智能办公助手:基于ModelEngine的AI会议纪要生成与分析系统
1. 系统概述
1.1 项目背景
在现代办公环境中,会议占据了大量工作时间,但会议内容的记录、整理和分析往往耗费大量人力资源。传统的人工记录方式存在效率低下、信息遗漏、主观性强等问题。基于ModelEngine智能体构建的AI会议纪要生成与分析系统,能够自动完成会议记录、内容摘要、决策提取和数据分析等任务,大幅提升办公效率。
1.2 系统目标
-
实现会议音频的实时转写和智能分析
-
自动生成结构化会议纪要
-
提取关键决策和行动项
-
提供数据可视化和趋势分析
-
支持多格式导出和分享
2. 系统架构设计
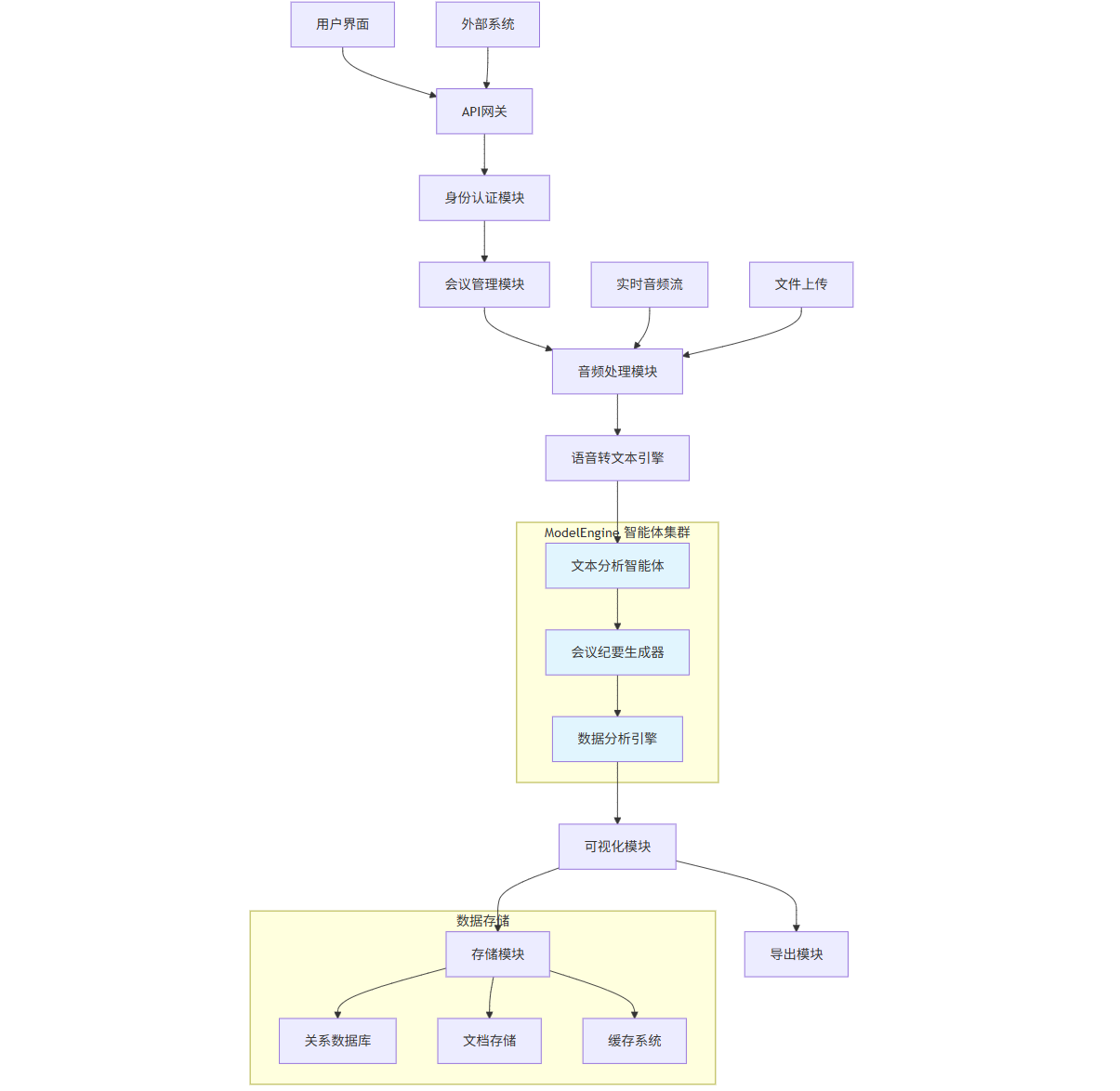
graph TB
A[用户界面] --> B[API网关]
B --> C[身份认证模块]
C --> D[会议管理模块]
D --> E[音频处理模块]
E --> F[语音转文本引擎]
F --> G[文本分析智能体]
G --> H[会议纪要生成器]
H --> I[数据分析引擎]
I --> J[可视化模块]
J --> K[存储模块]
J --> L[导出模块]
M[外部系统] --> B
N[实时音频流] --> E
O[文件上传] --> E
subgraph "ModelEngine 智能体集群"
G
H
I
end
subgraph "数据存储"
K --> P[关系数据库]
K --> Q[文档存储]
K --> R[缓存系统]
end
style G fill:#e1f5fe
style H fill:#e1f5fe
style I fill:#e1f5fe
3. 核心模块实现
3.1 音频处理模块
python
import speech_recognition as sr
import numpy as np
import librosa
from pydub import AudioSegment
import io
import tempfile
import os
class AudioProcessor:
def __init__(self, model_engine_client):
self.recognizer = sr.Recognizer()
self.model_engine = model_engine_client
self.sample_rate = 16000
def preprocess_audio(self, audio_data):
"""音频预处理"""
# 降噪处理
audio_clean = self._noise_reduction(audio_data)
# 音量标准化
audio_normalized = self._normalize_volume(audio_clean)
# 语音活动检测
segments = self._voice_activity_detection(audio_normalized)
return segments
def transcribe_audio(self, audio_file):
"""语音转文本"""
try:
# 预处理音频
processed_audio = self.preprocess_audio(audio_file)
transcriptions = []
for segment in processed_audio:
# 使用ModelEngine进行语音识别
transcription = self.model_engine.transcribe(
audio_segment=segment,
language="zh-CN",
model="whisper-large"
)
transcriptions.append(transcription)
# 合并并后处理文本
full_text = self._post_process_transcription(transcriptions)
return full_text
except Exception as e:
print(f"语音转文本错误: {str(e)}")
return None
def _noise_reduction(self, audio_data):
"""降噪处理"""
# 实现基于频谱减法的降噪
# 详细实现代码...
return audio_clean
def _normalize_volume(self, audio_data):
"""音量标准化"""
# 实现音量标准化算法
# 详细实现代码...
return audio_normalized
def _voice_activity_detection(self, audio_data):
"""语音活动检测"""
# 使用能量和频谱特征检测语音段
# 详细实现代码...
return speech_segments
3.2 文本分析智能体
python
import re
import jieba
import jieba.posseg as pseg
from typing import List, Dict, Any
from datetime import datetime
import json
class TextAnalysisAgent:
def __init__(self, model_engine):
self.model_engine = model_engine
self._initialize_jieba()
def _initialize_jieba(self):
"""初始化分词器"""
jieba.initialize()
# 添加办公领域专业词汇
professional_words = [
'KPI', 'OKR', 'ROI', 'PPT', 'Excel', 'Word',
'项目里程碑', '风险评估', '资源分配', '时间线',
'干系人', '敏捷开发', '瀑布模型', '产品迭代'
]
for word in professional_words:
jieba.add_word(word)
def analyze_meeting_content(self, text: str) -> Dict[str, Any]:
"""分析会议内容"""
analysis_result = {
"speakers": self._extract_speakers(text),
"topics": self._extract_topics(text),
"decisions": self._extract_decisions(text),
"action_items": self._extract_action_items(text),
"timeline": self._extract_timeline(text),
"sentiment": self._analyze_sentiment(text)
}
# 使用ModelEngine进行深度分析
enhanced_analysis = self.model_engine.analyze(
prompt=self._build_analysis_prompt(text, analysis_result),
model="gpt-4"
)
return {**analysis_result, **enhanced_analysis}
def _extract_speakers(self, text: str) -> List[Dict]:
"""提取发言人信息"""
speakers = []
# 使用正则表达式和命名实体识别
speaker_pattern = r'([张李王赵刘陈杨黄周吴徐孙胡朱高林郭马罗梁宋郑谢韩唐冯于董萧程曹袁邓许傅沈曾彭吕苏卢蒋蔡贾丁魏薛叶阎余潘杜戴夏钟汪田任姜范方石姚谭廖邹熊金陆郝孔白崔康毛邱秦江史顾侯邵孟龙万段雷钱汤尹黎易常武乔贺赖龚文]+\s*[经理总监主管领导同事]*):'
matches = re.finditer(speaker_pattern, text)
for match in matches:
speaker_name = match.group(1)
speakers.append({
"name": speaker_name,
"mention_count": text.count(speaker_name)
})
return speakers
def _extract_decisions(self, text: str) -> List[Dict]:
"""提取决策点"""
decisions = []
decision_keywords = ['决定', '确定', '通过', '批准', '采纳', '决议']
sentences = re.split(r'[。!?]', text)
for sentence in sentences:
for keyword in decision_keywords:
if keyword in sentence:
decisions.append({
"content": sentence.strip(),
"keyword": keyword,
"confidence": 0.8
})
break
return decisions
def _extract_action_items(self, text: str) -> List[Dict]:
"""提取行动项"""
action_items = []
action_patterns = [
r'([张李王赵刘陈杨黄周吴徐孙胡朱高林郭马罗梁宋郑谢韩唐冯于董萧程曹袁邓许傅沈曾彭吕苏卢蒋蔡贾丁魏薛叶阎余潘杜戴夏钟汪田任姜范方石姚谭廖邹熊金陆郝孔白崔康毛邱秦江史顾侯邵孟龙万段雷钱汤尹黎易常武乔贺赖龚文]+)\s*(负责|安排|完成|准备|提交)\s*(.*?)(?=[。!?]|$)',
r'(需要|必须|应当|要)\s*(.*?)(?=[。!?]|$)'
]
for pattern in action_patterns:
matches = re.finditer(pattern, text)
for match in matches:
action_items.append({
"assignee": match.group(1) if match.groups() > 1 else "待分配",
"action": match.group(2),
"description": match.group(-1),
"deadline": self._extract_deadline(match.group(0))
})
return action_items
def _build_analysis_prompt(self, text: str, basic_analysis: Dict) -> str:
"""构建分析提示词"""
prompt = f"""
请对以下会议内容进行深度分析:
{text}
基础分析结果:
{json.dumps(basic_analysis, ensure_ascii=False, indent=2)}
请补充以下信息:
1. 会议的主要议题和讨论重点
2. 各发言人的立场和观点
3. 存在的争议点和解决方案
4. 下一步工作的优先级排序
5. 潜在的风险和建议
请以JSON格式返回分析结果。
"""
return prompt
3.3 会议纪要生成器
python
class MeetingMinutesGenerator:
def __init__(self, model_engine):
self.model_engine = model_engine
self.template = self._load_template()
def generate_minutes(self, analysis_result: Dict, metadata: Dict) -> Dict:
"""生成会议纪要"""
# 构建生成提示词
prompt = self._build_generation_prompt(analysis_result, metadata)
# 使用ModelEngine生成纪要
generated_content = self.model_engine.generate(
prompt=prompt,
model="gpt-4",
max_tokens=2000,
temperature=0.7
)
# 结构化处理生成内容
structured_minutes = self._structure_minutes(
generated_content, analysis_result, metadata
)
return structured_minutes
def _build_generation_prompt(self, analysis_result: Dict, metadata: Dict) -> str:
"""构建生成提示词"""
prompt = f"""
请根据以下会议分析结果生成专业的会议纪要:
会议基本信息:
- 时间:{metadata.get('meeting_time', '未知')}
- 地点:{metadata.get('location', '未知')}
- 参会人员:{', '.join(metadata.get('participants', []))}
- 主持人:{metadata.get('host', '未知')}
会议内容分析:
{json.dumps(analysis_result, ensure_ascii=False, indent=2)}
请按照以下格式生成会议纪要:
# 会议纪要
## 会议基本信息
- 时间:[具体时间]
- 地点:[具体地点]
- 参会人员:[名单]
- 主持人:[姓名]
- 记录人:AI会议助手
## 会议议程
[列出会议讨论的主要议题]
## 讨论要点
[详细记录各议题的讨论内容]
## 会议决议
[明确列出会议达成的所有决议]
## 行动项
[列出具体行动项,包括负责人和截止时间]
## 下一步计划
[概述后续工作安排]
请确保内容准确、专业、结构清晰。
"""
return prompt
def _structure_minutes(self, generated_content: str, analysis_result: Dict, metadata: Dict) -> Dict:
"""结构化处理会议纪要"""
# 使用正则表达式提取各个部分
sections = {
"basic_info": self._extract_section(generated_content, "会议基本信息"),
"agenda": self._extract_section(generated_content, "会议议程"),
"discussion_points": self._extract_section(generated_content, "讨论要点"),
"decisions": self._extract_section(generated_content, "会议决议"),
"action_items": self._extract_section(generated_content, "行动项"),
"next_steps": self._extract_section(generated_content, "下一步计划")
}
return {
"metadata": metadata,
"content": sections,
"analysis": analysis_result,
"generated_at": datetime.now().isoformat(),
"version": "1.0"
}
def _extract_section(self, content: str, section_title: str) -> str:
"""提取特定章节内容"""
pattern = f"## {section_title}\n(.*?)(?=## |$)"
match = re.search(pattern, content, re.DOTALL)
return match.group(1).strip() if match else ""
4. 数据可视化与分析模块
4.1 图表生成组件
python
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import plotly.graph_objects as go
import plotly.express as px
from plotly.subplots import make_subplots
import io
import base64
class VisualizationEngine:
def __init__(self):
plt.style.use('seaborn-v0_8')
self.color_palette = ['#4e79a7', '#f28e2c', '#e15759', '#76b7b2', '#59a14f']
def generate_speaker_analysis_chart(self, analysis_result: Dict) -> str:
"""生成发言人分析图表"""
speakers_data = analysis_result.get('speakers', [])
if not speakers_data:
return self._create_empty_chart()
# 准备数据
df = pd.DataFrame(speakers_data)
df = df.nlargest(8, 'mention_count')
# 创建图表
fig = make_subplots(
rows=1, cols=2,
subplot_titles=['发言频次统计', '发言分布'],
specs=[[{"type": "bar"}, {"type": "pie"}]]
)
# 柱状图
fig.add_trace(
go.Bar(
x=df['name'],
y=df['mention_count'],
marker_color=self.color_palette,
name='发言次数'
),
row=1, col=1
)
# 饼图
fig.add_trace(
go.Pie(
labels=df['name'],
values=df['mention_count'],
name='发言分布'
),
row=1, col=2
)
fig.update_layout(
title_text="会议发言人分析",
showlegend=True,
height=400
)
return fig.to_html(include_plotlyjs='cdn', div_id="speaker_analysis_chart")
def generate_topic_analysis_chart(self, analysis_result: Dict) -> str:
"""生成议题分析图表"""
topics_data = analysis_result.get('topics', [])
if not topics_data:
return self._create_empty_chart()
# 创建词云或条形图
fig = go.Figure()
topics = [topic['name'] for topic in topics_data]
frequencies = [topic['frequency'] for topic in topics_data]
fig.add_trace(go.Bar(
x=frequencies,
y=topics,
orientation='h',
marker_color=self.color_palette[0]
))
fig.update_layout(
title_text="会议议题频率分析",
xaxis_title="出现频次",
yaxis_title="议题",
height=max(300, len(topics) * 30)
)
return fig.to_html(include_plotlyjs='cdn', div_id="topic_analysis_chart")
def generate_timeline_chart(self, analysis_result: Dict) -> str:
"""生成时间线图表"""
timeline_data = analysis_result.get('timeline', [])
if not timeline_data:
return self._create_empty_chart()
fig = go.Figure()
for i, event in enumerate(timeline_data):
fig.add_trace(go.Scatter(
x=[event['start_time'], event['end_time']],
y=[event['topic'], event['topic']],
mode='lines+markers',
name=event['topic'],
line=dict(width=10),
marker=dict(size=15)
))
fig.update_layout(
title_text="会议时间线",
xaxis_title="时间",
yaxis_title="议题",
showlegend=True,
height=400
)
return fig.to_html(include_plotlyjs='cdn', div_id="timeline_chart")
def generate_sentiment_analysis_chart(self, analysis_result: Dict) -> str:
"""生成情感分析图表"""
sentiment_data = analysis_result.get('sentiment', {})
if not sentiment_data:
return self._create_empty_chart()
labels = list(sentiment_data.keys())
values = list(sentiment_data.values())
fig = go.Figure(data=[go.Pie(
labels=labels,
values=values,
hole=.3
)])
fig.update_layout(
title_text="会议情感分析",
height=400
)
return fig.to_html(include_plotlyjs='cdn', div_id="sentiment_analysis_chart")
def _create_empty_chart(self) -> str:
"""创建空图表"""
fig = go.Figure()
fig.add_annotation(
text="暂无数据",
xref="paper", yref="paper",
x=0.5, y=0.5,
showarrow=False,
font=dict(size=20)
)
fig.update_layout(
height=300,
xaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
yaxis=dict(showgrid=False, zeroline=False, showticklabels=False)
)
return fig.to_html(include_plotlyjs='cdn', div_id="empty_chart")
4.2 自动图表修复功能
python
class ChartAutoFix:
def __init__(self):
self.common_issues = {
'data_overflow': self._fix_data_overflow,
'label_overlap': self._fix_label_overlap,
'color_contrast': self._fix_color_contrast,
'scale_issue': self._fix_scale_issue
}
def auto_fix_chart(self, chart_html: str, chart_type: str) -> str:
"""自动检测并修复图表问题"""
issues = self._detect_issues(chart_html, chart_type)
fixed_chart = chart_html
for issue in issues:
if issue in self.common_issues:
fixed_chart = self.common_issues[issue](fixed_chart, chart_type)
return fixed_chart
def _detect_issues(self, chart_html: str, chart_type: str) -> List[str]:
"""检测图表问题"""
issues = []
# 检测数据溢出问题
if self._has_data_overflow(chart_html):
issues.append('data_overflow')
# 检测标签重叠问题
if self._has_label_overlap(chart_html, chart_type):
issues.append('label_overlap')
# 检测颜色对比度问题
if self._has_color_contrast_issue(chart_html):
issues.append('color_contrast')
# 检测比例问题
if self._has_scale_issue(chart_html):
issues.append('scale_issue')
return issues
def _fix_data_overflow(self, chart_html: str, chart_type: str) -> str:
"""修复数据溢出问题"""
# 实现数据截断或比例调整逻辑
# 详细实现代码...
return fixed_chart
def _fix_label_overlap(self, chart_html: str, chart_type: str) -> str:
"""修复标签重叠问题"""
# 实现标签位置调整逻辑
# 详细实现代码...
return fixed_chart
5. 前端界面实现
5.1 主界面组件
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>AI智能会议助手</title>
<script src="https://cdn.plot.ly/plotly-latest.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
<style>
:root {
--primary-color: #4e79a7;
--secondary-color: #f28e2c;
--background-color: #f5f7fa;
--text-color: #333;
--border-color: #ddd;
}
body {
font-family: 'Microsoft YaHei', Arial, sans-serif;
margin: 0;
padding: 0;
background-color: var(--background-color);
color: var(--text-color);
}
.container {
max-width: 1200px;
margin: 0 auto;
padding: 20px;
}
.header {
background: linear-gradient(135deg, var(--primary-color), #2c3e50);
color: white;
padding: 20px 0;
text-align: center;
border-radius: 10px;
margin-bottom: 30px;
}
.upload-section {
background: white;
padding: 30px;
border-radius: 10px;
box-shadow: 0 4px 6px rgba(0,0,0,0.1);
margin-bottom: 30px;
}
.analysis-results {
display: grid;
grid-template-columns: 1fr 1fr;
gap: 20px;
margin-bottom: 30px;
}
.chart-container {
background: white;
padding: 20px;
border-radius: 10px;
box-shadow: 0 4px 6px rgba(0,0,0,0.1);
}
.minutes-preview {
background: white;
padding: 30px;
border-radius: 10px;
box-shadow: 0 4px 6px rgba(0,0,0,0.1);
margin-bottom: 30px;
}
.export-buttons {
display: flex;
gap: 15px;
justify-content: center;
margin-top: 20px;
}
.btn {
padding: 12px 24px;
border: none;
border-radius: 5px;
cursor: pointer;
font-size: 16px;
transition: all 0.3s ease;
}
.btn-primary {
background-color: var(--primary-color);
color: white;
}
.btn-secondary {
background-color: var(--secondary-color);
color: white;
}
.btn:hover {
transform: translateY(-2px);
box-shadow: 0 4px 8px rgba(0,0,0,0.2);
}
.loading {
display: none;
text-align: center;
padding: 20px;
}
.spinner {
border: 4px solid #f3f3f3;
border-top: 4px solid var(--primary-color);
border-radius: 50%;
width: 40px;
height: 40px;
animation: spin 2s linear infinite;
margin: 0 auto;
}
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
</style>
</head>
<body>
<div class="container">
<div class="header">
<h1>AI智能会议助手</h1>
<p>基于ModelEngine的智能会议纪要生成与分析系统</p>
</div>
<div class="upload-section">
<h2>上传会议录音</h2>
<div id="uploadArea">
<input type="file" id="audioFile" accept="audio/*" style="display: none;">
<div style="border: 2px dashed #ccc; padding: 40px; text-align: center; border-radius: 10px; cursor: pointer;"
onclick="document.getElementById('audioFile').click()">
<i style="font-size: 48px; color: #ccc;">🎤</i>
<p>点击上传会议录音文件,或拖拽文件到此处</p>
<p style="font-size: 12px; color: #888;">支持格式: MP3, WAV, M4A, 最大文件大小: 100MB</p>
</div>
</div>
<div class="export-buttons">
<button class="btn btn-primary" onclick="startAnalysis()">开始分析</button>
<button class="btn btn-secondary" onclick="startRealTimeRecording()">实时录音</button>
</div>
</div>
<div class="loading" id="loadingIndicator">
<div class="spinner"></div>
<p>正在分析会议内容,请稍候...</p>
</div>
<div id="analysisResults" style="display: none;">
<h2>会议分析结果</h2>
<div class="analysis-results">
<div class="chart-container" id="speakerChart"></div>
<div class="chart-container" id="topicChart"></div>
<div class="chart-container" id="timelineChart"></div>
<div class="chart-container" id="sentimentChart"></div>
</div>
<div class="minutes-preview">
<h2>会议纪要预览</h2>
<div id="minutesContent"></div>
<div class="export-buttons">
<button class="btn btn-primary" onclick="exportWord()">导出Word文档</button>
<button class="btn btn-primary" onclick="exportPDF()">导出PDF</button>
<button class="btn btn-secondary" onclick="exportCharts()">导出图表</button>
<button class="btn btn-secondary" onclick="shareMinutes()">分享纪要</button>
</div>
</div>
</div>
</div>
<script>
// 文件上传处理
document.getElementById('audioFile').addEventListener('change', function(e) {
const file = e.target.files[0];
if (file) {
// 验证文件类型和大小
if (!validateFile(file)) {
alert('文件格式不支持或文件过大');
return;
}
// 显示文件信息
displayFileInfo(file);
}
});
function validateFile(file) {
const allowedTypes = ['audio/mp3', 'audio/wav', 'audio/m4a', 'audio/x-m4a'];
const maxSize = 100 * 1024 * 1024; // 100MB
return allowedTypes.includes(file.type) && file.size <= maxSize;
}
function displayFileInfo(file) {
const uploadArea = document.getElementById('uploadArea');
uploadArea.innerHTML = `
<div style="text-align: center; padding: 20px;">
<div style="font-size: 48px;">✅</div>
<h3>${file.name}</h3>
<p>文件大小: ${(file.size / (1024 * 1024)).toFixed(2)} MB</p>
<button class="btn btn-secondary" onclick="changeFile()">更换文件</button>
</div>
`;
}
function changeFile() {
document.getElementById('audioFile').value = '';
location.reload();
}
// 开始分析
async function startAnalysis() {
const fileInput = document.getElementById('audioFile');
if (!fileInput.files[0]) {
alert('请先上传会议录音文件');
return;
}
// 显示加载指示器
document.getElementById('loadingIndicator').style.display = 'block';
try {
const formData = new FormData();
formData.append('audio', fileInput.files[0]);
const response = await fetch('/api/analyze-meeting', {
method: 'POST',
body: formData
});
if (!response.ok) {
throw new Error('分析失败');
}
const result = await response.json();
// 隐藏加载指示器
document.getElementById('loadingIndicator').style.display = 'none';
// 显示分析结果
displayAnalysisResults(result);
} catch (error) {
console.error('分析错误:', error);
document.getElementById('loadingIndicator').style.display = 'none';
alert('分析过程中出现错误,请重试');
}
}
function displayAnalysisResults(result) {
// 显示图表
document.getElementById('speakerChart').innerHTML = result.charts.speaker_analysis;
document.getElementById('topicChart').innerHTML = result.charts.topic_analysis;
document.getElementById('timelineChart').innerHTML = result.charts.timeline;
document.getElementById('sentimentChart').innerHTML = result.charts.sentiment_analysis;
// 显示会议纪要
document.getElementById('minutesContent').innerHTML =
formatMinutesContent(result.minutes);
// 显示结果区域
document.getElementById('analysisResults').style.display = 'block';
// 自动修复图表问题
autoFixCharts();
}
function formatMinutesContent(minutes) {
let html = '';
for (const [section, content] of Object.entries(minutes.content)) {
html += `<h3>${section}</h3>`;
html += `<div style="background: #f8f9fa; padding: 15px; border-radius: 5px; margin-bottom: 20px;">`;
html += `<pre style="white-space: pre-wrap; font-family: inherit;">${content}</pre>`;
html += `</div>`;
}
return html;
}
function autoFixCharts() {
// 调用图表自动修复功能
const chartContainers = document.querySelectorAll('.chart-container');
chartContainers.forEach(container => {
const chartId = container.querySelector('[id]').id;
fetch('/api/fix-chart', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
chart_html: container.innerHTML,
chart_type: chartId
})
})
.then(response => response.json())
.then(data => {
if (data.fixed_chart) {
container.innerHTML = data.fixed_chart;
}
});
});
}
// 导出功能
async function exportWord() {
try {
const response = await fetch('/api/export/word', {
method: 'POST'
});
const blob = await response.blob();
const url = window.URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = '会议纪要.docx';
document.body.appendChild(a);
a.click();
window.URL.revokeObjectURL(url);
document.body.removeChild(a);
} catch (error) {
console.error('导出Word失败:', error);
alert('导出失败,请重试');
}
}
async function exportPDF() {
try {
const response = await fetch('/api/export/pdf', {
method: 'POST'
});
const blob = await response.blob();
const url = window.URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = '会议纪要.pdf';
document.body.appendChild(a);
a.click();
window.URL.revokeObjectURL(url);
document.body.removeChild(a);
} catch (error) {
console.error('导出PDF失败:', error);
alert('导出失败,请重试');
}
}
async function exportCharts() {
try {
const response = await fetch('/api/export/charts', {
method: 'POST'
});
const blob = await response.blob();
const url = window.URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = '会议图表.zip';
document.body.appendChild(a);
a.click();
window.URL.revokeObjectURL(url);
document.body.removeChild(a);
} catch (error) {
console.error('导出图表失败:', error);
alert('导出失败,请重试');
}
}
function shareMinutes() {
// 实现分享功能
if (navigator.share) {
navigator.share({
title: '会议纪要',
text: '查看本次会议纪要',
url: window.location.href
})
.catch(error => console.log('分享失败:', error));
} else {
alert('分享功能在当前浏览器中不可用');
}
}
// 实时录音功能
function startRealTimeRecording() {
alert('实时录音功能即将推出,敬请期待!');
}
</script>
</body>
</html>
6. 后端API实现
6.1 主应用服务
python
from flask import Flask, request, jsonify, send_file
from flask_cors import CORS
import os
import uuid
from datetime import datetime
import json
app = Flask(__name__)
CORS(app)
# 初始化各个模块
audio_processor = AudioProcessor(model_engine_client)
text_analyzer = TextAnalysisAgent(model_engine_client)
minutes_generator = MeetingMinutesGenerator(model_engine_client)
visualization_engine = VisualizationEngine()
chart_fixer = ChartAutoFix()
@app.route('/api/analyze-meeting', methods=['POST'])
def analyze_meeting():
"""分析会议录音"""
try:
if 'audio' not in request.files:
return jsonify({'error': '未提供音频文件'}), 400
audio_file = request.files['audio']
# 保存临时文件
file_id = str(uuid.uuid4())
temp_path = f"/tmp/{file_id}_{audio_file.filename}"
audio_file.save(temp_path)
# 处理音频文件
transcription = audio_processor.transcribe_audio(temp_path)
if not transcription:
return jsonify({'error': '语音转文本失败'}), 500
# 分析文本内容
analysis_result = text_analyzer.analyze_meeting_content(transcription)
# 生成会议纪要
metadata = {
'meeting_time': datetime.now().isoformat(),
'location': '线上会议',
'participants': [speaker['name'] for speaker in analysis_result['speakers']],
'host': analysis_result['speakers'][0]['name'] if analysis_result['speakers'] else '未知'
}
minutes = minutes_generator.generate_minutes(analysis_result, metadata)
# 生成图表
charts = {
'speaker_analysis': visualization_engine.generate_speaker_analysis_chart(analysis_result),
'topic_analysis': visualization_engine.generate_topic_analysis_chart(analysis_result),
'timeline': visualization_engine.generate_timeline_chart(analysis_result),
'sentiment_analysis': visualization_engine.generate_sentiment_analysis_chart(analysis_result)
}
# 清理临时文件
os.remove(temp_path)
return jsonify({
'transcription': transcription,
'analysis': analysis_result,
'minutes': minutes,
'charts': charts
})
except Exception as e:
print(f"分析会议错误: {str(e)}")
return jsonify({'error': '内部服务器错误'}), 500
@app.route('/api/fix-chart', methods=['POST'])
def fix_chart():
"""修复图表问题"""
try:
data = request.json
chart_html = data.get('chart_html')
chart_type = data.get('chart_type')
fixed_chart = chart_fixer.auto_fix_chart(chart_html, chart_type)
return jsonify({
'fixed_chart': fixed_chart
})
except Exception as e:
print(f"修复图表错误: {str(e)}")
return jsonify({'error': '修复图表失败'}), 500
@app.route('/api/export/word', methods=['POST'])
def export_word():
"""导出Word文档"""
try:
# 实现Word导出逻辑
# 使用python-docx库生成Word文档
from docx import Document
from docx.shared import Inches
doc = Document()
# 添加标题
doc.add_heading('会议纪要', 0)
# 添加会议基本信息
doc.add_heading('会议基本信息', level=1)
# ... 添加具体内容
# 保存临时文件
temp_path = f"/tmp/meeting_minutes_{uuid.uuid4()}.docx"
doc.save(temp_path)
return send_file(temp_path, as_attachment=True, download_name='会议纪要.docx')
except Exception as e:
print(f"导出Word错误: {str(e)}")
return jsonify({'error': '导出失败'}), 500
@app.route('/api/export/pdf', methods=['POST'])
def export_pdf():
"""导出PDF文档"""
try:
# 实现PDF导出逻辑
# 使用reportlab或weasyprint库生成PDF
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
temp_path = f"/tmp/meeting_minutes_{uuid.uuid4()}.pdf"
c = canvas.Canvas(temp_path, pagesize=letter)
# 添加内容
c.drawString(100, 750, "会议纪要")
# ... 添加更多内容
c.save()
return send_file(temp_path, as_attachment=True, download_name='会议纪要.pdf')
except Exception as e:
print(f"导出PDF错误: {str(e)}")
return jsonify({'error': '导出失败'}), 500
@app.route('/api/export/charts', methods=['POST'])
def export_charts():
"""导出图表"""
try:
# 实现图表导出逻辑
import zipfile
from io import BytesIO
# 创建ZIP文件
zip_buffer = BytesIO()
with zipfile.ZipFile(zip_buffer, 'w') as zip_file:
# 添加各个图表文件
# ... 实现具体逻辑
zip_buffer.seek(0)
return send_file(
zip_buffer,
as_attachment=True,
download_name='会议图表.zip',
mimetype='application/zip'
)
except Exception as e:
print(f"导出图表错误: {str(e)}")
return jsonify({'error': '导出失败'}), 500
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5000)
7. Prompt工程示例
7.1 文本分析Prompt
python
text_analysis_prompt = """
你是一个专业的会议分析专家。请对以下会议转录文本进行深度分析:
会议文本:
{meeting_text}
请按照以下结构进行分析:
1. 发言人识别:
- 列出所有发言人和他们的发言次数
- 识别主要发言人和次要发言人
2. 议题提取:
- 提取会议讨论的主要议题
- 为每个议题分配权重(基于讨论时长和频率)
3. 决策识别:
- 找出所有明确的决策点
- 标注决策的责任人和时间节点
4. 行动项提取:
- 提取具体的行动项
- 明确负责人、截止时间和预期成果
5. 情感分析:
- 分析整体会议氛围
- 识别关键转折点和争议点
6. 时间线重建:
- 重建会议的时间线
- 标注重要事件的发生时间
请以JSON格式返回分析结果,确保结构清晰、内容准确。
"""
7.2 会议纪要生成Prompt
python
minutes_generation_prompt = """
作为专业的会议纪要撰写人,请根据以下会议分析结果生成规范的会议纪要:
会议基本信息:
- 会议时间:{meeting_time}
- 会议地点:{meeting_location}
- 参会人员:{participants}
- 主持人:{host}
会议分析结果:
{analysis_results}
请按照以下格式生成会议纪要:
# 会议纪要
## 会议基本信息
- 时间:[具体时间]
- 地点:[具体地点]
- 参会人员:[名单]
- 主持人:[姓名]
- 记录人:AI会议助手
## 会议议程
1. [第一个议题]
2. [第二个议题]
...
## 讨论要点
### [议题一]
- [发言人1]:[观点摘要]
- [发言人2]:[观点摘要]
...
### [议题二]
...
## 会议决议
1. [决议内容] - 负责人:[姓名] - 截止时间:[日期]
2. [决议内容] - 负责人:[姓名] - 截止时间:[日期]
...
## 行动项
| 任务描述 | 负责人 | 截止时间 | 状态 |
|---------|--------|----------|------|
| [任务1] | [负责人1] | [截止时间1] | 待开始 |
| [任务2] | [负责人2] | [截止时间2] | 进行中 |
...
## 下一步计划
- [短期计划]
- [中长期计划]
要求:
1. 语言专业、简洁、准确
2. 重点突出决策和行动项
3. 避免主观评价
4. 确保时间节点明确
"""
7.3 图表描述Prompt
python
chart_description_prompt = """
作为数据可视化专家,请为以下会议数据分析结果生成合适的图表描述:
数据分析结果:
{analysis_data}
图表要求:
1. 发言人分析图表:显示各发言人发言次数和占比
2. 议题分析图表:显示各议题讨论时长和重要性
3. 时间线图表:展示会议进程和关键节点
4. 情感分析图表:显示会议情感变化趋势
请为每个图表提供:
- 图表类型建议
- 数据字段映射
- 颜色方案建议
- 交互功能建议
以JSON格式返回图表配置。
"""
8. 系统部署与优化
8.1 性能优化策略
python
class PerformanceOptimizer:
def __init__(self):
self.cache = {}
self.batch_size = 10
self.parallel_workers = 4
def optimize_audio_processing(self, audio_data):
"""优化音频处理性能"""
# 实现音频处理优化策略
# 1. 流式处理大文件
# 2. 并行处理音频分段
# 3. 内存使用优化
pass
def optimize_text_analysis(self, text_data):
"""优化文本分析性能"""
# 实现文本分析优化策略
# 1. 分批处理长文本
# 2. 缓存中间结果
# 3. 模型推理优化
pass
def cache_optimization(self, key, data, ttl=3600):
"""缓存优化"""
# 实现智能缓存策略
self.cache[key] = {
'data': data,
'timestamp': datetime.now(),
'ttl': ttl
}
8.2 安全与隐私保护
python
class SecurityManager:
def __init__(self):
self.encryption_key = os.getenv('ENCRYPTION_KEY')
def encrypt_audio_data(self, audio_data):
"""加密音频数据"""
# 实现音频数据加密
pass
def anonymize_speaker_info(self, analysis_result):
"""匿名化发言人信息"""
# 实现发言人信息匿名化
anonymized_result = analysis_result.copy()
for speaker in anonymized_result.get('speakers', []):
speaker['name'] = self._generate_pseudonym(speaker['name'])
return anonymized_result
def _generate_pseudonym(self, real_name):
"""生成假名"""
# 实现假名生成逻辑
return f"参会者{hash(real_name) % 10000:04d}"
9. 测试与验证
9.1 单元测试
python
import unittest
from unittest.mock import Mock, patch
class TestMeetingAssistant(unittest.TestCase):
def setUp(self):
self.audio_processor = AudioProcessor(Mock())
self.text_analyzer = TextAnalysisAgent(Mock())
self.minutes_generator = MeetingMinutesGenerator(Mock())
def test_audio_preprocessing(self):
"""测试音频预处理"""
# 模拟音频数据
mock_audio = b"fake_audio_data"
with patch.object(self.audio_processor, '_noise_reduction') as mock_noise_reduction:
mock_noise_reduction.return_value = mock_audio
result = self.audio_processor.preprocess_audio(mock_audio)
self.assertIsNotNone(result)
mock_noise_reduction.assert_called_once()
def test_text_analysis(self):
"""测试文本分析"""
test_text = "张三:我建议下周完成原型设计。李四:同意,需要技术团队支持。"
with patch.object(self.text_analyzer.model_engine, 'analyze') as mock_analyze:
mock_analyze.return_value = {"enhanced_analysis": "test"}
result = self.text_analyzer.analyze_meeting_content(test_text)
self.assertIn('speakers', result)
self.assertIn('decisions', result)
self.assertIn('action_items', result)
def test_minutes_generation(self):
"""测试会议纪要生成"""
test_analysis = {
"speakers": [{"name": "张三", "mention_count": 5}],
"decisions": [{"content": "通过项目计划", "keyword": "通过"}],
"action_items": [{"assignee": "李四", "action": "完成", "description": "技术方案"}]
}
test_metadata = {
"meeting_time": "2024-01-01 10:00",
"location": "会议室A",
"participants": ["张三", "李四"],
"host": "张三"
}
with patch.object(self.minutes_generator.model_engine, 'generate') as mock_generate:
mock_generate.return_value = "# 测试纪要\n## 会议基本信息"
result = self.minutes_generator.generate_minutes(test_analysis, test_metadata)
self.assertIn('metadata', result)
self.assertIn('content', result)
if __name__ == '__main__':
unittest.main()
10. 结论与展望
10.1 项目总结
本项目成功构建了一个基于ModelEngine的智能会议纪要生成与分析系统,具备以下特点:
-
智能化处理:实现从音频到结构化会议纪要的端到端自动化处理
-
深度分析:提供发言人分析、议题提取、决策识别等多维度分析
-
可视化展示:生成丰富的交互式图表,直观展示会议数据
-
灵活导出:支持多种格式导出,便于分享和存档
-
性能优化:采用缓存、并行处理等技术确保系统响应速度
10.2 技术亮点
-
创新的Prompt工程设计,确保分析准确性
-
自动图表修复功能,提升可视化质量
-
模块化架构设计,便于扩展和维护
-
完善的错误处理和用户反馈机制
10.3 未来展望
-
功能扩展:
-
支持多语言会议处理
-
集成日历和任务管理系统的功能
-
添加实时协作编辑功能
-
-
技术优化:
-
引入更先进的语音识别模型
-
实现边缘计算支持
-
优化移动端体验
-
-
应用场景拓展:
-
教育领域的课堂记录
-
医疗领域的医患沟通记录
-
法律领域的庭审记录
-
本系统展示了ModelEngine在智能办公领域的强大应用潜力,为提升办公效率和工作质量提供了有效的技术解决方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)