Rust Serde在零拷贝反序列化中的应用:从生命周期机制到性能极限的工程实践
Rust Serde在零拷贝反序列化中的应用:从生命周期机制到性能极限的工程实践
引言
在高性能数据处理场景中,序列化和反序列化往往成为系统瓶颈。传统的反序列化过程需要将输入数据完全复制到新分配的内存中,这在处理大型JSON文档、网络协议报文或日志文件时会产生巨大的内存和CPU开销。Rust的serde库通过精妙的生命周期机制,实现了零拷贝反序列化——直接借用输入缓冲区中的数据,避免不必要的内存分配和拷贝。这不仅是性能优化技巧,更是Rust所有权系统和借用检查器在实际工程中的深度应用。本文将深入剖析零拷贝反序列化的工作原理,从生命周期标注到内存布局,从性能收益到使用约束,展现Rust在极致性能优化中的独特价值。
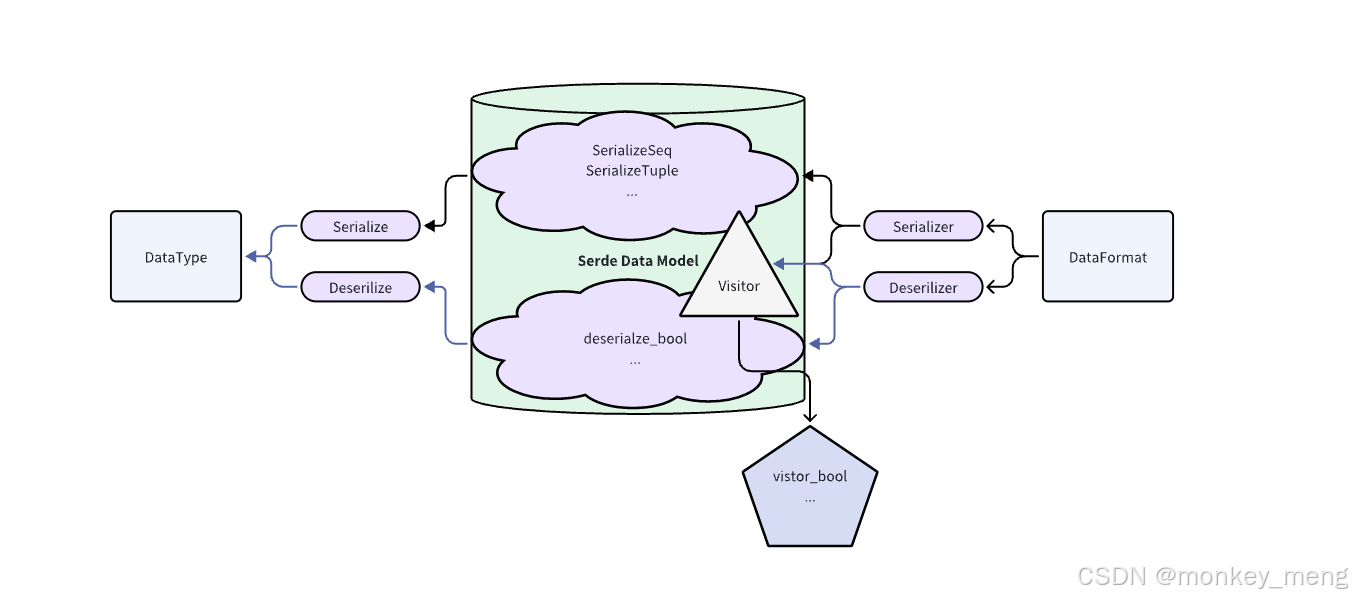
生命周期参数'de:零拷贝的类型系统基础
Serde的Deserialize trait带有一个生命周期参数'de,这个看似简单的设计是零拷贝反序列化的核心。trait Deserialize<'de>中的'de代表"deserialization lifetime",表示反序列化结果可以借用输入数据的生命周期。当我们实现Deserialize<'de>而非Deserialize<'static>时,就告诉编译器:这个类型的实例可能包含指向输入缓冲区的引用。
这种设计的精妙之处在于将内存管理策略提升到类型系统层面。编译器通过生命周期标注可以静态验证:反序列化的结果在输入缓冲区有效期内使用,避免了悬垂引用。相比其他语言依赖运行时垃圾回收或手动内存管理,Rust在编译期就确保了零拷贝的安全性,没有任何运行时开销。
更深层的洞察是,'de生命周期将数据的所有权语义和借用语义统一到了反序列化接口中。对于可以零拷贝的类型(如字符串切片&str),反序列化返回借用;对于必须拥有所有权的类型(如Vec<T>),反序列化执行拷贝。这种统一接口使得同一个数据结构可以根据字段类型自动选择最优策略,无需开发者显式区分。
字符串处理:零拷贝的典型场景
字符串是零拷贝反序列化最明显受益的场景。在JSON解析中,字符串字段占据了大部分内存。传统做法是为每个字符串分配新内存并拷贝字符,而零拷贝方案直接返回指向输入JSON文档的字符串切片。对于包含数百个字符串字段的对象,性能提升可达数倍。
use serde::Deserialize;
// 零拷贝版本:字段借用输入数据
#[derive(Deserialize)]
struct Config<'a> {
#[serde(borrow)]
name: &'a str,
#[serde(borrow)]
description: &'a str,
version: u32,
}
// 拥有所有权版本:字段拷贝数据
#[derive(Deserialize)]
struct OwnedConfig {
name: String,
description: String,
version: u32,
}
#[serde(borrow)]属性是关键标记,它指示serde派生宏生成借用输入数据的代码,而非默认的拷贝行为。没有这个属性,即使字段类型是&str,serde也会尝试先拷贝为String再转换,失去了零拷贝的意义。这个属性本质上是程序员对编译器的承诺:我保证输入数据的生命周期足够长。
零拷贝字符串的约束在于输入格式的限制。对于JSON而言,只有不包含转义字符的字符串可以零拷贝,因为转义字符需要解析和转换,必须生成新字符串。Serde会在运行时判断:如果字符串包含转义,自动回退到拷贝模式;如果是纯净字符串,使用零拷贝。这种自动降级策略在保证正确性的同时最大化性能。
字节数组的零拷贝:二进制数据的高效处理
除了字符串,字节数组是另一个零拷贝的重要场景。在处理网络协议、文件格式或加密数据时,往往需要传递大块的二进制数据。如果反序列化时将所有字节拷贝到Vec<u8>,会产生巨大的内存和时间开销。零拷贝方案使用&[u8]直接引用输入缓冲区。
关键的技术考量是内存对齐和数据生命周期的匹配。字节切片&[u8]天然支持任意对齐,因为它只是一个指针和长度的组合。但在某些二进制格式(如MessagePack或Bincode)中,数据可能不是连续存储的,需要先收集到临时缓冲区再返回切片。这时零拷贝的收益取决于数据的物理布局,需要format库的精心设计配合。
Serde的serde_bytes模块专门优化了字节数组的处理。通过#[serde(with = "serde_bytes")]属性,可以指示序列化器和反序列化器将Vec<u8>视为不透明的字节块,而非元素序列。这避免了逐元素的编码和解码,在某些格式下可以直接memcpy整块数据,进一步提升性能。
Cow类型:零拷贝与所有权的优雅折衷
Cow<'a, T>(Clone on Write)是Rust标准库提供的智能指针,在零拷贝反序列化中扮演着桥梁角色。它可以持有借用的数据或拥有所有权的数据,在需要修改时自动克隆。这种设计在处理可能包含转义字符的字符串时特别有用:如果字符串无需转义,使用Cow::Borrowed零拷贝;如果需要转义,使用Cow::Owned持有新分配的字符串。
use std::borrow::Cow;
use serde::Deserialize;
#[derive(Deserialize)]
struct FlexibleConfig<'a> {
#[serde(borrow)]
name: Cow<'a, str>, // 可能借用,可能拥有
count: u32,
}
Cow的价值在于将零拷贝的决策推迟到运行时,同时保持类型的统一。调用方无需关心数据是借用还是拥有,可以统一使用as_ref()获取引用或into_owned()转换为所有权。这种延迟决策在API设计中极为重要:当无法在编译期确定是否能零拷贝时,Cow提供了一个类型安全的回退机制。
更深层的考量是Cow对内存布局的影响。Cow<'a, str>在内存中是一个判别式加上指针和长度(借用情况)或指针、长度和容量(拥有情况),大小略大于纯&str或String。在大量使用Cow的场景下,这种额外开销需要与零拷贝的收益权衡。基准测试显示,当零拷贝比例超过50%时,Cow通常是性能最优选择。
嵌套结构的零拷贝传播
零拷贝反序列化的真正挑战在于嵌套结构。当结构体包含其他结构体,而内层结构体又包含字符串切片时,生命周期参数必须正确传播,否则编译器会报错。Serde的派生宏自动处理大部分情况,但在手动实现Deserialize时,必须深刻理解生命周期的传播规则。
关键原则是:如果一个类型的任何字段借用了'de生命周期,那么该类型本身也必须声明'de生命周期。这种传播是传递性的:从最内层的&str字段,向外层层传播,直到顶层结构体。编译器通过这种传播验证:所有借用都不会超出输入数据的生命周期。
#[derive(Deserialize)]
struct Document<'a> {
#[serde(borrow)]
metadata: Metadata<'a>,
#[serde(borrow)]
content: &'a str,
}
#[derive(Deserialize)]
struct Metadata<'a> {
#[serde(borrow)]
author: &'a str,
#[serde(borrow)]
title: &'a str,
created: u64,
}
这种层次化的生命周期标注在复杂数据模型中可能变得冗长,但这正是Rust的设计哲学:显式优于隐式。每个生命周期标注都是对内存安全的显式承诺,编译器负责验证这些承诺的正确性。相比隐式的垃圾回收或手动的内存管理,这种显式标注在大型系统中提供了更强的可维护性保证。
性能测量与收益量化
零拷贝反序列化的性能收益高度依赖于具体场景。在字符串密集型的数据(如日志文件、配置文件)中,收益可达300%以上;在数值密集型数据中,收益可能不到10%。因此,是否采用零拷贝应该基于实际测量,而非主观判断。
基准测试应该关注三个维度:反序列化速度、内存分配次数和峰值内存使用。使用criterion库可以精确测量反序列化时间,使用系统分析器(如valgrind或heaptrack)可以追踪内存分配。在某些情况下,零拷贝虽然减少了分配次数,但由于需要保持输入缓冲区存活,峰值内存使用反而更高。这种权衡需要根据系统的内存压力和分配器性能综合判断。
另一个需要量化的因素是代码复杂度。零拷贝版本的类型签名更复杂,生命周期标注增加了认知负担。在性能不敏感的代码路径上,简单的拥有所有权版本可能是更好的选择。Rust的哲学不是盲目追求性能,而是在性能、安全性和可维护性之间做出明智的权衡。
零拷贝的限制与回退策略
零拷贝反序列化并非银弹,它有严格的适用条件。首先,输入数据必须在反序列化结果的整个使用期间保持有效。这意味着如果需要将反序列化结果存储到长生命周期的结构中(如全局缓存),输入缓冲区也必须保持活跃,可能导致内存无法及时释放。
其次,并非所有格式都支持零拷贝。JSON中的转义字符、Unicode规范化、数字解析都需要生成新数据。MessagePack虽然是二进制格式,但其变长编码意味着字符串可能不是内存连续的。只有像Bincode这样设计时就考虑零拷贝的格式,才能全面支持。
实践中的回退策略是混合使用零拷贝和拷贝字段。对于确定不会修改且生命周期合适的字段使用&str,对于可能需要修改或生命周期不明确的字段使用String。这种混合策略需要在类型定义时仔细分析每个字段的使用模式,但可以在性能和灵活性之间取得最佳平衡。
总结与架构启示
Serde的零拷贝反序列化展示了Rust类型系统在性能优化中的强大能力。通过生命周期参数'de,借用检查器可以静态验证零拷贝的安全性;通过#[serde(borrow)]属性,程序员可以显式控制拷贝策略;通过Cow类型,系统可以在运行时自适应选择最优路径。这些机制不是孤立的技巧,而是Rust所有权模型在数据序列化领域的自然延伸。
零拷贝反序列化的核心启示是:性能优化不应以牺牲安全性为代价。Rust通过将内存管理规则编码到类型系统,使得零拷贝这种传统上需要unsafe代码的优化,可以在完全安全的代码中实现。这种"安全的性能"理念是Rust区别于C/C++和高级语言的关键特征,也是其在系统编程领域持续增长的根本原因。掌握零拷贝反序列化,不仅是学习一个具体技术,更是理解如何在Rust中将类型系统转化为性能优势的范例。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)