
【源力觉醒 创作者计划】深度解析百度文心大模型4.5系列
百度官方宣布在6月30日开源旗下大模型,一石激起千层浪。不仅是国内史无前例的一次规模化开源,放眼全球都极具竞争力的一次技术释放,也为AI应用爆发按下快进键。
一起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
一、前言:
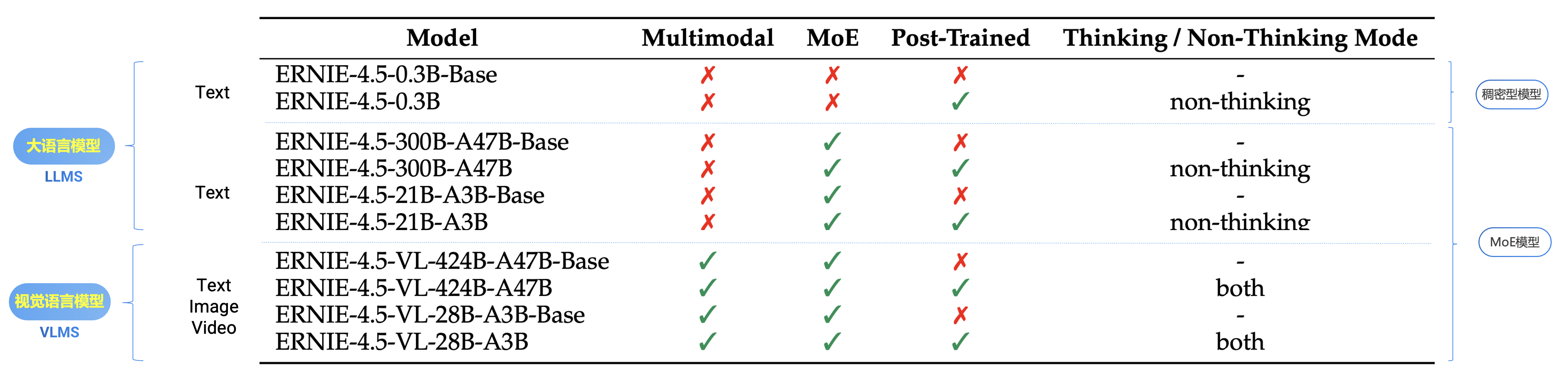
俗话说的好“众人拾柴火焰高”,2025年6月30日,百度正式开源文心大模型4.5系列模型,在 GitCode 上首发宣布“开源”了,其中,涵盖10款不同参数规模的模型,包括激活参数为47B和3B的混合专家(MoE)模型(最大总参数量达424B),以及0.3B的稠密参数模型,提供完整的ERNIEKit微调工具链和FastDeploy推理框架,兼容主流生态,适用于各种业务场景。

百度文心大模型4.5系列的开源是其技术发展的重要里程碑,该模型结合原生多模态架构与高效性能,在多个领域表现突出,此次开源选择了GitCode作为国内首发平台,全球开发者可免费下载使用,同时模型也在GitCode社区、飞桨星河社区、HuggingFace等平台同步上线。
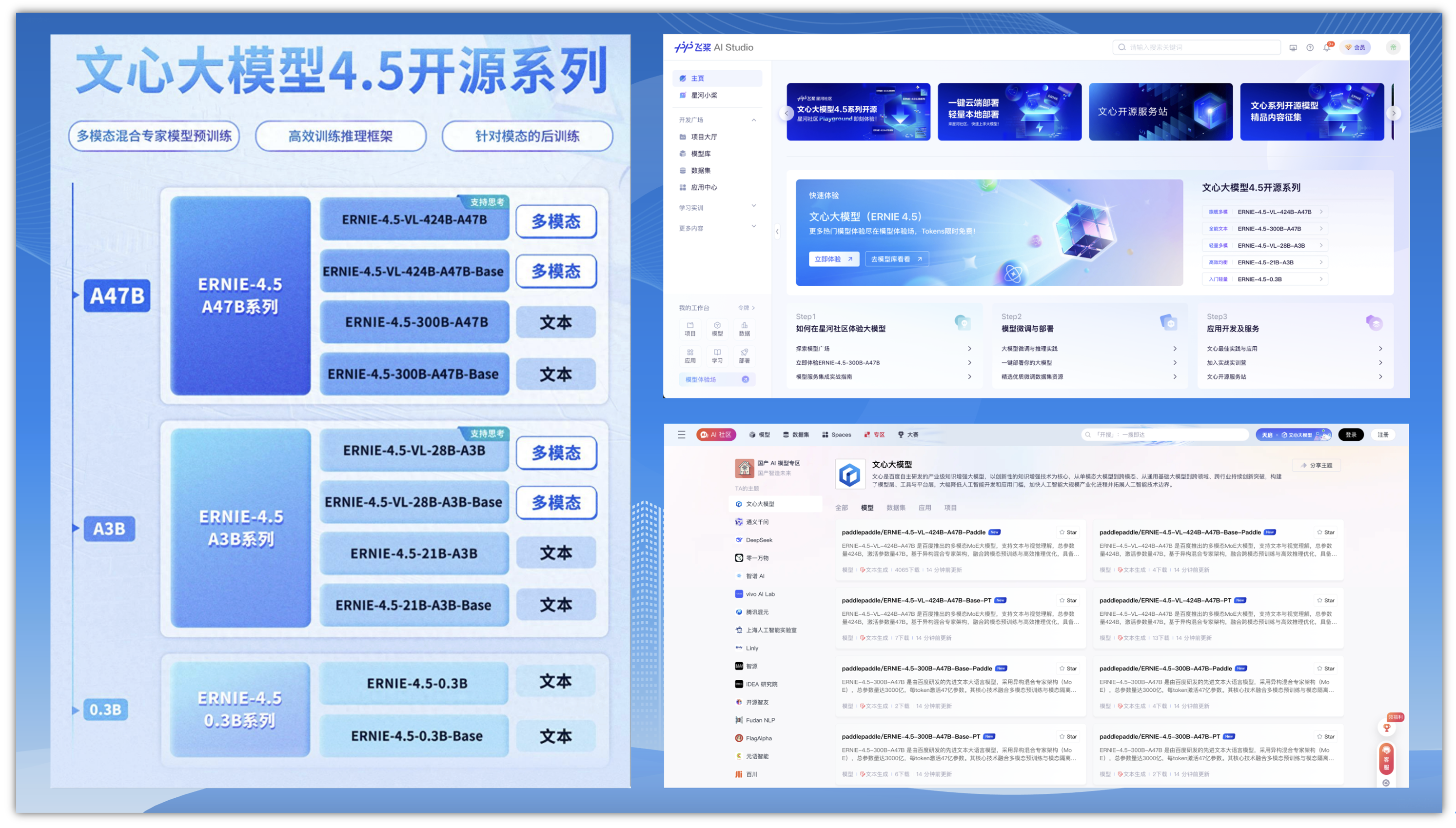
文心大模型4.5是百度于2025年3月16日发布的自研新一代原生多模态基础模型,其核心技术包括:
- ①. 多模态异构专家架构:通过跨模态参数共享机制实现文本、图像、音频和视频的协同优化,支持模态间知识融合,同时保留单一模态专用参数空间,显著提升多模态理解能力。
- ②. 高效训练框架:基于飞桨深度学习平台,模型FLOPs利用率达47%,在训练和推理中实现高性能与低延迟。
二、闭源的高墙,终究敌不过开放生态的洪流:
当DeepSeek以开源模式快速占领开发者心智,并通过免费商用协议构建起庞大的“朋友圈”时,百度的闭源策略瞬间沦为行业孤岛,开源模型“低成本、高性能”的特性已彻底改写竞争逻辑,企业若固守闭源,只会被生态边缘化。
这次开源的还将飞桨框架(PaddlePaddle)、ERNIEKit精调工具链、FastDeploy推理套件。

人工智能产业应用发展的越来越迅速,开发者需要面对的适配部署工作也越来越复杂,层出不穷的算法模型、各种架构的AI硬件、不同场景的部署需求(服务化、嵌入式、移动端等)、不同操作系统和开发语言等都为开发者项目落地带来不小的挑战。
为了解决部署落地难题,飞桨提供了FastDeploy套件,更关注端到端的推理部署能力,最大程度地避免部署中的碎片化工作,FastDeploy具备以下特色能力:
- ①. 低门槛:通过一行命令下载SDK,一行命令体验部署Demo。此外,对于不同硬件平台,FastDeploy提供了一致的代码,降低二次开发难度。
- ②. 多场景:支持云、边、端(包括移动端)丰富软硬件环境部署,支持图像、视频流、一键服务化等部署方式,满足不同场景的AI部署需求。
- ③. 多算法:支持图像分类、目标检测、图像分割、人脸检测、人体关键点检测、文本识别等30多个主流算法模型。

开源模式本质上是将软件源代码公开,包括代码、架构、训练数据、技术细节等均被公开,允许开发者自由查看、修改和共享,提升透明度和可扩展性,促进社区协作创新,这就避免了闭源模型常见的数据隐私风险和缺乏透明度等问题。
“文心大模型4.5”支持文本与视觉理解、高效推理优化及多模态任务处理等,并且预训练权重和推理代码完全开源,为开发者提供了极大的便利,该系列采用飞桨深度学习框架,实现了高效训练和部署,模型权重遵循Apache 2.0协议开源,支持学术研究和产业应用的自由使用与修改。
三、ERNIE 4.5技术解读:
文心4.5系列模型均使用飞桨深度学习框架进行高效训练、推理和部署。在大语言模型的预训练中,模型FLOPs利用率(MFU)达到47%。模型在多个文本和多模态数据集上取得了 SOTA 的性能,尤其是在指令遵循、世界知识记忆、视觉理解和多模态推理方面。
3.1 技术突破一:异构模态MoE架构(Heterogeneous Modality MoE):
针对 MoE 架构,文心一言提出了一种创新性的多模态异构模型结构,通过跨模态参数共享机制实现模态间知识融合,同时为各单一模态保留专用参数空间,此架构非常适用于从大语言模型向多模态模型的持续预训练范式,在保持甚至提升文本任务性能的基础上,显著增强多模态理解能力。
ERNIE 4.5 是百度研发的一系列大规模基础模型,一共包含10种变体(6个文本模型、4个多模态模型)的模型家族,核心特点如下:
3.1.1 模型架构 - 模态专属专家分离:
-
①. 包含混合专家模型(MoE)和密集模型(Dense),旗舰模型最大模型总参数量达424B(激活active参数47B),最小密集模型0.3B。
-
②. 支持异构模态结构(heterogeneous modality structure),支持跨模态参数共享,同时保留各模态专用参数。

和标准的多模态大模型一样,整体分为三个模块,主要技术点总结:
-
①. 视觉编码器(Vision Encoder):采用配备自适应分辨率和2D旋转位置嵌入(2D-RoPE)的ViT,自适应分辨率ViT,结合2D旋转位置嵌入(RoPE)和动态帧采样技术。
-
②. 适配器(Adapter): 对齐多模态特征空间,通过空间-时间压缩减少序列长度。空间和时间压缩,多模态位置嵌入,在视觉语言模型中使用3D-RoPE,分别编码时间、宽度和高度位置。
-
③. 多模态异构MoE设计:支持文本、图像、视频输入,通过共享参数和模态专用专家实现跨模态理解。文本和视觉特征被路由到不同的专家集合,同时它们也通过一组共享的专家以及所有的自注意力参数,视觉专家的参数是文本专家的三分之一。
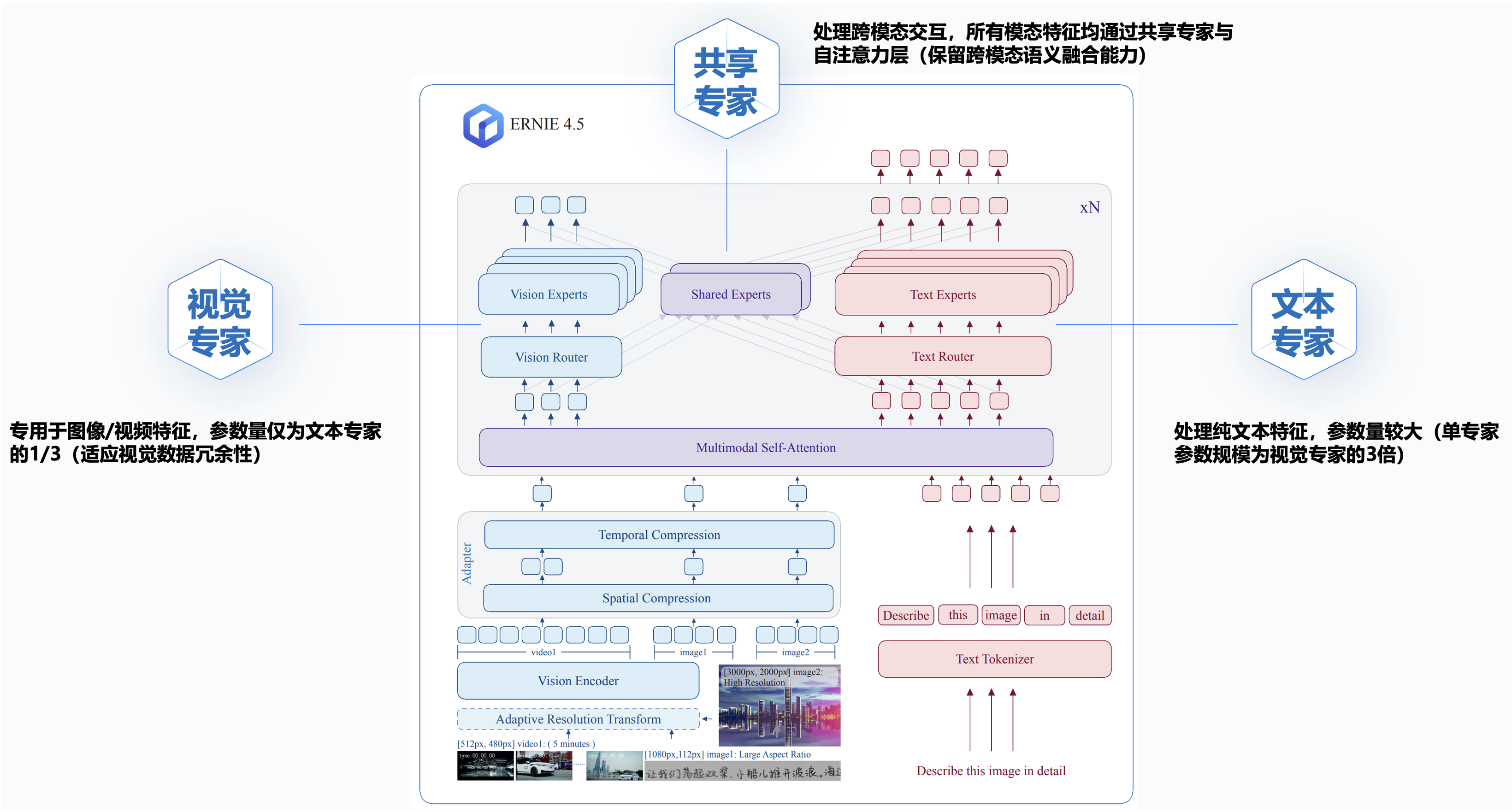
- ①. 文本专家:处理纯文本特征,参数量较大(单专家参数规模为视觉专家的3倍)。
- ②. 视觉专家:专用于图像/视频特征,参数量仅为文本专家的1/3,减少66%的计算量(适应视觉数据冗余性)。
- ③. 共享专家:通过双压缩层将视觉表征投影到共享嵌入空间,实现模态对齐与特征融合,处理跨模态交互,所有模态特征均通过共享专家与自注意力层(保留跨模态语义融合能力)。
ERNIE 4.5 模型通过模块化设计实现文本与视觉组件的灵活分离,利用视觉token的冗余性,降低计算开销,该架构通过分离模态参数与共享参数,平衡计算效率与多模态联合训练效果,适用于图像、视频和文本的跨模态任务。
3.1.2 模态隔离路由(Modality-Isolated Routing):
在多模态建模中,MoE路由容易出现不稳定性,尤其是将仅文本的MoE模型扩展到处理多模态输入可能导致MoE路由崩溃,从而降低文本能力,为了解决这个问题,提出了一个模态隔离的路由策略。
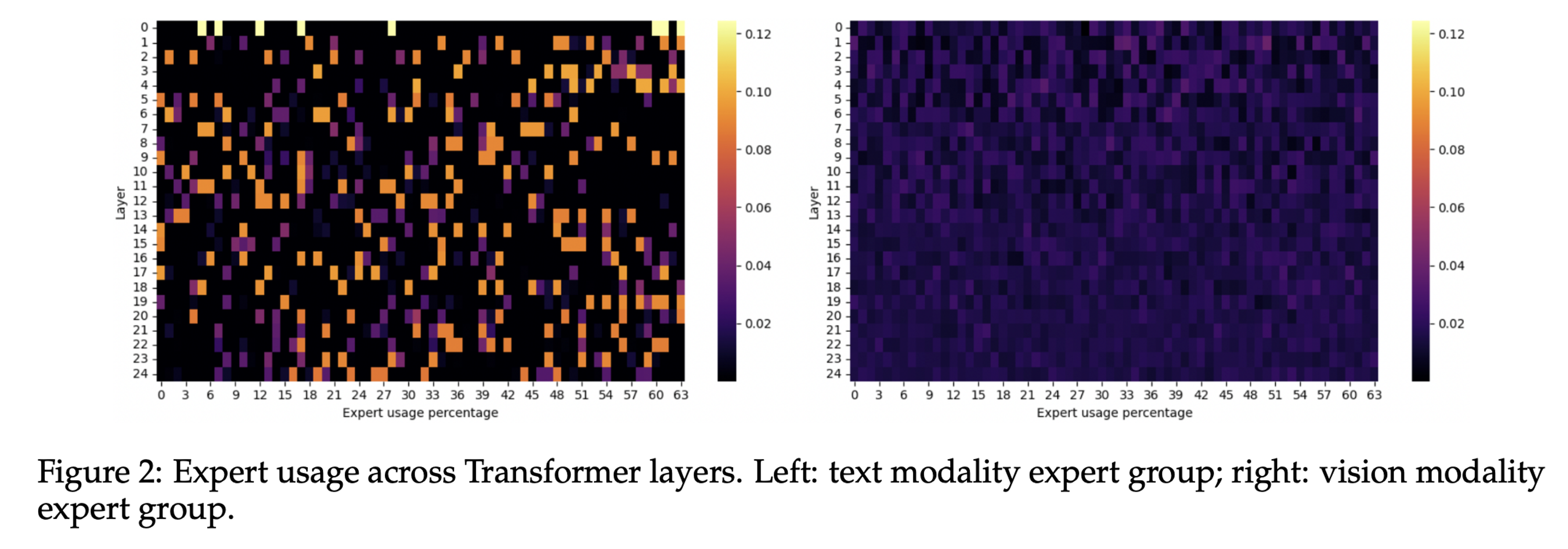
ERNIE 4.5中的FFN专家被分为三种类型, 不同模态特征的MoE使用率表现差异极大,因此要分开处理,避免跨模态干扰:
- ①. 文本(红色)路由至文本专家。
- ②. 视觉(蓝色)路由至视觉专家,视觉专家参数规模仅为文本专家的1/3,降低视觉计算冗余,提升效率。
- ③. 共享专家(紫色)处理统一跨模态隐藏状态,关通过自注意力层整合知识。
路由机制确保文本特征仅流向文本专家,视觉特征仅流向视觉专家,避免模态干扰(下图热力图显示文本专家激活集中,视觉专家激活分散),视觉专家在训练后期引入,避免路由崩溃,同时减少计算量(视觉理解依赖已有文本知识)。
- ①. 与稠密FFN方法(Wang et al.)对比:采用细粒度MoE骨干,提升可扩展性。
- ②. 与全MoE路由(Liang et al.)对比:保留稠密注意力层以维持跨模态交互,仅限FFN层使用MoE路由。
- ③. 与专家选择门控(Lin et al.)对比:采用细粒度Top-K路由,兼容自回归解码并支持长上下文训练。
通过路由正交损失(Router Orthogonalization Loss) 优化专家权重正交性,提升专家专业化程度(公式1),实验证明文本任务性能提升+1.44%,路由器正交化损失通过强制路由器权重向量正交化,促进更均衡的路由分配。
3.1.3 计算效率优化:
- ①. 视觉专家跳过最后一层Transformer(不影响交叉熵损失),减少冗余计算。
- ②. 视觉Token的FFN计算量降低66%(因视觉专家中间维度缩减至1/3)。
3.1.4 优势:
- ①. 多模态统一建模:
- (1). 联合优化文本与视觉参数,支持百亿级参数量扩展。
- (2). 所有参数(文本 + 视觉)联合优化,相较于部分调参方法,数据效率更高。
- (3). 保留了密集注意力层(Dense Attention),维持跨模态交互能力。
- ②. 路由稳定性:
- (1). 分阶段训练策略(文本知识先于视觉学习)减少总体计算量,避免路由崩溃,同时保持性能。
- (2). 视觉专家可在训练后期引入,避免路由机制崩溃(Routing Collapse)。
- ③. 推理灵活性:
- (1). 纯文本推理场景/任务:可跳过视觉专家,降低内存占用。
- (2). 多模态推理场景任务:支持模态感知流水线拆分(Prefill-Text/Prefill-Vision/Decode-Text模块独立部署,可参考PD分离),通过动态分配各模态计算预算,减少跨设备通信开销。
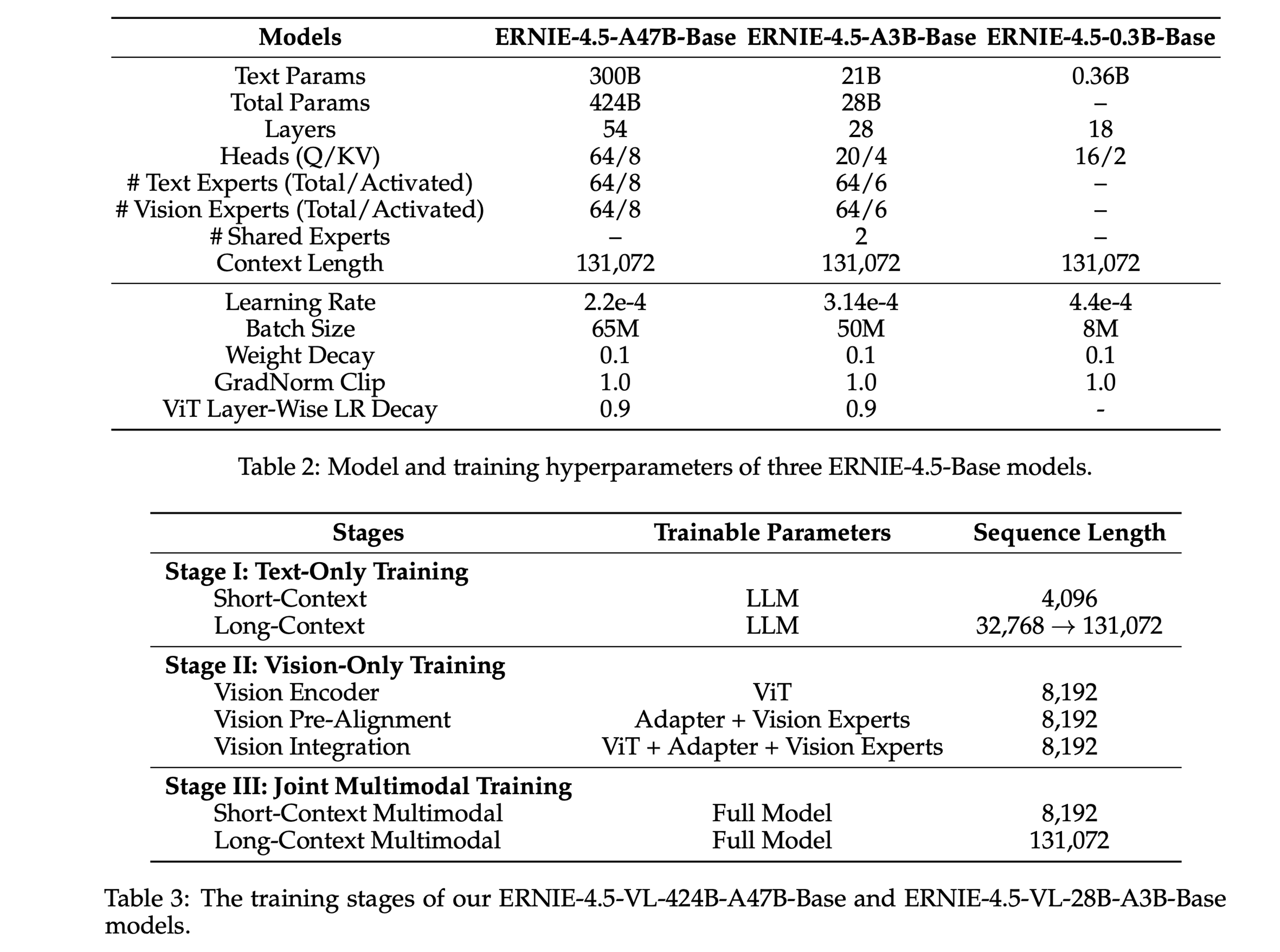
纯语言模型LLM Post-Training:
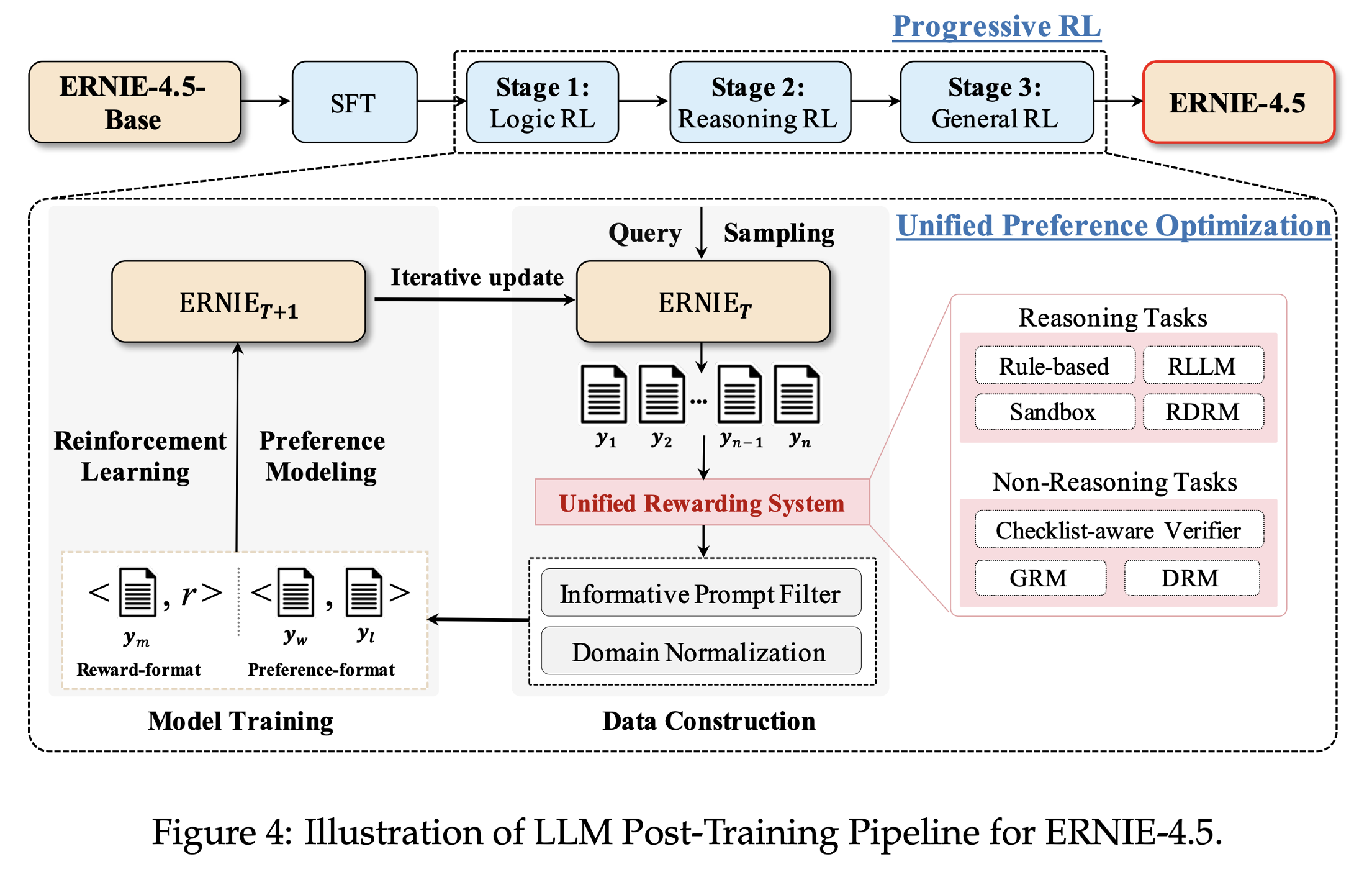
视觉语言模型VLM Post-Training:
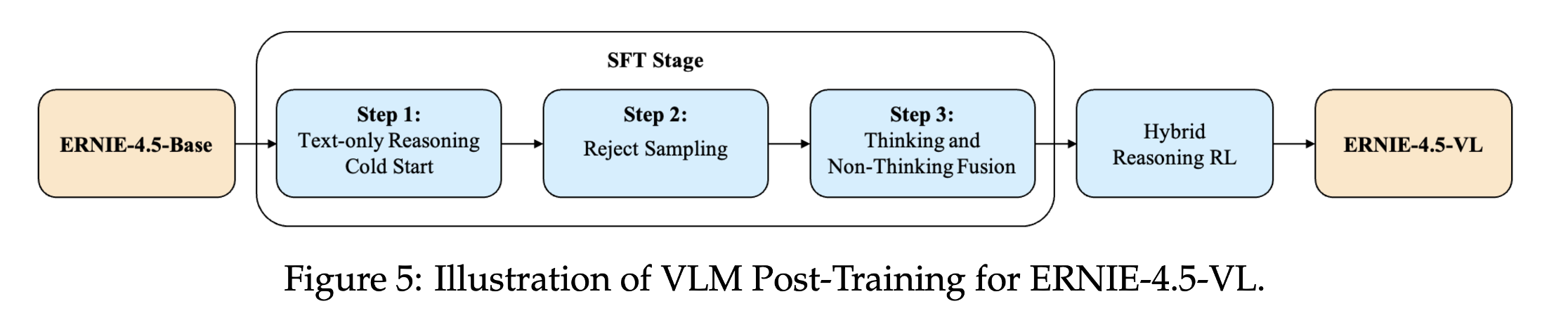
3.2 技术突破二:自适应视觉编码与对齐:
3.2.1 可变分辨率ViT编码器(Vision Encoder):
视觉编码器使用的是目NaViT的架构,支持自适应分辨率,即调整图像高度/宽度至ViT分块尺寸的整数倍,保留原始比例,避免固定分辨率导致的形变。
- ①. 图像:动态调整高/宽至ViT Patch尺寸的最近倍数,保留原始宽高比(避免方形扭曲)。
- ②. 视频:自适应帧采样策略(时长>阈值时降分辨率/减帧),最大化利用序列长度。
- ③. 位置编码:2D RoPE(图像)→ 3D RoPE(视频),独立编码时间、宽、高维度。
3.2.2 时间戳渲染(Temporal Grounding):
在视频帧左上角叠加绝对时间戳(替代位置嵌入),显式提供时序线索(图1示例),提升长视频理解能力。
3.2.3 跨模态对齐(Adapter模块):
- ①. 双压缩层:空间压缩(非重叠2×2 Patch → 4×降Token)、时间压缩(序列长减半),像素重排(Pixel Shuffle)实现特征融合。
- ②. 统一处理:静态图像视为双帧视频,确保时空建模一致性。
3.3 技术突破三:高效训练框架:
ERNIE 4.5 支持统一处理文本、图像与视频输入。以 ERNIE-4.5-VL-424B-A47B-Base 为例:
- ①. ViT编码器:6.3 亿参数,数据并行(DP),参数复制到所有设备。
- ②. MoE主干:总参数 4240 亿,每次激活 470 亿,混合并行(专家并行EP + 流水线并行PP + ZeRO-1数据并行)。
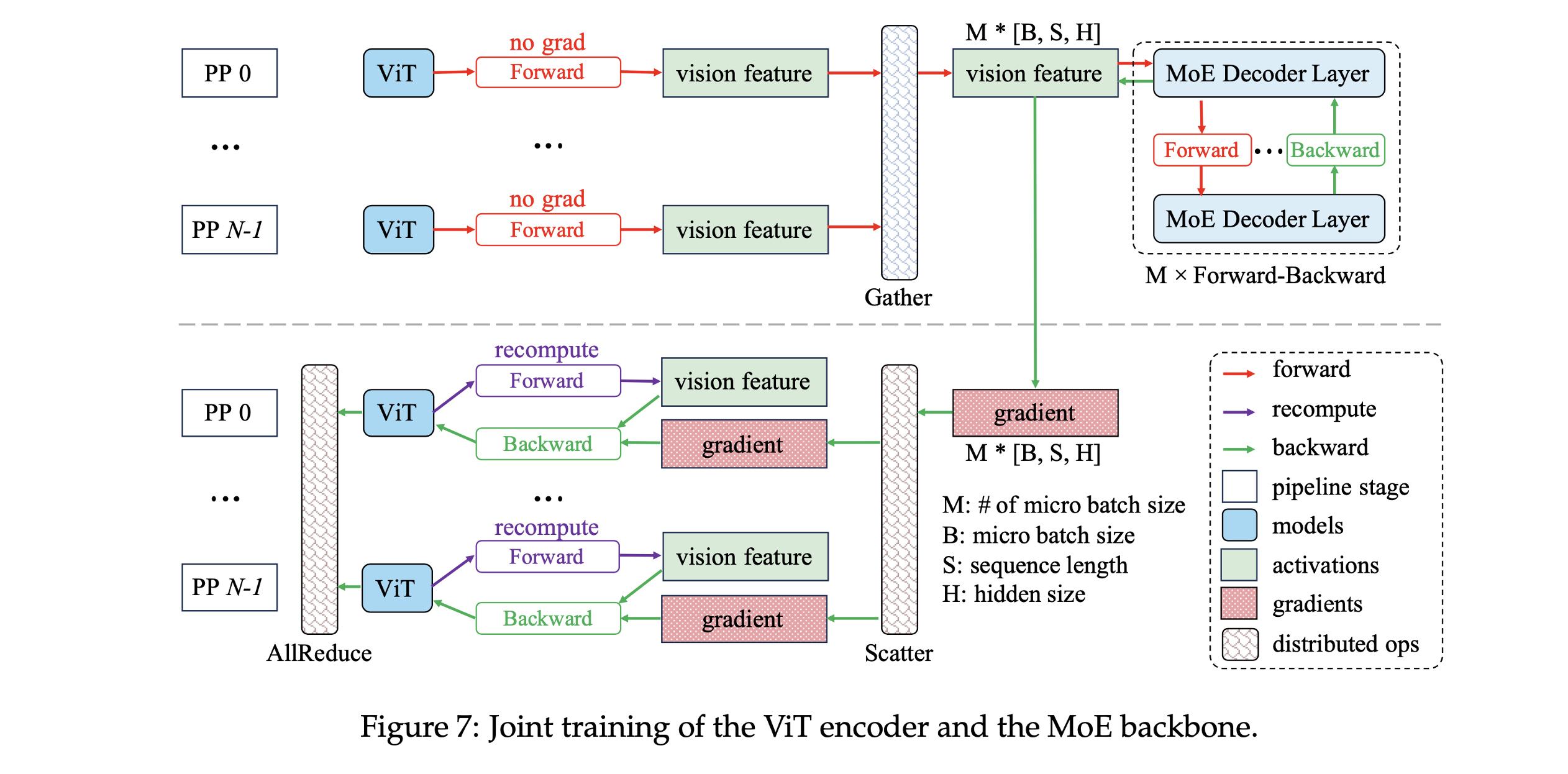
- ③. 关键创新:ViT梯度通过定制反向传播机制计算(图7),避免流水线并行导致的梯度断裂
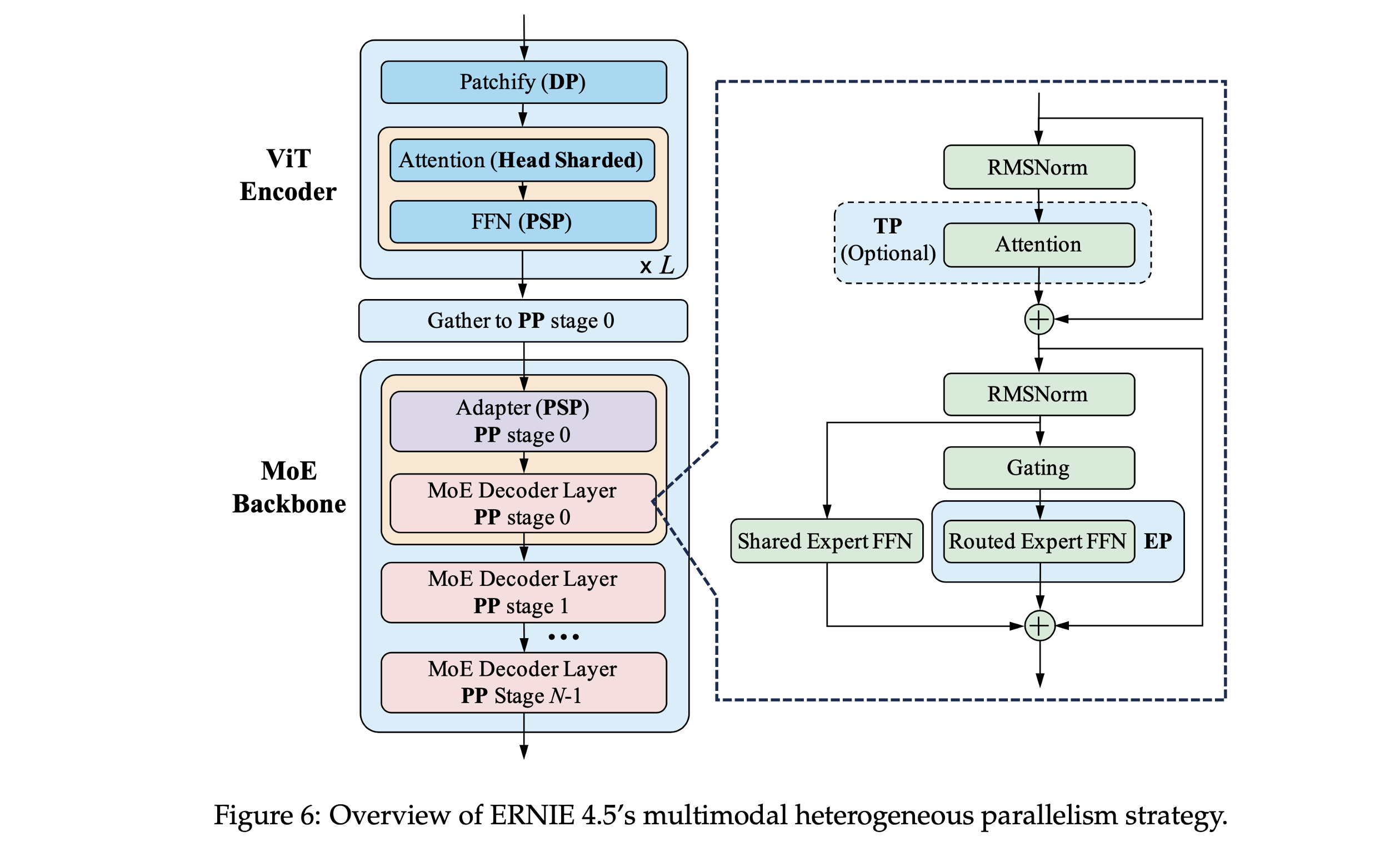
ERNIE 4.5提出的并行策略:
- ①. ViT 编码器复制于所有设备,采用数据并行。
- ②. MoE 主干采用 EP(专家并行)、PP(流水线并行)和 DP(数据并行)。
- ③. 推理时 ViT 前向输出传递到 MoE 第一阶段。
- ④. 自定义反向传播机制:在 MoE 主干反向传播完成后,将视觉特征的梯度分发回各 ViT 编码器。
- ⑤. ViT 参数更新使用 All-Reduce 同步。
- ⑥. ViT 可选重计算以节省内存。
分层级负载均衡策略:
ERNIE 4.5 支持变分辨率输入。由于图像/视频帧尺寸差异大,训练过程中 token 数量高度不均衡。我们提出两级负载均衡:
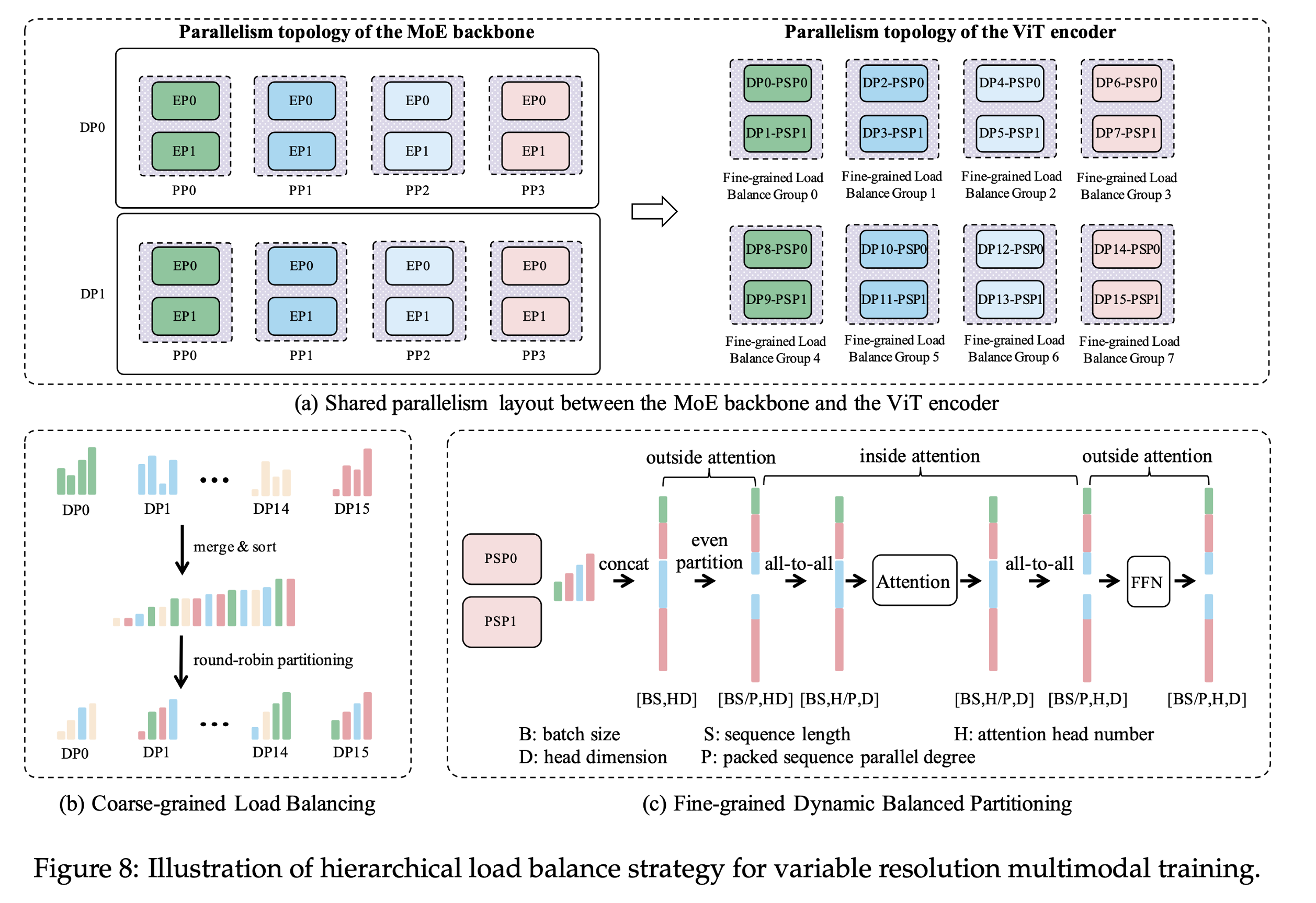
-
①. 一级Level 1(粗粒度):按Token数排序数据包,轮询分配至设备,将所有 packed sequences 按 token 数排序后使用 round-robin 分配,平衡总体 token 数。
-
②. 二级Level 2(细粒度):
-
(1). Attention 外部算子:序列并行(PSP)拼接数据包并均匀切分,采用“Packed Sequence 并行”(PSP),按序列长度均分;
-
(2). Attention 内部算子:All-to-All通信交换序列/注意力头维度,执行 All-to-All 通信交换序列长度和注意力头维度,确保正确计算后恢复 PSP。
-
③. 结果:多模态训练吞吐性能端到端多模态训练效率提升最高达 32%。
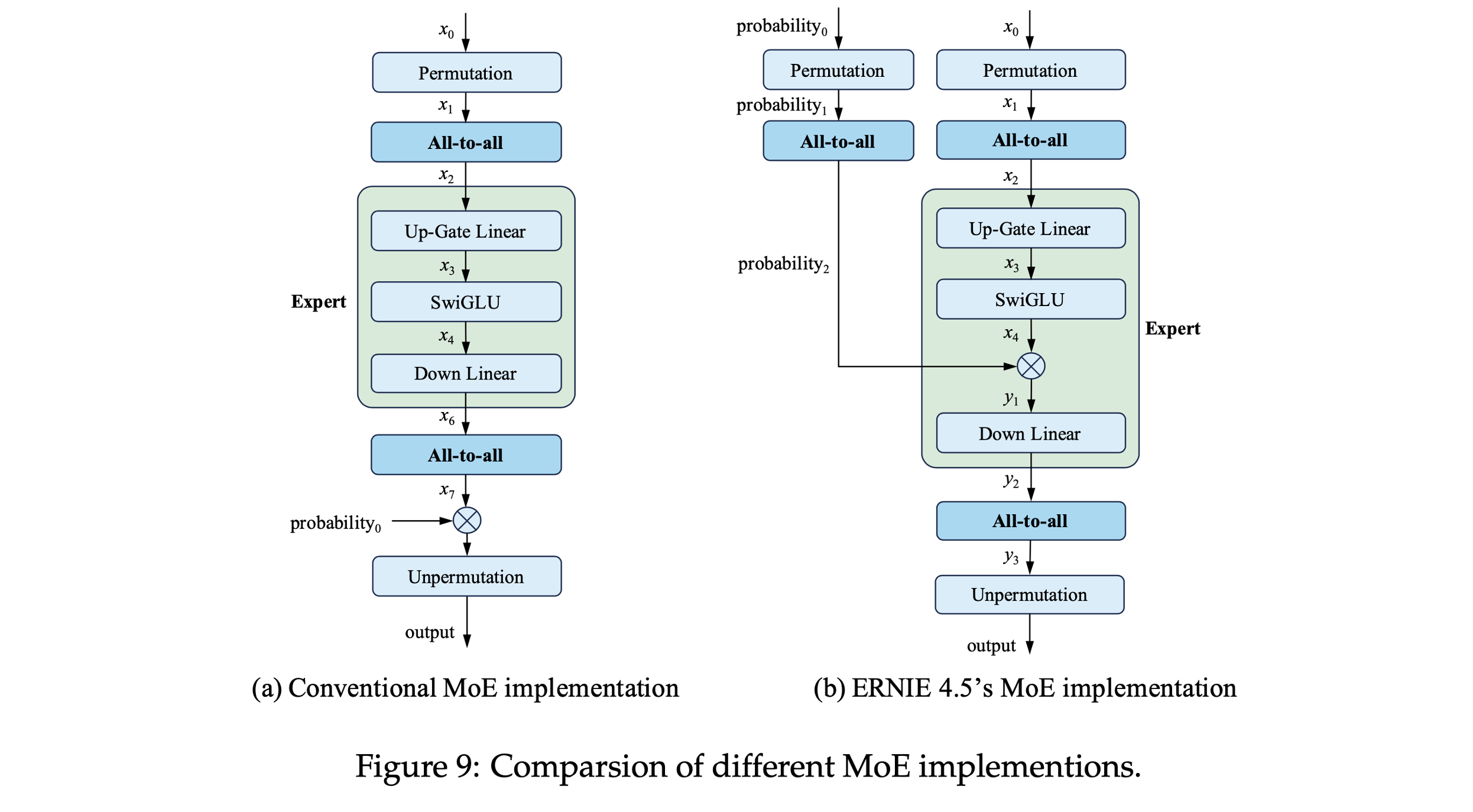
节点内专家并行(Intra-Node EP):
- ①. 所有专家通信仅限节点内,避免跨节点 All-to-All。
- ②. 使用 NCCL 实现 All-to-All。
- ③. 优化:将 gating 概率乘法操作移入专家计算模块内部,通过这种结构上的调整,在消费完张量后,即可立即释放第二次 all-to-all 的输出张量,减少内存压力。
- ④. 降低重计算需求,保持端到端吞吐性能。
FP8混合精度训练:
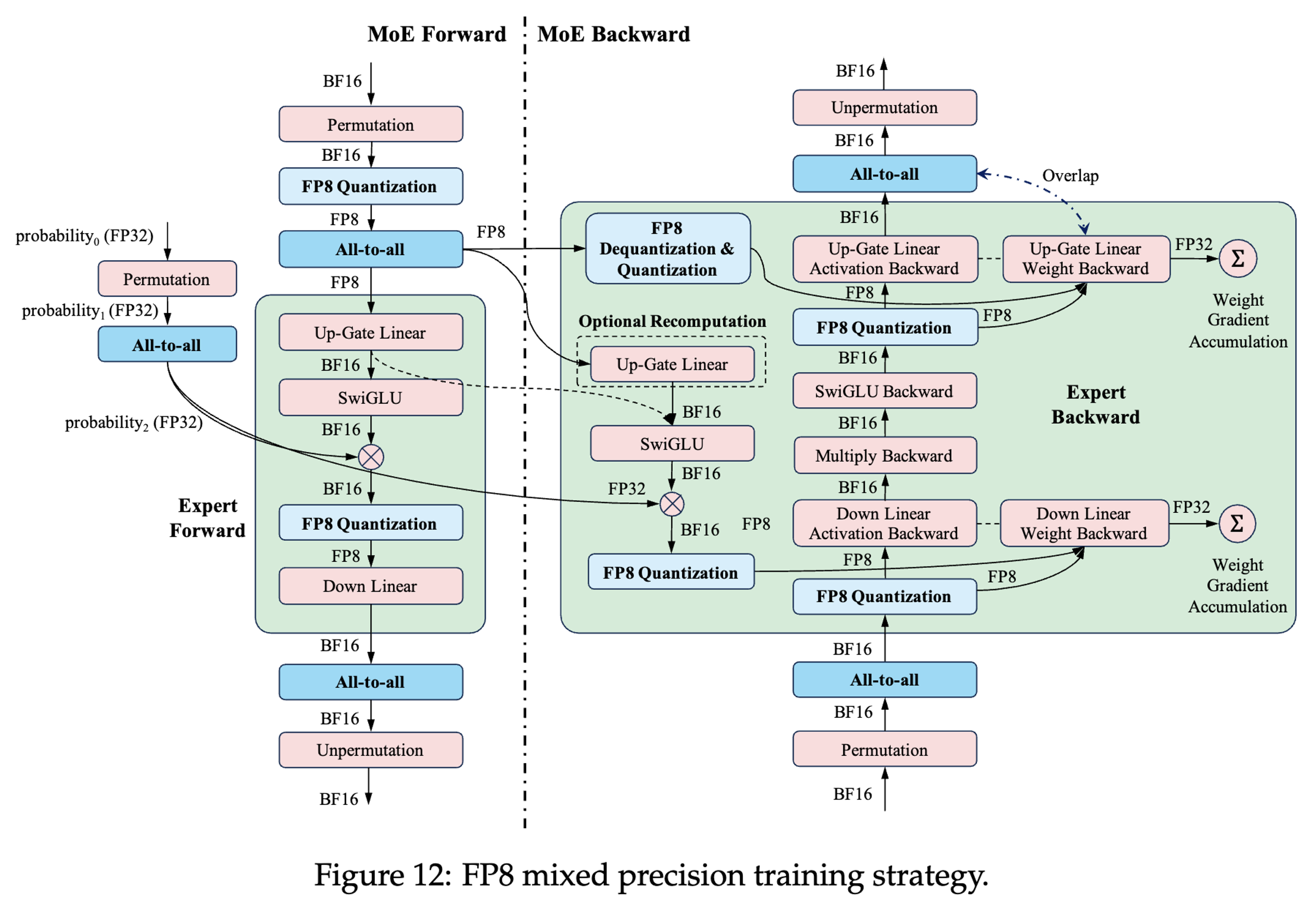
- ①. MoE FFN层优化:
- (1). 保留FP8输入激活(非BF16),减少内存占用。
- (2). 算子融合(SwiGLU + 门控概率乘法 + FP8量化)。
- ②. 通信优化:FP8精度All-to-All通信,带宽需求减半。
内存高效流水线调度:
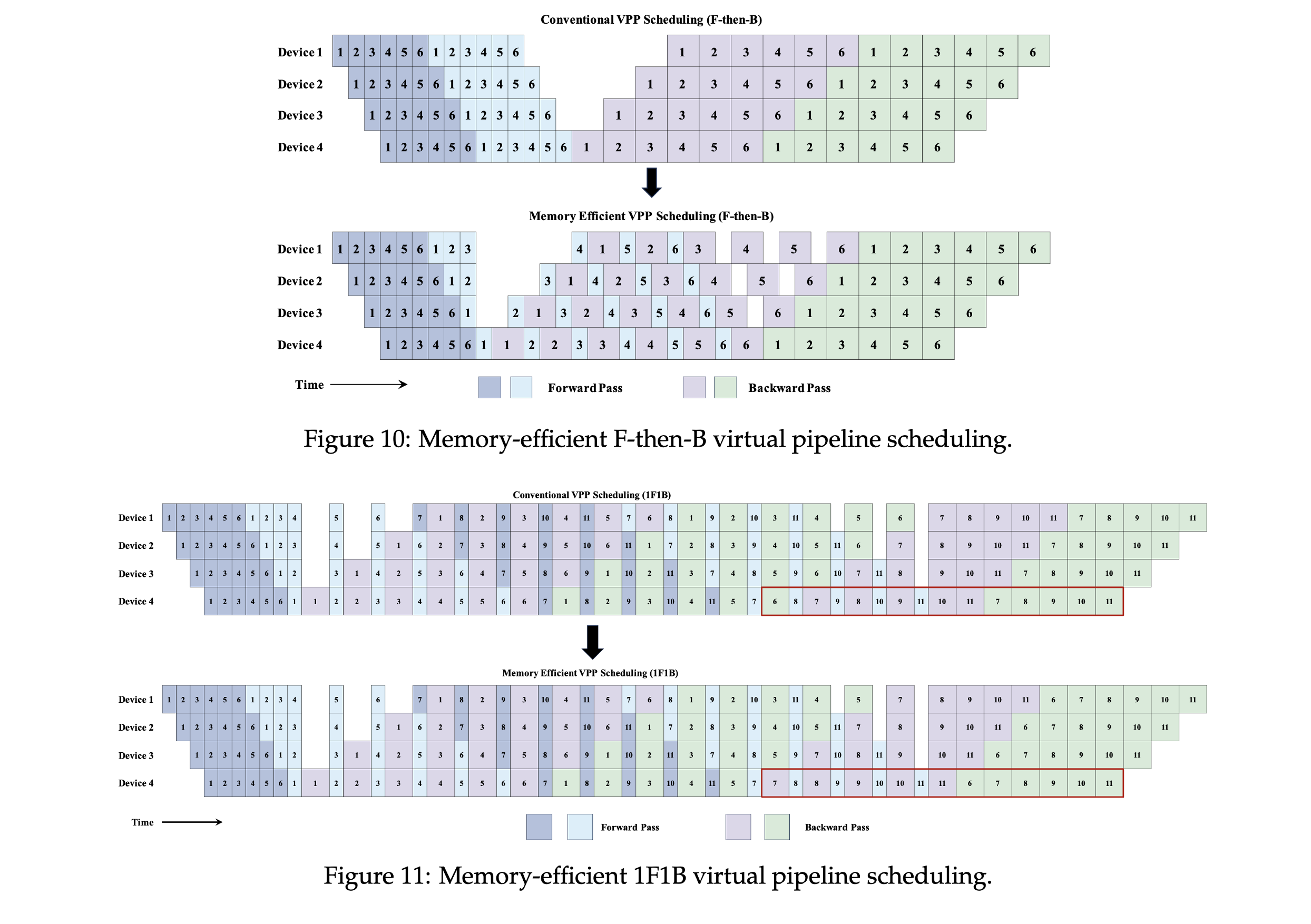
- ①. 虚拟流水线(VPP):最后阶段立即执行反向计算并释放损失函数内存。
- ②. 梯度释放技术:训练步结束时释放参数梯度内存,缓解BF16/FP8训练峰值压力。
3.4 技术突破四:框架级容错与扩展性:
零成本检查点(ZCC):
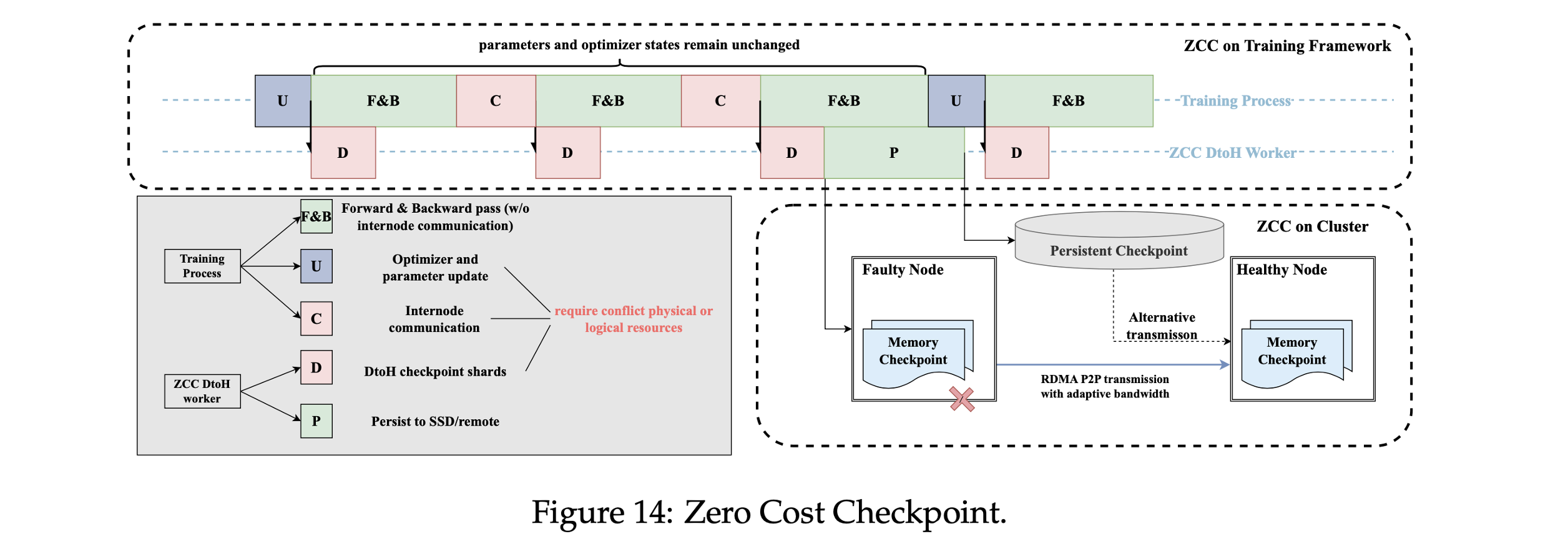
- ①. 训练框架侧:参数/优化器状态仅在更新时变化,异步Checkpoint与计算通信重叠。
- ②. 集群侧:RDMA点对点传输Checkpoint,故障恢复时间<8分钟(万卡集群有效训练时间>98%)。
动态扩展支持
四、推理性能基准测试 - 全面超越主流开源模型:
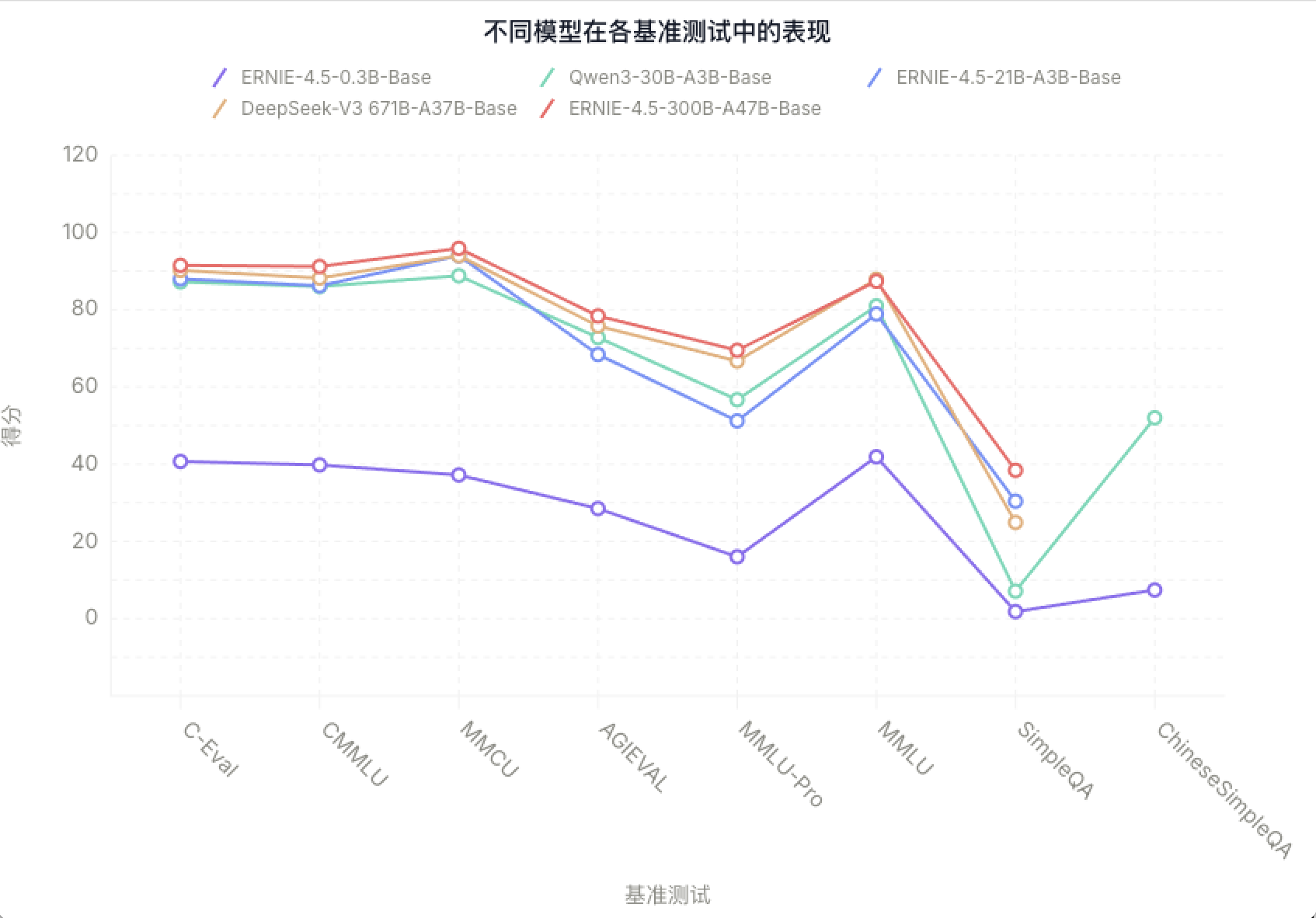
ERNIE-4.5-300B-A47B-Base在28个基准测试中的22个超越了DeepSeek-V3-671B-A37B-Base,在所有主要能力类别中均有领先的表现,相对于其他SOTA模型,在泛化能力、推理和知识密集型任务方面的显著提升。
4.1 pre-trained模型:
将 ERNIE-4.5-Base 与当前 SOTA 模型(如 DeepSeek-V3-Base 和 Qwen3-30B-A3B-Base)进行系统评估,覆盖五大核心能力:
- ①. 通用任务:C-Eval、CMMLU、MMCU、AGIEval、MMLU、MMLU-Redux、MMLU-Pro。
- ②. 事实知识:SimpleQA、ChineseSimpleQA。
- ③. 推理能力:BBH、DROP、ARC、HellaSwag、PIQA、WinoGrande、CLUEWSC。
- ④. 代码生成与理解:EvalPlus、MultiPL-E。
- ⑤. 数学推理:GSM8K、MATH、CM17K。
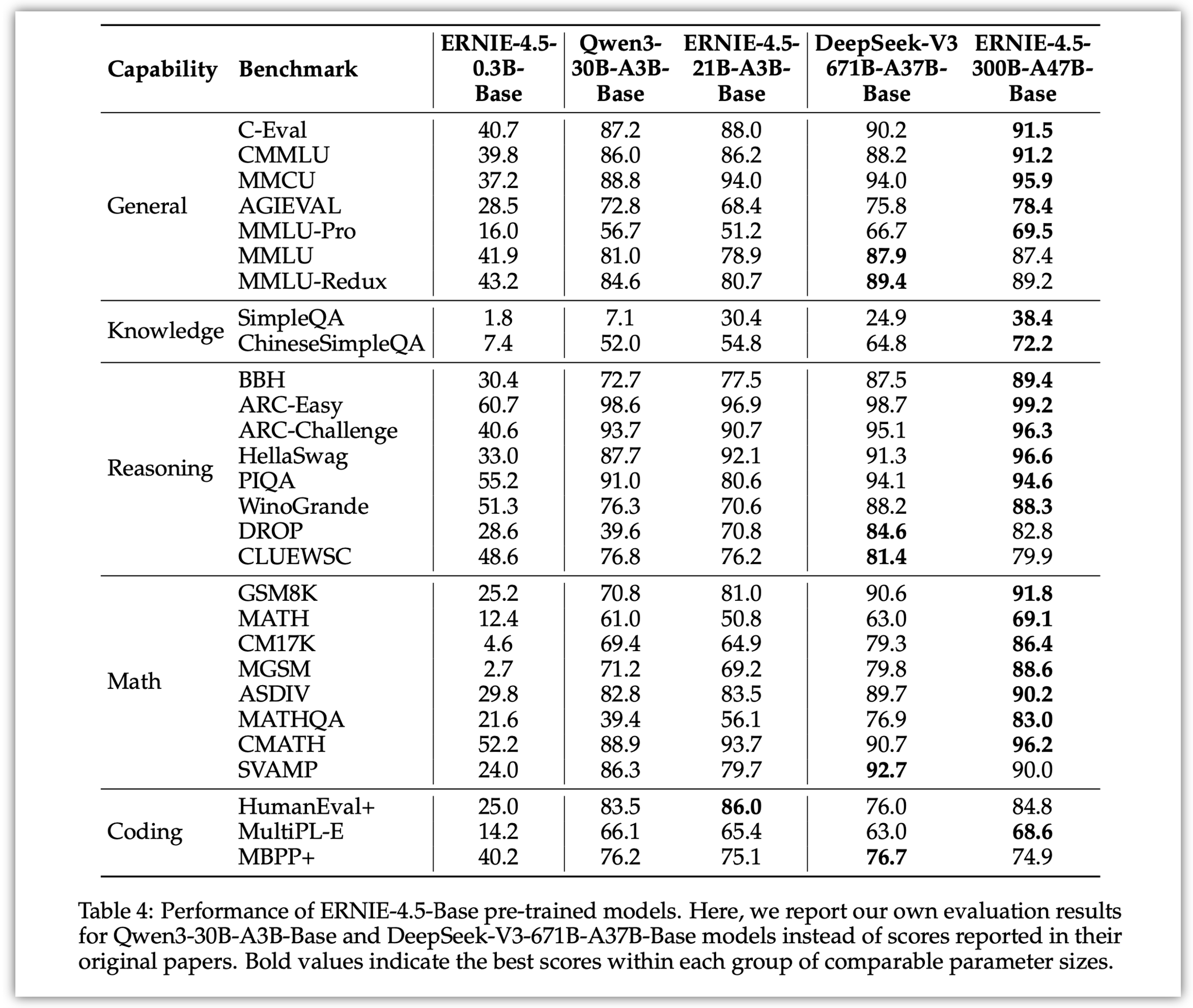
关键结果如下:
ERNIE-4.5-300B-A47B-Base:
- ①. 在 28 个基准中超越 DeepSeek-V3-671B-A37B-Base 的有 22 个。
- ②. 在中文任务(CMMLU、ChineseSimpleQA)表现尤为出色。
- ③. 得益于高质量中文语料与合成数据,在 QA 和复杂语言场景中表现强劲。
ERNIE-4.5-21B-A3B-Base:
- ①. 参数量仅为 Qwen3-30B 的 70%,但在 BBH 和 CMATH 等数学与推理任务上超越对方。
- ②. 体现出较高的参数效率与优异的性能-模型体积权衡。
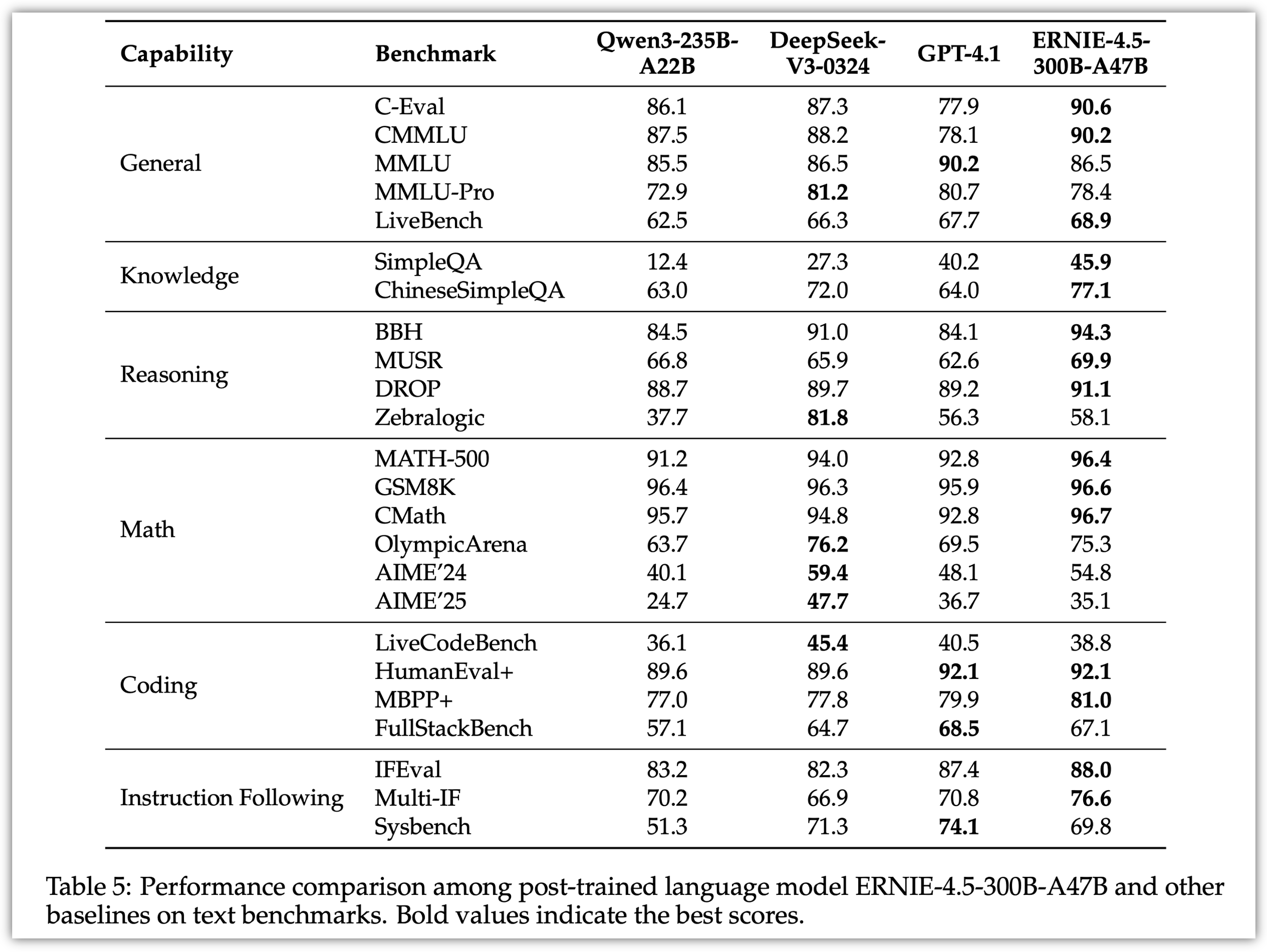
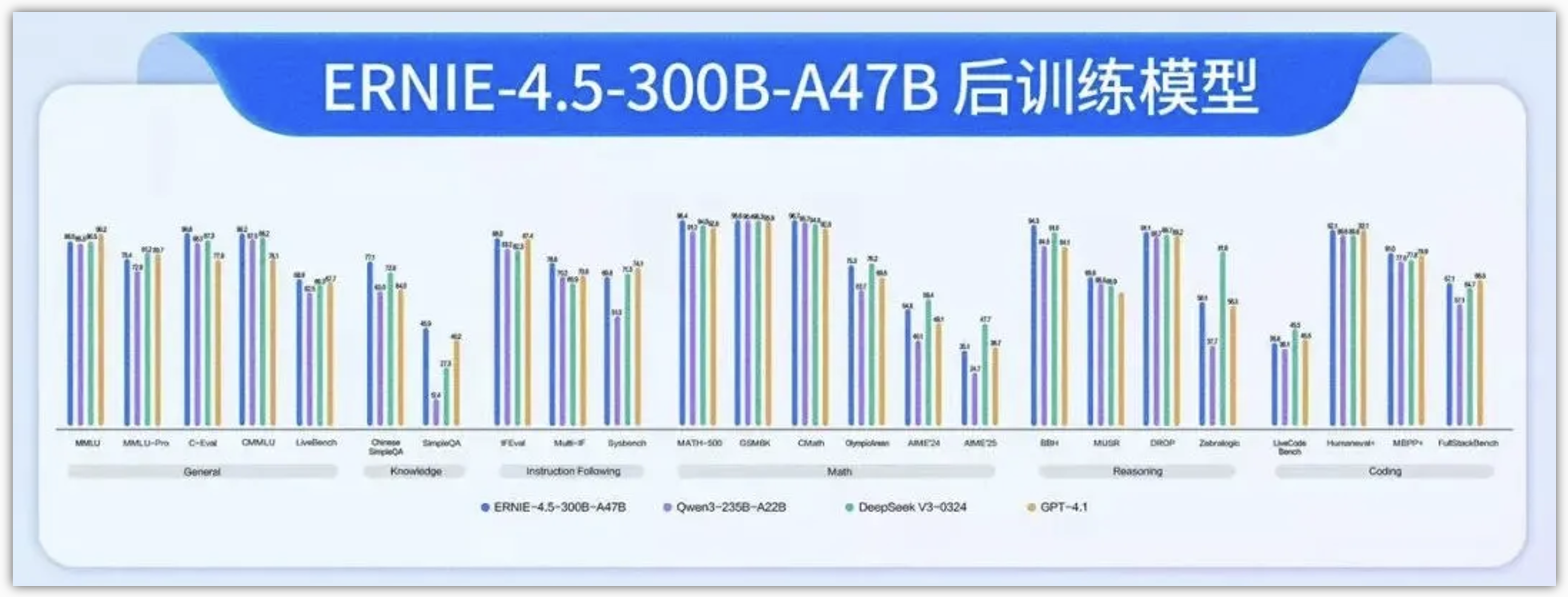
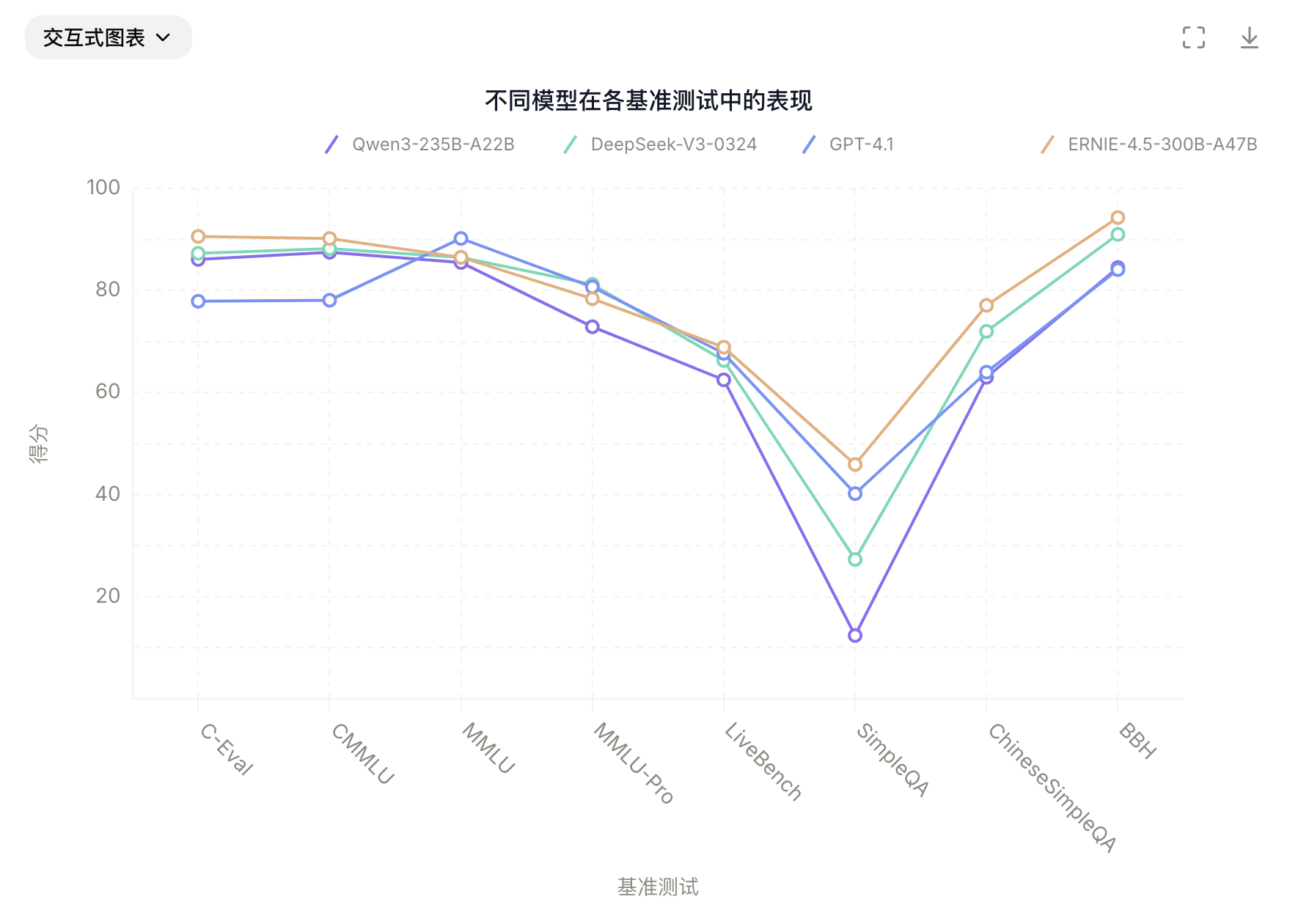
4.2 Post-trained模型:
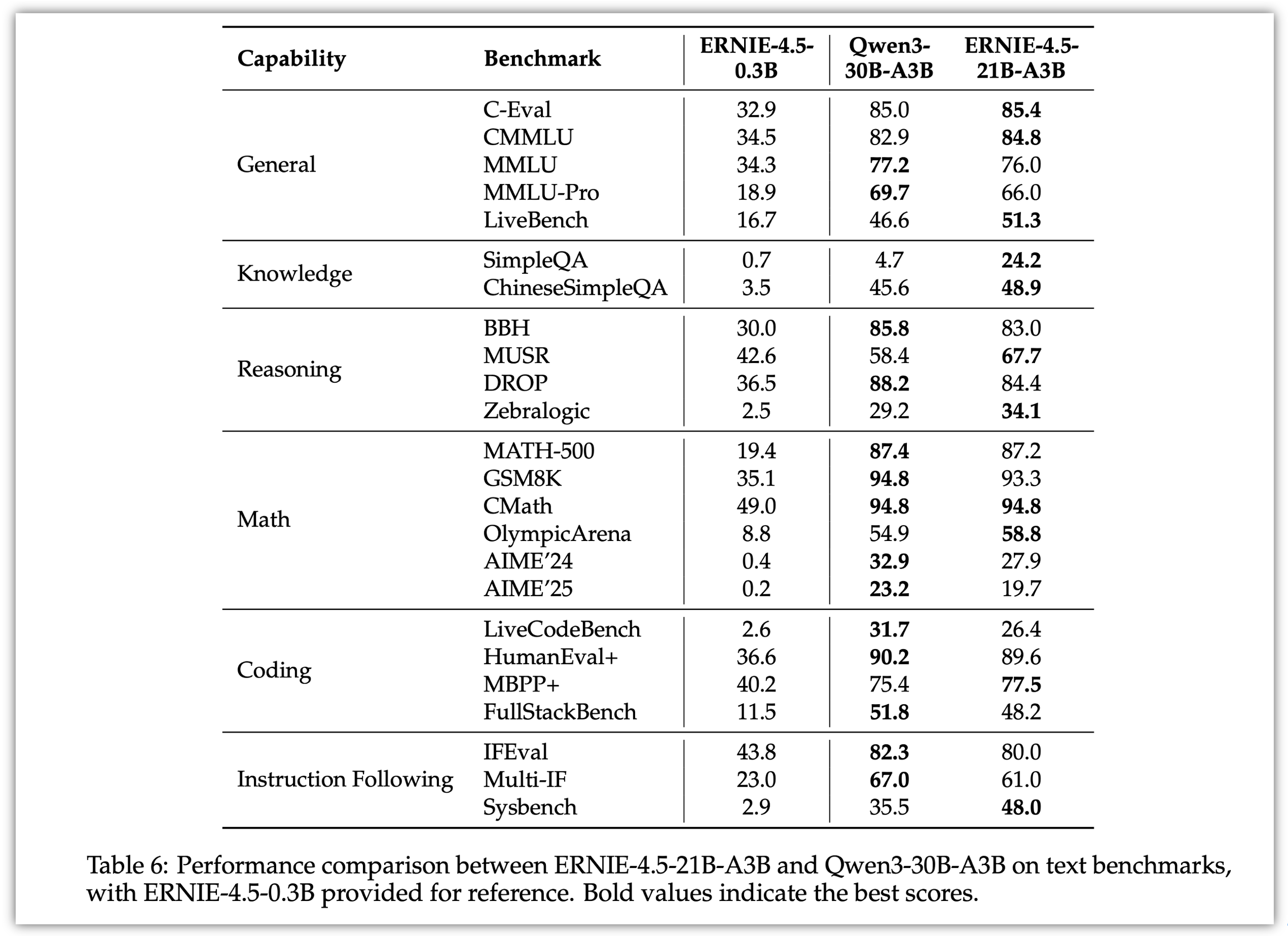
经过后训练的ERNIE-4.5-300B-A47B模型,在指令遵循和知识类任务方面表现出显著优势,其在IFEval、Multi-IF、SimpleQA 和 ChineseSimpleQA等基准测试中取得了业界领先的效果。轻量级模型ERNIE-4.5-21B-A3B尽管总参数量减少了约30%,但与Qwen3-30B-A3B相比,仍取得了具有竞争力的性能。
4.2 文本模型:
文本模型主要对比的是Qwen3-30B-A3B,ERNIE-4.5-21B- A3B-Base 在包括BBH 和CMATH在内的多个数学和推理基准上效果优于 Qwen3-30B-A3B-Base。尽管ERNIE-4.5-21B- A3B-Base 更小,但模型效果突出,实现了效果和效率的平衡。
4.3 多模态模型:
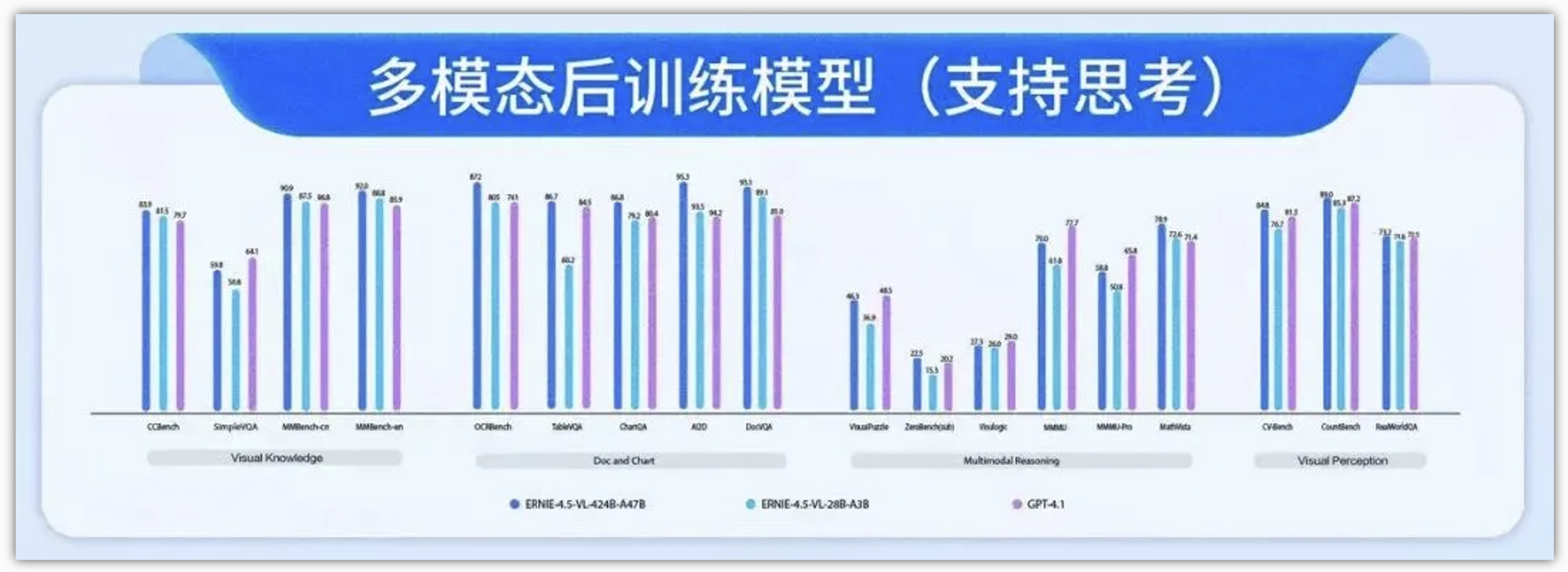
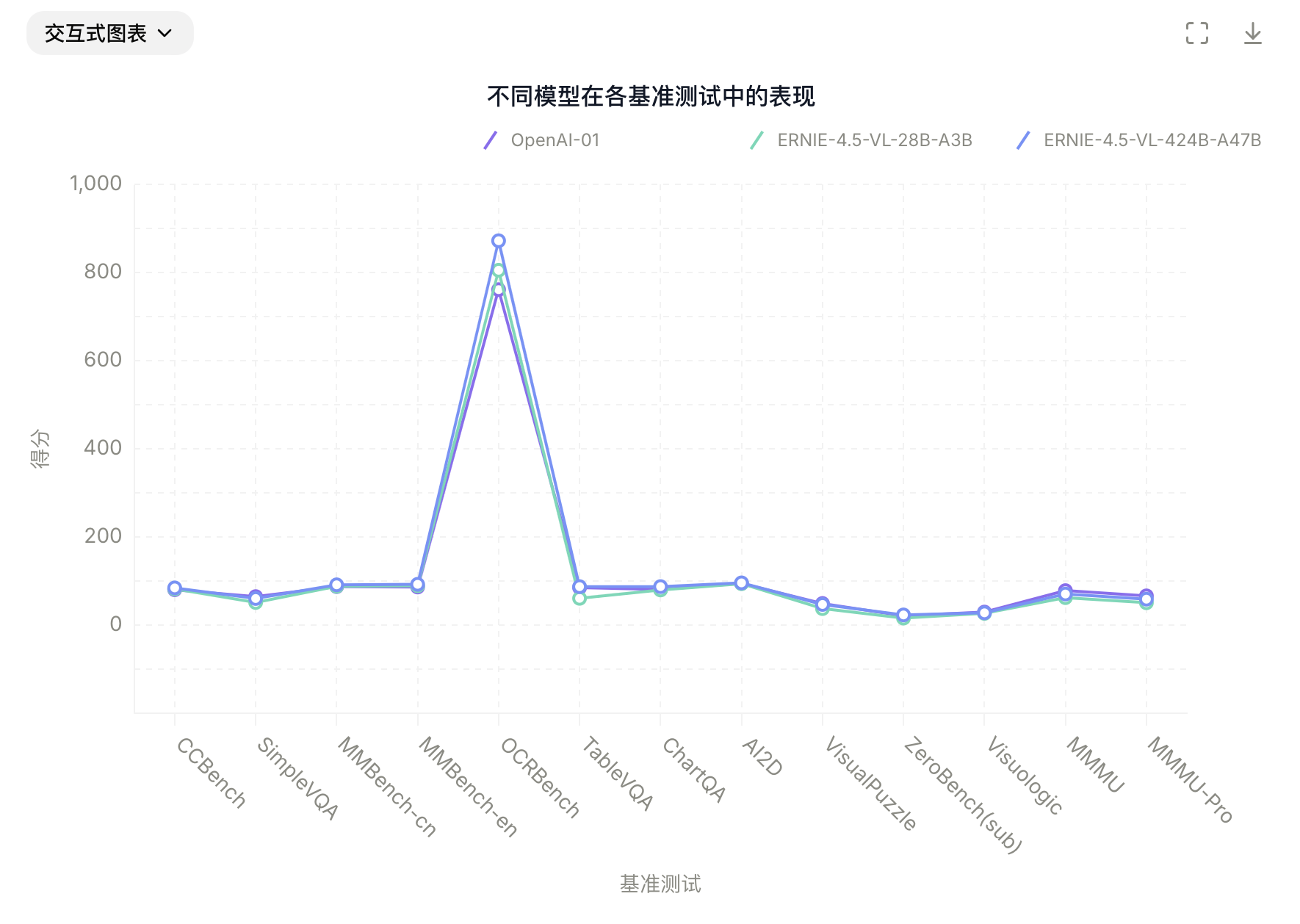
在非思考模式下,ERNIE-4.5-VL在视觉感知、文档与图表理解以及视觉知识方面效果突出,在一系列基准测试中表现优异。
在思考模式下,ERNIE-4.5-VL不仅展现出比非思考模式更强的推理能力,还保留了非思考模式的强大感知能力。分别在non-thinking、thinking下的测试:
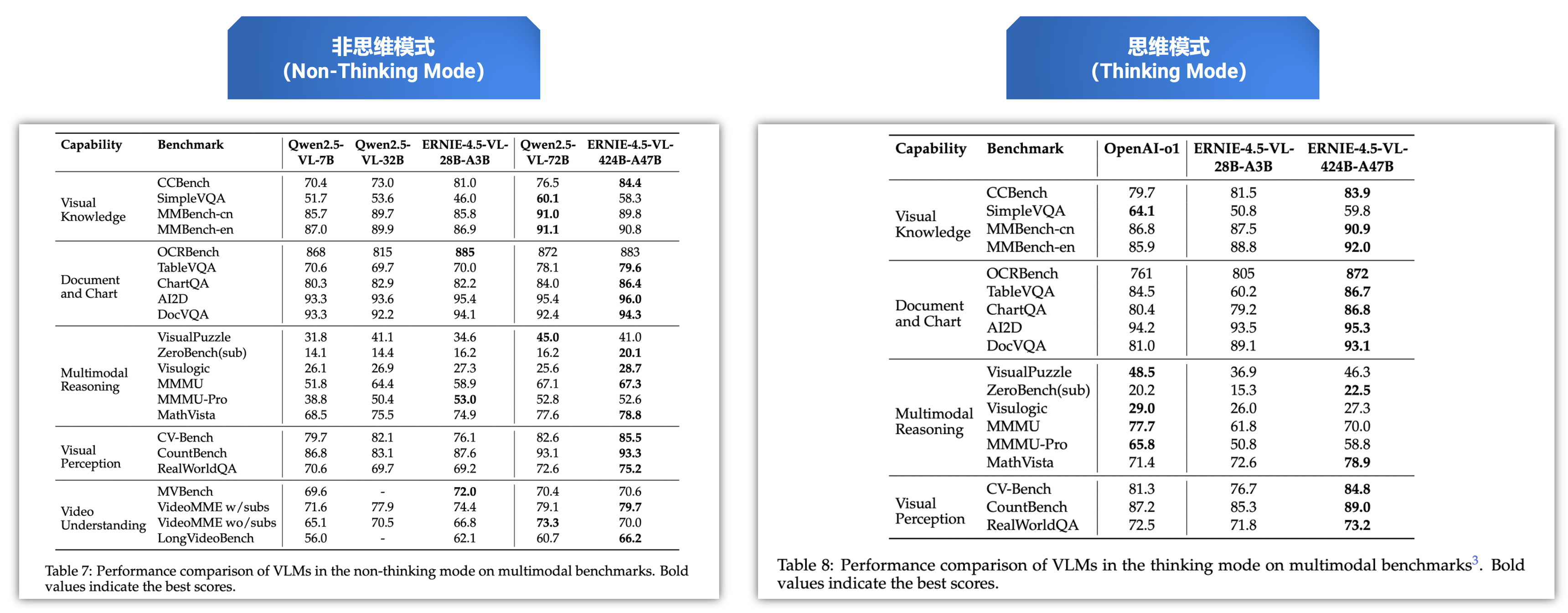
非思维模式(Non-Thinking Mode):
- ①. ERNIE-4.5-VL-424B-A47B 在 CountBench、CVBench、RealWorldQA 等感知任务中表现优异。
- ②. 文档、图表、图像 OCR 理解能力强。
- ③. 视频任务(含长视频)中展现出出色的时间感知与图像语义对齐。
- ④. 在 CCBench 上展现对中文文化/视觉概念的理解优势。
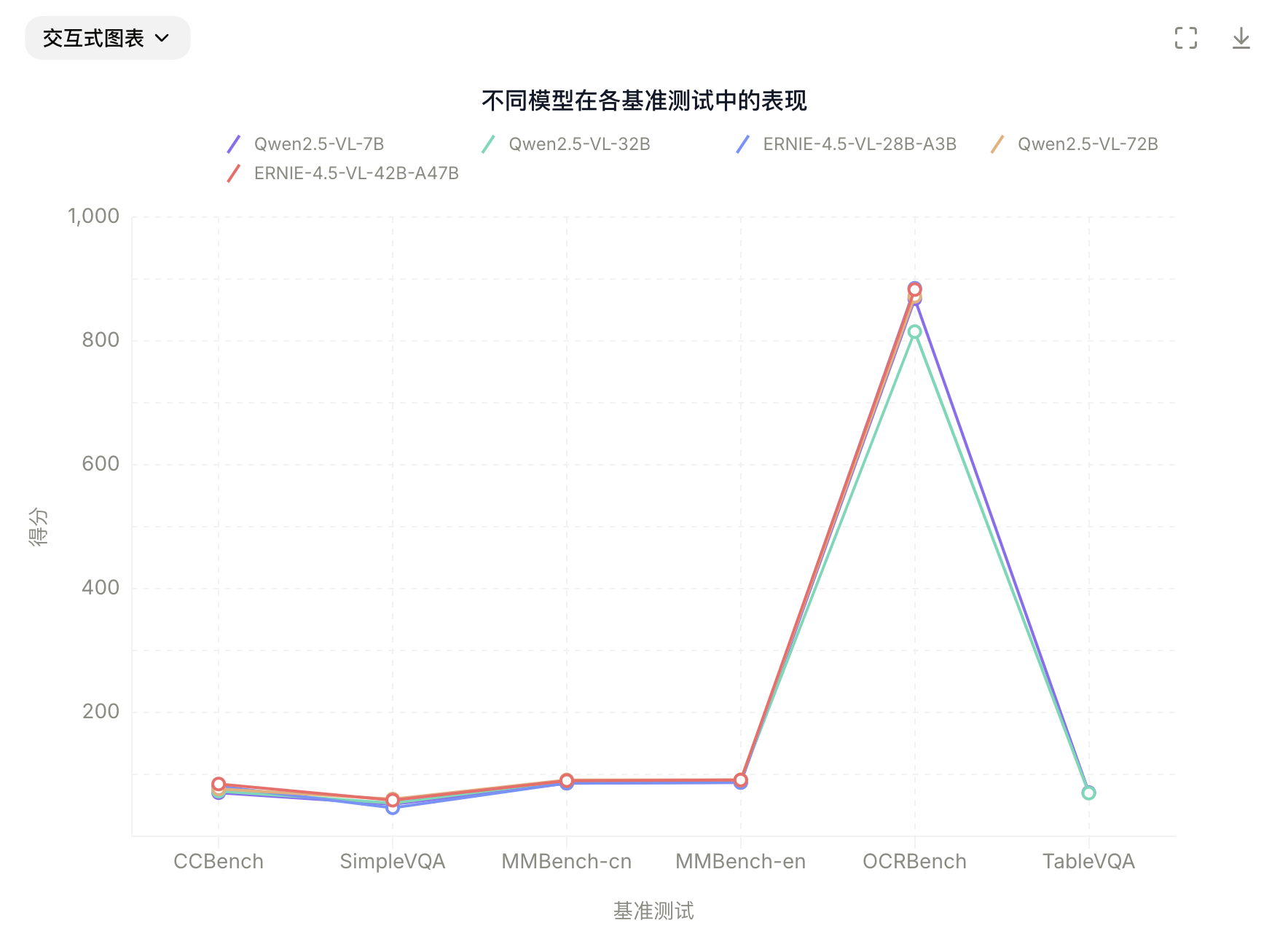
思维模式(Thinking Mode):
- ①. 在 MathVista、MMMU、VisualPuzzle 等多模态推理任务中显著超越非思维模式。
- ②. 推理能力来自于在 STEM 场景中的细致微调。
- ③. 同时保留感知能力。
- ④. 非思维模式也因联合训练得以提升基础能力。
五、百度文心大模型安装与部署环境:
由于AI大模型在环境部署上,有较强的算力硬件要求,百度文心大模型4.5系列多模态的模型,如28B、300B、A47B等多模态大模型,尤其是显卡资源,需要80G以上。但是,大多数本地环境很难支撑运行测试,我们可以选择一些一站式算力平台进行部署与测试,这里我们选择DAMODEL(丹摩智算)是专为 AI 打造的智算云,致力于提供丰富的算力资源与基础设施助力 AI 应用的开发、训练、部署。
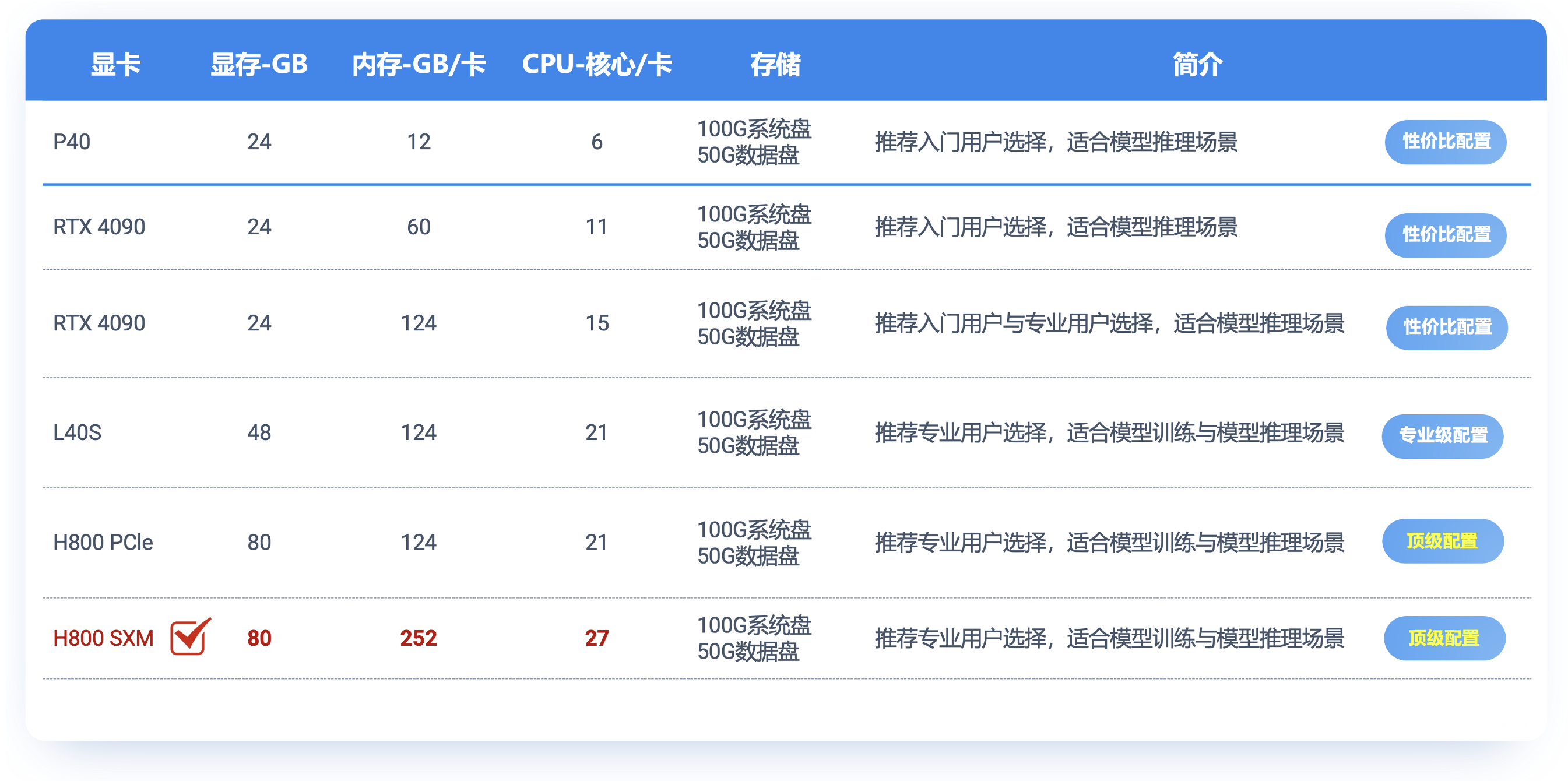
5.1 云算力平台硬件环境说明:
这里为了测试的方便性,统一开通一台A800的80G单显卡算力的云实例(NVIDIA A800-SXM4-80GB GPU),以下是本文测试使用的详细服务器配置:
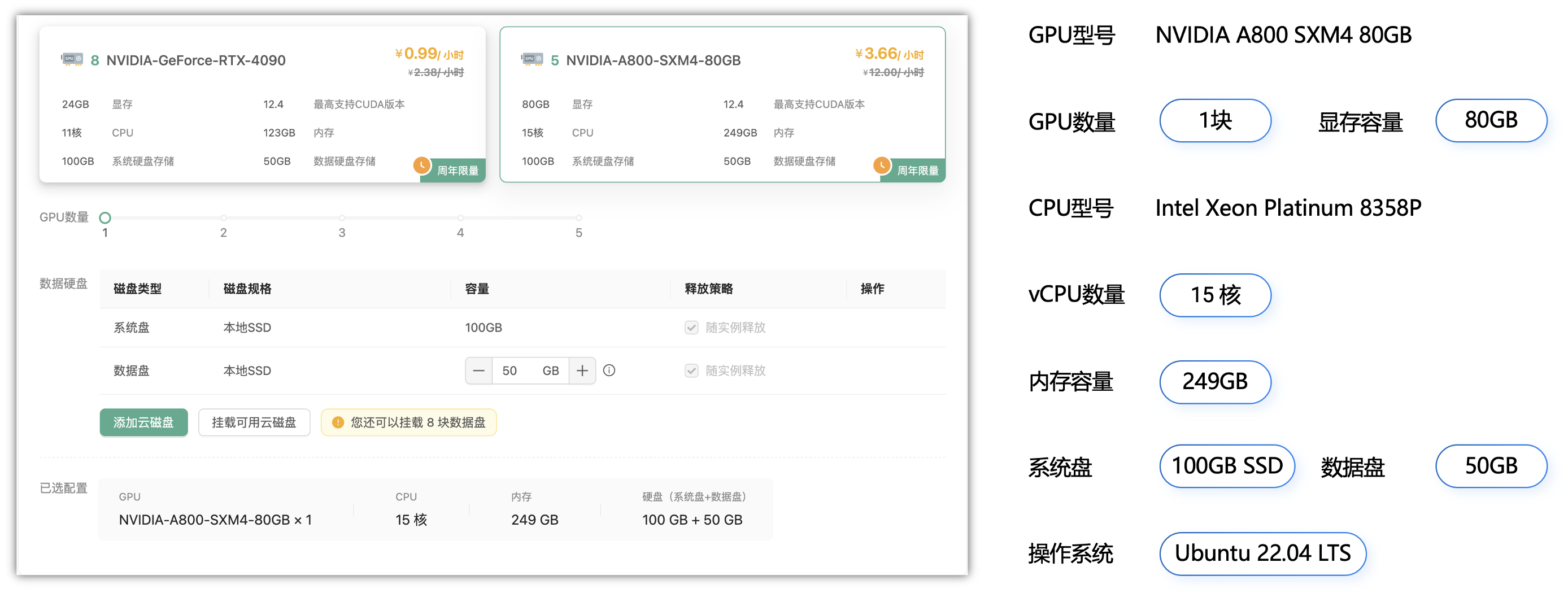
5.2 安装部署过程:
我们在这次环境部署安装中,基于PaddlePaddle 深度学习框架 和FastDeploy 推理引擎,结合 Hugging Face 镜像,完成模型本地化安装与部署。
5.2.1 升级 pip 至最新版:
“丹摩”服务器默认安装有Python环境,建议使用Python 3.9及以上的版本,并先确保pip升级为最新版本:
pip install --upgrade pip
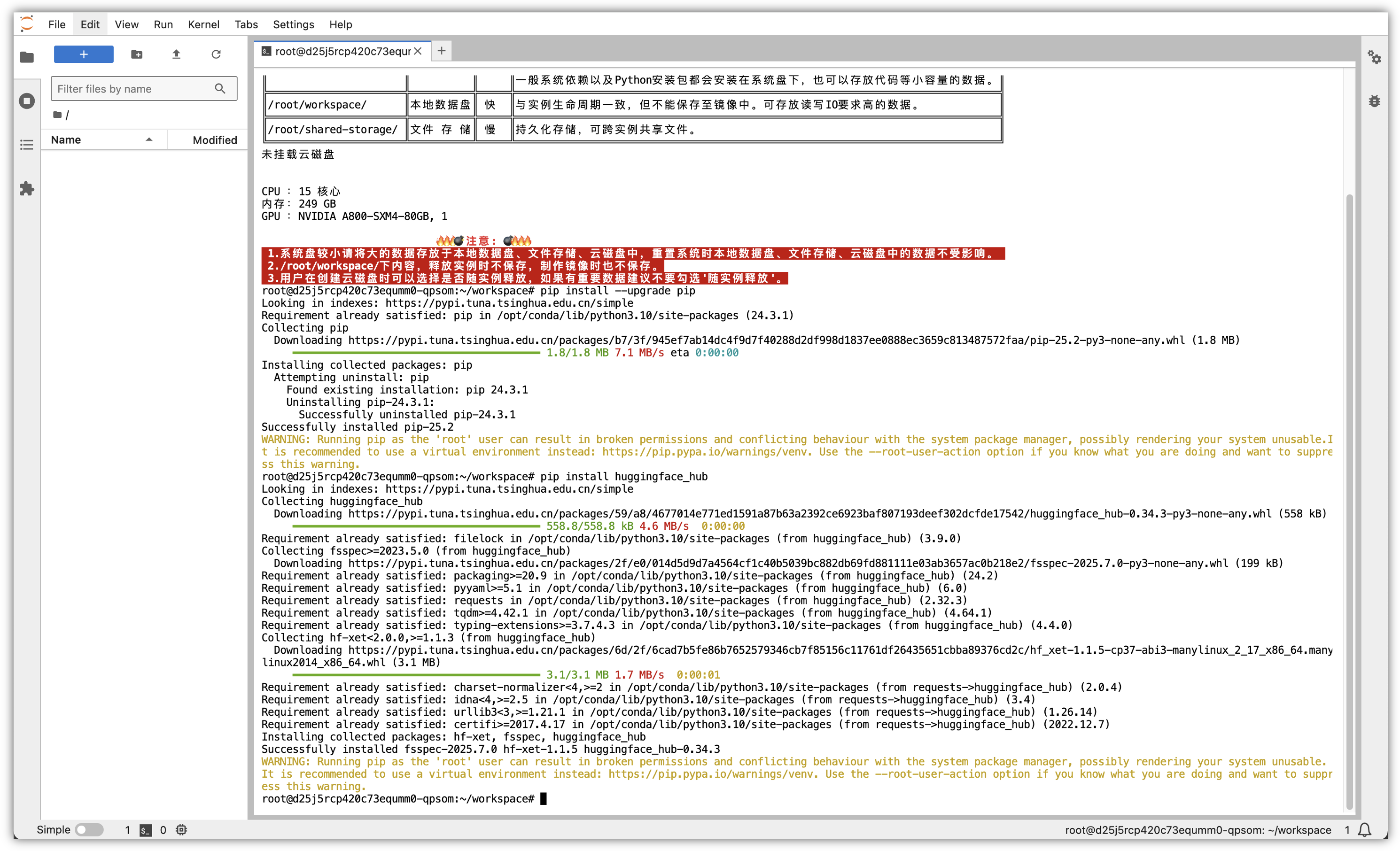
5.2.2 安装 Hugging Face 工具:
HuggingFace 是一个开源社区,提供了统一的 AI 研发框架、工具集、可在线加载的数据集仓库和预训练模型仓库。
因为百度在HuggingFace平台上托管了ERNIE-4.5-21B-A3B-Paddle模型权重,因此需借助 huggingface_hub 工具进行模型下载,首先进行工具的安装,安装完成后,就可以使用huggingface-cli 命令来操作:
pip install huggingface_hub
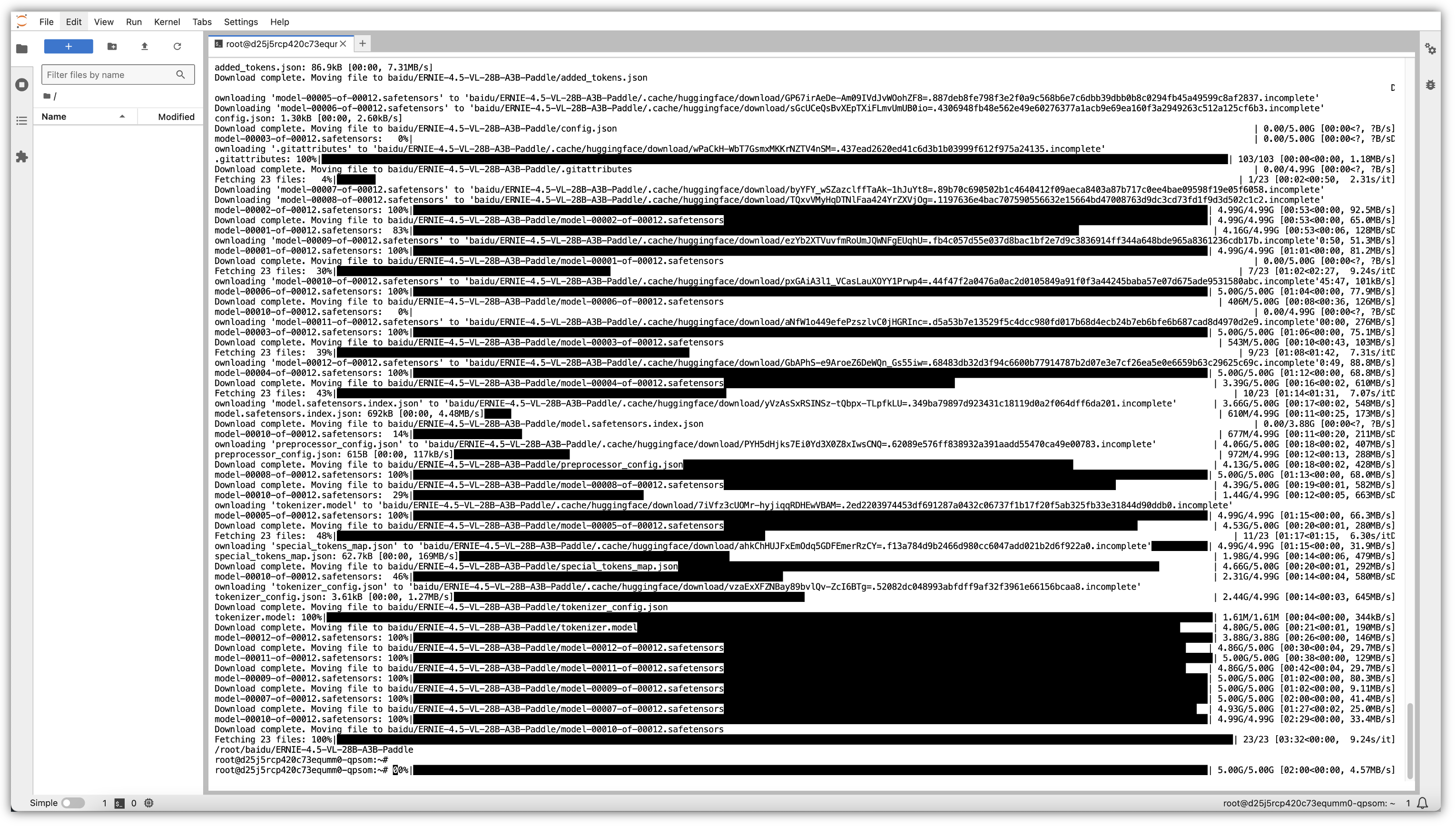
5.2.3 设置 Hugging Face国内镜像加速并下载模型:
# 如果无法访问huggingface.co,可切换至国内镜像加速
export HF_ENDPOINT=https://hf-mirror.com
# 使用huggingface-cli命令下载ERNIE-4.5-28B-A3B模型文件到本地目录
huggingface-cli download baidu/ERNIE-4.5-VL-28B-A3B-Paddle --local-dir baidu/ERNIE-4.5-VL-28B-A3B-Paddle
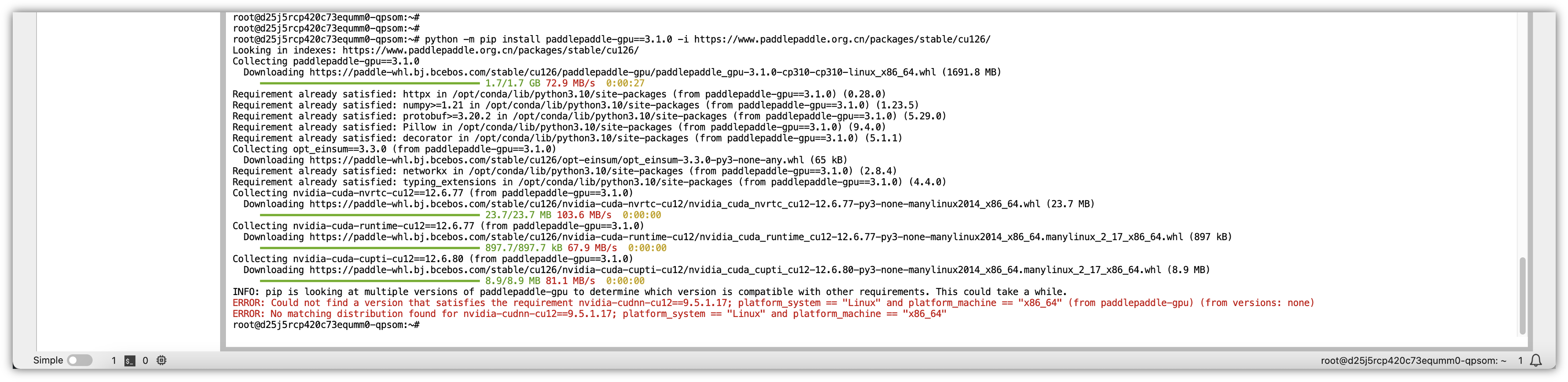
5.2.4 安装 PaddlePaddle GPU 版本:
以 CUDA 12.6 为例,确保安装匹配的 CUDA 驱动与 Paddle(如 cu113、cu118、cu126):
python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
5.2.5 安装 FastDeploy GPU 版本:
针对 SM80/90 架构(如 A30/A100/H100),使用如下命令安装 FastDeploy:
python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
5.2.6 启动ERNIE-4.5本地模型服务:
启动OpenAI兼容API服务,完成模型下载与依赖安装后,即可通过以下命令启动模型服务:
python -m fastdeploy.entrypoints.openai.api_server \
--model baidu/ERNIE-4.5-VL-28B-A3B-Paddle \
--port 8180 \
--metrics-port 8181 \
--engine-worker-queue-port 8182 \
--max-model-len 32768 \
--enable-mm \
--reasoning-parser ernie-45-vl \
--max-num-seqs 32
参数说明:
- ①. --model:本地模型目录(需包含model_index.json)
- ②. --port:主服务端口,提供 /v1/chat/completions 接口
- ③. --metrics-port:Prometheus监控端口(可选)
- ④. --max-model-len:最大上下文长度
- ⑤. --max-num-seqs:最大同时对话序列数(并发控制)
INFO 2025-07-31 21:13:43,785 1122 engine.py[line:253] Worker processes are launched with 97.50605368614197 seconds.
INFO 2025-07-31 21:13:43,786 1122 api_server.py[line:93] Launching metrics service at http://0.0.0.0:8181/metrics
INFO 2025-07-31 21:13:43,786 1122 api_server.py[line:96] Launching chat completion service at http://0.0.0.0:8180/v1/chat/completions
INFO 2025-07-31 21:13:43,786 1122 api_server.py[line:99] Launching completion service at http://0.0.0.0:8180/v1/completions
INFO: Started server process [1122]
INFO: Waiting for application startup.
[2025-07-31 21:14:00,124] [ INFO] - loading configuration file baidu/ERNIE-4.5-VL-28B-A3B-Paddle/preprocessor_config.json
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8180 (Press CTRL+C to quit)
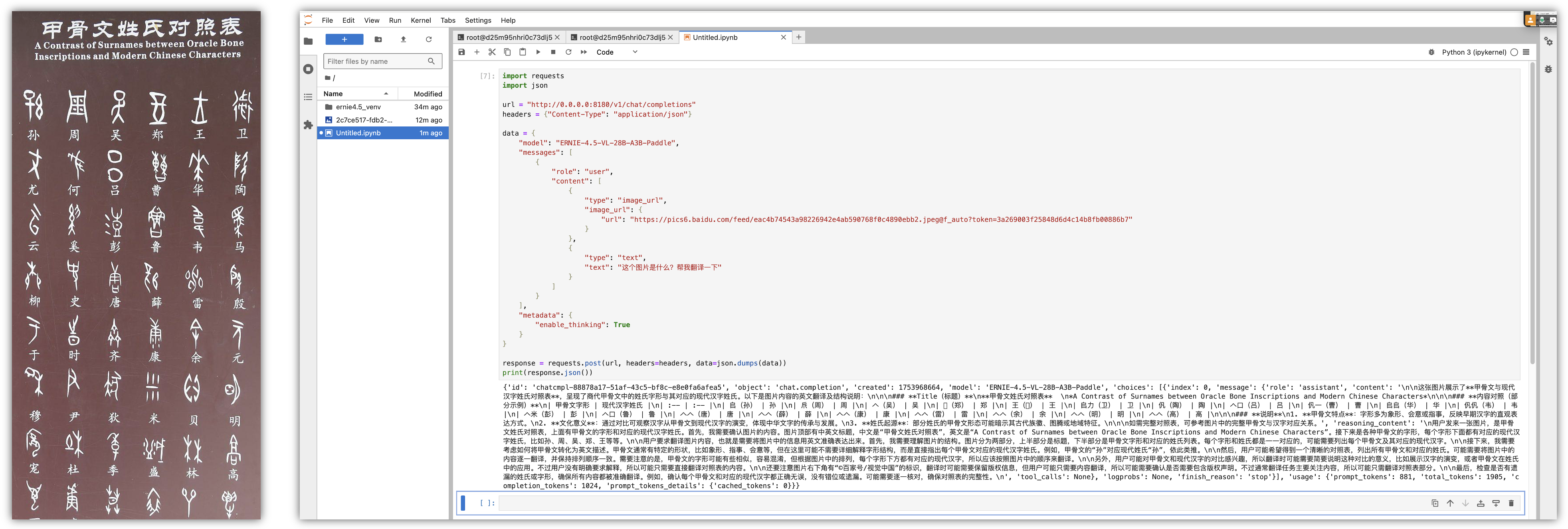
六、模型测试:
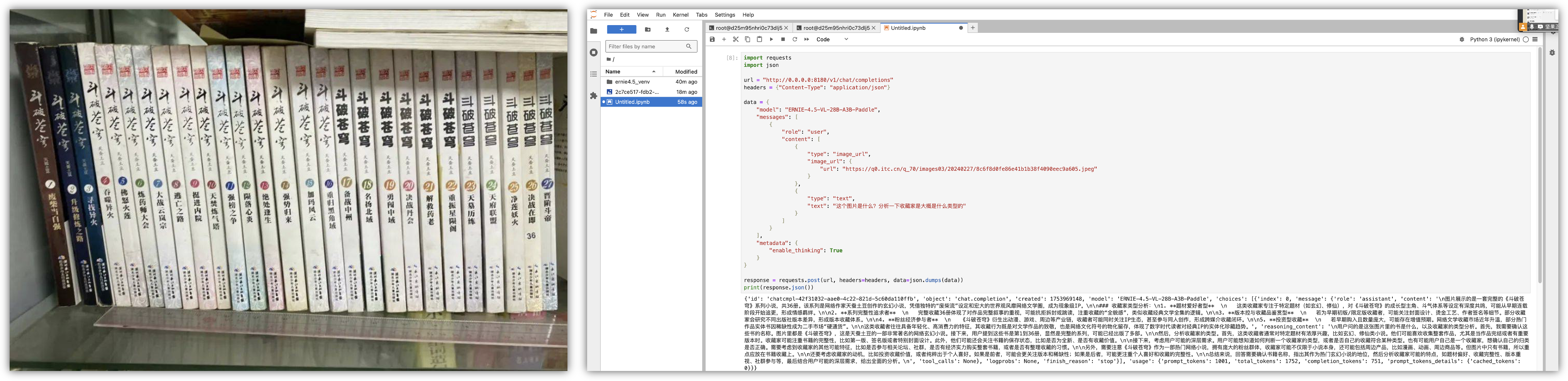
总结:
通过上面对“百度文心一言ERNIE 4.5开源大模型”深入的评测与技术解析,可以清晰地看到该模型在架构设计、推理性能、数据处理策略、二次开发便利性和特色功能等方面的全面优势,推动了整个AI技术行业的开放协作与生态共建。
从ERNIE 4.5产品与生态角度来看,百度ERNIE 4.5开源决策对整个AI生态产生了深远影响,通过开放涵盖47B、3B激活参数的混合专家模型等10款模型,为全球AI创新注入强劲动力。
同时,ERNIE 4.5的高性能与易用性显著降低了中小企业进入AI领域的门槛,加速了AI技术的产业化落地。同时,全面开源有利于更多的开发者与研究者的参与到推广,也兼具了开源社区和产业实际落地所需的高实用性和扩展性。
在企业私有库领域,ERNIE 4.5创新的“思考模式”进一步增强了模型在复杂逻辑推理任务中的表现,为Dify类似的开源的大语言模型(LLM)应用开发平台进行赋能,创造更多、更全、更理想的Agent智能体。
一起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 32
32 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)