Rust编程系列 - 为什么说VecDeque 是一个双向队列。在它的头部或者尾部执行添加或者删除操作,都是效率很 高的
容器
跟C++ 的 STL 类似,Rust 的标准库也给我们提供了一些比较常用的容器以及相关的迭 代器。目前实现了的容器有:
下面选择几个常见的命令来讲解它们的用法及特点。
Vec
Vec 是最常用的一个容器,对应C++ 里面的vector。 它就是一个可以自动扩展容量的 动态数组。它重载了Index 运算符,可以通过中括号取下标的形式访问内部成员。它还重 载了Deref/DerefMut 运算符,因此可以自动被解引用为数组切片。
常见用法示例如下:
fn main() {
//常见的几种构造Vec 的方式
//1.new() 方法与 default() 方法一样,构造一个空的Vec
let v1 = Vec: :<i32 > ::new();
//2.with_capacity() 方法可以预先分配一个较大空间,避免插入数据的时候动态扩容
//3.利用宏来初始化,语法跟数组初始化类似
let v3 = vec ! [1, 2, 3];
//插入数据
let mut v4 = Vec: :new();
//多种插入数据的方式
v4.push(1);
v4.extend_from_slice( & [10, 20, 30, 40, 50]);
v4.insert(2, 100);
println ! ("capacity:{}length:{}", v4.capacity(), v4.len());
//访问数据
/ / 调 用 IndexMut 运算符,可以写入数据
v4[5]=5;
let i=v4[5];
println!("{}",i);
/ / Index运算符直接访问,如果越界则会造成panic,
而get方法不会,因为它返回一个Option < T >
if let Some(i) = v4.get(6) {
println ! ("{}", i);
}
//Index 运算符支持使用各种 Range 作为索引
let slice = &v4[4..];
println ! ("{:?}", slice);
}
以上示例包含了Vec 中最常见的一些操作,还有许多有用的方法,不方便在本书一一罗 列,各位读者可以参考标准文档。
一个Vec 中能存储的元素个数最多为std::usize::MAX 个,超过了会发生panic。 因为它记录元素个数,用的就是usize 类型。如果我们指定元素的类型是0大小的类型, 那么,这个Vec 根本不需要在堆上分配任何空间。另外,因为Vec 里面存在一个指向堆 上的指针,它永远是非空的状态,编译器可以据此做优化,使得size_of::<Option<Vec>>()==size_of::<Vec>() 。
示例如下:
struct ZeroSized {}
fn main() {
let mut v = Vec: :<ZeroSized > ::new();
println ! ("capacity:{}length:{}", v.capacity(), v.len());
v.push(ZeroSized {});
v.push(ZeroSized {});
println ! ("capacity:{}length:{}", v.capacity(), v.len());
//p 永远指向 align_of::<Zerosized>(), 不需要调用 allocator let p=v.as_ptr();
println ! ("ptr:{:p}", p);
let size1 = std: :mem: :size_of: :<Vec < i32 >> ();
let size2 = std: :mem: :size_of: :<Option < Vec < i32 >>> ();
println ! ("size of Vec:{}size of option vec:{}", sizel, size2);
}
编译执行,可得结果为:
capacity: 18446744073709551615
length: 0 capacity: 18446744073709551615
length: 2 ptr: 0x1 size of Vec: 24 size of option vec: 24
将来类似Vec 的这些容器,还会像C++ 一样,支持一个新的泛型参数,允许用户自定 义 allocator 。 这部分目前还没有定下来,因此就不深入讨论了。
VecDeque
VecDeque 是一个双向队列。在它的头部或者尾部执行添加或者删除操作,都是效率很 高的。它的用法和Vec 非常相似,主要是多了pop_front()push_front()等方法。
基本用法示例如下:
use std: :collections: :VecDeque;
fn main() {
let mut queue = VecDeque: :with_capacity(64); //向尾部按顺序插入一堆数据
for i in 1..10 {
queue.push_back(i);
//从头部按顺序一个个取出来
while let Some(i) = queue.pop_front() {
println ! ("{}", i);
}
}
HashMap
HashMap<K,V,S>是基于hash 算法的存储一组键值对(key-value-pair)容器。其中,泛型参数K 是键的类型,V 是值的类型, S 是哈希算法的类型。 S 这个泛型参数有一个 默认值,平时我们使用的时候不需要手动指定,如果有特殊需要,则可以自定义哈希算法。
hash 算法的关键是,将记录的存储地址和key 之间建立一个确定的对应关系。这样,当 想查找某条记录时,我们根据记录的key, 通过一次函数计算,就可以得到它的存储地址, 进而快速判断这条记录是否存在、存储在哪里。因此, Rust 的 HashMap 要 求 ,key 要满足 Eq +Hash的约束。 Eq trait代表这个类型可以作相等比较,并且一定满足下列三个性质:
- 自反性——对任意a, 满 足a==a;
- 对称性——如果ab 成立,则ba 成立;
- 传递性——如果ab 且 bc 成立,则a==c 成立。
而Hash trait 更重要,它的定义如下:
trait Hash {
fn hash < H: Hasher > ( & self, state: &mut H);
}
trait Hasher {
fn finish( & self) - >u64;
fn write( & mut self, bytes: &[u8]);
}
如果一个类型,实现了Hash, 给定了一种哈希算法Hasher, 就能计算出一个u64 类 型的哈希值。这个哈希值就是HashMap 中计算存储位置的关键。
一般来说,手动实现Hash trait的写法类似下面这样:
struct Person {
first_name: String,
last_name: String,
}
impl Hash
for Person {
fn hash < H: Hasher > ( & self, state: &mut self.first_name.hash(state); self.last_name.hash(state);
}
}
这个hash 方法基本上就是重复性的代码,因此编译器提供了自动derive 来帮我们实 现。下面这种写法才是平时见得最多的:
# [derive(Hash)] struct Person {
first_name: String,
last_name: String,
}
一个完整的使用HashMap 的示例如下:
use std: :collections: :HashMap;# [derive(Hash, Eq, PartialEq, Debug)] struct Person {
first_name: String,
last_name: String,
}
impl Person {
fn new(first: &str, last: &str) - >Self {
Person {
first_name: first.to_string(),
last_name: last.to_string(),
} {}
fn main() {
let mut book = HashMap: :new();
book.insert(Person: :new("John", "Smith"), "521-8976");
book.insert(Person: :new("Sandra", "Dee"), "521-9655");
book.insert(Person: :new("Ted", "Baker"), "418-4165");
let p = Person: :new("John", "Smith");
//查找键对应的值
if let Some(phone) = book.get( & p) {
println ! ("Phone number found:{}", phone);
}
/ /删除book.remove( & p);
//查询是否存在
println ! ("Find key:{}", book.contains_key( & p));
}
HashMap 的查找、插入、删除操作的平均时间复杂度都是O(1) 。 在这个例子中, HashMap 内部的存储状态类似下图所示:
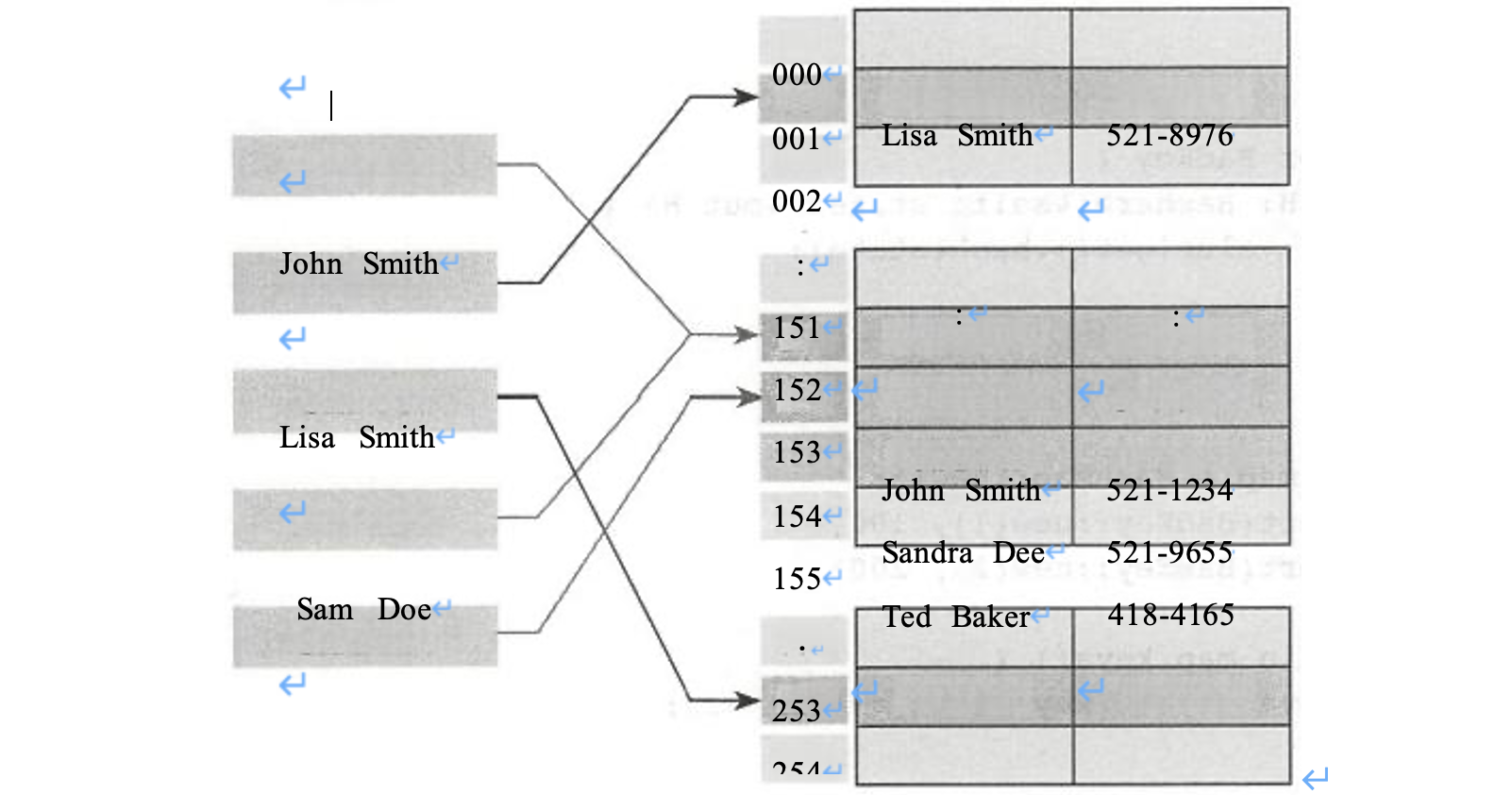
除了上面例子中演示的这些方法外,HashMap 还设计了一种叫作entry 的系列API。 考虑这样的一种场景,我们需要先查看某个key 是否存在,然后再做插入或删除操作。这种 时候,如果我们用传统的API,那么就需要执行两遍查找的操作:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)