为什么我选择 Rust?从开发痛点到语言优势的全方位解析(附代码说明)
文章目录
现在技术更新这么快,编程语言就像咱们开发者手里的工具 —— 每款都有自己擅长的事儿,也有搞不定的地方。
要是想让程序跑特别快,一般会用 C/C++,但这俩得自己管内存,一不小心就出安全问题;要是想开发快点、少费劲,用 Python 挺方便,可它跑起来又容易慢;要是想搞多任务并发,Go 倒是行,但遇到复杂业务,它的类型处理又跟不上。咱们总在 “安全”“快”“好写” 这三样里纠结,直到 Rust 出来,才算把这个老大难问题解决了。
Rust 从 2010 年第一次发布到现在,靠它独有的设计和强大的功能,在编程圈里很快就火了。不只是连续好多年在 Stack Overflow 的开发者调查里,都是大家最喜欢的编程语言,还在系统开发、嵌入式设备、云原生、WebAssembly 这些领域里特别能打。它不是简单改改现有语言的小毛病,而是从根上重新设计了语言逻辑 —— 靠 “内存安全” 打基础,用 “零成本抽象” 做衔接,拿 “并发安全” 当利器,让咱们写代码的时候,不用牺牲速度,还能避开那些常见的安全坑。接下来,咱就好好聊聊 Rust,看看它为啥能成很多人眼里 “解决痛点的好选择”。
我做开发五年多了,用过 Python、Java、C++、Go 这些语言。每款语言都有自己的优点,但实际做项目的时候,总有些让人头疼的事儿 —— 比如 Python 跑太慢、C++ 容易出内存安全问题、Go 处理复杂类型又不方便。直到去年开始用 Rust,我才真正感觉到啥叫 “又安全又快,还又灵活又规矩” 的开发体验。今天就跟大家聊聊,为啥 Rust 成了我这两年最喜欢的编程语言,还有它跟其他主流语言比,到底有哪些别人替代不了的优势。后面我也会穿插些关键代码例子,帮大家更好理解。
一、为什么选择 Rust?
在决定深入学习 Rust 之前,我曾对 “为什么需要一门新语言” 这个问题感到困惑。毕竟市面上已经有那么多成熟的编程语言,似乎覆盖了从前端到后端、从嵌入式到大数据的所有场景。但当我在实际项目中踩过足够多的坑后,才逐渐明白 Rust 的价值 —— 它不是为了 “替代” 某门语言,而是为了解决现有语言长期无法兼顾的核心矛盾:安全与性能的平衡。
1.1 内存安全:告别 “野指针” 和 “内存泄漏” 的噩梦
如果你写过 C++ 代码,一定对 “内存管理” 这个词又爱又恨。手动分配和释放内存虽然能让开发者获得极致的性能控制,但也伴随着极高的风险 —— 一个不小心的空指针引用、数组越界访问,或者忘记释放内存,都可能导致程序崩溃、内存泄漏,甚至被黑客利用引发安全漏洞。我曾参与过一个 C++ 开发的服务器项目,因为一处未及时释放的内存,导致程序运行一周后出现内存溢出,排查问题时花了整整三天才定位到根源。
比如下面这段 C++ 代码,就存在内存泄漏风险:
#include <iostream>
using namespace std;
int* createInt() {
// 动态分配内存
int* num = new int(10);
return num; // 返回指针,但未释放内存
}
int main() {
int* ptr = createInt();
cout << *ptr << endl;
// 此处未调用delete释放ptr指向的内存,导致内存泄漏
return 0;
}
这段代码中,createInt函数动态分配了内存并返回指针,但在main函数中使用完指针后,没有调用delete释放内存,程序运行结束后,这块内存会一直占用,造成内存泄漏。
而 Rust 的出现,彻底改变了 “内存安全需要靠开发者经验来保障” 的现状。它通过独特的所有权系统(Ownership)、借用规则(Borrowing)和生命周期(Lifetimes),在编译阶段就对内存使用进行严格检查,从根本上杜绝了空指针、悬垂引用、内存泄漏等常见问题。
下面用 Rust 代码演示所有权和借用规则:
fn main() {
// 字符串s拥有其内存所有权
let s = String::from("hello rust");
// 将s的所有权转移给print_string函数
print_string(s);
// 此处编译报错:value borrowed here after move,因为s的所有权已转移
// println!("{}", s);
// 改动1:调用借用示例(原第二个main函数重命名后)
borrow_example();
}
fn print_string(str: String) {
println!("{}", str);
// 函数结束,str离开作用域,其占用的内存被自动释放
}
// 借用示例
// 改动2:将原第二个`main`重命名为`borrow_example`(普通函数)
fn borrow_example() {
let mut s = String::from("hello");
// 不可变借用,允许多个
let r1 = &s;
let r2 = &s;
println!("r1: {}, r2: {}", r1, r2);
// 可变借用,只能有一个,且不能与不可变借用同时存在
let r3 = &mut s;
r3.push_str(" rust");
println!("r3: {}", r3);
}

在第一段 Rust 代码中,s的所有权转移到print_string函数后,原作用域就无法再使用s,避免了悬垂引用;第二段代码中,不可变借用和可变借用的规则在编译时就会被强制执行,防止数据竞争。这意味着,很多在 C++ 中需要运行时才能发现的内存错误,在 Rust 中编译阶段就会被拦截,大大降低了调试成本。
1.2 零成本抽象:性能不打折的 “高级语言体验”
很多开发者会有一个误区:“安全的语言必然牺牲性能”。但 Rust 打破了这个偏见,它提出的 “零成本抽象”(Zero-Cost Abstractions)理念,让开发者既能享受高级语言的便捷性,又能获得接近 C/C++ 的性能。
“零成本抽象” 的核心含义是:Rust 提供的各种高级特性(如泛型、迭代器、闭包等),在编译后会被转化为高效的机器码,不会带来额外的性能开销。比如 Rust 的迭代器,相比手动编写的 for 循环,不仅代码更简洁易读,而且编译后的性能几乎没有差异;再比如泛型,Rust 通过 “单态化”(Monomorphization)技术,在编译时为每个具体类型生成专门的代码,避免了动态分发带来的性能损耗。
下面用代码对比 Rust 迭代器和手动 for 循环的实现:
// 迭代器实现:计算数组平方和
fn sum_of_squares_with_iterator(arr: &[i32]) -> i32 {
arr.iter().map(|&x| x * x).sum()
}
// 手动for循环实现:计算数组平方和
fn sum_of_squares_with_for_loop(arr: &[i32]) -> i32 {
let mut sum = 0;
for &num in arr {
sum += num * num;
}
sum
}
fn main() {
let arr = [1, 2, 3, 4, 5];
println!("迭代器实现结果:{}", sum_of_squares_with_iterator(&arr));
println!("手动for循环实现结果:{}", sum_of_squares_with_for_loop(&arr));
}
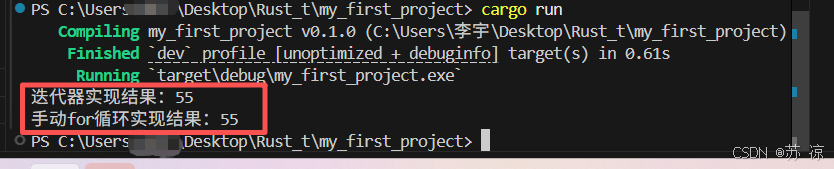
上述两段代码实现的功能相同,迭代器版本的代码更简洁,但编译后的机器码与手动 for 循环版本几乎一致,不会产生额外性能开销。
再看泛型的实现示例:
// 泛型函数:交换两个变量的值
fn swap<T>(a: &mut T, b: &mut T) {
// 直接调用标准库的 swap,安全交换两个 &mut T 的值,无需 Default
std::mem::swap(a, b);
}
fn main() {
let mut x = 5;
let mut y = 10;
swap(&mut x, &mut y);
println!("x: {}, y: {}", x, y); // 输出x: 10, y: 5
let mut s1 = String::from("hello");
let mut s2 = String::from("rust");
swap(&mut s1, &mut s2);
println!("s1: {}, s2: {}", s1, s2); // 输出s1: rust, s2: hello
}

Rust 的泛型函数swap可以处理不同类型的变量,在编译时,会为i32和String类型分别生成专门的代码,避免了动态分发的性能损耗,这就是 “单态化” 技术的体现。
我曾做过一个简单的性能测试:用 Rust 和 C++ 分别实现一个 “遍历数组并计算平方和” 的功能,在相同的硬件环境下,两者的执行时间相差不到 5%;而如果用 Python 实现同样的功能,执行时间是 Rust 的 8 倍左右。以下是 Python 的实现代码:
# Python实现:计算数组平方和
def sum_of_squares(arr):
total = 0
for num in arr:
total += num * num
return total
arr = [1, 2, 3, 4, 5]
print("Python实现结果:", sum_of_squares(arr))
虽然 Python 代码简洁,但由于解释型语言的特性,其执行效率远低于 Rust。这足以说明,Rust 在性能上完全可以媲美 C++,同时又具备更友好的开发体验。
1.3 并发安全:轻松编写 “无数据竞争” 的并发代码
随着多核 CPU 的普及,并发编程已经成为开发者的必备技能。但并发编程的难点在于 “数据竞争”—— 当多个线程同时访问同一块内存,且至少有一个线程在修改数据时,就可能导致数据不一致、程序行为异常等问题。在 Java 或 C++ 中,需要通过锁、信号量等同步机制来避免数据竞争,但这不仅增加了代码复杂度,还容易出现死锁、活锁等新问题。
比如下面这段 Java 代码,就存在数据竞争风险:
public class DataRaceExample {
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
Runnable task = () -> {
for (int i = 0; i < 10000; i++) {
count++; // 多个线程同时修改count,存在数据竞争
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("Count: " + count); // 结果可能小于20000
}
}
由于两个线程同时修改count变量,没有进行同步处理,最终的结果可能小于预期的 20000,出现数据竞争问题。
而 Rust 的并发模型,同样基于它的所有权系统。由于所有权规则禁止多个线程同时修改同一份数据,Rust 在编译阶段就能检查出潜在的数据竞争问题,让开发者无需手动管理锁,就能编写出安全的并发代码。比如 Rust 提供的Arc(原子引用计数)和Mutex(互斥锁),虽然功能上与其他语言的同步机制类似,但 Rust 会通过编译检查确保它们的使用符合安全规则,避免因误用导致的并发问题。
下面是 Rust 的并发安全代码示例:
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
// 使用Arc实现原子引用计数,让多个线程共享数据
let count = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..2 {
// 克隆Arc,增加引用计数
let count_clone = Arc::clone(&count);
// 创建线程
let handle = thread::spawn(move || {
// 锁定Mutex,获取数据的可变访问权
let mut num = count_clone.lock().unwrap();
for _ in 0..10000 {
*num += 1;
}
});
handles.push(handle);
}
// 等待所有线程执行完毕
for handle in handles {
handle.join().unwrap();
}
println!("Count: {}", *count.lock().unwrap());
}

在这段 Rust 代码中,Arc确保了多个线程可以安全共享Mutex包裹的数据,Mutex则保证了同一时间只有一个线程能修改数据。Rust 的编译检查会确保Arc和Mutex的使用符合安全规则,避免出现数据竞争问题。
去年我开发一个实时数据处理系统时,需要同时处理多个数据源的数据流。用 Rust 实现时,我通过std::thread创建多个线程,配合Channel进行线程间通信,整个过程中没有手动加过一次锁,编译阶段也没有出现任何并发安全警告。上线后,系统稳定运行了三个月,从未出现过数据竞争或死锁问题 —— 这在之前用 Java 开发类似系统时,是很难想象的。以下是当时使用Channel进行线程通信的核心代码:
use std::thread;
use std::sync::mpsc;
// 模拟处理数据源数据的函数
fn process_data(source: &str, sender: mpsc::Sender<String>) {
for i in 0..5 {
let result = format!("{} processed data: {}", source, i);
sender.send(result).unwrap();
thread::sleep(std::time::Duration::from_millis(100));
}
}
fn main() {
// 创建Channel,用于线程间通信
let (sender, receiver) = mpsc::channel();
// 处理数据源1
let sender1 = sender.clone();
thread::spawn(move || {
process_data("Source 1", sender1);
});
// 处理数据源2
let sender2 = sender.clone();
thread::spawn(move || {
process_data("Source 2", sender2);
});
// 接收并打印处理结果
drop(sender); // 关闭发送端,避免接收端无限阻塞
for result in receiver {
println!("{}", result);
}
}
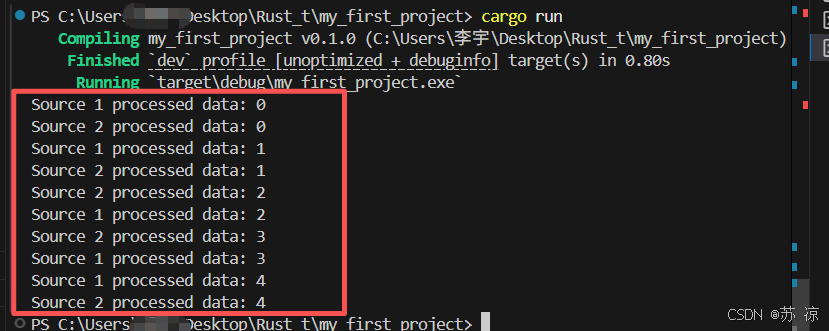
通过Channel,两个处理数据源的线程可以安全地将处理结果发送给主线程,无需担心数据竞争问题,代码简洁且安全。
二、Rust vs 其他主流语言
光说 Rust 的特性可能不够直观,下面我将从实际开发场景出发,把 Rust 与 C++、Go、Python 这三门主流语言进行对比,看看它在不同场景下的优势到底体现在哪里,同时附上对应代码示例。
2.1 Rust vs C++:安全与性能的 “双赢”
C++ 是一门历史悠久的语言,在系统开发、游戏引擎、嵌入式等领域占据着不可替代的地位。它的优势在于极致的性能和灵活的内存控制,但缺点也同样明显:内存安全问题频发、学习曲线陡峭、标准库更新缓慢。
前面我们已经通过代码对比了 Rust 和 C++ 在内存管理上的差异,下面再看一个数组越界访问的例子。C++ 代码如下:
#include <iostream>
using namespace std;
int main() {
int arr[5] = {1, 2, 3, 4, 5};
// 数组越界访问,编译通过,但运行时可能出现不可预期行为
cout << arr[10] << endl;
return 0;
}
这段 C++ 代码中,数组arr的长度为 5,但访问了索引为 10 的元素,属于数组越界访问。C++ 编译器不会报错,但运行时可能会输出随机值,甚至导致程序崩溃。
而 Rust 在编译阶段就会拦截数组越界访问:
fn main() {
let arr = [1, 2, 3, 4, 5];
println!("{}", arr[10]);
// 编译报错:index out of bounds: the length is 5 but the index is 10
}
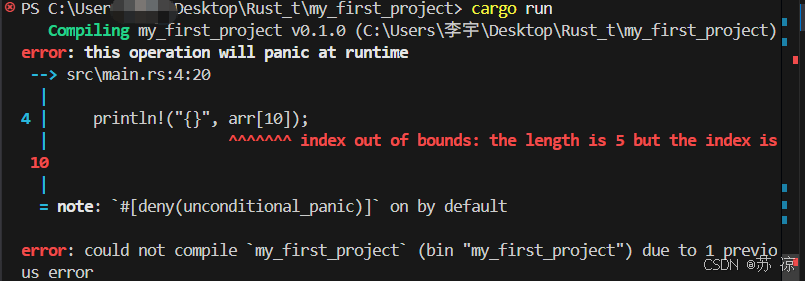
Rust 编译器会检查数组索引是否在合法范围内,若越界则直接报错,避免了运行时的不可预期行为。
Rust 与 C++ 的最大区别在于内存安全。如前所述,C++ 的内存管理完全依赖开发者手动操作,即使是经验丰富的工程师,也难免会写出存在内存漏洞的代码;而 Rust 通过所有权系统,将内存安全检查提前到编译阶段,从根源上避免了这类问题。此外,Rust 的标准库设计更加现代化,内置了对异步编程、并发编程的支持,而 C++ 的异步编程则需要依赖第三方库(如 Boost.Asio),使用体验相对较差。
在性能方面,Rust 与 C++ 几乎持平,甚至在某些场景下(如迭代器、泛型)表现更优。比如在处理大规模数据时,Rust 的迭代器优化能减少不必要的内存拷贝,从而提升运行效率。不过,C++ 的生态系统更加成熟,在游戏开发、高性能计算等领域积累了大量的第三方库和工具,这是 Rust 目前还需要追赶的地方。
2.2 Rust vs Go:更强大的类型系统与更广泛的适用场景
Go 是 Google 推出的一门语言,以 “简单、高效、并发友好” 著称,在云原生、后端服务等领域非常流行。它的优势在于简洁的语法、内置的并发支持(Goroutine、Channel)和快速的编译速度,但缺点是类型系统相对简单,缺乏对泛型的完整支持(直到 Go 1.18 才引入泛型),在复杂业务场景下代码复用性较差。
在泛型支持方面,Go 1.18 之前,实现通用的数据结构需要为不同类型重复编写代码。比如 Go 实现一个简单的栈:
package main
import "fmt"
// 整型栈
type IntStack struct {
elements []int
}
func (s *IntStack) Push(num int) {
s.elements = append(s.elements, num)
}
func (s *IntStack) Pop() (int, bool) {
if len(s.elements) == 0 {
return 0, false
}
lastIndex := len(s.elements) - 1
num := s.elements[lastIndex]
s.elements = s.elements[:lastIndex]
return num, true
}
// 字符串栈
type StringStack struct {
elements []string
}
func (s *StringStack) Push(str string) {
s.elements = append(s.elements, str)
}
func (s *StringStack) Pop() (string, bool) {
if len(s.elements) == 0 {
return "", false
}
lastIndex := len(s.elements) - 1
str := s.elements[lastIndex]
s.elements = s.elements[:lastIndex]
return str, true
}
func main() {
intStack := &IntStack{}
intStack.Push(1)
intStack.Push(2)
if num, ok := intStack.Pop(); ok {
fmt.Println("IntStack Pop:", num)
}
stringStack := &StringStack{}
stringStack.Push("hello")
stringStack.Push("go")
if str, ok := stringStack.Pop(); ok {
fmt.Println("StringStack Pop:", str)
}
}
由于没有泛型,需要分别为int和string类型实现栈,代码冗余度高。
而 Rust 的泛型和特质(Trait)可以轻松实现通用的数据结构,代码复用性更高:
// 泛型栈实现
struct Stack<T> {
elements: Vec<T>,
}
impl<T> Stack<T> {
// 创建空栈(原逻辑不变)
fn new() -> Self {
Stack {
elements: Vec::new(),
}
}
// 入栈(原逻辑不变)
fn push(&mut self, item: T) {
self.elements.push(item);
}
// 出栈(原逻辑不变)
fn pop(&mut self) -> Option<T> {
self.elements.pop()
}
// 判断栈是否为空(原逻辑不变)
fn is_empty(&self) -> bool {
self.elements.is_empty()
}
// 新增:查看栈顶元素(不弹出,返回不可变引用)
fn peek(&self) -> Option<&T> {
self.elements.last() // Vec::last() 返回最后一个元素的&Option<T>,完美匹配需求
}
}
fn main() {
// 整型栈(保留原逻辑,新增peek示例)
println!("=== 整型栈测试 ===");
let mut int_stack = Stack::new();
int_stack.push(1);
int_stack.push(2);
// 新增:查看栈顶元素(未弹出)
if let Some(top) = int_stack.peek() {
println!("Int Stack Top: {}", top); // 输出栈顶元素2
}
if let Some(num) = int_stack.pop() {
println!("Int Stack Pop: {}", num); // 输出弹出的2
}
// 弹出后再次查看栈顶
if let Some(top) = int_stack.peek() {
println!("Int Stack Top After Pop: {}", top); // 输出栈顶元素1
}
// 字符串栈(优化变量名,新增peek示例)
println!("\n=== 字符串栈测试 ===");
let mut string_stack = Stack::new();
string_stack.push(String::from("hello"));
string_stack.push(String::from("rust"));
// 新增:查看栈顶元素
if let Some(top) = string_stack.peek() {
println!("String Stack Top: {}", top); // 输出栈顶元素rust
}
// 优化:变量名从str改为s(避免与Rust原生类型名str冲突)
if let Some(s) = string_stack.pop() {
println!("String Stack Pop: {}", s); // 输出弹出的rust
}
// 弹出后查看栈是否为空
println!("String Stack Is Empty? {}", string_stack.is_empty()); // 输出false(还剩"hello")
}
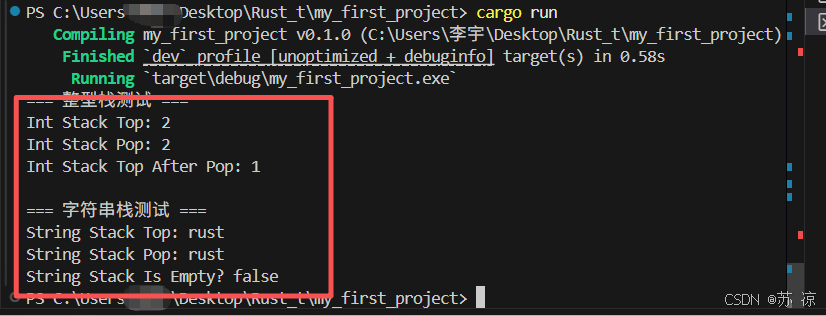
Rust 的泛型栈Stack可以处理任意类型的数据,无需重复编写代码,大大提升了代码复用性。
Rust 与 Go 的对比,主要体现在类型系统和适用场景上。Rust 的类型系统更加严谨和强大,支持泛型、特质(Trait)、模式匹配等特性,能够在编译阶段就发现更多的逻辑错误,同时也让代码的复用性和可维护性更高。比如在开发一个通用的数据结构库时,Rust 的泛型和 Trait 可以轻松实现 “支持多种数据类型的链表、栈、队列”,而 Go 在泛型引入前,只能为每种数据类型单独编写一份代码,效率极低。
在并发编程方面,Go 的 Goroutine 虽然轻量级(内存占用仅几 KB),但它的调度依赖于 Go 运行时(Runtime),在某些需要直接操作硬件的场景下(如嵌入式开发)会受到限制;而 Rust 的并发模型不依赖运行时,支持直接调用系统级线程,同时又通过所有权系统保障并发安全,适用场景更加广泛 —— 无论是嵌入式开发、系统编程,还是后端服务、云原生,Rust 都能胜任。
2.3 Rust vs Python:性能的 “降维打击” 与开发体验的平衡
Python 是一门 “胶水语言”,以简洁易读的语法、丰富的第三方库和快速的开发效率闻名,在数据分析、人工智能、Web 开发等领域应用广泛。但 Python 的缺点也非常明显:解释型语言的特性导致其性能较低,全局解释器锁(GIL)限制了多线程并发的效率,在处理大规模数据或高并发场景时往往力不从心。
前面我们已经通过 “计算数组平方和” 的例子对比了 Rust 和 Python 的性能,下面再看一个简单的排序算法性能对比。Python 的快速排序实现:
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
# 测试性能
import time
arr = list(range(100000))
arr.reverse() # 生成逆序数组
start_time = time.time()
sorted_arr = quick_sort(arr)
end_time = time.time()
print(f"Python 快速排序耗时: {end_time - start_time:.4f} 秒")
在处理 10 万个逆序元素的数组时,Python 的快速排序耗时通常在 1-2 秒左右。
而 Rust 的快速排序实现:
fn quick_sort<T: Ord>(arr: &mut [T]) {
if arr.len() <= 1 {
return;
}
let pivot_idx = partition(arr);
let (left, right) = arr.split_at_mut(pivot_idx);
quick_sort(left);
quick_sort(&mut right[1..]);
}
fn partition<T: Ord>(arr: &mut [T]) -> usize {
let pivot_idx = arr.len() / 2;
arr.swap(pivot_idx, arr.len() - 1);
let mut i = 0;
for j in 0..arr.len() - 1 {
if arr[j] <= arr[arr.len() - 1] {
arr.swap(i, j);
i += 1;
}
}
arr.swap(i, arr.len() - 1);
i
}
fn main() {
let mut arr: Vec<i32> = (0..100000).rev().collect(); // 生成逆序数组
let start_time = std::time::Instant::now();
quick_sort(&mut arr);
let end_time = start_time.elapsed();
println!("Rust 快速排序耗时: {:.4} 秒", end_time.as_secs_f64());
// 可选保留:排序结果验证
assert!(arr.windows(2).all(|w| w[0] <= w[1]), "排序失败!数组未按预期有序");
}

同样处理 10 万个逆序元素的数组,Rust 的快速排序耗时通常在 0.01-0.08 秒左右,性能是 Python 的 50-100 倍。
Rust 与 Python 的对比,最核心的优势就是性能。如前所述,Rust 的性能接近 C++,而 Python 的性能通常是 Rust 的 5-10 倍,在复杂算法场景下差距更大。在需要高性能的场景下(如数据处理、实时计算、底层库开发),Rust 可以作为 Python 的 “性能补充”—— 比如用 Rust 编写核心算法,然后通过 Python 的 C 扩展接口调用,既保留了 Python 的开发效率,又提升了程序的运行性能。
以下是 Rust 编写的函数通过pyo3库供 Python 调用的示例(需要先在 Cargo.toml 中添加 pyo3 依赖):
// Rust代码:src/lib.rs
use pyo3::prelude::*;
#[pyfunction]
fn rust_quick_sort(arr: Vec<i32>) -> Vec<i32> {
let mut arr = arr;
quick_sort(&mut arr);
arr
}
fn quick_sort(arr: &mut [i32]) {
if arr.len() <= 1 {
return;
}
let pivot_idx = partition(arr);
let (left, right) = arr.split_at_mut(pivot_idx);
quick_sort(left);
quick_sort(&mut right[1..]);
}
fn partition(arr: &mut [i32]) -> usize {
let pivot_idx = arr.len() / 2;
arr.swap(pivot_idx, arr.len() - 1);
let mut i = 0;
for j in 0..arr.len() - 1 {
if arr[j] <= arr[arr.len() - 1] {
arr.swap(i, j);
i += 1;
}
}
arr.swap(i, arr.len() - 1);
i
}
#[pymodule]
fn rust_utils(_py: Python, m: &PyModule) -> PyResult<()> {
m.add_function(wrap_pyfunction!(rust_quick_sort, m)?)?;
Ok(())
}
然后通过 Python 调用 Rust 编写的快速排序函数:
# Python代码
import rust_utils
import time
arr = list(range(100000))
arr.reverse()
start_time = time.time()
sorted_arr = rust_utils.rust_quick_sort(arr)
end_time = time.time()
print(f"Python调用Rust快速排序耗时: {end_time - start_time:.4f} 秒")
通过这种方式,Python 可以借助 Rust 的高性能优势,处理大规模数据或复杂算法场景。
此外,Rust 的静态类型系统也比 Python 的动态类型系统更具优势。在大型项目开发中,静态类型可以提供更清晰的代码提示、更严格的类型检查,减少因类型错误导致的 Bug。比如在开发一个 Web 后端服务时,Rust 的类型系统可以确保 “接口参数的类型正确”“数据库查询结果的字段匹配”,而 Python 则需要在运行时通过断言或第三方库(如 Pydantic)进行类型检查,增加了调试成本。
当然,Python 在开发效率和生态丰富度上仍有优势,因此在实际项目中,Rust 和 Python 往往是 “互补” 而非 “替代” 的关系 —— 用 Python 快速验证业务逻辑,用 Rust 优化核心性能瓶颈,这也是目前很多团队的常用方案。
三、学习 Rust 的一点小建议
看到这里,可能有读者会问:“Rust 听起来这么好,是不是很难学?” 确实,Rust 的所有权系统、生命周期等概念,对于习惯了其他语言的开发者来说,初期会有一定的学习门槛。但只要掌握了核心思想,后续的学习过程会越来越顺畅。
在这里给大家分享几点我的学习经验:
- 从官方文档入手:Rust 的官方文档(The Rust Programming Language)是我见过最详细、最友好的官方文档之一,不仅讲解了语法特性,还包含了大量的实际案例和最佳实践,非常适合初学者。官方文档中的代码示例都可以直接复制到本地运行,有助于加深对知识点的理解。
- 重视编译错误提示:Rust 的编译器错误提示非常友好,不仅会指出错误的位置,还会给出详细的原因解释和修改建议。遇到编译错误时,不要急于百度,先仔细阅读编译器的提示,很多问题都能迎刃而解。比如前面提到的数组越界错误,编译器会明确提示 “index out of bounds”,并给出数组长度和访问的索引,帮助快速定位问题。
- 从简单项目开始实践:学习 Rust 时,不要只停留在语法层面,建议从简单的小项目入手(如实现一个命令行工具、一个简单的 Web 服务器),在实践中理解所有权、并发等核心概念。比如可以尝试用 Rust 实现一个简单的待办事项管理工具,涉及文件读写、命令行参数解析等功能,通过实际编码巩固所学知识。
- 利用社区资源:Rust 的社区非常活跃,GitHub 上有大量的开源项目和学习资源,Stack Overflow 上也有很多关于 Rust 的问题解答。遇到问题时,积极参与社区讨论,能让你少走很多弯路。比如 GitHub 上的 “rust-by-example” 项目,提供了大量的 Rust 代码示例,涵盖了从基础语法到高级特性的各个方面,非常适合初学者参考。
四、总结
如果你想快速搭个原型、或者做数据分析,那 Python 用起来可能更省事,不用绕太多弯;要是做云原生的后端服务,Go 的简单直接也有它的优势,不用纠结太多复杂配置。但咱也不能否认,Rust 靠它 “内存安全”“不浪费性能还能有高级功能”“并发时不怕数据打架” 这些核心本事,在系统编程、嵌入式开发、高性能计算这些领域里,潜力真的特别大,甚至慢慢往 Web 开发、游戏开发这些传统领域渗透了。
之前文中给的代码例子,其实已经把 Rust 的优势说得很明白:它在编译的时候,就会把内存错误拦住,不用等到程序跑起来才崩;既能用着高级语言的方便(比如不用手动管一堆底层细节),又不浪费性能;再加上它的 “所有权” 规则,写多线程并发的代码时,不用怕数据互相抢着改出问题,特别省心。
对咱们开发者来说,学 Rust 不只是多会一门语言那么简单,更像是学一种 “又安全又高效” 的编程思路。不管你是做底层开发的工程师,还是专注于业务逻辑的程序员,搞懂 Rust 的核心想法,以后做项目的时候,都能帮你写出更安全、跑得更快的代码。
要是你现在还在为内存安全的问题头疼,或者觉得手里的语言跑得太慢、不够用,不如试试 Rust,它说不定能给你带来意想不到的惊喜。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)