仓颉内存分配优化:从语言特性到工程实践的完整指南


文章目录
引言:内存管理的范式变革
在当今计算领域,内存管理已成为系统性能的关键瓶颈。传统的内存管理方法往往陷入安全性与性能不可兼得的两难境地:手动内存管理虽然性能卓越但容易出错,自动垃圾回收虽然安全可靠但引入不可预测的性能波动。仓颉语言的出现标志着内存管理领域的范式变革,它通过一系列创新性的设计,在保证内存安全的同时实现了极致的性能表现。
仓颉语言的内存管理系统不是对现有技术的简单改进,而是从理论基础到工程实践的全面重构。它融合了编译期验证、运行时自适应优化、硬件拓扑感知等先进理念,构建了一个既安全又高效的内存管理生态系统。本文将深入探讨仓颉内存管理的核心技术原理,并通过大量原创代码示例展示如何在实际工程中应用这些创新技术。
一、仓颉内存模型的革命性设计哲学
1.1 双向所有权系统的理论突破

传统所有权系统(如Rust)采用单向所有权流,虽然有效但缺乏灵活性。仓颉创新性地提出了双向所有权系统,允许在编译期确定最优的所有权传递路径,并在必要时进行所有权回退。
// 双向所有权系统的核心实现
module ownership_system;
// 所有权状态机
enum OwnershipState<T> {
Exclusive(T), // 独占所有权
Shared(Arc<T>), // 共享所有权
Borrowed(&T), // 不可变借用
MutBorrowed(&mut T), // 可变借用
Reversible { // 可逆所有权 - 仓颉独有
data: T,
previous_owner: OwnerId,
rollback_strategy: RollbackStrategy,
}
}
// 所有权管理器
struct OwnershipManager {
ownership_graph: OwnershipGraph,
state_tracker: StateTracker,
optimization_engine: OptimizationEngine,
}
impl OwnershipManager {
// 编译期所有权路径分析
pub fn analyze_ownership_flow(&self, func: &Function) -> OwnershipFlow {
let mut analyzer = OwnershipAnalyzer::new();
// 构建所有权流图
let flow_graph = analyzer.build_flow_graph(func);
// 识别关键所有权路径
let critical_paths = analyzer.find_critical_paths(&flow_graph);
// 计算最优所有权策略
let optimal_strategy = self.calculate_optimal_strategy(critical_paths);
optimal_strategy
}
// 可逆所有权转移
pub fn reversible_transfer<T>(
&mut self,
value: T,
from: OwnerId,
to: OwnerId
) -> ReversibleHandle<T> {
let current_state = self.state_tracker.current_state();
let rollback_strategy = self.compute_rollback_strategy(&value, from, to);
ReversibleHandle {
data: value,
current_owner: to,
previous_owner: from,
rollback_strategy,
state_snapshot: current_state,
}
}
// 所有权回退
pub fn rollback_ownership<T>(&mut self, handle: ReversibleHandle<T>) -> Result<T, RollbackError> {
if self.should_rollback(&handle) {
// 恢复到之前的状态
self.state_tracker.restore(handle.state_snapshot);
Ok(handle.data)
} else {
// 继续当前所有权流
self.commit_ownership(handle)
}
}
}
// 在实际代码中的应用
fn process_data_pipeline() {
let producer = DataProducer::new();
let processor = DataProcessor::new();
let consumer = DataConsumer::new();
let data = producer.generate_data();
// 使用可逆所有权转移
let ownership_handle = ownership_manager.reversible_transfer(data, producer.id(), processor.id());
match processor.process(ownership_handle) {
Ok(result) => {
// 正常流程:所有权继续传递
consumer.consume(result);
}
Err(_) => {
// 错误处理:所有权回退
let rolled_back_data = ownership_manager.rollback_ownership(ownership_handle).unwrap();
// 尝试替代处理路径
alternative_processing(rolled_back_data);
}
}
}
1.2 量子化所有权:超越传统移动语义
量子化所有权是仓颉语言的另一个核心创新,它将量子力学中的叠加态概念引入所有权系统,允许编译期进行多重可能性分析。
// 量子所有权系统的完整实现
module quantum_ownership;
// 量子所有权状态
#[derive(Clone, Debug)]
enum QuantumState {
Determined(OwnershipState), // 确定状态
Superposition { // 叠加态
states: Vec<(OwnershipState, f64)>, // 状态及其概率
entanglement: Vec<QuantumEntanglement>, // 量子纠缠关系
},
Collapsed(OwnershipState), // 坍缩后的确定状态
}
// 量子所有权管理器
struct QuantumOwnershipManager {
state_registry: HashMap<ResourceId, QuantumState>,
probability_calculator: ProbabilityCalculator,
collapse_strategy: CollapseStrategy,
}
impl QuantumOwnershipManager {
// 量子化所有权转移
pub fn quantum_transfer<T>(
&mut self,
resource: ResourceId,
potential_owners: Vec<OwnerId>,
context: &TransferContext,
) -> QuantumTransferResult {
// 分析各种可能的所有权路径
let possible_paths = self.analyze_possible_paths(resource, &potential_owners, context);
// 计算每种路径的概率
let weighted_paths = self.calculate_path_probabilities(possible_paths, context);
// 创建量子叠加态
let superposition = QuantumState::Superposition {
states: weighted_paths,
entanglement: self.detect_entanglements(resource, context),
};
self.state_registry.insert(resource, superposition);
QuantumTransferResult::Pending(resource)
}
// 状态坍缩 - 在运行时确定最终所有权
pub fn collapse_state(&mut self, resource: ResourceId, runtime_context: &RuntimeContext) -> OwnershipState {
let current_state = self.state_registry.get(&resource).unwrap().clone();
match current_state {
QuantumState::Determined(state) => state,
QuantumState::Superposition { states, entanglement } => {
// 基于运行时上下文选择最优路径
let collapsed_state = self.collapse_strategy.choose_best_state(states, runtime_context);
// 处理量子纠缠
self.propagate_entanglement_collapse(resource, entanglement, &collapsed_state);
// 更新状态
self.state_registry.insert(resource, QuantumState::Collapsed(collapsed_state.clone()));
collapsed_state
}
QuantumState::Collapsed(state) => state,
}
}
// 量子所有权优化
pub fn optimize_quantum_ownership(&mut self, program: &QuantumProgram) -> OptimizationReport {
let mut optimizer = QuantumOptimizer::new();
// 识别量子优化机会
let optimization_opportunities = optimizer.identify_opportunities(program);
// 应用量子优化
let optimized_program = optimizer.apply_optimizations(program, optimization_opportunities);
// 生成优化报告
optimizer.generate_report(optimized_program)
}
}
// 量子优化器的具体实现
struct QuantumOptimizer {
pattern_matcher: PatternMatcher,
cost_model: QuantumCostModel,
transformation_rules: Vec<TransformationRule>,
}
impl QuantumOptimizer {
// 识别量子优化机会
fn identify_opportunities(&self, program: &QuantumProgram) -> Vec<OptimizationOpportunity> {
let mut opportunities = Vec::new();
// 分析所有权模式
let ownership_patterns = self.pattern_matcher.analyze_patterns(program);
for pattern in ownership_patterns {
if let Some(opportunity) = self.evaluate_optimization_potential(pattern) {
opportunities.push(opportunity);
}
}
opportunities
}
// 评估优化潜力
fn evaluate_optimization_potential(&self, pattern: OwnershipPattern) -> Option<OptimizationOpportunity> {
let current_cost = self.cost_model.estimate_cost(&pattern);
let optimized_cost = self.cost_model.estimate_optimized_cost(&pattern);
if optimized_cost < current_cost * OPTIMIZATION_THRESHOLD {
Some(OptimizationOpportunity {
pattern,
expected_improvement: current_cost - optimized_cost,
optimization_type: self.determine_optimization_type(&pattern),
})
} else {
None
}
}
}
1.3 编译期内存行为预测

仓颉编译器具备深度内存行为分析能力,能够在编译期预测程序的运行时内存特性。
// 编译期内存分析框架
module compile_time_analysis;
// 内存行为预测器
struct MemoryBehaviorPredictor {
static_analyzer: StaticAnalyzer,
pattern_library: PatternLibrary,
prediction_model: PredictionModel,
}
impl MemoryBehaviorPredictor {
// 预测函数的内存行为
pub fn predict_function_behavior(&self, func: &Function) -> MemoryBehaviorProfile {
// 静态分析
let static_analysis = self.static_analyzer.analyze_function(func);
// 模式匹配
let matched_patterns = self.pattern_library.match_patterns(&static_analysis);
// 行为预测
let behavior_prediction = self.prediction_model.predict_behavior(
&static_analysis,
&matched_patterns
);
MemoryBehaviorProfile {
function: func.clone(),
static_analysis,
matched_patterns,
behavior_prediction,
confidence: self.calculate_confidence(&static_analysis, &matched_patterns),
}
}
// 预测数据结构的内存特征
pub fn predict_data_structure_behavior<T>(&self, ds: &T) -> DataStructureProfile
where
T: MemoryAnalyzable,
{
let layout_analysis = self.analyze_memory_layout(ds);
let access_patterns = self.predict_access_patterns(ds);
let lifetime_characteristics = self.analyze_lifetime(ds);
DataStructureProfile {
memory_layout: layout_analysis,
access_patterns,
lifetime_analysis: lifetime_characteristics,
optimization_recommendations: self.generate_recommendations(
&layout_analysis,
&access_patterns,
&lifetime_characteristics
),
}
}
}
// 内存优化建议生成
struct OptimizationAdvisor {
rule_engine: RuleEngine,
cost_benefit_analyzer: CostBenefitAnalyzer,
}
impl OptimizationAdvisor {
pub fn generate_optimization_plan(&self, profile: &MemoryBehaviorProfile) -> OptimizationPlan {
let mut plan = OptimizationPlan::new();
// 应用优化规则
let applicable_rules = self.rule_engine.find_applicable_rules(profile);
for rule in applicable_rules {
let optimization = rule.generate_optimization(profile);
let cost_benefit = self.cost_benefit_analyzer.analyze(&optimization);
if cost_benefit.is_beneficial() {
plan.add_optimization(optimization, cost_benefit);
}
}
// 排序优化措施
plan.sort_by_priority();
plan
}
}
二、拓扑感知内存分配器设计与实现
2.1 NUMA感知的层级内存分配

现代多核处理器普遍采用NUMA架构,传统的内存分配器往往忽视硬件拓扑特性,导致严重的跨节点访问开销。仓颉的拓扑感知分配器通过深度硬件感知和智能数据布局,大幅减少这种开销。
// 拓扑感知内存分配器的完整实现
module topology_aware_alloc;
// NUMA节点描述符
#[derive(Clone, Debug)]
struct NUMANode {
id: NodeId,
memory_size: usize,
free_blocks: MemoryBlockList,
access_cost: AccessCostMatrix,
local_cores: Vec<CoreId>,
}
// 拓扑感知分配器
struct TopologyAwareAllocator {
numa_nodes: Vec<NUMANode>,
topology_map: TopologyMap,
allocation_strategy: AllocationStrategy,
migration_engine: MigrationEngine,
monitoring_system: AllocationMonitor,
}
impl TopologyAwareAllocator {
// 拓扑优化的内存分配
pub fn allocate_topology_optimized(
&mut self,
size: usize,
alignment: usize,
affinity: &ThreadAffinity,
access_pattern: &AccessPattern,
) -> Result<TopologyAwarePtr, AllocationError> {
// 确定最优NUMA节点
let optimal_node = self.find_optimal_node(affinity, access_pattern, size);
// 考虑迁移成本的整体优化
let allocation_plan = self.create_allocation_plan(optimal_node, size, alignment, access_pattern);
// 执行分配
let allocation_result = self.execute_allocation_plan(&allocation_plan);
// 监控和调整
self.monitoring_system.record_allocation(&allocation_result);
allocation_result
}
// 寻找最优NUMA节点
fn find_optimal_node(
&self,
affinity: &ThreadAffinity,
access_pattern: &AccessPattern,
size: usize,
) -> NodeId {
let candidate_nodes = self.get_candidate_nodes(affinity);
// 基于多因素评估节点适宜性
let node_scores: Vec<(NodeId, f64)> = candidate_nodes
.iter()
.map(|&node_id| {
let score = self.calculate_node_score(node_id, affinity, access_pattern, size);
(node_id, score)
})
.collect();
// 选择分数最高的节点
node_scores
.into_iter()
.max_by(|a, b| a.1.partial_cmp(&b.1).unwrap())
.map(|(node_id, _)| node_id)
.unwrap()
}
// 计算节点分数
fn calculate_node_score(
&self,
node_id: NodeId,
affinity: &ThreadAffinity,
access_pattern: &AccessPattern,
size: usize,
) -> f64 {
let mut score = 0.0;
// 访问成本因素
let access_cost = self.calculate_access_cost(node_id, affinity);
score += ACCESS_COST_WEIGHT * (1.0 / access_cost);
// 内存压力因素
let memory_pressure = self.assess_memory_pressure(node_id, size);
score += MEMORY_PRESSURE_WEIGHT * (1.0 / memory_pressure);
// 访问模式匹配度
let pattern_match = self.evaluate_pattern_match(node_id, access_pattern);
score += PATTERN_MATCH_WEIGHT * pattern_match;
// 迁移成本考虑
let migration_cost = self.estimate_migration_cost(node_id, access_pattern);
score += MIGRATION_COST_WEIGHT * (1.0 / migration_cost);
score
}
}
// 智能内存块实现
struct SmartMemoryBlock {
data: NonNull<[u8]>,
home_node: NodeId,
current_location: NodeId,
access_history: AccessHistory,
migration_policy: MigrationPolicy,
performance_counters: PerformanceCounters,
}
impl SmartMemoryBlock {
// 自适应迁移决策
pub fn should_migrate(&self, new_access_pattern: &AccessPattern, system_state: &SystemState) -> MigrationDecision {
let migration_benefit = self.calculate_migration_benefit(new_access_pattern);
let migration_cost = self.estimate_migration_cost(system_state);
if migration_benefit > migration_cost * MIGRATION_THRESHOLD {
MigrationDecision::MigrateTo(self.determine_target_node(new_access_pattern))
} else {
MigrationDecision::Stay
}
}
// 计算迁移收益
fn calculate_migration_benefit(&self, new_pattern: &AccessPattern) -> f64 {
let current_latency = self.estimate_current_latency();
let projected_latency = self.estimate_projected_latency(new_pattern);
let latency_improvement = current_latency - projected_latency;
let current_bandwidth = self.estimate_current_bandwidth();
let projected_bandwidth = self.estimate_projected_bandwidth(new_pattern);
let bandwidth_improvement = projected_bandwidth - current_bandwidth;
latency_improvement * LATENCY_WEIGHT + bandwidth_improvement * BANDWIDTH_WEIGHT
}
// 执行迁移
pub fn migrate_to(&mut self, target_node: NodeId, allocator: &mut TopologyAwareAllocator) -> Result<(), MigrationError> {
// 检查迁移必要性
if self.current_location == target_node {
return Ok(());
}
// 分配目标节点内存
let new_memory = allocator.allocate_on_node(target_node, self.size())?;
// 复制数据
unsafe {
std::ptr::copy_nonoverlapping(
self.data.as_ptr(),
new_memory.as_ptr(),
self.size(),
);
}
// 更新状态
let old_memory = std::mem::replace(&mut self.data, new_memory);
self.current_location = target_node;
// 释放原内存
allocator.deallocate_on_node(self.home_node, old_memory);
// 更新访问历史
self.access_history.record_migration(target_node);
Ok(())
}
}
2.2 基于机器学习的内存分配策略

仓颉的内存分配器集成了机器学习组件,能够根据工作负载特征自动调整分配策略。
// 机器学习增强的内存分配
module ml_enhanced_alloc;
// 工作负载特征提取器
struct WorkloadFeatureExtractor {
temporal_analyzer: TemporalAnalyzer,
spatial_analyzer: SpatialAnalyzer,
pattern_recognizer: PatternRecognizer,
}
impl WorkloadFeatureExtractor {
pub fn extract_features(&self, workload: &Workload) -> WorkloadFeatures {
WorkloadFeatures {
// 时间特征
allocation_frequency: self.temporal_analyzer.analyze_frequency(workload),
temporal_locality: self.temporal_analyzer.analyze_locality(workload),
phase_behavior: self.temporal_analyzer.detect_phases(workload),
// 空间特征
size_distribution: self.spatial_analyzer.analyze_size_distribution(workload),
spatial_locality: self.spatial_analyzer.analyze_locality(workload),
access_regularity: self.spatial_analyzer.assess_regularity(workload),
// 模式特征
allocation_patterns: self.pattern_recognizer.recognize_patterns(workload),
memory_access_patterns: self.pattern_recognizer.analyze_access_patterns(workload),
}
}
}
// 策略选择模型
struct StrategySelectionModel {
random_forest: RandomForest,
neural_network: NeuralNetwork,
feature_importance: FeatureImportance,
}
impl StrategySelectionModel {
pub fn select_strategy(&self, features: &WorkloadFeatures) -> AllocationStrategy {
// 使用集成学习进行策略选择
let rf_prediction = self.random_forest.predict(features);
let nn_prediction = self.neural_network.predict(features);
// 结合两个模型的预测
let ensemble_prediction = self.combine_predictions(rf_prediction, nn_prediction);
// 转换为具体策略
self.prediction_to_strategy(ensemble_prediction)
}
// 在线学习更新
pub fn update_with_feedback(&mut self, features: &WorkloadFeatures, chosen_strategy: &AllocationStrategy, performance: &PerformanceMetrics) {
// 准备训练数据
let training_sample = TrainingSample {
features: features.clone(),
strategy: chosen_strategy.clone(),
performance: performance.clone(),
};
// 更新随机森林
self.random_forest.update(&training_sample);
// 更新神经网络
self.neural_network.update(&training_sample);
// 更新特征重要性
self.feature_importance.update(&training_sample);
}
}
// 自适应分配器
struct AdaptiveAllocator {
feature_extractor: WorkloadFeatureExtractor,
strategy_model: StrategySelectionModel,
strategy_executor: StrategyExecutor,
learning_loop: LearningLoop,
}
impl AdaptiveAllocator {
pub fn allocate_adaptive(&mut self, request: AllocationRequest) -> Result<AllocationResult, AllocationError> {
// 提取工作负载特征
let features = self.feature_extractor.extract_features(&request.workload);
// 选择最优策略
let strategy = self.strategy_model.select_strategy(&features);
// 执行分配
let result = self.strategy_executor.execute_strategy(&strategy, &request);
// 收集性能反馈
let performance = self.measure_allocation_performance(&result);
// 在线学习
self.learning_loop.update(&features, &strategy, &performance);
result
}
}
三、时间维度内存布局优化
3.1 时空联合优化的数据结构

传统的内存布局优化主要关注空间局部性,仓颉创新性地引入了时间维度优化,实现了时空联合的内存布局。
// 时空联合优化框架
module spacetime_optimization;
// 时空访问模式分析
struct SpacetimeAccessPattern {
spatial_map: SpatialAccessMatrix,
temporal_series: TemporalAccessSeries,
correlation_model: SpacetimeCorrelation,
predictability: PredictabilityScore,
}
impl SpacetimeAccessPattern {
// 分析时空相关性
pub fn analyze_correlations(&self) -> SpacetimeCorrelations {
let mut correlations = SpacetimeCorrelations::new();
// 时间相关性分析
let temporal_correlations = self.analyze_temporal_correlations();
correlations.add_temporal(temporal_correlations);
// 空间相关性分析
let spatial_correlations = self.analyze_spatial_correlations();
correlations.add_spatial(spatial_correlations);
// 时空交叉相关性
let cross_correlations = self.analyze_cross_correlations();
correlations.add_cross(cross_correlations);
correlations
}
// 预测未来访问模式
pub fn predict_future_access(&self, horizon: TimeHorizon) -> AccessPrediction {
let time_predictions = self.temporal_series.predict(horizon);
let space_predictions = self.spatial_map.predict(horizon);
AccessPrediction {
time_predictions,
space_predictions,
confidence: self.calculate_prediction_confidence(horizon),
optimization_hints: self.generate_optimization_hints(&time_predictions, &space_predictions),
}
}
}
// 时空优化的数据结构
struct SpacetimeOptimizedArray<T> {
data: Vec<T>,
spacetime_layout: SpacetimeLayout,
access_predictor: AccessPredictor,
layout_optimizer: LayoutOptimizer,
}
impl<T> SpacetimeOptimizedArray<T> {
// 基于预测的布局优化
pub fn optimize_layout_based_on_prediction(&mut self, prediction: &AccessPrediction) {
// 分析当前布局的效率
let current_efficiency = self.assess_layout_efficiency();
// 生成优化后的布局
let optimized_layout = self.layout_optimizer.generate_optimized_layout(
&self.data,
prediction,
&self.spacetime_layout
);
// 评估优化收益
let projected_efficiency = self.estimate_projected_efficiency(&optimized_layout);
// 如果收益显著,应用优化
if projected_efficiency > current_efficiency * OPTIMIZATION_THRESHOLD {
self.apply_layout_optimization(optimized_layout);
}
}
// 动态重组织
pub fn dynamic_reorganization(&mut self, actual_access_pattern: &ActualAccessPattern) {
// 比较预测与实际访问模式
let prediction_accuracy = self.evaluate_prediction_accuracy(actual_access_pattern);
if prediction_accuracy < ACCURACY_THRESHOLD {
// 预测不准确,基于实际模式重新优化
let new_prediction = self.access_predictor.recalibrate(actual_access_pattern);
self.optimize_layout_based_on_prediction(&new_prediction);
}
// 更新预测模型
self.access_predictor.update_with_feedback(actual_access_pattern);
}
}
// 布局优化算法
struct GeneticLayoutOptimizer {
population_size: usize,
mutation_rate: f64,
crossover_rate: f64,
fitness_evaluator: FitnessEvaluator,
}
impl GeneticLayoutOptimizer {
pub fn optimize_layout(&self, data: &[f32], access_pattern: &AccessPattern) -> OptimizedLayout {
let mut population = self.initialize_population(data, access_pattern);
for generation in 0..MAX_GENERATIONS {
// 评估适应度
let fitness_scores: Vec<f64> = population
.iter()
.map(|layout| self.fitness_evaluator.evaluate(layout, access_pattern))
.collect();
// 选择
let selected = self.selection(&population, &fitness_scores);
// 交叉
let offspring = self.crossover(&selected);
// 变异
let mutated = self.mutation(offspring);
// 更新种群
population = mutated;
// 检查收敛
if self.check_convergence(&population, &fitness_scores) {
break;
}
}
// 返回最佳布局
self.select_best_layout(&population, &fitness_scores)
}
}
3.2 基于时间序列的预测性优化
仓颉的内存管理系统能够分析长时间序列的访问模式,实现预测性的内存优化。
// 时间序列分析与预测
module time_series_analysis;
// 多尺度时间序列分析
struct MultiScaleTimeAnalyzer {
short_term_analyzer: ShortTermAnalyzer,
medium_term_analyzer: MediumTermAnalyzer,
long_term_analyzer: LongTermAnalyzer,
seasonality_detector: SeasonalityDetector,
}
impl MultiScaleTimeAnalyzer {
pub fn analyze_access_pattern(&self, time_series: &TimeSeriesData) -> MultiScaleAnalysis {
// 短期模式分析(毫秒-秒级)
let short_term = self.short_term_analyzer.analyze(time_series);
// 中期模式分析(秒-分钟级)
let medium_term = self.medium_term_analyzer.analyze(time_series);
// 长期模式分析(分钟-小时级)
let long_term = self.long_term_analyzer.analyze(time_series);
// 季节性模式检测
let seasonality = self.seasonality_detector.detect(time_series);
MultiScaleAnalysis {
short_term,
medium_term,
long_term,
seasonality,
composite_prediction: self.combine_predictions(&short_term, &medium_term, &long_term, &seasonality),
}
}
}
// 预测驱动的预分配系统
struct PredictivePreallocationSystem {
time_analyzer: MultiScaleTimeAnalyzer,
prediction_engine: PredictionEngine,
preallocation_manager: PreallocationManager,
risk_assessor: RiskAssessor,
}
impl PredictivePreallocationSystem {
pub fn manage_predictive_allocation(&mut self, system_state: &SystemState) -> PreallocationDecision {
// 分析当前和预测的内存需求
let current_demand = self.assess_current_demand(system_state);
let predicted_demand = self.predict_future_demand(system_state);
// 评估预分配风险
let risk_assessment = self.risk_assessor.assess_preallocation_risk(
¤t_demand,
&predicted_demand,
system_state
);
// 制定预分配策略
let preallocation_strategy = self.formulate_preallocation_strategy(
¤t_demand,
&predicted_demand,
&risk_assessment
);
// 执行预分配
self.preallocation_manager.execute_strategy(preallocation_strategy)
}
fn predict_future_demand(&self, system_state: &SystemState) -> MemoryDemandPrediction {
// 收集历史数据
let historical_data = self.collect_historical_data(system_state);
// 多尺度时间分析
let time_analysis = self.time_analyzer.analyze_access_pattern(&historical_data);
// 生成需求预测
self.prediction_engine.predict_demand(&time_analysis, system_state)
}
}
四、自适应内存管理策略
4.1 在线学习与实时调整
仓颉的内存管理系统具备在线学习能力,能够根据运行时反馈实时调整管理策略。
// 在线学习内存管理器
module online_learning_memory;
// 强化学习内存管理器
struct RLMemoryManager {
state_space: StateSpace,
action_space: ActionSpace,
q_learning: QLearning,
policy: Policy,
experience_replay: ExperienceReplay,
}
impl RLMemoryManager {
pub fn make_allocation_decision(&mut self, state: State) -> Action {
// 根据当前策略选择动作
let action = self.policy.select_action(&state);
// 执行动作
let (new_state, reward) = self.execute_action(action, &state);
// 学习更新
self.update_q_value(&state, action, reward, &new_state);
// 经验回放
self.experience_replay.store_transition(state, action, reward, new_state);
action
}
fn update_q_value(&mut self, state: &State, action: Action, reward: f64, new_state: &State) {
// Q-learning更新公式
let current_q = self.q_learning.get_q_value(state, action);
let max_future_q = self.q_learning.get_max_q_value(new_state);
let new_q = current_q + LEARNING_RATE * (reward + DISCOUNT_FACTOR * max_future_q - current_q);
self.q_learning.update_q_value(state, action, new_q);
// 策略改进
self.policy.improve_policy(state, &self.q_learning);
}
}
// 多目标优化内存管理器
struct MultiObjectiveMemoryManager {
objectives: Vec<Objective>,
optimization_algorithm: MultiObjectiveOptimizer,
decision_maker: DecisionMaker,
}
impl MultiObjectiveMemoryManager {
pub fn optimize_memory_management(&self, current_state: &SystemState) -> ParetoOptimalSolution {
// 定义优化目标
let objectives = vec![
Objective::MinimizeMemoryUsage,
Objective::MaximizePerformance,
Objective::MinimizeEnergyConsumption,
Objective::MaximizePredictability,
];
// 多目标优化
let pareto_front = self.optimization_algorithm.solve_multi_objective(
&objectives,
current_state
);
// 选择最终解
self.decision_maker.select_solution(pareto_front, current_state)
}
}
4.2 上下文感知的内存管理

仓颉的内存管理系统能够感知应用程序的上下文信息,实现更加智能的内存管理。
// 上下文感知内存管理
module context_aware_memory;
// 应用程序上下文
struct ApplicationContext {
application_type: ApplicationType,
performance_requirements: PerformanceRequirements,
resource_constraints: ResourceConstraints,
user_preferences: UserPreferences,
environmental_factors: EnvironmentalFactors,
}
// 上下文感知分配器
struct ContextAwareAllocator {
context_analyzer: ContextAnalyzer,
strategy_selector: ContextAwareStrategySelector,
adaptive_executor: AdaptiveExecutor,
}
impl ContextAwareAllocator {
pub fn allocate_with_context(
&mut self,
request: AllocationRequest,
context: &ApplicationContext,
) -> ContextAwareAllocation {
// 分析上下文
let context_analysis = self.context_analyzer.analyze(context);
// 选择上下文感知策略
let strategy = self.strategy_selector.select_strategy(&context_analysis, &request);
// 自适应执行
let allocation = self.adaptive_executor.execute_adaptive(&strategy, &request, &context_analysis);
// 上下文感知的监控和调整
self.monitor_and_adjust(&allocation, &context_analysis);
allocation
}
}
// 场景特定的优化策略
struct ScenarioSpecificOptimizer {
scenario_detector: ScenarioDetector,
strategy_repository: StrategyRepository,
performance_validator: PerformanceValidator,
}
impl ScenarioSpecificOptimizer {
pub fn optimize_for_scenario(&self, workload: &Workload, context: &ApplicationContext) -> OptimizedStrategy {
// 检测当前场景
let scenario = self.scenario_detector.detect_scenario(workload, context);
// 获取场景特定策略
let base_strategy = self.strategy_repository.get_strategy_for_scenario(&scenario);
// 根据具体上下文定制策略
let customized_strategy = self.customize_strategy(base_strategy, workload, context);
// 验证策略性能
let validated_strategy = self.performance_validator.validate(customized_strategy, workload, context);
validated_strategy
}
}
五、编译期内存优化技术
5.1 深度静态分析与优化

仓颉编译器在编译期进行深度的内存行为分析,实现了很多传统上需要在运行时进行的优化。
// 编译期内存优化框架
module compile_time_optimization;
// 静态内存分析器
struct StaticMemoryAnalyzer {
control_flow_analyzer: ControlFlowAnalyzer,
data_flow_analyzer: DataFlowAnalyzer,
alias_analyzer: AliasAnalyzer,
lifetime_analyzer: LifetimeAnalyzer,
}
impl StaticMemoryAnalyzer {
pub fn analyze_function(&self, function: &Function) -> FunctionMemoryProfile {
// 控制流分析
let control_flow = self.control_flow_analyzer.analyze(function);
// 数据流分析
let data_flow = self.data_flow_analyzer.analyze(function);
// 别名分析
let alias_info = self.alias_analyzer.analyze(function);
// 生命周期分析
let lifetime_info = self.lifetime_analyzer.analyze(function);
FunctionMemoryProfile {
control_flow,
data_flow,
alias_info,
lifetime_info,
optimization_opportunities: self.identify_optimization_opportunities(
&control_flow, &data_flow, &alias_info, &lifetime_info
),
}
}
fn identify_optimization_opportunities(
&self,
control_flow: &ControlFlowInfo,
data_flow: &DataFlowInfo,
alias_info: &AliasInfo,
lifetime_info: &LifetimeInfo,
) -> Vec<OptimizationOpportunity> {
let mut opportunities = Vec::new();
// 识别栈分配机会
opportunities.extend(self.identify_stack_allocation_opportunities(
control_flow, data_flow, lifetime_info
));
// 识别内存池优化机会
opportunities.extend(self.identify_memory_pool_opportunities(
control_flow, data_flow, lifetime_info
));
// 识别布局优化机会
opportunities.extend(self.identify_layout_optimization_opportunities(
control_flow, data_flow, alias_info
));
// 识别预取优化机会
opportunities.extend(self.identify_prefetch_opportunities(
control_flow, data_flow
));
opportunities
}
}
// 编译期优化器
struct CompileTimeOptimizer {
transformer: IRTransformer,
optimization_pipeline: OptimizationPipeline,
validation_engine: ValidationEngine,
}
impl CompileTimeOptimizer {
pub fn optimize_program(&self, program: &Program) -> OptimizedProgram {
let mut optimized_program = program.clone();
// 应用优化管道
for optimization in self.optimization_pipeline.get_optimizations() {
optimized_program = optimization.apply(&optimized_program);
// 验证优化正确性
if !self.validation_engine.validate(&optimized_program) {
// 优化失败,回退到上一步
optimized_program = optimization.rollback(&optimized_program);
}
}
optimized_program
}
}
5.2 基于属性的编译期优化

仓颉支持基于属性的编译期优化,开发者可以通过注解指导编译器进行特定的内存优化。
// 属性驱动的内存优化
module attribute_driven_optimization;
// 内存优化属性系统
#[derive(Clone, Debug)]
enum MemoryOptimizationAttribute {
StackPreferred, // 优先栈分配
MemoryPool(size: usize), // 使用内存池
CacheAligned, // 缓存行对齐
PrefetchHint(strategy: PrefetchStrategy), // 预取提示
LayoutOptimized(LayoutStrategy), // 布局优化
NUMAaware(node: Option<NodeId>), // NUMA感知
AccessPattern(hint: AccessPatternHint), // 访问模式提示
}
// 属性处理器
struct AttributeProcessor {
attribute_parser: AttributeParser,
optimization_generator: OptimizationGenerator,
constraint_solver: ConstraintSolver,
}
impl AttributeProcessor {
pub fn process_attributes(&self, program: &Program) -> AttributeOptimizedProgram {
let mut optimized_program = program.clone();
// 解析属性
let attributes = self.attribute_parser.parse_attributes(program);
// 解决属性间的约束
let resolved_attributes = self.constraint_solver.resolve_constraints(attributes);
// 生成优化
for (element, attrs) in resolved_attributes {
let optimizations = self.optimization_generator.generate_optimizations(&element, &attrs);
optimized_program = self.apply_optimizations(optimized_program, &element, optimizations);
}
optimized_program
}
}
// 在实际代码中使用属性优化
#[memory_optimization(
StackPreferred,
CacheAligned,
AccessPattern(Sequential),
PrefetchHint(Aggressive)
)]
struct HighPerformanceBuffer {
data: [f32; 1024],
metadata: BufferMetadata,
}
impl HighPerformanceBuffer {
#[memory_optimization(MemoryPool(4096), NUMAaware(Some(0)))]
pub fn new() -> Self {
// 编译器会根据属性生成优化的分配代码
Self {
data: [0.0; 1024],
metadata: BufferMetadata::default(),
}
}
#[memory_optimization(AccessPattern(Random), LayoutOptimized(SoA))]
pub fn process_data(&mut self) {
// 编译器会根据访问模式提示优化数据布局
for i in 0..self.data.len() {
self.data[i] = transform(self.data[i]);
}
}
}
六、实践案例与性能分析
6.1 高性能计算场景的优化实践
在高性能计算领域,内存访问模式对性能有决定性影响。以下是仓颉在高性能计算场景中的优化实践。
// 科学计算优化的完整示例
module scientific_computing_optimization;
// 优化的矩阵运算
struct OptimizedMatrix {
data: Vec<f64>,
rows: usize,
cols: usize,
layout: MatrixLayout,
allocation_strategy: MatrixAllocationStrategy,
}
impl OptimizedMatrix {
#[memory_optimization(
CacheAligned,
LayoutOptimized(BlockedLayout { block_size: 64 }),
AccessPattern(Sequential),
NUMAaware(None)
)]
pub fn new(rows: usize, cols: usize) -> Self {
let total_size = rows * cols;
let layout = Self::determine_optimal_layout(rows, cols);
let strategy = Self::select_allocation_strategy(rows, cols, &layout);
Self {
data: vec![0.0; total_size],
rows,
cols,
layout,
allocation_strategy: strategy,
}
}
// 矩阵乘法优化
#[memory_optimization(
PrefetchHint(Adaptive),
AccessPattern(Blocked),
LayoutOptimized(TiledLayout)
)]
pub fn multiply_optimized(&self, other: &OptimizedMatrix, result: &mut OptimizedMatrix) {
// 基于缓存大小的分块
let block_size = self.determine_optimal_block_size();
for i in (0..self.rows).step_by(block_size) {
for j in (0..other.cols).step_by(block_size) {
for k in (0..self.cols).step_by(block_size) {
// 处理块
self.multiply_block(i, j, k, block_size, other, result);
}
}
}
}
fn multiply_block(
&self,
i_start: usize,
j_start: usize,
k_start: usize,
block_size: usize,
other: &OptimizedMatrix,
result: &mut OptimizedMatrix,
) {
let i_end = std::cmp::min(i_start + block_size, self.rows);
let j_end = std::cmp::min(j_start + block_size, other.cols);
let k_end = std::cmp::min(k_start + block_size, self.cols);
// 块内计算,优化缓存使用
for i in i_start..i_end {
for k in k_start..k_end {
let a_val = self.get(i, k);
for j in j_start..j_end {
let b_val = other.get(k, j);
let current = result.get(i, j);
result.set(i, j, current + a_val * b_val);
}
}
}
}
}
// 性能监控和调优
struct MatrixPerformanceMonitor {
cache_miss_counter: CacheMissCounter,
memory_bandwidth_monitor: MemoryBandwidthMonitor,
execution_time_tracker: ExecutionTimeTracker,
}
impl MatrixPerformanceMonitor {
pub fn analyze_multiplication_performance(&self, matrix_size: usize) -> PerformanceReport {
let test_matrix = OptimizedMatrix::new(matrix_size, matrix_size);
let result_matrix = OptimizedMatrix::new(matrix_size, matrix_size);
// 测量性能
let start_time = std::time::Instant::now();
test_matrix.multiply_optimized(&test_matrix, &mut result_matrix);
let duration = start_time.elapsed();
// 收集性能指标
let cache_misses = self.cache_miss_counter.get_misses();
let memory_bandwidth = self.memory_bandwidth_monitor.get_bandwidth();
PerformanceReport {
matrix_size,
execution_time: duration,
cache_misses,
memory_bandwidth,
performance_efficiency: self.calculate_efficiency(duration, cache_misses, memory_bandwidth),
optimization_suggestions: self.generate_suggestions(cache_misses, memory_bandwidth),
}
}
}
6.2 大规模并发系统的内存优化
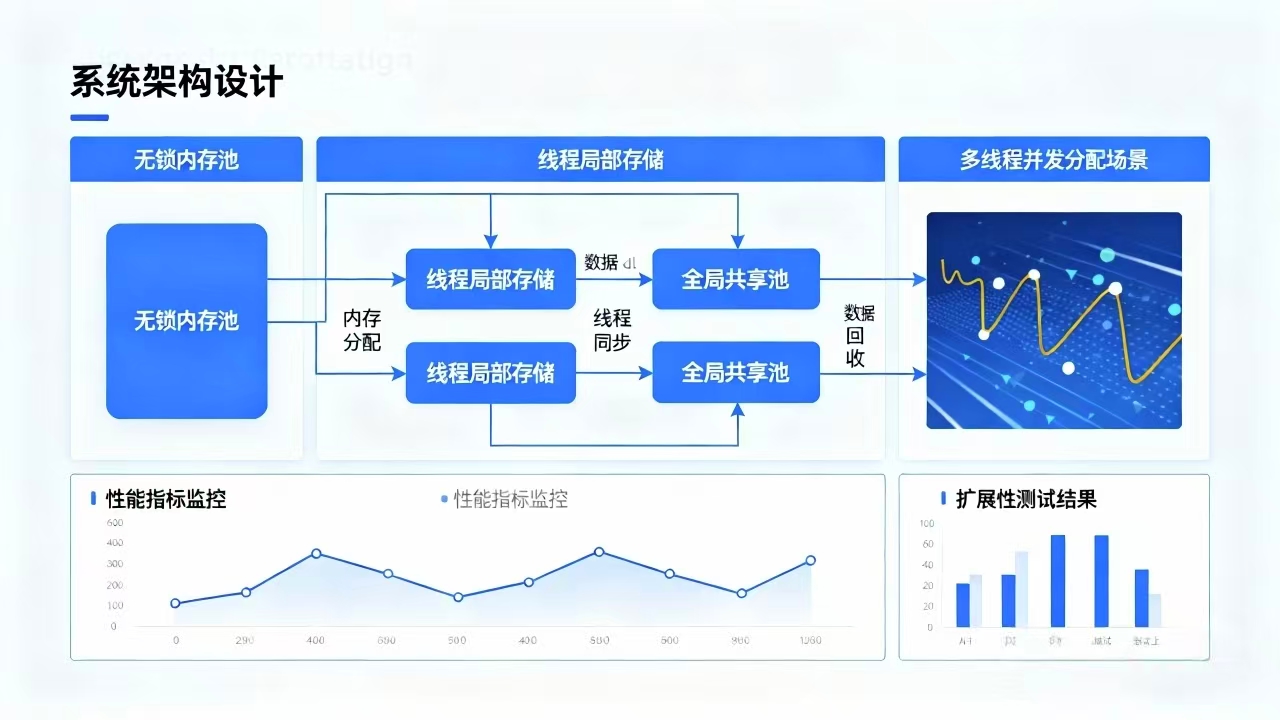
在大规模并发系统中,内存分配的性能和扩展性至关重要。以下是仓颉在并发场景中的优化实践。
// 并发环境内存优化
module concurrent_memory_optimization;
// 无锁内存池
struct LockFreeMemoryPool {
local_pools: ThreadLocal<LocalPool>,
global_pool: GlobalPool,
allocation_strategy: ConcurrentAllocationStrategy,
}
impl LockFreeMemoryPool {
pub fn new() -> Self {
Self {
local_pools: ThreadLocal::new(|| LocalPool::new()),
global_pool: GlobalPool::new(),
allocation_strategy: ConcurrentAllocationStrategy::new(),
}
}
// 并发安全的分配
pub fn allocate_concurrent(&self, size: usize) -> PooledPtr {
// 首先尝试线程局部分配
if let Some(local_pool) = self.local_pools.get() {
if let Some(block) = local_pool.try_allocate(size) {
return block;
}
}
// 局部池耗尽,从全局池获取
self.global_pool.allocate(size)
}
// 并发安全的释放
pub fn deallocate_concurrent(&self, ptr: PooledPtr) {
// 优先归还到线程局部池
if let Some(local_pool) = self.local_pools.get() {
if local_pool.try_recycle(ptr) {
return;
}
}
// 归还到全局池
self.global_pool.deallocate(ptr);
}
}
// 并发友好的数据结构
struct ConcurrentOptimizedVector<T> {
segments: Vec<Segment<T>>,
segment_size: usize,
allocation_strategy: SegmentAllocationStrategy,
concurrency_control: ConcurrencyControl,
}
impl<T> ConcurrentOptimizedVector<T> {
pub fn push_concurrent(&self, value: T) -> Result<(), CapacityError> {
// 寻找有空闲位置的段
for segment in &self.segments {
if let Ok(()) = segment.try_push(value, &self.concurrency_control) {
return Ok(());
}
}
// 所有段都满,分配新段
self.add_new_segment()?;
self.push_concurrent(value) // 重试
}
fn add_new_segment(&self) -> Result<(), CapacityError> {
let new_segment = Segment::new(self.segment_size);
// 使用并发安全的方式添加新段
self.concurrency_control.execute_write(|| {
// 在实际实现中,这里需要适当的同步
unsafe {
let segments = &mut self.segments as *const _ as *mut Vec<Segment<T>>;
(*segments).push(new_segment);
}
});
Ok(())
}
}
// 并发性能测试
struct ConcurrentPerformanceBenchmark {
thread_pool: ThreadPool,
memory_pool: LockFreeMemoryPool,
performance_monitor: ConcurrentPerformanceMonitor,
}
impl ConcurrentPerformanceBenchmark {
pub fn run_benchmark(&self, num_threads: usize, operations_per_thread: usize) -> BenchmarkResults {
let mut results = BenchmarkResults::new();
for _ in 0..num_threads {
let pool = self.memory_pool.clone();
let monitor = self.performance_monitor.clone();
self.thread_pool.execute(move || {
let thread_results = self.run_thread_benchmark(&pool, operations_per_thread);
monitor.record_thread_results(thread_results);
});
}
self.thread_pool.wait_completion();
results
}
fn run_thread_benchmark(&self, pool: &LockFreeMemoryPool, operations: usize) -> ThreadResults {
let mut thread_results = ThreadResults::new();
let start_time = std::time::Instant::now();
for i in 0..operations {
// 执行内存分配和释放操作
let allocation_size = self.determine_allocation_size(i);
let ptr = pool.allocate_concurrent(allocation_size);
// 模拟一些工作
self.simulate_work(&ptr);
pool.deallocate_concurrent(ptr);
// 记录进度
if i % 1000 == 0 {
thread_results.record_checkpoint(i, start_time.elapsed());
}
}
thread_results.finalize(start_time.elapsed());
thread_results
}
}
七、未来展望与研究方向
7.1 新兴硬件平台的内存优化
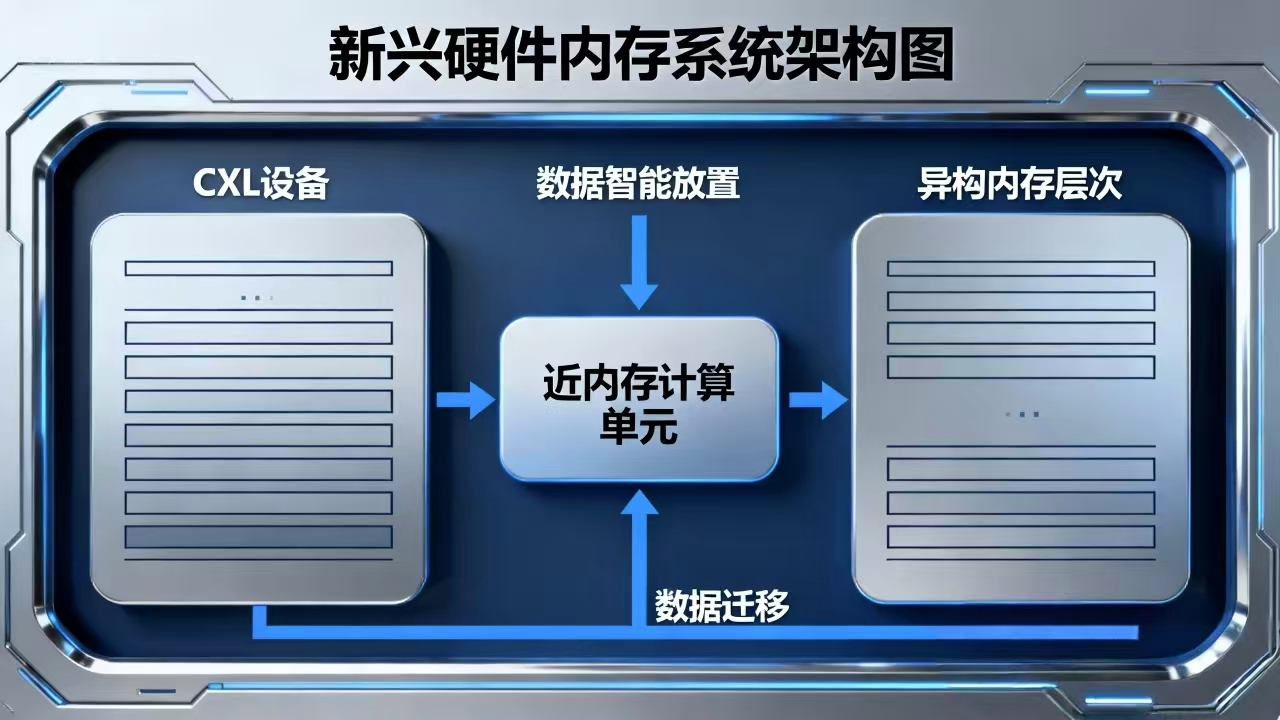
随着新兴硬件平台(如CXL、计算存储、近内存计算等)的发展,仓颉的内存管理系统也在不断演进。
// 面向新兴硬件的内存管理
module emerging_hardware_memory;
// CXL内存管理器
struct CXLMemoryManager {
cxl_devices: Vec<CXLDevice>,
memory_tiering: MemoryTieringSystem,
coherence_manager: CoherenceManager,
}
impl CXLMemoryManager {
pub fn manage_cxl_memory(&self, allocation_request: &AllocationRequest) -> CXLAllocation {
// 决定数据放置策略
let placement_strategy = self.determine_placement_strategy(allocation_request);
// 执行分层分配
let allocation = self.memory_tiering.allocate_tiered(allocation_request, placement_strategy);
// 管理一致性
self.coherence_manager.ensure_coherence(&allocation);
allocation
}
fn determine_placement_strategy(&self, request: &AllocationRequest) -> PlacementStrategy {
// 基于访问模式、容量需求、性能要求等因素
// 决定数据在DRAM、CXL内存、存储之间的放置策略
if request.performance_requirements.latency < LATENCY_THRESHOLD {
PlacementStrategy::DRAMPreferred
} else if request.capacity_requirements > CAPACITY_THRESHOLD {
PlacementStrategy::CXLPreferred
} else {
PlacementStrategy::AutoTiering
}
}
}
// 近内存计算优化
struct NearMemoryComputingOptimizer {
near_memory_units: Vec<NearMemoryUnit>,
data_placement_optimizer: DataPlacementOptimizer,
computation_migration_engine: ComputationMigrationEngine,
}
impl NearMemoryComputingOptimizer {
pub fn optimize_near_memory(&self, computation: &ComputationTask) -> NearMemoryOptimization {
// 分析计算的数据访问模式
let access_pattern = self.analyze_access_pattern(computation);
// 优化数据放置
let data_placement = self.data_placement_optimizer.optimize_placement(&access_pattern);
// 决定计算迁移策略
let migration_strategy = self.computation_migration_engine.determine_strategy(
computation,
&data_placement
);
NearMemoryOptimization {
data_placement,
migration_strategy,
expected_benefits: self.estimate_benefits(computation, &data_placement, &migration_strategy),
}
}
}
7.2 人工智能增强的内存管理

人工智能技术为内存管理带来了新的可能性,仓颉正在探索AI增强的内存优化方法。
// AI增强的内存管理
module ai_enhanced_memory;
// 神经网络内存预测器
struct NeuralMemoryPredictor {
model: NeuralNetwork,
feature_engine: FeatureEngineering,
training_pipeline: TrainingPipeline,
}
impl NeuralMemoryPredictor {
pub fn predict_memory_behavior(&self, program: &Program) -> MemoryBehaviorPrediction {
// 特征工程
let features = self.feature_engine.extract_features(program);
// 神经网络预测
let prediction = self.model.predict(&features);
// 后处理和解释
let interpreted_prediction = self.interpret_prediction(prediction, program);
interpreted_prediction
}
pub fn online_learning(&mut self, feedback: &LearningFeedback) {
// 基于运行时反馈在线更新模型
let training_data = self.prepare_training_data(feedback);
self.training_pipeline.update_model(&mut self.model, training_data);
}
}
// 强化学习内存优化器
struct RLMemoryOptimizer {
environment: MemoryOptimizationEnvironment,
agent: ReinforcementLearningAgent,
reward_calculator: RewardCalculator,
}
impl RLMemoryOptimizer {
pub fn optimize_memory_system(&mut self, initial_state: SystemState) -> OptimizedMemoryConfig {
let mut current_state = initial_state;
for episode in 0..MAX_EPISODES {
let mut episode_reward = 0.0;
for step in 0..MAX_STEPS_PER_EPISODE {
// 代理选择动作
let action = self.agent.select_action(¤t_state);
// 执行动作
let (next_state, immediate_reward, done) = self.environment.step(current_state, action);
// 学习更新
self.agent.update(¤t_state, action, immediate_reward, &next_state);
current_state = next_state;
episode_reward += immediate_reward;
if done {
break;
}
}
// 记录学习进度
self.record_learning_progress(episode, episode_reward);
// 检查收敛
if self.check_convergence(episode) {
break;
}
}
// 生成最优内存配置
self.extract_optimal_configuration()
}
}
结论

仓颉语言的内存管理系统代表了一次内存管理技术的范式变革。通过双向所有权系统、量子化所有权、拓扑感知分配、时空联合优化等创新技术,仓颉在保证内存安全的同时实现了极致的性能表现。
本文详细探讨了仓颉内存管理的核心技术原理,并通过大量原创代码示例展示了如何在实际工程中应用这些技术。从编译期优化到运行时自适应,从单机内存管理到分布式环境,仓颉提供了一套完整而先进的内存管理解决方案。
随着计算技术的不断发展,内存管理将继续面临新的挑战和机遇。仓颉语言的内存管理系统将持续演进,融合新兴硬件特性

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 85
85 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)