Hive中的.hiverc文件及命令运行方式
linux-dash
A beautiful web dashboard for Linux
项目地址:https://gitcode.com/gh_mirrors/li/linux-dash
·
在${HIVE_HOME}/bin目录下有个.hiverc文件,它是隐藏文件,我们可以用Linux的ls -a命令查看。我们在启动Hive的时候会去加载这个文件中的内容,所以我们可以在这个文件中配置一些常用的参数,如下:
#在命令行中显示当前数据库名
set hive.cli.print.current.db=true;
#查询出来的结果显示列的名称
set hive.cli.print.header=true;
#启用桶表
set hive.enforce.bucketing=true;
#压缩hive的中间结果
set hive.exec.compress.intermediate=true;
#对map端输出的内容使用BZip2编码/解码器
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
#压缩hive的输出
set hive.exec.compress.output=true;
#对hive中的MR输出内容使用BZip2编码/解码器
set mapred.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
#让hive尽量尝试local模式查询而不是mapred方式
set hive.exec.mode.local.auto=true;命令的运行方式:
1.在Linux命令行下使用hive -e "SQL语句"的方式运行:
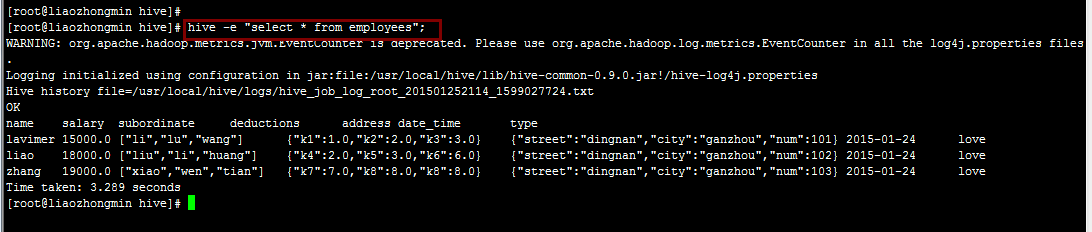
注:从图中可以看出这种方式并不需要进入Hive直接在Linux命令行运行,这可以避免切换状态带来的不便。
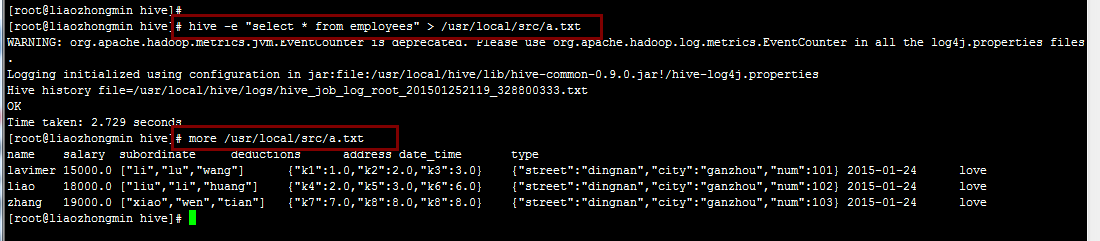
2.把查询结果导出到文件中,也是在Linux命令中使用hive -e "XXX" > a.txt
3.是执行语句安静的执行,使用hive -S -e "XXX"。

附:从上面我们可以看到和HQL语句执行相关的日志都不会输出了。
4.在Linux命令行中使用hive -f "文件" 执行写在某个文件中的HQL语句。
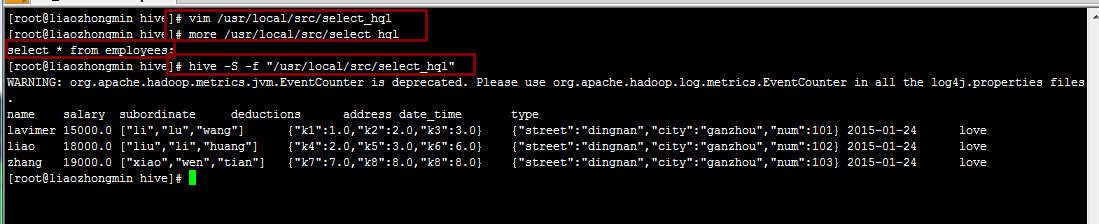
5.执行写在shell脚本中的查询语句
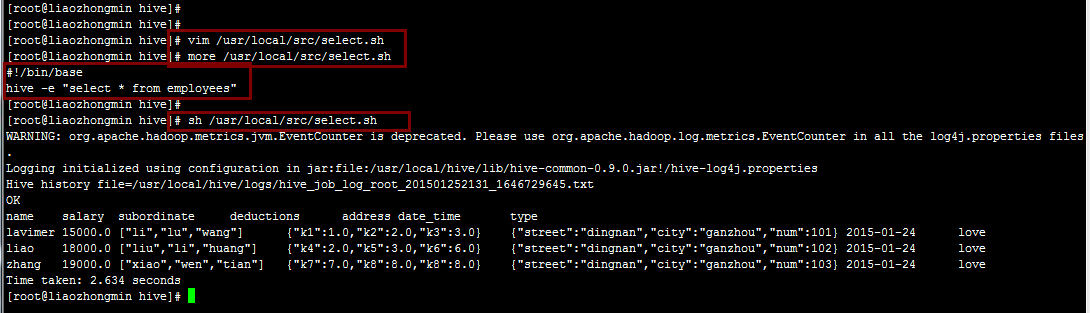
6.在Hive终端使用source 文件名 的形式执行写在文件中的语句

注:这个命令是在Hive终端执行的,且文件不需要使用双引号!
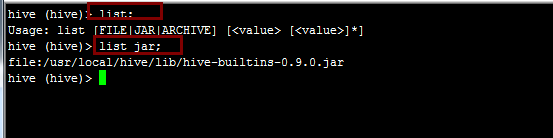
7.显示分布式缓存中的jar包,在hive终端使用list jar命令
A beautiful web dashboard for Linux
最近提交(Master分支:4 个月前 )
186a802e
added ecosystem file for PM2 5 年前
5def40a3
Add host customization support for the NodeJS version 5 年前

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)