
高速网络下的 Netmap 单 RX 队列内核旁路技术
感谢伯乐在线 @至秦前辈 校稿
原文链接 这里
在 前一篇文章 中,我们讨论了 Linux 内核网络协议栈的性能瓶颈。我们详细说明了如何利用内核旁路技术,让用户空间程序可以接收大量的数据包。遗憾的是,没有开源解决方案讨论过这个问题,来满足我们的需求。为了改善现状,我们决定为 Netmap 项目 做点贡献。在本篇文章中将描述我们提出的改动。

我们的需求
在 CloudFlare,我们经常处理汹涌的数据流量。我们的网络经常会接收到很多的数据包,它们总是来自大量的同步攻击。事实上此刻仅是这篇文章所在的服务器,都完全有可能每秒钟处理数百万的数据包。
因为 Linux 内核实际上不能真正处理大量的数据包,我们需要想办法解决这个问题。在洪水攻击期间,我们将选定的网络流量卸载到用户空间程序。这个应用程序以非常高的速度过滤数据包。大部分数据包被丢弃了,因为它们属于洪水攻击。少量“有效”的数据包被重新返回内核并且以正常流量的方式处理。
需要重点强调的是内核旁路技术只针对选定的流,这意味着所有其它的数据包都像往常一样经过内核。
这个工作完美地建立在基于 Solarflare 网卡的服务器上 —— 我们可以使用 ef_vi API 来实现内核旁路技术。不幸的是,我们没有在基于Intel IXGBE 网卡的服务器上实现这个功能。
直到 Netmap 出现。
Netmap
过去的几个月里,我们一直认真地思考如何在非 Solarflare 网卡选定的数据流上,完成旁路技术(又叫做:分叉驱动)。
我们考虑过 PF_RING,DPDK 和其他一些定制的解决方案,但不幸的是所有这些方案都应用在整个网卡上(译者注:即不能在选定的数据流上操作),最后我们决定最好的方式就是根据我们需要的功能给 Netmap 打补丁。
我们选择 Netmap 是因为:
- 它完全开源并且基于 BSD 许可发布。
- 它可以很好得支持网卡无关 API。
- 它非常快:很容易满足线路速率的要求。
- 这个项目维护得很好并且相当成熟。
- 代码的质量非常高。
- 对特定驱动的修改很小:大多数神奇的事都发生在共享的Netmap 模块,很容易对添加的新硬件提供支持。
单 RX 队列模块介绍
通常当一个网卡进入 Netmap 模式,所有的 RX 队列都会从内核中分离出来并用于 Netmap 的应用程序。
我们不希望这样。我们想让大部分 RX 队列留在内核模式中,仅仅在选定的 RX 队列上采用 Netmap 模式,我们把这个功能称为:“单 RX 队列模式”。
其目的是暴露一个简单的 API,它可以:
- 在“单 RX 队列模式”下打开一个网络接口。
- 这将允许 Netmap 应用从特定的 RX 队列上接收数据包。
- 其他所有队列都被绑定在主机网络协议栈上。
- 按需添加或删除“单 RX 队列模式”下的 RX 队列。
- 最后从 Netmap 模式上移除这个接口,并将 RX 队列重新绑定到主机协议栈上。
这个 Netmap 的补丁正在等待代码审查,可以在这里找到它:
一个从 eth3 的 RX 4 号队列上接收数据包的小程序看起来像这样:
d = nm_open("netmap:eth3~4", NULL, 0, 0);
while (1) {
fds = {fds: d->fd, events: POLLIN};
poll(&fds, 1, -1);
ring = NETMAP_RXRING(d->nifp, 4);
while (!nm_ring_empty(ring)) {
i = ring->cur;
buf = NETMAP_BUF(ring, ring->slot[i].buf_idx);
len = ring->slot[i].len;
//process(buf, len)
ring->head = ring->cur = nm_ring_next(ring, i);
}
}这段代码非常接近 Netmap 的示例程序。事实上唯一区别在于 nm_open() 调用,它使用了新的语法,netmap:ifname~queue_number。
再次,当运行这段代码时只要数据包到达 4 号 RX 队列就会进入 netmap 程序,所有其他的 RX 和 TX 队列将被 Linux 内核网络协议栈处理。
你可以在这里找到更多完整的例子:
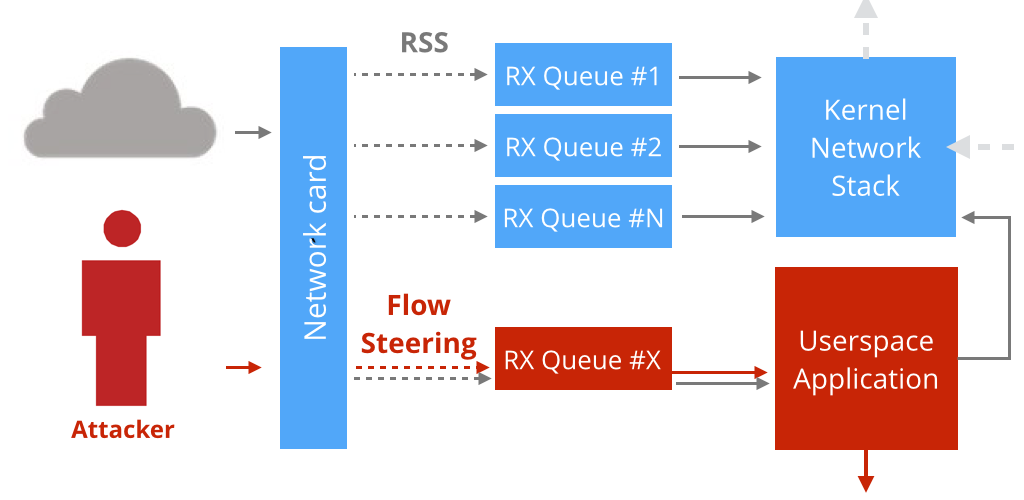
独立一个队列
由于 RSS(译者注:Receive Side Scaling,由微软提出,通过这项技术能够将网络流量分散到多个 cpu 上,降低单个 cpu 的占用率) 的存在,多队列网卡上的一个数据包可以出现在任意一个 RX 队列上。这是为什么打开单 RX 模式时,必须确保只有选定的流才可以进入 Netmap 队列。
这些是必须做的:
- 修改间接表以确保没有 RSS 散列的数据包到达这里。
- 使用流控制技术专门引导数据流到达独立的队列中。
- 用 RFS(译者注:Receive Flow Steering,接收流控制)方法解决 —— 确保即将运行 Netmap 的 CPU 上没有其他程序运行。
举个例子:
$ ethtool -X eth3 weight 1 1 1 1 0 1 1 1 1 1
$ ethtool -K eth3 ntuple on
$ ethtool -N eth3 flow-type udp4 dst-port 53 action 4这里我们设置间接表以阻止前往 4 号 RX 队列的流量,接着我们使用流控制技术,将所有目的端口是 53 的 UDP 流量引导向 4 号队列
尝试一下
以下是如何在 IXGBE 网卡上运行这项技术。首先获取源码:
$ git clone https://github.com/jibi/netmap.git
$ cd netmap
$ git checkout -B single-rx-queue-mode
$ ./configure --drivers=ixgbe --kernel-sources=/path/to/kernel加载 Netmap 补丁模块并设定接口:
$ insmod ./LINUX/netmap.ko
$ insmod ./LINUX/ixgbe/ixgbe.ko
$
# Distribute the interrupts:
$ (let CPU=0; cd /sys/class/net/eth3/device/msi_irqs/; for IRQ in *; do
echo $CPU > /proc/irq/$IRQ/smp_affinity_list; let CPU+=1
done)
$
# Enable RSS:
$ ethtool -K eth3 ntuple on现在我们开始以 6 M UDP 数据包来填充这个接口,htop 命令显示服务器此刻完全忙于处理大量的数据包:
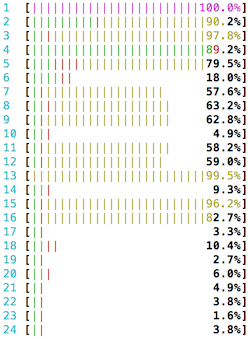
为了应对大流量,我们启动 Netmap。首先我们需要编辑间接表,挑选出 4 号 RX 队列:
$ ethtool -X eth3 weight 1 1 1 1 0 1 1 1 1 1
$ ethtool -N eth3 flow-type udp4 dst-port 53 action 4这导致所有的数据包都去往 4 号 RX 队列。
在 Netmap 设置接口前,必须关闭硬件卸载的功能:
$ ethtool -K eth3 lro off gro off最后我们启动 netmap 卸载功能:
$ sudo taskset -c 15 ./nm_offload eth3 4
[+] starting test02 on interface eth3 ring 4
[+] UDP pps: 5844714
[+] UDP pps: 5996166
[+] UDP pps: 5863214
[+] UDP pps: 5986365
[+] UDP pps: 5867302
[+] UDP pps: 5964911
[+] UDP pps: 5909715
[+] UDP pps: 5865769
[+] UDP pps: 5906668
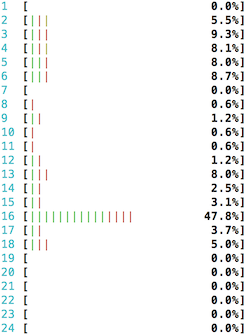
[+] UDP pps: 5875486正如你看到的,基于单 RX 队列的 netmap 程序大约收到 5.8M 数据包。
为了完整性,这有一个仅运行在单核下的 netmap 的 htop 展示:
感谢
我要感谢 Pavel Odintsov,是他提出了使用 Netmap 这种方式的可能性。他还做了初步的修改,使得我们在基础上进行开发。
我也要感谢 Luigi Rizzo,为他对 Netmap 所做的工作和对我们补丁提出很棒的意见。
结束语
在 CloudFalre ,我们应用程序协议栈是以开源软件为基础的。我们对开源工作者所做出的卓越工作表示感激,无论何时我们会尽力回报社区 —— 我们希望 “单 RX 队列 Netmap 模式”对其他人能有所帮助。
你可以在 这里 找到更多关于 CloudFlare 的开源代码。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)