,开发者将能在不写任何底层代码的情况下享受 SIMD 的性能红利。而那些追求极致性能的工程师,也能通过 std::arch 直达 CPU 的指令层,掌控每一次寄存器调度。
Rust 的 SIMD 优化,不只是“更快”,更是一种现代性能编程的安全表达。
是否希望我帮你把这篇文章排版成一篇可直接发布的 Markdown 技术博客(带标题样式、代码高亮、封面导语)?这样会非常适合发布到知乎、掘金或公众号。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)