Rust 中的数据并行处理:Rayon 库的设计原理与实践
Rust 中的数据并行处理:Rayon 库的设计原理与实践
在多核时代,充分利用 CPU 的并行计算能力成为性能优化的关键。然而,并行编程往往伴随着线程同步、数据竞争和复杂的错误处理。Rayon 库通过一种优雅而安全的方式解决了这一难题,它将并行计算的复杂性隐藏在迭代器接口之后,让开发者能够以极少的代码改动将顺序算法转化为并行算法。Rayon 的核心贡献在于证明:在 Rust 的所有权和类型系统的约束下,我们不仅能实现安全的并行计算,而且能保持代码的简洁性和表现力。
Rayon 的架构基石:工作窃取调度
Rayon 的性能优势来自于其采用的工作窃取(Work Stealing)调度策略。与传统的线程池固定分配任务不同,工作窃取允许空闲的线程主动从其他忙碌的线程中"窃取"工作,从而实现负载均衡。这种策略特别适合不可预测的工作负载分布场景。当某个线程处理的数据块耗时特别长时,其他线程不会因为等待而浪费 CPU 周期,而是能够继续处理其他任务。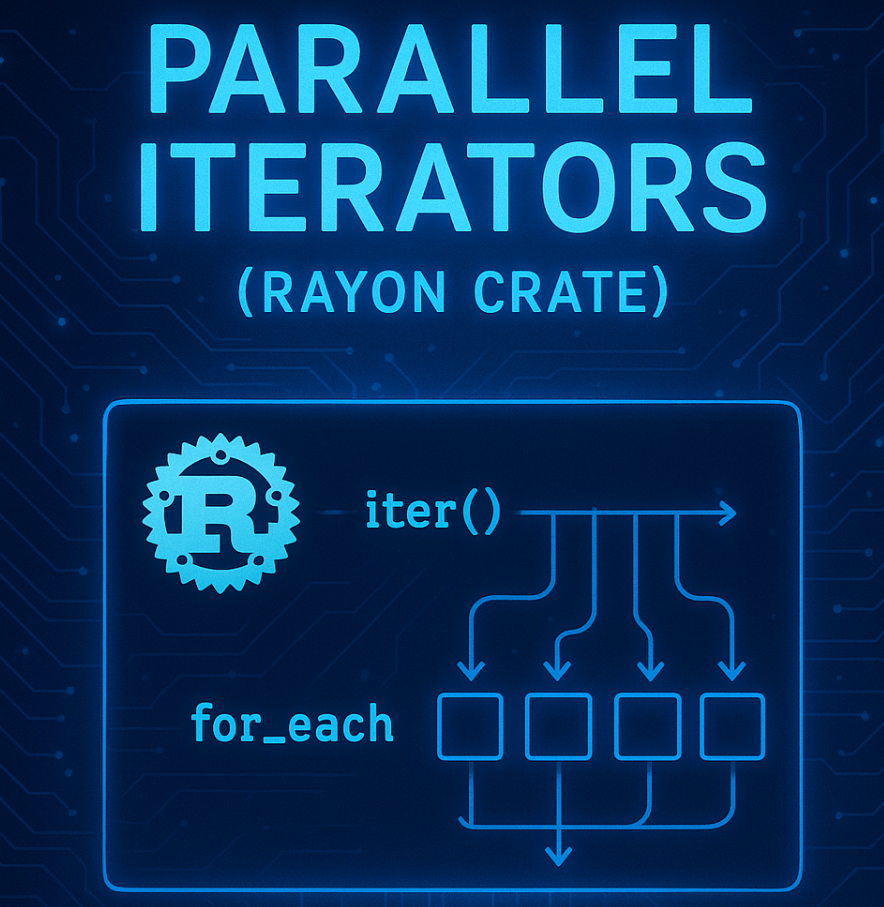
从 Rust 的角度看,工作窃取的实现需要解决一个关键挑战:如何在保证线程安全的前提下,让多个线程访问共享的任务队列。Rayon 通过使用无锁数据结构(Lock-Free Data Structures)来应对这一挑战。具体来说,每个工作线程维护一个本地的双端队列(Deque),任务可以从队列的一端添加,也可以从同一端移除。当线程空闲时,它会尝试从其他线程的队列末端窃取任务。这种设计最大化了缓存局部性,因为线程优先处理自己的本地任务,只有在必要时才访问其他线程的数据。
Rayon 迭代器的设计模式
Rayon 的魅力在于其迭代器 API 的设计。它提供了 ParallelIterator trait,对标 Rust 标准库的 Iterator trait,但在语义上做了关键的扩展:并行化。这种设计允许开发者通过链式调用 .par_iter()、.map()、.filter() 等方法来组织并行计算流程。
从编程语言的角度看,这是一个优雅的解决方案。它利用 Rust 的 trait 系统提供了一致的接口,使得顺序和并行代码在使用方式上保持高度的相似性。然而,内部实现却完全不同。当我们链接多个 ParallelIterator 操作时,Rayon 会构建一个计算任务树,每个节点代表一个变换操作。这个任务树在执行时被递归地分解为更小的子任务,直到任务粒度足够小,可以由单个工作线程顺序执行。
use rayon::prelude::*;
fn compute_intensive_demo() {
let data: Vec<i32> = (0..1000000).collect();
// 顺序版本
let sum_sequential: i32 = data.iter()
.filter(|x| x % 2 == 0)
.map(|x| x * x)
.sum();
// 并行版本:仅需改变迭代器来源
let sum_parallel: i32 = data.par_iter()
.filter(|x| x % 2 == 0)
.map(|x| x * x)
.sum();
println!("Sequential: {}, Parallel: {}", sum_sequential, sum_parallel);
}
// 高级应用:自定义分治算法
fn parallel_quicksort<T: Ord + Send>(mut arr: Vec<T>) -> Vec<T> {
if arr.len() <= 1 {
return arr;
}
let pivot_index = partition(&mut arr);
// 关键:使用 rayon::join 并行执行左右两部分排序
let (left, right) = arr.split_at_mut(pivot_index);
let (left_sorted, right_sorted) = rayon::join(
|| parallel_quicksort(left.to_vec()),
|| parallel_quicksort(right.to_vec()),
);
[left_sorted, vec![arr[pivot_index]], right_sorted].concat()
}
fn partition<T: Ord>(arr: &mut [T]) -> usize {
// 实现 partition 逻辑
arr.len() / 2
}
所有权系统与并行安全性的统一
Rayon 最深刻的贡献可能在于它展示了 Rust 的所有权和借用检查机制如何天然地支持安全的并行编程。在 Rayon 中,并行闭包必须满足 Send + Sync traits 的约束,这保证了它们可以跨线程边界安全传输。更重要的是,Rayon 的 API 设计使得数据竞争在编译时就被排除了。
考虑 reduce 操作的实现。当我们使用 reduce 将多个线程的结果合并时,Rayon 要求提供一个纯函数来组合两个值。这个设计选择排除了基于锁的同步,因为每个线程可以独立地计算局部结果,只在最后的合并阶段组织全局结果。这不仅提高了性能,还从根本上避免了死锁的可能性。
// reduce 的安全性体现
fn parallel_aggregation() {
let numbers: Vec<i32> = (1..=1000000).collect();
// 并行求和
let sum = numbers.par_iter()
.sum::<i64>();
// 并行求最大最小值
let (max, min) = numbers.par_iter()
.copied()
.reduce(
|| (i32::MIN, i32::MAX),
|(max_a, min_a), (max_b, min_b)| {
(max_a.max(max_b), min_a.min(min_b))
},
);
println!("Sum: {}, Max: {}, Min: {}", sum, max, min);
}
// 处理不均匀工作负载的场景
fn process_with_custom_granularity() {
let data: Vec<String> = vec![
String::from("a"), String::from("very_long_string_that_takes_time"),
String::from("b"),
];
let processed: Vec<_> = data.par_iter()
// with_max_len 控制任务粒度,对不均匀工作负载优化
.with_max_len(1)
.map(|s| {
simulate_heavy_work(s);
s.to_uppercase()
})
.collect();
}
fn simulate_heavy_work(s: &str) {
std::thread::sleep(std::time::Duration::from_millis(s.len() as u64));
}
性能考量与最佳实践
虽然 Rayon 提供了便捷的并行 API,但并不是所有计算都适合并行化。并行化本身有开销:工作分解、数据分发、结果合并等操作都消耗 CPU 周期。一般来说,只有当单个操作的计算复杂度足够高时,并行化的收益才能超过这些开销。
在实践中,开发者应该基于基准测试(benchmarking)来决定是否并行化。Rayon 的 scope API 和 join 函数提供了更精细的控制,允许在特定的热点代码路径上应用并行化,而不是盲目地并行化所有操作。
总结
Rayon 库代表了 Rust 并行编程哲学的一次成功实践。它利用 Rust 的类型系统和所有权模型,在编译时消除数据竞争,同时通过工作窃取调度和高效的任务分解实现了接近最优的性能。对于需要充分利用多核处理器的应用,Rayon 无疑是首选方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)