Ubuntu+caffe+python(No GPU)配置及CentOS+Caffe+python+GPU配置
他的sudo apt-get install XXX我全都用不了 我的总是提示apt-get找不到命令或者提示没有什么文件或者目录之类的错误 所以他用终端的地方我全自己到网上下载相应的包:
http://www.gnu.org/software/libtool/
http://ftp.gnu.org/gnu/autoconf/
http://ftp.gnu.org/gnu/automake/
https://curl.haxx.se/download.html
http://pkgs.fedoraproject.org/repo/pkgs/gmock/gmock-1.7.0.zip/073b984d8798ea1594f5e44d85b20d66/
总共我下载了六个包 放在protobuf文件夹下 解压缩后 分别进入每个解压缩的文件夹 打开终端 分别运行:
./configure
make
make all
这样六个文件都真正装好了 但我的在protobuf文件夹下打开终端 运行./autogen.sh时总是不行 百度了也不行 总是报错
一、后来我就干脆在虚拟机上先装Ubuntu:
http://blog.csdn.net/jenyzhang/article/details/51491393 很顺利的装好了 但立即重启时老是停留在 Buffer I/O error on dev sr0,logical block 725527,async page read 几行这种提示上 后来我就直接关机 关机了再重新打开这个Ubuntu虚拟机 就好了。
二、装caffe以及python接口:
按照http://www.th7.cn/Program/Python/201610/980832.shtml 来的。但我换了顺序 我是先
sudo apt-get install --no-install-recommends libboost-all-dev 然后再装sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler 接着再装sudo apt-get install libatlas-base-dev 接着再装sudo apt-get install the python-dev 然后装sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev 然后再按照他的第2步:编译和安装Caffe 。。。但我在编译caffe时 输入make all 指令时报错 :提示找不到hdf5.h 我百度后 http://blog.csdn.net/kexinmcu/article/details/52316986 按照这个解决了。这样make all 成功 make test也成功 make runtest也成功。 再开始其第3步:增加python支持这步 开始我看不清 就从这里开始参考:http://www.linuxdiyf.com/linux/24836.html 编译python时: make pycaffe报错:找不到arrayobject.h 解决办法:sudo apt-get install python-numpy 这样就解决了。这样第3步的几条指令均成功。再开始第4步 第4.2步报错说:pip 找不到指令 于是我在终端输入sudo apt-get install python-pip即解决了。 接着执行4.2步 第一个ipython[all]装时失败了 我就先装后面的几个 有的成功 有的失败 失败的是protobuf和skimage 解决办法是:自己手动下载一个 protobuf2.6.1后进入这个文件夹自己安装并改路径 ./configure --prefix=/usr/local/protobuf make make check make install(需要超级用户root权限) 这样protobuf也可以算是解决了。 对于skimage指令安装不成功 我百度了很多不奏效 就自己下载了一个scikit-image-master的包并解压安装即可。最后再sudo pip install "ipython[all]" 但报错说没有这个all 我想是版本问题吧 所以我就没有继续装它了。 在执行4.3步的ipython notebook时报错:please install ipython-notebook 于是我install ipython-notebook但报错说不能locate package python-notebook 于是我又apt-get update 结果还是不行。但后来我不知道怎么搞了一下 忘记了 重新又试了一遍这几条指令 又可以了。ipython-notebook的结果和教程中有点不一样 可能是版本关系 直接点击图片中的dream.ipynb即可。

后来按照http://blog.csdn.net/fubin0000/article/details/51835153 测试一下例子:
注意要在根努力下 运行到最后一步时报错说没有GPU 原来这个网址是说的GPU下的 我就把lenet_solver.prototxt里的solver_mode:GPU改成了CPU 就行了!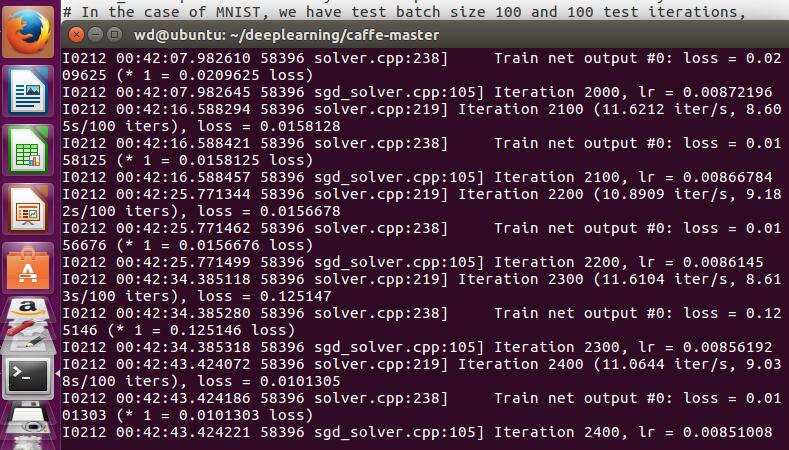
/************************************************************************************************************************************************************/
昨天从家里回来 晚上看了一本很好看的小说 九鹭非香的《招摇》很好看 结果就看到了凌晨多 今天睡到11点 吃了中饭来加个班 因为星期五的事情还没弄完 现在弄完了 一边等它训练 一边回忆下 我的2016好了。
2016年对我来说是很重要的一年。
2016年我出来工作了整整一年,完成了从一个学生到朝九晚五的上班族的转变。从开始不想工作每天只盼望下班后立马回到学校到后来的自主加班学习到很晚,从镜子里无忧无虑的面庞到后来慢慢成熟坚定的眉眼,我知道自己成长了很多。当然,其中有很多人帮助了我,我从他们身上学到很多,无论是公司的同事还是同一行业的网友。越来越发现学无止境,时间越长发现自己需要学习的东西越多,自己的能力还需要很大程序的提高。
2016年最伤心的事就是外婆的去世,我本以为16年年底回去可以给她压岁钱了,用我自己挣的钱。。。但她最终还是没等到。
2016年让我感觉被肯定的事就是得了奖学金。当然这可能是因为我这一届的这个专业的都是女孩子,而她们大多是以后当老师的,所以整体来说奖学金就比较容易拿。尽管如此,这也是靠我自己拿到的,我还是感觉到有种收获的喜悦。
2016年开心的事就是可以花自己赚的钱。无论是给爸妈买东西、给自己买护肤品、给妹妹打钱或者给宿舍里的妹子或者朋友发红包,我都觉得无比开心。
2016年朋友们的大事:一个闺蜜生了小孩,一个闺蜜结婚了和她相恋几年的男友,当他牵着她走上红毯,我感动到流泪。
2016年最无奈的事:爸妈总是耳提面命:谁谁谁交了男朋友,谁谁谁订婚了,谁谁谁都生孩子了。。。
2016年完成的多年的小梦想:用工资在夏天纹了一朵梅花
/***********************************************************************************************************************************************/
2017年对自己的期望:
在公司,工作上更努力,同时提升自己的能力。
在学校,这学期就要毕业了,最后享受下住学校的感觉,感受下师大的美女如云。毕业时有毕业旅行,我有个计划,这几个月要好好攒钱,买个相机然后带爸妈来长沙玩玩,再带他们去海边玩玩,再带他们去看看妹妹。另外我以前准备毕业论文好好写的,要写得是我们专业最好的,但现在不想了,因为重心在工作上了,所以可能就是写个普通水平的毕业论文吧。
17年期待的电视剧wuli颖宝的《特工皇妃楚乔传》,因为这是我看过的小说啊 超好看 现在拍成电视女主又是我喜欢的 她把小说花千骨也拍得很好 所以很期待这部剧啊!
咦运行完了: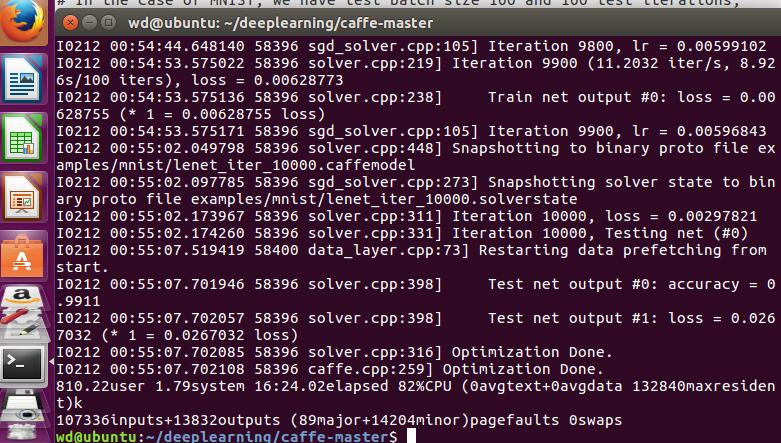
学习训练测试自己的图片集:
基本上按照:http://www.cnblogs.com/denny402/p/5083300.html
一、创建文件夹放自己的训练测试图片集 我这里训练集的第0到第10955属于猫 10956---22145属于狗 测试集0---97属于猫 98--191属于狗
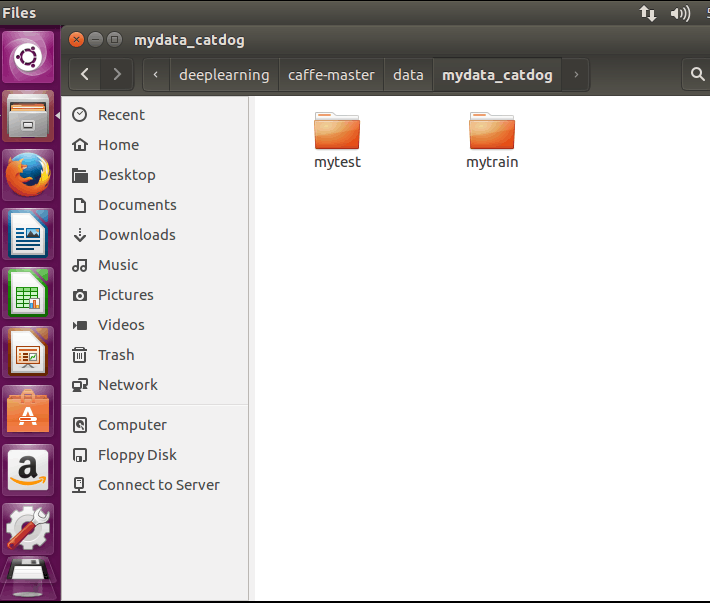
二、创建脚本.py运行得到训练集与测试集的标签:
#for create the train and test.txt according to the images for train or test.
#why can not it do work just one time?
import os,glob
import re
numbers=re.compile(r'(\d+)')
def numericalSort(value):
parts=numbers.split(value)
parts[1:2]=map(int,parts[1::2])
return parts
print('make the test.txt...')
test_txt=open('test.txt','w')
imgs_path2='/home/wd/deeplearning/caffe-master/data/mydata_catdog/mytest'
imgsextension2=['jpg']
os.chdir(imgs_path2)
imglist2=[]
for extension in imgsextension2:
extension='*.'+extension
imglist2+=[os.path.realpath(e) for e in glob.glob(extension)]
#imglist+=glob.glob(extension)
i=0;
for infile in sorted(imglist2,key=numericalSort):
if(i<=97):
str3=infile+' '+'0'+'\n'
test_txt.writelines(str3)
else:
str4=infile+' '+'1'+'\n'
test_txt.writelines(str4)
i+=1
test_txt.close()
print('make the train.txt...')
train_txt=open('train.txt','w')
imgs_path='/home/wd/deeplearning/caffe-master/data/mydata_catdog/mytrain'
imgsextension=['jpg']
os.chdir(imgs_path)
imglist=[]
for extension in imgsextension:
extension='*.'+extension
imglist+=[os.path.realpath(e) for e in glob.glob(extension)]
#imglist+=glob.glob(extension)
i=0;
for infile in sorted(imglist,key=numericalSort):
if(i<=10955):
str1=infile+' '+'0'+'\n'
train_txt.writelines(str1)
else:
str2=infile+' '+'1'+'\n'
train_txt.writelines(str2)
i+=1
train_txt.close()
print("成功生成文件列表") 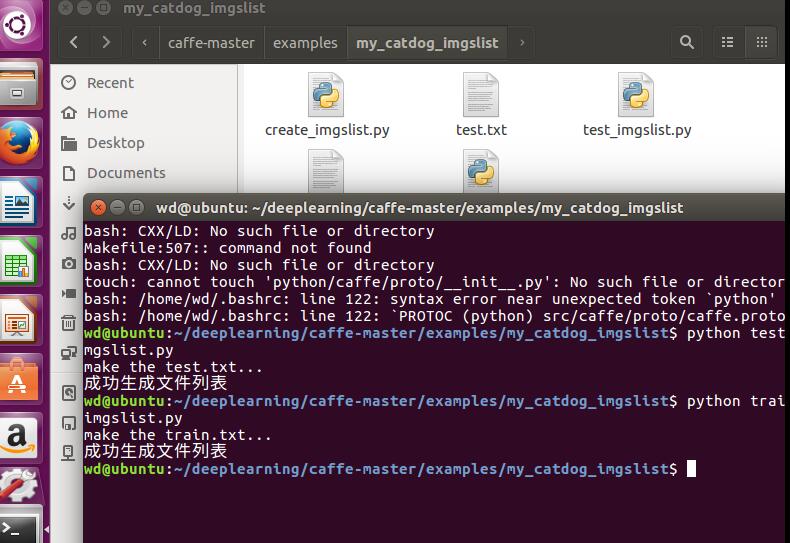 这样即可生成两个txt:
这样即可生成两个txt: 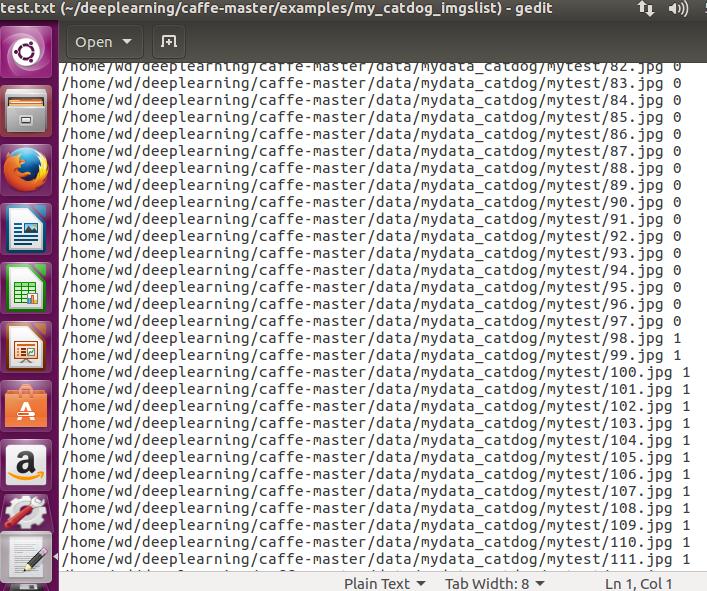
三、将图片转成lmdb格式:
在刚刚生成txt的目录下 创建一个create_lmdb.sh的脚本:
#!/usr/bin/env sh
# Create the imagenet lmdb inputs
# N.B. set the path to the imagenet train + val data dirs
set -e
EXAMPLE=examples/my_catdog_imgslist #the create_lmdb.sh file's location
DATA=examples/my_catdog_imgslist #the txt file's location
TOOLS=build/tools
TRAIN_DATA_ROOT=/home/wd/deeplearning/caffe-master/data/mydata_catdog/mytrain/
VAL_DATA_ROOT=/home/wd/deeplearning/caffe-master/data/mydata_catdog/mytest/
# Set RESIZE=true to resize the images to 256x256. Leave as false if images have
# already been resized using another tool.#我的图片本来都是300X300的 所以我没再缩放大小
RESIZE=false
if $RESIZE; then
RESIZE_HEIGHT=256
RESIZE_WIDTH=256
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit 1
fi
if [ ! -d "$VAL_DATA_ROOT" ]; then
echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit 1
fi
echo "Creating train lmdb..."
rm -rf $EXAMPLE/catdog_train_lmdb
rm -rf $EXAMPLE/catdog_test_lmdb
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
$EXAMPLE/catdog_train_lmdb
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$DATA/test.txt \
$EXAMPLE/catdog_test_lmdb
echo "Done."sh examples/my_catdog_imgslist/create_lmdb.sh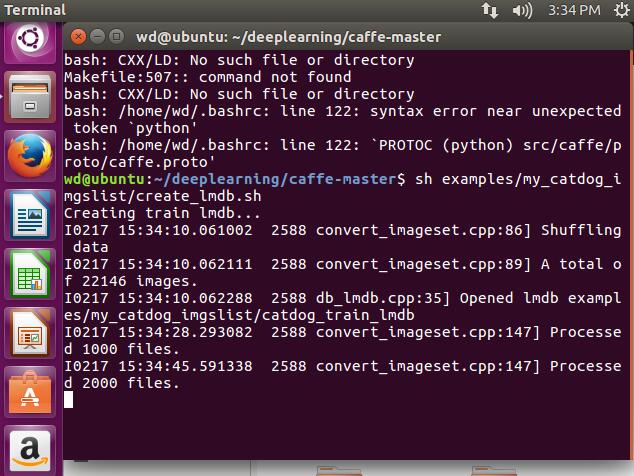
四、计算训练集的均值:
五、创建模型并编写配置文件:

参数设置意义:http://www.cnblogs.com/Allen-rg/p/5795867.html
对于训练样本(T个):train.prototxt中的batch_size若为train_b 那么solver.prototxt中的test_interval>=(T/train_b) 如果想迭代n次 那么最大迭代次数要设置为n*test_interval
对于测试样本:如果有1000个测试样本,batch_size为25,那么需要40次才能完整的测试一次。 所以test_iter为40;这个数要大于等于40.
学习率变化规律我们设置为随着迭代次数的增加,慢慢变低。总共迭代47500次,我们将变化5次,所以stepsize设置为47500/5=9500,即每迭代9500次,我们就降低一次学习率。
####参数含义#############
net: "examples/AAA/train_val.prototxt" #训练或者测试配置文件
test_iter: 40 #完成一次测试需要的迭代次数
test_interval: 475 #测试间隔
base_lr: 0.01 #基础学习率
lr_policy: "step" #学习率变化规律
gamma: 0.1 #学习率变化指数
stepsize: 9500 #学习率变化频率
display: 20 #屏幕显示间隔
max_iter: 47500 #最大迭代次数
momentum: 0.9 #动量
weight_decay: 0.0005 #权重衰减
snapshot: 5000 #保存模型间隔
snapshot_prefix: "models/A1/caffenet_train" #保存模型的前缀
solver_mode: GPU #是否使用GPU
然后经过conv卷积层和pool池化层后的图片大小计算公式:[(上一层的长度+2*pad长度-kernel长度)/步长stride]+1 这个pad的意思是在图片周围加上几圈像素 如果不设置默认为0 stride步长的意思是每次窗口移动的距离 不设置默认为窗口大小的长度
六、训练测试:
sudo build/tools/caffe train -solver examples/myfile/solver.prototxt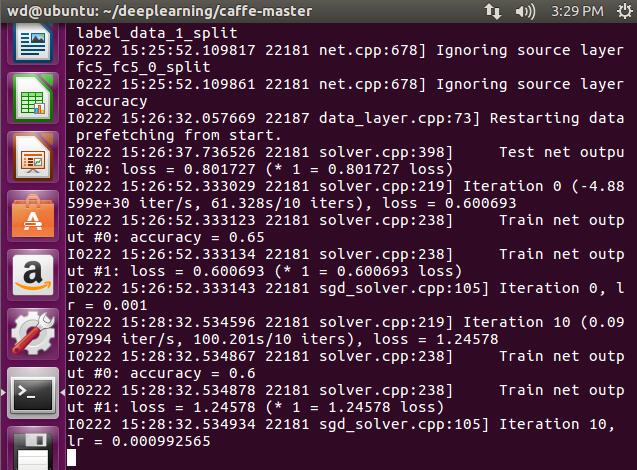
太慢了就是!
/**********训练时生成log日志************************/
如果要生成Log日志 就不能像第六步那样训练 为了区分 我在我的文件夹下my_catdog_imgslist下创建了一个make_plot_train.sh的脚本:
build/tools/caffe train -solver=examples/my_catdog_imgslist/solver.prototxt >examples/my_catdog_imgslist/catdog_log.txt 2>&1sh examples/my_catdog_imgslist/make_plot_train.sh
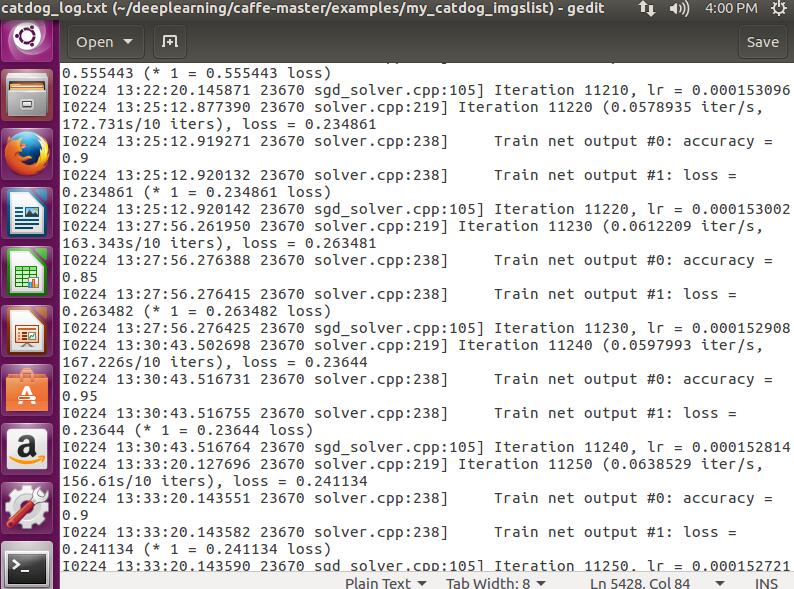
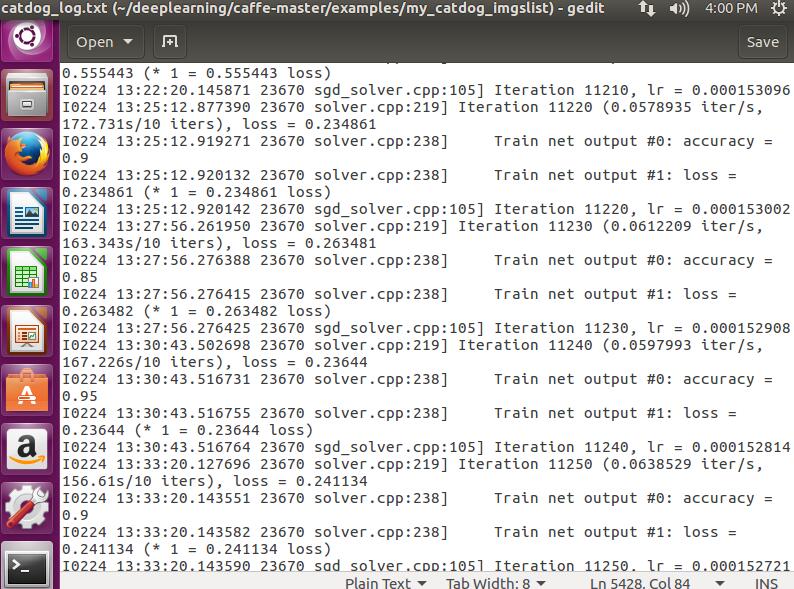
百分之九十的样子了!然后也生成了.caffemodel文件!
解除某个文件或文件夹的root权限 在此文件或文件夹的目录打开终端 输入 sudo chown -R 用户名 文件或者文件夹名 这样就行了
/*************************************去一台linux的新电脑上重新装GPU版本的caffe*****************************************/
命令:lspci |grep VGA 结果显示是NVIDIA显卡:GeForce GTX 750 Ti 然后再https://developer.nvidia.com/cuda-gpus 查到我要下5.0的显卡驱动才行 所以去http://www.nvidia.cn/Download/index.aspx?lang=cn 去下载linux版本的显卡驱动 
第三步:如上第二步进入系统后按Ctrl+Alt+BackSpace进入字符界面用root登陆,如果还是图形界面,就进入图形界面后在shell下输入命令init 3进入字符界面。
第四步:在字符界面进入显卡驱动的目录后用sh ./NVIDIA-Linux-x86-173.08-pkg1.run开始安装弹出第一个画面选择Accept允许安装
但出现错误: ERROR: The Nouveau kernel driver is currently in use by your system. This driver is incompatible with the NVIDIA driver, and must bedisabled before proceeding. Please consult the NVIDIA driver README and your Linux distribution's documentation for details on how to correctly disable the Nouveau kernel driver. 于是reboot重启。禁用Nouveau:最好先在init 3下进入shell界面输入: lsmod |grep nouveau 如果有出来东西 证明这个ERROR报错的部分的确如它说的一样与我装英伟达驱动冲突了 init 5换回图形界面 开始解决问题:1、首先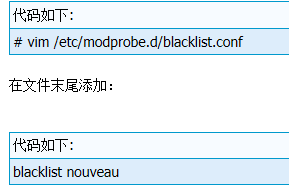
/*****************************安装好了英伟达驱动 就可以装VMware了 然后待会儿在VMware上装Ubuntu+CAFFE**************/
/************************下载一个VMware 因为要在linux上装Ubuntu系统********************************/
https://my.vmware.com/cn/group/vmware/details?downloadGroup=WKST-1252-LX&productId=524&rPId=13365#product_downloads 下载VMware
然后去目录中打开终端 : chmod +x VMware-Workstation-7.0.0-203739.i386.bundle
然后./VMware-Workstation-7.0.0-203739.i386.bundle 就可以安装了 按照http://www.jb51.net/LINUXjishu/95627.html 最多去查下密钥而已。
/*******************还是不行 原来虚拟机上不支持CUDA 即使我本机上有NVIDIA显卡和驱动 即使虚拟机也下了VM tools也下了驱动也不行*****/
/***************后来直接在CentOS上直接装caffe+GPU**************/
1、装显卡驱动:
按照:http://blog.csdn.net/chieryu/article/details/50218597 中间报过一个错误:Unable to find the kernel source tree for the currently running kernel. Please make sure you have installed the kernel source files for your kernel and that they are properly configured; on Red Hat Linux systems, for example, be sure you have the 'kernel-source' or 'kernel-devel' RPM installed. If you know the correct kernel source files are installed, you may specify the kernel source path with the '--kernel-source-path' command line option
解决办法:
yum -y kernel-devel kernel-headersThe NVIDIA CUDA Toolkit provides command-line and graphical
tools for building, debugging and optimizing the performance
of applications accelerated by NVIDIA GPUs, runtime and math
libraries, and documentation including programming guides,
user manuals, and API references. The NVIDIA CUDA Toolkit
License Agreement is available in Chapter 1. 始终停留在这里:解决办法:按Ctrl+C即可。 参考:http://www.linuxidc.com/Linux/2016-11/137561.htm 还有检查CUDA Toollkit是否成功安装:sudo /usr/local/cuda-8.0/bin/nvcc 出现提示信息 就证明按照成功了。
2、安装caffe
按照:http://blog.csdn.net/chieryu/article/details/50218763 的后部分,但make all时出问题:caffe/common.hpp:fatal error:boost/shared_ptr.hpp:No such file or directory 解决办法:我的boost版本是boost1.63 将这个文件夹下的include的boost文件夹 复制到usr/local/include下面即可
然后又make all 结果又出问题:caffe/common.hpp:fatal error:gflags/gflags.h:No such file or directory 解决办法:先检查是否联网的 然后
sudo yum install epel-release 然后再 sudo yum install gflags-devel
又make all结果又出现:caffe/common.hpp:fatal error:glog/logging.h:No such file or directory 解决办法:sudo yum install glog-devel又make all结果又出现:caffe/common.hpp:fatal error:opencv2/core/core.h:No such file or directory 解决办法:将opencv2这个文件夹复制到usr/local/include下面4、配置caffe的python接口 pycaffe:又make all结果又出现:fatal error:hdf5.h:No such file or directory 解决办法:sudo yum install hdf5-devel又make all结果又出现:usr/bin/ld:cannot find -lopencv_highgui等等 build_release/lib/libcaffe.so.1.0.0-rc4 error 1 这个问题找了网上很多方法 终于知道解决办法:进入usr/lib64目录下 看是否有libopencv_highgui.so等等 如果只有类似libopencv_highgui.so.3.2之类的 就打开终端建立一个链接:sudo ln -sv libopencv_highgui.so.3.2 libopencv_highgui.so 即可 发现本来cannot find的库都可以找到了不报错了最后又make all看可以了不 结果还剩下两个提示:ld:cannot find -lcblas和latlas这两个 解决办法:打开caffe-master下的Makefile定位到有cblas的地方 有2处 但语句都是LIBRARY += 啥啥啥的 这句都替换成LIBRARY += satlas 然后将/usr/lib64/atlas/下的文件libsatlas.so复制一个到/usr/lib64下 即可 重新编译make all。终于libcaffe.so这里不报错了!但还是报了个错:examples/cpp_classification/classification.o: undefined reference to symbol '_ZN2cv6imreadERKNS_6StringEi' 解决办法:将Makefile文件的LIBRARIES += opencv_core opencv_highgui等那一行 后面加上opencv_imgcodecs 然后在lib64里面像之前那样创建链接:比如我的是sudo ln -sv libopencv_imgcodecs.so.3.2 libopencv_imgcodecs.so 即可 然后再make all就没问题了啊!!!!喜极而泣!因为我们这样断断续续的make all实际是连续的 比如解决了一个问题 再make all它会连着上一次正确的地方继续编译而已 如果想全部重新来编译 那么先在caffe根目录下 make clean 再make all即可发现不报错了!!!3、make test 在根目录下 因为之前完成了 make all所以接下来 make test 不报错 接着 make runtest出错:.build_release/tools/caffe: error while loading shared libraries: libcudart.so.8.0: cannot open shared object file: No such file or directory解决办法:32-bit:
sudo ldconfig /usr/local/cuda/lib64-bit:
sudo ldconfig /usr/local/cuda/lib64 我是64位 用这个 就不报找不到libcudart.so的错误了 但报了build_release/tools/caffe:error while loading shared libraries:libprotobuf.so.9:cannot open shared object file 解决办法:查找到libprotobuf.so.9在哪里 然后将它复制到/usr/lib64下面即可 再次运行make runtest终于成功了哈哈!!!!!!!!!!!!!好几天了!CentOS下装caffe这么麻烦!
4、上面已经装好了CentOS+caffe 但貌似还没配置python接口啊完成了!!!
在caffe根目录下:make pycaffe 报错说:Python.h没有这个目录或文件! 解决办法:yum install python-devel 接着报错说:numpy/arrayobject.h没有这个文件或目录!解决办法:在caffe的python下 打开终端 yum install numpy即可。再次make pycaffe时报错说ld:cannot find -lboost_python于是我找到libboost_python.so将其复制一个到/usr/lib64下即可。最后再一次make pycaffe不再报错!!!!!!!!!终于配置好了!
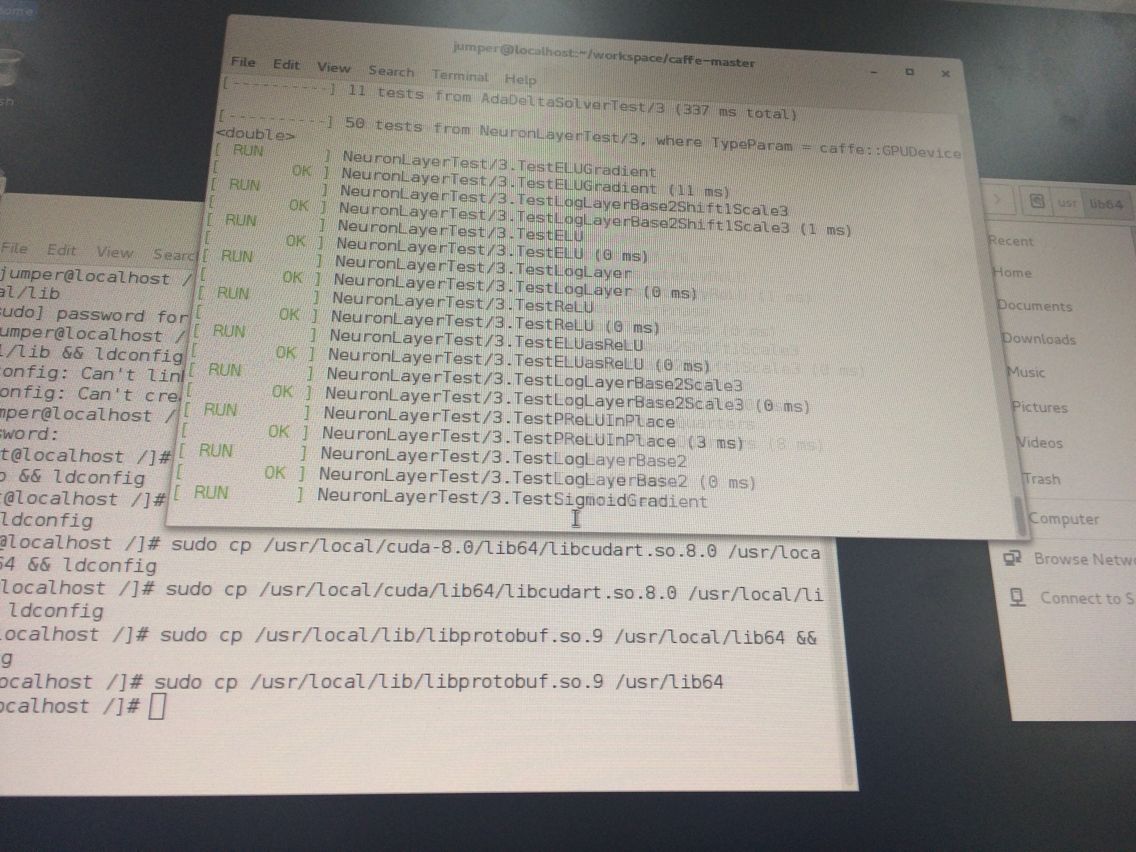
配置好了的CentOS+caffe+python+GPU就是飞一般的快啊!训练mnist那个只要三分钟就出来了:准确率0.9909 三分钟啊!!!!!
另外我终于明白为什么网上一搜 全是Ubuntu+caffe的 而很少CentOS+caffe+gpu+python的 因为太生不如死了这个过程! 用Ubuntu配置就很顺利!不管怎样 还是配置好了CentOS下的gpu加速的版本!开心。
http://www.cnblogs.com/alexanderkun/p/5701733.html
caffe 每层结构
/***********************用CentOS+caffe+GPU做自己的上一个小例子***********************/
前面的生成txt文件、转成lmdb和上面差不多 和ubuntu下差不多 但在转成lmdb.sh里出了问题:报错说:build/tools/convert_imageset:error while loading shared libraries:libcudart.so.8.0:cannot open shared object file 解决办法:
sudo cp /usr/local/cuda-6.5/lib64/libcudart.so.8.0 /usr/lib64/libcudart.so.8.0 && sudo ldconfig
sudo cp /usr/local/cuda-6.5/lib64/libcublas.so.8.0 /usr/lib64/libcublas.so.8.0 && sudo ldconfig
sudo cp /usr/local/cuda-6.5/lib64/libcurand.so.8.0 /usr/lib64/libcurand.so.8.0 && sudo ldconfig即可。
计算均值也一样
配置文件那里改成GPU 因为我这个gpu下的 当然用mode GPU了
开始训练也几乎一样!飞一般的快啊 :
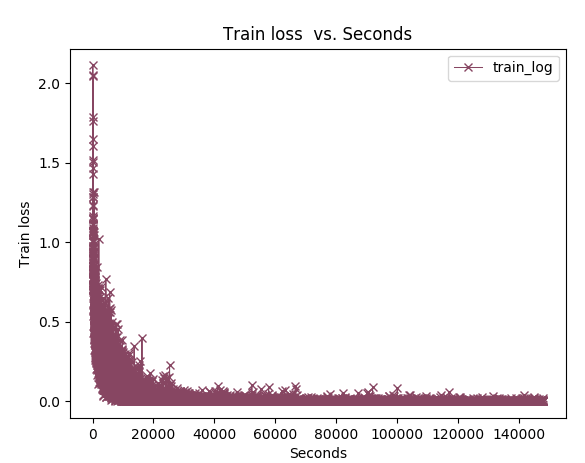
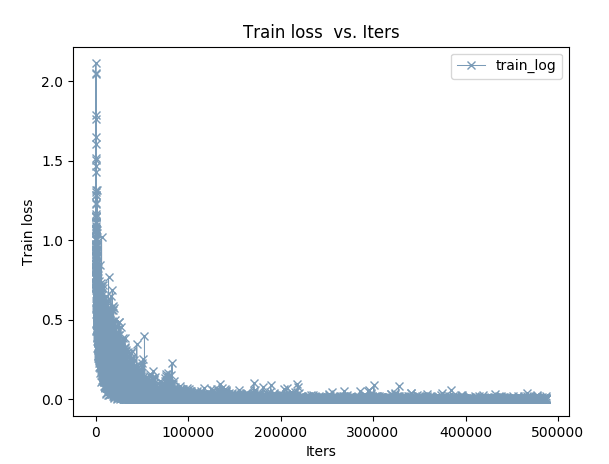
想画曲线图 更直观:
画accuracy和loss曲线图:还是用之前我传过的一个windows下gpu+caffe版本中的caffe-plot.py脚本放在caffe-master/python下面即可 然后再在caffe-master/examples/(我新建的猫狗文件夹) 这个目录下新建一个sh脚本 内容是:
python python/caffe-plot.py examples/cats_dogs/train_log.txt运行时本来出了个错误:ImportError:No module named matplotlib.pyplot
在python文件夹下 打开终端 yum install python-matplotlib 即可。 但出来还是不行 原来我的caffe的python接口没有配置 只是有python 但接口没配置 傻!
重新配置caffe的python接口 先按照 http://deuteronploun.blogspot.jp/2014/04/pythonmatplotlibbasemap-in-centos.html 装好了matplotlib 因为import matplotlib显示没问题。 然后 http://blog.csdn.net/tsinghuahui/article/details/46790705 但还是有错额。。。因为我的caffe的python接口没有配置 当我python 然后import caffe 会报错说没有caffe!说明caffe的python接口没有配置好 哪怕之前好像某一步make pycaffe完成了 make test和make runtest也都完成了 import caffe报错就是实实在在错了!好了 重新配置caffe的python接口:
按照 http://www.cnblogs.com/denny402/p/5088399.html 但anaconda必须要装!中间报了一个错:
ImportError: “No module named google.protobuf.internal
原因:之前装过一个pip 而刚刚装anaconda时会自带一个pip 解决办法:pip install protobuf
/home/username/anaconda2/bin/pip install protobuf
终于可以了:
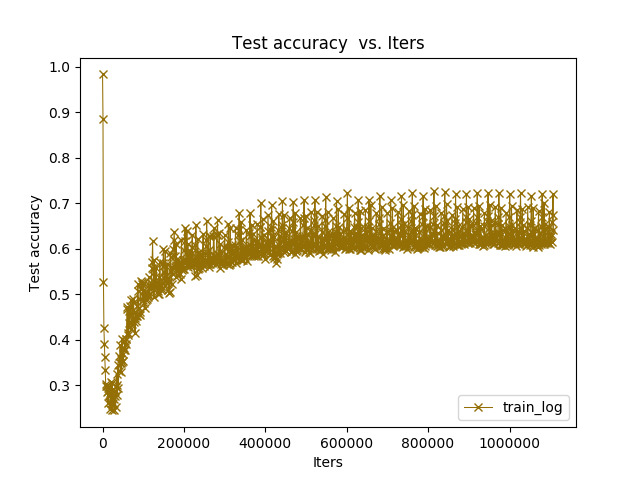
画图的这个我最终还是没有用python脚本去读log.txt日志 因为出来都不对 为什么?
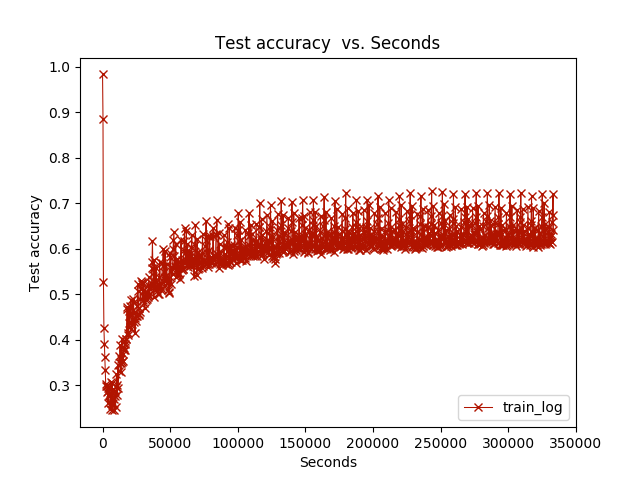
后来按照 http://blog.csdn.net/maweifei/article/details/53026349 这个人的用caffe自带的画图工具:
画出网络结构:
首先确保protobuf是3+以下的版本 我的是2.6.1 http://www.cnblogs.com/txg198955/p/6185787.html 报过错AttributeError: 'google.protobuf.pyext._message.RepeatedScalarConta' object has no attribute '_values' 解决办法:https://github.com/NVIDIA/DIGITS/issues/591 即可。而且画出来是正确的: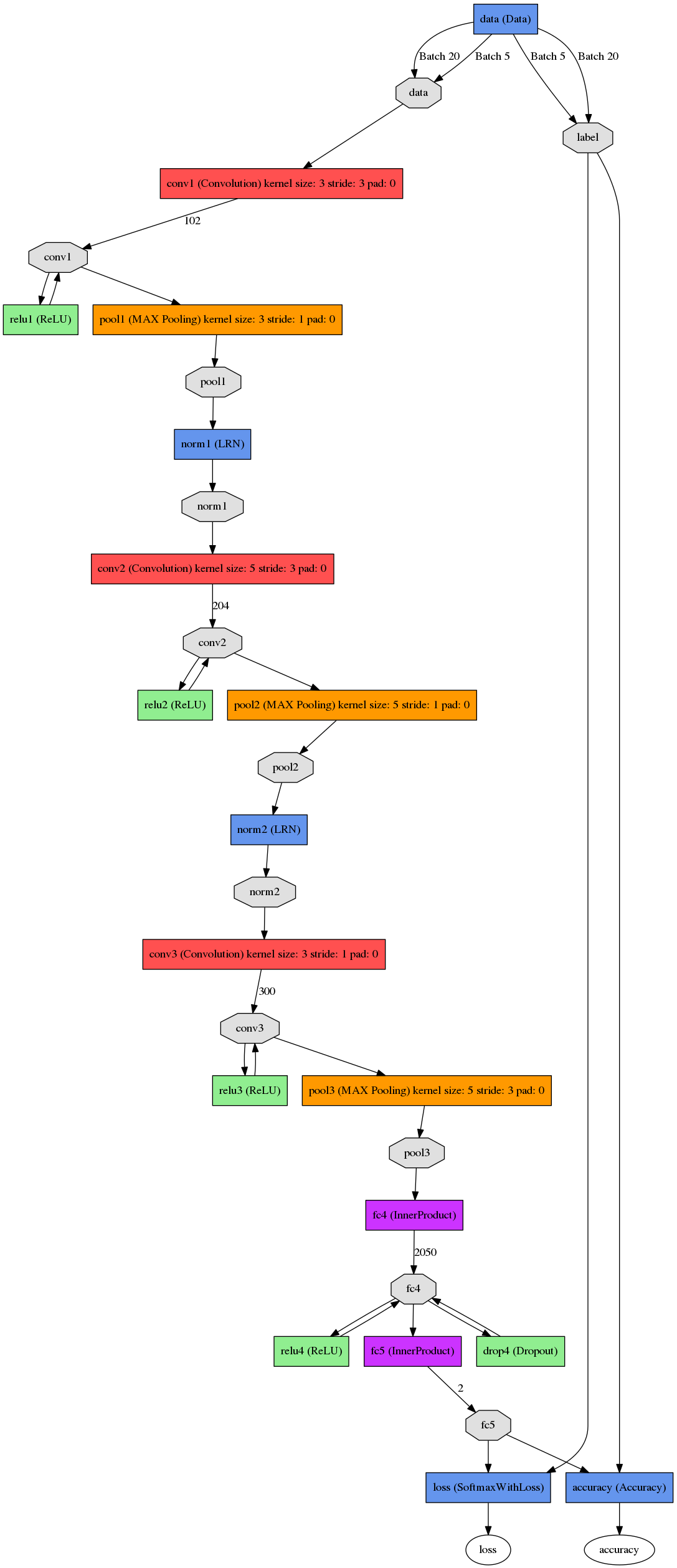
提取特征部分也没问题:
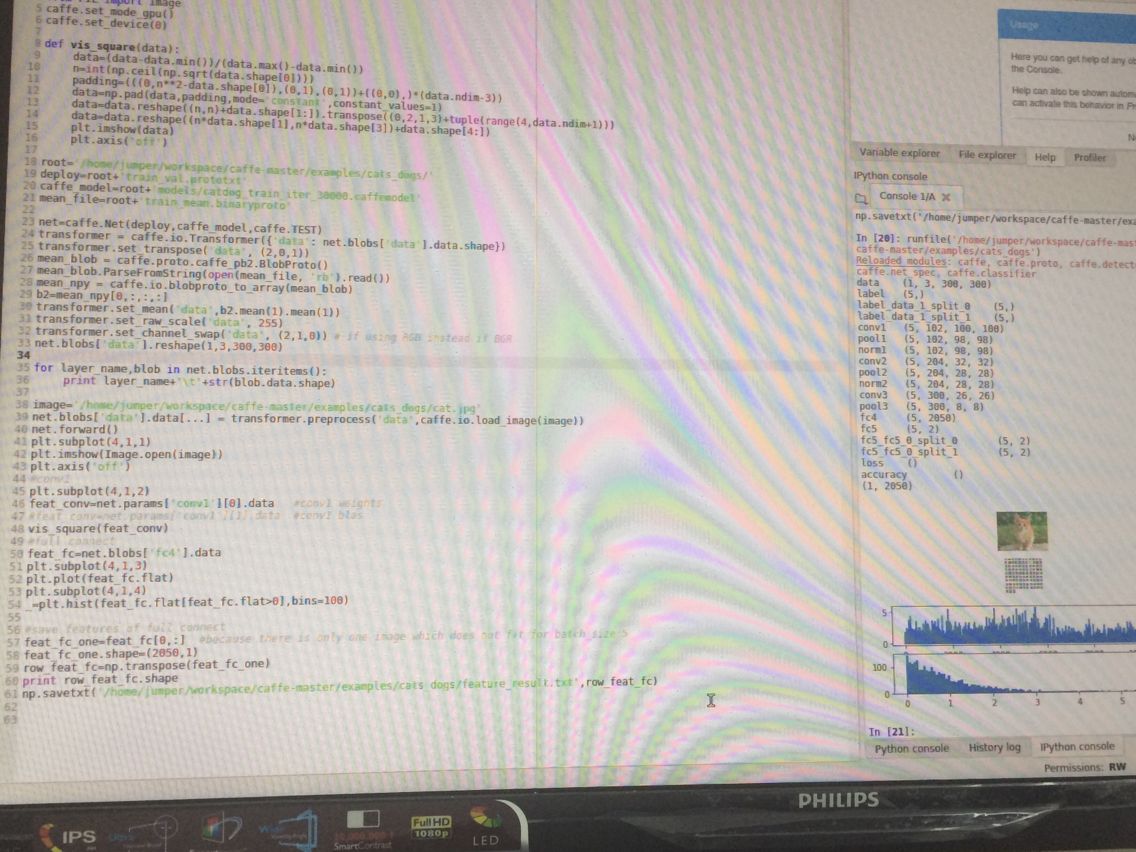
但画曲线图那里为什么出来的不正确呢?
/*****************终于明白了哈哈*************************************************/
原来是train_val.prototxt那里最后写了TRAIN 是算的train_accuracy 画图这部分重新改过来以后就行了
我这个例子目录下的文件 脚本及生成文件:
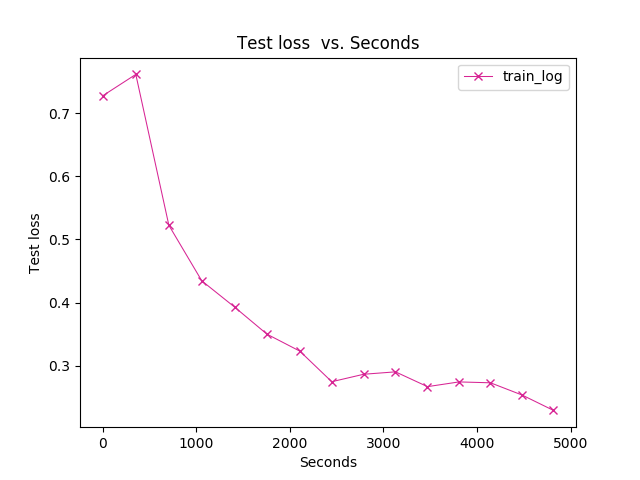
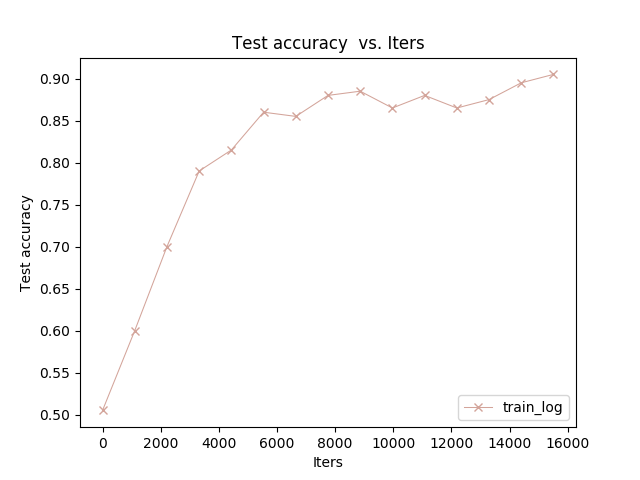
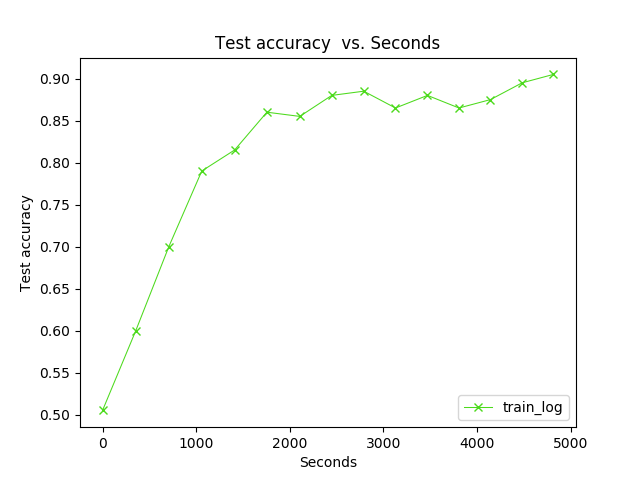
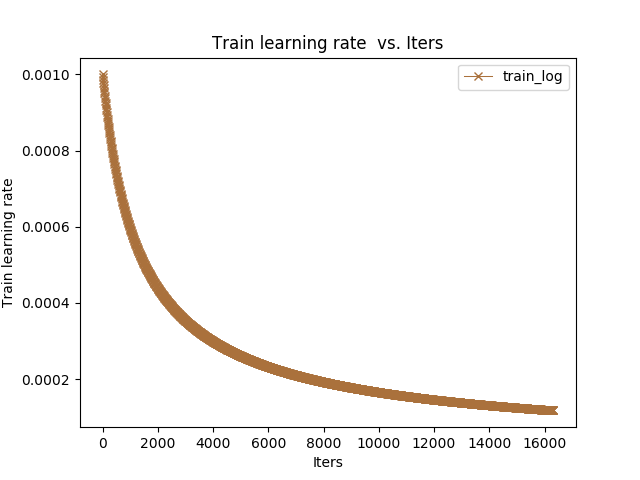
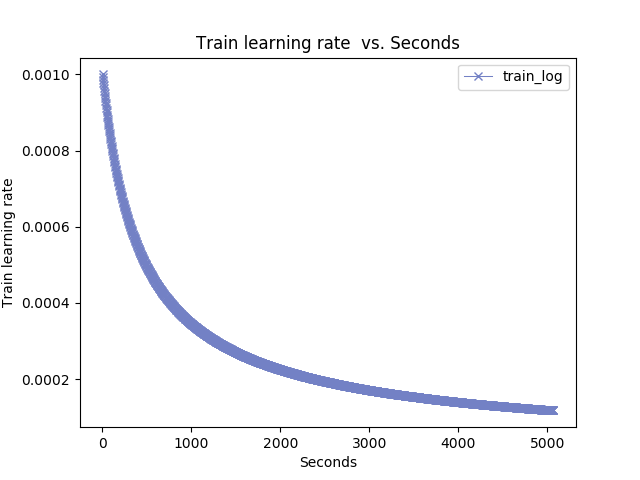
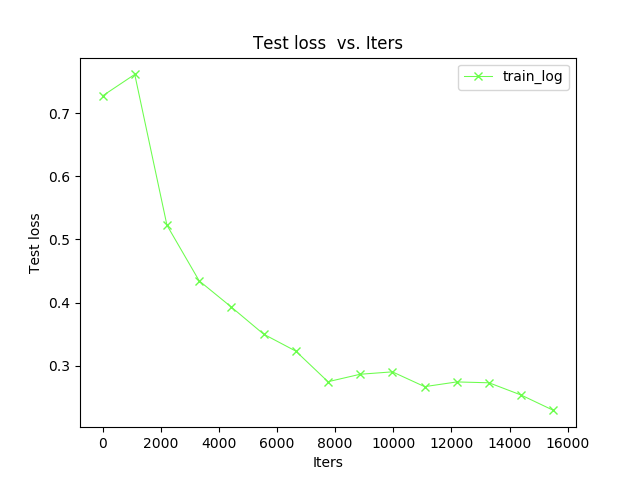
我的画图的临时生成文件:日志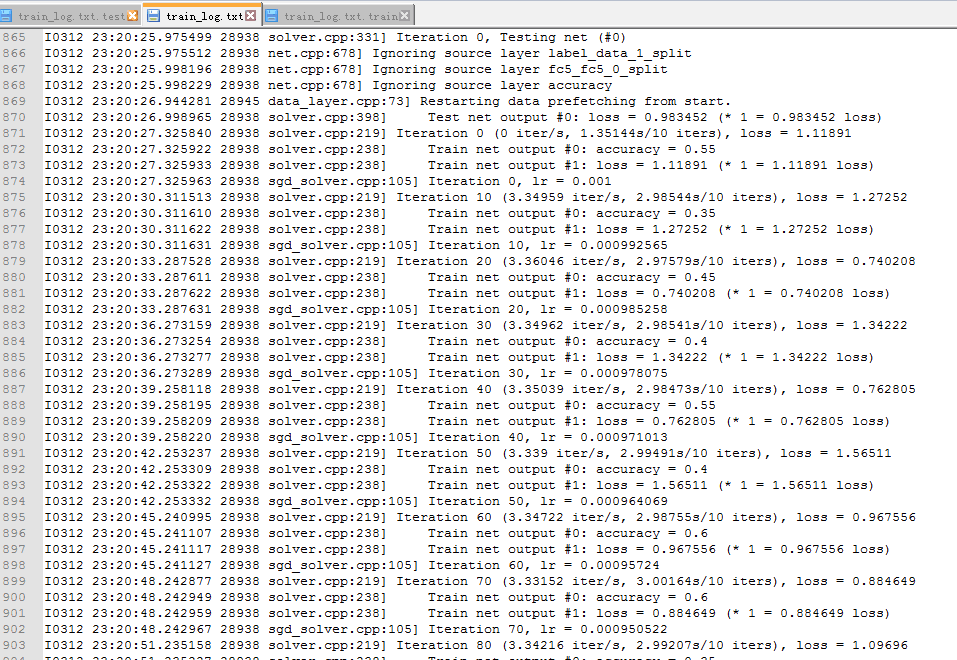
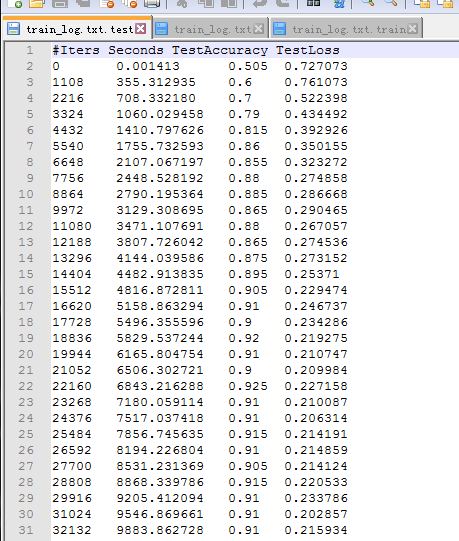
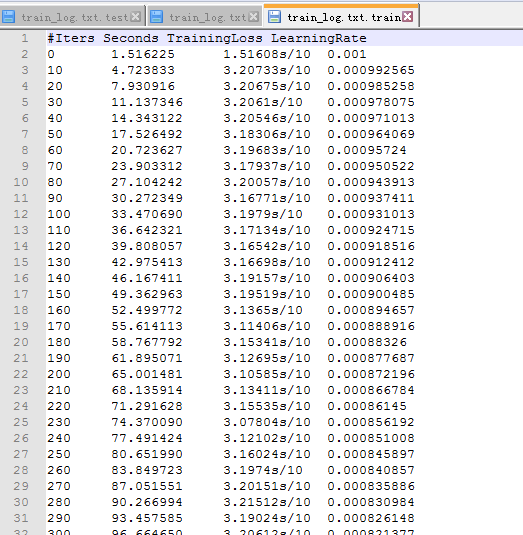
然后是parse-log.sh提取的train文件
我在parse-log.sh脚本中 在这句 grep 'Iteration ' aux.txt | sed 's/.*Iteration \([[:digit:]]*\).*/\1/g' > aux0.txt 后加了个保存aux.txt的操作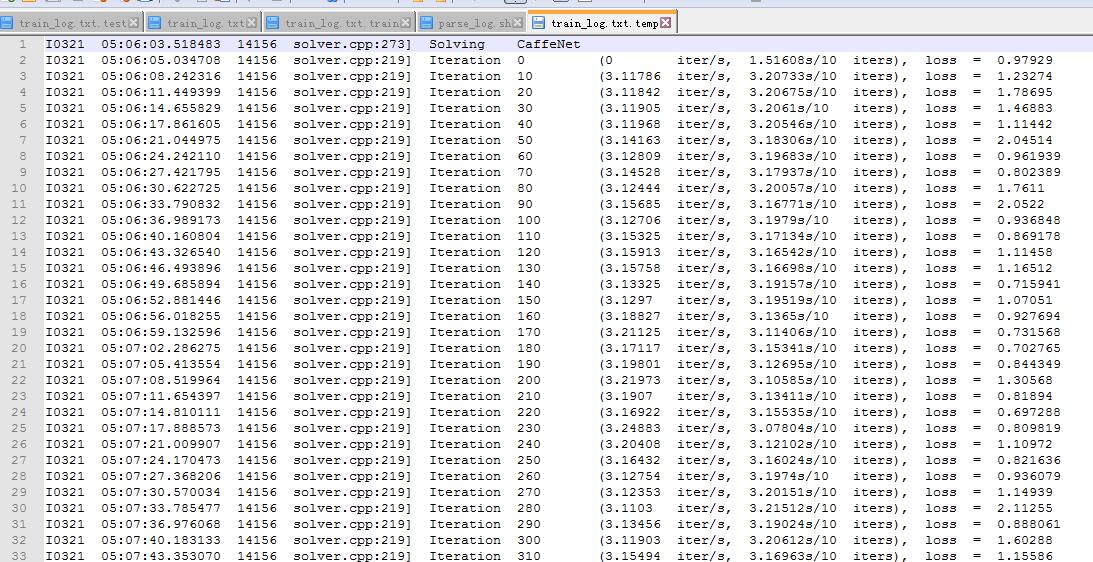
grep ', loss = ' $1 | awk '{print $9}' > aux1.txt
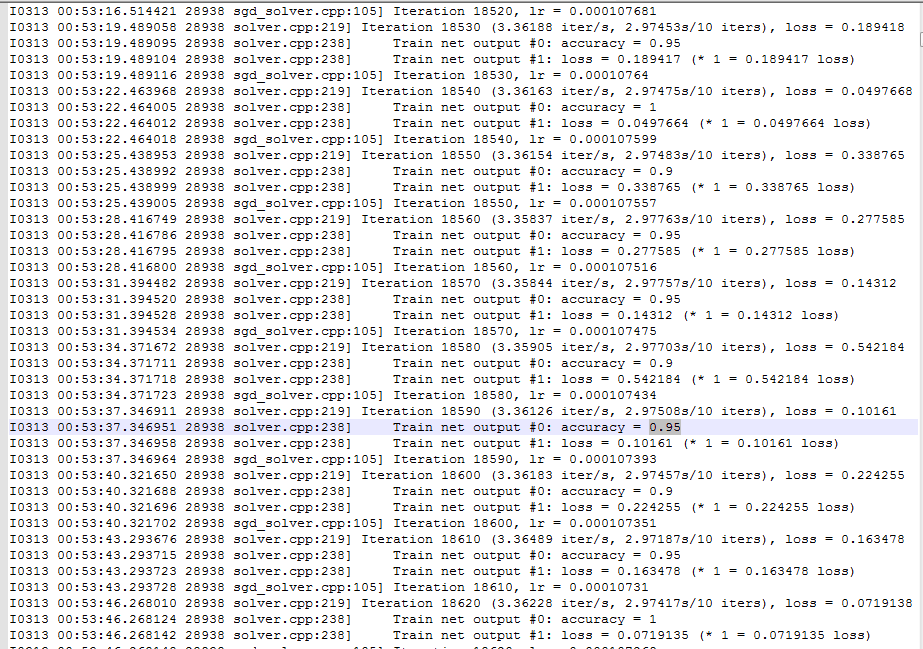
grep ', lr = ' $1 | awk '{print $9}' > aux2.txt按道理来说应该就能准确提取loss的啊 可是提取出来却有s/iter
我懂了 刚刚看了一下http://blog.csdn.net/taiyang1987912/article/details/39187525 了解了parse-log.sh 提取关键字loss后的数字 那个语句的意思 终于明白了:对于parse-log生成的关于train的临时文件中 按照caffe自带的parse-log中它提取到的是第9列(专业的叫第9个域) 也就是带S/10的那些数 

至于利用caffemodel对新样本分类: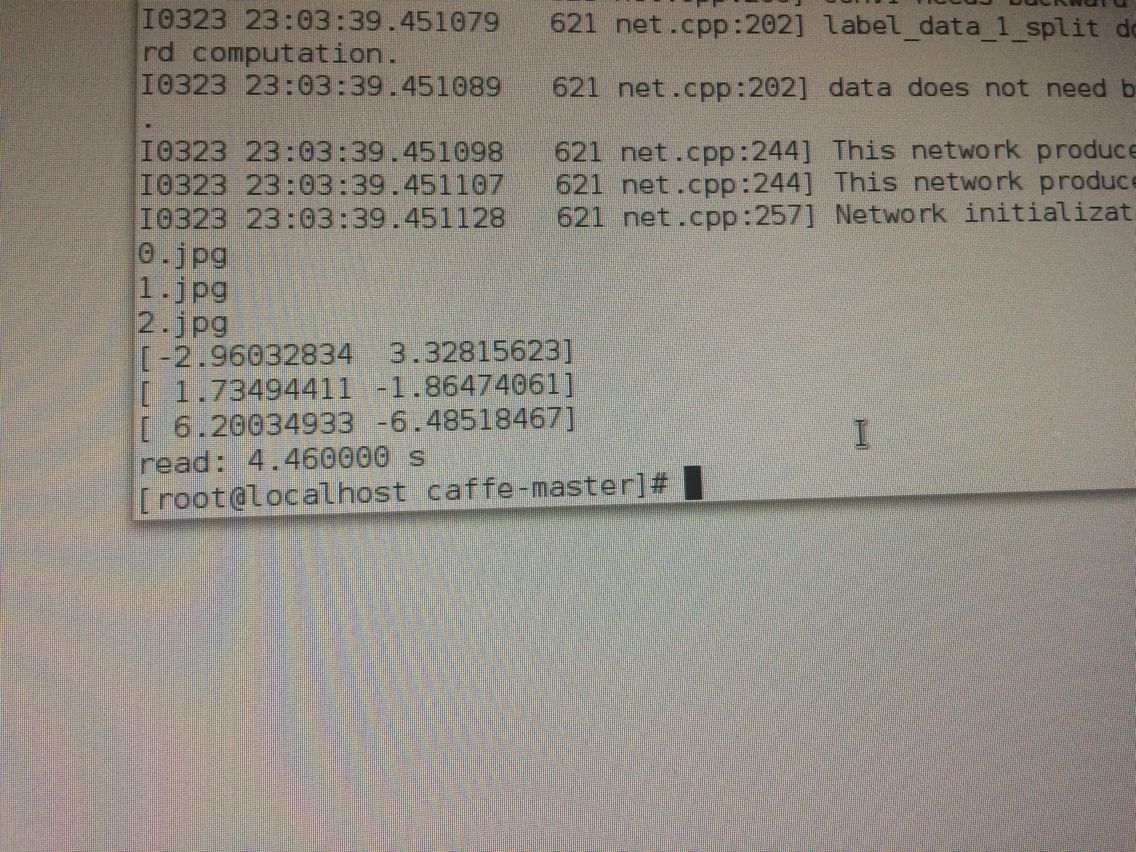
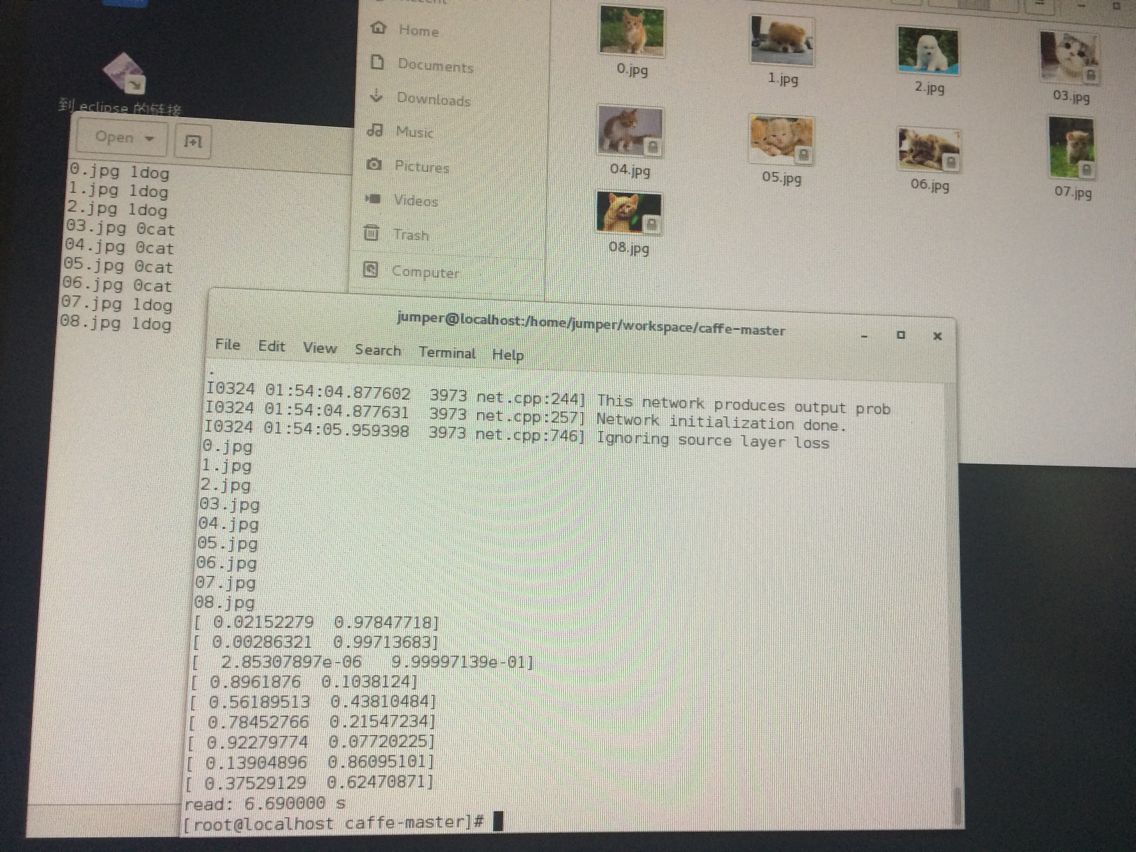
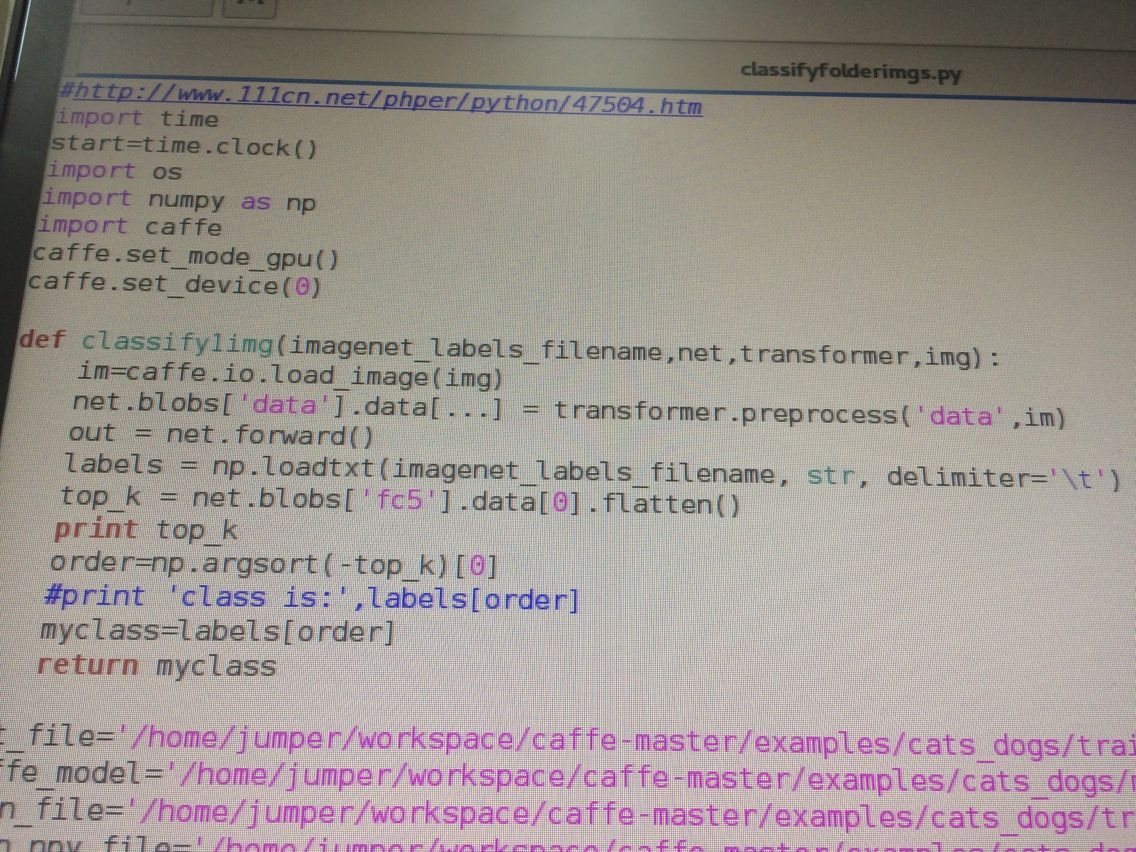
贴上我的train_val.prototxt:
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 300
mean_file: "/home/jumper/workspace/caffe-master/examples/cats_dogs/train_mean.binaryproto"
}
data_param {
source: "/home/jumper/workspace/caffe-master/examples/cats_dogs/train_lmdb"
batch_size: 20
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 300
mean_file: "/home/jumper/workspace/caffe-master/examples/cats_dogs/train_mean.binaryproto"
}
data_param {
source: "/home/jumper/workspace/caffe-master/examples/cats_dogs/test_lmdb"
batch_size: 5
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 102
kernel_size: 3
stride: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 204
kernel_size: 5
stride: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 5
stride: 1
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 300
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 5
stride: 3
}
}
layer {
name: "fc4"
type: "InnerProduct"
bottom: "pool3"
top: "fc4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2050
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "fc4"
top: "fc4"
}
layer {
name: "drop4"
type: "Dropout"
bottom: "fc4"
top: "fc4"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc5"
type: "InnerProduct"
bottom: "fc4"
top: "fc5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc5"
bottom: "label"
top: "loss"
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc5"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
name: "CaffeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 9 dim: 3 dim: 300 dim: 300 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 102
kernel_size: 3
stride: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 1
}
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 204
kernel_size: 5
stride: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 5
stride: 1
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 300
kernel_size: 3
stride: 1
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 5
stride: 3
}
}
layer {
name: "fc4"
type: "InnerProduct"
bottom: "pool3"
top: "fc4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2050
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "fc4"
top: "fc4"
}
layer {
name: "drop4"
type: "Dropout"
bottom: "fc4"
top: "fc4"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc5"
type: "InnerProduct"
bottom: "fc4"
top: "fc5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc5"
top: "prob"
}对了如果要保存模型为.h5而不是caffemodel 那么在solver.prototxt中加上一句:snapshot_format:HDF5即可 即生成的就是h5而不是caffemodel。
今天2017.5.11 刚刚帮别人linux电脑装CUDA加速:在我按照之前的步骤关闭nouveau后,reboot竟然进入不了图形界面,重启卡住:
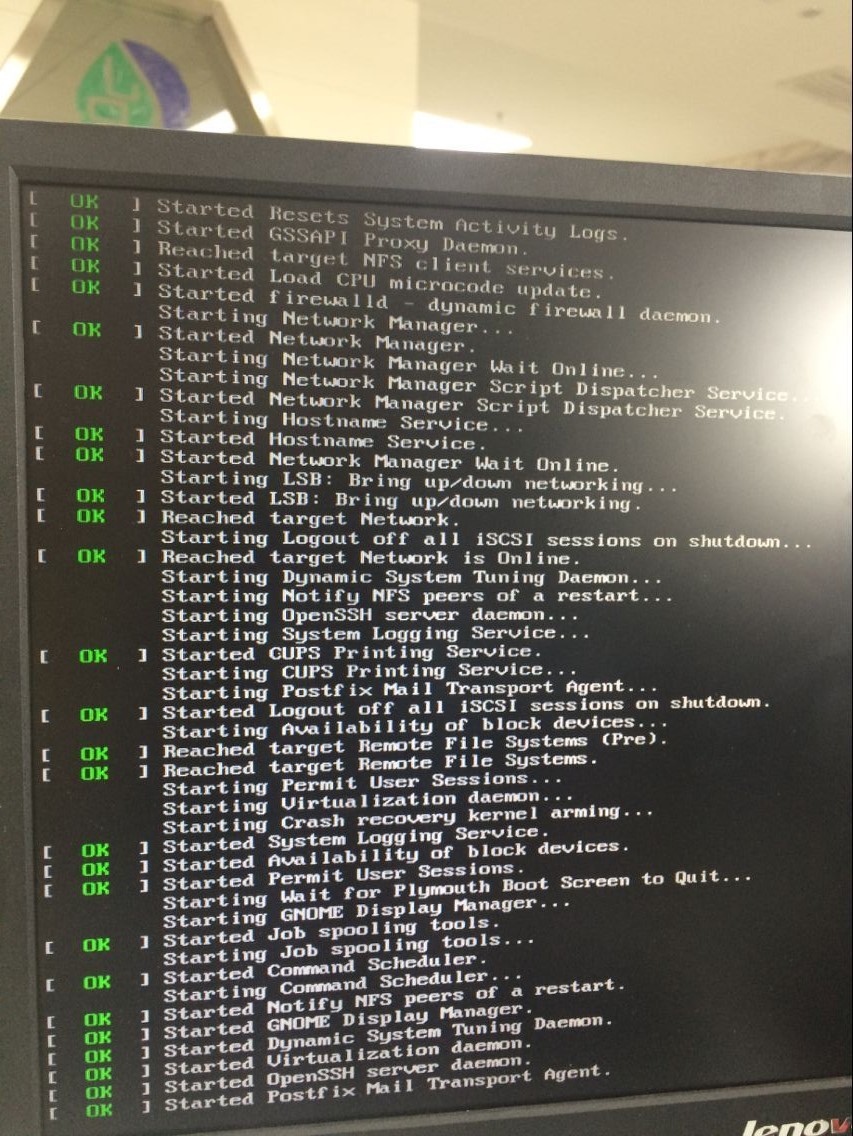
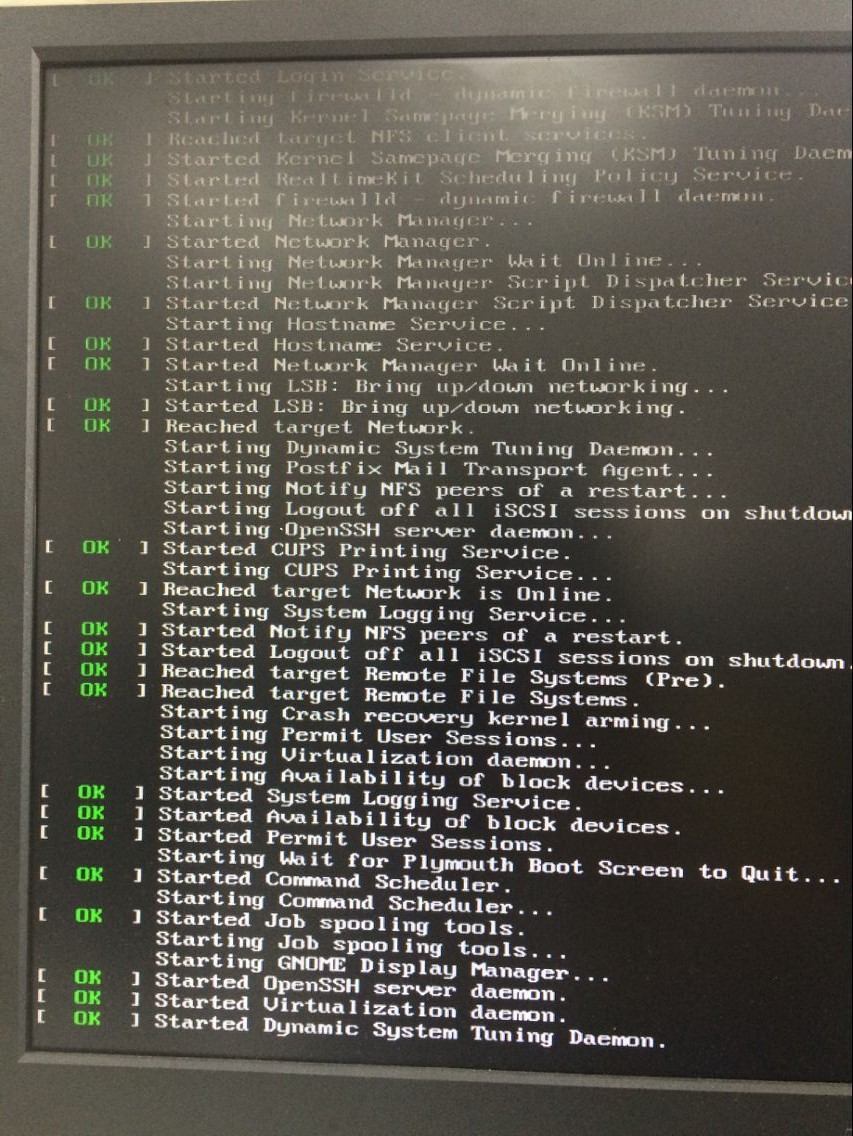
出现这种情况,能够按artl+alt+f2进入命令行,但怎么也进不了图形界面。
没办法,只能叫他先重装系统。然后我首先下载cuda驱动也就是NVIDIA-Linux-x86_64-375.39.run文件 然后记好我放的位置;
然后按照之前的方法关闭nouveau;然后重启
重启又卡住像上面一样,然后进入命令行,输入 sh /.../NVIDIA-Linux-x86_64-375.39.run安装驱动即可。没出现问题。然后装好了再重启即可进入图形界面;、
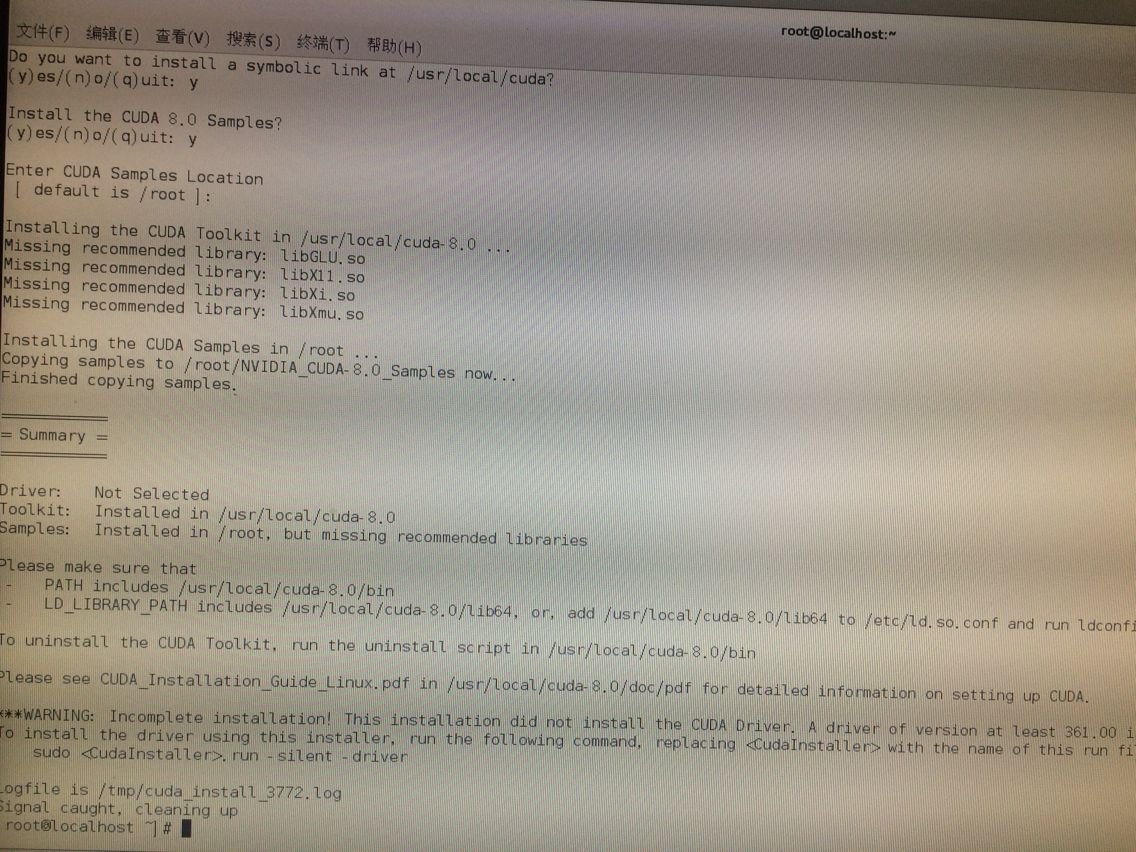
再下载cuda toolkit文件:cuda_8.0.61_375.26_linux.run,用sh安装,但出现个问题:
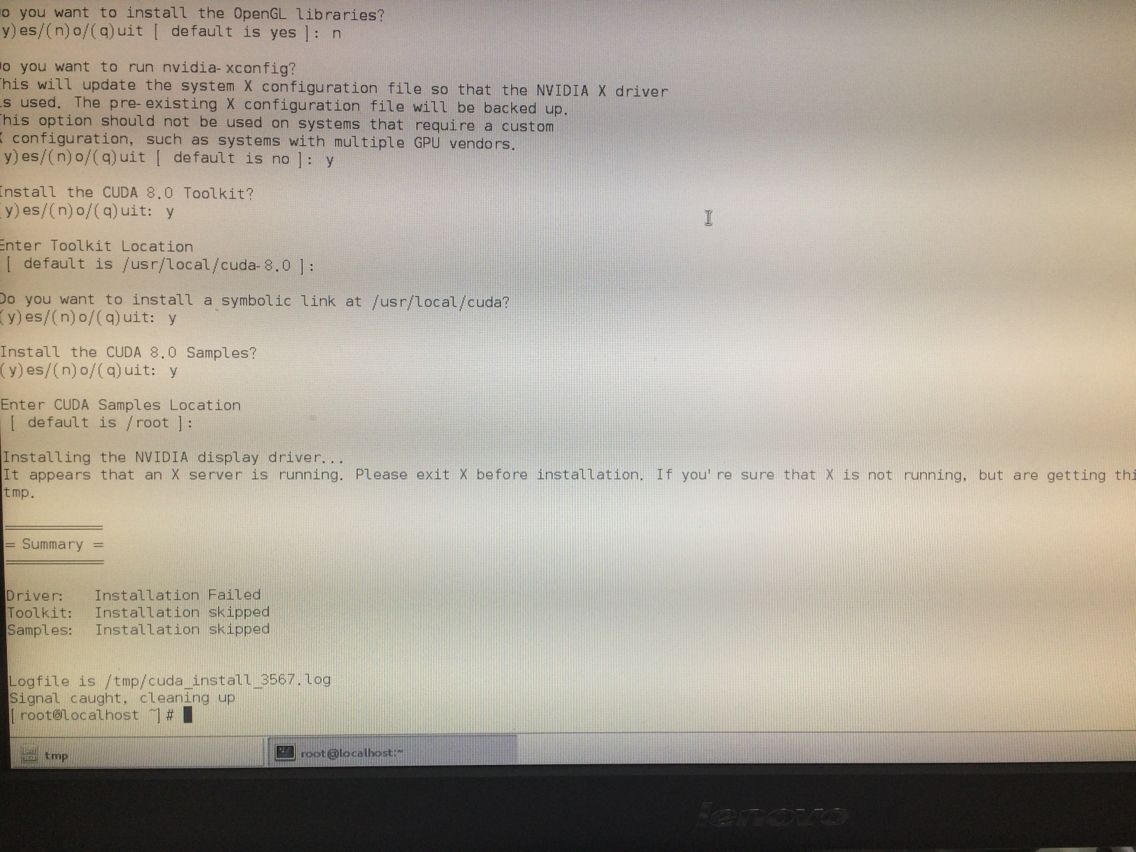
检测驱动是否安装好 nvidia-smi
检测toolkit是否安装好 /usr/local/cuda-8.0/bin/nvcc
但竟然nvcc找不到命令也就是装失败了。 我去这个目录下看 的确没有nvcc 于是Toolkit部分我又重来了一遍 发现结果又有nvcc了 输入提示信息:nvcc warning:The 'compute_20','sm_20'....这就表示成功安装好了ToolKit。
完毕。
后来大神在import tensorflow时报了一个错:Couldn’t open CUDA library libcudnn.so.5. LD_LIBRARY_PATH: I tensorflow/stream_executor/cuda/cuda_dnn.cc:3459] Unable toload cudnn DSO. 因为我之前没有装cudnn的 所以报这个也正常 于是我下载了对应版本的cudnn 将h文件和libcudnn分别放到/usr/local/cuda-8.0/include里 和/lib64里,当然也复制一份到/usr/include里、/usr/lib64里即可。
退出终端 重新打开一个终端 import tensorflow就没问题了!
他的电脑比我奇葩,我自己电脑装时没遇到这些问题。
(补充:今天2017.09.04 他所有过程都在init 3即shell界面下重做一遍 就可以了 最后所有都在shell界面装好后重启 就可以进入图形界面了)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)