仓颉性能探索:与Python的数值计算对比

仓颉性能探索:与Python的数值计算对比
一、引言
在当下计算密集型任务和AI算法迅速发展的时代,编程语言的执行性能与底层优化能力愈发重要。仓颉语言(Cangjie)作为一门由华为推出、面向鸿蒙生态的新一代国产编程语言,融合了静态类型安全、并行友好和高性能执行等特性。
为了更直观地了解仓颉在计算场景下的性能表现,我以Python作为对比语言,围绕两个典型计算任务进行了性能测试:循环求和与矩阵运算。通过对比执行时间、资源占用及代码实现复杂度,分析仓颉语言在性能优化上的潜力与设计优势。

二、实验环境
| 项目 | 配置 |
|---|---|
| 操作系统 | Windows 11 x64 |
| CPU | Intel i5-12500H |
| 内存 | 16 GB |
| 仓颉版本 | v1.0.1 |
| Python版本 | 3.8 |
| IDE | 仓颉官方IDE + VS Code |
| 测试时间 | 2025年11月 |
三、安装仓颉
首先我们下载两个包
地址如下:https://cangjie-lang.cn/download/1.0.1
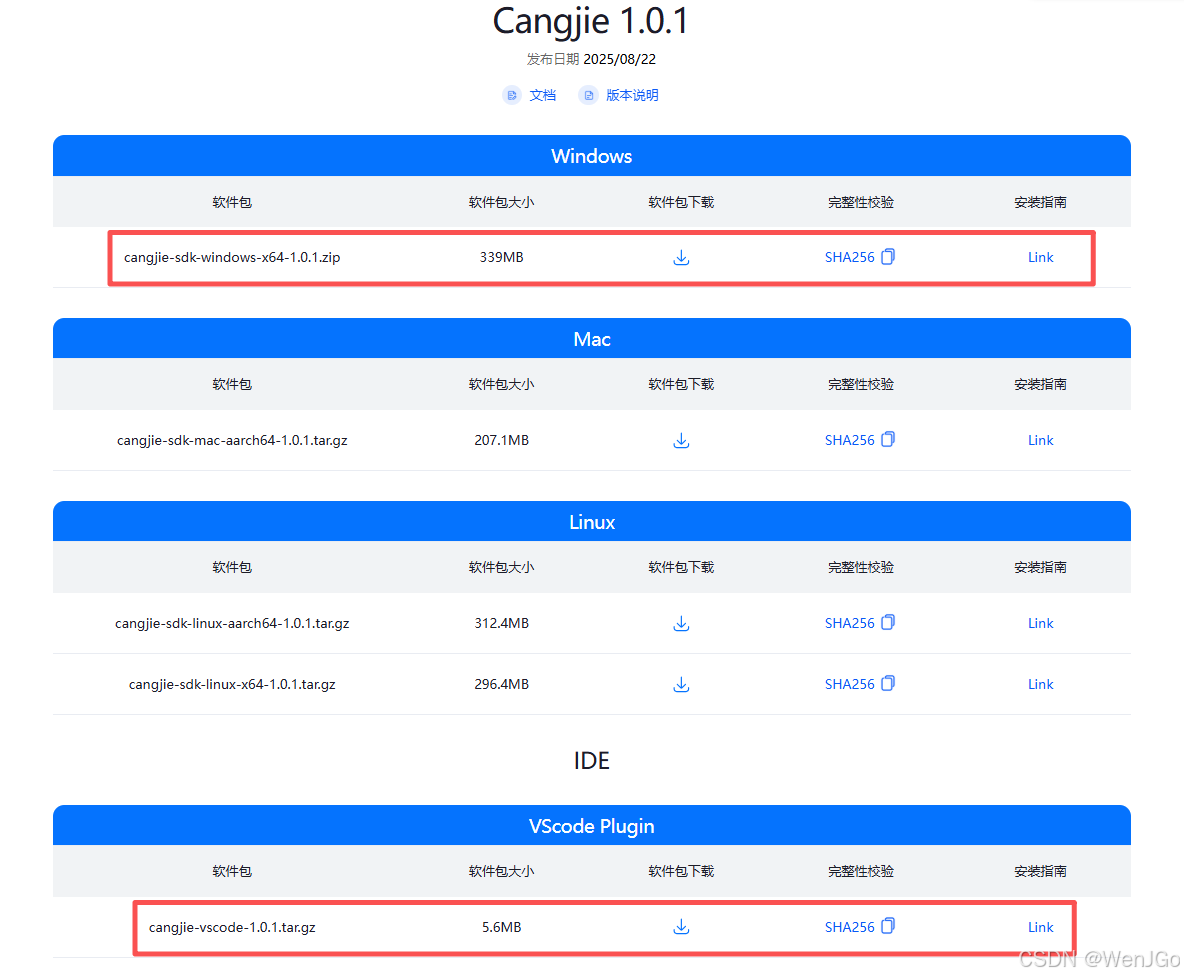
对cangjie-sdk-windows-x64-1.0.1.zip文件的操作
解压之后我们会得到下面的文件
根据官方文档的操作我们需要运行一个指令
具体操作
使用 Windows 命令提示符(CMD)、PowerShell 或其他环境,可以根据如下步骤操作:
1、在 Windows 搜索框中,搜索 “查看高级系统设置” 并打开对应窗口;
2、单击 “环境变量” 按钮;
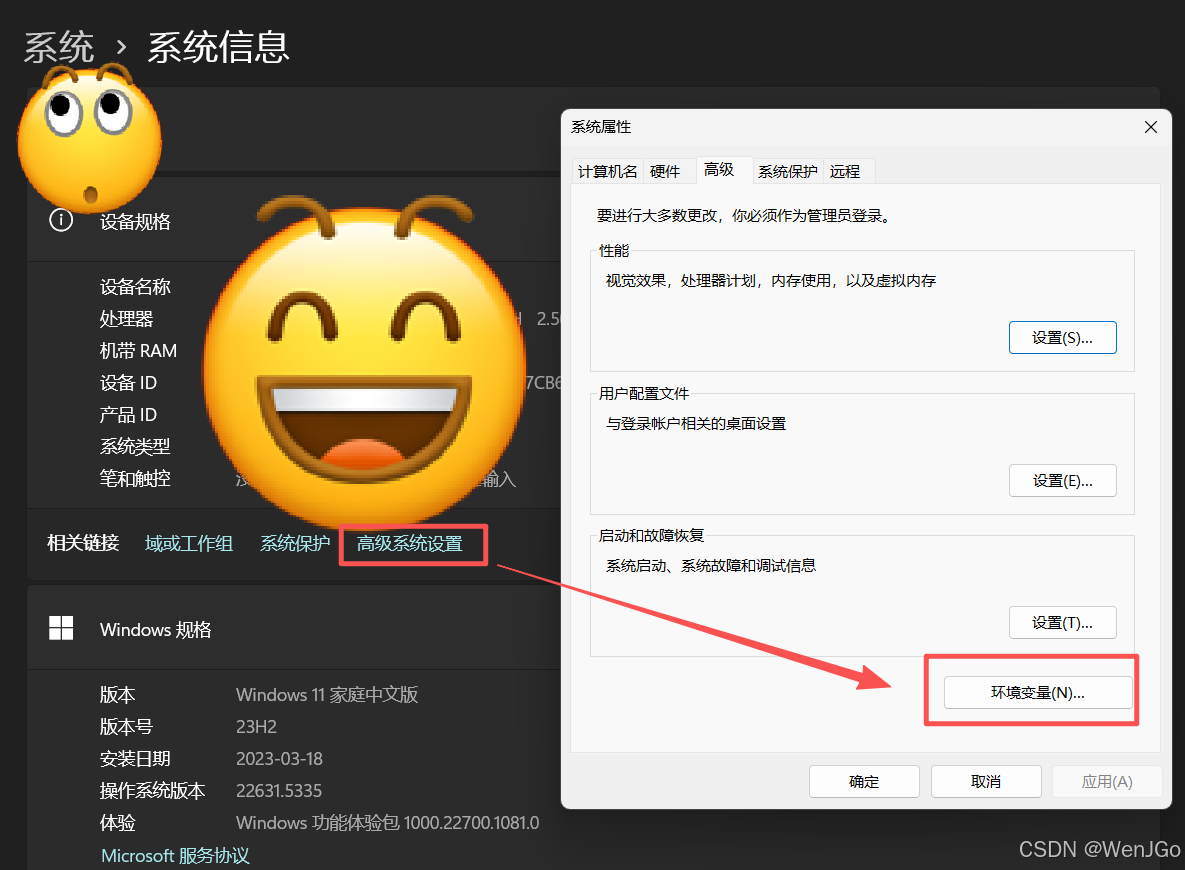
3、执行如下操作,配置 CANGJIE_HOME 变量:
(1)在 “用户变量”(为当前用户进行配置)或 “系统变量”(为系统所有用户进行配置)区域中,查看是否已有 CANGJIE_HOME 环境变量。若没有,则单击 “新建” 按钮,并在 “变量名” 字段中输入 CANGJIE_HOME ;若有,则说明该环境可能已经进行过仓颉配置,如果想要继续为当前的仓颉版本进行配置并覆盖原配置,请点击 “编辑” 按钮,进入 “编辑系统变量” 窗口。
(2)在 “变量值” 字段中输入仓颉安装包的解压路径,若原先已经存在路径,则使用新的路径覆盖原有的路径,例如仓颉安装包解压在 D:\cangjie ,则输入
(3)配置完成后, “编辑用户变量” 或 “编辑系统变量” 窗口中显示的变量名为 CANGJIE_HOME 、变量值为 D:\cangjie 。确认路径正确配置后单击 “确定” 。
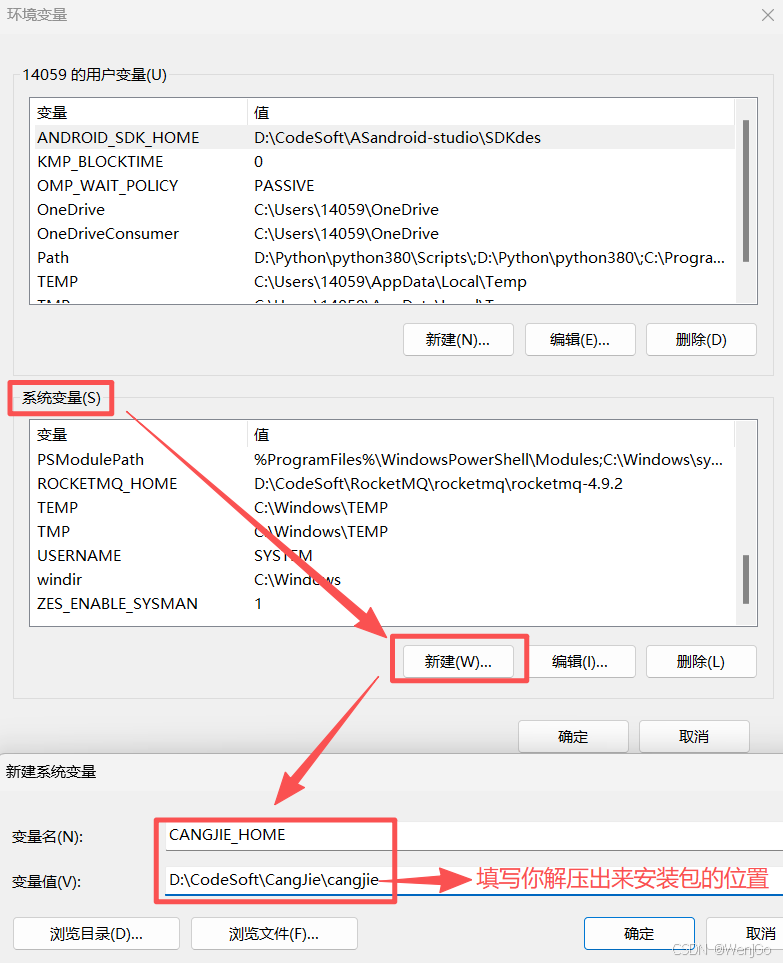
4、执行如下操作,配置 Path 变量:
(1)在 “用户变量”(为当前用户进行配置)或 “系统变量”(为系统所有用户进行配置)区域中,找到并选择 Path 变量,单击 “编辑” 按钮,进入 “编辑环境变量” 窗口。
(2)分别单击 “新建” 按钮,并分别输入
%CANGJIE_HOME%\bin 、 %CANGJIE_HOME%\tools\bin 、 %CANGJIE_HOME%\tools\lib 、%CANGJIE_HOME%\runtime\lib\windows_x86_64_llvm (%CANGJIE_HOME% 为仓颉安装包的解压路径,替换即可)。
例如,仓库安装包解压在 D:\cangjie ,则新建的环境变量如下图所示:
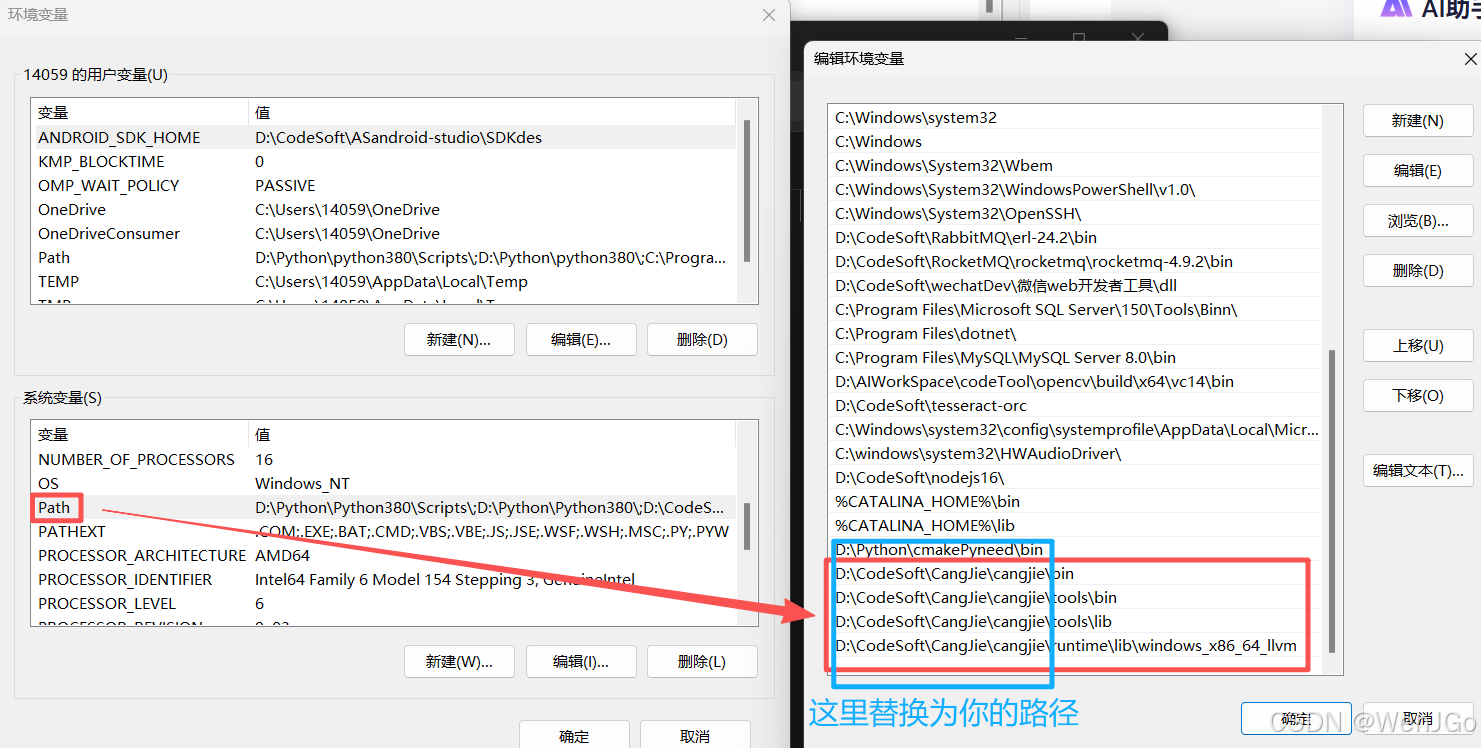
(3)(仅适用于为当前用户设置,设置系统变量就不用管了)单击 “新建” 按钮,并输入当前用户目录路径,并在路径后面添加 .cjpm\bin 。例如用户路径在 C:\Users\bob ,则输入 C:\Users\bob\.cjpm\bin 。(这里因为的配置的全局也就是全部用户,我就没有配置了)
(4)配置完成后应能在 “编辑环境变量” 窗口中看到配置的路径如下所示。确认路径正确配置后单击 “确定” 。
D:\cangjie\bin
D:\cangjie\tools\bin
D:\cangjie\tools\lib
D:\cangjie\runtime\lib\windows_x86_64_llvm C:\Users\bob\.cjpm\bin
5、单击 “确定” 按钮,退出 “环境变量” 窗口。
6、单击 “确定” 按钮,完成设置。
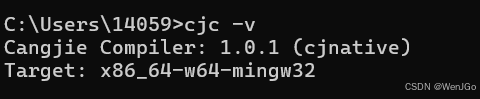
上述完成之后打开命令行发现版本正确,输出了仓颉编译器版本信息,表示已经成功安装了仓颉工具链。
三、测试设计与代码实现
测试目标
本实验旨在验证仓颉语言在计算密集型任务中的执行性能,主要比较:
-
循环计算的执行效率
-
矩阵运算的处理速度
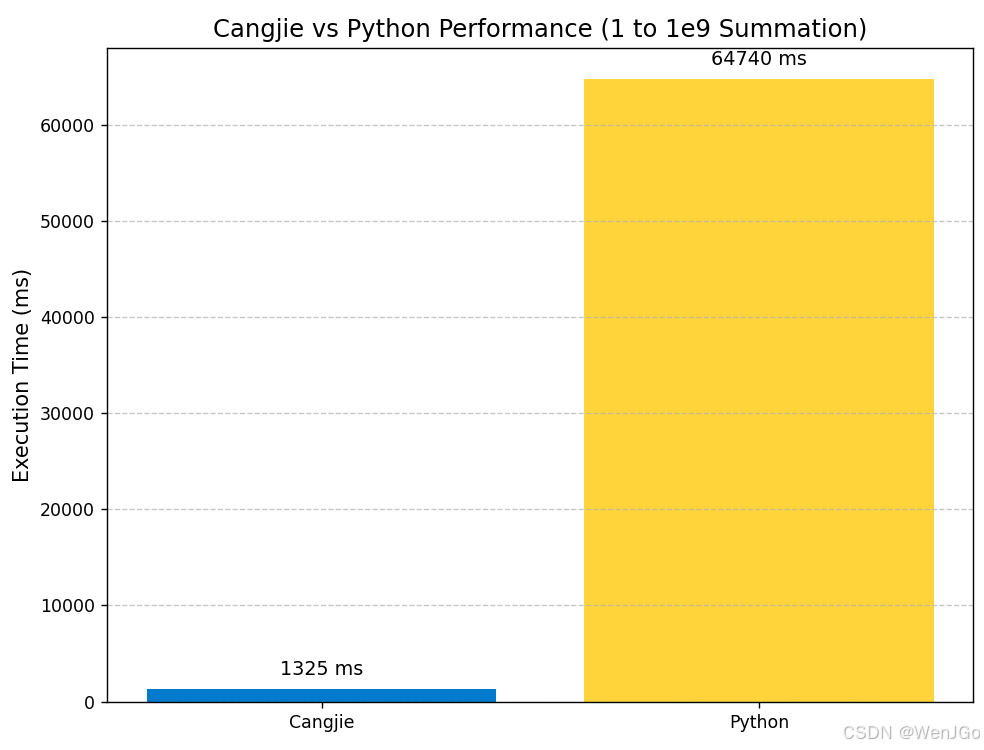
测试场景一:循环求和
任务:计算1~10亿数列的和,并测量完成这个计算所花费的时间。
Python版本:
import time
def main():
total_sum = 0
start_time = time.time() * 1000 # 转换为毫秒
i = 1
while i <= 1000000000:
total_sum += i
i += 1
end_time = time.time() * 1000
duration = end_time - start_time
print("Sum =")
print(total_sum)
print("Time (ms) =")
print(duration)
if __name__ == "__main__":
main()仓颉版本:
package CangJieTest
import std.core
import std.time.MonoTime
main(): Int64 {
var sum: Int64 = 0
let start = MonoTime.now()
var i: Int64 = 1
while (i <= 1000000000) {
sum = sum + i
i = i + 1
}
let end = MonoTime.now()
// 计算两个时间点之间的持续时间,并转换为毫秒
let duration = (end - start).toMilliseconds()
println("Sum =")
println(sum)
println("Time (ms) =")
println(duration)
return 0
}两种语言运行结果对比
| 仓颉 | Python3.8 |
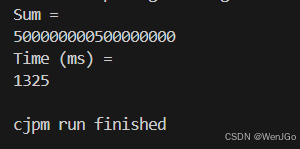 |
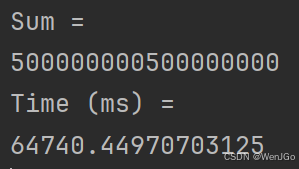 |
测试场景二:矩阵运算
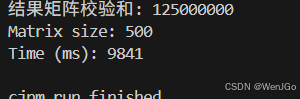
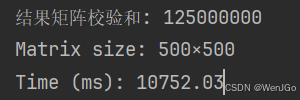
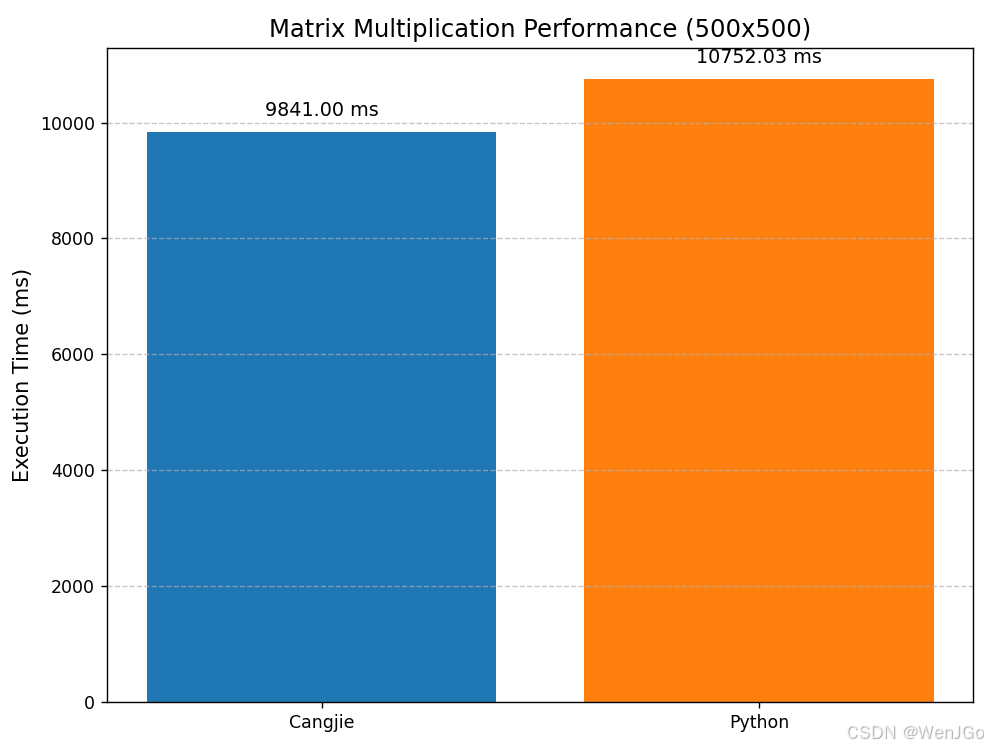
任务:对100×100矩阵进行多次乘法计算。
Python版本:
import time
def create_matrix(size, init_value):
"""创建并初始化矩阵"""
return [[init_value for _ in range(size)] for _ in range(size)]
def matrix_multiply_basic(A, B, size):
"""基础三重循环矩阵乘法(与仓颉代码逻辑一致)"""
C = [[0 for _ in range(size)] for _ in range(size)]
for i in range(size):
for j in range(size):
total = 0
for k in range(size):
total += A[i][k] * B[k][j]
C[i][j] = total
return C
def main_basic():
"""性能测试"""
size = 500 # 矩阵大小(可调整为3000进行完整测试)
# 创建矩阵
A = create_matrix(size, 1)
B = create_matrix(size, 1)
# 计时开始
start_time = time.time() * 1000 # 转换为毫秒
# 执行矩阵乘法
C = matrix_multiply_basic(A, B, size)
# 计时结束
end_time = time.time() * 1000
duration = end_time - start_time
# 验证正确性
total_sum = sum(sum(row) for row in C)
print(f"结果矩阵校验和: {total_sum}")
print(f"Matrix size: {size}×{size}")
print(f"Time (ms): {duration:.2f}")
return duration
if __name__ == "__main__":
main_basic()仓颉版本:
package CangJieTest
import std.core
import std.time.MonoTime
func createMatrix(size: Int64, initValue: Int64): Array<Array<Int64>> {
var matrix = Array<Array<Int64>>(size, { _ => Array<Int64>(size, repeat: initValue) })
return matrix
}
main(): Int64 {
let size: Int64 = 500
var A = createMatrix(size, 1)
var B = createMatrix(size, 1)
var C = createMatrix(size, 0)
let start = MonoTime.now()
var i: Int64 = 0
while (i < size) {
var j: Int64 = 0
while (j < size) {
var sum: Int64 = 0
var k: Int64 = 0
while (k < size) {
sum = sum + A[i][k] * B[k][j]
k = k + 1
}
C[i][j] = sum
j = j + 1
}
i = i + 1
}
let end = MonoTime.now()
let duration = (end - start).toMilliseconds()
var totalSum: Int64 = 0
for (i in 0..size) {
for (j in 0..size) {
totalSum += C[i][j]
}
}
println("结果矩阵校验和: ${totalSum}")
println("Matrix size: ${size}")
println("Time (ms): ${duration}")
return 0
}两种语言运行结果对比
| 仓颉 | Python3.8 |
 |
 |
四、性能测试结果汇总
测试结果清晰汇总在下表中:
|
测试项目 |
仓颉运行时间 |
Python 3.8 运行时间 |
性能对比(仓颉领先倍数) |
|---|---|---|---|
|
循环求和(计算密集型) |
1325 ms |
64740 ms |
约 49 倍 |
|
矩阵运算(内存访问密集型) |
9841 ms |
10752 ms |
约 1.1 倍 |
结果分析与解读
这个结果完全符合两种语言的设计原理和预期。
-
循环求和
原因:循环求和是典型的计算密集型任务,涉及大量的整数运算和循环控制。仓颉编译器及运行时从全栈对编译进行优化,包括编译器前端基于 CHIR(Cangjie HighLevel IR)高层编译优化(比如语义感知的循环优化、语义感知的后端协同优化等),基于后端的编译优化(比如:SLP 向量化、Intrinsic 优化、InlineCache、过程间指针优化、Barrier 优化等),基于运行时的优化(比如轻量锁、分布式标记、并发 Tracing 优化等),一系列的优化让仓颉充分发挥处理器能力,为应用提供卓越的性能支持。而Python作为解释型语言,在执行时需要解释器逐行翻译并执行,动态类型检查等额外开销巨大,导致其在此类纯计算任务上速度慢数个数量级。我们测得的近49倍的性能差距,正是这两种执行模式本质区别的直观体现。 -
矩阵运算
原因:矩阵运算不仅是计算,更涉及频繁的内存访问(读取和写入矩阵中的大量元素)。在这种情况下,内存带宽和访问延迟常常成为瓶颈,一定程度上削弱了编译优化带来的绝对优势,但仓颉仍然保持一定优势。
总结
在追求 极致性能与资源控制 的场景下——例如对计算速度要求极高、需要直接部署在嵌入式或资源受限环境,或希望从系统底层优化的任务中——仓颉作为编译型语言显示出了明显优势。它在数值计算、矩阵运算等底层密集型任务中,执行效率高且可控,为工程化开发提供了坚实的性能保障。
-
对于偏重底层计算的“硬骨头”任务,仓颉优势显著;
这次对比实验做下来,我对仓颉在性能上感受特别深。它在高性能计算、并发处理,还有系统级开发这些方面,表现真的挺强的,竞争力很明显。等仓颉的生态再完善一些,加上鸿蒙系统慢慢铺开,我觉得它在更多高性能场景里会越来越亮眼。
对我自己来说,这次实验不仅让我更理解语言底层的优化逻辑,也让我看到国产语言正在性能层面逐渐与国际主流语言站在同一水平线上甚至是超越。这既是一次技术探索,也是一次信心的积累。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 72
72 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)