
开源SOTA:阶跃发布端到端语音大模型Step-Audio 2 mini!
大家好,今天阶跃星辰正式发布最强开源端到端语音大模型 Step-Audio 2 mini,该模型在多个国际基准测试集上取得 SOTA 成绩。
它将语音理解、音频推理与生成统一建模,在音频理解、语音识别、跨语种翻译、情感与副语言解析、语音对话等任务中表现突出,并率先支持语音原生的 Tool Calling 能力,可实现联网搜索等操作。
一句话总结,Step-Audio 2 mini “听得清楚、想得明白、说得自然”。模型现已上线 GitCode、Hugging Face 等平台,欢迎大家下载、试用并反馈。
性能 SOTA
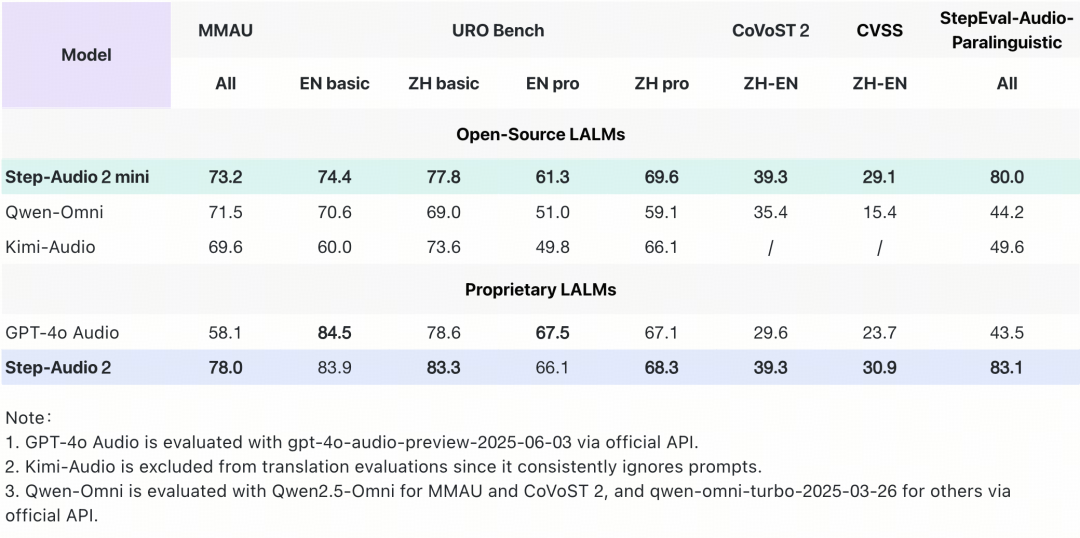
Step-Audio 2 mini 在多个关键基准测试中取得 SOTA 成绩,在音频理解、语音识别、翻译和对话场景中表现突出,综合性能超越 Qwen-Omni 、Kimi-Audio 在内的所有开源端到端语音模型,并在大部分任务上超越 GPT-4o Audio。
-
在通用多模态音频理解测试集 MMAU 上,Step-Audio 2 mini 以 73.2 的得分位列开源端到端语音模型榜首;
-
在衡量口语对话能力的 URO Bench 上, Step-Audio 2 mini 在基础与专业赛道均拿下开源端到端语音模型最高分,展现出优秀的对话理解与表达能力;
-
在中英互译任务上, Step-Audio 2 mini 优势明显,在 CoVoST 2 和 CVSS 评测集上分别取得 39.3 和 29.1 的分数,大幅领先 GPT-4o Audio 和其他开源语音模型;
-
在语音识别任务上,Step-Audio 2 mini 取得多语言和多方言第一。其中开源中文测试集平均 CER(字错误率) 3.19,开源英语测试集平均 WER(词错误率) 3.50,领先其他开源模型 15% 以上。
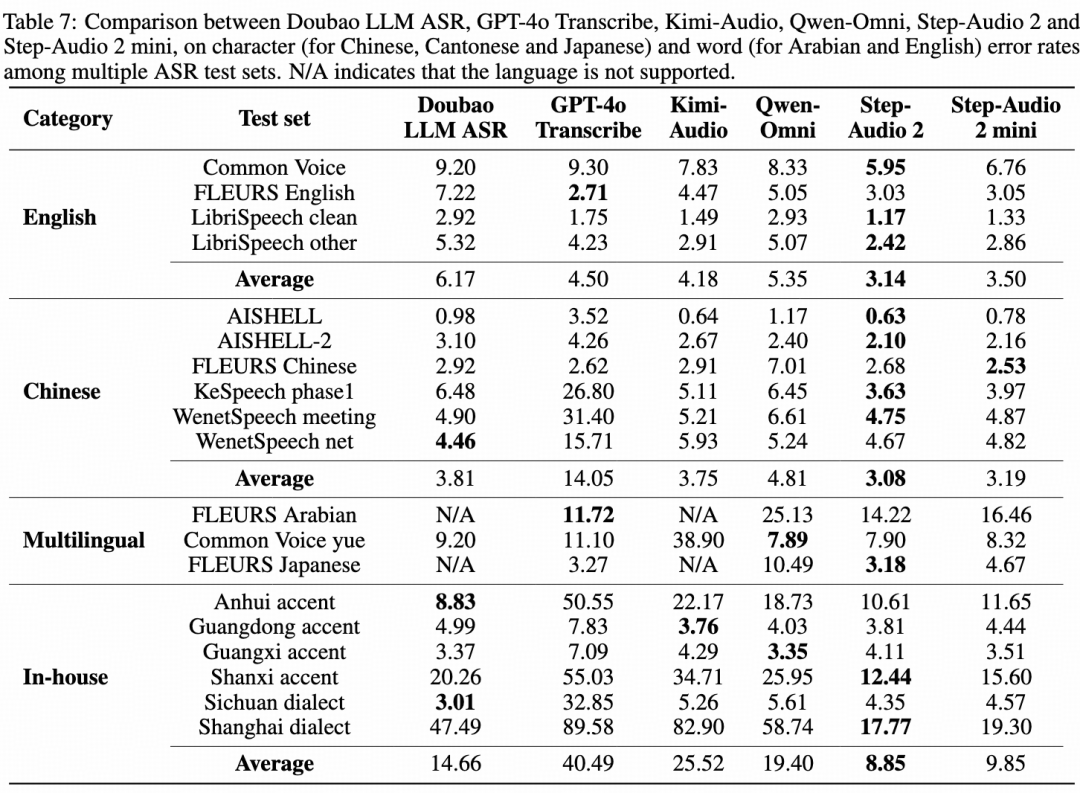
论文链接:https://arxiv.org/abs/2507.16632
真端到端架构,轻松听懂“弦外之音”
过往的 AI 语音常被吐槽智商、情商双低。一是“没知识”,缺乏文本大模型一样的知识储备和推理能力;二是“冷冰冰”,听不懂潜台词,语气、情绪、笑声这些“弦外之音”。Step-Audio 2 mini 通过创新架构设计,有效解决了此前语音模型存在的问题,做到“走脑又走心”。
-
真端到端多模态架构:Step-Audio 2 mini 突破传统 ASR+LLM+TTS 三级结构,实现原始音频输入到语音响应输出的直接转换,架构更简洁、时延更低,并能有效理解副语言信息与非人声信号。
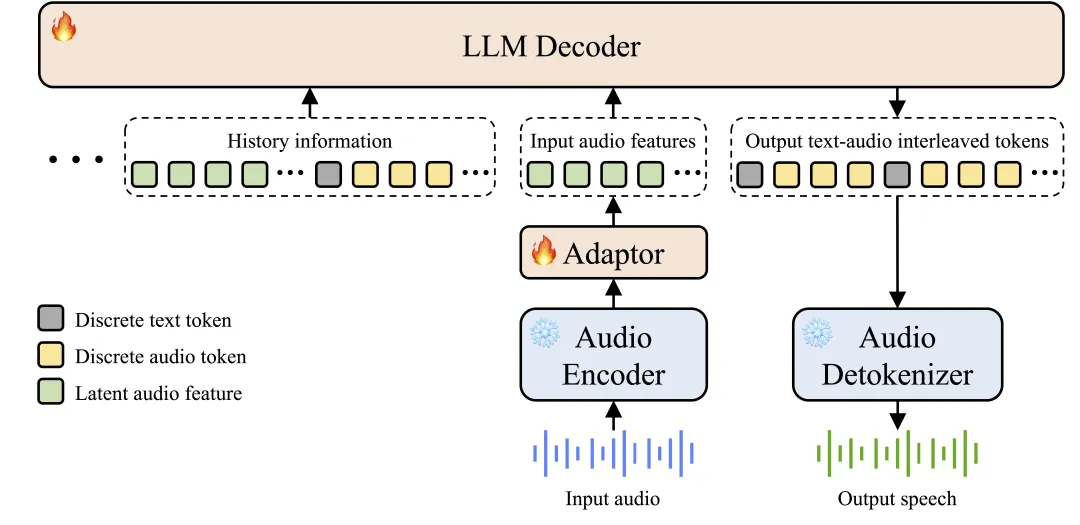
图:Step-Audio 2 mini 模型架构图
-
CoT 推理结合强化学习:Step-Audio 2 mini 在端到端语音模型中首次引入链式思维推理(Chain-of-Thought, CoT)与强化学习联合优化,能对情绪、语调、音乐等副语言和非语音信号进行精细理解、推理并自然回应。
-
音频知识增强:模型支持包括 web 检索等外部工具,有助于模型解决幻觉问题,并赋予模型在多场景扩展上的能力。
能力分析
无论是大自然的声音、精湛的配音,还是实时信息搜索,Step-Audio 2 都能精确理解,展现了在处理复杂音频任务上的巨大潜力。
精准识别,听懂万物之声
Step-Audio 2 mini 像一位听力超棒的音乐家,能分清鸟叫、流水、车声和发条玩具声这四种不同的“音符”。它甚至能听出汽车声中的“激情”——引擎加速和呼啸而过,而不只是冷冰冰地告诉你:“这是车。”
实时搜索,随时获得行业最新资讯
聊到 OpenAI 最新动态,Step-Audio 2 mini 通过工具调用搜索,迅速挖掘出最新语音模型资讯。
语速控制,轻松拿捏
此前,我们发布了同系列满血版 Step Audio 2,现已上线阶跃AI App。打开首页,点击右上角“电话”按钮,即可与模型进行实时对话,体验“深度聆听”和“多音色切换”功能。
不止对话,一起深度思考
当被问及“爱美是自由还是枷锁”这类哲学难题时,Step-Audio 2 mini 能将抽象问题转化为“购物前问自己三个问题”的极简方法论。这背后强大的逻辑推理能力,不仅能引导用户厘清思路,更能找到解决问题的具体路径。
欢迎体验
Step-Audio 2 mini 现已上线,欢迎体验和反馈。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 12
12 0
0- 0



 已为社区贡献150条内容
已为社区贡献150条内容

所有评论(0)