Linux内核构建系统原理
Linux内核构建系统原理
KEY:内核构建 内核编译 kbuild Linux
内核与应用程序分开构建
内核与应用程序被设计成分开构建的,由C头文件和C库实现(KEMIN:我们一般都是基于库编译构建应用程序,这是默认的。但是如果没有与实时系统的统一构建方式对比,认识面很单一,难以较全面认识构建软件的本质)。分开构建的优点是易于独立开发新应用,满足动态需求;缺点或代价是对内核与应用的接口的维护。
举一个具体例子详述[分开构建 ]所带来的不便。假设某OEM厂商要生产两种功能类似的网络产品:以太网桥(Ethernet bridge)和路由器(router),这两项产品是基于同一个硬件设计的。由于两种产品的硬件是一样的,基本的系统支撑软件部分也是一样的(比如boot loader和BSP),它们的不同只在于基于支撑软件上的更高级一些软件功能部分。因此,为了节省开发成本,OEM厂商只为它们维护一套单一的基本支撑软件部分代码,然后根据系统选项分别为它们构建特定功能软件部分。系统构建选项可通make实现,比如make bridge构建以太网桥,make router构建路由。要实现这两个选项则要完成很多“不便”的工作(KEMIN:由此可见分开构建的方便所带来的不便,代价代价!):
- 第一,为内核配置相应的协议软件,比如以太网桥需要spanning bridge,路由需要IP协议;
- 第二,构建相应的应用软件,比如路由器的路由服务进程(routed daemon);
- 第三,配置相应的启动文件,比如网络接口初始化文件;
- 第四,选择相应的配置文件(比如HTML文件和CGI脚本)打包进根文件系统。
用户可能会问,为什么不把两种产品所需的东西全打包进根文件系统,然后在运行时由产品自己判断和执行所需要的东西呢?桌面系统和服务器产品一般这样做的,但嵌入式系统与桌面系统和服务器的需求不同,为了节省资源,更多的组件配置发生在构建时,而不是运行时。
要实现[构建时的组件配置 ],需要什么样的机制呢?
内核构建过程(用户角度)
内核构建系统(kernel build system),行话kbuild,是和内核源码绑定在一起的基于GNU make的脚本系统。通过构建系统(以下简称kbuild),你可以轻易的对内核进行组态(KEMIN:组态就是所谓的配置,个人觉得台湾的这一译法较为形象和准确,为了术语统一,以下还是使用配置一语,了解本质后二语可互换),并构建新内核。组态与构建不完全一样,因为两过程的输入与产出不一样(KEMIN:以2.6版为例,组态的输入是Kconfig,输出是.config;.config是构建的输出之一)。另外,由于kbuild具有很好的可扩展性,你可以很容易的把你的新内核代码,比如驱动程序,挂接入kbuild。
通过kbuild对内核组态和编译的过程可分为四步:
第一,指定交叉开发环境(内核的目标体系结构);
通常通过修改已有的makefile获得,假设目标平台是ARM,修改以下:
1. ARCH ?= arm
2. CROSS_COMPILE ?= arm-linux-
或运行带参数的make:
1. $ cd /usr/scr/linuxXX
2. $ make ARCH=arm CROSS_COMPILE=arm-linux-
第二,内核组件选择
通过make XXconfig进行组件选择,选择组件的类型有:
- * 处理器选择
- * 载板选择
- * 驱动选择
- * 通用内核选项(generic kernel options)选择
完成组件选择后,kbuild会生成一些记录文件(KEMIN:就是配置文件.config),以便后续步骤参考。
第三,编译并链接
生成源码的目标文件,并链接成单一内核镜像文件,此过程步骤以下:
- 1.make dep:生成头文件依赖信息(.c文件依赖于哪个.h文件),此步只适用2.4版;
- 2.make clean/make mrpoper:make clean清理(先前)所有目标文件、内核镜像和所有中间生成文件,配置信息除外;make mrpoper则连配置信息也清除掉;
- 3.make:最后生成内核镜像——vmlinux文件。内核构建到处其实还没有完,内核镜像还需要一些后处理(postprocessing),比如压缩,比如加入启动代码(bootstrapping )等。由于平台和bootloader的差异,后处理过程没有标准。
第四,构建动态加载模块
构建动态加载模块,使用make modules 命令。
以上四步基本满足一般的内核构建需要,不过对[嵌入式系统 ],你可能需更多的自定义构建功能,比如:
- 你想为你的BSP指一个单独的目录
- 你想手动修改配置信息,为你的载板编译所需的软件
- 你想添加自己的链接器、编译器和汇编参数
- You may want to build intelligence in the kbuild for doing a systemwide build.
要想对内核构建系统做手脚,必须理解它的工作原理。
内核配置子系统
内核源码目录的顶层Makefile负责用来构建[内核镜像]和[动态加载模块]二者。它通过递归源码树的子目录来实现的,具体进入哪些子目录取决于组件的选择,也就是内核配置。
配置什么?
每种体系统都会输出组件列表给内核配置时选择,组件类型包括:
- 第一,处理器特性;
- 第二,硬件载板;
- 第三,载板特殊的硬件配置;
- 第四,内核子系统组件(这些组件或多或少是独立于体系的,比如网络协议栈)
配置库
每种体系都关联着一个组件数据库,此库以文件形式保存在arch/$ARCH目录下。2.4版是config.in,2.6版是Kconfig。在配置内核时,此文件会被解释(parsed)来提供组件选择。如果你要添加硬件特征[配置项 ],你得修改此文件。
配置语言
虽然内核配置使用make命令,[内核配置子系统 ]的配置库使用了一种不同的配置描述语言,并且2.4与2.6都有所不同。这种语言语法很简单,很接近自然语言,这里不详述,只谈使用技术。
什么是[ 内核配置子系统 ]?为什么可以使用不同的脚本语言?
因为配置过程是整个内核构建过程的串行子部分,产出特定的配置信息,所以完全可以使用独立的更简单的领域特定语言(domain-specific language)。
第一,每一个内核子部分(subsection)都有单独的配置文件定义配置规则,比如,网络部分,配置信息保存在子目录下的Kconfig。体系相关的配置文件会导入这个文件,例如,在2.4版,MIPS的体系配置文件(arch/mips/config- shared.in)有一行用来导入VFS的配置(fs/config.in)配置规则。
第二,配置文件.config通过名值对(name=value )保存[配置项 ]。配置项的名有前缀CONFIG_,后面跟着定义在配置文件里的组件名。配置项的值有如下几种:
- 布尔值:y or n
- 三态值(tristate): y, n, or m(module)
- 字符串:
- 整型:
- 十六进制数值:
第三,配置变量可以被定义为是否需要用户指定,如果不需要,配置变量使用默认值;
第四,可以为配置变量定义依赖;依赖性用来决定配置项的可见性;
第五,每个配置变量都关联一个帮助文本。
那么[内核配置子系统]是如何将被选择的组件信息输出到kbuild的呢?[内核配置子系统]在用户完全配置操作后会生成一个配置文件.config,内有已选定组件的[名值对]列表。顶层的makefile通过包含.config来达到组件选择。
配置例子
让我们看一个具体例子。假设我们有一个驱动源码 drivers/net/sample.c,它的配置项是CONFIG_SAMPLE,布尔值。当使用命令make config进行配置时,用户会被询问:
Build sample network driver (CONFIG_SAMPLE) [y/N]?
如果他选择y,那么“CONFIG_SAMPLE=y ”会被添加到.config文件。在drivers/net/Makefile内有一行:
obj-$(CONFIG_SAMPLE)+= sample.o
当这个makefile被kbuild递归读取到时,这一行会被翻译成:
obj-y+= sample.o
obj-y 是kbuild预先定义好的构建规则。如果配置变量是三态值,配置选择了模块,那么构建命令(makefile规则)是:
obj-m+= sample.o
对源码进行配置
除了[makefile规则]需要[配置信息]进行动态生成外,内核源码内同样有代码依赖配置信息。比如2.4版内核源码init/main.c 有如下代码:
#ifdef CONFIG_PCI
pci_init();
#endif
宏CONFIG_PCI定义与否的信息来自用户配置操作。为了把配置信息传递入源码,kbuild 得把[名值对]翻译成宏定义,保存在include/linux/autoconf.h。然后,这个头文件会被分拆为多个头文件,保存在include /config目录。例如上面的例子,CONFIG_PCI生成一个include/config/pci.h与之对应,内有一行:
#define CONFIG_PCI
为内核添加代码文件或代码片断
If you are a kernel developer and you make an addition to a particular subsystem, you place your files or edits in a specific subdirectory and update the Makefile if necessary to incorporate your changes. If your code is embedded in a file that already existed, you can surround your code within an #ifdef(CONFIG_<NAME>) block. If this value is selected in the .config file, it is #defined in include/ linux/autoconf.h and your changes are included at compile time.
2.6版kbuild
在2.6版的kbuild,由于更多的[构建信息]被转移到几个特别的Makefile去,比如编译器和库信息定义在顶层Makefile和体系相关Makefile,构建规则集中定义在scripts/Makefile.*s,所以子目录的Makefile的内容和格式变得相当简洁,它们只需要编织以下三个字符串:
- $(obj-y) 列出将链接入 built-in.o 的目标文件
- $(obj-m) 列出将用以构建动态加载模块的目标文件
- $(lib-y) 列出将用以构建lib.a的目标文件
与2.4相比,2.6有如下一些改进:
- 第一,没有需要显式包含的Rules.make,构建规则隐式导出(KEMIN:?);
- 第二,每一个Makefile不指定目标,因为有一个一致的构建目标:built-in.o;
- 第三,没有subdirs-* 变量,目录访问列表与目标列表使用同一个变量:obj-*;
- 第四,目标文件有导出符号的不需要特别指定(kbuild会根据源码内的EXPORT_SYMBOL宏进行判断符号的导出)。
2.4版与2.6版内核构建系统的差别
- 第一,2.6版的内核构建系统使用不同的框架,2.6版的kbuild更简单。比如,2.4版的体系相关makefile没有任何的标准,2.6的有。
- 第二,2.6版的操作提示更友好;
- 第三,2.6版可以把编译目标文件输出到别处(通过make O=dir ),2.4只能原地编译;
- 第四,2.4版的make dep会修改源文件的时间截,这会对一些源码管理系统产生影响。2.6版编译内核时不改动源码文件,这样保证你有一份只读的[源码树]。当多个开发者都拥自己的[目标树]的时候可以省下不少空间。
在正式开始递归调用make之前,kbuild必须得到一些信息,做一些预备工作,包括更新include/linux/version.h和设定 include/asm的符号链接(指定体系相关的文件),此外,kbuild还要创建include/linux/autoconf.h and include/linux/config。完成后,kbuild开始下行访问所有子目录,分别调用它们的Makefile,生成它们各的目标文件。具体实现原理,请看下一小节。
2.6版kbuild实现原理(待译)
In the source tree, virtually every directory has a Makefile. As mentioned in the previous section, the Makefiles in subtrees devoted to a particular category of the source code (or kernel subsystem) are fairly straightforward and merely define target source files to be added to the list that is then looked at to build them. Alongside these, five other Makefiles define rules and execute them. These include the source
- root Makefile,
- the arch/$(ARCH)/Makefile,
- scripts/Makefile.build,
- scripts/Makefile.clean,
- scripts/Makefile.
Figure 9.7 shows the relationship between the various Makefiles. We define the relationships to be of the " include " type or of the " execute " type. When we refer to an "include" type relationship, we mean that the Makefile pulls in the information from a file by using the rule include <filename> . When we refer to an "execute" type relationship, we mean that the original Makefile executes a make f call to the secondary Makefile.
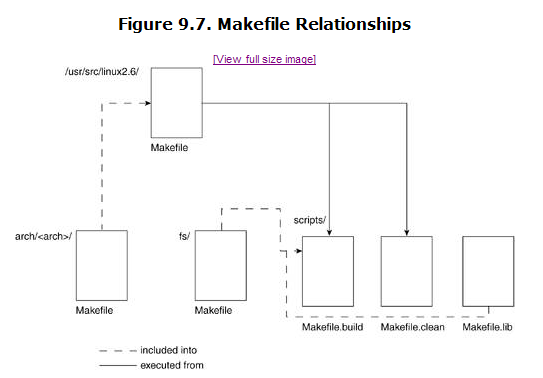
When we issue a make call at the root of the source tree, we call on the root Makefile. The root Makefile defines variables that are then exported to other Makefiles and issues further make calls in each of the root-level source subdirectories, passing off execution to them.
Calls to the compiler and linker are defined in scripts/Makefile.build. This means that when we descend into subdirectories and build the object by means of a call to make, we are somehow executing a rule defined in Makefile.build . This is done by way of the shorthand call $(Q) $(MAKE) $(build)=<dir>. This rule is the way make is invoked in each subdirectory. The build variable is shorthand for
Makefile
1157 build := -f $(if $(KBUILD_SRC),$(srctree)/)scripts/Makefile.build obj
-----------------------------------------------------------------------
A call to $(Q) $(MAKE) $(build)=fs expands to
"@ make f /path/to/source/scripts/Makefile.build obj=fs".
The scripts/Makefile.build then reads the Makefile of the directory it was passed as parameter (fs, in our example). This sub-Makefile has defined one or more of the lists obj-y, obj-m, lib-y, and others. The file scripts/Makefile.build, along with any definitions from the included scripts/ Makefile.lib, compiles the source files in the subdirectory and descends into any further subdirectories defined in the lists mentioned. The call is the same as what was just described.
Let's see how this works in an example. If, under the configuration tool, we go to the File Systems menu and select Ext3 journalling filesystem support, CONFIG_EXT3_FS will be set to y in the .config file. A snippet of the sub-Makefile corresponding to fs is shown here:
Makefile
49 obj-$(CONFIG_EXT3_FS) += ext3/
-----------------------------------------------------------------------
When make runs through this rule, it evaluates to obj-y += ext3/, making ext3/ one of the elements of obj-y. make, having recognized that this is a subdirectory, calls $(Q) $(MAKE) $(build)=ext3.
$(Q)
The $(Q) variable prefixes all $(MAKE) calls. With the 2.6 kernel tree and the cleanup of the kbuild infrastructure, you can suppress查禁; 压制; 废止 the verbose详细的, 冗长的 mode of the make output. make prints the command line prior to executing it. When a line is prefixed with the @, the output (or echo) of that line is suppressed:
--------------------------------------------------------------------
Makefile
254 ifeq ($(KBUILD_VERBOSE),1)
255 quiet =
256 Q =
257 else
258 quiet=quiet_
259 Q = @
260 endif
--------------------------------------------------------------------
As we can see in these lines, Q is set to @ if KBUILD_VERBOSE is set to 0, which means that we do not want the compile to be verbose.
参考
- Original translation: http://blog.csdn.net/keminlau/archive/2009/11/18/4831495.aspx
- Linux内核配置系统浅析:http://www.ibm.com/developerworks/cn/linux/kernel/l-kerconf/
- Contributing to the Linux Kernel—The Linux Configuration:http://www.linuxjournal.com/article/4082

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)