仓颉语言中的引用计数实现原理与工程实践
在现代语言设计中,内存管理模型 是性能与安全的平衡核心。传统的垃圾回收(GC)机制虽然能自动管理内存,但常引入延迟与不可预测的暂停;而纯手动管理又容易导致悬空指针或内存泄漏。仓颉语言(Cangjie)选择了第三条路径——以 引用计数(Reference Counting, RC)为核心的确定性内存回收机制,并结合编译期分析与运行时优化,实现了“零暂停、高确定性”的内存管理模型。
一、引用计数机制的设计理念
仓颉语言的内存管理基于“对象拥有者模型”(Ownership Model)。每个对象在分配时会附带一个 引用计数(ref count),表示当前有多少个活动引用(指针或变量)指向它。当引用计数降为零时,对象立即被释放。
这种机制的最大优势在于:
-
确定性释放 —— 对象生命周期与作用域绑定,不依赖后台 GC 线程;
-
低延迟 —— 无需全局扫描堆空间,回收操作在局部完成;
-
语言层一致性 —— 与仓颉的智能指针(
SharedPtr、WeakPtr)机制无缝对接。
仓颉编译器在生成代码时,会自动插入“引用计数增减指令”,确保每次对象拷贝、传参或赋值都能正确更新计数。这一过程由编译期所有权分析(Ownership Analysis)驱动,保证计数的准确性与无竞争性。
二、仓颉引用计数的底层实现
仓颉运行时的引用计数采用 区域式分层计数模型(Regional Hierarchical RC Model),主要包含三层机制:
-
线程局部引用缓存(Thread-Local RC Cache)
对频繁增减计数的对象,仓颉采用线程本地缓存,批量同步全局计数。这样在高并发场景下避免了原子操作的性能开销。 -
区域归约(Regional Aggregation)
对象按内存区域(region)分组,每个 region 维护聚合引用计数。当一个区域内的所有对象引用均清零时,运行时可整体释放该区域内存,大幅降低碎片率。 -
弱引用机制(Weak RC Links)
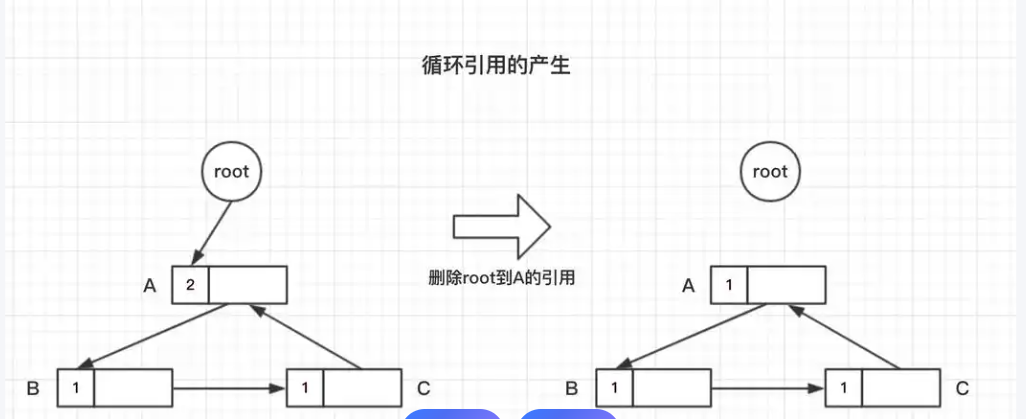
为防止循环引用(尤其在SharedPtr场景下),仓颉实现了弱引用标记(weak flag)。WeakPtr不参与计数增减,仅在目标对象销毁时自动失效,从而保证引用链不会形成闭环。
此外,仓颉的引用计数指令集经过硬件级优化:
-
增减计数操作使用 无锁原子指令(lock-free atomic inc/dec);
-
编译器在 SSA(静态单赋值)阶段进行计数折叠(Count Folding),自动消除多余的 +1/-1 对操作;
-
对逃逸分析确认的短生命周期对象,直接栈上分配,无需计数管理。
三、实践:引用计数在异步与并发环境下的行为
在异步编程模型中,任务与协程常跨线程执行,引用计数管理的正确性与性能尤为关键。仓颉运行时在协程调度器(Scheduler)层面引入了 跨线程引用转移机制(Cross-Thread Ownership Transfer)。当对象被捕获至异步任务中时,编译器会将引用计数的更新操作迁移至调度线程执行,以确保线程安全与执行顺序一致性。
在多任务场景下,引用计数的实时性还配合仓颉的“任务快照模型(Task Snapshot Model)”:当协程挂起时,引用状态被快照保存;恢复时再重新关联引用,从而避免悬空或重复释放。这种机制在复杂的 Actor 模型或数据流管线中尤为高效,使仓颉在并发场景下保持内存管理的确定性。
四、专业思考:引用计数的优势、边界与优化方向
仓颉选择引用计数而非传统 GC,并非追求简化,而是出于实时性与工程可控性的考虑。相比 GC 的延迟性,RC 的即时释放更符合系统编程与高频计算任务需求。
但引用计数也并非完美无缺。其主要挑战包括:
-
循环引用问题 —— 虽可用弱引用解决,但会增加开发复杂度;
-
频繁计数操作开销 —— 对高频对象创建场景,计数指令可能成为性能瓶颈。
仓颉通过编译器优化与运行时分层机制有效缓解这些问题。未来版本还计划引入 混合回收模型(Hybrid RC-GC Model):对长期驻留堆对象启用低频标记清理,而短生命周期对象继续使用 RC,以获得更高的整体内存效率。
五、结语
仓颉语言的引用计数机制不仅是一种内存管理手段,更是一种语言哲学的体现:将资源生命周期从运行时转移到语言语义层进行管理。通过编译期分析、线程局部缓存与结构化弱引用,仓颉在保证安全的同时,兼顾了性能与实时性。这种设计使得仓颉不仅适用于通用业务开发,更具备支撑高性能系统编程与 AI 计算框架的工程潜力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)