Rust专项——死锁规避与无锁方案:原子操作与 Lock-Free 基础
·
在并发编程中,死锁是常见隐患;而**无锁(Lock-Free)**数据结构能避免互斥开销,适合高频热路径。本节梳理死锁成因、规避原则,以及原子操作与无锁设计的基础模式。
1. 死锁成因与经典案例
- 线程 A 持有锁1,等待锁2;线程 B 持有锁2,等待锁1 → 循环等待,永远阻塞。
- Rust 中常见于:
Mutex/RwLock嵌套、多锁获取顺序不一致、递归锁滥用。
use std::sync::{Arc, Mutex};
let m1 = Arc::new(Mutex::new(0));
let m2 = Arc::new(Mutex::new(0));
let mm1 = Arc::clone(&m1);
let mm2 = Arc::clone(&m2);
thread::spawn(move || {
let _a = mm1.lock().unwrap();
thread::sleep(Duration::from_millis(10));
let _b = mm2.lock().unwrap(); // 等待 m2
});
let _b = m2.lock().unwrap();
thread::sleep(Duration::from_millis(10));
let _a = m1.lock().unwrap(); // 等待 m1 -> 死锁
2. 死锁规避策略
2.1 锁排序(Lock Ordering)
- 约定:所有线程按相同顺序获取多把锁(如总是先 m1 再 m2)。
fn safe_op(m1: &Mutex<i32>, m2: &Mutex<i32>) {
let _a = m1.lock().unwrap();
let _b = m2.lock().unwrap();
// 始终先 m1 后 m2
}
2.2 超时/非阻塞尝试
- 用
try_lock()或超时锁,失败时回退、重试或降级处理。
if let Ok(guard) = m1.try_lock() {
if let Ok(_) = m2.try_lock() { /* 成功 */ }
} else { /* 回退 */ }
2.3 减少锁粒度
- 缩小临界区,避免在锁内做 I/O/长计算;必要时拆分为多把小锁。
2.4 避免嵌套锁
- 尽量单锁单操作;若必须多锁,统一顺序或重构为单锁。
3. 原子操作:AtomicUsize、AtomicBool 等
- 无需互斥即可做读写-修改-写回(RMW);适合计数、标志位、简单状态机。
use std::sync::atomic::{AtomicUsize, Ordering};
let count = AtomicUsize::new(0);
count.fetch_add(1, Ordering::SeqCst); // 原子加
count.compare_exchange(0, 1, Ordering::SeqCst, Ordering::SeqCst); // CAS
let v = count.load(Ordering::SeqCst);
3.1 内存序(Memory Ordering)简介
SeqCst:最强一致性(默认保守、正确但慢);Relaxed:只保证单变量原子,无跨线程顺序约束(最快);Acquire/Release:对特定同步点提供部分顺序约束(性能与一致性平衡)。
4. 无锁计数器(基础无锁模式)
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
use std::sync::Arc; // 新增:导入Arc
struct Counter(AtomicUsize);
impl Counter {
fn new() -> Self {
Self(AtomicUsize::new(0))
}
// 原子递增操作
fn inc(&self) {
self.0.fetch_add(1, Ordering::Relaxed);
}
// 原子加载操作
fn get(&self) -> usize {
self.0.load(Ordering::Relaxed)
}
}
fn main() {
// 使用Arc实现多线程间共享Counter
let c = Arc::new(Counter::new());
let mut handles = vec![];
// 创建8个线程,每个线程递增计数器1000次
for _ in 0..8 {
let cc = Arc::clone(&c);
handles.push(thread::spawn(move || {
for _ in 0..1000 {
cc.inc();
}
}));
}
// 等待所有线程完成
for handle in handles {
handle.join().unwrap();
}
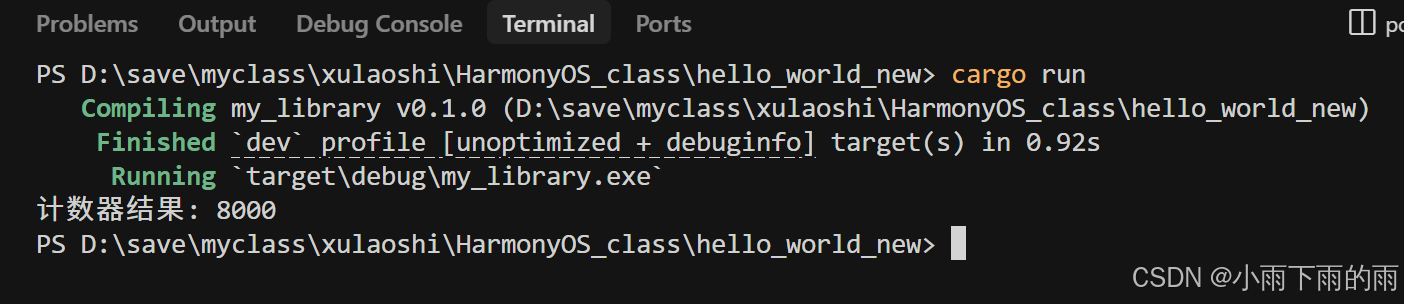
// 输出最终结果(应为8000)
println!("计数器结果: {}", c.get());
}
5. Compare-And-Swap(CAS)与乐观更新
use std::sync::atomic::{AtomicUsize, Ordering};
fn try_update(atom: &AtomicUsize, old: usize, new: usize) -> bool {
atom.compare_exchange(old, new, Ordering::SeqCst, Ordering::SeqCst).is_ok()
}
// 自旋更新示例
loop {
let cur = atom.load(Ordering::SeqCst);
let next = cur + 1;
if try_update(atom, cur, next) { break; }
}
- CAS 在冲突少时性能优秀;冲突多时自旋开销大,需退回到锁或退避策略。
6. Lock-Free 栈(Treiber Stack,简化版)
use std::sync::atomic::{AtomicPtr, Ordering};
use std::ptr;
struct Node<T> { val: T, next: *mut Node<T> }
pub struct Stack<T> { head: AtomicPtr<Node<T>> }
impl<T> Stack<T> {
pub fn new() -> Self { Self { head: AtomicPtr::new(ptr::null_mut()) } }
pub fn push(&self, v: T) {
let node = Box::into_raw(Box::new(Node { val: v, next: ptr::null_mut() }));
loop {
let cur = self.head.load(Ordering::Acquire);
unsafe { (*node).next = cur; }
if self.head.compare_exchange_weak(cur, node, Ordering::Release, Ordering::Relaxed).is_ok() {
break;
}
}
}
}
注意:完整实现需要处理 ABA 问题与内存安全,初学建议用标准库或成熟库(如
crossbeam)。
7. 适用场景与选型
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 简单计数/标志 | AtomicUsize/Bool |
零开销、无锁 |
| 复杂状态/大对象 | Arc<Mutex<T>> |
安全、易理解 |
| 读多写少 | Arc<RwLock<T>> |
并行读 |
| 高频更新/无锁队列 | 成熟无锁库(crossbeam) |
性能与正确性 |
8. 常见错误与修复
- 在多锁间顺序不一致 → 统一排序或单锁化;
Atomic误用跨多个变量的原子性(需要事务语义) → 用锁保护或重新设计;Ordering选择不当导致数据竞争 → 保守用SeqCst,优化时再降级;- 无锁算法中忘记处理 ABA → 用版本号/标记指针或成熟库。
9. 实战:无锁环形缓冲区(简化版)
use std::sync::atomic::{AtomicUsize, Ordering};
struct RingBuf<T, const N: usize> {
data: [Option<T>; N],
write: AtomicUsize,
read: AtomicUsize,
}
impl<T: Copy, const N: usize> RingBuf<T, N> {
fn try_push(&self, v: T) -> bool {
let w = self.write.load(Ordering::Acquire);
let r = self.read.load(Ordering::Acquire);
if (w + 1) % N == r { return false; } // 满
self.data[w] = Some(v);
self.write.store((w + 1) % N, Ordering::Release);
true
}
fn try_pop(&self) -> Option<T> {
let r = self.read.load(Ordering::Acquire);
let w = self.write.load(Ordering::Acquire);
if r == w { return None; } // 空
let v = self.data[r].take();
self.read.store((r + 1) % N, Ordering::Release);
v
}
}
10. 练习
- 实现一个无锁计数器(
AtomicUsize),并对比Arc<Mutex<usize>>的性能; - 用 CAS 实现“无锁栈”的
pop,处理并发push/pop的 ABA 风险; - 设计一个“多生产者多消费者队列”(MPMC),先用
crossbeam::channel验证需求,再考虑无锁方案; - 模拟死锁场景,用锁排序修复,并加入超时机制。
小结:
- 死锁:统一锁序、减少粒度、避免嵌套;必要时用
try_lock/超时。 - 无锁:适合简单原子操作(计数/标志);复杂结构优先用成熟库。
Atomic+CAS可构建高性能无锁结构,但正确性要求高,建议先掌握模式再自制。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)