Rust:重塑编程世界的新力量
目录
前言:Rust 掀起的编程风暴
自 2010 年问世以来,Rust 凭借所有权、借用与生命周期等创新机制,把 C/C++ 常见的空指针、缓冲区溢出等内存隐患直接消灭在编译期,而且它保持与 C 比肩的性能,并天生支持高并发,所以在 Stack Overflow 开发者调查中连续多年蝉联“最受欢迎的编程语言”。这份人气迅速转化为工业界的广泛落地,比如Mozilla 用 Rust 重构 Firefox 核心组件,显著提升了浏览器的稳定性与速度;又如Cloudflare 把 Rust 写进网络栈,以应对每秒千万级请求并降低服务中断风险;再如微软更将 Rust 引入 Windows 内核,借助其内存安全和高性能双重优势加固操作系统根基。除了系统级场景,Rust 还在区块链和 WebAssembly 两大前沿阵地大放异彩,Parity Ethereum 等底层链选择 Rust 构建高可靠性的共识与执行引擎,而 Rust-to-WebAssembly 的流畅工具链则让浏览器端也能跑出原生级性能。随着 crates.io 上覆盖网络、AI、图形、密码学等海量高质量库的持续涌现,Rust 的生态系统已日臻成熟,为开发者提供了开箱即用的生产力。从内存安全到并发模型,从内核到浏览器,Rust 正以独树一帜的技术哲学和日益壮大的社区生态,在竞争激烈的编程语言舞台上掀起一场席卷系统与应用、后端与前端、当下与未来的“安全高性能”编程风暴。那么本文就来详细介绍一下Rust相关的内容,方便大家一起交流讨论。

Rust 初印象:独特魅力大揭秘
先来介绍一下关于Rust相关的历史。
1、诞生传奇与发展征程
其实Rust 的诞生充满了传奇色彩,它源于 Mozilla 工程师 Graydon Hoare 对现有编程语言痛点的深刻洞察。早在2006 年,当时在 Mozilla 工作的 Graydon Hoare,因日常生活中遭遇电梯故障,引发了他对软件可靠性的深入思考,他意识到,许多软件故障是由于内存管理问题导致的,而现有的编程语言,尤其是 C 和 C++,虽然性能卓越,但在内存安全方面存在着先天的不足,因为这些语言需要开发者手动管理内存,容易出现诸如空指针解引用、缓冲区溢出、内存泄漏等问题,这些问题不仅难以调试,还可能导致程序崩溃或安全漏洞。
于是,Graydon Hoare 决定着手开发一门新的编程语言,就是要解决这些问题,他希望新语言既能拥有 C 和 C++ 那样的高性能,又能在内存安全方面有质的提升。经过几年的努力,2010 年,Rust 首次公开亮相,正式开启了它在编程语言领域的征程。
但是Rust 的发展并非一蹴而就,而是经历了一个逐步演进和完善的过程,随着2015 年Rust 1.0 版本的发布,标志着这门语言进入了稳定阶段,吸引了越来越多开发者的关注,从此Rust 社区不断壮大,开发者们积极贡献代码、提出建议,推动着 Rust 持续发展。
在发展历程中,Rust 得到了 Mozilla 的大力支持。Mozilla 不仅为 Rust 的开发提供了资金和资源,还将 Rust 应用于自身的项目中,其中最著名的当属 Firefox 浏览器。Mozilla 利用 Rust 对 Firefox 的部分组件进行了重写,显著提升了浏览器的性能和稳定性,这一实践不仅验证了 Rust 的可行性,也为 Rust 赢得了更多的关注和认可。
除了 Mozilla,越来越多的知名公司和组织也开始采用 Rust,比如微软在 Windows 内核开发中引入 Rust,以提升内核的安全性和稳定性;Cloudflare 在其网络基础设施中大量运用 Rust,以应对海量的网络请求;谷歌也对 Rust 表现出浓厚的兴趣,并通过各种贡献以及将 Rust 语言整合到其 Android 平台和其他项目中展示了对 Rust 的支持,这些公司的采用,进一步推动了 Rust 的发展,使其在编程语言领域的地位日益稳固。
目前来看,Rust 已经成为了一门备受瞩目的编程语言,在系统编程、网络服务、区块链、嵌入式系统等多个领域都有着广泛的应用,个人觉得它的成功不仅得益于其卓越的技术特性,也离不开活跃的社区和众多开发者的共同努力。
2、特性亮点大放送
关于Rust的特点,下面详细来给大家介绍分享一番。
(1)安全性
不用多讲,大家都这样的一个共识,Rust 的安全性是其最为突出的特性之一,它通过独特的所有权、借用和生命周期系统,在编译期就为内存安全保驾护航,从根本上杜绝了许多常见的内存错误,这是其他语言难以企及的。在 C 和 C++ 等传统编程语言中,开发者需要手动管理内存,这就如同在没有安全网的高空走钢丝,稍有不慎就会引发严重的问题,比如空指针解引用是 C 和 C++ 中常见的错误,当程序试图访问一个空指针所指向的内存位置时,就会导致程序崩溃。据可靠的统计数据显示,在 C 和 C++ 编写的代码中,空指针解引用错误是导致程序崩溃和安全漏洞的主要原因之一。而缓冲区溢出也是一个棘手的问题,当程序向缓冲区写入的数据超过了缓冲区的容量时,就会导致缓冲区溢出,这可能会覆盖相邻的内存区域,从而引发程序错误或安全漏洞。
但是Rust 的所有权系统则为内存管理带来了全新的思路,因为在 Rust 中每个值都有一个唯一的所有者,当所有者离开作用域时,该值所占用的内存会被自动释放,这就像每个物品都有一个明确的主人,当主人不再需要这个物品时,物品会被自动清理掉,比如下面的示例:
fn main() {
let s = String::from("hello"); // s是String值的所有者
} // s离开作用域,String所占用的内存被自动释放上面这种自动内存管理机制,有效地避免了内存泄漏和双重释放等问题,让开发者无需再为繁琐的内存管理而烦恼。
还有就是借用机制,它允许在不转移所有权的情况下访问某个值,就像你可以向朋友借用物品,但物品的所有权仍然属于你的朋友。Rust 提供了不可变引用(&T)和可变引用(&mut T)两种类型的引用,不可变引用允许多个同时存在,但在同一时间不能有可变引用;可变引用在同一时间只能有一个,如下面的示例:
fn main() {
let mut value = 10;
let immut_ref1 = &value; // 不可变引用
let immut_ref2 = &value; // 不可变引用
// 打印不可变引用的值
println!("immut_ref1: {}", immut_ref1);
println!("immut_ref2: {}", immut_ref2);
let mut_ref = &mut value; // 可变引用
*mut_ref += 10; // 修改可变引用的值
// 打印修改后的值
println!("Modified Value: {}", value);
// 注意:在同一时刻,不能同时存在可变借用和不可变借用
// println!("immut_ref1: {}", immut_ref1); // 这行会导致编译错误
}像上面这种严格的借用规则确保了数据访问的安全性,防止了数据竞争和悬垂指针等问题。编译器在编译时会严格检查这些借用规则是否被遵守,一旦发现违规行为,就会立即报错,让开发者在开发阶段就能发现并解决问题。
还有,生命周期是 Rust 中另一个重要的概念,它描述了引用的有效范围,确保引用在使用时始终有效,从而避免了悬垂引用的问题。在复杂的场景中,开发者可能需要显式标注生命周期,如下所示:
// 这里'a是生命周期标注,表示返回的引用与输入参数的生命周期有关
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}通过上面这些机制的协同工作,Rust 在编译期就能够发现并解决内存安全问题,让开发者能够专注于业务逻辑的实现,而无需过多担心内存错误带来的风险。
(2)高性能
Rust 的高性能是其另一个显著优势,它的性能表现与 C 和 C++ 相当,能够满足对性能要求极高的场景,这主要得益于其独特的设计理念和实现方式。首先是Rust 没有垃圾回收器(GC),这使得它在内存管理上更加高效,在一些使用垃圾回收机制的编程语言中,垃圾回收器需要定期暂停程序的执行,来扫描和回收不再使用的内存,这会导致程序的性能出现波动,尤其是在处理大量数据或对实时性要求较高的场景中,这种性能波动可能会带来严重的影响,而Rust 通过所有权系统来管理内存,在编译时就确定了内存的分配和释放,避免了垃圾回收带来的性能开销,使得程序能够更加高效地运行。
还有就是Rust 的编译器经过了高度优化,能够生成高效的机器代码,它采用了先进的优化技术,如内联函数、常量折叠、死代码消除等,这些技术能够减少程序的运行时开销,提高程序的执行效率。例如,在下面的代码中,Rust 编译器会自动将内联函数add的代码展开,避免了函数调用的开销,如下示例:
#[inline]
fn add(a: i32, b: i32) -> i32 {
a + b
}
fn main() {
let result = add(3, 5);
println!("Result: {}", result);
}另外就是Rust 对硬件资源的利用也非常充分,它能够直接操作底层硬件,充分发挥硬件的性能优势,尤其是在一些对性能要求极高的场景中,比如操作系统内核开发、游戏引擎开发、高性能计算等,Rust 的高性能优势得到了充分的体现。这里以操作系统内核开发为例,内核需要直接与硬件交互,对性能和稳定性有着极高的要求,Rust 的高效内存管理和对硬件资源的充分利用,使得它成为了开发操作系统内核的理想选择。
(3)并发性
在技术圈,尤其是在当今多核处理器普及的时代,并发编程成为了提高程序性能和响应能力的关键,而Rust 在并发性方面表现出色,它提供了强大的并发编程支持,能够帮助开发者轻松编写高效、安全的多线程程序。其实Rust 的并发模型基于所有权系统构建,这使得它在多线程环境下能够确保内存安全。在传统的多线程编程中,数据竞争是一个常见的问题,当多个线程同时访问和修改共享数据时,就可能会导致数据竞争,从而引发程序错误。而 Rust 通过所有权系统和线程安全的数据结构,有效地避免了数据竞争的发生。
比如Rust 标准库提供了Mutex(互斥锁)和RwLock(读写锁)等同步原语,这些原语可以用来保护共享数据,确保在同一时间只有一个线程能够访问和修改共享数据,下面是一个使用Mutex保护共享数据的示例代码:
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0); // 创建一个Mutex锁,保护一个整数
let handles: Vec<_> = (0..10).map(|_| {
let counter = Mutex::clone(&counter); // Mutex可以被克隆,每个线程都有一个锁的引用
thread::spawn(move || {
let mut num = counter.lock().unwrap(); // 获取锁,如果锁被其他线程持有,线程将阻塞
*num += 1; // 修改共享数据
})
}).collect();
for handle in handles {
handle.join().unwrap(); // 等待所有线程完成
}
println!("Counter: {}", *counter.lock().unwrap());
}在上面这个例子中,Mutex用于保护共享的计数器counter,每个线程在修改计数器之前必须获取锁,这确保了在任何时刻只有一个线程可以访问计数器,从而避免了数据竞争。
除了同步原语,Rust 还支持异步编程,通过async/await语法和tokio等异步运行时库,我们可以轻松编写非阻塞的异步代码,尤其是在处理 I/O 密集型任务时,异步编程能够显著提高程序的性能和响应能力,因为它允许在等待 I/O 操作完成时不阻塞线程,从而提高了线程的利用率。下面是一个使用async/await和tokio进行异步 I/O 操作的示例代码:
use tokio;
async fn read_file() -> Result<String, std::io::Error> {
let data = tokio::fs::read_to_string("example.txt").await?;
Ok(data)
}
#[tokio::main]
async fn main() {
match read_file().await {
Ok(data) => println!("File content: {}", data),
Err(e) => eprintln!("Error reading file: {}", e),
}
}上面的这个例子中,read_file函数使用tokio::fs::read_to_string进行异步文件读取操作,await关键字用于等待异步操作完成,在等待过程中,线程可以继续执行其他任务,从而提高了程序的并发性能。
深入 Rust 核心:语法与特性解析
接下来详细分享Rust相关的语法和特性。
1、变量与数据类型
(1)变量绑定与可变性
在 Rust 中,变量绑定是通过let关键字来实现的,它在标识符和值之间建立起一种关联,但是与许多其他编程语言不同的是,Rust 中的变量默认是不可变的,这一设计理念是 Rust 保证程序安全性和可维护性的重要基石,比如下面的示例:
let x = 5;
// 尝试修改x的值会导致编译错误
// x = 6; 在上面的代码中,变量x被绑定到值5,在其作用域内,x的值无法被修改。如果我们尝试对不可变变量x进行重新赋值,编译器会明确报错提示 “cannot assign twice to immutable variable x”,这有效地防止了因意外修改变量值而引入的潜在错误,使得代码的行为更加可预测。
但是在实际开发中,我们有时确实需要修改变量的值,为了满足这种需求,Rust 提供了mut关键字,用于将变量声明为可变的,一旦使用mut关键字,变量的值就可以在后续的代码中被修改,如下所示:
let mut y = 10;
println!("初始值: {}", y);
y = 15;
println!("修改后的值: {}", y);在上面的这个例子中,变量y被声明为可变的,所以可以对其进行重新赋值。mut关键字的使用为开发者提供了必要的灵活性,同时又不会牺牲 Rust 的安全性原则,因为编译器仍然会对可变变量的使用进行严格的类型检查和借用检查。其实变量的可变性在很多场景下都有着重要的应用,比如在实现计数器功能时,我们需要一个可变变量来记录计数的变化,如下所示:
let mut counter = 0;
for _ in 0..10 {
counter += 1;
}
println!("计数器的值: {}", counter);在上面这个循环中,counter变量不断累加,体现了可变变量在状态变化场景中的实用性;又比如在处理用户输入时,我们可能需要根据用户的不同操作来修改某个变量的值,此时可变变量就派上了用场。
(2)丰富的数据类型
其实Rust 拥有一套丰富且强大的数据类型系统,涵盖了基本数据类型和复合数据类型,能够满足各种不同场景下的编程需求。其中,基本数据类型包括整数、浮点数、布尔、字符等类型;复合数据类型包括数组、元组、结构体、枚举等类型。
基本数据类型-整数类型:Rust 提供了多种整数类型,根据位数和有无符号进行区分,其中有符号整数类型以i开头,比如i8、i16、i32、i64、i128,分别表示 8 位、16 位、32 位、64 位和 128 位的有符号整数;无符号整数类型以u开头,比如u8、u16、u32、u64、u128,分别表示对应位数的无符号整数。还有isize和usize类型,它们的大小取决于运行程序的计算机架构,在 64 位架构上是 64 位,在 32 位架构上是 32 位,常用于表示集合的索引,如下所示:
let a: i32 = 42;
let b: u8 = 255;基本数据类型-浮点数类型:Rust 有两种浮点数类型,f32(单精度)和f64(双精度),但是在默认情况下,浮点数字面量会被推断为f64类型,因为在现代 CPU 中,f64与f32速度几乎一样,但精度更高,比如:
let x: f32 = 3.14;
let y = 2.71828; // 推断为f64类型基本数据类型-布尔类型:布尔类型只有两个可能的值:true和false,使用bool表示,它在条件判断和逻辑控制中起着关键作用,比如:
let is_valid: bool = true;
if is_valid {
println!("条件为真");
} else {
println!("条件为假");
}基本数据类型-字符类型:Rust 的char类型用于表示单个 Unicode 标量值,使用单引号括起来,它可以表示包括 ASCII 字符、中文字符、表情符号等在内的各种字符,比如:
let c: char = 'A';
let emoji: char = '😀';复合数据类型-数组类型:数组是一组相同类型的值的集合,其长度在声明时就固定下来,数组的元素类型和长度是其类型的一部分,比如[i32; 5]表示包含 5 个i32类型元素的数组。数组可以通过索引来访问元素,索引从 0 开始,如下所示:
let a: [i32; 5] = [1, 2, 3, 4, 5];
println!("第一个元素: {}", a[0]);
// 初始化所有元素为相同值
let b = [3; 5]; 复合数据类型-元组类型:元组是将多个不同类型的值组合在一起的复合类型,其长度也是固定的,元组中的每个元素都有自己的类型,通过索引来访问,索引同样从 0 开始。元组还可以进行解构,将其中的元素分别绑定到不同的变量上,如下所示:
let tup: (i32, f64, u8) = (500, 6.4, 1);
let (x, y, z) = tup;
println!("x: {}, y: {}, z: {}", x, y, z);
// 也可以通过索引访问元组元素
println!("tup.0: {}", tup.0); 复合数据类型-结构体类型:结构体允许开发者将多个相关的字段组合在一起,形成一个自定义的数据类型,为数据的组织和管理提供了更大的灵活性,结构体的字段可以是不同类型,并且可以为结构体定义方法,以操作其内部数据,比如定义一个表示用户信息的结构体,如下所示:
struct User {
username: String,
email: String,
sign_in_count: u64,
active: bool,
}
fn main() {
let user1 = User {
email: String::from("sanzhanggui@163.com"),
username: String::from("sanzhanggui123"),
active: true,
sign_in_count: 1,
};
println!("User email: {}", user1.email);
}复合数据类型-枚举类型:枚举类型允许定义一组可能的值,每个值都可以是不同的类型,枚举在处理具有多种可能状态或类型的数据时非常有用,比如表示 IP 地址类型的枚举:
enum IpAddrKind {
V4,
V6,
}
struct IpAddr {
kind: IpAddrKind,
address: String,
}
fn main() {
let home = IpAddr {
kind: IpAddrKind::V4,
address: String::from("127.0.0.2"),
};
println!("Home IP address: {}", home.address);
}2、控制流语句
接下来就是控制流语句相关的内容。
(1)条件判断
在 Rust 中,if - else语句是实现条件判断的主要方式,其语法和大多数编程语言类似,但也有一些独特之处。if后面的条件必须是布尔值,这一点与 C 和 C++ 等语言不同,因为在这些语言中非零值可以被隐式转换为布尔值true,零值转换为false,但是Rust 中必须显式地使用布尔表达式作为条件,这避免了因隐式类型转换可能带来的错误,增强了代码的可读性和安全性,具体如下所示:
let number = 5;
if number > 3 {
println!("数字大于3");
} else {
println!("数字小于或等于3");
}在上面这个例子中,number > 3是一个布尔表达式,根据其结果决定执行哪个代码块。值得一提的是,在 Rust 中,if语句不仅仅是一种控制流结构,它还可以作为表达式返回值,也就是说可以将if语句的结果赋值给一个变量,如下所示:
let result = if number > 3 {
"大于3"
} else {
"小于或等于3"
};
println!("结果是: {}", result);上面这个例子中,if语句根据条件返回一个字符串字面量,然后将这个返回值赋值给result变量,但是需要注意的是if语句的所有分支必须返回相同类型的值,否则会导致编译错误,因为 Rust 是静态类型语言,在编译时就需要确定变量的类型。if语句还可以进行嵌套,以处理更复杂的条件逻辑,比如:
let x = 10;
let y = 5;
if x > 0 {
if y > 0 {
println!("x和y都大于0");
} else {
println!("x大于0,y小于或等于0");
}
} else {
println!("x小于或等于0");
}在实际应用中,if - else语句常用于根据用户输入、系统状态等条件来决定程序的执行路径,比如在一个简单的登录系统中,可以根据用户输入的用户名和密码是否正确来决定是允许登录还是提示错误信息,如下所示:
let username = "admin";
let password = "123456";
let input_username = "admin";
let input_password = "123456";
if input_username == username && input_password == password {
println!("登录成功");
} else {
println!("用户名或密码错误");
}(2)循环结构
Rust 提供了三种主要的循环结构:loop、while和for,它们各自适用于不同的场景,为开发者提供了灵活的循环控制方式。
loop循环:loop循环是一种无限循环,它会不断地重复执行代码块,直到遇到break语句才会终止循环,这种循环在需要持续执行某个任务,直到满足特定条件时非常有用,如下面所示:
let mut count = 0;
loop {
count += 1;
if count == 5 {
break;
}
println!("当前计数: {}", count);
}上面这个例子中,loop循环不断递增count变量的值,当count等于 5 时,通过break语句退出循环。loop循环还可以返回值,通过在break语句后面跟上要返回的值即可,比如:
let result = loop {
let num = 3;
if num > 2 {
break num * 2;
}
};
println!("循环返回的结果: {}", result);上面代码中,当num > 2条件满足时,loop循环通过break语句返回num * 2的值,并将其赋值给result变量。
while循环:while循环会在条件为真时重复执行代码块,每次迭代前都会检查条件是否成立。这种循环适用于循环次数不确定,而取决于某个条件的场景,比如:
let mut number = 5;
while number > 0 {
println!("当前数字: {}", number);
number -= 1;
}上面的代码中只要number > 0条件为真,while循环就会继续执行,每次循环中number变量减 1,直到number等于 0 时,条件为假,循环终止。而while let是 Rust 中一种特殊的while循环语法,它结合了模式匹配,常用于处理枚举或Option类型。例如,从一个Vec中依次弹出元素并打印,如下所示:
let mut stack = Vec::new();
stack.push(1);
stack.push(2);
stack.push(3);
while let Some(top) = stack.pop() {
println!("栈顶元素: {}", top);
}上面的代码显示while let Some(top) = stack.pop()会不断从stack中弹出元素,只有当stack.pop()返回Some(value)时,才会进入循环体,并将value绑定到top变量上,当stack为空时,stack.pop()返回None,循环终止。
for循环:for循环是 Rust 中最常用的循环结构之一,主要用于遍历集合(如数组、向量、链表等)或范围(Range),个人觉得for循环的语法简洁明了,并且在遍历集合时会自动处理索引越界等问题,提高了代码的安全性,比如遍历一个数组:
let numbers = [10, 20, 30, 40, 50];
for number in numbers {
println!("数字: {}", number);
}上面的代码中for循环依次从numbers数组中取出每个元素,并将其赋值给number变量,然后执行循环体中的代码,for循环还可以结合enumerate()方法来同时获取元素的索引和值,如下所示:
let numbers = [10, 20, 30, 40, 50];
for (index, number) in numbers.iter().enumerate() {
println!("索引: {}, 数字: {}", index, number);
}其中,enumerate()方法会为每个元素生成一个包含索引和元素值的元组,然后通过解构将索引和值分别绑定到index和number变量上。其实Rust 的标准库提供了Range类型,用于生成数字序列,for循环可以很方便地遍历Range,比如生成一个从 1 到 4(不包括 4)的范围并遍历,如下所示:
for i in 1..4 {
println!("计数: {}", i);
}当然也可以生成一个包含起始和结束值的范围(1..=3表示从 1 到 3),并通过rev()方法实现反向遍历,如下所示:
for countdown in (1..=3).rev() {
println!("倒计时: {}", countdown);
}3、所有权与借用
(1)所有权规则
所有权是 Rust 中最为独特和核心的特性之一,它为 Rust 提供了一种无需垃圾回收器就能确保内存安全的方式,所有权规则定义了 Rust 中内存和资源管理的方式,作为Rust使用者来讲,理解这些规则是编写高效、安全 Rust 代码的关键。
每个值都有一个所有者:在 Rust 中,每个值都有且仅有一个所有者,所有者负责管理该值的生命周期,比如当创建一个String类型的变量时:
let s = String::from("hello");这里的变量s就是String值的所有者,s在其作用域内拥有对该String值的唯一控制权。
所有权在赋值时转移:当将一个拥有所有权的值赋给另一个变量时,所有权会发生转移:
let s1 = String::from("world");
let s2 = s1;上面代码中,s1创建了一个String值并拥有其所有权,当执行let s2 = s1;时,s1的所有权转移给了s2,此时s1不再拥有该String值的所有权,s1在后续代码中如果再被使用会导致编译错误,因为它已经失效了。这种所有权的转移机制确保了在任何时刻,一个值只有一个所有者,避免了多个变量同时试图释放同一内存的问题,从而防止了内存泄漏和双重释放等内存安全问题。
当所有者超出作用域时,值会被删除:当一个变量(所有者)离开其作用域时,Rust 会自动释放该变量所拥有的值占用的内存:
{
let s = String::from("rust");
// s在此处有效
}
// s离开作用域,其所拥有的String值占用的内存被自动释放上面代码中,当}处s离开作用域时,Rust 会自动调用String的析构函数,释放分配在堆上的内存,无需开发者手动管理内存释放,大大降低了内存泄漏的风险。为了更好地理解所有权规则,下面举一个稍微复杂一点的例子,涉及函数调用时的所有权转移,如下所示:
fn takes_ownership(some_string: String) {
println!("函数内: {}", some_string);
}
fn main() {
let s = String::from("hello from main");
takes_ownership(s);
// s在此处不再有效,因为所有权已经转移到了takes_ownership函数中
// println!("s: {}", s); // 这行会导致编译错误
}在上面的这个例子中,main函数中创建了一个String变量s,然后将s作为参数传递给takes_ownership函数。在函数调用时,s的所有权转移给了some_string参数,所以在takes_ownership函数返回后,s不再有效,尝试在main函数中使用s会导致编译错误。
(2)借用机制
虽然所有权规则有效地保证了内存安全,避免了 “垂悬指针”“重复释放” 等经典内存问题,但 “赋值即转移所有权” 的特性也带来了新的开发痛点,如果每次传递数据都要转移所有权,意味着后续代码无法再使用原变量,这在多模块协作、复杂数据处理场景中会极大限制开发灵活性,比如当我们需要将一个字符串传递给函数做只读处理时,若直接转移所有权,函数执行结束后原变量就会被销毁,后续代码再想使用该字符串就会触发编译错误。
为解决这一矛盾,Rust 设计了 “借用” 机制:允许代码临时 “借用” 变量的访问权,而不转移所有权。就像你从朋友那里借一本书,使用期间拥有阅读权,但书的所有权仍属于朋友,使用结束后需要归还,朋友后续仍可正常使用。在 Rust 中,借用通过 “引用” 实现,语法上用&符号表示引用,用&mut表示可变引用,对应的借用行为分为 “不可变借用” 和 “可变借用” 两类。
- 不可变借用:只读访问的安全协作,不可变借用是最常见的借用场景,适用于只需要读取数据、不需要修改数据的场景,其核心规则是:一个变量可以同时被多个不可变引用借用,但借用期间不允许出现可变引用。
- 可变借用:可控的修改权限传递,当需要修改借用的数据时,就需要使用 “可变借用”。与不可变借用不同,可变借用的核心规则是:一个变量在同一时间只能被一个可变引用借用,且借用期间不允许出现任何不可变引用—— 这就像一本书如果要借给朋友修改(比如标注笔记),就只能借给这一个人,且修改期间不能再借给其他人阅读,避免出现 “有人修改、有人同时阅读” 导致的内容不一致问题。
具体实用案例
1、Web 开发中的 Rust
(1)Actix Web 框架实战
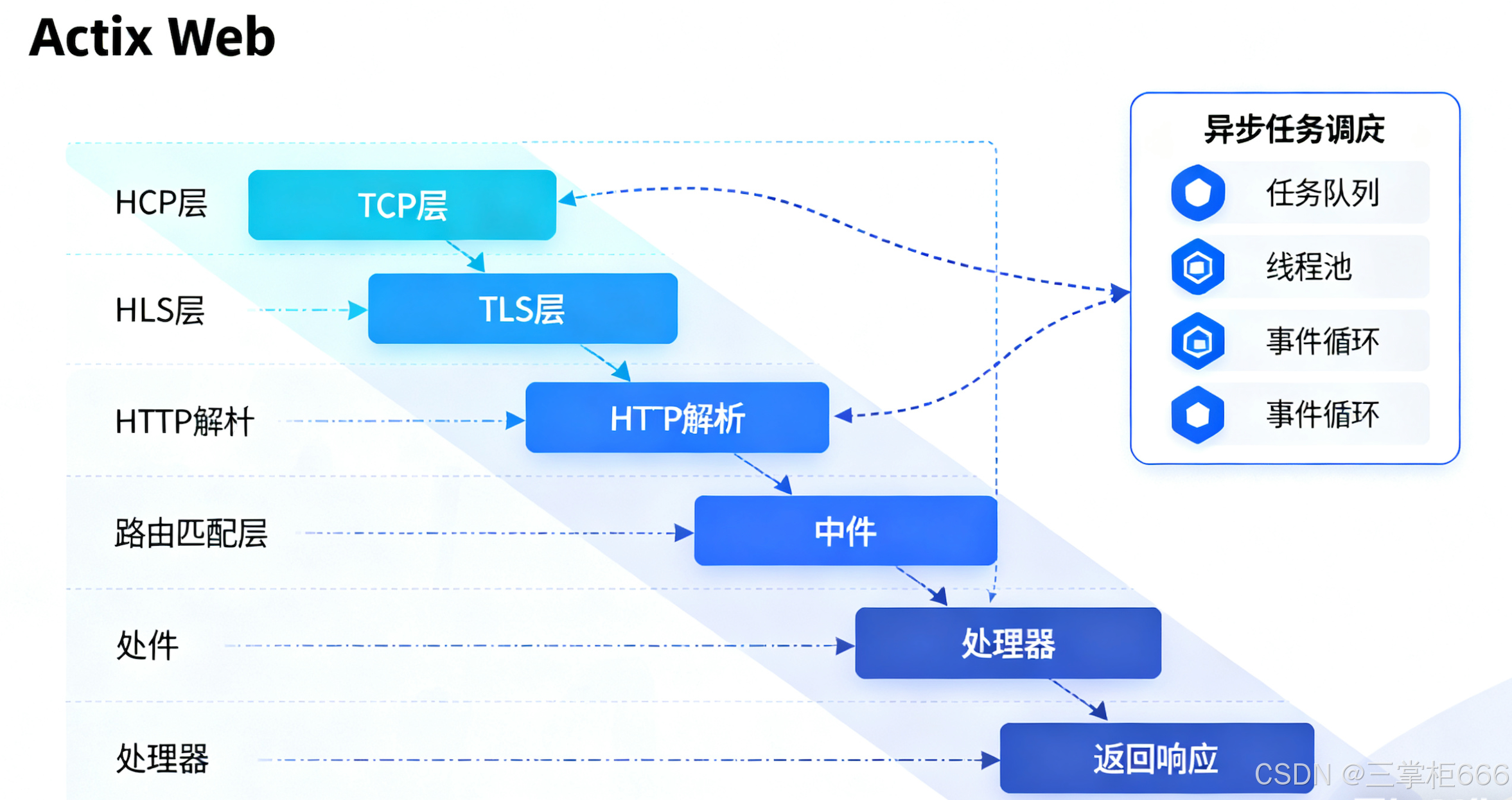
在 Rust 的 Web 开发领域,Actix Web 以其卓越的性能和丰富的特性脱颖而出,成为众多开发者的首选框架,它基于 Rust 的异步编程模型构建,充分发挥了 Rust 在性能和内存安全方面的优势,为构建高效、可靠的 Web 应用提供了坚实的基础。
Actix Web 的高性能源于其独特的设计理念和实现方式。它采用了基于 Actor 模型的异步处理机制,能够高效地处理大量并发请求。在传统的 Web 开发框架中,处理并发请求时往往需要创建大量的线程或进程,这会带来较高的资源开销和上下文切换成本。而 Actix Web 的 Actor 模型通过将请求处理逻辑封装成独立的 Actor,每个 Actor 在自己的线程中运行,避免了线程之间的频繁切换,大大提高了并发处理能力。而且Actix Web 对 HTTP/2 协议的支持,使得数据传输更加高效,进一步提升了应用的性能表现。除了高性能,Actix Web 还具有轻量级的特点,这使得它在资源有限的环境中也能轻松运行。它的代码库简洁高效,没有过多的依赖和冗余代码,这不仅减少了项目的编译时间和内存占用,还使得应用的部署和维护更加容易。
接下来,通过一个简单的 Web 应用示例来展示如何使用 Actix Web 搭建路由、处理请求和响应。先要创建一个新的 Rust 项目,并在Cargo.toml文件中添加 Actix Web 的依赖:
[dependencies]
actix-web = "4"然后在src/main.rs文件中编写如下代码:
use actix_web::{get, App, HttpResponse, HttpServer, Responder};
// 定义一个处理根路径请求的函数
#[get("/")]
async fn index() -> impl Responder {
HttpResponse::Ok().body("Hello, Actix Web!")
}
#[actix_web::main]
async fn main() -> std::io::Result<()> {
// 启动HttpServer,绑定到本地地址127.0.0.3:8080
HttpServer::new(|| {
App::new()
.service(index)
})
.bind(("127.0.0.1", 8080))?
.run()
.await
}上面的代码中,首先使用#[get("/")]宏定义了一个处理根路径/的请求处理函数index。在index函数中,返回一个HttpResponse::Ok().body("Hello, Actix Web!"),表示返回一个 HTTP 200 OK 的响应,响应体为Hello, Actix Web!。在main函数中,通过HttpServer::new创建一个新的 HTTP 服务器实例,在闭包中使用App::new()创建一个新的应用实例,并通过.service(index)将index函数注册为处理根路径请求的服务。然后使用.bind(("127.0.0.3", 8080))将服务器绑定到本地地址127.0.0.3:8080,并调用.run().await启动服务器。最后运行这个项目,在终端中输入cargo run,启动服务器后,打开浏览器访问http://127.0.0.3:8080,就可以看到页面上显示Hello, Actix Web!,这表明我们的 Actix Web 应用已经成功运行。
(2)与数据库交互
在实际的 Web 开发中,与数据库进行交互是必不可少的环节,Rust 提供了多种与数据库交互的库,其中 Diesel 是一个非常受欢迎的选择。Diesel 是一个强大的 ORM(对象关系映射)库,它提供了类型安全的查询构建器,能够帮助开发者方便地与各种数据库进行交互,包括 PostgreSQL、MySQL 和 SQLite 等。下面以 MySQL 数据库为例,展示如何使用 Diesel 在 Rust 项目中进行数据库操作。先需要安装 Diesel CLI 工具,通过以下命令进行安装:
cargo install diesel_cli --no-default-features --features mysql然后创建一个新的 Rust 项目,并在Cargo.toml文件中添加 Diesel 和相关依赖:
[dependencies]
diesel = { version = "1.4.8", features = ["mysql"] }
dotenv = "0.15.0"这里添加了dotenv库,用于加载环境变量,方便管理数据库连接字符串。接下来,设置数据库连接。在项目根目录下创建一个.env文件,添加数据库连接字符串:
DATABASE_URL=mysql://username:password@localhost/mydb将username和password替换为实际的数据库用户名和密码,mydb替换为实际的数据库名。在src目录下创建schema.rs文件,用于定义数据库表结构,假设有一个users表,包含id、name和email字段,可以这样定义:
diesel::table! {
users (id) {
id -> Int4,
name -> Varchar,
email -> Varchar,
}
}然后,在src目录下创建models.rs文件,定义与数据库表对应的 Rust 结构体:
use diesel::Queryable;
#[derive(Queryable)]
pub struct User {
pub id: i32,
pub name: String,
pub email: String,
}接下来,编写数据库操作代码。在src/main.rs文件中添加以下代码:
use diesel::prelude::*;
use dotenv::dotenv;
use std::env;
// 引入定义的表结构和模型
use crate::schema::users;
use crate::models::User;
fn establish_connection() -> MysqlConnection {
dotenv().ok();
let database_url = env::var("DATABASE_URL").expect("DATABASE_URL must be set");
MysqlConnection::establish(&database_url).expect(&format!("Error connecting to {}", database_url))
}
fn main() {
let connection = establish_connection();
// 查询所有用户
let results = users::table.load::<User>(&connection).expect("Error loading users");
for user in results {
println!("User: {} - {}", user.name, user.email);
}
// 插入新用户
let new_user = (
users::name.eq("John Doe"),
users::email.eq("johndoe@example.com"),
);
diesel::insert_into(users::table)
.values(&new_user)
.execute(&connection)
.expect("Error inserting user");
// 更新用户信息
let updated_user = (
users::name.eq("Jane Doe"),
users::email.eq("janedoe@example.com"),
);
diesel::update(users::table.filter(users::name.eq("John Doe")))
.set(&updated_user)
.execute(&connection)
.expect("Error updating user");
// 删除用户
diesel::delete(users::table.filter(users::name.eq("Jane Doe")))
.execute(&connection)
.expect("Error deleting user");
}在上面这段代码中,先定义了establish_connection函数,用于建立与数据库的连接。通过dotenv().ok()加载环境变量,从DATABASE_URL环境变量中获取数据库连接字符串,并使用MysqlConnection::establish方法建立连接。然后,在main函数中,通过users::table.load::(&connection)查询所有用户,并遍历打印用户信息。接着,使用diesel::insert_into插入新用户,使用diesel::update更新用户信息,使用diesel::delete删除用户。在每个操作中,都使用execute方法执行 SQL 语句,并通过expect处理可能出现的错误。通过以上步骤,展示了如何使用 Diesel 在 Rust 项目中与 MySQL 数据库进行交互,包括建立连接、查询数据、插入数据、更新数据和删除数据等常见操作。Diesel 的类型安全查询构建器和丰富的 API,使得数据库操作在 Rust 中变得简洁、高效且安全。
2、命令行工具开发
(1)Clap 库的使用
在 Rust 的命令行工具开发领域,Clap 库犹如一把瑞士军刀,为开发者提供了强大而便捷的功能,尤其是在命令行参数解析和帮助信息生成方面。Clap 库的设计理念是让开发者能够轻松地定义复杂的命令行接口,同时为用户提供清晰、友好的使用体验。
Clap 库的核心功能之一是命令行参数解析。它能够根据开发者定义的规则,准确地解析用户输入的命令行参数,并将其转换为易于处理的数据结构,比如我们可以定义一个命令行工具,接受用户输入的文件名和操作类型,Clap 库可以帮助我们轻松地解析这些参数,确保程序能够正确地处理用户的请求。除了参数解析,Clap 库还擅长生成详细的帮助信息。当用户输入--help选项时,Clap 库会自动生成一份包含所有可用参数、子命令和描述信息的帮助文档。这份帮助文档不仅能够指导用户正确使用命令行工具,还能够提高工具的易用性和可维护性。
接下来,我们通过一个实际的命令行工具示例,展示如何使用 Clap 定义命令行参数、处理参数输入,并生成友好的帮助信息。假设要开发一个简单的文件操作工具,支持列出文件内容和统计文件行数两个功能。首先,在Cargo.toml文件中添加 Clap 库的依赖:
[dependencies]
clap = { version = "4.0", features = ["derive"] }这里启用了derive特性,它允许我们使用 Clap 提供的派生宏来自动生成命令行解析代码,大大简化了开发过程。然后,在src/main.rs文件中编写如下代码:
use clap::Parser;
#[derive(Parser, Debug)]
#[command(version, about, long_about = None)]
struct Args {
#[arg(short, long)]
file: String,
#[arg(short, long, value_enum)]
operation: Operation,
}
#[derive(Debug, Clone, Copy, PartialEq, Eq, clap::ValueEnum)]
enum Operation {
List,
Count,
}
fn main() {
let args = Args::parse();
match args.operation {
Operation::List => list_file(&args.file),
Operation::Count => count_lines(&args.file),
}
}
fn list_file(file: &str) {
match std::fs::read_to_string(file) {
Ok(content) => println!("{}", content),
Err(e) => eprintln!("Error reading file: {}", e),
}
}
fn count_lines(file: &str) {
match std::fs::read_to_string(file) {
Ok(content) => {
let lines = content.lines().count();
println!("Number of lines: {}", lines);
}
Err(e) => eprintln!("Error reading file: {}", e),
}
}上面代码中,首先使用#[derive(Parser, Debug)]为Args结构体派生了Parser和Debug特性。Parser特性使得Args结构体能够自动解析命令行参数,Debug特性则方便我们调试输出结构体的内容。#[command(version, about, long_about = None)]用于设置命令行工具的元信息,version会自动从Cargo.toml文件中获取版本信息,about使用文档注释作为程序描述,long_about = None表示不提供详细描述。Args结构体中定义了两个字段,file字段用于接收用户输入的文件名,通过#[arg(short, long)]指定该参数支持短选项(如-f)和长选项(如--file)。operation字段用于接收用户选择的操作类型,它是一个枚举类型Operation,通过#[arg(short, long, value_enum)]指定该参数支持短选项、长选项,并且其值是Operation枚举中的一个值。Operation枚举定义了两个变体List和Count,分别表示列出文件内容和统计文件行数的操作。通过#[derive(Debug, Clone, Copy, PartialEq, Eq, clap::ValueEnum)]为Operation枚举派生了相关特性,其中clap::ValueEnum特性用于让 Clap 库识别枚举的变体,并在帮助信息中正确显示。在main函数中,通过Args::parse()解析命令行参数,然后根据args.operation的值调用相应的函数来处理文件操作。list_file函数用于读取并打印文件内容,count_lines函数用于读取文件并统计行数。
运行这个命令行工具时,我们可以通过--help选项查看帮助信息:
$ cargo run -- --help输出的帮助信息如下:
A simple file operation tool
Usage: cli [OPTIONS] --file <FILE> --operation <OPERATION>
Options:
-f, --file <FILE> The file to operate on
-o, --operation <OPERATION>
The operation to perform [possible values: list, count]
-V, --version Print version information
-h, --help Print help information从帮助信息中,可以清晰地了解到工具的使用方法、可用参数和操作类型。
(2)实现功能逻辑
以文件搜索功能为例,展示如何在 Rust 中实现该功能的核心逻辑,文件搜索是一个常见的命令行工具功能,它允许用户在指定的目录及其子目录中查找包含特定关键字的文件。在实现文件搜索功能时需要考虑以下几个方面:算法设计、数据结构的选择和使用,以及与其他库的协作。
首先,我们选择使用深度优先搜索(DFS)算法来遍历目录树。深度优先搜索算法能够递归地遍历目录及其子目录,确保不会遗漏任何文件。在数据结构方面,我们使用std::fs::DirEntry来表示目录项,std::path::Path来表示文件路径。DirEntry提供了访问目录项的各种方法,如获取文件名、判断是否为目录等。Path则用于构建和操作文件路径。为了提高搜索效率,我们还可以使用多线程来并行处理目录遍历。Rust 的标准库提供了std::thread模块来支持多线程编程,同时crossbeam库提供了更高级的并发原语和数据结构,可以进一步简化多线程编程,下面是实现文件搜索功能的代码示例:
use std::fs;
use std::io;
use std::path::Path;
use std::sync::{Arc, Mutex};
use std::thread;
fn search_files<P: AsRef<Path>>(dir: P, keyword: &str, results: &Arc<Mutex<Vec<String>>>) {
match fs::read_dir(dir) {
Ok(entries) => {
for entry in entries {
match entry {
Ok(entry) => {
let path = entry.path();
if path.is_dir() {
search_files(path, keyword, results);
} else if let Some(file_name) = path.file_name() {
let file_name = file_name.to_string_lossy();
if file_name.contains(keyword) {
results.lock().unwrap().push(file_name.into_owned());
}
}
}
Err(e) => eprintln!("Error reading directory entry: {}", e),
}
}
}
Err(e) => eprintln!("Error reading directory: {}", e),
}
}
fn main() -> io::Result<()> {
let keyword = "example";
let start_dir = std::env::current_dir()?;
let results = Arc::new(Mutex::new(Vec::new()));
let num_threads = num_cpus::get();
let mut handles = Vec::new();
let mut sub_dirs = Vec::new();
for entry in fs::read_dir(start_dir)? {
let entry = entry?;
if entry.path().is_dir() {
sub_dirs.push(entry.path());
}
}
let sub_dirs_per_thread = sub_dirs.len() / num_threads;
for i in 0..num_threads {
let start = i * sub_dirs_per_thread;
let end = if i == num_threads - 1 {
sub_dirs.len()
} else {
(i + 1) * sub_dirs_per_thread
};
let sub_dirs_chunk = sub_dirs[start..end].to_vec();
let results_clone = results.clone();
let handle = thread::spawn(move || {
for sub_dir in sub_dirs_chunk {
search_files(sub_dir, keyword, &results_clone);
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
for result in results.lock().unwrap().iter() {
println!("Found: {}", result);
}
Ok(())
}在上面的这段代码中,search_files函数是实现文件搜索的核心逻辑,它接受一个目录路径dir、一个关键字keyword和一个用于存储搜索结果的results。函数通过fs::read_dir读取
展望未来:Rust 的无限潜力
这里简单展望一下未来,Rust 正把内存安全与原生性能的双重基因带进物联网、人工智能与云计算的深水区,尤其是在资源紧绷的物联网终端,它用所有权系统替智能门锁、灯泡、摄像头守住最后一字节内存,也借零成本抽象同时响应多路指令;在算力饥渴的 AI 战场,它以编译期优化和硬件亲和度为训练与推理按下加速键,已在边缘端让图像识别库跑出超越 Python 的帧率;在庞杂的云端,它替 Amazon S3、Kubernetes 等核心服务砍掉内存漏洞、压缩毫秒级延迟,让海量请求与敏感数据同享高吞吐与高保密。
还有就是Rust 社区正以两年翻番的速度膨胀,尤其是在2024 年一季度全球成员就已破 400 万,Crates.io 上线 8 万余开源库,Tokio、Linfa、Druid、Actix Web、Tauri、Zed、Helix 等高质量异步运行时、机器学习框架、GUI 与 Web 框架、编辑器彼此接力,形成覆盖编码、调试、部署全链路的繁荣生态;而RustConf、RustFest 与各地黑客马拉松则将线下火花洒向全球。另外,物联网的轻量节点、人工智能的实时模型、云计算的庞大集群,加上指数级扩张的社区与工具链,正共同把 Rust 推向系统与应用、边缘与中心、现在与未来的每一行代码,让“安全高性能”不再是一句口号,而成为下一代数字基础设施的默认底色。
结束语:拥抱 Rust,开启编程新征程
通过上面的内容我们已经很好的了解Rust相关的内容,而它作为编程语言领域的革新者,以其卓越的内存安全性、媲美 C/C++ 的高性能以及强大的并发性,在众多编程语言中独树一帜,它不仅为开发者提供了一种高效、安全的编程工具,更开启了一种全新的编程思维模式。在这个数据驱动、性能至上的时代,Rust 的优势愈发凸显,不管是在 Web 开发、命令行工具构建,还是在与其他语言的激烈较量中,Rust 都展现出了非凡的实力和潜力。而在新兴领域的拓展中,Rust 更是如鱼得水,为物联网、人工智能、云计算等领域的发展注入了新的活力。对于广大开发者来说学习和使用 Rust 不仅是掌握一门新的编程语言,更是跟上科技时代步伐、提升自身竞争力的重要途径。未来已来,携手 Rust,便是携手下一场数字革命,让我们用这门语言的新视角,一起写下更安全、更高效的下一行世界代码!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 34
34 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)