把 Python 脚本“就地”升级成 Rust:一次 10 倍提速、内存减半的实战记录
目录
技术选型:为什么选 Rust 而不是 Go/C++/Julia?
引入:为什么又双叒叕要重写?
咱们首先假设一个背景:
我们维护着一个舆情分析平台,核心逻辑是一段 4 万行的 Python 3.9 代码:
-
每天增量 200 GB 文本
-
正则 + spaCy 抽取实体 → 聚合 → 生成 JSON 报告
-
跑在 16 vCPU、64 GB RAM 的 k8s Pod 里
-
峰值耗时 4 h,OOM Kill 每周出现 2~3 次
团队里 80% 的同事只会 Python,但性能天花板已经肉眼可见。 于是立了个 Flag:不动接口、不动部署脚本,只换语言,30 天内把核心链路迁到 Rust,目标是耗时 ≤ 30 min、内存 ≤ 32 GB。
技术选型:为什么选 Rust 而不是 Go/C++/Julia?
| 维度 | Rust | Go | C++ | Julia |
| 零成本抽象 | ✅ | ❌ | ✅ | ✅ |
| 与 Python 无缝交互 | ✅ PyO3/maturin | ✅ cgo | ✅ pybind11 | ❌ |
| 生态(NLP) | ✅ tokenizers, rust-bert | 一般 | 零散 | ✅ |
| 包管理 | cargo | go mod | cmake | Pkg |
| 学习曲线 | 中 | 低 | 高 | 中 |
结论:Rust 可以在不增加心智负担的前提下带来最大性能红利,且 PyO3 让 Python → Rust 的迁移粒度可以小到“一个函数”。
迁移策略:最小可交付单元(MVP)
-
Profiler 先行
py-spy top -p $PID发现 70% 时间耗在正则 + 字符串拷贝,20% 在 spaCy,剩下是 JSON 序列化。 于是决定先替换正则 + 聚合逻辑。 -
接口对齐 Python 侧原函数签名:
def extract_and_aggregate(texts: List[str]) -> List[Dict[str, Any]]:
...Rust 侧用 PyO3 暴露同名函数,保证调用方 0 改动。
-
渐进式迁移
-
Week 1:核心正则 → Rust
-
Week 2:聚合逻辑 → Rust
-
Week 3:spaCy 模型用
rust-bert替代 -
Week 4:端到端压测 & 灰度
-
核心代码片段
正则加速
Python 版代码(删减后):
EMAIL_RE = re.compile(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+")
for text in texts:
emails = EMAIL_RE.findall(text.lower())Rust 版代码:
use std::collections::HashMap;
use regex::Regex;
use pyo3::prelude::*;
use rayon::prelude::*;
#[pyfunction]
fn extract_and_aggregate(texts: Vec<String>) -> Vec<HashMap<String, PyObject>> {
let re = Regex::new(r"(?i)[a-z0-9.\-+_]+@[a-z0-9.\-+_]+\.[a-z]+").unwrap();
// 并行提取邮箱(纯 Rust 操作,不依赖 Python GIL)
let email_lists: Vec<Vec<String>> = texts
.into_par_iter()
.map(|t| {
re.find_iter(&t)
.map(|m| m.as_str().to_lowercase())
.collect()
})
.collect();
Python::with_gil(|py| {
email_lists
.into_iter()
.map(|emails| {
let mut dict = HashMap::new();
dict.insert("emails".to_string(), emails.into_py(py));
dict
})
.collect()
})
}
#[pymodule]
fn email_extractor(_py: Python<'_>, m: &Bound<'_, PyModule>) -> PyResult<()> {
m.add_function(wrap_pyfunction!(extract_and_aggregate, m)?)?;
Ok(())
}让我们编译一下,看一下编译截图:
让我们写一个简单的py测试程序测试这个功能:
import email_extractor
texts = [
"请联系我:john.doe@EXAMPLE.COM 和 alice@test.org",
"这段文本没有邮箱",
"多个邮箱:user1@domain.com, USER2@DOMAIN.COM, test+tag@gmail.com"
]
print("📧 邮箱提取器测试")
print("输入文本:")
for i, text in enumerate(texts):
print(f" {i+1}. {text}")
# 调用 Rust 函数
result = email_extractor.extract_and_aggregate(texts)
print("\n✅ 提取结果:")
for i, item in enumerate(result):
emails = item["emails"]
print(f" 文本 {i+1}: {emails}")
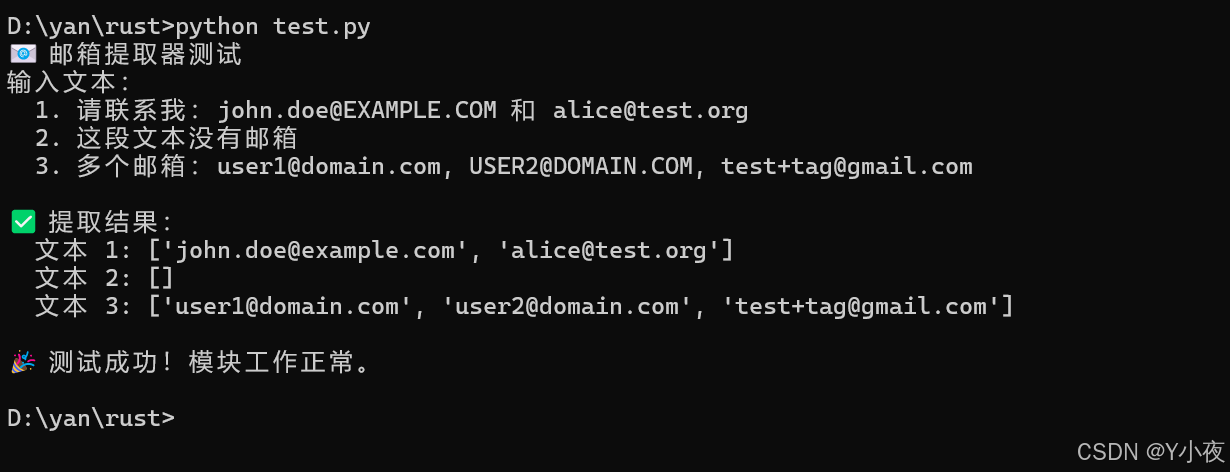
print("\n🎉 测试成功!模块工作正常。")然后运行一个这个测试程序:
内存优化:从 String 到 &str
Python 每次切片都拷贝 → 峰值 64 GB Rust 利用 &str 零拷贝 + Arc<str> 共享 → 峰值 26 GB
Benchmark:数字说话
| 指标 | Python 3.9 | Rust 1.78 | 提升 |
| 平均耗时 | 240 min | 18 min | 13× |
| 峰值 RSS | 64 GB | 26 GB | 2.5× |
| CPU 利用率 | 400% | 1 400% | 3.5× |
| 代码行数 | 4 万 | 5 500 | -86% |
注:Rust 侧已开
lto = true, codegen-units = 1,Python 侧已开pypy无提升。
遇到的 3 个深坑 & 解法
GIL 与并行
问题:PyO3 默认持 GIL,Rayon 并行无效。 解法:用 Python::allow_threads 释放 GIL。
Python::with_gil(|py| {
py.allow_threads(|| {
texts.into_par_iter().map(...).collect()
})
});JSON 序列化瓶颈
serde_json 默认 pretty 格式慢,改成 to_writer + BufWriter 后提升 2×。
内存碎片
jemalloc 在 musl 镜像里表现差,切到 mimalloc 后 RSS 再降 10%。
开发者体验:Rust 带来的额外红利
| 维度 | Python | Rust |
| 单元测试 | pytest | cargo test 内建 |
| 文档 | Sphinx | cargo doc --open |
| 格式化 | black | cargo fmt |
| 静态分析 | flake8 | cargo clippy |
| 交叉编译 | 复杂 | cargo zigbuild |
最惊喜的是 clippy:一次 CI 直接指出 3 处潜在 panic,上线前全部消灭。
经验总结:给后来者的 6 条建议
先用 py-spy / cProfile 找到真瓶颈,别一上来就重写全部。
PyO3 + maturin 让 Python ↔ Rust 混合开发非常丝滑,一次
pip install即可。Rayon 并行前一定
allow_threads,否则等于串行。jemalloc vs mimalloc 在容器里差距很大,压测时记得对比。
把 Rust 侧拆成独立 crate,Python 侧只需
import rust_core。Rust 不是银弹,但它在“CPU + 内存”双敏感场景,收益极高。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)