告别复制粘贴:用 ModelEngine 可视化编排构建“每日行业情报自动化流水线”
引言
作为一名需要时刻关注行业动态的内容创作者,我每天早上的第一件事就是打开十几个标签页,搜索最新的行业新闻,然后手动复制、粘贴、汇总成简报。这个过程枯燥、重复且低效。
在接触了 ModelEngine 的可视化编排功能后,我意识到这个痛点完全可以被自动化解决。通过将复杂的工作流拆解为一个个功能节点,再像搭积木一样将它们连接起来,我成功构建了一个“全自动行业研报生成器”。今天就来分享一下这个工作流的搭建过程和心得。
一、 场景设计与工作流规划
我的目标是实现一个自动化的流水线:输入关键词 -> 自动联网搜索 -> 抓取核心内容 -> 大模型总结提炼 -> 输出结构化日报。
在 ModelEngine 的编排画布上,这个思路被清晰地转化为以下几个基础节点的连接:
- 开始节点 (Start Node):接收用户输入的关键词(例如:“新能源汽车电池技术”)。
- 搜索工具节点 (Search Tool Node):利用内置的搜索插件,根据关键词获取最新的网页链接列表。
- 网络爬虫节点 (Web Scraper Node):访问搜索到的链接,提取网页正文内容。
- 大模型节点 (LLM Node):核心大脑,负责阅读爬取的内容,并按要求写成简报。
- 结束节点 (End Node):输出最终结果。
二、 核心搭建过程:可视化节点的魅力
1. 像画图一样搭建骨架
ModelEngine 的画布操作非常直观。我从左侧的组件栏中拖拽出所需的节点。最让我感到舒适的是节点之间的连线体验,数据的流向一目了然。
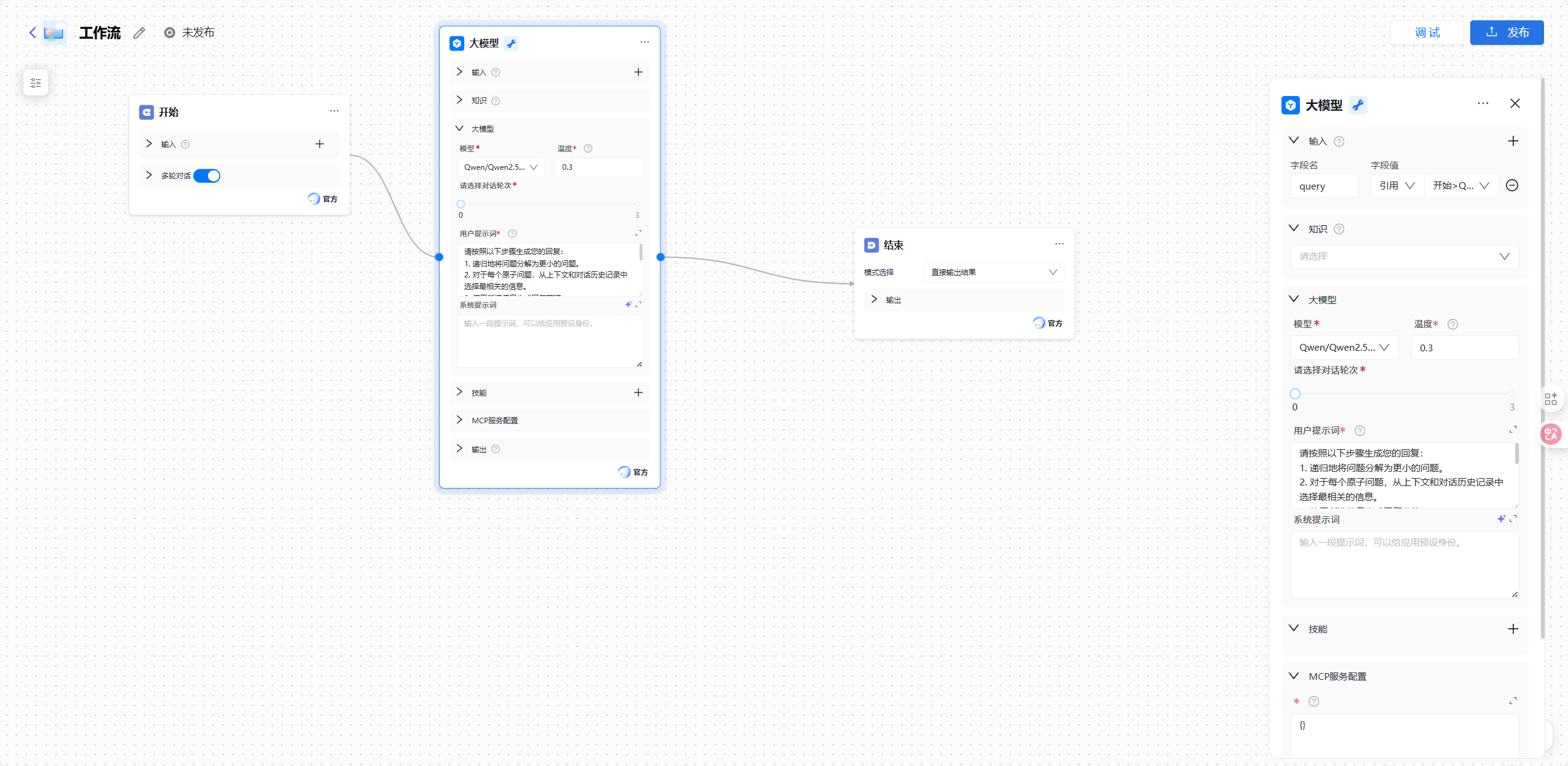
2. 配置核心大脑:LLM 节点
工作流中最关键的是 LLM 节点的配置。我们需要告诉大模型如何处理上游节点传过来的杂乱数据。在 LLM 节点的提示词编辑区,我使用了变量引用功能。
以下是我在 LLM 节点中配置的 Prompt 代码片段:
您是一位资深的行业分析师。请阅读以下通过网络搜索获取的多篇关于“{{start_node.query_keyword}}”的文章内容。
输入数据来源:
{{scraper_node.scraped_content}}
任务要求:
1. 请提取上述内容中最重要的 3-5 条行业动态。
2. 过滤掉广告和无关信息。
3. 将结果汇总成一篇结构清晰的早报,包含“核心观点”和“详细摘要”两个部分。
4. 输出格式采用 Markdown。
通过 {{node_name.variable}} 这种简单的语法,我轻松地将爬虫节点抓取的数据喂给了大模型。
三、 工作流开发与调试:像程序员一样 Debug
可视化编排看起来简单,但复杂的流程难免会出错。ModelEngine 提供的调试模式是我觉得最专业的功能之一。
在搭建完初步流程后,我点击了“运行”进行测试。第一次运行并不顺利,大模型输出的内容非常少。
这时,我打开了调试面板。我能够清晰地查看每一个节点的输入和输出数据。
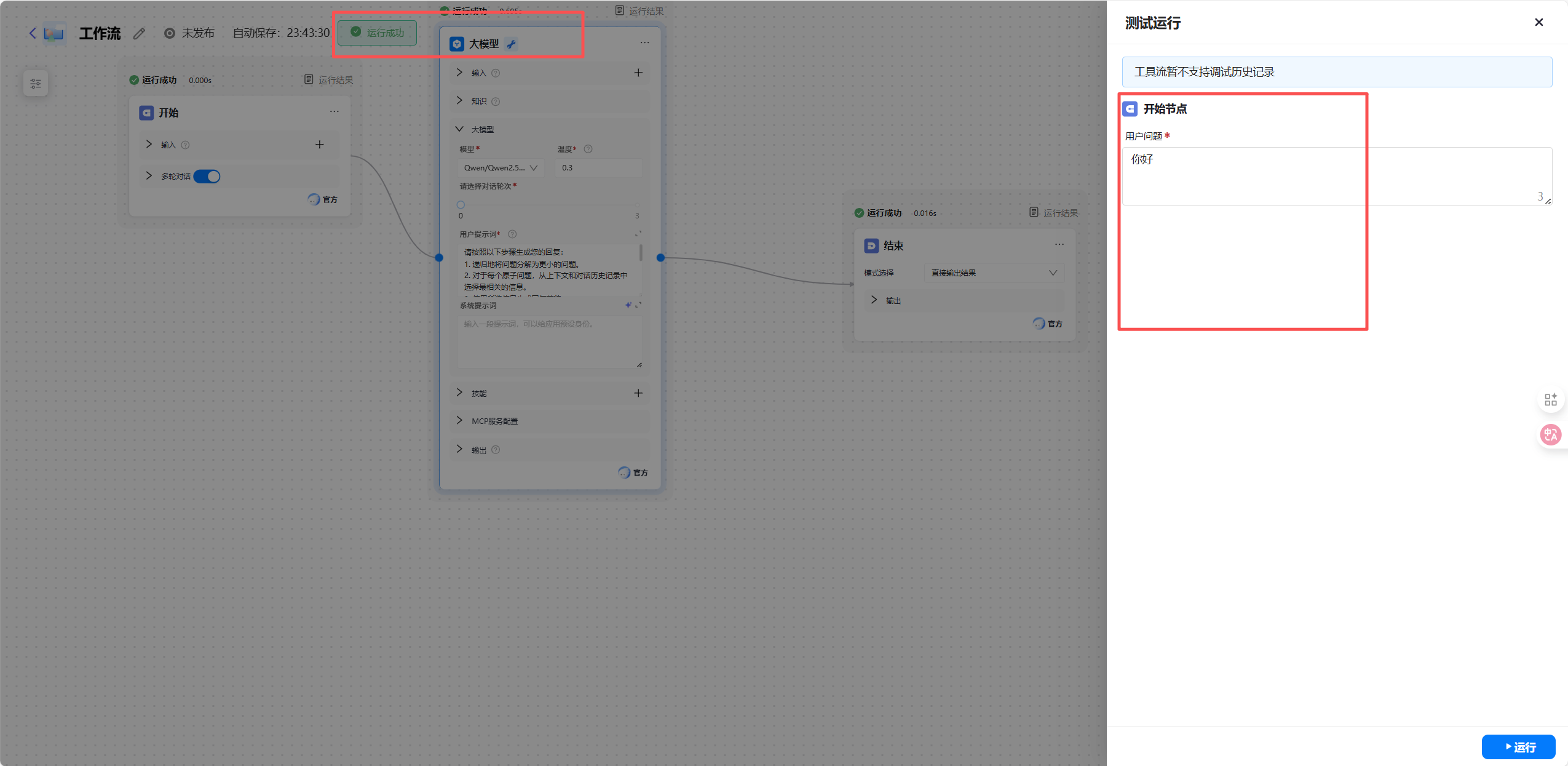
通过调试面板,我很快发现问题出在爬虫节点:它抓取的内容包含了太多网页侧边栏的无效信息,导致大模型无法抓到重点。定位问题后,我调整了爬虫节点的配置参数(或在 LLM prompt 中增加了更强的过滤指令),再次运行,问题解决。这种可视化的 Debug 体验,比在一堆代码日志里找问题要高效得多。
四、 成果展示与心得
现在,我只需要在对话框输入一个关键词,等待 30 秒,一篇排版精美的行业简报就会自动呈现在我面前,效率提升了至少十倍。
ModelEngine 的可视化编排功能,不仅降低了开发 AI 应用的门槛,更重要的是它提供了一种清晰的工程化思维方式。它让复杂的业务逻辑变得可视、可控、可调试。对于希望构建复杂 AI 工作流的开发者来说,这是一个不可多得的利器。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)