「源力觉醒 创作者计划」文心、DeepSeek、Qwen 3.0 大模型实测对决赛:核心能力全方位拆解
引言
文心大模型 ERNIE 4.5 于 6 月 30 日正式发布开源代码,并在 GitCode 平台首发!本次百度一次性开源 10 款模型,覆盖基础、对话、多模态、思考等多个方向,甚至将核心训练框架与分布式策略完全开放。并且听说,该系列模型在基准测试中实现了 SOTA 级性能,大幅超越 Qwen3、DeepSeek-V3 等同类模型。下面就让我们通过对比这几款顶级大模型,一窥文心 4.5 的实力究竟如何!

文章目录
一 、文心开源模型ERNIE 4.5 简介
1.1 不同版本特性介绍
文心一言本次开源主要分为3类模型,一种是我们很熟悉的 文本语言大模型,第二种是具备多模态特性的视觉语言大模型,不仅能进行文本对话,能对文字、图片、音频、视频等内容进行综合理解。第三种是一个参数为0.3B的稠密型模,最低显存只需6GB的GPU算就可以部署了。
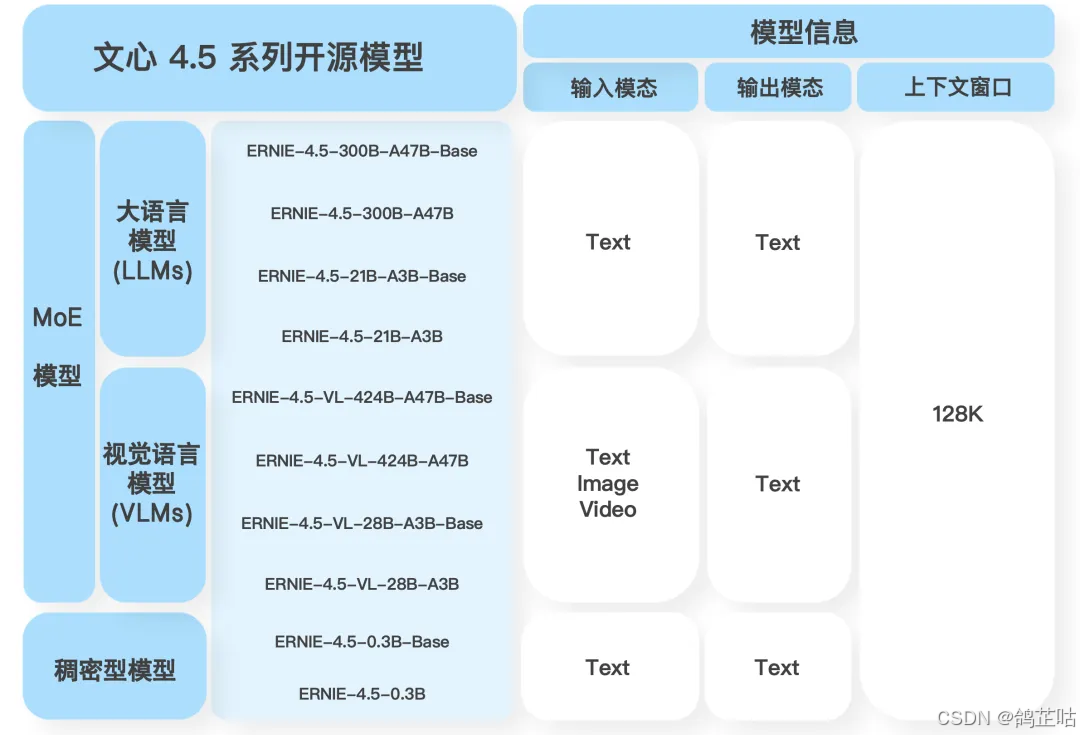
所有的模型都支持128K的上下的上下文窗口,覆盖了基础、对话、多模态、思考等多个方向。
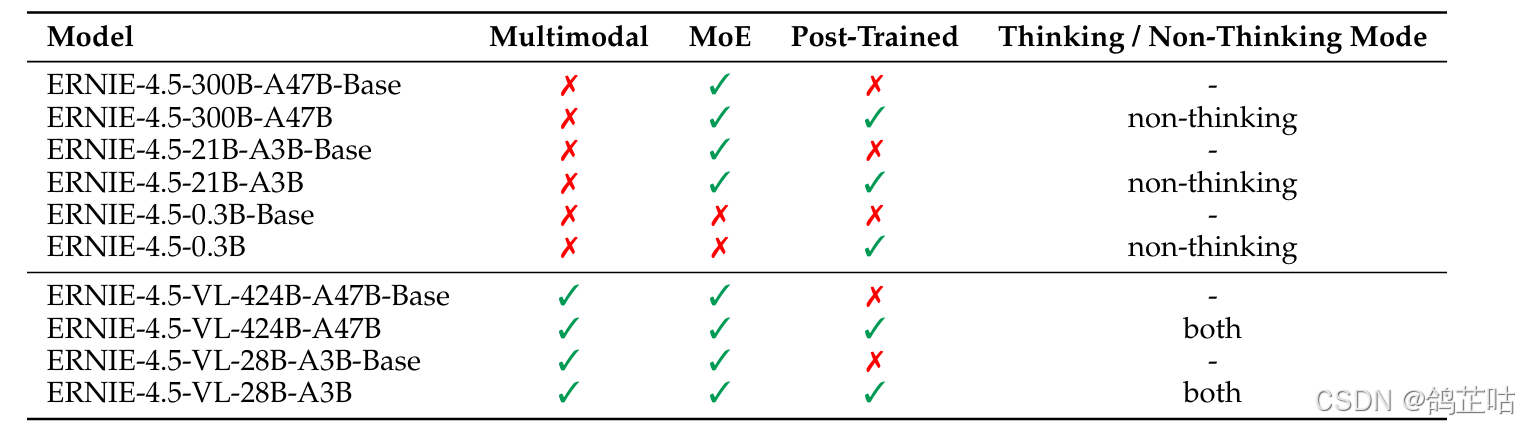
1.2 异构多模态MoE架构
异构MoE(Heterogeneous MoE)作为ERNIE 4.5的核心架构,其创新的“异构模态MoE”设计巧妙破解了多模态模型训练中的关键矛盾——既支持跨模态参数共享(涵盖自注意力参数与专家参数共享),又能为各独立模态配置专用参数,实现了共享与专属的灵活平衡。
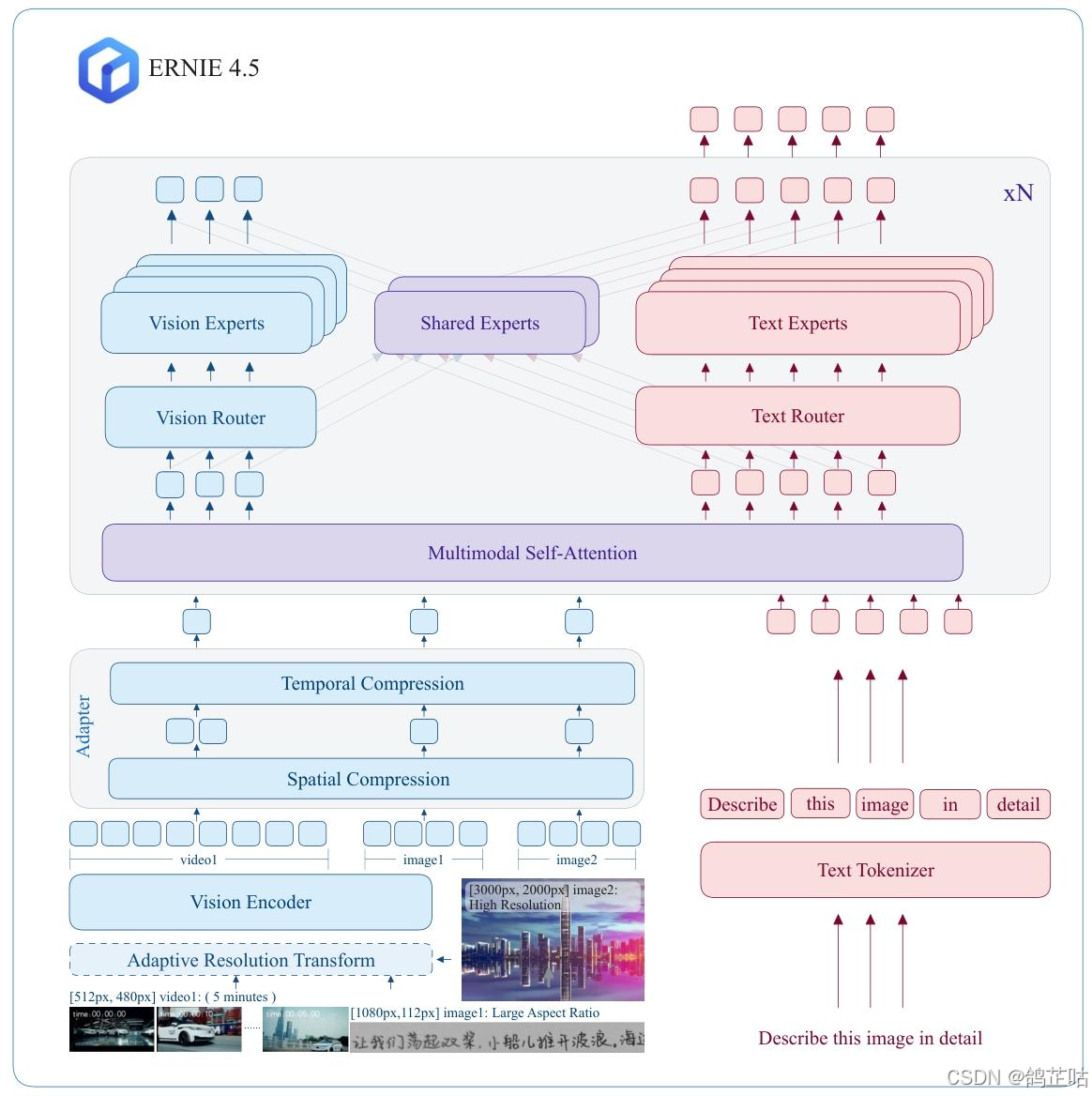
与传统统一MoE架构不同,ERNIE 4.5将专家(Experts)明确划分为文本专家、视觉专家和共享专家三类,并创新性引入模态感知的专家分配策略:其中视觉专家的参数规模仅为文本专家的三分之一,通过这种差异化设计大幅提升了视觉信息处理的效率,让多模态数据的协同处理更具针对性与经济性。
1.3 一整套部署工具链
百度此次不仅一次性开源了 10 款覆盖基础能力、对话交互、多模态处理及深度思考等多个维度的大模型,为不同场景需求的开发者提供了丰富的选择空间;更配套推出了一整套从部署到推理的全链路工具链 —— 包括支持一键部署的 FastDeploy、优化训练效率的 ERNIEKit 等,这些工具深度适配开源模型的技术特性,能帮助开发者跳过复杂的环境配置与底层优化环节,快速完成模型的本地化部署、性能调优与实际场景落地
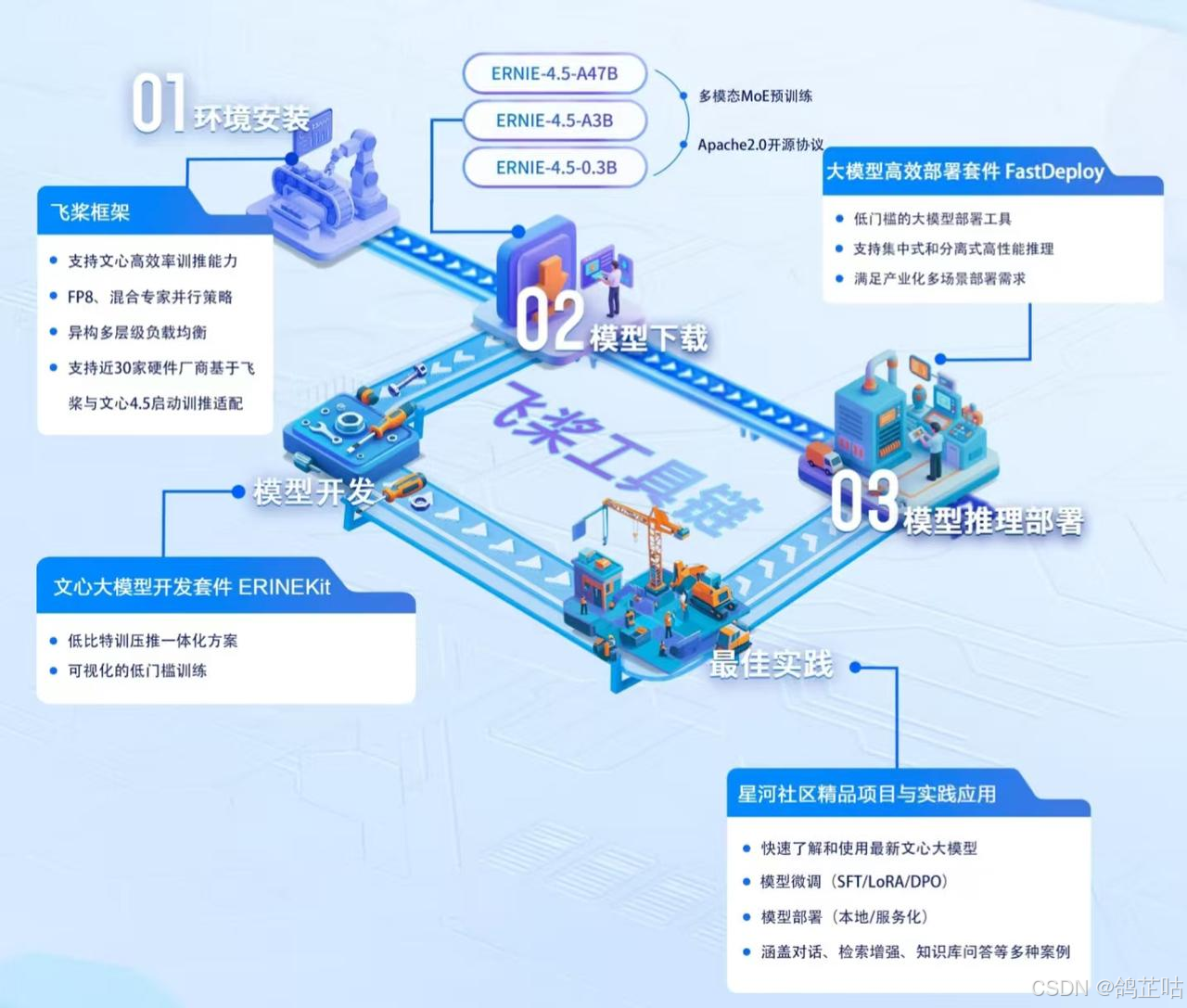
除此之外文心大模型本次开源全部按照Apache 2.0协议开源,这意味着我们不管是使用它进行学术研究,还是用在商用领域开发产业相关的应用项目,都完全没问题。
对于高效部署套件FastDeploy 百度也开源了核心代码,均采用 Apache - 2.0 开源许可证,提供了一行代码开箱即用的多硬件部署体验,使用接口兼容vLLM和OpenAI协议。
1.4 支持本地轻量化部署
在模型量化、对齐、LoRA精调等方面,文心在异构并行策略中引入了 FP8 混合精度训练框架和容错系统,对内存、通信、计算开销进行优化。文心最大 的ERNIE 4.5 语言模型采用了 8 路专家并行 (EP)、12 路管道并行 (PP)和 ZeRO-1 数据并行 (DP)配置。
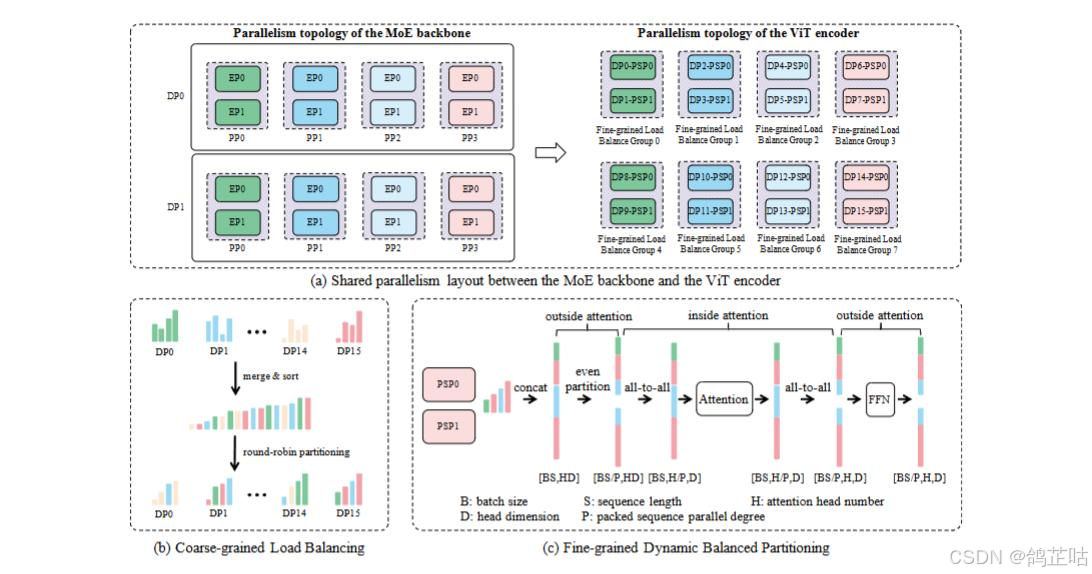
通过以上全面优化,实现了 47% 的模型 FLOPs 利用率 (MFU),比DeepSeek的 FLOPs 利用率还高。
| 模型名称 | 上下文长度 | 量化方式 | 最低部署资源 | 说明 |
|---|---|---|---|---|
| baidu/ERNIE-4.5-VL-424B-A47B-Paddle | 32K/128K | WINT4 | 4×80G GPU 显存/1T 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-VL-424B-A47B-Paddle | 32K/128K | WINT8 | 8×80G GPU 显存/1T 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-Paddle | 32K/128K | WINT4 | 4×64G GPU 显存/600G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-Paddle | 32K/128K | WINT8 | 8×64G GPU 显存/600G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-2Bits-Paddle | 32K/128K | WINT2 | 1×141G GPU 显存/600G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-W4A8C8-TP4-Paddle | 32K/128K | W4A8C8 | 4×64G GPU 显存/160G 内存 | 固定 4-GPU 配置,建议启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-FP8-Paddle | 32K/128K | FP8 | 8×64G GPU 显存/600G 内存 | 建议启用分块预填充,仅支持带专家并行的 PD 分离部署 |
| baidu/ERNIE-4.5-300B-A47B-Base-Paddle | 32K/128K | WINT4 | 4×64G GPU 显存/600G 内存 | 建议启用分块预填充 |
| baidu/ERNIE-4.5-300B-A47B-Base-Paddle | 32K/128K | WINT8 | 8×64G GPU 显存/600G 内存 | 建议启用分块预填充 |
| baidu/ERNIE-4.5-VL-28B-A3B-Paddle | 32K | WINT4 | 1×24G GPU 显存/128G 内存 | 需启用分块预填充 |
| baidu/ERNIE-4.5-VL-28B-A3B-Paddle | 128K | WINT4 | 1×48G GPU 显存/128G 内存 | 需启用分块预填充 |
| baidu/ERNIE-4.5-VL-28B-A3B-Paddle | 32K/128K | WINT8 | 1×48G GPU 显存/128G 内存 | 需启用分块预填充 |
| baidu/ERNIE-4.5-21B-A3B-Paddle | 32K/128K | WINT4 | 1×24G GPU 显存/128G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-21B-A3B-Paddle | 32K/128K | WINT8 | 1×48G GPU 显存/128G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-21B-A3B-Base-Paddle | 32K/128K | WINT4 | 1×24G GPU 显存/128G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-21B-A3B-Base-Paddle | 32K/128K | WINT8 | 1×48G GPU 显存/128G 内存 | 128K 长度需启用分块预填充 |
| baidu/ERNIE-4.5-0.3B-Paddle | 32K/128K | BF16 | 1×6G/12G GPU 显存/2G 内存 | 无 |
| baidu/ERNIE-4.5-0.3B-Base-Paddle | 32K/128K | BF16 | 1×6G/12G GPU 显存/2G 内存 | 无 |
这种架构优化与部署工具的深度协同,使得文心开源模型 ERNIE 4.5 的本地化部署门槛显著降低。企业无需为满足大模型运行需求投入巨额硬件采购费用,更不必承担长期的算力维护成本,这让更多企业能够以可控的成本享受到前沿大模型技术的赋能。在降低技术应用门槛的同时,也为行业的规模化智能化升级提供了切实可行的路径
二、实测准备与说明
本次实测我们采用,调用API 的形式来结合UI给大家更好的展示结果。
2.1 测试模型简介
- 本次的参赛选手分别是:ERNIE-4.5-Turbo-128K-Preview & DeepSeek-V3 & DeepSeek-VL2-Small 3个多模态视觉大模型。
| 模型名称 | 参数级别(billion) | 是否支持多模态 |
|---|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 424B | 是 |
| DeepSeek-V3 | 671B | 是 |
| Qwen3-235B-A22B | 235B | 是 |
他们都具备多模态能力能对文字、图片、音频、视频等内容进行综合理解。其中文心模型我们选择的是ERNIE-4.5-Turbo-128K-Preview 这一模型,
ERNIE-4.5-Turbo-128K-Preview是文心 4.5(ERNIE 4.5)系列中的一个具体型号,对比文心4.5,速度更快、价格更低。
2.2 测试维度与方法
本次评分的机制为,
首token最快3分,最快耗时 3分,答案是否正确 4分这三个核心方面分别体现了大模型响应效率,处理时长,和推理能力。
| 模型名称 | 最优 | 中等 | 最差 |
|---|---|---|---|
| 首Token | 3 | 2 | 1 |
| 总耗时 | 4 | 2 | 1 |
| 正确性 | (正确4分) | (酌情给分) | (错误 0分) |
为全面检验各模型的综合性能,本次大模型测试将围绕多类典型应用场景展开分层评估:每个测试环节均精心设计 多个具有场景代表性的问题,涵盖基础能力验证、复杂任务处理及实战场景适配等维度 。
三、各模型核心能力实测拆解
3.1 逻辑推理能力测试
数学推理
问题:
- 数学推理:“小明有 3 个苹果,小红苹果数是小明的 2 倍多 1 个,两人苹果平均分给 5 个小朋友,每人分几个?” 要求分步推导。


通过测试我们可以看到文心4.5是本次输出结果最快的大模型,对比Deepseek-V3 领先了10秒左右,在这道简单数学上速度远没有 Qwen3-235B-A22B 和文心4.5快。反而是输出了很多猜想。
| 模型名称 | 首Token | 总耗时 | 正确性 | 总分 |
|---|---|---|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 1.94s | 11.88 s | 正确 | 10 |
| DeepSeek-V3 | 1.69 s | 24.75 s | 正确 | 7 |
| Qwen3-235B-A22B | 0.97 s | 13.12 s | 正确 | 9 |
逻辑谜题
问题:
- 逻辑谜题:“甲说乙说谎,乙说丙说谎,丙说甲乙都说谎。谁讲真话?” 需构建逻辑链验证。

从本次逻辑谜题测试结果来看,文心 4.5(ERNIE-4.5-Turbo-128K-Preview)延续了其高效响应的优势,以 14.9 秒的总耗时成为绝对领先地位 —— 这一速度不仅比 DeepSeek-V3(39.85 秒)快了近 25 秒,更是 Qwen3-235B-A22B(28.82 秒)的约 1.9 倍,几乎实现了对后两者的速度翻倍领先。值得关注的是,在保持极速响应的同时,文心 4.5 与其他两款模型一样均给出了正确答案
| 模型名称 | 首Token | 总耗时 | 正确性 | 总分 |
|---|---|---|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 2.4s | 14.9 s | 正确 | 9 |
| DeepSeek-V3 | 1.67s | 39.85 s | 正确 | 7 |
| Qwen3-235B-A22B | 0.77s | 28.82s | 正确 | 9 |
常识逻辑
问题:
- 常识逻辑:“雨天洗车后,车更易脏?用物理 / 化学原理解释”,考验跨学科推理。

在常识逻辑测试上,各家大模型的表现都很不错。文心依旧是保持着输出最快的优势,我们需要什么答案它就回答什么。不做其他多余解释。千问模型和DeepSeek 在这类问题上进行建议优化,给出了雨天洗车的建议。
| 模型名称 | 首Token | 总耗时 | 正确性 | 总分 |
|---|---|---|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 1.73s | 15.55s | 正确 | 9 |
| DeepSeek-V3 | 1.51s | 27.48 s | 正确 | 7 |
| Qwen3-235B-A22B | 1.02s | 21.27s | 正确 | 9 |
结果汇总对比
| 模型名称 | 总分 |
|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 10+9+9=28 |
| DeepSeek-V3 | 7+7+7=21 |
| Qwen3-235B-A22B | 9+9+9=27 |
ERNIE-4.5-Turbo-128K-Preview(文心 4.5)
- 优势:总耗时三项均最快,高效响应突出;回答紧扣需求,无冗余信息,针对性强;全对且总分第一,速度与准确性平衡最佳。
- 劣势:首 Token 响应略慢于另两款;
Qwen3-235B-A22B(千问 3)
-
优势:首 Token 速度最快,初始反馈敏捷;全对且总分接近文心 4.5,表现均衡;会补充实用建议,场景适配灵活。
-
劣势:总耗时比文心 4.5 慢 10%-93%;额外建议可能偏离精准需求,简洁性不足。
DeepSeek-V3
-
优势:首 Token 响应稳定,中等偏上;推导过程细致,逻辑链可读性强;
-
劣势:总耗时为文心 4.5 的 1.6-2.7 倍,效率偏低;总分最低,综合竞争力较弱,实时性场景适配差。
| 模型名称 | 核心特点 | 适用场景 |
|---|---|---|
| 文心 4.5 | 高效精准 | 快速处理、短平快问答 |
| Qwen3 | 即时反馈 + 表现均衡 | 个人助手、多轮对话 |
| DeepSeek-V3 | 细节扎实但速度较慢 | 对时效要求低的复杂分析 |
3.2 知识问答能力测试
通用知识
问题:
- 通用知识:“‘安史之乱’的起止时间、主要人物及对唐朝的影响”,要求覆盖史实关键点。

在通用知识测试环节中,DeepSeek-V3 的表现明显落后于其他两款模型,成为本次测试中成绩垫底的大模型。从关键指标来看,其不仅首 Token 响应速度处于劣势 —— 在同类问题的初始反馈上,比文心 4.5 和千问模型慢了 0.5-1.2 秒,给用户的即时交互体验打了折扣;所以本次测试ERNIE-4.5-Turbo-128K-Preview 是我们的最优大模型。
| 模型名称 | 首Token | 总耗时 | 总调用(tokens) | 正确性 | 总分 |
|---|---|---|---|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 0.77s | 29.27s | 1128 tokens | 正确 | 11 |
| DeepSeek-V3 | 1.45s | 36.05s | 875 tokens | 正确 | 6 |
| Qwen3-235B-A22B | 0.94s | 34.52s | 1065 tokens | 正确 | 8 |
专业领域
问题
- 专业领域:医学题“心梗患者溶栓治疗的适应症与禁忌症”,法律题“遗嘱继承中,口头遗嘱的有效条件”。
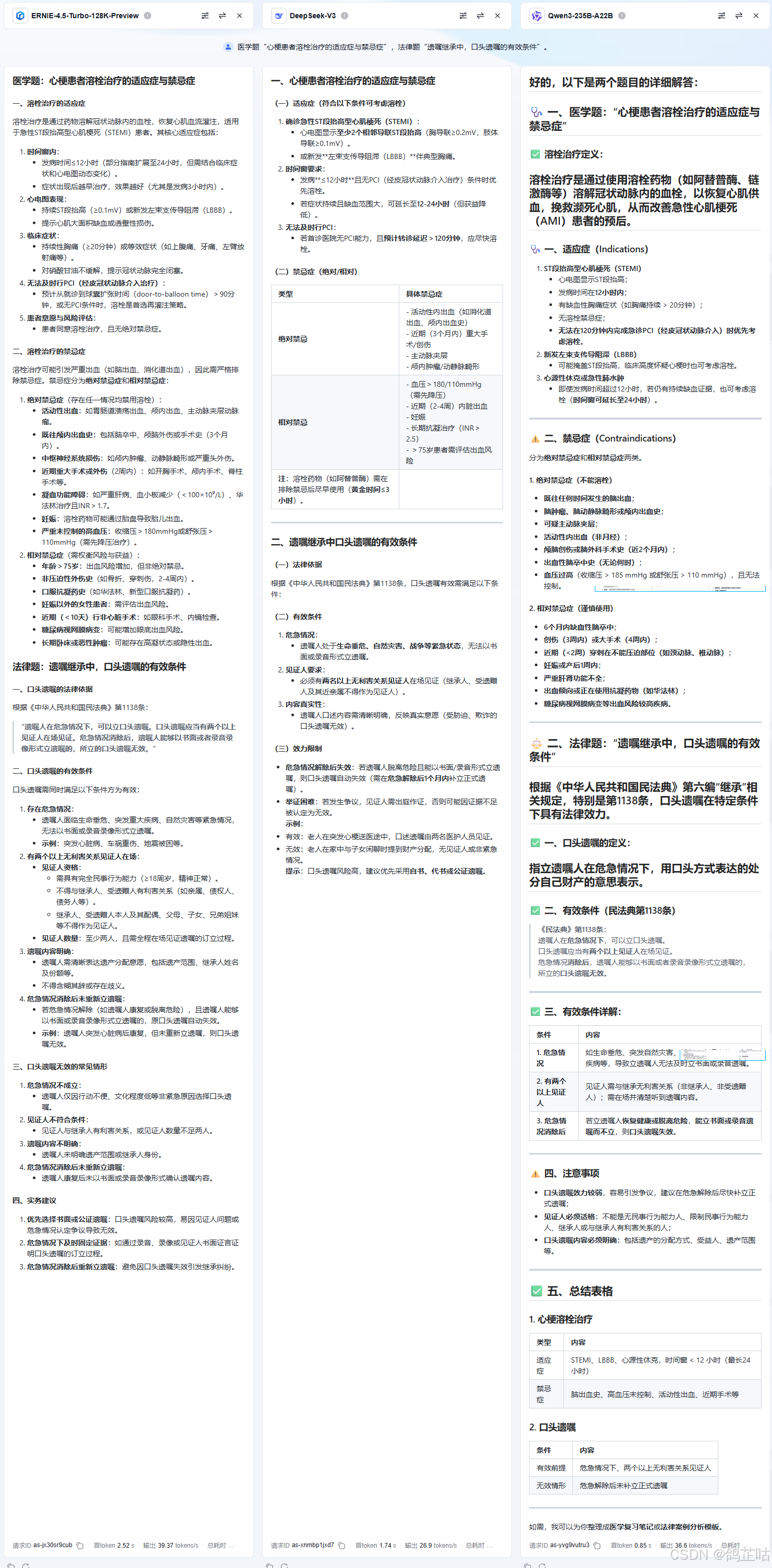
在专业领域测试中,千问与 DeepSeek 的整体表现旗鼓相当,测试成绩难分伯仲。不过,若从输出内容的丰富度来看,文心 4.5 与千问的优势则更为突出 —— 二者在回答专业问题时,不仅能精准覆盖核心知识点,还会补充大量细节化的文字描述,比如对复杂概念的分层解析、专业流程的分步拆解,或是结合实际案例的延伸说明。
这种 “干货满满” 的输出风格,既展现了模型对专业领域知识的深度掌握,也为使用者提供了更全面的信息参考,无疑是专业场景下极具价值的优势。相比之下,DeepSeek 在内容详尽度上稍显逊色,虽能保证答案的专业性与准确性,但输出的文字篇幅和细节丰富度略不及前两者。
| 模型名称 | 首Token | 总耗时 | 总调用(tokens) | 正确性 | 总分 |
|---|---|---|---|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 2.52s | 36.48s | 1337 tokens | 正确 | 6 |
| DeepSeek-V3 | 1.74s | 28.21s | 712 tokens | 正确 | 9 |
| Qwen3-235B-A22B | 0.85s | 33.93s | 1065 tokens | 正确 | 9 |
3.2 语言理解能力测试
多语言与翻译
问题一:
- 多语言与翻译:“将句子『The quick brown fox jumps over the lazy dog』翻译成中文、法语和日语,并解释这句英语的特别之处。”
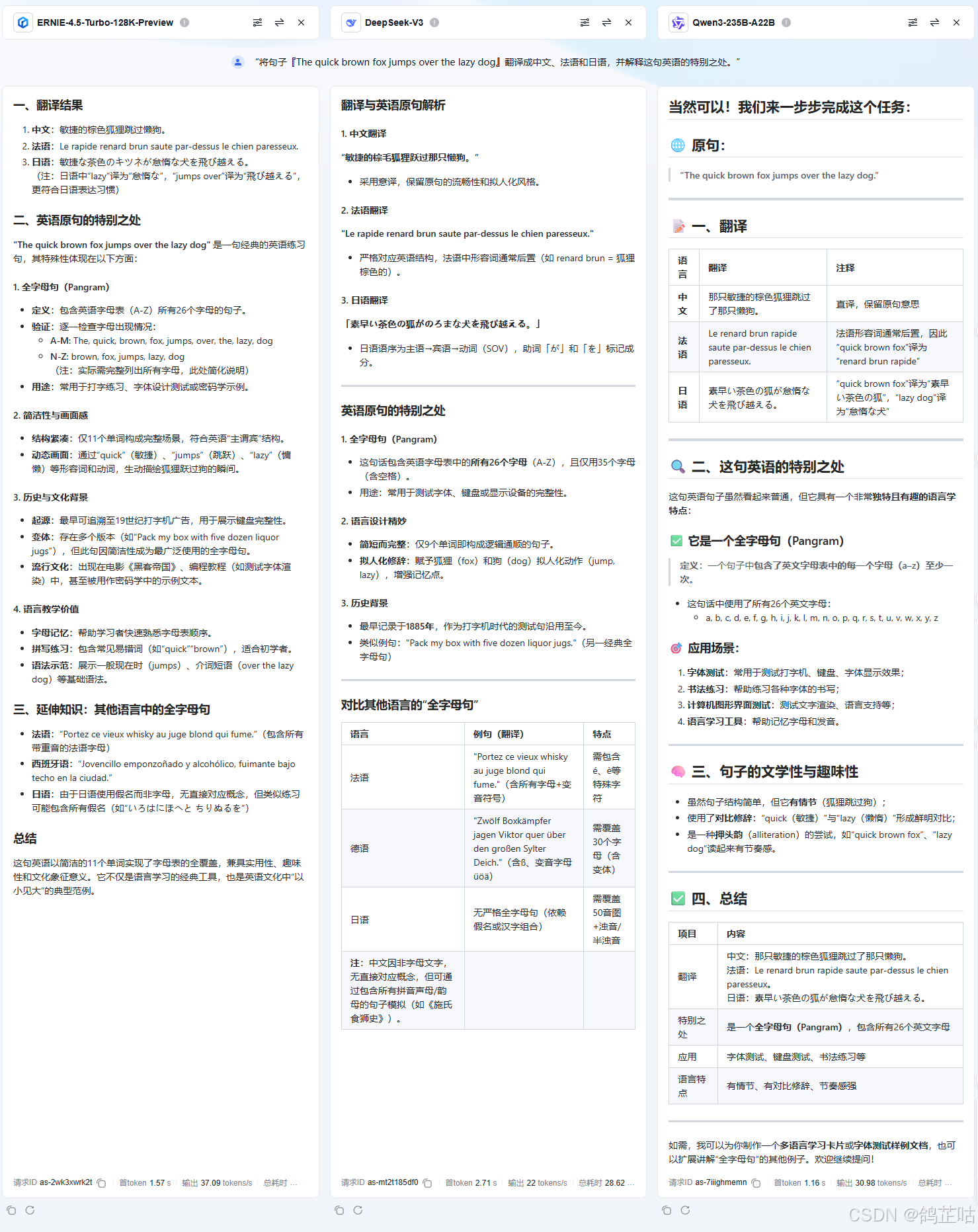
在多语言翻译测试中,文心 4.5 的表现令人惊喜地呈现出碾压性优势,整体评测分数大幅领先于 DeepSeek-V3 与 Qwen3-235B-A22B,堪称 “一骑绝尘”。更值得关注的是,它不仅以最少的耗时完成了翻译任务,保证了高效的响应速度,同时输出的总 tokens 数量也是所有测试模型中最多的。
| 模型名称 | 首Token | 总耗时 | 总调用(tokens) | 正确性 | 总分 |
|---|---|---|---|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 1.57s | 22.43s | 774 tokens | 正确 | 10 |
| DeepSeek-V3 | 2.71s | 28.62s | 570 tokens | 正确 | 6 |
| Qwen3-235B-A22B | 1.16s | 23.65s | 697 tokens | 正确 | 8 |
多语种混合
问题二:
- 多语种混合:输入“日本語と英語の mix テキスト、この意味を中国語で説明して(日语+英语混合文本,用中文解释含义 )”,测试跨语种理解。
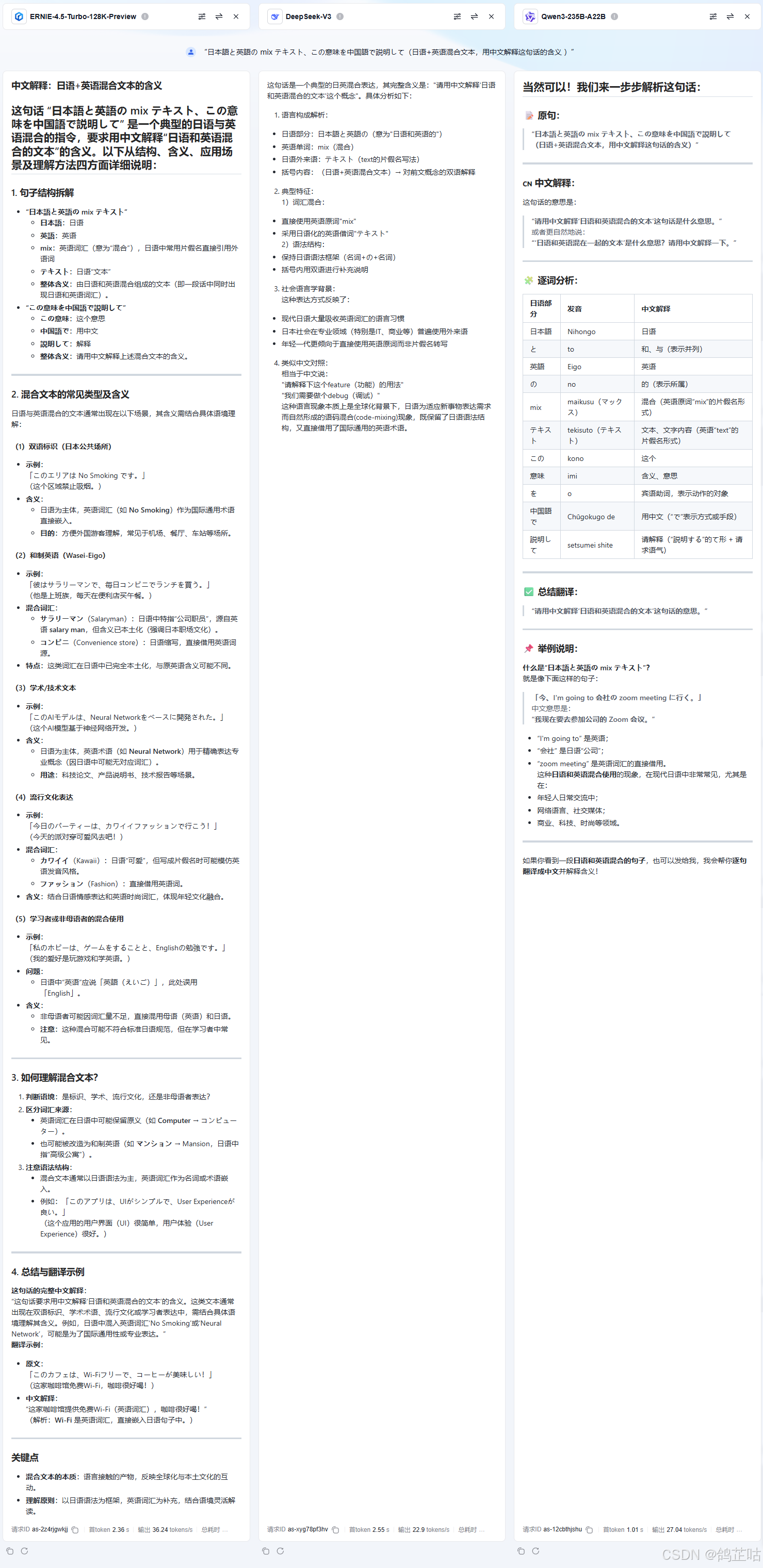
在多语种混合场景测试中,三款模型的表现呈现明显梯度差异。其中,DeepSeek-V3 的表现最为逊色,不仅整体输出质量垫底,其总 tokens 输出量甚至不足 ERNIE-4.5-Turbo-128K-Preview 的四分之一,在处理多语言混杂的复杂语境时,常出现语义断裂、转换生硬的问题,信息覆盖度严重不足。
Qwen3-235B-A22B 的表现则相对中规中矩,虽能基本完成多语种混合内容的理解与转换,逻辑连贯性和准确性达到合格线,但与 ERNIE-4.5 相比,其输出内容的丰富度存在显著差距
| 模型名称 | 首Token | 总耗时 | 总调用(tokens) | 正确性 | 总分 |
|---|---|---|---|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 2.36s | 38.84s | 1322 tokens | 正确 | 7 |
| DeepSeek-V3 | 2.55s | 15.65s | 300 tokens | 输出劣少 | 6 |
| Qwen3-235B-A22B | 1.01s | 22.43s | 579 tokens | 正确 | 8 |
3.5 代码能力测试
在代码这部分我们也来进行测试一下看看3个大模型的代码能力怎么样?本次也选取了一个比较有难度的代码任务,为了更好的展示效果我们选择生成单个html文件,方便网页直接打开查看。
问题:通过html,创建一个动态时钟页面,要求如下:
必须以单个html文件形式创建,有时针分针秒针的表盘式时钟。
时间会每秒自动更新,始终显示当前时间。
样式要求:时钟在页面中央,背景为淡蓝色
- 得分点:需要时针分针秒针
聚集在表盘中心,且时间显示正确,
时钟位置在页面中央,背景颜色为淡蓝色,
只能使用单个html文件创建。
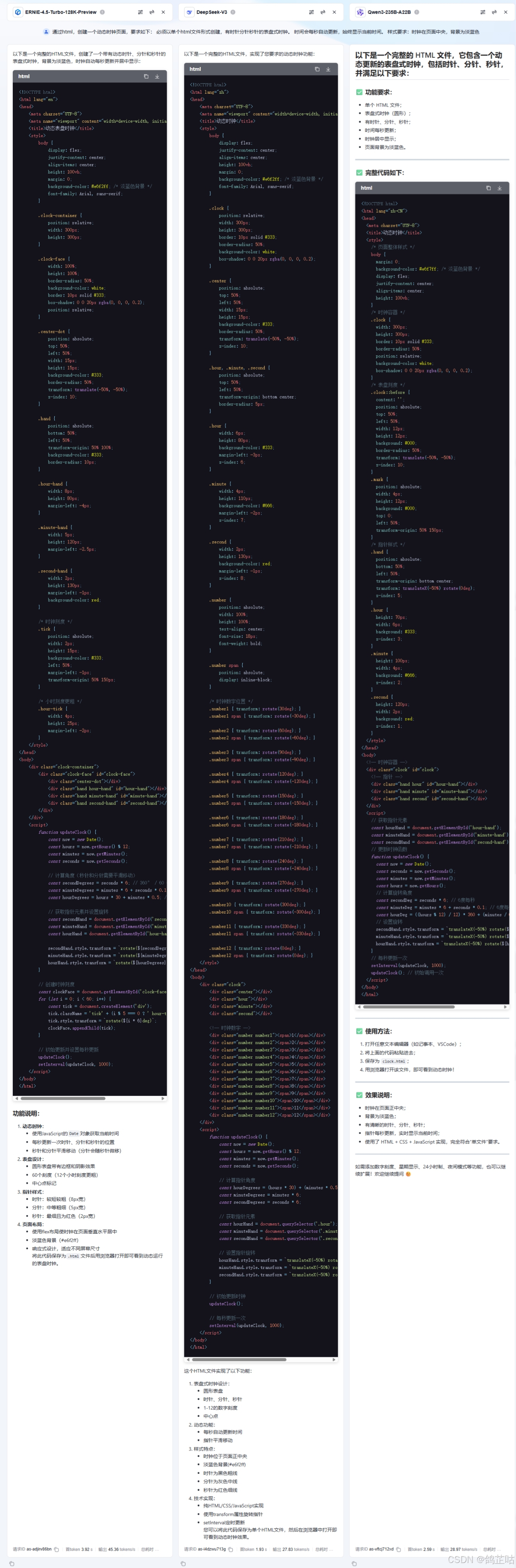
在代码能力测试环节,直观来看,DeepSeek-V3 在生成代码的长度上表现颇为突出,其评分也与文心 4.5 一同位居榜首,形成并列第一的局面。不过,代码的长度与评分并不能完全等同于实际质量,下面我们运行一下各个大模型生成的代码看看哪家的代码要求完成的最好吧!
| 模型名称 | 首Token | 总耗时 | 总调用(tokens) | 正确性 | 总分 |
|---|---|---|---|---|---|
| ERNIE-4.5-Turbo-128K-Preview | 3.92s | 37.23s | 1511 tokens | 正确 | 8 |
| DeepSeek-V3 | 1.93s | 57.99s | 1560 tokens | 不合格 | 6 |
| Qwen3-235B-A22B | 2.59s | 42.77s | 1164 tokens | 正确 | 7 |
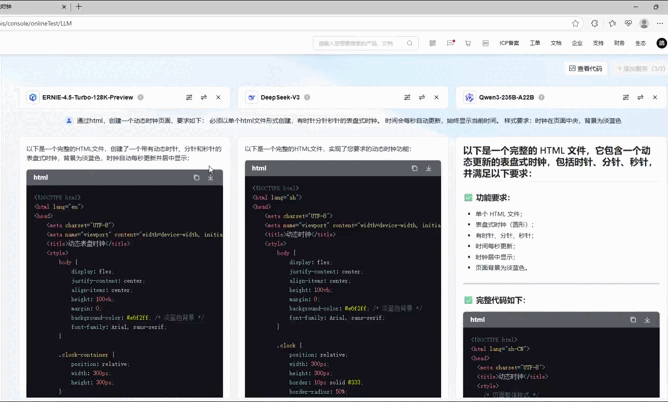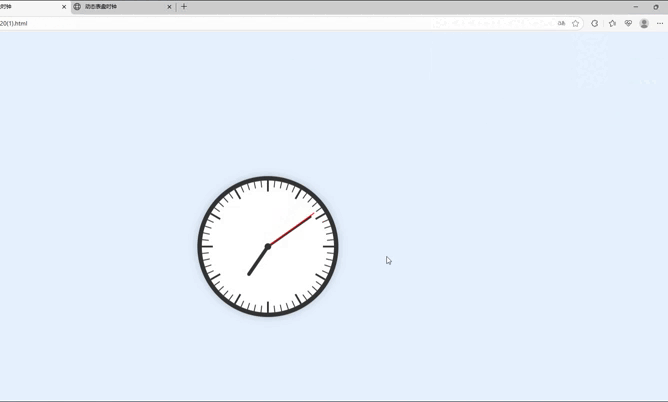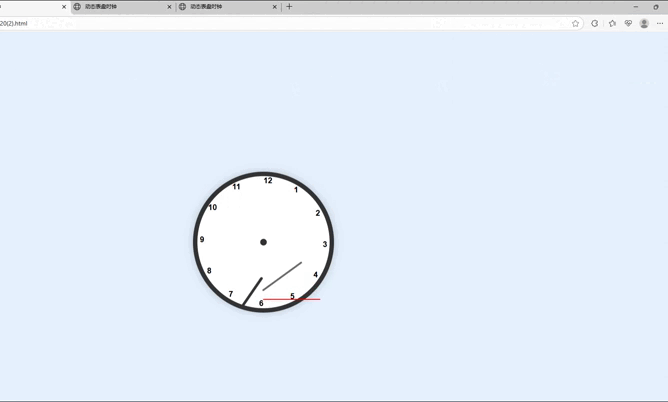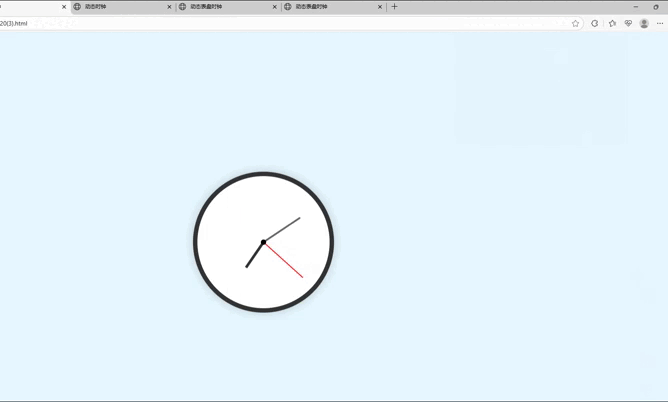
令人意外的是,在代码长度上看似占优的DeepSeek-V3,此次却在实际效果中出现了明显问题——生成的时钟未能居中显示在页面上,功能实现存在疏漏。相比之下,文心4.5的代码展示效果最为出色:不仅时钟整体布局美观协调,指针还能与时间刻度完全精准对齐,完美达成了设计目标。而Qwen3-235B-A22B的表现稍逊一筹,虽然基本功能得以实现,但存在一个关键缺陷——指针缺乏对应的时间刻度标识,导致视觉呈现和实用性上略打折扣。
五、结语
本次测试横跨逻辑推理、知识问答、语言理解、代码能力等多个维度,对 ERNIE-4.5-Turbo-128K-Preview、DeepSeek-V3、Qwen3-235B-A22B 三款大模型展开全面较量。结果清晰显示,文心 4.5 在绝大多数场景中均展现出超越同级的实力:总耗时上的迅捷响应、输出内容的精准贴合,使其在效率与质量的平衡上独树一帜;多语言翻译环节的碾压性表现,代码实现时的完美呈现,更凸显其硬核功底。
- 大家不妨即刻着手部署实践,亲自解锁文心 4.5 带来的卓越效能吧!!!
- 😀一起来轻松玩转文心大模型吧!🎉🎉🎉
- 📌文心大模型免费下载地址: https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)