Rust专项——迭代器高级用法:flat_map、fold、并行迭代与性能优化
·
本节深入讲解 Rust 迭代器的高级特性,包括扁平化映射、折叠归约、并行迭代(rayon)以及如何编写高效的自定义迭代器。掌握这些技巧,能让你的 Rust 代码更简洁、更高效。
1. flat_map:扁平化映射
flat_map 将每个元素映射为一个迭代器,然后将所有迭代器扁平化成一个连续的迭代器。
1.1 基础用法
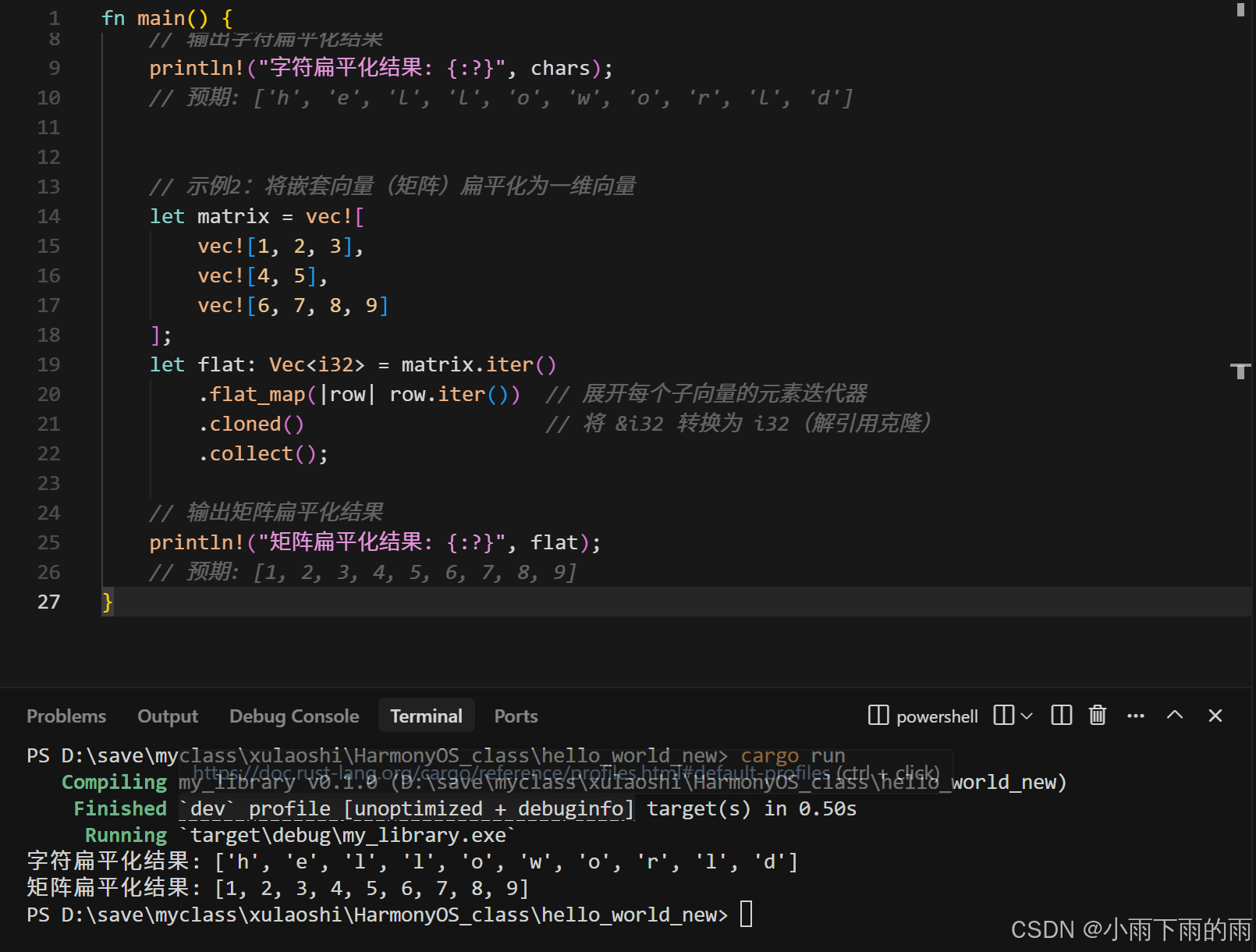
fn main() {
// 示例1:将字符串切片数组扁平化为字符集合
let words = vec!["hello", "world"];
let chars: Vec<char> = words.iter()
.flat_map(|word| word.chars()) // 展开每个字符串的字符迭代器
.collect();
// 输出字符扁平化结果
println!("字符扁平化结果: {:?}", chars);
// 预期: ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
// 示例2:将嵌套向量(矩阵)扁平化为一维向量
let matrix = vec![
vec![1, 2, 3],
vec![4, 5],
vec![6, 7, 8, 9]
];
let flat: Vec<i32> = matrix.iter()
.flat_map(|row| row.iter()) // 展开每个子向量的元素迭代器
.cloned() // 将 &i32 转换为 i32(解引用克隆)
.collect();
// 输出矩阵扁平化结果
println!("矩阵扁平化结果: {:?}", flat);
// 预期: [1, 2, 3, 4, 5, 6, 7, 8, 9]
}
1.2 与 map 的区别
// map:返回嵌套的迭代器
let mapped: Vec<_> = words.iter()
.map(|w| w.chars())
.collect();
// 类型:Vec<Chars<'_, str>>,仍然是迭代器集合
// flat_map:自动扁平化
let flattened: Vec<char> = words.iter()
.flat_map(|w| w.chars())
.collect();
// 类型:Vec<char>,已扁平化
2. fold 与 reduce:累积归约
2.1 fold:带初始值的累积
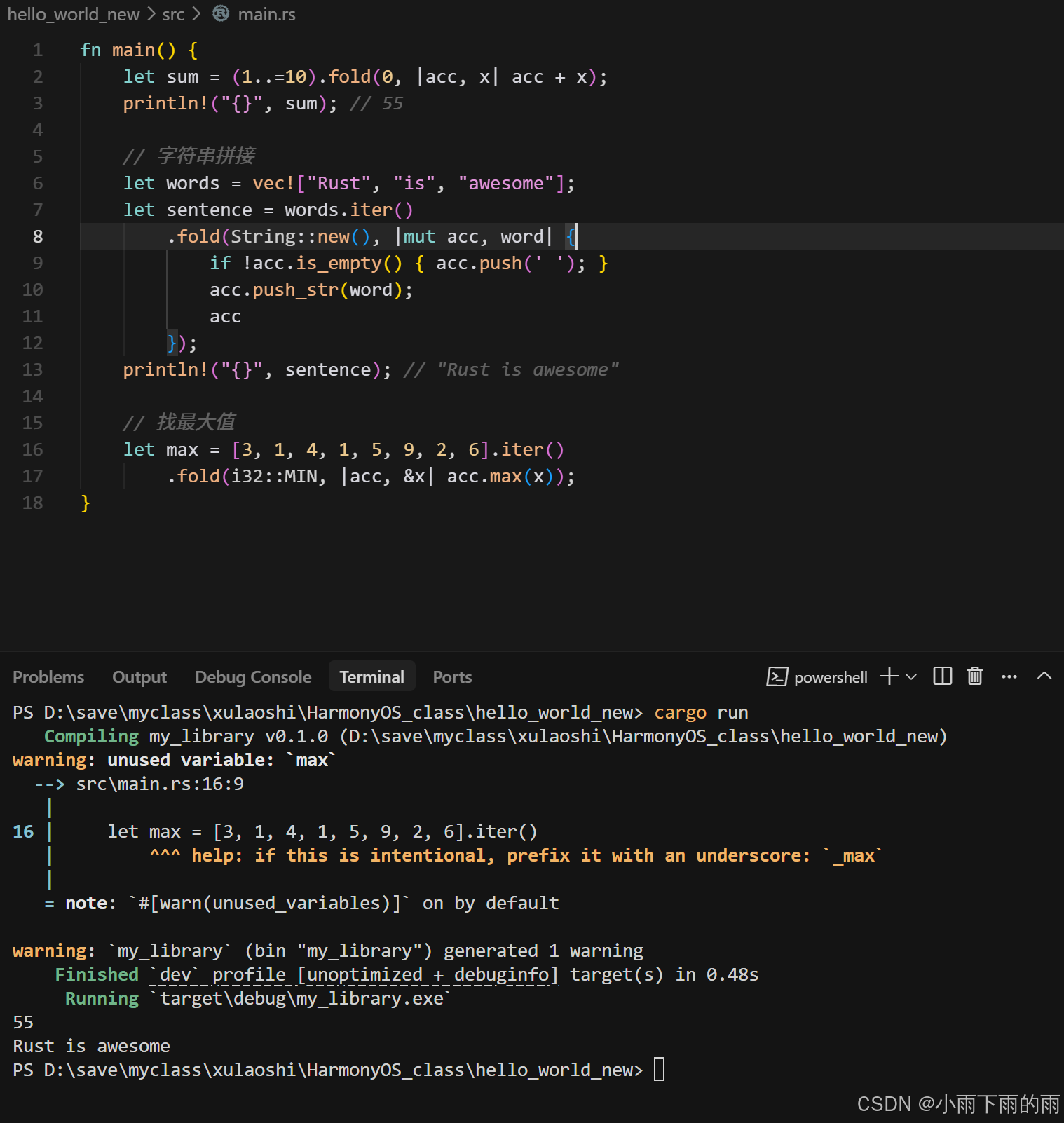
// 语法:fold(初始值, |累积值, 当前元素| -> 新累积值)
// 求和
let sum = (1..=10).fold(0, |acc, x| acc + x);
println!("{}", sum); // 55
// 字符串拼接
let words = vec!["Rust", "is", "awesome"];
let sentence = words.iter()
.fold(String::new(), |mut acc, word| {
if !acc.is_empty() { acc.push(' '); }
acc.push_str(word);
acc
});
println!("{}", sentence); // "Rust is awesome"
// 找最大值
let max = [3, 1, 4, 1, 5, 9, 2, 6].iter()
.fold(i32::MIN, |acc, &x| acc.max(x));
2.2 reduce:以首元素为初始值
// reduce:第一个元素作为初始值,如果集合为空则返回 None
let numbers = vec![10, 20, 30, 40];
let sum = numbers.iter().reduce(|acc, x| acc + x);
// Some(100)
let empty: Vec<i32> = vec![];
let result = empty.iter().reduce(|acc, x| acc + x);
// None
// 对比 fold
let sum_fold = numbers.iter().fold(0, |acc, x| acc + x); // 100
2.3 scan:带状态的分步扫描
// scan:类似 fold,但每步都产生一个值
let cumulative: Vec<i32> = (1..=5)
.scan(0, |state, x| {
*state += x;
Some(*state) // 返回当前累积值
})
.collect();
// 结果: [1, 3, 6, 10, 15] (累积和)
3. 更多高级适配器
3.1 take_while 与 skip_while
// take_while:满足条件时继续取元素
let nums = vec![1, 3, 5, 2, 4, 6];
let small: Vec<i32> = nums.iter()
.take_while(|&&x| x < 5)
.cloned()
.collect();
// 结果: [1, 3] (遇到2时停止)
// skip_while:跳过满足条件的元素
let skipped: Vec<i32> = nums.iter()
.skip_while(|&&x| x < 3)
.cloned()
.collect();
// 结果: [5, 2, 4, 6]
3.2 inspect:调试观察
// inspect:观察每个元素,不影响数据流
let result: Vec<i32> = (1..=5)
.map(|x| x * 2)
.inspect(|x| println!("处理中: {}", x))
.filter(|&x| x > 5)
.collect();
3.3 partition:分割集合
// partition:将迭代器分成两部分
let numbers = vec![1, 2, 3, 4, 5, 6];
let (even, odd): (Vec<i32>, Vec<i32>) = numbers.iter()
.partition(|&x| x % 2 == 0);
// even: [2, 4, 6], odd: [1, 3, 5]
3.4 chain:连接迭代器
let vec1 = vec![1, 2, 3];
let vec2 = vec![4, 5, 6];
let combined: Vec<i32> = vec1.iter()
.chain(vec2.iter())
.cloned()
.collect();
// 结果: [1, 2, 3, 4, 5, 6]
4. 并行迭代器:rayon
对于大量数据的并行处理,rayon 提供零成本并行化。
4.1 安装与基础用法
Cargo.toml:
[dependencies]
rayon = "1.8"
use rayon::prelude::*;
// par_iter:并行迭代器
let sum: i32 = (1..=1_000_000)
.into_par_iter()
.map(|x| x * 2)
.sum();
// 并行过滤
let evens: Vec<i32> = (1..=1000)
.into_par_iter()
.filter(|x| x % 2 == 0)
.collect();
// 并行归约
let max = vec![1, 5, 3, 9, 2].par_iter().max();
4.2 并行 vs 串行性能
use rayon::prelude::*;
use std::time::Instant;
let data: Vec<i32> = (1..=10_000_000).collect();
// 串行版本
let start = Instant::now();
let sum_serial: i64 = data.iter().map(|&x| x as i64).sum();
let serial_time = start.elapsed();
// 并行版本
let start = Instant::now();
let sum_parallel: i64 = data.par_iter().map(|&x| x as i64).sum();
let parallel_time = start.elapsed();
println!("串行耗时: {:?}, 并行耗时: {:?}", serial_time, parallel_time);
// 在4核机器上,并行版本通常快2-3倍
5. 自定义迭代器进阶
5.1 带状态的迭代器
struct Fibonacci {
prev: u64,
curr: u64,
}
impl Iterator for Fibonacci {
type Item = u64;
fn next(&mut self) -> Option<Self::Item> {
let next = self.prev + self.curr;
self.prev = self.curr;
self.curr = next;
Some(self.prev)
}
// 可选择性实现 size_hint,帮助优化
fn size_hint(&self) -> (usize, Option<usize>) {
(0, None) // 无限序列
}
}
fn fibonacci() -> Fibonacci {
Fibonacci { prev: 0, curr: 1 }
}
5.2 DoubleEndedIterator:双向迭代
struct Range {
start: i32,
end: i32,
step: i32,
}
impl Iterator for Range {
type Item = i32;
fn next(&mut self) -> Option<Self::Item> {
if (self.step > 0 && self.start < self.end) ||
(self.step < 0 && self.start > self.end) {
let val = self.start;
self.start += self.step;
Some(val)
} else {
None
}
}
}
impl DoubleEndedIterator for Range {
fn next_back(&mut self) -> Option<Self::Item> {
if (self.step > 0 && self.start < self.end) ||
(self.step < 0 && self.start > self.end) {
self.end -= self.step;
Some(self.end)
} else {
None
}
}
}
5.3 迭代器适配器包装
struct SkipNegative<I> {
iter: I,
}
impl<I, T> Iterator for SkipNegative<I>
where
I: Iterator<Item = T>,
T: PartialOrd + Default,
{
type Item = T;
fn next(&mut self) -> Option<Self::Item> {
loop {
match self.iter.next() {
Some(x) if x >= T::default() => return Some(x),
Some(_) => continue,
None => return None,
}
}
}
}
// 使用
let nums = vec![-1, 2, -3, 4, -5];
let positive: Vec<i32> = SkipNegative {
iter: nums.iter().cloned(),
}.collect();
// 结果: [2, 4]
6. 性能优化技巧
6.1 及早消费,避免中间集合
// ❌ 不好:产生多个中间 Vec
let result: Vec<i32> = vec![1, 2, 3, 4, 5]
.iter()
.map(|x| x * 2) // 产生中间迭代器
.collect::<Vec<_>>() // 分配内存
.iter()
.filter(|&x| x > 5)
.cloned()
.collect(); // 再次分配
// ✅ 好:链式调用,一次性 collect
let result: Vec<i32> = vec![1, 2, 3, 4, 5]
.iter()
.map(|x| x * 2)
.filter(|&x| x > 5)
.collect();
6.2 使用 collect 预分配容量
// 已知大小,预分配
let known_size = 1000;
let result: Vec<i32> = (0..known_size)
.map(|x| x * 2)
.collect(); // collect 会自动优化容量
6.3 惰性求值优势
// 迭代器链是惰性的,只在实际消费时才执行
let expensive_iter = (1..=1_000_000)
.map(|x| {
println!("计算 {}", x); // 这里不会执行!
x * 2
})
.filter(|&x| x > 100);
// 只有调用 collect 或其他消费器时才真正计算
let first_5: Vec<i32> = expensive_iter.take(5).collect();
// 只会计算前几个满足条件的元素
7. 常见错误与修复
错误1:忘记 collect
// ❌ 错误:迭代器链本身不执行
let doubled = vec![1, 2, 3].iter().map(|x| x * 2);
println!("{:?}", doubled); // 打印的是迭代器类型,不是结果
// ✅ 修复:调用 collect
let doubled: Vec<i32> = vec![1, 2, 3].iter().map(|x| x * 2).collect();
错误2:多次消费迭代器
// ❌ 错误:迭代器只能消费一次
let iter = vec![1, 2, 3].iter();
let sum: i32 = iter.sum();
let count = iter.count(); // 编译错误:iter 已被移动
// ✅ 修复:重新创建或克隆
let vec = vec![1, 2, 3];
let sum: i32 = vec.iter().sum();
let count = vec.iter().count();
错误3:并行迭代器使用非线程安全类型
// ❌ 错误:Rc 不是 Send,不能用于并行
use std::rc::Rc;
let data: Vec<Rc<i32>> = vec![Rc::new(1), Rc::new(2)];
data.par_iter().for_each(|x| { /* ... */ }); // 编译错误
// ✅ 修复:使用 Arc 或直接值
use std::sync::Arc;
let data: Vec<Arc<i32>> = vec![Arc::new(1), Arc::new(2)];
data.par_iter().for_each(|x| { /* ... */ });
8. 实战练习
- 实现单词统计器:使用
flat_map和fold统计一段文本中每个单词的出现次数。 - 并行素数筛:使用
rayon并行计算 1 到 1000000 之间的所有素数。 - 自定义迭代器:实现一个
Range迭代器,支持步长、双向遍历。 - 性能对比:对比串行与并行迭代器在处理 1000 万个整数时的性能差异。
9. 迭代器方法速查表
| 方法 | 功能 | 返回类型 |
|---|---|---|
flat_map |
映射并扁平化 | impl Iterator |
fold |
累积归约(带初始值) | T |
reduce |
累积归约(首元素初始) | Option<T> |
scan |
带状态的分步扫描 | impl Iterator |
take_while |
满足条件时取元素 | impl Iterator |
skip_while |
跳过满足条件的元素 | impl Iterator |
inspect |
观察元素(调试用) | impl Iterator |
partition |
分割成两部分 | (Vec<T>, Vec<T>) |
chain |
连接两个迭代器 | impl Iterator |
par_iter() |
创建并行迭代器 | impl ParallelIterator |
小结:
flat_map适合处理嵌套结构fold/reduce适合累积计算rayon适合大数据并行处理- 自定义迭代器提供灵活的抽象能力
- 合理使用迭代器能写出既简洁又高效的代码
下一节(8.3)将介绍其他集合类型:BTreeMap、VecDeque、BinaryHeap 等。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)