我的第一个全栈项目:使用AI大模型总结每一版软件的代码改动
项目目的:
在每一版软件要发版前,使用AI大模型总结一下这一版软件相比于前一版做了哪些改动,方便我们写在release note中。
项目内容:
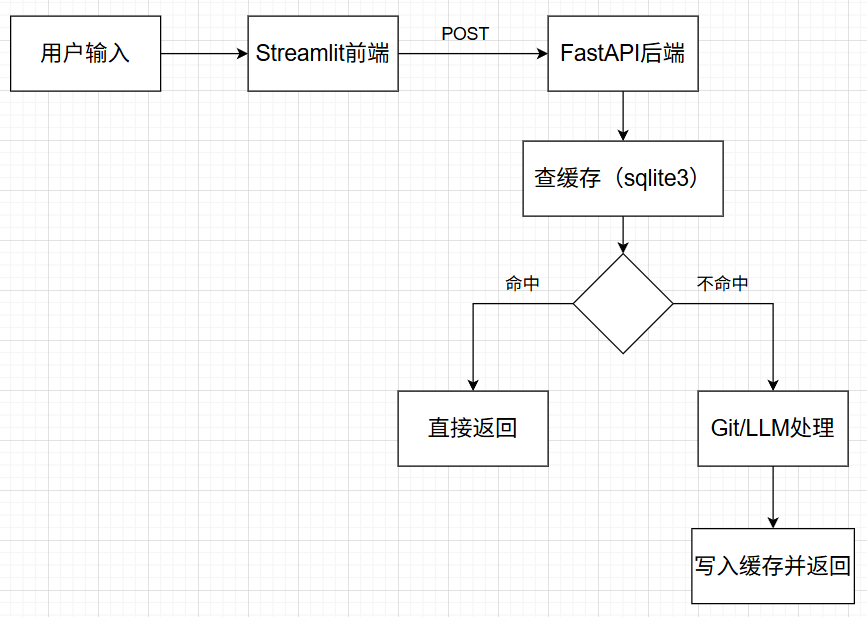
我们使用一个前端框架搭建一个网页应用,用来输入当前软件的tag1,和前一版软件的tag2,以及提供一个显示窗口来展现软件的改动内容。网页应用在接收到输入后,通过 HTTP POST 请求发送到后端的接口。FastAPI 后端收到请求,解析参数,后端会比较两个tag之间的改动,并将这些改动输入给大语言模型做总结。大语言模型总结完后,将总结的结果返回给后端,最终将change scope作为 JSON 返回给前端。前端收到后端返回的 change scope,直接以 Markdown 格式渲染展示,用户可复制到 release note。
使用的技术:
前端:
- Streamlit:一个开源 Python 库,我用这个库做一个简单的GUI,用来接收输入以及显示最终的change scope。
- requests:用于向后端发送 HTTP POST 请求。
后端:
- FastAPI:现代高性能 Python Web 框架,实现 RESTful API。
- sqlite3:轻量级本地数据库,用于缓存查询结果。选这个作为数据库的主要原因是目前想快速搭建一个MVP,后续会尝试迁移到Redis + PostgreSQL的方案(等使用这个方案后,我也会发布使用心得)。
- LangChain + ChatOpenAI:调用本地大模型进行自然语言总结,在这里我使用的是Qwen3开源模型。
具体细节:
1.使用streamlit搭建好网页应用,方便我们将输入的tags传递给后端。
2.设计了Git相关的API,方便我们对比输入的两个tag之间的代码差异(假如有submodule的话,也比较同一个submodule在不同tag之间的差异)。
3.前端输入的tags,通过发送HTTP POST给FastAPI后端,后端这块先查询输入的tags是否已经存储在数据库中,如果有的话,直接返回结果,返回给前端显示结果;如果数据库没有的话,则调用Git API,获得两个tag之间的全部代码差异,并将差异导入给大语言模型,让其总结change scope,将tags和change scope存储到数据库中,并将结果返回到前端显示。
整体的结构如下图所示:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)