让AI开发像搭积木一样简单:ModelEngine全链路实战拆解
让AI开发像搭积木一样简单:ModelEngine全链路实战拆解
最近在和几个做企业数字化转型的朋友聊天,大家都在抱怨同一个问题:现在大模型这么火,都知道AI能帮业务提效,但真要把AI用起来,从数据准备到模型训练再到最后上线,整个流程太折腾了。数据工程师、算法工程师、开发工程师各干各的,工具链不统一,对接成本高,一个简单的智能客服项目可能要搞上好几个月。
如果你也在面对这样的困境,那今天聊的ModelEngine可能会让你眼前一亮。这不是又一个“又一个AI平台”,而是华为开源的一套全流程AI开发工具链,它想把AI开发的整个链条打通,让企业用AI像搭积木一样简单。
一、ModelEngine到底是什么?为什么值得关注?

简单说,ModelEngine就是一个“AI开发全家桶”。它想解决的是AI落地过程中最痛的那些点:
- 流程割裂:数据处理用一套工具,模型训练用另一套,部署上线又要换平台
- 门槛太高:搞AI需要懂算法、懂框架、懂工程,团队配置要求高
- 迭代太慢:想换个模型试试?可能又要重写一大堆代码
ModelEngine的思路很直接——把AI开发的全流程打包成一套工具链,从数据清洗、知识生成,到模型微调、应用编排,再到最后的部署上线,全部在一个平台上搞定。
最让我觉得有意思的是它的三层架构(从产品架构图能看出来):
- AI基础设施层:负责最底层的算力、存储、网络,这是AI的“水电煤”
- AI平台层:核心功能都在这里,包括数据工程、模型工程、智能体、应用编排
- 解决方案层:针对不同场景(智能边缘、企业AI、智算中心)的打包方案
这架构设计得很务实,既考虑了技术深度,又考虑了业务落地。
二、FIT框架:Java工程师的“AI救星”
modelengine FIT:重新定义AI工程化的三维坐标系:
如果你是个Java工程师,看到AI项目可能有点头疼——现在AI生态几乎被Python垄断,LangChain、LlamaIndex这些热门框架都是Python的。Java团队想接入大模型,要么硬着头皮学Python,要么自己造轮子。
ModelEngine里的FIT框架就是来解决这个问题的。它号称是“Java生态的LangChain革命”,我仔细看了它的介绍,觉得这个说法还真不夸张。
FIT框架有三个核心:
- FIT Core:支持多语言(Java/Python/C++)函数计算,最厉害的是“智能聚散部署”——同一份代码,不用修改就能在单机或分布式环境下运行,系统会自动决定是本地调用还是走RPC
- WaterFlow Engine:流式编排引擎,可以用图形化拖拽的方式编排业务流程,从简单的函数调用到复杂的跨系统流程都能处理
- FEL:专门为LLM设计的表达式语言,让Java开发者能用熟悉的方式调用大模型能力
这相当于给Java团队提供了一整套“AI武器库”,不用跳出自己的技术栈就能玩转大模型。
三、Aido:开箱即用的AI应用平台
如果说ModelEngine是底层工具链,那Aido就是基于这套工具链构建的上层应用平台。它是完全开源的(MIT协议),你可以把它理解成一个“智能体操作系统”。
Aido有几个特点特别实用:
- RAG工作流编排:现在做企业知识库,RAG几乎是标配。Aido可以完整支持检索、重排、结果过滤整个流程,而且能接入多种知识库
- 智能体协作:单个AI能力有限,但多个智能体分工协作就能处理复杂任务。Aido支持智能体之间的任务路由和协作
- 模型随便换:今天用GPT-4,明天想换成Claude或者国产大模型?在Aido里就是切换个配置的事
- 富媒体交互:AI回复不只是文本,可以嵌入表格、图表、表单,甚至自定义的前端组件
我在Aido的示例里看到一个真实场景:让AI同步订单物流状态并通知客服团队。AI会自动执行一系列操作——查询订单、获取物流信息、更新系统状态、发送通知——整个过程完全自动化。这种“懂业务”的AI应用,正是企业最需要的。
四、实战思考:如何用ModelEngine真正落地一个AI项目?
说了这么多功能,具体怎么用呢?我结合自己的理解,给你拆解一个典型的企业AI项目落地流程:
在Aido官网我们可以选择从模版创建,利用现成模版创建一个智能体,这是会让我们的开发过程迅速且高效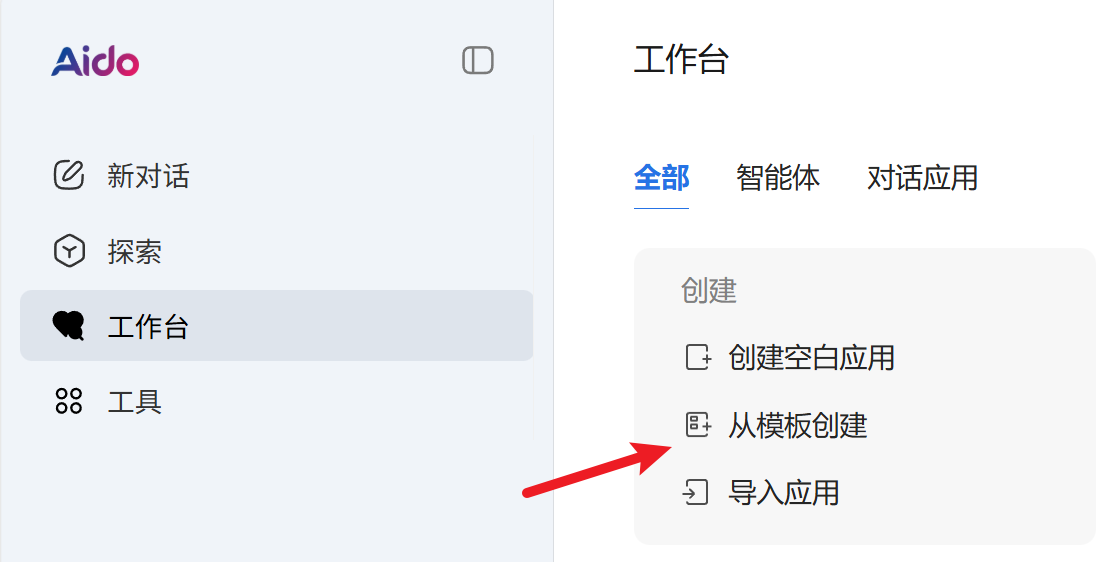
可以看到这里有很多模板供选择,我选择 塔罗 这个模版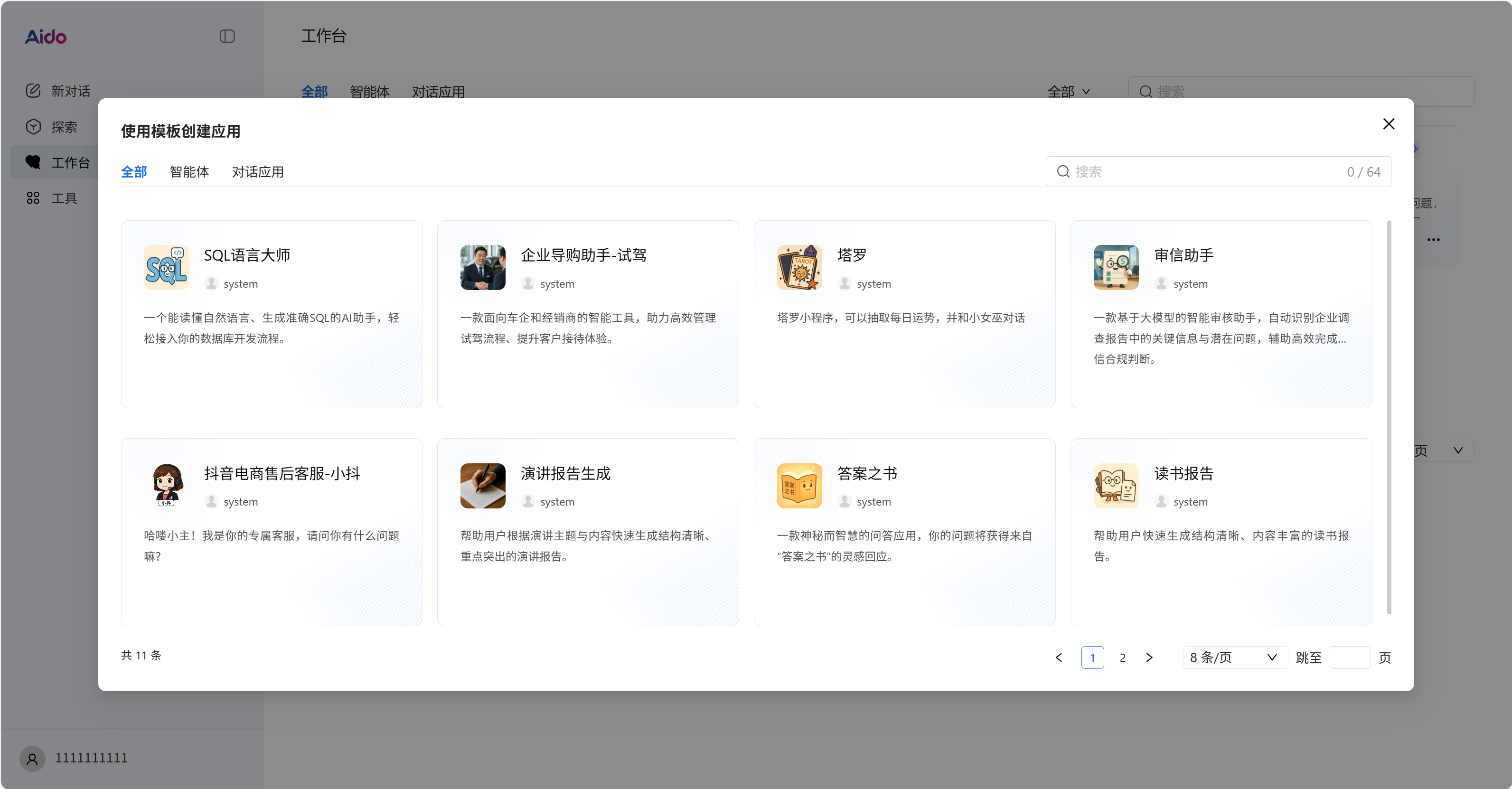
取名叫塔罗小女巫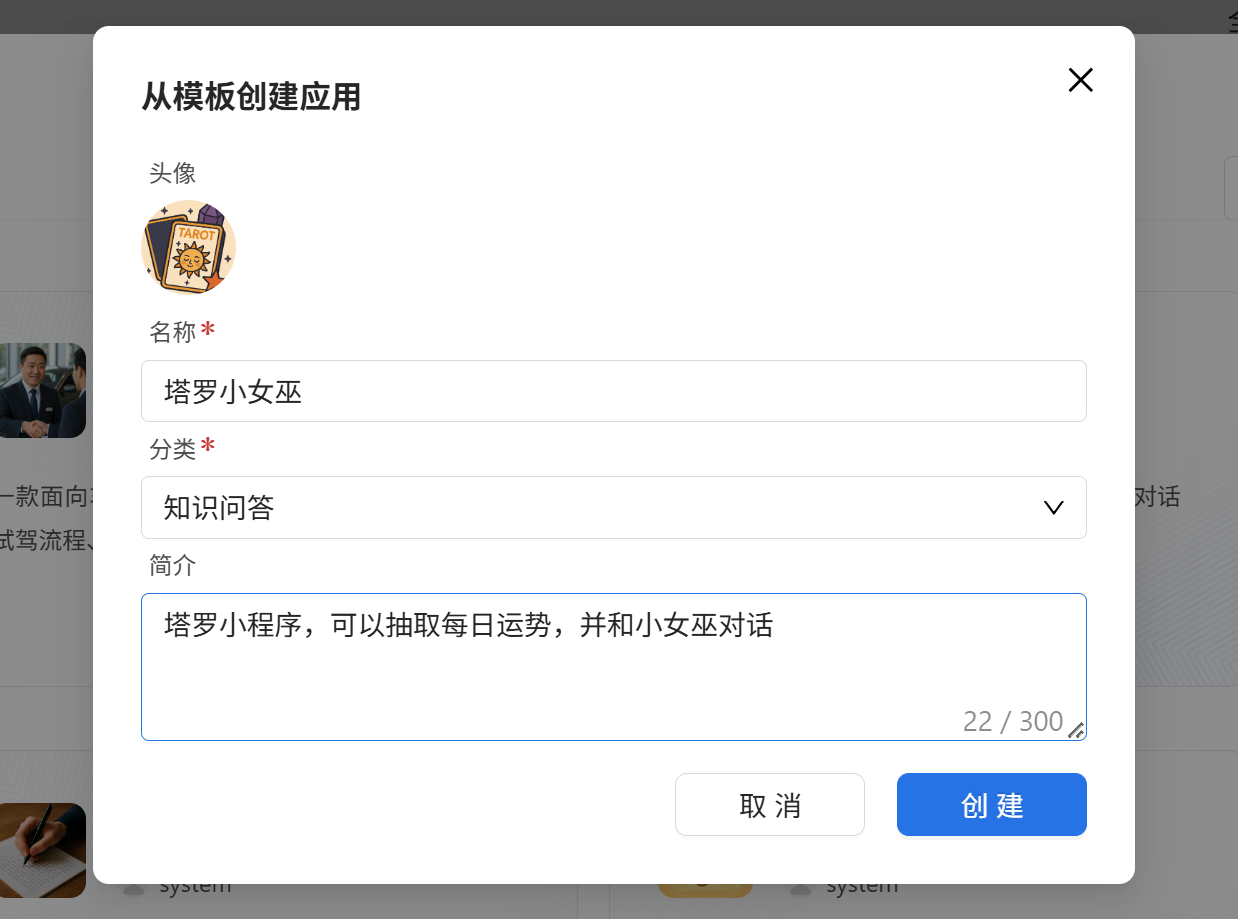
创建后的界面如下,我们可以进一步进行详细设置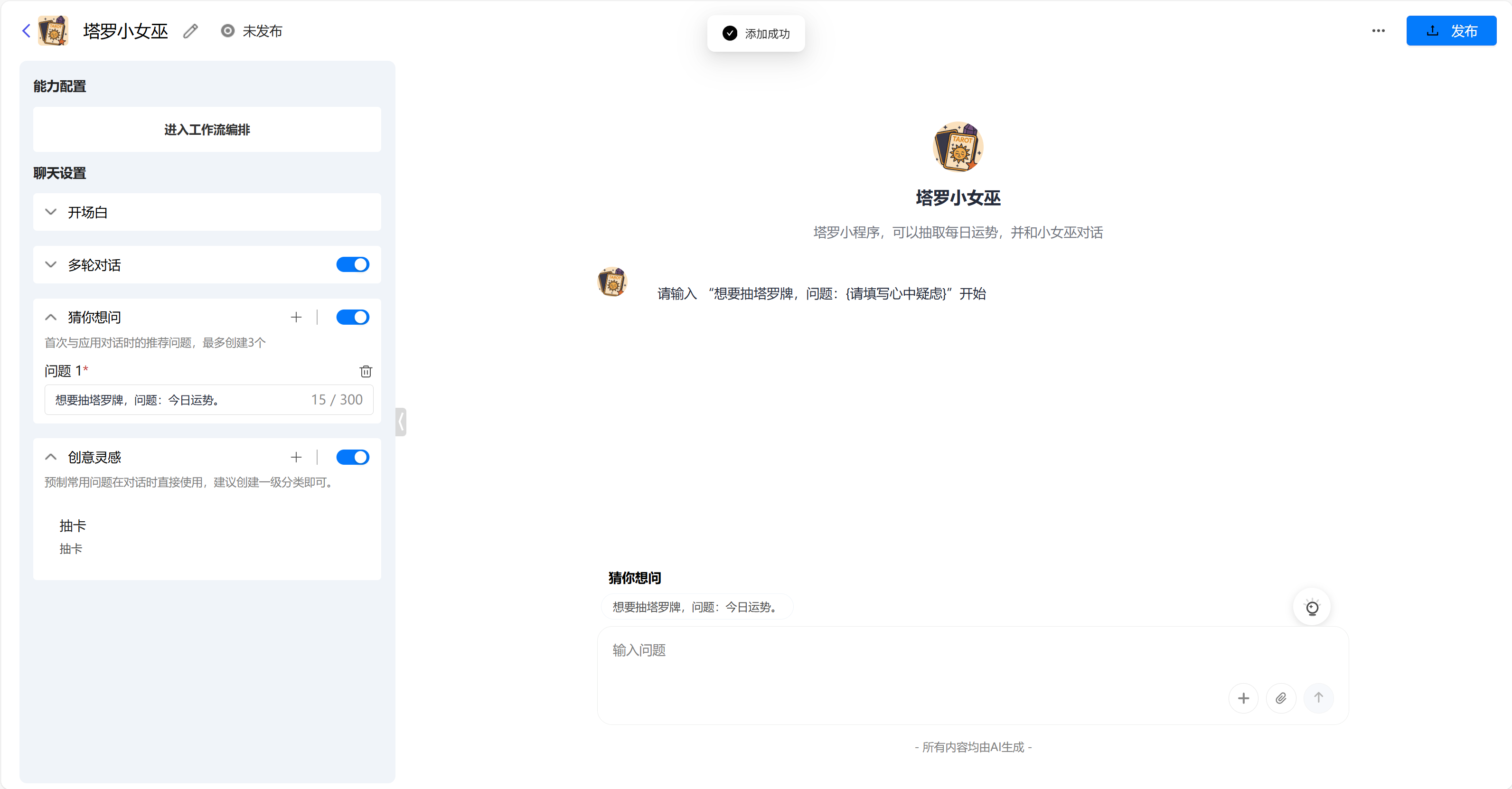
我们先设置工作流,可以看到这些组件我们可以进行进一步的设置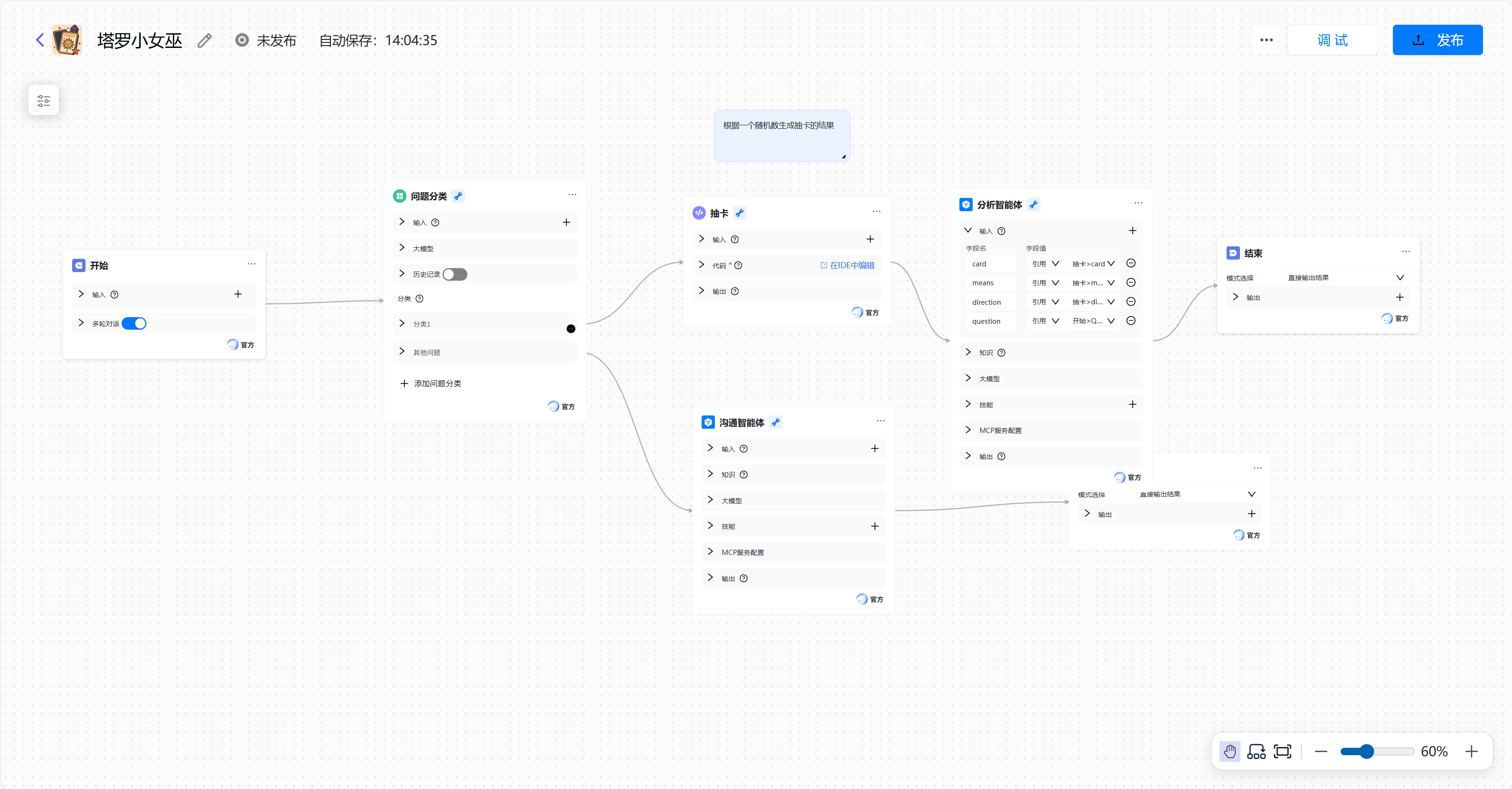
我们可以设置抽卡部分的代码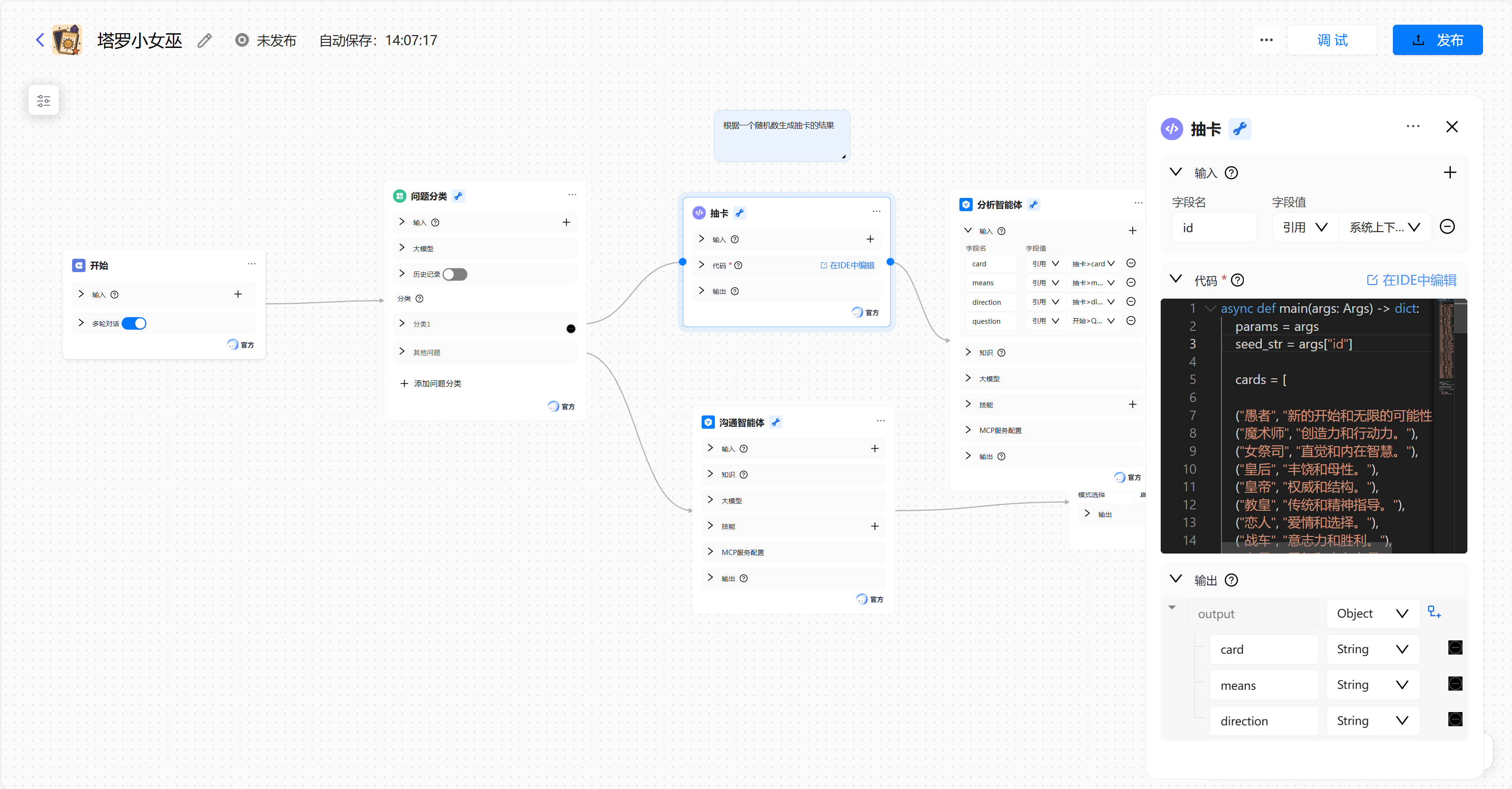
如下是我设置的抽卡的代码部分,感兴趣的朋友们可以参考一下:
async def main(args: Args) -> dict:
"""
塔罗牌单张抽取函数
根据用户ID生成确定性随机数,从78张塔罗牌中抽取一张,
并判断牌面方向(正位/逆位)
Args:
args: 包含用户参数的字典,必须包含"id"键
Returns:
dict: 包含抽取结果
- card: 牌名
- means: 牌意解释
- direction: 牌面方向("正位"或"逆位")
"""
# 获取参数
params = args
# 获取用户ID作为随机种子
# 使用确定性算法确保同一用户每次抽到相同的牌(除非刷新种子)
seed_str = args["id"]
# 78张塔罗牌数据集
# 格式:(牌名, 基本牌意解释)
# 包含22张大阿尔卡纳和56张小阿尔卡纳(四花色:权杖、圣杯、宝剑、星币)
cards = [
# 大阿尔卡纳 (Major Arcana) - 0-21
("愚者", "新的开始和无限的可能性。"),
("魔术师", "创造力和行动力。"),
("女祭司", "直觉和内在智慧。"),
("皇后", "丰饶和母性。"),
("皇帝", "权威和结构。"),
("教皇", "传统和精神指导。"),
("恋人", "爱情和选择。"),
("战车", "意志力和胜利。"),
("力量", "勇气和内在力量。"),
("隐士", "内省和孤独。"),
("命运之轮", "命运和变化。"),
("正义", "公正和平衡。"),
("倒吊人", "牺牲和新的视角。"),
("死神", "结束和转变。"),
("节制", "和谐和适度。"),
("恶魔", "诱惑和束缚。"),
("高塔", "突变和解放。"),
("星星", "希望和灵感。"),
("月亮", "幻象和潜意识。"),
("太阳", "快乐和成功。"),
("审判", "觉醒和复兴。"),
("世界", "完成和成就。"),
# 权杖组 (Wands) - 火元素,代表行动、创造、能量
("权杖王牌", "新的创意和激情。"),
("权杖二", "计划和决策。"),
("权杖三", "远见和探索。"),
("权杖四", "庆祝和稳定。"),
("权杖五", "冲突和竞争。"),
("权杖六", "胜利和认可。"),
("权杖七", "防御和挑战。"),
("权杖八", "快速行动和进展。"),
("权杖九", "坚韧和毅力。"),
("权杖十", "负担和责任。"),
("权杖侍者", "好奇和冒险。"),
("权杖骑士", "热情和冲动。"),
("权杖皇后", "自信和独立。"),
("权杖国王", "领导力和远见。"),
# 圣杯组 (Cups) - 水元素,代表情感、关系、直觉
("圣杯王牌", "爱情和情感的新开始。"),
("圣杯二", "伙伴关系和和谐。"),
("圣杯三", "友谊和庆祝。"),
("圣杯四", "冷漠和沉思。"),
("圣杯五", "失望和悲伤。"),
("圣杯六", "怀旧和童年回忆。"),
("圣杯七", "幻想和选择。"),
("圣杯八", "放弃和寻找更好的。"),
("圣杯九", "满足和愿望实现。"),
("圣杯十", "家庭和幸福。"),
("圣杯侍者", "创意和情感表达。"),
("圣杯骑士", "浪漫和追求。"),
("圣杯皇后", "同情和关怀。"),
("圣杯国王", "情感平衡和智慧。"),
# 宝剑组 (Swords) - 风元素,代表思想、沟通、冲突
("宝剑王牌", "真理和新的想法。"),
("宝剑二", "决策和僵局。"),
("宝剑三", "心碎和痛苦。"),
("宝剑四", "休息和恢复。"),
("宝剑五", "冲突和失败。"),
("宝剑六", "过渡和康复。"),
("宝剑七", "欺骗和策略。"),
("宝剑八", "限制和困境。"),
("宝剑九", "焦虑和忧虑。"),
("宝剑十", "结束和背叛。"),
("宝剑侍者", "好奇和观察。"),
("宝剑骑士", "冲动和行动。"),
("宝剑皇后", "独立和清晰。"),
("宝剑国王", "权威和理性。"),
# 星币组 (Pentacles) - 土元素,代表物质、财务、工作
("星币王牌", "物质和财务的新开始。"),
("星币二", "平衡和适应。"),
("星币三", "团队合作和技能。"),
("星币四", "控制和保守。"),
("星币五", "贫困和困难。"),
("星币六", "慷慨和分享。"),
("星币七", "耐心和评估。"),
("星币八", "努力和专注。"),
("星币九", "自立和舒适。"),
("星币十", "财富和遗产。"),
("星币侍者", "学习和成长。"),
("星币骑士", "勤奋和责任。"),
("星币皇后", "实用和关怀。"),
("星币国王", "成功和安全。")
]
# 计算种子值:将用户ID中每个字符的Unicode码点累加
# 不使用内置sum()函数,采用手动累加确保确定性
seed_sum = 0
for char in seed_str:
seed_sum = seed_sum + ord(char) # ord()获取字符的Unicode码点
# 使用模运算确保索引在cards列表范围内
# 同一用户ID总是映射到同一张牌(确定性随机)
idx = seed_sum % len(cards)
# 从cards列表中获取牌名和基本牌意
card, means = cards[idx]
# 判断牌面方向:使用种子值的奇偶性决定
# 偶数为正位,奇数为逆位
# 正位:牌面正常方向,通常表示牌意的正面或显性层面
# 逆位:牌面倒置,通常表示牌意的负面、隐性或需要关注的层面
direction = "正位" if seed_sum % 2 == 0 else "逆位"
# 返回抽取结果
return {
"card": card, # 抽取的牌名
"means": means, # 基本牌意解释
"direction": direction # 牌面方向
}
然后我们可以在发布前进行调试,若出现问题,我们可以很直接的寻找到问题,这是我的调试结果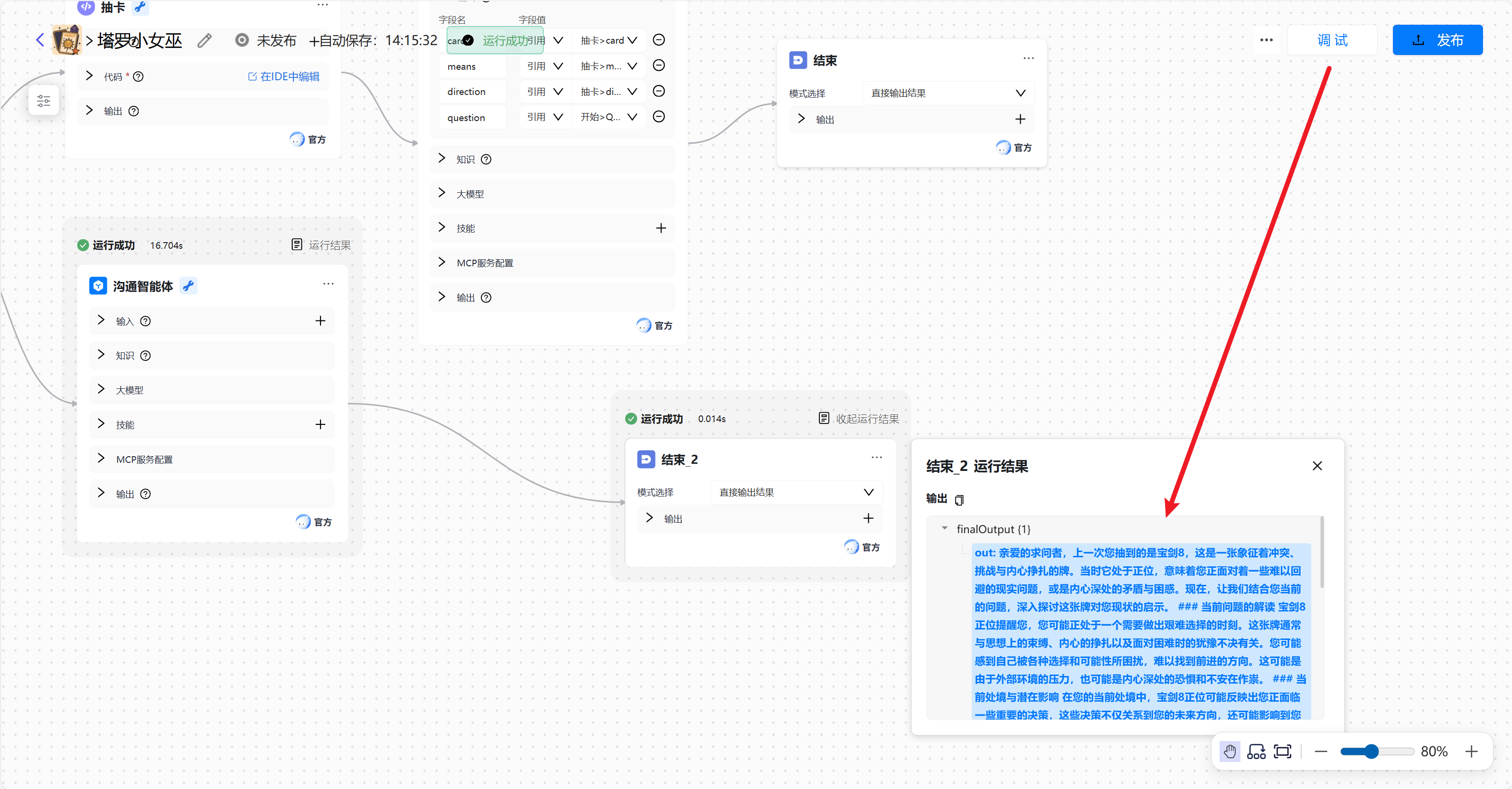
退出工作流我们可以看到这边功能配置界面,可以设置一些细节方面的东西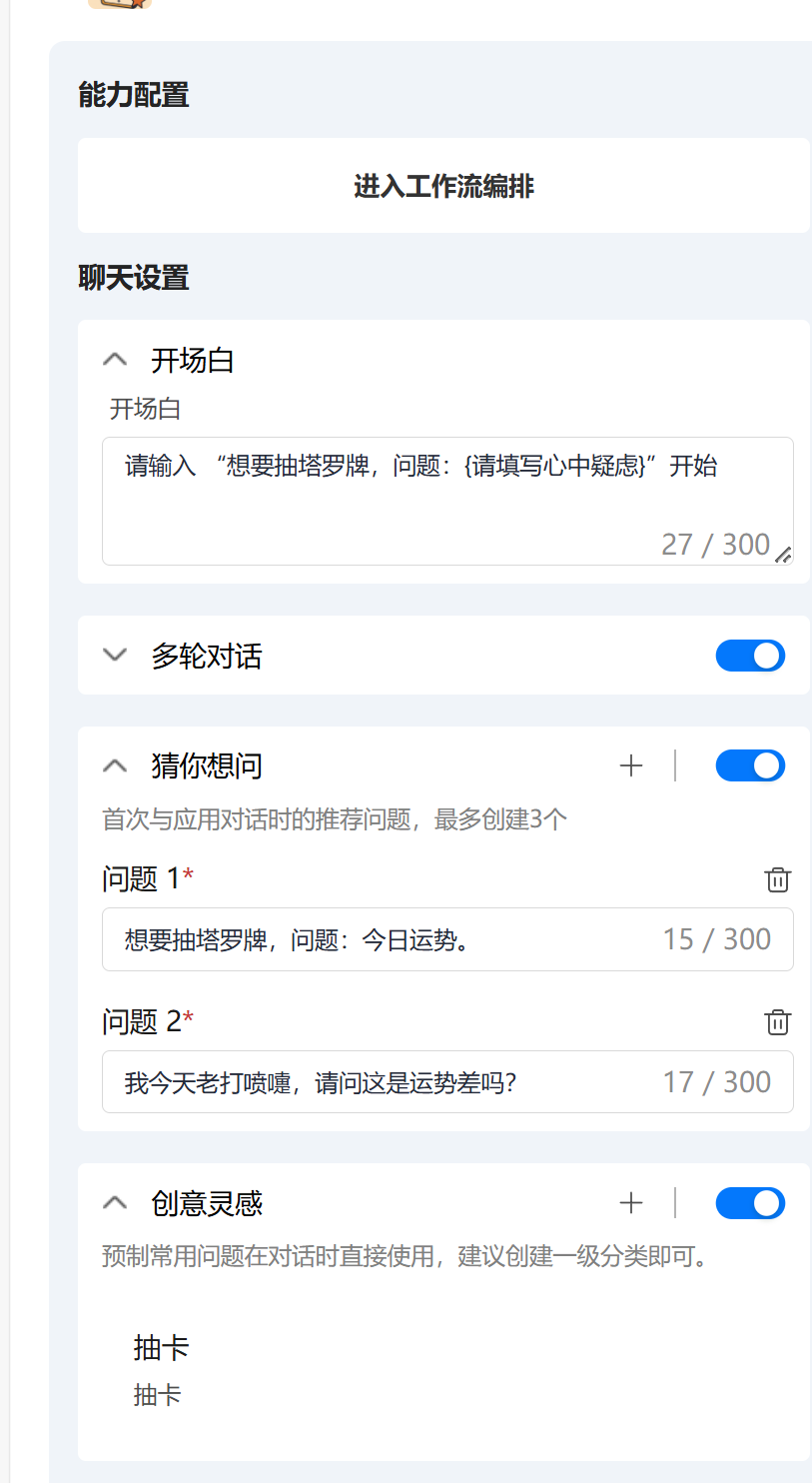
最终的应用效果如下
然后我们可以进行发布啦
在工作台可以看到我们发布的对话应用
点击这个应用可以看到我们可以通过外部调用,URl和API调用都行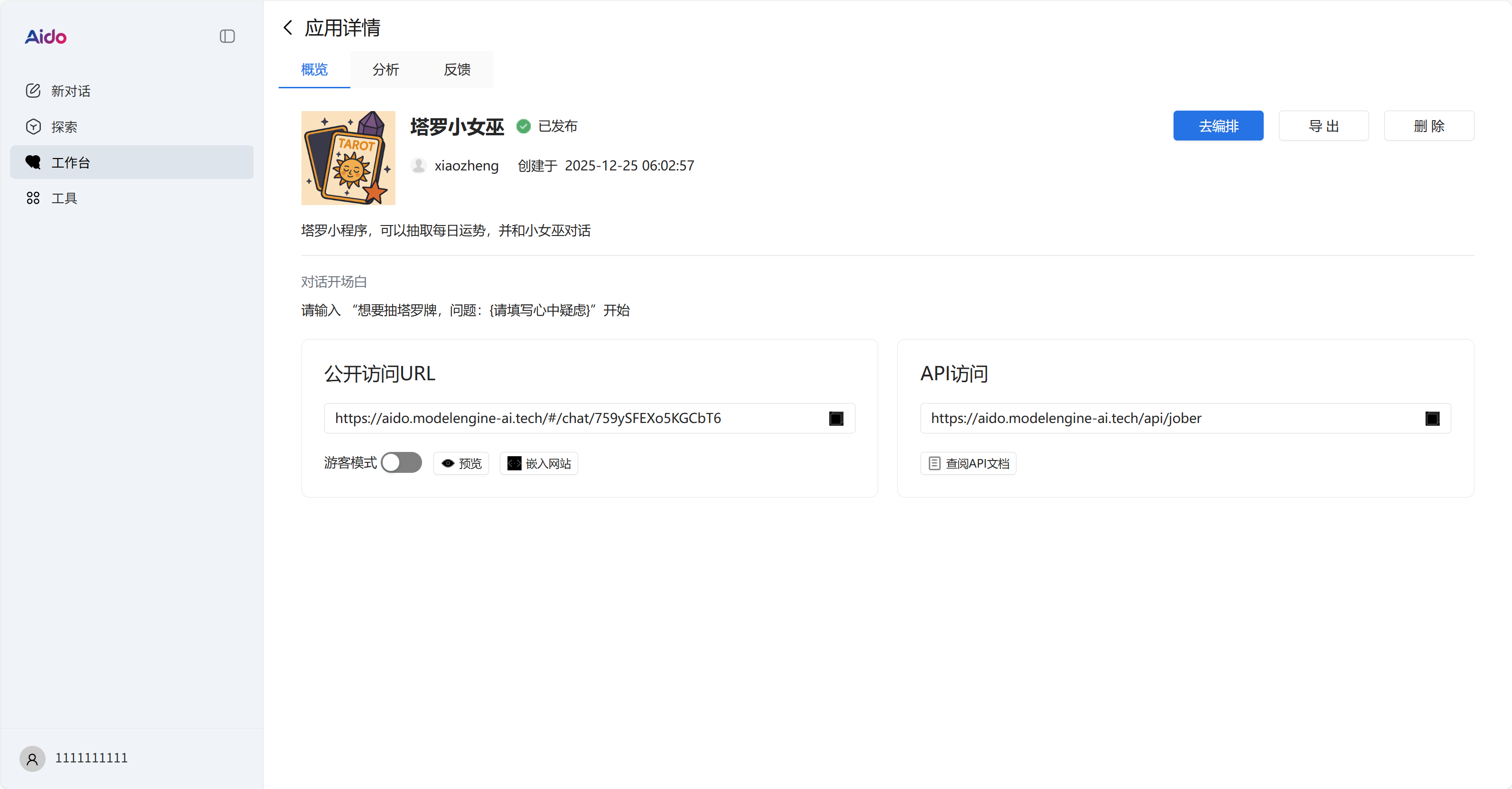
外部调用效果图如下
五、谁最适合用ModelEngine?
根据我的观察,这几类团队会特别喜欢ModelEngine:
- 传统企业的IT团队:有Java技术栈,想引入AI但不想重建技术体系
- 中小型创业公司:资源有限,需要快速验证AI应用,不想在基础设施上投入太多
- 系统集成商:要给客户交付AI解决方案,需要一套稳定、可定制的基础平台
- 个人开发者:想学习全链路AI开发,但被复杂的工具链劝退
六、一些冷思考
ModelEngine虽然强大,但也不是银弹:
- 学习成本:功能多意味着要学的东西也多,团队需要时间熟悉
- 定制需求:如果业务特别特殊,可能还是需要二次开发
- 社区生态:虽然是华为开源,但社区活跃度还需要时间培养
不过总的来说,ModelEngine代表了一个很清晰的方向:AI工程化。当AI从技术演示走向真实业务,我们需要的不再是炫酷的模型,而是稳定、可维护、易集成的工程体系。
写在最后
AI正在从“技术话题”变成“业务标配”,但如何让AI真正用起来,而不只是做个Demo,这是所有企业都要面对的问题。ModelEngine提供了一种思路——通过标准化的工具链,降低AI应用的门槛,让更多团队能把精力放在业务创新上,而不是技术折腾上。
如果你正在考虑企业AI落地,不妨去看看ModelEngine的开源项目,或许它能帮你少踩很多坑。AI的世界变化很快,但好的工程实践永远值得投入。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)